pptx
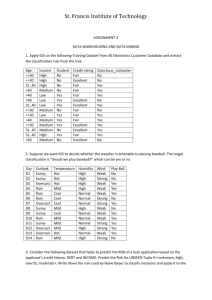
advertisement

Decision Trees
Reading: Textbook, “Learning From Examples”,
Section 3
Training data:
Day
Outlook
Temp
Humidity
D1
D2
D3
D4
D5
D6
D7
D8
D9
D10
D11
D12
D13
D14
Sunny
Sunny
Overcast
Rain
Rain
Rain
Overcast
Sunny
Sunny
Rain
Sunny
Overcast
Overcast
Rain
Hot
Hot
Hot
Mild
Cool
Cool
Cool
Mild
Cool
Mild
Mild
Mild
Hot
Mild
High
High
High
High
Normal
Normal
Normal
High
Normal
Normal
Normal
High
Normal
High
Wind
Weak
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Strong
PlayTennis
No
No
Yes
Yes
Yes
No
Yes
No
Yes
Yes
Yes
Yes
Yes
No
Decision Trees
• Target concept: “Good days to play tennis”
• Example:
<Outlook = Sunny, Temperature = Hot, Humidity =
High, Wind = Strong>
Classification?
• How can good decision trees be automatically constructed?
• Would it be possible to use a “generate-and-test” strategy
to find a correct decision tree?
– I.e., systematically generate all possible decision trees,
in order of size, until a correct one is generated.
• Why should we care about finding the simplest (i.e.,
smallest) correct decision tree?
Decision Tree Induction
• Goal is, given set of training examples, construct decision
tree that will classify those training examples correctly
(and, hopefully, generalize)
• Original idea of decision trees developed in 1960s by
psychologists Hunt, Marin, and Stone, as model of human
concept learning. (CLS = “Concept Learning System”)
• In 1970s, AI researcher Ross Quinlan used this idea for AI
concept learning:
– ID3 (“Itemized Dichotomizer 3”), 1979
The Basic Decision Tree Learning Algorithm
(ID3)
1. Determine which attribute is, by itself, the most useful
one for distinguishing the two classes over all the training
data. Put it at the root of the tree.
Outlook
The Basic Decision Tree Learning Algorithm
(ID3)
1. Determine which attribute is, by itself, the most useful
one for distinguishing the two classes over all the training
data. Put it at the root of the tree.
2. Create branches from the root node for each possible
value of this attribute. Sort training examples to the
appropriate value.
Outlook
Sunny Overcast
Rain
D4, D5, D6
D10, D14
D1, D2, D8
D9, D11
D3, D7, D12
D13
The Basic Decision Tree Learning Algorithm
(ID3)
1. Determine which attribute is, by itself, the most useful
one for distinguishing the two classes over all the training
data. Put it at the root of the tree.
2. Create branches from the root node for each possible
value of this attribute. Sort training examples to the
appropriate value.
3. At each descendant node, determine which attribute is, by
itself, the most useful one for distinguishing the two
classes for the corresponding training data. Put that
attribute at that node.
Outlook
Sunny Overcast
Rain
Wind
Humidity
Yes
The Basic Decision Tree Learning Algorithm
(ID3)
1. Determine which attribute is, by itself, the most useful
one for distinguishing the two classes over all the training
data. Put it at the root of the tree.
2. Create branches from the root node for each possible
value of this attribute. Sort training examples to the
appropriate value.
3. At each descendant node, determine which attribute is, by
itself, the most useful one for distinguishing the two
classes for the corresponding training data. Put that
attribute at that node.
4. Go to 2, but for the current node.
Note: This is greedy search with no backtracking
The Basic Decision Tree Learning Algorithm
(ID3)
1. Determine which attribute is, by itself, the most useful
one for distinguishing the two classes over all the training
data. Put it at the root of the tree.
2. Create branches from the root node for each possible
value of this attribute. Sort training examples to the
appropriate value.
3. At each descendant node, determine which attribute is, by
itself, the most useful one for distinguishing the two
classes for the corresponding training data. Put that
attribute at that node.
4. Go to 2, but for the current node.
Note: This is greedy search with no backtracking
How to determine which attribute is the best classifier for
a set of training examples?
E.g., why was Outlook chosen to be the root of the tree?
“Impurity” of a split
• Task: classify as Female or Male
• Instances: Jane, Mary, Alice, Bob, Allen, Doug
• Each instance has two binary attributes: “wears lipstick”
and “has long hair”
“Impurity” of a split
Pure split
Impure split
Wears lipstick
T
Jane, Mary, Alice
Has long hair
F
Bob, Allen, Doug
T
Jane, Mary, Bob
F
Alice, Allen, Doug
For the each node of the tree we want to choose attribute that
gives purest split.
But how to measure degree of impurity of a split ?
Entropy
• Let S be a set of training examples.
p+ = proportion of positive examples.
p− = proportion of negative examples
Entropy(S) = -(p+ log2 p+ + p- log2 p- )
• Entropy measures the degree of uniformity or nonuniformity in a collection.
• Roughly measures how predictable collection is, only on
basis of distribution of + and − examples.
Entropy
• When is entropy zero?
• When is entropy maximum, and what is its value?
•
Entropy gives minimum number of bits of information
needed to encode the classification of an arbitrary
member of S.
–
If p+ = 1, don’t need any bits (entropy 0)
– If p+ = .5, need one bit (+ or -)
–
If p+ = .8, can encode collection of {+,-} values using
on average less than 1 bit per value
•
Can you explain how we might do this?
Entropy of each branch?
Pure split
Impure split
Wears lipstick
T
Jane, Mary, Alice
Has long hair
F
Bob, Allen, Doug
T
Jane, Mary, Bob
F
Alice, Allen, Doug
What is the entropy of the “Play Tennis” training set?
Day Outlook Temp Humidity Wind
D1
D2
D3
D4
D5
D6
D7
D8
D9
D10
D11
D12
D13
D14
Sunny
Sunny
Overcast
Rain
Rain
Rain
Overcast
Sunny
Sunny
Rain
Sunny
Overcast
Overcast
Rain
Hot
Hot
Hot
Mild
Cool
Cool
Cool
Mild
Cool
Mild
Mild
Mild
Hot
Mild
High
High
High
High
Normal
Normal
Normal
High
Normal
Normal
Normal
High
Normal
High
Weak
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Strong
PlayTennis
No
No
Yes
Yes
Yes
No
Yes
No
Yes
Yes
Yes
Yes
Yes
No
•
Suppose you’re now given a new example. In absence of
any additional information, what classification should you
guess?
What is the average entropy of the “Humidity” attribute?
In-class exercise:
• Calculate information gain of the “Outlook” attribute.
Formal definition of Information Gain
Sv
Gain(S, A) = Entropy(S) - å
Entropy(Sv )
vÎValues(A ) S
where Values(A) = {possible values for attribute A} and
Sv = {instances Î S with value v of attribute A}
Sv
Gain(S, A) = Entropy(S) - å
Entropy(Sv ), where Sv = {instances Î S with value v}
S
vÎValues(A )
Day
Outlook
D1
D2
D3
D4
D5
D6
D7
D8
D9
D10
D11
D12
D13
D14
Sunny
Sunny
Overcast
Rain
Rain
Rain
Overcast
Sunny
Sunny
Rain
Sunny
Overcast
Overcast
Rain
Temp
Hot
Hot
Hot
Mild
Cool
Cool
Cool
Mild
Cool
Mild
Mild
Mild
Hot
Mild
Humidity
High
High
High
High
Normal
Normal
Normal
High
Normal
Normal
Normal
High
Normal
High
Wind
PlayTennis
Weak
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Strong
No
No
Yes
Yes
Yes
No
Yes
No
Yes
Yes
Yes
Yes
Yes
No
Operation of ID3
1. Compute information gain for each attribute.
Outlook
Temperature
Humidity
Wind
ID3’s Inductive Bias
• Given a set of training examples, there are typically many
decision trees consistent with that set.
– E.g., what would be another decision tree consistent
with the example training data?
• Of all these, which one does ID3 construct?
– First acceptable tree found in greedy search
ID3’s Inductive Bias, continued
• Algorithm does two things:
– Favors shorter trees over longer ones
– Places attributes with highest information gain closest
to root.
• What would be an algorithm that explicitly constructs the
shortest possible tree consistent with the training data?
ID3’s Inductive Bias, continued
• ID3: Efficient approximation to “find shortest tree”
method
• Why is this a good thing to do?
Overfitting
• ID3 grows each branch of the tree just deeply enough to
perfectly classify the training examples.
• What if number of training examples is small?
• What if there is noise in the data?
• Both can lead to overfitting
– First case can produce incomplete tree
– Second case can produce too-complicated tree.
But...what is bad about over-complex trees?
Overfitting, continued
• Formal definition of overfitting:
– Given a hypothesis space H, a hypothesis h H is said
to overfit the training data if there exists some
alternative h’ H, such that
TrainingError(h) < TrainingError(h’),
but
TestError(h’) < TestError(h).
Medical data set
Overfitting, continued
Accuracy
training data
test data
Size of tree (number of nodes)
Overfitting, continued
• How to avoid overfitting:
– Stop growing the tree early, before it reaches point of
perfect classification of training data.
– Allow tree to overfit the data, but then prune the tree.
Pruning a Decision Tree
• Pruning:
– Remove subtree below a decision node.
– Create a leaf node there, and assign most common
classification of the training examples affiliated with
that node.
– Helps reduce overfitting
Training data:
Day
Outlook
Temp
Humidity
D1
D2
D3
D4
D5
D6
D7
D8
D9
D10
D11
D12
D13
D14
D15
Sunny
Sunny
Overcast
Rain
Rain
Rain
Overcast
Sunny
Sunny
Rain
Sunny
Overcast
Overcast
Rain
Sunny
Hot
Hot
Hot
Mild
Cool
Cool
Cool
Mild
Cool
Mild
Mild
Mild
Hot
Mild
Hot
High
High
High
High
Normal
Normal
Normal
High
Normal
Normal
Normal
High
Normal
High
Normal
Wind
Weak
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Strong
Strong
PlayTennis
No
No
Yes
Yes
Yes
No
Yes
No
Yes
Yes
Yes
Yes
Yes
No
No
Example
Outlook
Sunny
Overcast
Rain
Wind
Humidity
Yes
Strong
High
Weak
Normal
No
No
Temperature
Hot
Mild
No
Cool
Yes
Yes
Yes
Example
Outlook
Sunny
Overcast
Rain
Wind
Humidity
Yes
Strong
High
Weak
Normal
No
No
Temperature
Hot
Mild
No
Cool
Yes
Yes
Yes
Example
Outlook
Sunny
Overcast
Rain
Wind
Humidity
Yes
Strong
High
Weak
Normal
No
No
Temperature
Hot
Mild
No
D9 Sunny Cool Normal Weak Yes
D11 Sunny Mild Normal Strong Yes
D15 Sunny Hot Normal Strong No
Cool
Yes
Yes
Yes
Example
Outlook
Sunny
Overcast
Rain
Wind
Humidity
Yes
Strong
High
Weak
Normal
No
No
Temperature
Hot
Mild
Yes
D9 Sunny Cool Normal Weak Yes
D11 Sunny Mild Normal Strong Yes
D15 Sunny Hot Normal Strong No
Cool
Majority: Yes
No
Yes
Yes
Example
Outlook
Sunny
Overcast
Rain
Wind
Humidity
Yes
Strong
High
Normal
No
No
Weak
Yes
Yes
How to decide which subtrees to prune?
How to decide which subtrees to prune?
Need to divide data into:
Training set
Pruning (validation) set
Test set
• Reduced Error Pruning:
– Consider each decision node as candidate for pruning.
– For each node, try pruning node. Measure accuracy of
pruned tree over pruning set.
– Select single-node pruning that yields best increase in
accuracy over pruning set.
– If no increase, select one of the single-node prunings
that does not decrease accuracy.
– If all prunings decrease accuracy, then don’t prune.
Otherwise, continue this process until further pruning is
harmful.
Simple validation
• Split training data into training set and validation set.
• Use training set to train model with a given set of parameters (e.g., #
training epochs). Then use validation set to predict generalization
accuracy.
Error rate
validation
training
stop training/pruning/... here
• Finally, use separate test set to test final classifier.
training time
or nodes pruned
or...
Miscellaneous
• If you weren’t here last time, see me during the break
• Graduate students (545) sign up for paper presentations
– This is optional for undergrads (445)
– Two volunteers for Wednesday April 17
• Coursepack on reserve in library
• Course mailing list: MLSpring2013@cs.pdx.edu
Recap from last time
Today
• Decision trees
• Continuous attribute values
• ID3 algorithm for constructing
decision trees
• Gain ratio
• UCI ML Repository
• Calculating information gain
• Optdigits data set
• Overfitting
• C4.5
• Reduced error pruning
• c pruning
• Evaluating classifiers
2
• Homework 1
Exercise: What is information gain of Wind?
Day
Outlook
D1
D2
D3
D4
D5
D6
D7
D8
D9
D10
D11
D12
D13
D14
Sunny
Sunny
Overcast
Rain
Rain
Rain
Overcast
Sunny
Sunny
Rain
Sunny
Overcast
Overcast
Rain
Temp
Hot
Hot
Hot
Mild
Cool
Cool
Cool
Mild
Cool
Mild
Mild
Mild
Hot
Mild
Gain(S, A) = Entropy(S) -
Humidity
Wind
High
High
High
High
Normal
Normal
Weak
Strong
Weak
Weak
Weak
Strong
Normal
High
Normal
Normal
Normal
Weak
Weak
Weak
Strong
High
Normal
High
å
vÎValues( A)
Sv
S
Weak
Strong
Entropy(Sv )
where Values(A) = {possible values for attribute A} and
Sv = {instances Î S with value v of attribute A}
PlayTennis
No
No
Yes
Yes
Yes
No
Strong
No
Yes
Yes
Yes
Strong
Yes
No
Yes
Yes
E(S) = .94
Continuous valued attributes
• Original decision trees: Two discrete aspects:
– Target class (e.g., “PlayTennis”) has discrete values
– Attributes (e.g., “Temperature”) have discrete values
• How to incorporate continuous-valued decision attributes?
– E.g., Temperature [0,100]
Continuous valued attributes, continued
• Create new attributes, e.g., Temperaturec true if
Temperature >= c, false otherwise.
• How to choose c?
– Find c that maximizes information gain.
Training data:
Day
Outlook
Temp
D1
D2
D3
D4
D5
D6
Sunny
Sunny
Overcast
Rain
Rain
Rain
85
72
62
60
20
10
Humidity
High
High
High
High
Normal
Normal
Wind
Weak
Strong
Weak
Weak
Strong
Weak
PlayTennis
No
No
Yes
Yes
No
Yes
• Sort examples according to values of Temperature found in
training set
Temperature:
10
20
60
62
72
85
PlayTennis:
Yes No
Yes Yes No
No
• Find adjacent examples that differ in target classification.
• Choose candidate c as midpoint of the corresponding
interval.
– Can show that optimal c must always lie at such a
boundary.
• Then calculate information gain for each candidate c.
• Choose best one.
• Put new attribute Temperaturec in pool of attributes.
Example
Temperature: 10
PlayTennis: Yes
20
No
60
Yes
62
Yes
72
No
85
No
Example
Temperature: 10
PlayTennis: Yes
20
No
60
Yes
62
Yes
72
No
85
No
Example
Temperature: 10
PlayTennis: Yes
20
No
60
Yes
c =15 c =40
62
Yes
72
No
c =67
85
No
Example
Temperature: 10
PlayTennis: Yes
20
No
60
Yes
62
Yes
c =15 c =40
Define new attribute: Temperature15 , with
Values(Temperature15) = { <15 , >=15}
72
No
c =67
85
No
Training data:
Day
Outlook
Temp
Humidity
D1
D2
D3
D4
D5
D6
Sunny
Sunny
Overcast
Rain
Rain
Rain
>=15
>=15
>=15
>=15
>=15
<15
High
High
High
High
Normal
Normal
What is Gain(S, Temperature15)?
Wind
Weak
Strong
Weak
Weak
Strong
Weak
PlayTennis
No
No
Yes
Yes
No
Yes
• All nodes in decision tree are of the form
Ai
Threshold
< Threshold
Alternative measures for selecting attributes
• Recall intuition behind information gain measure:
– We want to choose attribute that does the most work in
classifying the training examples by itself.
– So measure how much information is gained (or how
much entropy decreased) if that attribute is known.
• However, information gain measure favors attributes with
many values.
• Extreme example: Suppose that we add attribute “Date” to
each training example. Each training example has a
different date.
Day
Date
Outlook
Temp
Humidity Wind
D1
D2
D3
D4
D5
D6
D7
D8
D9
D10
D11
D12
D13
D14
3/1
3/2
3/3
3/4
3/5
3/6
3/7
3/8
3/9
3/10
3/11
3/12
3/13
3/14
Sunny
Sunny
Overcast
Rain
Rain
Rain
Overcast
Sunny
Sunny
Rain
Sunny
Overcast
Overcast
Rain
Hot
Hot
Hot
Mild
Cool
Cool
Cool
Mild
Cool
Mild
Mild
Mild
Hot
Mild
High
High
High
High
Normal
Normal
Normal
High
Normal
Normal
Normal
High
Normal
High
Gain (S, Outlook) = .94 - .694 = .246
What is Gain (S, Date)?
Weak
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Strong
PlayTennis
No
No
Yes
Yes
Yes
No
Yes
No
Yes
Yes
Yes
Yes
Yes
No
• Date will be chosen as root of the tree.
• But of course the resulting tree will not generalize
Gain Ratio
• Quinlan proposed another method of selecting attributes, called “gain
ratio”:
Gain Ratio(S, A) =
Gain(S, A)
Penalty Term for Splitting Data into too many parts
Suppose attribute A splits the training data S into m subsets. Call the
subsets S1, S2, ..., Sm.
ìï S S
S üï
We can define a set: Split ( S, A) = í 1 , 2 ,..., m ý
S ïþ
ïî S S
The Penalty Term is the entropy of this set.
m
Penalty Term (A)= Entropy ( Split(S, A)) = -å
i=1
Si
S
log2 i
S
S
For example: What is the Penalty Term for the “Date” attribute? How
about for “Outlook”?
Day
Date
Outlook
Temp
Humidity Wind
D1
D2
D3
D4
D5
D6
D7
D8
D9
D10
D11
D12
D13
D14
3/1
3/2
3/3
3/4
3/5
3/6
3/7
3/8
3/9
3/10
3/11
3/12
3/13
3/14
Sunny
Sunny
Overcast
Rain
Rain
Rain
Overcast
Sunny
Sunny
Rain
Sunny
Overcast
Overcast
Rain
Hot
Hot
Hot
Mild
Cool
Cool
Cool
Mild
Cool
Mild
Mild
Mild
Hot
Mild
High
High
High
High
Normal
Normal
Normal
High
Normal
Normal
Normal
High
Normal
High
PlayTennis
Weak
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Weak
Weak
Strong
Strong
Weak
Strong
No
No
Yes
Yes
Yes
No
Yes
No
Yes
Yes
Yes
Yes
Yes
No
m
Penalty Term (A)= Entropy ( Split(S, A)) = -å
i=1
Si
S
log2 i
S
S
UCI ML Repository
http://archive.ics.uci.edu/ml/
http://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of
+Handwritten+Digits
optdigits-pictures
optdigits.info
optdigits.names
Homework 1
• How to download homework and data
• Demo of C4.5
• Accounts on Linuxlab?
• How to get to Linux Lab
• Need help on Linux?
• Newer version C5.0: http://www.rulequest.com/see5-info.html