VHDL Coding The Golden Rules
advertisement

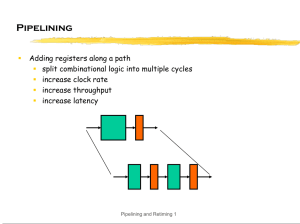
VHDL Coding Exercise 4: FIR Filter Where to start? Feedback Algorithm Designspace Exploration Architecture Optimization RTLBlock diagram VHDL-Code Algorithm • High-Level System Diagram Context of the design Inputs and Outputs Throughput/rates Algorithmic requirements • Algorithm Description Mathematical Description Performance Criteria Accuracy Optimization constraints Implementation constraints Area Speed y k bi xk i N xk i 0 FIR yk Architecture (1) • Isomorphic Architecture: Straight forward implementation of the algorithm xk b0 b1 b2 bN 2 bN 1 bN yk Architecture (2) • Pipelining/Retiming: Improve timing xk b0 b1 b2 bN 2 bN 1 bN yk Insert register(s) at the inputs or outputs Increases Latency Architecture (2) • Pipelining/Retiming: Improve timing xk b0 b1 b2 bN 2 bN 1 bN yk Insert register(s) at the inputs or outputs Increases Latency Perform Retiming: Move registers through the logic without changing functionality Backwards: Forward: Architecture (2) • Pipelining/Retiming: Improve timing xk b0 b1 b2 bN 2 bN 1 bN yk Insert register(s) at the inputs or outputs Increases Latency Perform Retiming: Move registers through the logic without changing functionality Backwards: Forward: Architecture (2) • Pipelining/Retiming: Improve timing xk b0 b1 b2 bN 2 bN 1 bN yk Insert register(s) at the inputs or outputs Increases Latency Perform Retiming: Move registers through the logic without changing functionality Backwards: Forward: Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain bN 2 bN 1 bN Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain bN 2 bN 1 bN Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain Perform Retiming bN 2 bN 1 bN Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain Perform Retiming bN 2 bN 1 bN Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain Perform Retiming bN 2 bN 1 bN Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain Perform Retiming bN 2 bN 1 bN Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain Perform Retiming bN 2 bN 1 bN Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain Perform Retiming bN 2 bN 1 bN Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain Perform Retiming bN 2 bN 1 bN Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain Perform Retiming bN 2 bN 1 bN Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain Perform Retiming bN 2 bN 1 bN Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain Perform Retiming bN 2 bN 1 bN Architecture (3) • Retiming and simple transformation: Optimization xk b0 b1 b2 yk Reverse the adder chain Perform Retiming bN 2 bN 1 bN Architecture (4) • More pipelining: Add one pipelining stage to the retimed circuit xk b0 b1 b2 bN 2 bN 1 bN yk The longest path is given by the multiplier Unbalanced: The delay from input to the first pipeline stage is much longer than the delay from the first to the second stage Architecture (5) • More pipelining: Add one pipelining stage to the retimed circuit xk b0 b1 b2 bN 2 bN 1 yk Move the pipeline registers into the multiplier: Paths between pipeline stages are balanced Improved timing Tclock = (Tadd + Tmult)/2 + Treg bN Architecture (6) • Iterative Decomposition: Reuse Hardware xk b0 b1 bN 2 b2 bN 1 bN yk Identify regularity and reusable hardware components Add control xk multiplexers storage elements Control Increases Cycles/Sample b0 bN 0 yk RTL-Design • Choose an architecture under the following constraints: It meets ALL timing specifications/constraints: Throughput Latency Iterative Decomposition It consumes the smallest possible area It requires the least possible amount of power • Decide which additional functions are needed and how they can be implemented efficiently: Storage of samples x(k) => MEMORY xk Storage of coefficients bi => LUT Address generators for MEMORY and LUT b => COUNTERS b Control => FSM 0 N 0 yk RTL-Design • RTL Block-diagram:N Datapath y k bi xk i i 0 xk b0 0 bN • FSM: Interface protocols datapath control: yk RTL-Design • How it works: y k bi xk i N IDLE i 0 Wait for new sample RTL-Design • How it works: y k bi xk i N IDLE i 0 Wait for new sample Store to input register RTL-Design • How it works: y k bi xk i N IDLE i 0 Wait for new sample Store to input register NEW DATA: Store new sample to memory RTL-Design • How it works: y k bi xk i N i 0 IDLE Wait for new sample Store to input register NEW DATA: Store new sample to memory RUN: y k bi xk i N i 0 RTL-Design • How it works: y k bi xk i N i 0 IDLE Wait for new sample Store to input register NEW DATA: Store new sample to memory RUN: N y k bi x k i i 0 Store result to output register RTL-Design • How it works: y k bi xk i N i 0 IDLE Wait for new sample Store to input register NEW DATA: Store new sample to memory RUN: N y k bi x k i i 0 Store result to output register DATA OUT: Output result RTL-Design • How it works: y k bi xk i N i 0 IDLE Wait for new sample Store to input register NEW DATA: Store new sample to memory RUN: N y k bi x k i i 0 Store result to output register DATA OUT: Output result / Wait for ACK RTL-Design • How it works: y k bi xk i N i 0 IDLE Wait for new sample Store to input register NEW DATA: Store new sample to memory RUN: N y k bi x k i i 0 Store result to output register DATA OUT: Output result / Wait for ACK IDLE: … Translation into VHDL • Some basic VHDL building blocks: Signal Assignments: Outside a process: AxD YxD AxD YxD • This is NOT allowed !!! BxD Within a process (sequential execution): AxD BxD YxD • Sequential execution • The last assignment is kept when the process terminates Translation into VHDL • Some basic VHDL building blocks: Multiplexer: AxD BxD YxD Default Assignment CxD SELxS Conditional Statements: AxD BxD SelAxS OUTxD CxD DxD SelBxS STATExDP Translation into VHDL • Common mistakes with conditional statements: Example: AxD ?? • NO default assignment SelAxS OUTxD BxD • NO else statement ?? SelBxS STATExDP • ASSIGNING NOTHING TO A SIGNAL IS NOT A WAY TO KEEP ITS VALUE !!!!! => Use FlipFlops !!! Translation into VHDL • Some basic VHDL building blocks: Register: DataREGxDN DataREGxDP Register with ENABLE: DataREGxDN DataREGxDN DataREGxDP DataREGxDP Translation into VHDL • Common mistakes with sequential processes: DataREGxDN DataREGxDP CLKxCI • Can not be translated into hardware and is NOT allowed DataRegENxS DataREGxDN DataREGxDP 0 1 DataREGxDN CLKxCI DataRegENxS • Clocks are NEVER generated within any logic DataREGxDP • Gated clocks are more complicated then this • Avoid them !!! Translation into VHDL • Some basic rules: Sequential processes (FlipFlops) Only CLOCK and RESET in the sensitivity list Logic signals are NEVER used as clock signals Combinatorial processes Multiple assignments to the same signal are ONLY possible within the same process => ONLY the last assignment is valid Something must be assigned to each signal in any case OR There MUST be an ELSE for every IF statement • More rules that help to avoid problems and surprises: Use separate signals for the PRESENT state and the NEXT state of every FlipFlop in your design. Use variables ONLY to store intermediate results or even avoid them whenever possible in an RTL design. Translation into VHDL • Write the ENTITY definition of your design to specify: Inputs, Outputs and Generics Translation into VHDL • Describe the functional units in your block diagram one after another in the architecture section: Translation into VHDL • Describe the functional units in your block diagram one after another in the architecture section: Translation into VHDL • Describe the functional units in your block diagram one after another in the architecture section: Register with ENABLE Register with ENABLE Translation into VHDL • Describe the functional units in your block diagram one after another in the architecture section: Register with CLEAR Translation into VHDL • Describe the functional units in your block diagram one after another in the architecture section: Counter Counter Translation into VHDL • Describe the functional units in your block diagram one after another in the architecture section: Translation into VHDL • The FSM is described with one sequential process and one combinatorial process Translation into VHDL • The FSM is described with one sequential process and one combinatorial process Translation into VHDL • The FSM is described with one sequential process and one combinatorial process Translation into VHDL • The FSM is described with one sequential process and one combinatorial process MEALY Translation into VHDL • The FSM is described with one sequential process and one combinatorial process Translation into VHDL • The FSM is described with one sequential process and one combinatorial process MEALY Translation into VHDL • The FSM is described with one sequential process and one combinatorial process MEALY Translation into VHDL • Complete and check the code: Declare the signals and components Check and complete the sensitivity lists of ALL combinatorial processes with ALL signals that are: used as condition in any IF or CASE statement being assigned to any other signal used in any operation with any other signal Check the sensitivity lists of ALL sequential processes that they contain ONLY one global clock and one global async. reset signal no other signals Other Good Ideas • Keep things simple • Partition the design (Divide et Impera): Example: Start processing the next sample, while the previous result is waiting in the output register: Just add a FIFO to at the output of you filter • Do NOT try to optimize each Gate or FlipFlop • Do not try to save cycles if not necessary • VHDL code Is usually long and that is good !! Is just a representation of your block diagram Does not mind hierarchy