Speech Processing: The Natural Method BME5525 Project Report
advertisement

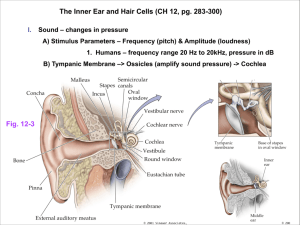
Speech Processing: The Natural Method BME5525 Project Report (FIT, Summer 2014) Francisco J. Rocha Abstract– This paper presents a view into the natural human speech recognition process. The current state of the art speech recognition methods have not yet achieved the level of adaptability and sophistication of the natural process. Humans are able to recognize and understand the voice of a person in a room while others are talking, they can also identify the direction of the source, and even the emotion with which the person is talking. This study is intended to explore the elements involved in the natural recognition of speech in humans, while keeping in view the potential portability of those elements to artificial systems. I. INTRODUCTION Hearing is a perception of external excitation factors, and in that aspect it is no different from other senses like touch or smell. However, just being able to hear a sound is not sufficient to enable the ability to understand speech. Speech carries much more information than just sound, it is a complex message that conveys meaning and emotion. The ability to understand such a message is acquired over a long period of time during a person’s developmental process. It is the culmination of training of a very large number of neurons, all interconnected and working together to decode a very intricate message in a quick and efficient way. Humans have an extremely well developed communication system, it involves the abilities to produce speech and to understand it. Humans can discern the voice and message from a single person in the middle of a room full of other talking people, but we are not alone in this ability, other animals are also capable of distinguishing a single individual’s “voice”, seals and penguins are known to be able to recognize a single individual from the pack by simply listening to their call. However, they are not able to carry a conversation like humans do. That ability is exclusive to our species and is the result of an evolved brain with the appropriate neuronal interconnections that enable the conveyance of abstract ideas and emotions via words and intonation. The brain uses just a few distinct elements in the recognition of speech; those are the external ear, the middle ear, the Cochlea with its organ of Corti, and the neurons that connect this system to the massive neuronal interconnectivity of the brain. It is this last element and all of its parallel interconnections with immense quantities of neurons that is the key for the almost instantaneous recognition of speech. II. Figure 1: Sound arrives to the external ear in waves of pressure differentials caused by compression and rarefaction of air [1]. Figure 2: Sound travels through the ear canal into the middle ear where it causes movement of the eardrum [1]. THE HEARING PROCESS. Sound is transported from point A to point B by the translational expansion of oscillatory pressure differentials of air molecules [1] [2] [3]. These differentials arrive to the external ear and are guided into the ear canal. At the end of the ear canal is the tympanic membrane that is pushed in when high pressures arrive, and bows out in response to low pressures [1] [3]. Figure 3: Sound pressure differentials cause movement of the tympanic membrane. The Malleus-Incus-Stapes bones amplify that movement and transmit it to the inner ear. [1]. The tympanic membrane oscillates in synchrony with the arrival of the pressure differentials, and in turn it moves the bones in the inner ear, the Malleus, the Incus, and the Stapes [1]. These bones are arranged such that they modulate the Page 1 of 7 F. Rocha amplitude of the vibrations and transmit them into the inner ear. They are also connected to small ligaments intended to limit the movement and regulate the projection of the bones under high amplitude sounds [1]. The vibrations of the Stapes are transmitted directly into the Cochlea, which is a tube filled with fluid and capped on the opposite end by a membrane called the oval window. This tube is folded in half at the Helicotrema [Figure 3] and both halves are separated by the organ of Corti [1]. The Cochlea is arranged in such a way, that it resonates at different locations to different frequencies [Figure 4]. This characteristic resonance is what establishes the basis by which we can recognize individual frequencies of sound [1], or complex sounds with multiple simultaneous frequencies like music or speech [4]. the two membranes are mechanically excited when oscillations traverse from one side of the Cochlea to the other. This is due to deflection of the Basilar membrane against the Tectorial membrane [Figure 6]. Figure 5: The Cochlea is a closed tube capped with the Stapes bone in one end, and a flexible membrane on the other. The tube is folded in half and the halves are separated by the Organ of Corti. [1]. Figure 4: Different sound frequencies resonate at different locations within the Cochlea, this resonance produces deflection of the Basilar membrane. [1]. The organ of Corti [Figure 5] stands between both halves of the Cochlea, and its walls are formed by the Basilar membrane. When the Stapes transmit the sound oscillations into the Cochlea, the Basilar membrane deflects to accommodate those oscillations and functions as a shortcut for the wave to reach the oval window [1]. The Basilar membrane has embedded within itself a series of about 15,000 specialized neurons called Hair cells [Figure 5]. These Hair cells transduce mechanical excitation into neuronal impulses called “Action Potentials” and they are directly responsible for sensing the fluid oscillations in the Cochlea. The Tectorial membrane is inside the organ of Corti; its function is to serve as a kinetic counterbalance to oppose the movement of the Basilar membrane. Hair cells located between Figure 6: The Tectorial membrane rests on hair-cells that fire neural impulses when stimulated by movement. [1]. Page 2 of 7 F. Rocha Figure 7: The organ of Corti has about 15,000 hair cells evenly distributed along its entire length [1] [2]. All hair cells respond in the same way to mechanical stimulus, however, the resonance characteristics of the cochlear duct have physically defined frequency response; groups of contiguous hair cells respond to excitation with a corresponding positional frequency grouping. Hair cells are the business end of the hearing system: they are the true sensor of sound vibrations, and transduce the mechanical vibrations into the neuronal impulses that convey the necessary information to the brain [Figure 6]. III. Hair cells are very fragile neurons and do not regenerate; once damaged hair cells do not heal and are replaced by scar tissue, this process is conducive to irreversible deafness [1] [Figure 10]. THE LOUDNESS DETECTION Hair cells have very fine sensitivity and detect the slightest mechanical movement of the Basilar and Tectorial membranes. They are so sensitive, that can detect deflections of the membrane comparable to a fraction of the diameter of a hydrogen atom [1]. The transduction function of hair cells is essentially that of a frequency modulator, where amplitude of membrane deflection is the modulation factor [Figure 8]. Large membrane deflection produces a higher mechanical excitation of the hair cells, and therefore a higher frequency of the neuronal impulses generated by the hair cells [Figure 9]. The modulation bandwidth range for this frequency goes from 0 Hz (at rest), to about 200 Hz (for maximum excitation). Figure 8: Hair cells operate by transmitting neural impulses of constant amplitude: 1 Vp-p from -70 mV to +30 mV. However, their frequency is proportional to the intensity of the stimulus they receive. Figure 10: The auditory system can detect sounds so faint that the distance of basilar membrane deflection is comparable to only a fraction of the diameter of a hydrogen atom. Extreme sound pressure levels cause excessive travel of the basilar membrane and results in scarring and irreversible damage of hair cells. Each hair cell generates neurotransmitter signals proportional to the stimulus they receive [1] [3], these signals are received by a single neuron that distributes those signals to a third layer of multiple receiving neurons [3]. Neurons at rest are always in a process to reach a steadystate charge of about -70 mV [1] [2]. At the synaptic interface, a receiving neuron must reach a threshold of -50 mV before it can fire a neuronal signal (action potential). Interconnections of neurons at the synaptic interface can be either excitatory or inhibitory [1] [2]. Therefore, a threshold potential can be reached by rapid arrival of multiple excitatory action potentials from a single input, or by simultaneous arrival of excitatory action potentials from multiple inputs [Figure 11]. However, arrival of inhibitory inputs is also possible, and these inputs can discharge the receiving neurons and cancel the effect of excitatory inputs. Inhibitory function is very important as it can regulate the effect of multiple neurons arriving onto a single one [2]. This function can be interpreted as a “voting” mechanism by which Figure 9: Therefore, a stronger stimulus produces higher frequency impulses than a weaker one. Page 3 of 7 F. Rocha Figure 11: Graded potentials build up charge at postsynaptic neurons, excitatory inputs arriving close together are likely to trigger an action potential, whereas inhibitory inputs reduce charge and the likeliness of firing action potential. [1]. Higher frequencies of excitatory inputs are more likely to buildup sufficient charge to fire an action potential. some neurons “vote” in favor of triggering a response while others “vote” against. With respect of speech recognition, this function is paramount to combine the response to multiple frequencies and identify a phoneme based on the expert “vote” of a set of neurons trained to recognize a specific sound. IV. THE (VERY) FAST FOURIER TRANSFORM As described earlier, the Cochlea has physical characteristics that enable frequencies from 20 Hz to about 20,000 Hz to resonate at specific locations. Because of this property, and thanks to the distribution of hair cells along the length of the organ of Corti, it is possible for the inner ear to perform instantaneous time-domain to frequency-domain decomposition of sound. This a function of the physical geometry of the Cochlea, and involves no algorithms or calculations whatsoever, therefore it is not subject to windowing or filtering artifacts; it is simply a resonance chamber with a continuous distribution of sensors along its length resulting in a direct digitization of its frequency response. Each one of the hair cells corresponds to one bit of information that represents its own specific frequency [1] [2] [3] [5]. Figure 12: A specific sound can be identified by a neuron that receives the appropriate combination of inputs from a define set of hair cells. These sound-identifying neurons feed forward into other neurons that detect a sequence of identifiable sounds (i.e. words). [1] Page 4 of 7 F. Rocha V. DIRECT SPEECH RECOGNITION ASCII encoding is done using only 7 bits. In this way, one can encode up to 27 = 128 different characters [Figure 13]. Modern computers use 64 bits to encode information; that translates into 264 = 8.446 x1018 possible individual characters. Thanks to the 15,000 hair cells distributed along the organ of Corti, humans can distinguish about 15,000 individual frequencies, thus resulting in about 215,000 = 2.818 x104515 possible combinations of distinguishable complex sounds! There are time delays involved in the inter-neuron communication essential to speech recognition. These delays allow successive cascading and coherent signal arrival of recognizable sounds. To illustrate the above process, let’s consider a neuron recognizing the proper combination of hair cell signals corresponding to the sound “S” and that it fires at time t0, it then will feed its dendrite outputs to all possible neurons that can follow the “S” sound: “C”, “P”, “N”, “T”, … etc. All the receiving neurons are thus briefly activated and are now “listening” to the corresponding signals from hair cells that would indicate the presence of the next sound in the sequence. In this case, let’s say the following sound received is “T”, then the only the neuron corresponding to the sequence “ST” is triggered at time t1 and fires, its output is now sent to all the possible neurons that could follow after “ST” such as “A”, “O”, “U”, “R”, etc. If the next sound is “R”, then the corresponding neuron would fire and activate the next sequence of neurons to detect all possible subsequent combinations. This process repeats until the entire word “STRONG” is decoded. Figure 13: ASCII encoding is done using only 7 bits. With this encoding, one can encode up to 27 = 128 different characters Although 215,000 is an overwhelmingly impressive number, it only contemplates the “on” or “off” states of detectable frequencies. In reality, each one of those frequencies is detected by hair cells sensitive to the continuous variation of amplitude, resulting in the neuronal output from hair cells with continuous frequency modulation of action potentials. The overall result is our ability to detect an infinite number of distinguishable sounds, each of them different from the next by a succinct combination of frequencies and amplitudes. Figure 15: Sequential sound identification and selection from a predetermined sequence is essential to speech recognition and forming of words. In addition to sounds sequences, the human speech recognition system is also capable of identifying subtle characteristics in sounds that differentiate one speaker from another. One can think of this functionality in a similar way as our ability of distinguishing shades of colors. That is how we can instantaneously detect not only what is said, but also who is saying it, see Figure 16 and Figure 17 for an illustration of this concept. Figure 14: The activation of specific groups of hair cells, combined with their proportional intensity (loudness), are the elements that identify sounds as perception of specific phonemes. Detection of a single complex sound is not sufficient for speech recognition. It is necessary to detect a sequence of sounds that together form words or expressions. Our neurons are arranged in a vastly interconnected network that facilitates cascaded progression and combination of signals [Figure 15Figure 12]. Figure 16: Illumination of a select group of pixels is used in displays to visually represent letters. In a similar manner, “illumination” or firing of a select group of neurons identifies the specific sounds corresponding to a given phoneme. Page 5 of 7 F. Rocha Left sound t0 tn=tn-1+Δ t t1 t11 t0 Figure 17: If each pixel is allowed to have different intensity levels and colors, then each letter can be represented with multiple variations. VI. DIRECTIONAL COINCIDENCE DETECTOR Typically we don’t think twice about where a sound came from, we intuitively “know” where the source is and seems almost inconsequential. A major area of interest in speech recognition is our ability to identify the directionality of sound. Two elements are known that participate in this ability, one is the detection of the time arrival difference between the ears, and the other is the detection of subtle variations in amplitude. A. Interaural Time Difference Sound travels through air at about 340 m/s, and the separation between the ears is about 20 cm, therefore the arrival time delta between ears can be from 0 µs, in the case of an exactly centered source, to about 580 µs in the case of a full left or full right source. Time arrival differences between the ears is caused by transmission delays due to distance. These temporal delays are interpreted as phase shift differentials by coincidence detector neurons [3]. Our directionality detection mechanism is capable to work within the above constrains, it is a rather simple mechanism but very efficient and effective. The process involves coincidental arrival of excitatory action potentials onto a series of neurons arranged in sequential order, followed by inhibitory signals fed to the immediate neighboring neurons to squelch noisy or ambiguous responses. This concept is illustrated in Figure 18 which can be used as point reference for the following example: let’s say two neurons are used as the source of coincident signals, both neurons are capable of identifying the same complex sound and are assumed to decode it in the same amount of time. The action potentials from both neurons are fed into a series of neurons in opposite directions. The length of signal travelled is increasingly longer from one neuron to the next, thus creating time delay effects up to a sum total maximum equivalent to the time separation between the ears (~580 µs). In the top illustration of Figure 18, the left “red” neuron decodes the sound first and fires an action potential. Instants later, the right “Blue” neuron finally senses the same sound at the right ear and also fires an action potential. The Left and Right signals eventually arrive simultaneously at one of the neurons in the coincidence detector and trigger a response of that neuron to indicate detection of coincidence arrival. That response also triggers inhibitory signals to the neighboring neurons to prevent ambiguous detections, this phenomena is called lateral inhibition [2]. t1 t11 t0 t2 t2 t1 t3 t2 t10 t5 t4 t8 t9 t10 t11 t3 t9 t10 t5 t4 t8 t3 t9 t6 t5 t7 t6 t6 t10 t9 t8 t4 t1 t2 t3 t4 t7 t5 t9 t8 t7 t10 t2 t3 t4 t5 t9 t8 t7 t5 t6 t7 t4 t8 t6 t6 t7 t3 t1 t10 t2 t1 Right Sound Figure 18: Activation of a neuron closer to the right indicates that the sound comes from the left. Activation of a neuron in the middle indicates that the sound comes from a centered location. Activation of a neuron closer to the left indicates that the sound comes from the right. B. Interaural Level Difference Sound amplitude differences due to distance differences from the source to each ear can also be perceived by the brain as an indicator of directionality [3]. Perception of level differences is less influential in directionality detection than perception of time difference [2], nonetheless it is an influential factor worth considering. VII. CONCLUSION Hearing, in the purist sense, is a perception no different from touch or smell. However, our ability to produce speech is directly linked to our ability to understand it. It is a very complex process involving multiple layers of open and closed loop mechanisms, all operating simultaneously in a coherent way. Humans learn to discriminate speech from other sounds over time, as a result of neurons creating interconnections to detect groups of frequencies in ways that convey appreciable meaning. The scale of the natural speech recognition system is massive, but its building blocks are elemental and minimalistic; what makes them so powerful is their substantial parallel interconnectivity. Modern artificial speech recognition systems have a long way to go to reach the efficiency levels of natural systems. However, their massive parallelism can be implemented using modern chip manufacturing technologies and should be feasible to produce. New communication technologies can also be modeled after the natural speech recognition process, and intelligent systems can adapt and discriminate desired signals from background noise of simultaneous streams in the same channel, just like humans can identify the sound of one person in the background of a cocktail party. Page 6 of 7 F. Rocha VIII. REFERENCES [1] L. Sherwood, Fundamentals of Human Physiology, 4 ed., Beltmont, Ca: Brooks/Cole, 2012, pp. 161-168. [2] D. U. Silverthorn, Human Phisiology, an Integrated Approach, Glenview, IL: Pearson, 2013. [3] J. Schnupp, I. Nelken and A. King, Auditory Neuroscience: Making Sense of Sound, Cambridge: MIT, 2011. [4] J. Schnupp, I. Nelken and A. King, "Auditory Neuroscience," . MIT Lincoln Laboratory, 6 2014. [Online]. Available: http://auditoryneuroscience.com/. [5] T. F. Quatieri, Discrete-Time Speech Signal Processing, Principles and Practice, Upper Saddle River, NJ: Prentice Hall, 2002, pp. 401-412. Francisco J. Rocha (M’05) was born in Salamanca, Spain in 1968. He received the B.S. degree in electrical engineering from Florida Atlantic University, Boca Raton, Florida in 1998. From 1995 to 2006, he was a design engineer at Motorola and was involved in the development of telecommunication portable devices, control-center stations, and base transceiver stations. Since 2006 he has been working at JetBlue in the development of avionic test systems. Mr. Rocha is currently pursuing the M.S. degree in biomedical engineering at the Florida Institute of Technology. Page 7 of 7