Essentials Of Review - American Statistical Association
advertisement

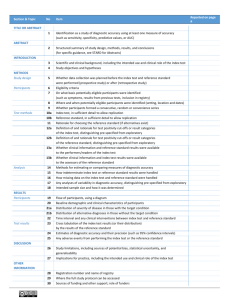
Revising FDA’s “Statistical Guidance on Reporting Results from Studies Evaluating Diagnostic Tests” FDA/Industry Statistics Workshop September 28-29, 2006 Kristen Meier, Ph.D. Mathematical Statistician, Division of Biostatistics Office of Surveillance and Biometrics Center for Devices and Radiological Health, FDA 1 Outline • • • • • • • Background of guidance development Overview of comments STARD Initiative and definitions Choice of comparative benchmark and implications Agreement measures – pitfalls Bias Estimating performance without a “perfect” [reference] standard - latest research • Reporting recommendations 2 Background • Motivated by CDC concerns with IVDs for sexually transmitted diseases • Joint meeting of four FDA device panels (2/11/98): Hematology/Pathology, Clinical Chemistry/Toxicology, Microbiology and Immunology • Provide recommendations on “appropriate data collection, analysis, and resolution of discrepant results, using sound scientific and statistical analysis to support indications for use of in vitro diagnostic devices when the new device is compared to another device, a recognized reference method or ‘gold standard,’ or other procedures not commonly used, and/or clinical criteria for diagnosis” 3 Statistical Guidance Developed “Statistical Guidance on Reporting Results from Studies Evaluating Diagnostic Tests: Draft Guidance for Industry and FDA Reviewers” • • • • issued in Mar. 12, 2003 with a 90-day comment period http://www.fda.gov/cdrh/osb/guidance/1428.html for all diagnostic products not just in vitro diagnostics only addresses diagnostic devices with 2 possible outcomes (positive/negative) • does not address design and monitoring of clinical studies for diagnostic devices 4 Dichotomous Diagnostic Test Performance New Test Study Population TRUTH Truth+ Truth Test+ TP (true+) FP (false+) Test FN (false ) TN (true) estimate: sensitivity (sens) = Pr(Test+|Truth+) 100%×TP/(TP+FN) specificity (spec) = Pr(Test|Truth) 100%×TN/(FP+TN) “Perfect” test: sens=spec=100% (FP=FN=0) 5 Example Data: 220 Subjects TRUTH New + Test total + 44 1 7 168 51 169 Unbiased Estimates Sens 86.3% (44/51) Spec 99.4% (168/169) Imperfect Standard + New + 40 5 Test 4 171 total 44 176 Biased* Estimates 90.9% (40/44) 97.2% (171/176) * Misclassification bias (see Begg 1987) 6 Recalculation of Performance Using “Discrepant Resolution” STAGE 1 – retest discordants using a “resolver” test Imperfect Standard + STAGE 2 – revise 2x2* based on resolver result Resolver/imperfect std. “+” “” New + 40 5 (5+, 0) Test 4 (1+, 3) 171 New + Test 45 1 0 174 total total 46 174 44 176 “sens” 90.9% (40/44) “spec” 97.2% (171/176) 97.8% (45/46) 100% (174/174) *assumes concordant=“correct” 7 Topics for Guidance Realization: • Problems are much larger than “discrepant resolution” • 2x2 is an oversimplification, but still useful to start Provide guidance: • What constitutes “truth”? • What to do if we don’t know truth? • What name do we give performance measures when we don’t have truth? • Describing study design: how were subjects, specimens, measurements, labs collected/chosen? 8 Comments on Guidance FDA received comments from 11 individuals/organizations: • provide guidance on what constitutes “perfect standard” – remove “perfect/imperfect standard” concept and include and define “reference/non-reference standard” concept (STARD) • reference and use STARD concepts • provide approach for indeterminate, inconclusive, equivocal, etc… results – minimal recommendations • discuss methods for estimating sens and spec when a perfect [reference] standard is not used – cite new literature • include more discussion on bias, including verification bias – some discussion added, add more references • add glossary 9 STARD Initiative STAndards for Reporting of Diagnostic Accuracy Initiative • effort by international working group to improve quality of reporting of studies of diagnostic accuracy • checklist of 25 items to include when reporting results • provide definitions for terminology • http://www.consortstatement.org/stardstatement.htm 10 STARD Definitions Adopted Purpose of a qualitative diagnostic test is to determine whether a target condition is present or absent in a subject from the intended use population • Target condition (condition of interest) – can refer to a particular disease , a disease stage, health status, or any other identifiable condition within a patient, such as staging a disease already known to be present, or a health condition that should prompt clinical action, such as the initiation, modification or termination of treatment • Intended use population (target population) – those subjects/patients for whom the test is intended to be used 11 Reference Standard (STARD) Move away from notion of a fixed, theoretical “Truth” • “considered to be the best available method for establishing the presence or absence of the target condition…it can be a single test or method, or a combination of methods and techniques, including clinical follow-up” • dichotomous - divides the intended use population into condition present or absent • does not consider outcome of new test under evaluation 12 Reference Standard (FDA) What constitutes “best available method”/reference method? • opinion and practice within the medical, laboratory and regulatory community • several possible methods could be considered • maybe no consensus reference standard exists • maybe reference standard exists but for non-negligible % or intended use population, the reference standard is known to be in error FDA ADVICE: • consult with FDA on choice of reference standard before beginning your study • performance measures must be interpreted in context: report reference standard along with performance measures 13 Benchmarks for Assessing Diagnostic Performance NEW: FDA recognizes 2 major categories of benchmarks • reference standard (STARD) • non-reference standard (a method or predicate other than a reference standard; 510(k) regulations) OLD: “perfect standard” and “imperfect standard”, “gold standard” – concepts and terms deleted Choice of comparative method determines which performance measures can be reported 14 Comparison with Benchmark • If a reference standard is available: use it • If a reference standard is available, but impractical: use it to the extent possible • If a reference standard is not available or unacceptable for your situation: consider constructing one • If a reference standard is not available and cannot be constructed, use a non-reference standard and report agreement 15 Naming Performance Measures: Depends on Benchmarks Terminology is important – help ensure correct interpretation Reference standard (STARD) • a lot of literature on studies of diagnostic accuracy (Pepe 2003, Zhou et al. 2002) • report sensitivity, specificity (and corresponding CIs), predictive values of positive and negative results Non-reference standard (due to 510(k) regulations) • report positive percent agreement and negative percent agreement • NEW: include corresponding CIs (consider score CIs) • interpret with care – many pitfalls! 16 Agreement New Test Study Population Non-Reference Standard + Test+ a b Test c d Positive percent agreement (new/non ref. std.) =100%×a/(a+c) Negative percent agreement (new/non ref. std.)=100%×d/(b+d) [overall percent agreement=100%×(a+d)/(a+b+c+d)] “Perfect” new test: PPA≠100% and NPA≠100% 17 Pitfalls of Agreement • agreement as defined here is not symmetric: calculation is different depending on which marginal total you use for the denominator • overall percent agreement is symmetric, but can be misleading (very different 2x2 data can give the same overall agreement • agreement ≠ “correct” • overall agreement, PPA and NPA can change (possibly a lot) depending the prevalence (relative frequency of target condition in intended use population) 18 Overall Agreement Misleading New + Test total Non-Ref Standard + 40 1 19 512 59 513 Non-Ref Standard + New + 40 19 Test 1 512 total 41 531 overall agreement = 96.5% ((40+512)/572)) PPA = 67.8% (40/59) NPA = 99.8% (512/513) PPA = 97.6% (40/41) NPA = 96.4% (512/531) 19 Agreement ≠ Correct Original data: Non-Reference Standard + New + 40 5 Test 4 171 Stratify data above by Reference Standard outcome Reference Std + Reference Std Non-Ref Std Non-Ref Std + + New + 39 5 New + 1 0 Test 1 6 Test 3 165 tests agree and are wrong for 6+1 = 7 subjects 20 Bias Unknown and non-quantified uncertainty • Often existence, size (magnitude), and direction of bias cannot be determined • Increasing overall number of subjects reduces statistical uncertainty (confidence interval widths) but may do nothing to reduce bias 21 Some Types of Bias • • • • error in reference standard use test under evaluation to establish diagnosis spectrum bias – do not choose the “right” subjects” verification bias – only a non-representative subset of subjects evaluated by reference standard, no statistical adjustments made to estimates • many other types of bias See Begg (1987), Pepe (2003), Zhou et al. (2002) 22 Estimating Sens and Spec Without a Reference Standard • Model-based approaches: latent class models and Bayesian models. See Pepe (2003), and Zhou et al. (2002) • Albert and Dodd (2004) – incorrect model leads to biased sens and spec estimates – different models can fit data equally well, yet produce very different estimates of sens and spec • FDA concerns & recommendations: – difficult to verify that model and assumptions are correct – try a range of models and assumptions and report range of results 23 Reference Standard Outcomes on a Subset • Albert and Dodd (2006, under review) – use info from verified and non-verified subjects – choosing between competing models is easier – explore subset choice (random, test dependent) • Albert (2006, under review) – estimation via imputation – study design implications (Albert, 2006) • Kondratovich (2003; 2002-Mar-8 FDA Microbiology Devices Panel Meeting) – estimation via imputation 24 Practices to Avoid • using terms “sensitivity” and “specificity” if reference standard is not used • discarding equivocal results in data presentations and calculations • using data altered or updated by discrepant resolution • using the new test as part of the comparative benchmark 25 External validity A study has high external validity if the study results are sufficiently reflective of the “real world” performance of the device in the intended use population 26 External validity FDA recommends • include appropriate subjects and/or specimens • use final version of the device according to the final instructions for use • use several of these devices in your study • include multiple users with relevant training and range of expertise • cover a range of expected use and operating conditions 27 Reporting Recommendations • CRITICAL - need sufficient detail to be able to assess potential bias and external validity • just as (more?) important as computing CI’s correctly • see guidance for specific recommendations 28 References Albert, P. S. (2006). Imputation approaches for estimating diagnostic accuracy for multiple tests from partially verified designs. Technical Report 042, Biometric Research Branch, Division of Cancer Treatment and Diagnosis, National Cancer Institute (http://linus.nci.nih.gov/~brb/TechReport.htm). Albert, P.S., & Dodd, L.E. (2004). A cautionary note on the robustness of latent class models for estimating diagnostic error without a gold standard. Biometrics, 60, 427–435. Albert, P. S. and Dodd, L. E. (2006). On estimating diagnostic accuracy with multiple raters and partial gold standard evaluation. Technical Report 041, Biometric Research Branch, Division of Cancer Treatment and Diagnosis, National Cancer Institute (http://linus.nci.nih.gov/~brb/TechReport.htm). Begg, C.G. Biases in the assessment of diagnostic tests. Statistics in Medicine 1987;6:411-423. Bossuyt, P.M., Reitsma, J.B., Bruns, D.E., Gatsonis, C.A., Glasziou, P.P., Irwig, L.M., Lijmer, J.G., Moher, D., Rennie, D., & deVet, H.C.W. (2003). Towards complete and accurate reporting of studies of diagnostic accuracy: The STARD initiative. Clinical Chemistry, 49(1), 1–6. (Also appears in Annals of Internal Medicine (2003) 138(1), W1–12 and in29 British Medical Journal (2003) 329(7379), 41–44) References (continued) Bossuyt, P.M., Reitsma, J.B., Bruns, D.E., Gatsonis, C.A., Glasziou, P.P., Irwig, L.M., Moher, D., Rennie, D., deVet, H.C.W., & Lijmer, J.G. (2003). The STARD statement for reporting studies of diagnostic accuracy: Explanation and elaboration. Clinical Chemistry, 49(1), 7–18. (Also appears in Annals of Internal Medicine (2003) 138(1), W1–12 and in British Medical Journal (2003) 329(7379), 41–44) Lang, Thomas A. and Secic, Michelle. How to Report Statistics in Medicine. Philadelphia: American College of Physicians, 1997. Kondratovich, Marina (2003). Verification bias in the evaluation of diagnostic devices. Proceedings of the 2003 Joint Statistical Meetings, Biopharmaceutical Section, San Francisco, CA. Pepe, M. S. (2003). The statistical evaluation of medical tests for classification and prediction. New York: Oxford University Press. Zhou, X. H., Obuchowski, N. A., & McClish, D. K. (2002). Statistical methods in diagnostic medicine. New York: John Wiley & Sons. 30 31