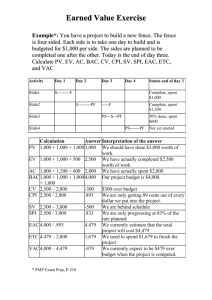
Presented
advertisement

Feature Selection for
High-Dimensional Data:
A Fast CorrelationBased Filter Solution
Presented by Jingting Zeng
11/26/2007
Outline
Introduction to Feature Selection
Feature Selection Models
Fast
Correlation-Based Filter (FCBF)
Algorithm
Experiment
Discussion
Reference
Introduction of Feature
Selection
Definition
A process
that chooses an optimal subset of features
according to an objective function
Objectives
To
reduce dimensionality and remove noise
To improve mining performance
Speed of learning
Predictive accuracy
Simplicity and comprehensibility of mined results
An Example for Optimal Subset
Data set (whole set)
Five
Boolean features
C = F1∨F2
F3= ┐F2 ,F5= ┐F4
Optimal subset:
{F1, F2}or{F1, F3}
Models of Feature Selection
Filter model
Separating
feature selection from classifier learning
Relying on general characteristics of data (information,
distance, dependence, consistency)
No bias toward any learning algorithm, fast
Wrapper model
Relying
on a predetermined classification algorithm
Using predictive accuracy as goodness measure
High accuracy, computationally expensive
Filter Model
Wrapper Model
Two Aspects for Feature
Selection
How to decide whether a feature is
relevant to the class or not
How to decide whether such a relevant
feature is redundant or not compared to
other features
Linear Correlation Coefficient
For a pair of variables (x,y):
However, it may not be able to capture the
non-linear correlations
Information Measures
Entropy of variable X
Entropy of X after observing Y
Information Gain
Symmetrical Uncertainty
Fast Correlation-Based Filter
(FCBF) Algorithm
How to decide whether a feature fi is
relevant to the class C or not
Find
a subset S ' , such that
fi S ', 1 i N , SUi ,c
How to decide whether such a relevant
feature is redundant
Use
the correlation of features and class as a
reference
Definitions
Predominant Correlation
fi
correlation between a feature f i and the
class C is predominant
iff SU i ,c and f j S ', SU j ,i SU i ,c
The
Redundant peer (RP)
there is SU j ,i SU i ,c, f j is a RP of f i
Use Sp to denote the set of RP for S i
i
If
Spi
i
Spi
C
Three Heuristics
If Spi , treat f i as a predominant feature,
remove all features in Spi and skip identifying
redundant peers for them
If Spi , process all the features in Spi at
first. If non of them becomes predominant,
follow the first heuristic
The feature with the largest SU i ,c value is
always a predominant feature and can be a
starting point to remove other features.
Spi
i
Spi
C
FCBF Algorithm
Time
Complexity:
O(N)
FCBF Algorithm (cont.)
Time
complexity:
O(NlogN)
Experiments
FCBF are compared to ReliefF, CorrSF
and ConsSF
Summary of the 10 data sets
Results
Results (cont.)
Pros and Cons
Advantage
Very
fast
Select fewer features with higher accuracy
Disadvantage
Cannot
detect some features
4 features generated by 4 Gaussian functions and
adding 4 additional redundant features, FCBF
selected only 3 features
Discussion
FCBF compares only individual features
with each other
Try to use PCA to capture a group of
features. Based on the result, then the
FCBF is used.
Reference
L. Yu and H. Liu. Feature selection for high-dimensional
data: A fast correlation-based filter solution. In Proc 12th
Int Conf on Machine Learning (ICML-03), pages 856–
863, 2003
Biesiada J, Duch W (2005), Feature Selection for HighDimensional Data: A Kolmogorov-Smirnov CorrelationBased Filter Solution. (CORES'05) Advances in Soft
Computing, Springer Verlag, pp. 95-104, 2005.
www.cse.msu.edu/~ptan/SDM07/Yu-Ye-Liu.pdf
www1.cs.columbia.edu/~jebara/6772/proj/Keith.ppt
Thank you!
Q and A