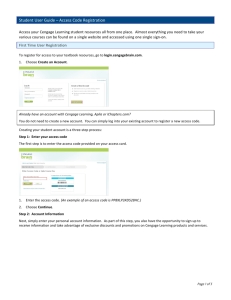
compute
advertisement

Chapter 13 Inference About Comparing Two Populations Copyright © 2009 Cengage Learning Comparing Two Populations Previously we looked at techniques to estimate and test parameters for one population: Population Mean µ Population Proportion p We will still consider these parameters when we are looking at two populations, however our interest will now be: The difference between two means. The ratio of two variances. The difference between two proportions. Copyright © 2009 Cengage Learning Difference between Two Means In order to test and estimate the difference between two population means, we draw random samples from each of two populations. Initially, we will consider independent samples, that is, samples that are completely unrelated to one another. Population 1 Sample, size: n1 Parameters: (Likewise, we consider Copyright © 2009 Cengage Learning Statistics: for Population 2) Difference between Two Means Because we are comparing two population means, we use the statistic, which is an unbiased and consistent estimator of µ1- µ2. Copyright © 2009 Cengage Learning Sampling Distribution of 1. is normally distributed if the original populations are normal –or– approximately normal if the populations are nonnormal and the sample sizes are large (n1, n2 > 30) 2. The expected value of 3. The variance of is µ1- µ2 is and the standard error is: Copyright © 2009 Cengage Learning Making Inferences About μ1-μ2 Since is normally distributed if the original populations are normal –or– approximately normal if the populations are nonnormal and the sample sizes are large, then: is a standard normal (or approximately normal) random variable. We could use this to build the test statistic and the confidence interval estimator for µ1 - µ2. Copyright © 2009 Cengage Learning Making Inferences About μ1-μ2 …except that, in practice, the z statistic is rarely used since the population variances are unknown. ?? Instead we use a t-statistic. We consider two cases for the unknown population variances: when we believe they are equal and conversely when they are not equal. More about this later… Copyright © 2009 Cengage Learning Test Statistic for μ1-μ2 (equal variances) Calculate – the pooled variance estimator as… …and use it here: degrees of freedom Copyright © 2009 Cengage Learning CI Estimator for μ1-μ2 (equal variances) The confidence interval estimator for μ1-μ2 when the population variances are equal is given by: pooled variance estimator Copyright © 2009 Cengage Learning degrees of freedom Test Statistic for μ1-μ2 (unequal variances) The test statistic for μ1-μ2 when the population variances are unequal is given by: degrees of freedom Likewise, the confidence interval estimator is: Copyright © 2009 Cengage Learning Which test to use? Which test statistic do we use? Equal variance or unequal variance? Whenever there is insufficient evidence that the variances are unequal, it is preferable to perform the equal variances t-test. This is so, because for any two given samples: The number of degrees of freedom for the equal variances case ≥ Larger numbers of degrees of freedom have the same effect as having larger sample sizes Copyright © 2009 Cengage Learning The number of degrees of freedom for the unequal variances case ≥ Testing the Population Variances Testing the Population Variances H0: σ12 / σ22 = 1 H1: σ12 / σ22 ≠ 1 Test statistic: s12 / s22, which is F-distributed with degrees of freedom ν1 = n1– 1 and ν2 = n2 −2. The required condition is the same as that for the t-test of µ1 - µ2 , which is both populations are normally distributed. Copyright © 2009 Cengage Learning Testing the Population Variances This is a two-tail test so that the rejection region is F F / 2,1 , 2 or F F1 / 2, , 1 2 Copyright © 2009 Cengage Learning Example 13.1 Millions of investors buy mutual funds choosing from thousands of possibilities. Some funds can be purchased directly from banks or other financial institutions while others must be purchased through brokers, who charge a fee for this service. This raises the question, can investors do better by buying mutual funds directly than by purchasing mutual funds through brokers. Copyright © 2009 Cengage Learning Example 13.1 To help answer this question a group of researchers randomly sampled the annual returns from mutual funds that can be acquired directly and mutual funds that are bought through brokers and recorded the net annual returns, which are the returns on investment after deducting all relevant fees. Xm13-01 Can we conclude at the 5% significance level that directlypurchased mutual funds outperform mutual funds bought through brokers? Copyright © 2009 Cengage Learning Example 13.1 IDENTIFY To answer the question we need to compare the population of returns from direct and the returns from broker- bought mutual funds. The data are obviously interval (we've recorded real numbers). This problem objective - data type combination tells us that the parameter to be tested is the difference between two means µ1- µ2. Copyright © 2009 Cengage Learning Example 13.1 IDENTIFY The hypothesis to be tested is that the mean net annual return from directly-purchased mutual funds (µ1) is larger than the mean of broker-purchased funds (µ2). Hence the alternative hypothesis is H1: µ1- µ2 > 0 and H0: µ1- µ2 = 0 To decide which of the t-tests of µ1 - µ2 to apply we conduct the F-test of σ12/ σ22 . Copyright © 2009 Cengage Learning Example 13.1 IDENTIFY From the data we calculated the following statistics. s12 = 37.49 and s22 = 43.34 Test statistic: F = 37.49/43.34 = 0.86 Rejection region: F F / 2,1 ,2 F.025,49,49 F.025,50,50 1.60 or F F1 / 2,1 , 2 F.975,49,49 1 / F.025,49,49 1 / F.025,50,50 1 / 1.60 .63 Copyright © 2009 Cengage Learning Example 13.1 IDENTIFY Click Data, Data Analysis, and F-Test Two Sample for Variances Copyright © 2009 Cengage Learning Example 13.1 IDENTIFY A B C 1 F-Test Two-Sample for Variances 2 3 Direct Broker 4 Mean 6.63 3.72 5 Variance 37.49 43.34 6 Observations 50 50 7 df 49 49 8 F 0.86 9 P(F<=f) one-tail 0.3068 10 F Critical one-tail 0.6222 The value of the test statistic is F = .86. Excel outputs the one-tail p-value. Because we're conducting a two-tail test, we double that value. Thus, the p-value of the test we're conducting is 2 .3068 = .6136. Copyright © 2009 Cengage Learning Example 13.1 IDENTIFY There is not enough evidence to infer that the population variances differ. It follows that we must apply the equalvariances t-test of µ1- µ2 Copyright © 2009 Cengage Learning Example 13.1 COMPUTE For manual calculations click Example 13.1 Manual Calculations For Excel skip to next slide. Copyright © 2009 Cengage Learning 12.22 Example 13.1 COMPUTE Click Data, Data Analysis, t-Test: Two-Sample Assuming Equal Variances Copyright © 2009 Cengage Learning Example 13.1 COMPUTE A B C 1 t-Test: Two-Sample Assuming Equal Variances 2 3 Direct Broker 4 Mean 6.63 3.72 5 Variance 37.49 43.34 6 Observations 50 50 7 Pooled Variance 40.41 8 Hypothesized Mean Difference 0 9 df 98 10 t Stat 2.29 11 P(T<=t) one-tail 0.0122 12 t Critical one-tail 1.6606 13 P(T<=t) two-tail 0.0243 14 t Critical two-tail 1.9845 Copyright © 2009 Cengage Learning Example 13.1 INTERPRET The value of the test statistic is 2.29. The one-tail p-value is .0122. We observe that the p-value of the test is small (and the test statistic falls into the rejection region). As a result we conclude that there is sufficient evidence to infer that on average directly-purchased mutual funds outperform broker-purchased mutual funds Copyright © 2009 Cengage Learning Confidence Interval Estimator Suppose we wanted to compute a 95% confidence interval estimate of the difference between mean caloric intake for consumers and non-consumers of high-fiber cereals. The unequal-variances estimator is (x1 x 2 ) t / 2 2 s p 1 1 n1 n 2 We use the t-Estimate_2 Means (Eq-Var) worksheet in the Estimators workbook or manually (Click here). Copyright © 2009 Cengage Learning Confidence Interval Estimator COMPUTE A B C D 1 t-Estimate of the Difference Between Two Means (Equal-Variances) 2 3 Sample 1 Sample 2 Confidence Interval Estimate 4 Mean 6.63 3.72 2.91 5 Variance 37.49 43.34 Lower confidence limit 6 Sample size 50 50 Upper confidence limit 7 Pooled Variance 40.42 8 Confidence level 0.95 Copyright © 2009 Cengage Learning E F ± 2.52 0.39 5.43 Confidence Interval Estimator INTERPRET We estimate that the return on directly purchased mutual funds is on average between .39 and 5.43 percentage points larger than broker-purchased mutual funds. Copyright © 2009 Cengage Learning Example 13.2 What happens to the family-run business when the boss’s son or daughter takes over? Does the business do better after the change if the new boss is the offspring of the owner or does the business do better when an outsider is made chief executive officer (CEO)? In pursuit of an answer researchers randomly selected 140 firms between 1994 and 2002, 30% of which passed ownership to an offspring and 70% appointed an outsider as CEO. Copyright © 2009 Cengage Learning Example 13.2 For each company the researchers calculated the operating income as a proportion of assets in the year before and the year after the new CEO took over. The change (operating income after – operating income before) in this variable was recorded. Xm13-02 Do these data allow us to infer that the effect of making an offspring CEO is different from the effect of hiring an outsider as CEO? Copyright © 2009 Cengage Learning Example 13.2 IDENTIFY The problem objective is to compare two populations. Population 1: Operating income of companies whose CEO is an offspring of the previous CEO Population 2: Operating income of companies whose CEO is an outsider The data type is interval (operating incomes). Thus, the parameter to be tested is µ1- µ2, where µ1 = mean operating income for population 1 and µ2 = mean operating income for population 2. Copyright © 2009 Cengage Learning Example 13.2 IDENTIFY We want to determine whether there is enough statistical evidence to infer that µ1 is different from µ2. That is, that µ1- µ2 is not equal to 0. Thus, H1: µ1- µ2 ≠ 0 and H0: µ1- µ2 = 0 We need to determine whether to use the equal-variances or unequal-variances t –test of µ1- µ2. Copyright © 2009 Cengage Learning Example 13.2 IDENTIFY Click Data, Data Analysis, and F-Test Two Sample for Variances Copyright © 2009 Cengage Learning Example 13.2 IDENTIFY A B C 1 F-Test Two-Sample for Variances 2 3 Offspring Outsider 4 Mean -0.10 1.24 5 Variance 3.79 8.03 6 Observations 42 98 7 df 41 97 8 F 0.47 9 P(F<=f) one-tail 0.0040 10 F Critical one-tail 0.6314 The value of the test statistic is F = .47. The p-value of the test we're conducting is 2 .0040 = .0080. Copyright © 2009 Cengage Learning Example 13.2 IDENTIFY Thus, the correct technique is the unequal-variances t-test of µ1- µ2. Copyright © 2009 Cengage Learning Example 13.2 COMPUTE For manual calculations click Example 13.2 manual calculations For Excel skip to next slide. Copyright © 2009 Cengage Learning 12.37 Example 13.2 COMPUTE Click Data, Data Analysis, t-Test: Two-Sample Assuming Unequal Variances Copyright © 2009 Cengage Learning Example 13.2… COMPUTE A B C 1 t-Test: Two-Sample Assuming Unequal Variances 2 3 Offspring Outsider 4 Mean -0.10 1.24 5 Variance 3.79 8.03 6 Observations 42 98 7 Hypothesized Mean Difference 0 8 df 111 9 t Stat -3.22 10 P(T<=t) one-tail 0.0008 11 t Critical one-tail 1.6587 12 P(T<=t) two-tail 0.0017 13 t Critical two-tail 1.9816 Copyright © 2009 Cengage Learning Example 13.2… INTERPRET The t-statistic is – 3.22 and its p-value is .0017. Accordingly, we conclude that there is sufficient evidence to infer that the mean times differ. Copyright © 2009 Cengage Learning Confidence Interval Estimator We can also draw inferences about the difference between the two population means by calculating the confidence interval estimator. We use the unequal-variances confidence interval estimator of and a 95% confidence level. We use the t-Estimate_2 Means (Uneq-Var) worksheet in the Estimators workbook or manually (Click here). Copyright © 2009 Cengage Learning Confidence Interval Estimator COMPUTE We activate the t-Estimate_2 Means (Uneq-Var) worksheet in the Estimators workbook and substitute the sample statistics and confidence level. A B C D 1 t-Estimate of the Difference Between Two Means (Unequal-Variances) 2 3 Sample 1 Sample 2 Confidence Interval Estimate 4 Mean -0.10 1.24 -1.34 5 Variance 3.79 8.03 Lower confidence limit 6 Sample size 42 98 Upper confidence limit 7 Degrees of freedom 110.75 8 Confidence level 0.95 Copyright © 2009 Cengage Learning E F ± 0.82 -2.16 -0.51 Confidence Interval Estimator INTERPRET We estimate that the mean change in operating incomes for outsiders exceeds the mean change in the operating income for offspring lies between .51 and 2.16 percentage points. Copyright © 2009 Cengage Learning Checking the Required Condition Both the equal-variances and unequal-variances techniques require that the populations be normally distributed. As before, we can check to see whether the requirement is satisfied by drawing the histograms of the data. Copyright © 2009 Cengage Learning Checking the Required Condition: Example 13.1 Frequency . Histogram 20 10 0 -5 0 5 10 15 20 More 15 20 More Direct Frequency Histogram 20 10 0 -5 0 5 10 Broker Copyright © 2009 Cengage Learning Checking the Required Condition: Example 13.2 Frequency . Histogram 20 10 0 -4 -2 0 2 4 Offspring Frequency Histogram 40 20 0 -4 -2 0 2 4 Outsider Copyright © 2009 Cengage Learning 6 8 10 Violation of the Required Condition When the normality requirement is unsatisfied, we can use a nonparametric technique-the Wilcoxon rank sum test for independent samples (Chapter 19)--to replace the equalvariances test of µ1-µ2 . We have no alternative to the unequal-variances test of µ1-µ2 when the populations are very nonnormal. Copyright © 2009 Cengage Learning Terminology If all the observations in one sample appear in one column and all the observations of the second sample appear in another column, the data is unstacked. If all the data from both samples is in the same column, the data is said to be stacked. Copyright © 2009 Cengage Learning Developing an Understanding of Statistical Concepts 1 The formulas in this section are relatively complicated. However, conceptually both test statistics are based on the techniques we introduced in Chapter 11 and repeated in Chapter 12. That is, the value of the test statistic is the difference between the statistic and the hypothesized value of the parameter measured in terms of the standard error. Statistic Parameter Test statistic S tan dard error Copyright © 2009 Cengage Learning Developing an Understanding of Statistical Concepts 2 As was the case with the interval estimator of p, the standard error must be estimated from the data for all inferential procedures introduced here. The method we use to compute the standard error of x1 x 2 depends on whether the population variances are equal. When they are equal we calculate and use the pooled variance estimator sp2. We are applying an important principle here, and we will so again in Section 13.5 and in later chapters. Where possible, it is advantageous to pool sample data to estimate the standard error. Copyright © 2009 Cengage Learning Developing an Understanding of Statistical Concepts 2 In the previous application, we are able to pool because we assume that the two samples were drawn from populations with a common variance. Combining both samples increases the accuracy of the estimate. Thus, sp2 is a better estimator of the common variance than either s12 or s22 separately. When the two population variances are unequal, we cannot pool the data and produce a common estimator. We must compute and use them to estimate σ12 and σ22, respectively. Copyright © 2009 Cengage Learning Identifying Factors I… Factors that identify the equal-variances t-test and estimator of : Copyright © 2009 Cengage Learning Identifying Factors II… Factors that identify the unequal-variances t-test and estimator of : Copyright © 2009 Cengage Learning “Ignorance ain’t what folks don’t know, it’s what folks know that just ain’t so”. Will Rogers Few things illustrate this more than how statistical results are interpreted. Copyright © 2009 Cengage Learning Example 13.3 Despite some controversy, scientists generally agree that high-fiber cereals reduce the likelihood of various forms of cancer. However, one scientist claims that people who eat high-fiber cereal for breakfast will consume, on average, fewer calories for lunch than people who don't eat high-fiber cereal for breakfast. Copyright © 2009 Cengage Learning Example 13.3 If this is true, high-fiber cereal manufacturers will be able to claim another advantage of eating their product--potential weight reduction for dieters. As a preliminary test of the claim, 150 people were randomly selected and asked what they regularly eat for breakfast and lunch. Copyright © 2009 Cengage Learning Example 13.3 Each person was identified as either a consumer or a nonconsumer of high-fiber cereal, and the number of calories consumed at lunch was measured and recorded. Xm13-03 Can the scientist conclude at the 5% significance level that his belief is correct? Copyright © 2009 Cengage Learning Example 13.3 H 0 : (1 2 ) 0 H1 : (1 2 ) 0 . A B C 1 t-Test: Two-Sample Assuming Unequal Variances 2 3 Consumers Nonconsumers 4 Mean 604.02 633.23 5 Variance 4103 10670 6 Observations 43 107 7 Hypothesized Mean Difference 0 8 df 123 9 t Stat -2.09 10 P(T<=t) one-tail 0.0193 11 t Critical one-tail 1.6573 12 P(T<=t) two-tail 0.0386 13 t Critical two-tail 1.9794 Copyright © 2009 Cengage Learning Example 13.3 The value of the test statistic is −2.09. The one-tail p-value is .0193. We conclude that there is sufficient evidence to infer that consumers of high-fiber cereal do eat fewer calories at lunch than do nonconsumers. Copyright © 2009 Cengage Learning Observational and Experimental Data From this result, we're inclined to believe that eating a highfiber cereal at breakfast may be a way to reduce weight. However, other interpretations are plausible. For example, people who eat fewer calories are probably more health conscious, and such people are more likely to eat high-fiber cereal as part of a healthy breakfast. In this interpretation, high-fiber cereals do not necessarily lead to fewer calories at lunch. Copyright © 2009 Cengage Learning Observational and Experimental Data Instead another factor, general health consciousness, leads to both fewer calories at lunch and high-fiber cereal for breakfast. Notice that the conclusion of the statistical procedure is unchanged. On average, people who eat high-fiber cereal consume fewer calories at lunch. However, because of the way the data were gathered, we have more difficulty interpreting this result. Copyright © 2009 Cengage Learning Observational and Experimental Data From the result in Example 13.3, we're inclined to believe that eating a high-fiber cereal at breakfast may be a way to reduce weight. However, other interpretations are possible. For example, people Who eat fewer calories at lunch are probably more health conscious, and such people are more likely to eat high-fiber cereal as part of a healthy breakfast. In this interpretation, high-fiber cereals do not necessarily lead to Fewer calories at lunch. Instead another factor, general health consciousness, leads to both fewer calories at lunch and high-fiber cereal for breakfast. Copyright © 2009 Cengage Learning Observational and Experimental Data Suppose that we redo Example 13.3 using the experimental approach. We randomly select 150 people to participate in the experiment. We randomly assign 75 to eat high-fiber cereal for breakfast and the other 75 to eat something else. We then record the number of calories each person consumes at lunch. Copyright © 2009 Cengage Learning Observational and Experimental Data Both groups should be similar in all other dimensions, including health consciousness. (Larger sample sizes increase the likelihood that the two groups will be similar.) If the statistical result is about the same as in Example 13.3, we may have some valid reason to believe that high-fiber cereal at breakfast leads to a decrease in caloric intake at lunch. Copyright © 2009 Cengage Learning Matched Pairs Experiment… Previously when comparing two populations, we examined independent samples. If, however, an observation in one sample is matched with an observation in a second sample, this is called a matched pairs experiment. To help understand this concept, let’s consider Example 13.4 Copyright © 2009 Cengage Learning Example 13.4 In the last few years a number of web-based companies that offer job placement services have been created. The manager of one such company wanted to investigate the job offers recent MBAs were obtaining. In particular, she wanted to know whether finance majors were being offered higher salaries than marketing majors. Copyright © 2009 Cengage Learning Example 13.4 In a preliminary study she randomly sampled 50 recently graduated MBAs half of whom majored in finance and half in marketing. From each she obtained the highest salary (including benefits) offer (Xm13-04). Can we infer that finance majors obtain higher salary offers than do marketing majors among MBAs? Copyright © 2009 Cengage Learning Example 13.4 IDENTIFY The parameter is the difference between two means (where µ1 = mean highest salary offer to finance majors and µ2 = mean highest salary offer to marketing majors). Because we want to determine whether finance majors are offered higher salaries, the alternative hypothesis will specify that is greater than. Calculation of the F-test of two variances indicates the use the equal-variances test statistic. Copyright © 2009 Cengage Learning Example 13.4 The hypotheses are H 0 : (1 2 ) 0 H1 : (1 2 ) 0 The Excel output is: Copyright © 2009 Cengage Learning IDENTIFY Example 13.4 COMPUTE A B C 1 t-Test: Two-Sample Assuming Equal Variances 2 3 Finance Marketing 4 Mean 65,624 60,423 5 Variance 360,433,294 262,228,559 6 Observations 25 25 7 Pooled Variance 311,330,926 8 Hypothesized Mean Difference 0 9 df 48 10 t Stat 1.04 11 P(T<=t) one-tail 0.1513 12 t Critical one-tail 1.6772 13 P(T<=t) two-tail 0.3026 14 t Critical two-tail 2.0106 Copyright © 2009 Cengage Learning Example 13.4 INTERPRET The value of the test statistic (t =1.04) and its p-value (.1513) indicate that there is very little evidence to support the hypothesis that finance majors attract higher salary offers than marketing majors. Copyright © 2009 Cengage Learning Example 13.4 INTERPRET We have some evidence to support the alternative hypothesis, but not enough. Note that the difference in sample means is x1 x 2 = (65,624 -60,423) = 5,201 Copyright © 2009 Cengage Learning Example 13.5 Suppose now that we redo the experiment in the following way. We examine the transcripts of finance and marketing MBA majors. We randomly sample a finance and a marketing major whose grade point average (GPA) falls between 3.92 and 4 (based on a maximum of 4). We then randomly sample a finance and a marketing major whose GPA is between 3.84 and 3.92. Copyright © 2009 Cengage Learning Example 13.5 We continue this process until the 25th pair of finance and marketing majors are selected whose GPA fell between 2.0 and 2.08. (The minimum GPA required for graduation is 2.0.) As we did in Example 13.4, we recorded the highest salary offer . Xm13-05 Can we conclude from these data that finance majors draw larger salary offers than do marketing majors? Copyright © 2009 Cengage Learning Example 13.5 IDENTIFY The experiment described in Example 13.4 is one in which the samples are independent. That is, there is no relationship between the observations in one sample and the observations in the second sample. However, in this example the experiment was designed in such a way that each observation in one sample is matched with an observation in the other sample. The matching is conducted by selecting finance and marketing majors with similar GPAs. Thus, it is logical to compare the salary offers for finance and marketing majors in each group. This type of experiment is called matched pairs. Copyright © 2009 Cengage Learning Example 13.5 IDENTIFY For each GPA group, we calculate the matched pair difference between the salary offers for finance and marketing majors. Copyright © 2009 Cengage Learning Example 13.5 IDENTIFY The numbers in black are the original starting salary data (Xm13-05) ; the numbers in blue were calculated. although a student is either in Finance OR in Marketing (i.e. independent), that the data is grouped in this fashion makes it a matched pairs experiment (i.e. the two students in group #1 are ‘matched’ by their GPA range the difference of the means is equal to the mean of the differences, hence we will consider the “mean of the paired differences” as our parameter of interest: Copyright © 2009 Cengage Learning Example 13.5 IDENTIFY Do Finance majors have higher salary offers than Marketing majors? Since: We want to research this hypothesis: H1: (and our null hypothesis becomes H0: Copyright © 2009 Cengage Learning ) Test Statistic for IDENTIFY The test statistic for the mean of the population of differences ( ) is: which is Student t distributed with nD–1 degrees of freedom, provided that the differences are normally distributed. Copyright © 2009 Cengage Learning Example 13.5 COMPUTE For manual calculations click Example 13.5 Manual Calculations For Excel skip to next slide. Copyright © 2009 Cengage Learning 12.80 Example 13.5 COMPUTE Click Data, Data Analysis, t-Test: Paired Two- Sample for Means Copyright © 2009 Cengage Learning Example 13.5 COMPUTE A B C 1 t-Test: Paired Two Sample for Means 2 3 Finance Marketing 4 Mean 65,438 60,374 5 Variance 444,981,810 469,441,785 6 Observations 25 25 7 Pearson Correlation 0.9520 8 Hypothesized Mean Difference 0 9 df 24 10 t Stat 3.81 11 P(T<=t) one-tail 0.0004 12 t Critical one-tail 1.7109 13 P(T<=t) two-tail 0.0009 14 t Critical two-tail 2.0639 Copyright © 2009 Cengage Learning Example 13.5 INTERPRET The p-value is .0004. There is overwhelming evidence that Finance majors do obtain higher starting salary offers than their peers in Marketing. Copyright © 2009 Cengage Learning Example 13.6 Confidence Interval Estimator for µD We can derive the confidence interval estimator for algebraically as: A B 1 t-Estimate: Mean 2 3 4 Mean 5 Standard Deviation 6 LCL 7 UCL Copyright © 2009 Cengage Learning C Difference 5065 6647 2321 7808 Checking the Required Condition The population of differences are required to be normally distributed. As before, we can check to see whether the requirement is satisfied by drawing the histogram of the differences. . Frequency Histogram 10 5 0 0 5000 10000 Difference Copyright © 2009 Cengage Learning 15000 20000 Violation of the Required Condition If the differences are very nonnormal, we cannot use the ttest of µD. We can, however, employ a nonparametric technique--the Wilcoxon signed rank sum test for matched pairs, which we present in Chapter 19. Copyright © 2009 Cengage Learning Independent Samples or Matched Pairs: Which Experimental Design is Better? Examples 13.4 and 13.5 demonstrated that the experimental design is an important factor in statistical inference. However, these two examples raise several questions about experimental designs. 1 Why does the matched pairs experiment result in rejecting the null hypothesis, whereas the independent samples experiment could not? Copyright © 2009 Cengage Learning Independent Samples or Matched Pairs: Which Experimental Design is Better? 2 Should we always use the matched pairs experiment? In particular, are there disadvantages to its use? 3 How do we recognize when a matched pairs experiment has been performed? Copyright © 2009 Cengage Learning Independent Samples or Matched Pairs: Which Experimental Design is Better? 1 The matched pairs experiment worked in Example 13.5 by reducing the variation in the data. To understand this point, examine the statistics from both examples. In Example 13.4, we found x1 x 2 5,201 and in Example 13.5 x D 5,065 Copyright © 2009 Cengage Learning Independent Samples or Matched Pairs: Which Experimental Design is Better? Thus, the numerators of the two test statistics were quite similar. However, the test statistic in Example 13.5 was much larger than the test statistic in Example 13.4 because of the standard errors. Copyright © 2009 Cengage Learning Independent Samples or Matched Pairs: Which Experimental Design is Better? In Example 13.4, we calculated s 2p 311,330 ,926 2 s p 1 1 4,991 n1 n 2 Example 13.5 produced s D 6,647 sD 1,329 nD Copyright © 2009 Cengage Learning Independent Samples or Matched Pairs: Which Experimental Design is Better? 2 Will the matched pairs experiment always produce a larger test statistic than the independent samples experiment? The answer is, “Not necessarily.” Suppose that in our example we found that companies did not consider grade point averages when making decisions about how much to offer the MBA graduates. In such circumstances, the matched pairs experiment would result in no significant decrease in variation when compared to independent samples. Copyright © 2009 Cengage Learning Independent Samples or Matched Pairs: Which Experimental Design is Better? 3 As you've seen, in this course we deal with questions arising from experiments that have already been conducted. Thus, one of your tasks is to determine the appropriate test statistic. In the case of comparing two populations of interval data, you must decide whether the samples are independent (in which case the parameter is) or matched pairs (in which case the parameter is) to select the correct test statistic. Copyright © 2009 Cengage Learning Independent Samples or Matched Pairs: Which Experimental Design is Better? To help you do so, we suggest you ask and answer the following question: Does some natural relationship exist between each pair of observations that provides a logical reason to compare the first observation of sample 1 with the first observation of sample 2, the second observation of sample 1 with the second observation of sample 2, and so on? If so, the experiment was conducted by matched pairs. If not, it was conducted using independent samples. Copyright © 2009 Cengage Learning Developing an Understanding of Statistical Concepts 1 Two of the most important principles in statistics were applied in this section. The first is the concept of analyzing sources of variation. In Examples 13.4 and 13.5, we showed that by reducing the variation between salary offers in each sample we were able to detect a real difference between the two majors.. Copyright © 2009 Cengage Learning Developing an Understanding of Statistical Concepts 1 This was an application of the more general procedure of analyzing data and attributing some fraction of the variation to several sources. In Example 13.5, the two sources of variation were the GPA and the MBA major. However, we were not interested in the variation between graduates with differing GPAs. Instead we only wanted to eliminate that source of variation, making it easier to determine whether finance majors draw larger salary offers. Copyright © 2009 Cengage Learning Developing an Understanding of Statistical Concepts 1 In Chapter 14, we will introduce a technique called the analysis of variance which does what its name suggests; it analyzes sources of variation in an attempt to detect real differences. In most applications of this procedure, we will be interested in each source of variation and not simply in reducing one source. We refer to the process as explaining the variation. The concept of explained variation also will be applied in Chapters 16 - 18. Copyright © 2009 Cengage Learning Developing an Understanding of Statistical Concepts 2 The second principle demonstrated in this section is that statistics practitioners can design data-gathering procedures in such a way that they can analyze sources of variation. Before conducting the experiment in Example 13.5, the statistics practitioner suspected that there were large differences between graduates with different GPAs. Copyright © 2009 Cengage Learning Developing an Understanding of Statistical Concepts 2 Consequently, the experiment was organized so that the effects of those differences were mostly eliminated. It is also possible to design experiments that allow for easy detection of real differences and minimize the costs of data gathering. Copyright © 2009 Cengage Learning Identifying Factors… Factors that identify the t-test and estimator of Copyright © 2009 Cengage Learning : Inference about the ratio of two variances So far we’ve looked at comparing measures of central location, namely the mean of two populations. When looking at two population variances, we consider the ratio of the variances, i.e. the parameter of interest to us is: The sampling statistic: is F distributed with degrees of freedom. Copyright © 2009 Cengage Learning Inference about the ratio of two variances Our null hypothesis is always: H0: (i.e. the variances of the two populations will be equal, hence their ratio will be one) Therefore, our statistic simplifies to: Copyright © 2009 Cengage Learning Example 13.7 IDENTIFY In Example 12.3, we applied the chi-squared test of a variance to determine whether there was sufficient evidence to conclude that the population variance was less than 1.0. Suppose that the statistics practitioner also collected data from another container-filling machine and recorded the fills of a randomly selected sample. Can we infer at the 5% significance level that the second machine is superior in its consistency? Copyright © 2009 Cengage Learning Example 13.7 IDENTIFY The problem objective is to compare two populations where the data are interval. Because we want information about the consistency of the two machines, the parameter we wish to test is σ12 / σ22, where σ12 is the variance of machine 1 and σ22, is the variance for machine 2. Copyright © 2009 Cengage Learning Example 13.7 IDENTIFY We need to conduct the F-test of to determine whether the variance of population 2 is less than that of population 1. Expressed differently, we wish to determine whether there is enough evidence to infer that is σ12 is larger than σ22. Hence the hypotheses we test are H0: σ12 / σ22 = 1 H1: σ12 / σ22 > 1 Copyright © 2009 Cengage Learning Example 13.7 COMPUTE For manual calculations click Example 13.7 Manual Calculations For Excel skip to next slide. Copyright © 2009 Cengage Learning 12.106 Example 13.7 COMPUTE Click Data, Data Analysis, F-Test Two-Sample for Variances. Copyright © 2009 Cengage Learning Example 13.7 A B C 1 F-Test Two-Sample for Variances 2 3 Machine 1 Machine 2 4 Mean 999.7 999.8 5 Variance 0.6333 0.4528 6 Observations 25 25 7 df 24 24 8 F 1.40 9 P(F<=f) one-tail 0.2085 10 F Critical one-tail 1.9838 Copyright © 2009 Cengage Learning COMPUTE Example 13.7 INTERPRET There is not enough evidence to infer that the variance of machine 2 is less than the variance of machine 1. Copyright © 2009 Cengage Learning Example 13.8 Determine the 95% confidence interval estimate of the ratio of the two population variances in Example 13.7. The confidence interval estimator for σ12 / σ22 is: Copyright © 2009 Cengage Learning Example 13.8 COMPUTE For manual calculations click Example 13.8 Manual Calculations For Excel skip to next slide. Copyright © 2009 Cengage Learning 12.111 Example 13.8 COMPUTE Open the F-Estimator_2 Variances worksheet in the Estimators workbook and substitute sample variances, samples sizes, and the confidence level. A B C D 1 F-Estimate of the Ratio of Two Variances 2 3 Sample 1 Sample 2 Confidence Interval Estimate 4 Sample variance 0.6333 0.4528 Lower confidence limit 5 Sample size 25 25 Upper confidence limit 6 Confidence level 0.95 E 0.6164 3.1741 That is, we estimate that σ12 / σ22 lies between .6164 and 3.1741 Note that one (1.00) is in this interval. Copyright © 2009 Cengage Learning Identifying Factors Factors that identify the F-test and estimator of Copyright © 2009 Cengage Learning : Difference Between Two Population Proportions We will now look at procedures for drawing inferences about the difference between populations whose data are nominal (i.e. categorical). As mentioned previously, with nominal data, calculate proportions of occurrences of each type of outcome. Thus, the parameter to be tested and estimated in this section is the difference between two population proportions: p1–p2. Copyright © 2009 Cengage Learning Statistic and Sampling Distribution… To draw inferences about the the parameter p1–p2, we take samples of population, calculate the sample proportions and look at their difference. is an unbiased estimator for p1–p2. x1 successes in a sample of size n1 from population 1 Copyright © 2009 Cengage Learning Sampling Distribution The statistic is approximately normally distributed if the sample sizes are large enough so that: Since its “approximately normal” we can describe the normal distribution in terms of mean and variance… …hence this z-variable will also be approximately standard normally distributed: Copyright © 2009 Cengage Learning Testing and Estimating p1–p2 Because the population proportions (p1 & p2) are unknown, the standard error: is unknown. Thus, we have two different estimators for the standard error of , which depend upon the null hypothesis. We’ll look at these cases on the next slide… Copyright © 2009 Cengage Learning Test Statistic for p1–p2 There are two cases to consider… Copyright © 2009 Cengage Learning Example 13.9 The General Products Company produces and sells a bath soap, which is not selling well. Hoping to improve sales General products decided to introduce more attractive packaging. The company’s advertising agency developed two new designs. Copyright © 2009 Cengage Learning Example 13.9 The first design features several bright colors to distinguish it from other brands. The second design is light green in color with just the company’s logo on it. As a test to determine which design is better the marketing manager selected two supermarkets. In one supermarket the soap was packaged in a box using the first design and in the second supermarket the second design was used. Copyright © 2009 Cengage Learning Example 13.9 The product scanner at each supermarket tracked every buyer of soap over a one week period. The supermarkets recorded the last four digits of the scanner code for each of the five brands of soap the supermarket sold. Xm13-09 The code for the General Products brand of soap is 9077(the other codes are 4255, 3745, 7118, and 8855). Copyright © 2009 Cengage Learning Example 13.9 After the trial period the scanner data were transferred to a computer file. Because the first design is more expensive management has decided to use this design only if there is sufficient evidence to allow them to conclude that it is better. Should management switch to the brightly-colored design or the simple green one? Copyright © 2009 Cengage Learning Example 13.9 IDENTIFY The problem objective is to compare two populations. The first is the population of soap sales in supermarket 1 and the second is the population of soap sales in supermarket 2. The data are nominal because the values are “buy General Products soap” and “buy other companies’ soap.” These two factors tell us that the parameter to be tested is the difference between two population proportions p1-p2 (where p1 and p2 are the proportions of soap sales that are a General Products brand in supermarkets 1 and 2, respectively. Copyright © 2009 Cengage Learning Example 13.9 IDENTIFY Because we want to know whether there is enough evidence to adopt the brightly-colored design, the alternative hypothesis is H1: (p1 – p2) > 0 The null hypothesis must be H0: (p1 – p2) = 0 which tells us that this is an application of Case 1. Thus, the test statistic is z Copyright © 2009 Cengage Learning (p̂1 p̂ 2 ) 1 1 p̂(1 p̂) n1 n 2 Example 13.9 COMPUTE For manual calculations click Example 13.9 Manual Calculations For Excel skip to next slide. Copyright © 2009 Cengage Learning 12.125 Example 13.9 COMPUTE Click Add-Ins, Data Analysis Plus, Z-Test: 2 Proportions Copyright © 2009 Cengage Learning Example 13.9 COMPUTE A B C 1 z-Test: Two Proportions 2 3 Supermarket 1 Supermarket 2 4 Sample Proportions 0.1991 0.1493 5 Observations 904 1038 6 Hypothesized Difference 0 7 z Stat 2.90 8 P(Z<=z) one tail 0.0019 9 z Critical one-tail 1.6449 10 P(Z<=z) two-tail 0.0038 11 z Critical two-tail 1.96 Copyright © 2009 Cengage Learning Example 13.9 INTERPRET The value of the test statistic is z = 2.90; its p-value is .0019. There is enough evidence to infer that the brightly-colored design is more popular than the simple design. As a result, it is recommended that management switch to the first design. Copyright © 2009 Cengage Learning Example 13.10 Suppose in our test marketing of soap packages scenario that instead of just a difference between the two package versions, the brightly colored design had to outsell the simple design by at least 3% Copyright © 2009 Cengage Learning Example 13.10 IDENTIFY Our research hypothesis now becomes: H1: (p1–p2) > .03 And so our null hypothesis is: H0: (p1–p2) = .03 Since the r.h.s. of H0 is not zero, it’s a “case 2” type problem Copyright © 2009 Cengage Learning Example 13.10 COMPUTE Click Add-Ins, Data Analysis Plus, Z-Test: 2 Proportions Copyright © 2009 Cengage Learning Example 13.10 COMPUTE A B C 1 z-Test: Two Proportions 2 3 Supermarket 1 Supermarket 2 4 Sample Proportions 0.1991 0.1493 5 Observations 904 1038 6 Hypothesized Difference 0.03 7 z Stat 1.14 8 P(Z<=z) one tail 0.1261 9 z Critical one-tail 1.6449 10 P(Z<=z) two-tail 0.2522 11 z Critical two-tail 1.96 Copyright © 2009 Cengage Learning Example 13.10 INTERPRET There is not enough evidence to infer that the brightly colored design outsells the other design by 3% or more. Copyright © 2009 Cengage Learning Confidence Interval Estimator The confidence interval estimator for p1–p2 is given by: and as you may suspect, its valid when… Copyright © 2009 Cengage Learning Example 13.11 To help estimate the difference in profitability, the Marketing manager in Examples 13.9 and 13.10 would like to estimate the difference between the two proportions. A confidence level of 95% is suggested. Copyright © 2009 Cengage Learning Example 13.11 COMPUTE For manual calculations click Example 13.11 Manual Calculations For Excel skip to next slide. Copyright © 2009 Cengage Learning 12.136 Example 13.11 COMPUTE Click Add-Ins, Data Analysis Plus, Z-Estimate: 2 Proportions Copyright © 2009 Cengage Learning Example 13.11 COMPUTE A B C D 1 z-Estimate: Two Proportions 2 3 Supermarket 1 Supermarket 2 4 Sample Proportions 0.1991 0.1493 5 Observations 904 1038 6 7 LCL 0.0159 8 UCL 0.0837 Copyright © 2009 Cengage Learning Identifying Factors… Factors that identify the z-test and estimator for p1–p2 Copyright © 2009 Cengage Learning