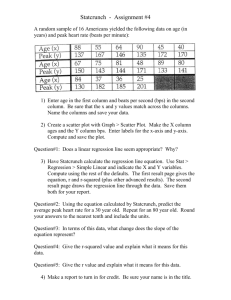
Overview – Courses - STT
advertisement

Bivariate data Bivariate data – Graphical & statistical techniques Graphical techniques • Scatter-plot • Difference-plot • Residual-plot • Krouwer-plot • Influences on the plots (data-range; subgroups; outliers; scaling) • Influences of random- and systematic errors on the plots • Linearity • Specifications in plots Combined graphical/statistical techniques • The Bland & Altman approach Correlation • The statistical model • Correlation in method comparison • Non-parametric correlation Regression • Ordinary linear regression (OLR) • Deming regression • Passing-Bablok regression (non-parametric) • Weighted regression • Regression & method comparison • Regression & calibration Datasets; GraphBivariate-EXCEL; Correlation&Regression; CorrRegr-EXCEL; Bland&Altman Statistics & graphics for the laboratory 87 Graphical techniques The scatter-plot Construction of the axes • x-axis: comparative method (A) • y-axis: test method (B) • line of equality ( y = x ): - - Usually, both axes extend from 0 to the highest result Glucose (mmol/l) 25 20 15 10 5 0 0 5 10 15 Glucose (mmol/l) 20 25 The absolute difference plot Construction of the x-axis • Hierarchically higher (A) and lower method (B) – x-axis: hierarchically higher method (A) • Hierarchically equivalent methods – x-axis: (A + B)/2 Construction of the y-axis –y = B - A Absolute bias (mmol/l) 6 – y-axis is freely scalable – x-axis bisects the y-axis at 0 4 2 0 -2 0 5 10 15 20 25 -4 -6 Glucose (mmol/l) Statistics & graphics for the laboratory 88 Graphical techniques The percent (%) difference plot Construction of the x-axis • Hierarchically higher (A) and lower method (B) – x-axis: hierarchically higher method (A) • Hierarchically equivalent methods – x-axis: (A + B)/2 Construction of the y-axis – y = [(B - A)/A]x100, or [(B - A)/0.5x(A + B)]x100 30 – y-axis is freely scalable – x-axis bisects the y-axis at 0 Percent bias (%) 20 10 0 -10 0 5 10 15 20 25 -20 -30 Glucose (mmol/l) The residuals plot Construction of the axes • x-axis: comparison method (A) • y-axis: regression (OLR) residuals: yi - ŷ – y-axis is freely scalable – x-axis bisects the y-axis at 0 Residuals (mmol/l) 6 4 2 0 -2 0 5 10 15 20 25 -4 -6 Glucose (mmol/l) Statistics & graphics for the laboratory 89 Graphical techniques The Krouwer plot (for the % bias) Construction of the axes • x-axis: %-bias • y-axis: “folded” cumulative percentage "Folded" cumulative % 50% 40% 30% 20% 10% 0% -15 -10 -5 0 5 Percent bias (%) 10 15 Construction of the Krouwer plot "Folded cumulative percentage" Cumulative frequency 1 Fold this area over an angle of 180° 0,8 0,6 0,4 0,2 Folded cum. frequency 0 -5 -4 -3 -2 -1 0 1 Multiple of s 2 3 4 5 -5 -4 -3 -2 -1 0 1 2 Multiple of s 3 4 5 0,5 0,4 0,3 0,2 0,1 0 Statistics & graphics for the laboratory 90 Graphical techniques Characteristics of the plots Scatter plot (with the line y = x) • Simple construction: the same for methods with the same/different hierarchy • Good overview about the data through the comparison with the y = x line “Difference” plots (absolute, %, residuals) • y-axis is freely scalable • Construction depends on method hierarchy • The residuals plot can only be constructed with knowledge of regression data Not a pure graphical technique, but: useful for the judgement of linearity (shown later) Krouwer plot • Gives an overview about the general distribution of errors • Information is lost about the concentration-dependency of errors Graphical presentation of a method comparison First conclusion • There are several different types of graphics for the interpretation of method comparison studies • The residuals- and the Krouwer plot are useful for the interpretation of special aspects of a method comparison (linearity, respectively, error distribution) • The scatter plot (y = x included) and the absolute and %-difference plot give the best overview about method comparison data More detailed investigation with those 3 Influences on the plots • Range of the results • “Subgroups” • Outliers • Scaling of the axes Statistics & graphics for the laboratory 91 Graphical techniques Influence of the range Influence of the range on the different plots 140 130 120 120 130 140 150 y=x 25 50 75 100 125 150 9 10 5 0 -5120 4 Absolute bias Glucose (mmol/l) 6 y=x 5 0 5 10 15 6 3 0 -3120 20 25 130 140 150 -6 -9 Sodium (mmol/l) 20 0 150 -15 25 10 140 -10 Sodium (mmol/l) 15 130 Percent bias (%) 15 150 0 Percent bias plot Sodium (mmol/l) 30 2 0 -2 0 5 10 15 20 25 -4 Percent bias (%) 150 125 100 75 50 25 0 Absolute bias plot Absolute bias Sodium (mmol/l) Scatter plot -6 20 10 0 -10 0 5 10 15 20 25 -20 -30 Glucose (mmol/l) Glucose (mmol/l) Glucose (mmol/l) - Graphical resolution resolution ofof thethe scatter plot: plot: worseworse than the bias the plots. -Graphical scatter than bias plots. - The resolution of the scatter plot can be improved by an insert. -The resolution of the scatter plot can be improved by an insert. Influence of the range on the different plots Scatter plot 0 4000 400 y=x 800 2000 1000 0 0 5000 10000 -1000 0 0 5000 10000 -2000 log Absolute bias log Estradiol (pmol/l) 3 2 log y = log x 0 1 2 3 4 0 5 5000 10000 -25 Estradiol (pmol/l) 0,30 4 log Estradiol (pmol/l) 0 Estradiol (pmol/l) 5 0 25 -50 Estradiol (pmol/l) 1 Percent bias (%) 0 50 0,15 0,00 0 1 2 3 4 5 -0,15 log Percent bias (%) 400 6000 Percent bias plot 2000 800 8000 Absolute bias Estradiol (pmol/l) 10000 Absolute bias plot -0,30 15 10 5 0 -5 0 1 2 3 4 5 -10 -15 log Estradiol (pmol/l) log Estradiol (pmol/l) - Graphical resolution of the scatter plot: worse than the bias plots. - Scatter plot: improve resolution by insert or logarithmic scale -Graphical resolution of the scatter plot: worse than the bias plots. -Scatter plot: improve resolution by an insert or logarithmic scale. Don't expect that "one size fits all" Statistics & graphics for the laboratory DatasetsMethComp 92 Graphical techniques Subgroups Note: y-axis of the difference plot is freely scalable! Therefore, its graphical resolution, usually, is better than the one of the scatter plot A “subgroup” is easier to see in the %-difference plot than in the scatter plot 40 30 Percent bias (%) Glucose (mmol/l) 25 20 15 10 5 20 10 0 -10 0 5 10 15 20 25 -20 -30 0 0 5 10 15 Glucose (mmol/l) 20 -40 25 Glucose (mmol/l) Outliers Glucose “normal” PERCENT BIAS PLOT 20 15 10 5 0 2 0 0 15 20 25 -4 25 10 0 0 10 Absolute bias 15 15 10 5 0 25 10 15 20 25 -20 Glucose (mmol/l) 80 5 0 -5 0 5 -10 Glucose (mmol/l) 20 5 10 15 20 Glucose (mmol/l) 10 -2 25 0 5 5 10 15 20 -10 -15 25 Percent bias (%) 5 10 15 20 Glucose (mmol/l) 20 Percent bias (%) 4 0 Glucose (mmol/l) ABSOLUTE BIAS PLOT Absolute bias Glucose (mmol/l) SCATTER PLOT 25 40 0 0 5 10 15 20 25 -40 -80 Glucose (mmol/l) Glucose (mmol/l) Glucose “with outliers” Outliers have no influence on the resolution of the scatter plot, but reduce the resolution of the difference plots. Scatter plot more robust than difference plots Statistics & graphics for the laboratory 93 Graphical techniques Scaling 30 A 1 0 -1 0 5 10 15 20 25 -2 -3 20 15 B 10 0 -10 0 5 10 15 20 25 -20 -30 Glucose (mmol/l) Absolute bias 2 Absolute bias Absolute bias 3 10 C 5 0 -5 0 5 10 15 20 25 -10 -15 Glucose (mmol/l) Glucose (mmol/l) y-scaling … Effect… A: "as the data are" Good resolution, but x- & y-axis cannot be compared directly B: free Good/poor agreement can be manipulated graphically C: identical (graphical distance) x and y scaling Loss of resolution, but better direct comparison possible Graphs and errors Random errors • SD constant (small range; e.g., sodium) • CV constant (medium range; e.g., glucose) • SD/CV variable (wide range; e.g., estradiol) CV constant/SD decreasing down to a certain concentration, then SD/CV Common situation CV SD SD constant and CV increasing Concentration Statistics & graphics for the laboratory 94 Graphical techniques Graphs and errors Systematic errors -Constant -Proportional -Combination (constant/proportional) -Non-linearity Graphs and errors Examples Systematic errors •y=x • y = 1.1 • x •y=x+1 Random errors • General examples with CV = 2% and SD = 0.1 Case 1: y = x Scatter plot CV = 2% 1 30 20 10 0 0 0 0 SD = 0.1 Abs. Diff. plot 10 20 30 10 20 30 -1 1 30 20 10 0 0 0 0 10 20 30 -1 10 20 30 % Diff. plot 10 5 0 -5 0 -10 10 5 0 -5 0 -10 10 20 30 10 20 30 From: D. Stöckl. Ann Clin Biochem 1996;33:575-7 Statistics & graphics for the laboratory 95 Graphical techniques Graphs and errors What could be noted? For case 1: y = x Better resolution of the difference plots Scatter plot • At constant CV, typical V-form of the random error limits • At constant SD, parallel limits for random error Absolute difference plot • At constant CV, typical V-form of the random error limits • At constant SD, parallel limits for random error %-difference plot • At constant CV, parallel limits for random error • At constant SD, typical hyperbolic limits for random error Case 2: y = 1.1 • x Scatter plot CV = 2% 30 20 10 0 0 SD = 0.1 Abs. Diff. plot 10 20 30 3 2 1 0 -1 -2 0 -3 10 20 30 3 2 1 0 -1 -2 0 -3 30 20 10 0 0 10 10 20 30 20 30 % Diff. plot 20 10 0 -10 0 -20 30 15 0 -15 0 -30 10 20 30 10 20 30 Case 3: y = x + 1 Scatter plot CV = 2% 30 20 10 0 0 SD = 0.1 10 20 30 2 1 0 -1 0 -2 10 20 30 2 1 0 -1 0 -2 30 20 10 0 0 Abs. Diff. plot 10 10 20 30 20 30 % Diff. plot 120 60 0 -60 0 -120 120 60 0 -60 0 -120 10 20 30 10 20 30 Statistics & graphics for the laboratory 96 Graphical techniques Graphs and errors What could be noted? (additionally to y = x) A large proportional error • Deteriorates the resolution of the absolute difference plot • Has no influence on the %-difference plot A large constant error (as compared to the random error) • Has no influence on the absolute difference plot • The hyperbolic error limits in the %-difference plot become “one-sided” Summary The difference plots, generally, have a better resolution than the scatter plot The scatter plot is robust against all sorts of errors The limits for random error are • V-shaped (constant CV) • parallel (constant SD) The absolute difference plot is robust against constant errors, but sensitive to proportional errors (loss of resolution) The limits for random error are • V-shaped (constant CV) • parallel (constant SD) The %-difference plot is robust against proportional errors, but sensitive towards constant errors The limits for random error are • parallel (CV constant and no constant error), • 2-sided hyperbolic (SD constant and no const. error), or • 1-sided hyperbolic (existence of a relatively big constant error) Statistics & graphics for the laboratory 97 Graphical techniques Linearity Judgement of linearity Consider the following ways Regression analysis 20 15 10 5 0 25 4 y = 1,0697x 0,6433 20 15 10 5 0 0 Residuals plot Residual (mmol/l) 25 Glucose (mmol/l) Glucose (mmol/l) Scatter plot 5 10 15 20 25 Glucose (mmol/l) 0 5 10 15 20 25 Glucose (mmol/l) 2 0 0 5 10 15 20 25 -2 -4 Glucose (mmol/l) Best with regression (residuals plot) For a broad range Logarithmic 5000 10000 4000 Routine Routine 1000 100 10 3000 2000 1000 0 1 1 10 100 1000 ID-GC/MS 10000 0 1000 2000 3000 ID-GC/MS 4000 5000 Easier with a logarithmic plot Conclusion: "no size fits all" Statistics & graphics for the laboratory 98 Graphical techniques Specifications Specifications are needed for the interpretation of a method comparison. We look for specifications in • The scatter plot • The absolute difference plot • The %-difference plot The scatter plot Routine (mmol/l) 25 20 15 10 5 0 0 5 10 15 20 25 Reference (mmol/l) Sort of specification: Constant: 1 mmol/l Proportional: 10% The %-difference plot 20 3 2 1 0 -1 0 5 10 15 20 -2 25 Routine (% difference) Routine (abs. difference) The absolute difference plot 15 10 5 0 -5 0 5 10 15 20 25 -10 -15 -20 -3 Reference (mmol/l) Sort of specification: Constant: 1 mmol/l Proportional: 10% Reference (mmol/l) Sort of specification: Constant: 1 mmol/l Proportional: 10% Statistics & graphics for the laboratory 99 Graphical techniques Specifications Glucometer XYZ (mmol/l) "Error grid analysis" (glucose) 25 Sort of specification: complex Base assumptions A A C 20 E 15 B B 10 D 5 1. Values <3.9 mmol/l to increase 2. Values >10 mmol/l to lower 3. Deviations from the reference up to 20% are acceptable, or, both values (glucometer and reference) are <3.9 mmol/l D Interpretation of the areas: C 0 0 E 5 10 15 20 Reference (mmol/l) 25 A: clinically accurate B: clinically irrelevant deviation of >20% C: possible unnecessary overcorrection D: glucometer produces dangerous errors E: wrong treatment Adapted from: Clarke et al. Diabetes Care 1987;10:622-8 Summary The scatter plot is useful for all sorts of specifications The limits for specifications (around y = x) are • parallel (absolute specification) • or V-shaped (% specification) The absolute difference plot is most appropriate for absolute specifications The limits for specifications (around 0) are • parallel (absolute specification) • or V-shaped (% specification) The %-difference plot is most appropriate for % specifications The limits for specifications (around 0) are • parallel (% specification) • 2-sided hyperbolic (absolute specification) Annex • More examples • Examples sorted according to plot-type Statistics & graphics for the laboratory 100 Exercises GraphBivariate-EXCEL This file is a template for a Scatter plot (with line of equality) Absolute bias plot (x-axis with hierarchichally higher method, only) % bias plot (x-axis with hierarchichally higher method, only) Absolute bias plot (x-axis with average x&y) % bias plot (x-axis with average x&y) Residuals plot It may be adapted to the needs of the user. This file can also be used to reproduce most of the plots in this tutorial by using the datasets in: Datasets(Method comparison: Sodium, Glucose, Estradiol) Statistics & graphics for the laboratory 101 Graphical techniques Annex – More examples Case 4: y = x + 0.05 Scatter plot CV = 2% 30 20 10 0 1 0 0 0 SD = 0.1 Abs. Diff. plot 10 20 30 10 20 30 -1 1 30 20 10 0 0 0 0 10 20 30 10 20 30 -1 % Diff. plot 10 5 0 -5 0 -10 10 5 0 -5 0 -10 10 20 30 10 20 30 Case 5: y = 1.1 • x + 1 Scatter plot CV = 2% 30 20 10 0 0 SD = 0.1 10 20 30 6 3 0 -3 0 -6 10 20 30 6 3 0 -3 0 -6 30 20 10 0 0 Abs. Diff. plot 10 10 20 30 20 30 % Diff. plot 120 60 0 -60 0 -120 120 60 0 -60 0 -120 10 20 30 10 20 30 Statistics & graphics for the laboratory 102 Graphical techniques Scatter-plot y=x y = 1,1x y = x + 0,05 y=x+1 y = 1,1x + 1 CV = 2% 30 20 10 0 30 20 10 0 0 30 20 10 0 0 10 20 30 30 20 10 0 10 20 30 0 10 20 30 30 20 10 0 0 10 20 30 0 10 20 30 0 10 20 30 SD = 0.1 30 20 10 0 30 20 10 0 0 10 20 30 30 20 10 0 0 30 20 10 0 10 20 30 0 10 20 30 30 20 10 0 0 10 20 30 Absolute bias-plot y=x y = 1,1x y = x + 0,05 y=x+1 y = 1,1x + 1 CV = 2% 1 0 0 10 -1 3 2 1 0 -1 20 30 -2 0 -3 1 0 10 20 30 0 10 -1 2 1 0 20 30 -1 0 -2 10 6 3 0 20 30 -3 0 -6 10 20 30 10 20 30 SD = 0.1 1 0 0 -1 10 3 2 1 0 -1 20 30 -2 0 -3 1 0 10 20 30 0 10 20 -1 2 1 0 30 -1 0 -2 10 6 3 0 20 30 -3 0 -6 % bias-plot y=x y = 1,1x y = x + 0,05 y=x+1 y = 1,1x + 1 CV = 2% 10 5 0 -5 0 -10 20 10 0 -10 10 20 30 0 -20 10 5 0 -5 10 20 30 0 -10 120 60 0 -60 10 20 30 0 -120 120 60 0 -60 10 20 30 0 -120 10 5 0 10 20 30 -5 0 -10 120 60 0 10 20 30 -60 0 -120 120 60 0 10 20 30 -60 0 -120 10 20 30 SD = 0.1 10 5 0 -5 0 -10 30 15 0 10 20 30 -15 0 -30 Statistics & graphics for the laboratory 10 20 30 103 Notes Notes Statistics & graphics for the laboratory 104 Combined graphical/statistical techniques Combined graphical/statistical techniques The Bland&Altman approach for the interpretation of method comparison studies References • Altman DG, Bland JM. Measurement in medicine: the analysis of method comparison studies. Statistician 1983;32:307-17. • Bland JM, Altman DG. Statistical methods for assessing agreement between two methods of clinical measurement. Lancet 1986;307-10. • Bland JM, Altman DG. Measuring agreement in method comparison studies. Stat Methods Med Res 1999;8:135-60. Approach The goal of the Bland & Altman approach is to compare the outcome of method comparison studies in terms of systematic (SE) and total error (TE) with quality specifications for systematic (SEspec) and total error (TEspec). Calculations This requires the following calculations (note: the B&A symbols are used here) -Mean difference (đ) and its 95% confidence limits (CL) (equivalent to SE) -1.96 SDdiff and its CL (equivalent to TE) SDdiff = standard deviation of the differences between the methods Those are to be compared with the specifications in the following way: • đ ± CL SEspec and • 1.96 SDdiff ± CL TEspec, Graphics At the same time, Bland&Altman recommended to present the data in an absolute bias plot including the lines for đ and 1.96 SDdiff. Original plot Adapted from: Bland JM, Altman DG. Lancet 1986;i:307-10. Statistics & graphics for the laboratory 105 Combined graphical/statistical techniques Combined graphical/statistical techniques Limitations of the original plot • Does not recognize different method hierarchies Same hierarchy: x = (A+B)/2 Different hierarchy: x = A • In many cases a %-bias plot is more appropriate. In that connection, it is better to calculate the 1.96 CV values, because the SD is often increasing with the level, so that no mean SD exists. • Does not include confidence limits • Does not include TE/SE-specifications Statistics & graphics for the laboratory 106 Combined graphical/statistical techniques Combined graphical/statistical techniques 3 2 1 0 -1 %-bias plot 20 0 5 10 15 20 25 -2 -3 Routine (% difference) Routine (abs. difference) Remember: Quality specifications in the Absolute bias plot 15 10 5 0 -5 0 5 10 15 20 25 -10 -15 -20 Reference (mmol/l) Sort of specification: Constant: 1 mmol/l Proportional: 10% Reference (mmol/l) Sort of specification: Constant: 1 mmol/l Proportional: 10% Limitations of the original plot • Does not recognize different method hierarchies • In many cases a %-bias plot is more appropriate • Does not include confidence limits • Does not include TE/SE-specifications Because of these limitations, it is recommended to use an "extended" Bland&Altman plot (see next page) See also following references • Stöckl D. Beyond the myths of difference plots [letter]. Ann Clin Biochem 1996;33:575-7. • Dewitte K, Fierens C, Stöckl D, Thienpont LM. Application of the Bland-Altman plot for the interpretation of method-comparison studies: a critical investigation of its practice. Clin Chem 2002;48:799-801. • Stöckl D, Rodríguez Cabaleiro D, Van Uytfanghe K, Thienpont LM. Interpreting method comparison studies by use of the bland-altman plot: reflecting the importance of sample size by incorporating confidence limits and predefined error limits in the graphic. Clin Chem 2004;50:2216-8. Statistics & graphics for the laboratory 107 Combined graphical/statistical techniques Bland & Altman plot – Expanded Recommendations • Construct the x-axis according to the hierarchy of the methods • Choose a bias-plot (absolute, %) that fits your data • Use the "extended" version of the plot (+specifications and CL's) (the 1-sided limits are chosen because the comparison is versus a specification). • Be aware of the meaning of the calculated estimates "mean" bias or "mean" SD/CV 20 Routine - Reference (%) 15 Mean Diff. 10 5 ±1,96 CVdiff. 0 ±95% CL's -5 3 4 5 6 7 8 9 SE limit -10 TE limit -15 -20 Reference (mmol/l) Bland&Altman This file contains a template for the Bland&Altman plot with pre-programmed confidence limits and entries for the SE and TE specifications. It may be adapted to the needs of the user. Statistics & graphics for the laboratory 108 Notes Notes Statistics & graphics for the laboratory 109 Notes Notes Statistics & graphics for the laboratory 110 Correlation and Regression Correlation and Regression Correlation • The statistical model • Correlation in method comparison • Non-parametric correlation Regression • Ordinary linear rgression (OLR) • Deming regression • Passing-Bablok regression (non-parametric) • Weighted regression • Regression & method comparison • Regression & calibration Statistics & graphics for the laboratory 111 Correlation Correlation and regression Correlation • Correlation concerns association between variables, e. g. serum cholesterol and indicators of heart disease. • Correlation is a descriptive measure that does not allow conclusions concerning causal relationships. • Correlation is also used together with regression (method comparison studies) Comparison Correlation <> Regression Regression model: one variable (the dependent variable, y) is a function of another variable (the independent variable, x) • Example: Blood pressure may be considered a function of age Correlation model: both variables are random effects factors • Example: Human arm and leg lengths are correlated Univariate and multivariate correlation • Univariate (simple): between two variables • Multivariate: between several variables and an outcome measure, e.g. between serum cholesterol and triglyceride and an indicator of heart disease Univariate correlation and relationships of data • Linear relationship (often implicitly assumed) • A curvilinear relationship, e.g. a polynomial model • Cyclical relationship Linear correlation – Computations Pearson´s product – moment correlation coefficient r Computation from the cross product and sums of squared deviations from the mean values: r is dimensionless and can take values from -1 to +1 • The correlation coefficient can be computed regardless of variable distribution types. • Associated significance tests depend on the type of distributions and are valid for the bivariate normal distribution. Coefficient of determination (r2) Squaring r gives the Coefficient of determination which tells us the proportion of variance that the two variables have in common. For a height-weight example, r = 0.807 and squaring r gives 0.6512, which means that the height of a person explains 65% of the person’s weight; the other 35% could probably be explained by other factors, perhaps nature and nurture. Statistics & graphics for the laboratory 112 Correlation Hypothesis testing and r Testing against zero: Standard error of r : SEr = [(1-r2)/(N-2)]0.5 t-test for significance against zero: t = (r – 0)/SEr with (N-2) degrees of freedom Non-zero correlation r is transformed to z = 0.5 ln[(1+r)/(1-r)] (Fisher´s z-transformation, which yields a symmetric normal-like distribution) SE of z: [1/(N-3)]0.5 Hypothesis testing and confidence intervals are based on the z-transformation n 1 2 3 4 5 6 7 8 9 10 15 20 30 50 100 500 Probability 95% 99% 0.997 1.000 0.950 0.990 0.878 0.959 0.811 0.917 0.754 0.874 0.707 0.834 0.666 0.798 0.632 0.765 0.602 0.735 0.576 0.708 0.482 0.606 0.423 0.537 0.349 0.449 0.273 0.354 0.195 0.254 0.088 0.115 Note: n = n - 2 r-critical Critical values for r 1 0.8 0.6 0.4 0.2 0 -0.2 0 -0.4 -0.6 -0.8 -1 99% 95% 20 40 60 80 100 n-2 Correlation and P • A weak correlation may be highly statistically significant given a large N, e.g. as observed in large epidemiological studies. • The clinical importance of a given degree of correlation depends on the situation. Statistics & graphics for the laboratory 113 Correlation Correlation Meaning of the Pearson correlation coefficient, r • Measure for the strength of linear correlation r=0 r=0 r = +1 r = -1 • Becomes smaller (e.g., <1) when dispersion in y occurs r is a measure for random analytical error r = 0,9507 r = +1 Correlation in method comparison studies 30 A 20 10 r = 0,9969 0 0 10 20 Test method Test method • Systematic errors have no influence on r 30 B 20 10 30 0 C 20 10 r = 0,9969 0 0 10 20 30 Reference method 10 20 30 Reference method Test method Test method Reference method 30 r = 0,9969 0 A: No SE B: Constant SE C: Proportional SE D: Constant & proportional SE 30 D 20 10 r = 0,9969 0 0 10 20 30 Reference method Statistics & graphics for the laboratory 114 Correlation Correlation in method comparison studies 175 150 150 125 125 r = 0,786 100 100 150 Test 175 Test Test The Pearson correlation coefficient, r • Influence of the data range: – r: increases with the range – Inclusion of extreme values: artificial improvement of r 100 r = 0,963 100 125 150 Reference 175 100 r = 0,962 50 125 150 Reference 175 50 100 150 Reference Conclusion: correlation in method comparison studies The Pearson correlation coefficient, r is, as measure for method comparability, difficult to interpret • r depends on the range of x-values. The greater the range is, the higher are the values for r • r is not influenced by systematic errors • Often, much too small values of r (e.g., r = 0.8) are judged as a good correlation in method comparison Some advocate to use r as indicator for proper data distribution before applying linear regression and recommend for this purpose r-values >0.975 (small range) or >0.99 (wide range). However, when several methods are compared with the same data-set, r is a useful index for ranking the methods. Nonparametric correlation The parametric correlation coefficient is sensitive towards outliers. Nonparametric correlation coefficients (Spearman or Kendall) are more robust and are calculated on the basis of the ordered (ranked) observations. The computation principle is an assessment of how well the rank order of the second variable corresponds to the rank order of the first variable. Statistics & graphics for the laboratory 115 Notes Notes Statistics & graphics for the laboratory 116 Regression Regression Linear regression procedures – Linear regression procedures assume a linear relationship between 2 variables (e.g., 2 methods): yi = a0 + b • xi (a0 = intercept; b = slope) – Slope and intercept of the regression line are determined by minimizing the sum of the squared distances between the data points and the regression line (parametric procedures) Linear regression in method comparison gives information on: – Constant systematic error (intercept) – Proportional systematic error (slope) – Random error (SDy/x) Non-linear or curvilinear regression procedures – Minimize the sum of squares of the residuals on the basis of any clear mathematical relationship (polynomial, logarithmic, etc.) between two methods – In the easiest case, the curve can be approximated by several linear regression calculations performed over different ranges of x (e.g., the low, middle, and high range) – Curvilinear regression is most adequate for calibration purposes, either for the dose/response case, or for calibration of a routine method through method comparison with a reference method Statistics & graphics for the laboratory 117 Regression Regression Linear regression procedures: Overview Ordinary least-squares regression (OLR) • Weighted variant Deming regression • Weighted variant Passing Bablok regression (non-parametric) Ordinary least-squares regression (OLR) Assumptions (see also figure): • x: error-free, which implicates that SDax = 0 • y : measurement uncertainty is present, with assumption that SDay is constant throughout the measurement range and normally distributed. Statistics & graphics for the laboratory 118 Regression Ordinary least-squares regression (OLR) Computations xm = Σ xi/N ym = Σ yi/N u = Σ(xi - xm)2 q = Σ(yi - ym)2 p = Σ (xi - xm)(yi - ym) Statistical estimates of OLR • Slope (b), SE(b) & 0.95-confidence limits (CLs) for b • Intercept (a0), SE(a0) & 0.95-CLs for a0 • Standard error of the y-estimate (SDy/x) • Regression residuals • 95% prediction interval for single points b = p/u a 0 = ym - b x m OLR: REMARKS • OLR minimizes the sum of the squares of the y-residuals (= deviations of yi from the regression line in y-direction) • The regression line will pass through a centroid point that is the mean of x and the mean of y • Disadvantage of OLR is its sensitivity towards outliers (i.e. extreme values of x or big residuals in the y-direction) • OLR gives biased slope estimate in case of narrow range and measurement error in x Linear regression estimates: graphical presentation OLR: Limitation SDay constant SDay is normally not constant but increases with increasing values of x (when measurement values are distributed over a decade or more). This is reflected in the residual plot by a trend towards increasing scatter at high levels. >Because of the latter, weighted forms of linear regression have been introduced. Statistics & graphics for the laboratory 119 Regression Weighted OLR CV SD SD/CV Weighted linear regression In a weighted regression procedure, SDa is regarded proportional to a function of the level x (=c h(x)) and weights are: • wi = 1/h(xi)2 Weights are inversely proportional to SDay Concentration Concentration Centroid of a weighted regression line 25 20 Routine The centroid point of the weighted regression line does not pass through the mean of x and y but lies more at the side of the origin CV SD SD/CV Example: Proportional relationship between SDa and xi (Fig., upper part): wi = 1/(xi)2 Ppossibly truncated at a low limit (Fig., lower part) Weighted mean 15 10 5 Mean 0 0 10 15 Reference 20 25 1.2 Expected slope Slope Further limitations of OLR Biased slope estimate in case of narrow range (x) and analytical error (a) in x ß´= ß/(1+λ) λ = ơa2/ ơX2 This leads to incorrect testing of significance 5 0.8 Slope from OLR 0.4 0.0 0.4 0.8 1.2 SDa/SDx Limitation: error (a) in x In method comparison studies, the assumption of an error-free x is often not valid. For that reason, regression techniques have been developed that allow error in both variables (x & y): >e.g., Deming regression Statistics & graphics for the laboratory 120 Regression Deming regression Assumptions: • x & y: measurement errors may be present in both, with SDax = SDay or SDax and SDay related (SDax/SDay) • SDax and SDay: constant throughout the measurement range and normally distributed Deming regression estimates a straight line by minimization of the sum of squared distances at an angle to the regression line dependent on the relation between the x and y precision, resulting in an estimate without bias (contrarily to OLR that gives a biased slope estimate in case of SDax0) Graphical representation of the assumptions: measurement uncertainty in both x and y The model assumed in Deming regression analysis Computation of the Deming regression line Minimization of the weighted sum of squared distances to the line: S = [(x - X)2 + (y-Y)2 ]; = SDax2/ SDay2 which provides the solution: b =[(λq - u)+[(u- λq)2+4 λp2]0.5]/ 2λp a0 = ym - b xm Computation of standard errors SE(a0) and SE(b) requires a specialized procedure, e.g. the jackknife method. Jackknife principle Computerized resampling principle. Sampling variation is simulated by consecutively withdrawing one (x, y) of the set with recalculation of estimates From the dispersion of estimates, SEs are derived. Statistics & graphics for the laboratory 121 Regression Weighted Deming regression Model assumed in weighted Deming regression analysis Higher efficiency in case of proportional measurement uncertainty (constant CV), reflected by more homogenous scatter of standardized residuals and smaller SEs of slope and intercept estimates. Method comparison example (Datasets-MethComp) (n = 50; Statistics: CBstat, K. Linnet) Deming regression: Slope: b = 1.053 SE(b) = 0.023; 0.02< P < 0.05 Intercept: a0 = -0.22 SE(a0) = 0.19; n.s. from 0 No significant deviation from linearity No outliers Residuals show increased scatter at high levels: poor model fit. Weighted Deming regression: Slope: b = 1.032 SE(b) = 0.012; 0.01< P < 0.02 Intercept: a0 = -0.01 SE(a0) = 0.07; n.s. from 0 Homogeneous scatter of residuals: Better model fit. weighted Weighted versus unweighted Deming Smaller SEs of slope and intercept: SE(b) = 0.012 versus 0.023 unweighted SE(a0) = 0.07 versus 0.19 unweighted Statistics & graphics for the laboratory 122 Regression Deming regression Weighted versus unweighted Deming regression Given measurement values distributed over a decade or more, the analytical SD seldom is constant but varies often proportionally, so that the CV% is about constant. In this case, it is advantageous to apply a weighted analysis, which provides lower SEs of estimates. Weighted Deming regression analysis covers the probably most commonly occurring data situation in method comparison studies. Passing-Bablok regression Assumptions: • Passing-Bablok regression is a non-parametric method, making no assumptions about distribution of errors. May be used in case of constant or proportional error • It assumes that the ratio SDax/SDay is equal to the slope Passing-Bablok regression uses the slopes between any two data points xi/yi to calculate the slope of the regression line. The intercept is estimated so that at least half of the data points are located above or on the regression line and at least half the data points below or on the regression line. An advantage of Passing-Bablok regression is its robustness to outliers. A disadvantage are the broader confidence intervals (due to the nature of nonparametric procedures). Geometrical interpretation of regression techniques (minimizing residuals) 20 a Method Y Method Y 20 90° 10 d 0 90°+d 10 d 0 0 20 10 Method X 20 0 20 c Method Y Method Y b 10 d d 0 10 Method X d 20 2 S1,2 10 1 S2,3 S1,3 3 0 0 10 Method X 20 0 10 Method X 20 Statistics & graphics for the laboratory 123 Regression Linear regression with CBstat – Summary of output data • Slope (b), SE(b) & 0.95-confidence limits (CLs) for b • Intercept (a0), SE(a0) & 0.95-CLs for a0 • Standard error of the y-estimate (SDy/x) • Correlation coefficient (+ P-value) • Outlier identification (4s) • Scatter plot with regression line, 0.95-confidence region and x = y line • Residuals plot (normalized) • Additional: runs test for linearity Residuals for linearity testing Runs test: Sequences of residuals with the same sign are counted and related to critical limits (= testing of randomness of residuals) Relationship correlation & regression r is related to the regression slope(s): • r = [byx bxy ]0.5: r is the geometric mean of the two regression slopes • byx = r SDy/SDx: i.e. r is a rescaled version of the regression slope (identity given SDy = SDx) r is related to SDy/x: r2 ~ 1 – SD2y/x/SD2ay Linear regression – In method comparison Calculation of a bias (DC) 10 Bias may consist of: • Constant part (0) (e.g. fixed matrix effect) • Proportional part (ß-1) (e.g. calibration difference) DC = YC – XC = 0 + (b – 1) • XC YC b DC 5 0 0 0 5 Statistics & graphics for the laboratory XC 10 124 Regression Linear regression – In method comparison Confidence interval of a bias or systematic difference (SE) Prediction interval Statistical significance of estimates: • Does the slope deviate from 1? t = (b-1)/SE(b) Indication for proportional error • Does the intercept deviate from 0? t = (a0 - 0)/SE(a0) Indication for constant error • SDy/x (from OLR) Measure for random error • Are the data pairs linearly related? Additional in CBstat Runs test or visual inspection of residuals plot Indication for (non)linear relationship – Further application CI for SE at a critical concentration 25 25 20 20 y (mmol/l) y (mmol/l) Statistical test for slope equal to 1 (95% confidence limits to consider) 15 10 5 0 15 10 5 0 0 5 10 15 20 25 x (mmol/l) Simulation: CV 5% Regression y = 0.9443x – 0.1521 95% CLs for slope 0.9106 – 0.9780 Significantly different from 1 0 5 10 15 20 25 x (mmol/l) Simulation: CV = 15% Regression y = 0.9414x – 0.1233 95% CLs for slope 0.8656 – 1.0172 NOT significantly different from 1: high RE! Statistics & graphics for the laboratory 125 Regression Interpretation of SDy/x in method comparison • SDy/x is a measure for the random error component in method comparison, i.e. in both x and y. Thus: SDy/x is related to the expected total imprecision: SDy/x2 = SDay2 + b2 SDax2 • Given proportional analytical errors (and intercept around 0), approximately: CVy/x2 = CVay2 + CVax2 or CVy/x = 2 CVay for CVay = CVax • If only imprecision effects play a role in the method comparison, SDy/x2 SDay2 + b2 SDax2 (to convert SDy/x into CVy/x, take value of y) If SDy/x2 >> SDay2 + b2 SDax2 Proof of sample-related effects (see exercises) Routine (mmol/L) Comparison of regression procedures in practice 6,0 All regression procedures … 5,5 – Ordinary least-squares regression (OLR) 5,0 – Deming regression (DR) 4,5 – Passing-Bablok regression (PBR) 4,0 … give nearly the same results Note: r = 0.993 3,5 3,0 3,0 3,5 4,0 4,5 5,0 5,5 6,0 Reference (mmol/L) Routine (mmol/L) 6,0 The regression procedures … 5,5 – OLR, DR, PBR 5,0 … give different results Note: r = 0.871 4,5 4,0 3,5 3,0 3,0 3,5 4,0 4,5 5,0 5,5 6,0 Reference (mmol/L) Conclusion Choose the "statistically best" regression method? Answer: No, look for analytical reasons of the poor comparability! Notice also that the 95% CLs of the slope are: 1.08 – 1.44 Statistics & graphics for the laboratory 126 Regression Regression: Examples from the practice When different regression procedures give different results … – OLR (red): y = 0.750 x – 0.006 (r = 0.996) – Passing Bablok (blue): y = 0.686 x + 0.022 … look whether the data are linear! The residuals plot demonstrates non-linearity 0,2 3 Residuals Routine 4 2 1 0,1 0 -0,1 0 0 1 2 3 Reference 4 0 1 2 3 4 -0,2 Reference CI for SE at a critical concentration Therapeutic interval for drug assay: 300 – 2000 nmol/L Delta = Ŷ-X = a0 + (b-1)X = 20.3 +(1.014 – 1)X • X = 300 : Delta = 24.5 ; SE(Delta) = 9.5 Significance test: texp = (Delta – 0)/SE = 2.6 ; tcrit[0.05;n –2) = 1.998 significant • X = 2000: Delta = 48.9 ; SE(Delta) = 34.2 t = 1.4 not significant Conclusion: • At the lower decision point, a statistical significant difference exists, but it is judged to be clinically unimportant • At the upper decision point, no difference of statistical significance • The assays can be interchanged without clinical consequences Statistics & graphics for the laboratory 127 Regression Regression & correlation in method comparison Summary • Perform correlation analysis before [r-values >0.975 (small range) or >0.99 (wide range)] • In case of a method comparison of methods of the same hierarchy, regression techniques, that take the error in x and y into account, should be used. We recommend Deming regression. • Classical OLR is only applicable in case of method comparison with a reference method or in the calibration case (weighed-in concentrations). • Regression data are the more unreliable the greater the random error and the smaller the data range are. • Often forgotten data from regression analysis are the 95% confidence limits of slope and intercept. • Linear regression always results in a line, even when the data are not linear. Therefore, linear regression data always should be accompanied by a graphical presentation of results (scatter plot with x = y line or residuals plot) and the indication of the number of observations. The graph should be visually inspected for adequate range, distribution of data, and linearity Regression analysis provides information about: • constant systematic difference (intercept) • proportional systematic difference (slope) • random error (SDy/x from OLR) • sample-related effects (SDy/x >>>SDay2 + b2SDax2) Regression software CBstat (K. Linnet): A Windows program • (weighted) OLR • (weighted) Deming regression • Passing Bablok regression (www.cbstat.com) MedCalc (www.medcalc.com) EP-Evaluator (D. G. Rhoads Ass., USA) (www.dgrhoads.com) Analyse-It (Excel-plug-in) (www.analyse-it.com) Statistics & graphics for the laboratory 128 Regression Regression and calibration Calculations • Concentration of unknown and its random error • Limit of Detection (LoD) Graphical model • S = Signal • Yb = Signal of blank via regression = intercept a • Sb = Sy/x • LoD = a + 3 Sy/x Concentration (x0) and its random error (Sx0) NOTE: do not confuse with x at zero (0) concentration! Calculate x0 from signal (y0) via regression equation y = bx + a x0 = (y0 – a)/b Sx0: approximation: m = number of measurements of unknown n = number of calibration points The confidence interval of x0 is: CI = ± t(n-2, ) • Sx0 Calculation of LoD • Yb = "Signal of blank" via regression = intercept a • Sb = "Standard deviation of blank" = Sy/x "Signal" LoD = a + 3 Sy/x Calculate CLoD via regression equation. Statistics & graphics for the laboratory 129 Data transformation CAVE log transformation Introduction of non-linearity by data transformation in method comparison and commutability studies. Stöckl D, Thienpont LM. Clin Chem Lab Med 2008;46:1784-5. 6 y = 1.0994x - 0.3849 300 250 200 150 100 50 Routine method (lnAU).. Routine method (AU).. 350 0 y = 1.0113x + 0.0339 5 4 3 2 1 0 50 100 150 200 250 300 350 1 Reference method (AU) 3 4 5 6 6 y = 0.9995x + 14.65 300 250 200 150 100 50 0 Routine method (lnAU).. 350 Routine method (AU).. 2 Reference method (lnAU) 5 4 3 y = -0.0108x 3 + 0.21x 2 - 0.376x + 3.075 2 1 0 50 100 150 200 250 300 350 Reference method (AU) 1 2 3 4 5 6 Reference method (lnAU) Statistics & graphics for the laboratory 130 Exercises CorrRegr-EXCEL This EXCEL-file describes the advantages and disadvantages of the different EXCEL options for performing correlation and regression analysis. These options are: 1. With the fx icon 2. With Tools>Data Analysis 3. With a figure It also contains a worksheet with the additional regression features -95% confidence interval of the slope -95% prediction interval Correlation&Regression This tutorial contains interactive exercises for self-education in: -Correlation, and -Regression Worksheet correlation shows the influence of dispersion, slope, intercept, and range on r. Worksheet regression1 shows the influence of dispersion, slope, and intercept on the standard errors of slope, intercept, and Sy/x. Worksheet regression2 shows the influence of the range on the standard errors of slope, intercept, and Sy/x (this example is constructed with a constant SD over the range). Note r and r-square are given for information, only. Datasets (Method comparison: Weighted Deming, PractRegr1, PractRegr2) Statistics & graphics for the laboratory 131 Annex Introduction EXCEL® requirements The "Data Analysis" Add-in • In the "Worksheet Menu Bar", under • Tools "Data Analysis" should appear If it is not present, • Click "Tools" and Add-Ins Activate Analysis ToolPak & Analysis ToolPak - VBA … if not present in "Add-Ins" Install them from the EXCEL or Office package • "Add-ins" Statistics & graphics for the laboratory 132 Annex Tips to create EXCEL®-figures Create a figure: "Chart-wizard" Data&DataPresentation ("Figure") Modify a figure with: • "Chart-wizard" • "Chart-menu" • Double-click (left) on an element Move or size • Left mouse click depressed: Notice the full squares! • Shift & left click: Notice the empty squares! : move with : size with right click > Format object, : or, direct with the "Format" menu Statistics & graphics for the laboratory 133 Annex Tips to create EXCEL®-figures (ctd.) Make your own "templates": Activate figure • Chart>Chart type>Custom types>User defined>Add IMPORTANT: Scale names and sizes are kept too! Layout tips for EXCEL-figures • Not more than 8 columns (standard width 8,43) • Not more than 22 rows (standard height 12,75) • Font: minimum 16 (14), bold preferred • Use thick lines • Symbol size 6 or 7 • Click off autoscaling • Click "Don't move or size with cells" Statistics & graphics for the laboratory 134 Annex Copy EXCEL®-figures into PowerPoint Windows 98 with Office 2000 experience • Copy & paste direct if animation is intended • Copy & paste direct, then >Copy>Delete>Edit>Paste special: Picture (Enhanced metafile: "EMF") = Easy magnification without loss of quality • Copy & paste direct, then >Copy>Delete>Edit>Paste special: GIF, preferably keep 100% size: often looks more attractive • Note: Often preferred to copy the cell-range where the figure is placed ("What you see is what you get": colours, layout) • Adding text: often preferable in PowerPoint! Print EXCEL®-figures from PowerPoint Windows 98 with Office 2000 experience Note: Printing of ppt-Figures may pose problems. Check the print early if you want to make handouts! EMF figures ("Cells direct", then EMF) print well • In the absence of Gaussian-type lines • Incorporate text preferably in the .ppt slide and copy both as EMF [Bigger] GIF figures ("Cells direct", then GIF) • Advantage: better print of Gaussian-type lines • Problems: Incorporated text and scales have poor resolution, can be improved by • Paste direct, then GIF, then add text (& axes, eventually) in ppt, then copy & paste special both as EMF • Note: Overpaste of figure scales with .ppt text fields works only with GIF, but not with EMF. Statistics & graphics for the laboratory 135 Annex Copy EXCEL®-figures into PowerPoint – Examples Example: 5 columns, 16 rows, font 16 & 14 bold Cells direct 12 8 4 117,2 106,3 0 84,5 Bin Frequency-polygon Frequency 117,2 106,3 95,4 12 8 4 0 84,5 Frequency Frequency-polygon 95,4 Direct Bin Cells direct & EMF Cells direct & GIF 12 8 4 117,2 106,3 95,4 0 84,5 Frequency Frequency-polygon Bin Statistics & graphics for the laboratory 136 Annex Statistical resources Glossary of statistical terms http://linkage.rockefeller.edu/wli/glossary/stat.html http://www.statsoft.com/textbook/glosfra.html http://www.stats.gla.ac.uk/steps/glossary/index.html (most practical) http://davidmlane.com/hyperstat/glossary.html http://stat-www.berkeley.edu/~stark/SticiGui/Text/gloss.htm Interesting educational resources http://www.ruf.rice.edu/%7Elane/rvls.html http://www.math.uah.edu/stat/index.xml http://cast.massey.ac.nz/ http://www.anu.edu.au/nceph/surfstat/surfstat-home/surfstat.html (with progress tests!) http://www.stat.vt.edu/~sundar/java/applets/ http://www.kuleuven.ac.be/ucs/java/version2.0/Content.htm http://www.seeingstatistics.com/seeing1999/resources/opening.html (many possibilities, own data!) http://www.margaret.net/statistics/p02.htm http://bmj.bmjjournals.com/collections/statsbk/index.shtml http://science.widener.edu/svb/stats/stats.html http://www.vam.org.uk/vamstatdemo/demolist.asp http://www.stat.sc.edu/~west/applets/tdemo1.html (t-distribution) http://www.visualstatistics.net/ (t-distribution for EXCEL!) http://www.stat.uiowa.edu/~rlenth/Power/ (power) Statistical software General http://www.spss.com/sigmastat/ http://www.sas.com/technologies/analytics/statistics/index.html http://www.stata.com/ http://www.minitab.com/ http://www.graphpad.com/ (also educational!) "Laboratory statistics" http://www.medcalc.be http://www.cbstat.com http://www.analyse-it.com http://www.dgrhoads.com/ Statistics & graphics for the laboratory 137 Annex Statistical resources Books •Biometry: The Principles and Practice of Statistics in Biological Research. Robert R. Sokal, F. James Rohlf •Statistics and Chemometrics for Analytical Chemistry. James N. Miller, Jane C. Miller •Clinical Investigation and Statistics in Laboratory Medicine. Richard Jones, Brian Payne •Statistics at Square One. Ninth Edition. T D V Swinscow (see also: http://bmj.bmjjournals.com/collections/statsbk/index.shtml) •http://www.statsoft.com/textbook/stathome.html •http://davidmlane.com/hyperstat/ •http://faculty.vassar.edu/lowry/webtext.html •http://www.tufts.edu/~gdallal/LHSP.HTM Books (PDF) from the net •Analyzing Data with GraphPad Prism. A companion to GraphPad Prism version 3 (graphpad.com). •The InStat Guide to Choosing and Interpreting Statistical Tests. A manual for GraphPad InStat Version 3 (graphpad.com). •NIST/SEMATECH e-Handbook of Statistical Methods (http://www.itl.nist.gov/div898/handbook/) Statistics & graphics for the laboratory 138 Statistical tables Outlier testing: Dixon Q-test (one-tailed) x1 x2 x3 ... xn n P = 0.01 P = 0.05 3 4 5 6 7 8 9 10 11 12 13 14 16 18 20 25 0.988 0.889 0.780 0.698 0.637 0.683 0.635 0.597 0.679 0.642 0.615 0.641 0.595 0.561 0.535 0.489 0.941 0.765 0.642 0.560 0.507 0.554 0.512 0.477 0.576 0.546 0.521 0.546 0.507 0.475 0.450 0.406 Test quotient (x n - x n-1)/(x n-x 1) (x n - x n-1)/(x n-x 2) (x n - x n-2)/(x n-x 2) (x n - x n-2)/(x n-x 3) From: Rohlf FJ, Sokal RR. Statistical tables. 3rd ed. New York: WH Freedman & Co.: 1995. Factors for control limits of range rules n R0.01 R0.05 2 3 4 6 8 10 12 16 20 3.64 4.12 4.40 4.76 4.99 5.16 5.29 5.50 5.65 2.77 3.31 3.63 4.03 4.29 4.47 4.62 4.85 5.01 From: Pearson ES. The probability integral of the range of samples of n observations from a normal population. I. Forew ord and tables. Biometrika 1942;32:301. Statistics & graphics for the laboratory 139 Cochran C – Critical values Statistics & graphics for the laboratory 140 Annex Presenter's publications & courses related to the topic Publications •Stöckl D. Beyond the myths of difference plots [letter]. Ann Clin Biochem 1996;33:575-7. •Stöckl D. Difference versus mean plots [reply]. Ann Clin Biochem 1997;34:571. •Hyltoft Petersen P, Stöckl D, Blaabjerg O, Pedersen B, Birkemose E, Thienpont L, Flensted Lassen J, Kjeldsen J. Graphical interpretation of analytical data from comparison of a field method with a reference method by use of difference plots [opinion]. Clin Chem 1997;43:2039-46. •Stöckl D, Dewitte K, Thienpont LM. Validity of linear regression in method comparison studies: is it limited by the statistical model or the quality of the analytical input data? Clin Chem 1998;44:2340-6. •Stöckl D, Dewitte K, Fierens C, Thienpont LM. Evaluating clinical accuracy of systems for self-monitoring of blood glucose by error grid analysis. Comment on constructing the “upper A-line”. Diabetes Care 2000;11:1711-2. •Dewitte K, Fierens C, Stöckl D, Thienpont LM. Application of the Bland-Altman plot for interpretation of method-comparison studies: a critical investigation of its practice. Clin Chem 2002;48:799-801;discussion 801-2. •Cabaleiro DR, Stöckl D, Thienpont LM. Error messages when calculating chisquare statistics with microsoft EXCEL. Clin Chem Lab Med 2004;42:243. •Stöckl D, Rodríguez Cabaleiro D, Van Uytfanghe K, Thienpont LM. Interpreting method comparison studies by use of the bland-altman plot: reflecting the importance of sample size by incorporating confidence limits and predefined error limits in the graphic. Clin Chem 2004;50:2216-8. •Stöckl D, Rodríguez Cabaleiro D, Thienpont LM. Peculiarities and problems with the EXCEL F-test. Clin Chem Lab Med 2004:42:273. Courses •Analytical quality in the medical laboratory: Concepts for method selection, evaluation, and control. In cooperation with Belgian Association of Laboratory Technologists and Hogeschool Gent (Gent, Belgium, 1998). •Practice-oriented strategies for the development and evaluation of analytical methods. FOCUS: Graphical and statistical techniques for the interpretation of method comparison studies (academical year 2000/1). In cooperation with Prof. LM Thienpont (University of Ghent). •Graphical and statistical techniques for the interpretation of method comparison studies. 14th IFCC European Congress of Clinical Chemistry and Laboratory Medicine - Euromedlab 2001 (Prague, Czech Republic). •Graphical techniques for the intepretation of method comparison studies. Education days for Clinical Biochemists: Method validation. Odense, Denmark: 1720 December 2001. •Educational course on biostatistics. 18th International Congress of Clinical Chemistry and Laboratory Medicine IFCC Worldlab 2002 (Kyoto, Japan). •Statistical and graphical techniques for the intepretation of method comparison studies. 15th IFCC European Congress of Clinical Chemistry and Laboratory Medicine - Euromedlab 2003 (Barcelona, Spain). •Statistical and graphical tools for the medical laboratory – A problem oriented journey from test utility to internal quality control. 2003 (Bratislava, Slovakia). •Statistical and graphical tools for the laboratory – from test utility to IQC. Full-day Workshop, AACC 2004. Statistics & graphics for the laboratory 141