Statistical Inference - edventure-ga
advertisement

AP Statistics
Summer, 2013
Paul L. Myers
The Paideia School
Atlanta, GA 30307
myers.paul@paideiaschool.org
www.edventure-ga.com
AP Statistics Summer Institute
Summer, 2013
Paul L. Myers, Consultant
The Paideia School, Atlanta, GA
myers.paul@paideiaschool.org
Day 1
o
o
o
o
Logistics & Introductions
The AP Program & The AP Statistics Syllabus
Appropriate Use of Technology – Graphing Calculators
Topic I - Exploring Data
Constructing and interpreting graphical displays of univariate data
Summarizing distributions of univariate data
Comparing distributions of univariate date
Exploring bivariate data
Exploring categorical data
Day 2
o Materials & Resources
o Appropriate Use of Technology – Computer Software
o Topic II - Sampling & Experimentation
Overview of methods of data collection
Planning and conducting surveys
Planning and conducting experiments
Generalizability of results and conclusions that can be drawn from
observational studies, experiments, and surveys
Day 3
o The AP Audit Syllabus & Timeline
o Appropriate Use of Hands-On Activities
o Topic III - Anticipating Patterns
Probability
Combining independent random variables
The normal distribution
Sampling distributions
Day 4
o AP Exam Review Tips
o Grading the AP Exam
o Topic IV - Statistical Inference
Estimation
Tests of Significance
2
Random Introductions
On the average, how many draws will it take to introduce N people?
Each person is assigned a random integer from 1 to N.
Random integers, from 1 to N, are selected with replacement.
A short TI-8X home-screen program:
o Initialize a Counter:
0 C
o Update the Counter:
C 1 C
o Select a Random Integer:
RandInt (1, N)
0 C
Enter
C 1 C :{C , RandInt (1, N )}
Enter
Person Number
1
P (Introduced)
E [Introduced]
2
3
4
5
N
3
AP Statistics Topic Outline
Topic
Exam Percentage
Exploring Data
20%-30%
Sampling &
Experimentation
Anticipating Patterns
10%-15%
Statistical Inference
30%-40%
20%-30%
4
Exploring Data
5
Topic I – Exploring Data
Describing patterns and departures from patterns (20%-30%)
Exploring analysis of data makes use of graphical and numerical techniques to study patterns and
departures from patterns. Emphasis should be placed on interpreting information from graphical and
numerical displays and summaries.
A. Constructing and interpreting graphical displays of distributions of univariate data
(dotplot, stemplot, histogram, cumulative frequency plot)
1. Center and spread
2. Clusters and gaps
3. Outliers and other unusual features
4. Shape
B. Summarizing distributions of univariate data
1. Measuring center: median, mean
2. Measuring spread: range, interquartile range, standard deviation
3. Measuring position: quartiles, percentiles, standardized scores (z-scores)
4. Using boxplots
5. The effect of changing units on summary measures
C. Comparing distributions of univariate data (dotplots, back-to-back stemplots, parallel
boxplots)
1. Comparing center and spread: within group, between group variables
2. Comparing clusters and gaps
3. Comparing outliers and other unusual features
4. Comparing shapes
D. Exploring bivariate data
1. Analyzing patterns in scatterplots
2. Correlation and linearity
3. Least-squares regression line
4. Residuals plots, outliers, and influential points
5. Transformations to achieve linearity: logarithmic and power transformations
E. Exploring categorical data
1. Frequency tables and bar charts
2. Marginal and joint frequencies for two-way tables
3. Conditional relative frequencies and association
4. Comparing distributions using bar charts
6
Activity 1: How Do The Colors
Vary?
1. Find the weight (in grams) of your bag of M&Ms.
(We will use it in a later activity!)
______________
2. Open your bag of M&Ms and count the number and the percentage of each color and the
total number of M&Ms in the bag.
Color
Brown
Yellow
Red
Blue
Orange
Green
Total
Number
Percentage
3. Using your M&Ms, construct a pie chart of colors.
Pie Chart
7
Matching Displays to Variables I
Consider the following list of variables and data displays:
A. Scores on a fairly easy examination in statistics
B. Number of months required to achieve pregnancy for a sample of women who attempted
to get pregnant
C. Age at death of a sample of 34 persons
D. Heights of a group of college students
E. The last digit in the social security number of each of 40 students
F. Number of medals won by medal-winning countries in the 2000 Sydney Olympics
G. SAT scores for a group of college students
8
Matching Displays to Variables II
Consider the following group of histograms and summary statistics. Each of the variables
corresponds to one of the histograms.
Variable Mean Median Standard Deviation
1
60
50
10
2
50
50
15
3
50
50
10
4
53
50
20
5
47
50
10
6
50
50
5
9
Matching Displays to Variables III
Consider the following group of histograms and box plots. Each box plot corresponds to one of
the histograms. Match the box plots to the histograms and explain how you made your choices.
10
United States Presidents
President
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
George Washington
John Adams
Thomas Jefferson
James Madison
James Monroe
John Quincy Adams
Andrew Jackson
Martin Van Buren
William Henry Harrison
John Tyler
James Polk
Zachary Taylor
Millard Fillmore
Franklin Pierce
James Buchanan
Abraham Lincoln
Andrew Johnson
Ulysses S. Grant
Rutherford B. Hayes
James A. Garfield
Chester A. Arthur
Grover Cleveland
Benjamin Harrison
Grover Cleveland
William McKinley
Theodore Roosevelt
William Howard Taft
Thomas Woodrow Wilson
Warren G. Harding
John Calvin Coolidge
Herbert Clark Hoover
Franklin D. Roosevelt
Harry S Truman
Dwight D. Eisenhower
John F. Kennedy
Lyndon B. Johnson
Richard M. Nixon
Gerald R. Ford
James E. Carter
Ronald W. Reagan
George H. W. Bush
William J. Clinton
George W. Bush
Barack Obama
Date of
Birth
2/22/1732
10/30/1735
4/13/1743
3/16/1751
4/28/1758
7/11/1767
3/15/1767
12/5/1782
2/9/1773
3/29/1790
11/2/1795
11/24/1784
1/7/1800
11/23/1804
4/23/1791
2/12/1809
12/29/1808
4/27/1822
10/4/1822
11/19/1831
10/5/1830
3/18/1837
8/20/1833
3/18/1837
1/29/1843
10/27/1858
9/15/1857
12/28/1856
11/2/1865
7/4/1872
8/10/1874
1/30/1882
5/8/1884
10/14/1890
5/29/1917
8/27/1908
1/9/1913
7/14/1913
10/1/1924
2/6/1911
6/12/1924
8/19/1946
7/6/1946
8/4/1961
Date of
Inauguration
4/30/1789
3/4/1797
3/4/1801
3/4/1809
3/4/1817
3/4/1825
3/4/1829
3/4/1837
3/4/1841
4/6/1841
3/4/1845
3/5/1849
7/9/1850
3/4/1853
3/4/1857
3/4/1861
4/15/1865
3/4/1869
3/4/1877
3/4/1881
9/19/1881
3/4/1885
3/4/1889
3/4/1893
3/4/1897
9/14/1901
3/4/1909
3/4/1913
3/4/1921
8/3/1923
3/4/1929
3/4/1933
4/12/1945
1/20/1953
1/20/1961
11/22/1963
1/20/1969
8/9/1974
1/20/1977
1/20/1981
1/20/1989
1/20/1993
1/20/2001
1/20/2009
Date of
Death
12/14/1799
7/4/1826
7/4/1826
6/28/1836
7/4/1831
2/23/1848
6/8/1845
7/24/1862
4/4/1841
1/18/1862
6/15/1849
7/9/1850
3/8/1874
10/8/1869
6/1/1868
4/15/1865
7/31/1875
7/23/1885
1/17/1893
9/19/1881
11/18/1886
6/24/1908
3/13/1901
6/24/1908
9/14/1901
1/6/1919
3/8/1930
2/3/1924
8/2/1923
1/5/1933
10/20/1964
4/12/1945
12/26/1972
3/28/1969
11/22/1963
1/22/1973
4/22/1994
12/26/2006
6/6/04
Age at
Inauguration
57
61
57
57
58
57
61
54
68
51
49
64
50
48
65
52
56
46
54
49
50
47
55
55
54
42
51
56
55
51
54
51
60
62
43
55
56
61
52
69
64
46
55
47
Age at
Death
67
90
83
85
73
80
78
79
68
71
53
65
74
64
77
56
66
63
70
49
56
71
67
71
58
60
72
67
57
60
90
63
88
78
46
64
81
93
93
11
1. What do you think the shape of Inauguration Ages will be?
2. Draw a stem-and-leaf plot of Inauguration Ages.
4
*
5
*
6
*
3. Find the 5-Number Summary of Inauguration Ages.
Min
Q1
Med
Q3
Max
=
=
=
=
=
4. Draw a boxplot of Inauguration Ages.
5. Are there any outliers? Who are they and what are their ages?
6. Draw a histogram of Inauguration Ages.
7. Find the mean and standard deviation of Inauguration Ages.
12
1. What do you think the shape of Death Ages will be?
2. Draw a stem-and-leaf plot of Death Ages.
4
*
5
*
6
*
7
*
8
*
9
*
3. Find the 5-Number Summary of Death Ages.
Min
Q1
Med
Q3
Max
=
=
=
=
=
4. Draw a boxplot of Death Ages.
5. Are there any outliers? Who are they and what are their ages?
6. Draw a histogram of Death Ages.
7. Find the mean and standard deviation of Death Ages.
13
AP Statistics
One-Variable Statistics Project
Your report must be done in Word and your displays must be done in Fathom and pasted into
your Word document. Your report must be titled and the title centered and in bold type. All
narratives must be in complete sentences and written in paragraph form with correct
punctuation and spelling. Graphical displays must be complete (titled, axes labeled and scaled,
sized appropriately) and arranged in a logical format on the page. Your project will be graded on
content and presentation.
You will use internet resources to find a set of data concerning a topic of interest to you. Your
data set must have a minimum of 50 individuals. Information about one quantitative variable and
at least one categorical variable should be collected for these individuals. You will then write a
report about the data set that follows the guidelines below:
Part I: The Introduction
Describe your data set, give its web address, and describe what you are intending to investigate.
Be sure to include some background information about your data so that your project becomes
interesting to the reader. You may include photos from the web site in this portion of your
project.
Part II: The Analysis
Display your data graphically and numerically.
(a) Create at least one display which is appropriate for your quantitative variable.
(b) Calculate the appropriate measures of center and spread and mark these values on your
display.
(c) Create an appropriate summary table of your numerical measures.
(d) Create at least one display that compares the quantitative variable split by category.
(e) Calculate the appropriate measures of center and spread split by category and mark
these values on your display.
(f) Create an appropriate summary table of your numerical measures split by category.
Part III: The Conclusion
Summarize the findings of your investigation. Issues that you should address include but are not
limited to:
1. Shape. Is the shape clear or does one type of graph more clearly show a shape than another? In
the display, does the scaling make any difference in the overall shape?
2. Unusual Features. Are there any outliers? How do you know? If so, identify them and either
justify eliminating them or explain their presence.
3. Spread. What percentage of your data points are within one standard deviation of the mean?
4. Comparisons. When your data is split by category, compare and contrast the distributions.
14
AP Statistics
One-Variable Statistics Project Grading Rubric
Introduction - Describe your data set, give its web address, and
describe what you are intending to investigate. Be sure to include some
background information about your data so that your project becomes
interesting to the reader. You may include photos from the web site in
this portion of your project.
Quantitative Displays
(g) Create at least one display which is appropriate for your
quantitative variable.
(h) Calculate the appropriate measures of center and spread and
mark these values on your display.
(i) Create an appropriate summary table of your numerical
measures.
Quantitative Displays split by Category
(j) Create at least one display that compares the quantitative
variable split by category.
(k) Calculate the appropriate measures of center and spread split
by category and mark these values on your display.
(l) Create an appropriate summary table of your numerical
measures split by category.
Conclusion - Summarize the findings of your investigation. Issues that
you should address include but are not limited to:
1 point
2 points
2 points
1. Shape. Is the shape clear or does one type of graph more clearly
show a shape than another? In the display, does the scaling make any
difference in the overall shape?
2. Unusual Features. Are there any outliers? How do you know? If so,
identify them and either justify eliminating them or explain their
presence.
3 points
3. Spread. What percentage of your data points are within one
standard deviation of the mean?
4. Comparisons. When your data is split by category, compare and
contrast the distributions.
Presentation - Your report must be done in Word and your displays
must be done in Fathom and pasted into your Word document. Your
report must be titled and the title centered and in bold type. All
narratives must be in complete sentences and written in paragraph form
with correct punctuation and spelling. Graphical displays must be
complete (titled, axes labeled and scaled, sized appropriately) and
arranged in a logical format on the page.
2 points
TOTAL
10 points
15
Multiple Choice Practice
1.
2.
16
3.
4.
17
Free Response Practice
2006 FR#1 – The Catapults
Two parents have each built a toy catapult for use in a game at an elementary school fair. To
play the game, the students will attempt to launch Ping-Pong balls from the catapults so that the
balls land within a 5-centimeter band. A target line will be drawn through the middle of the band,
as shown in the figure below. All points on the target line are equidistant from the launching
location.
If a ball lands within the shaded band, the student will win a prize.
The parents have constructed the two catapults according to slightly different plans. They want
to test these catapults before building additional ones. Under identical conditions, the parents
launch 40 Ping-Pong balls from each catapult and measure the distance that the ball travels before
landing. Distances to the nearest centimeter are graphed in the dotplot below.
(a) Comment on any similarities and any differences in the two distributions of distances traveled
by balls launched from catapult A and catapult B.
(b) If the parents want to maximize the probability of having the Ping-Pong balls land within the
band, which one of the catapults, A or B, would be better to use than the other? Justify your
choice.
(c) Using the catapult that you chose in part (b), how many centimeters from the target line
should this catapult be placed? Explain why you chose this distance.
18
Free Response Practice
2008 FR#1 – Breakfast Cereal
19
Is There an Association Between Spaces From Go and Property Cost?
Property
Mediterranean Avenue
Baltic Avenue
Reading Railroad
Oriental Avenue
Vermont Avenue
Connecticut Avenue
St. Charles Place
Electric Company
States Avenue
Virginia Avenue
Penn Railroad
St. James Place
Tennessee Avenue
New York Avenue
Kentucky Avenue
Indiana Avenue
Illinois Avenue
B & O Railroad
Atlantic Avenue
Ventnor Avenue
Water Works
Marvin Gardens
Pacific Avenue
North Carolina Avenue
Pennsylvania Avenue
Short Line Railroad
Park Place
Boardwalk
1.
2.
3.
4.
5.
6.
Spaces from
GO
1
3
5
6
8
9
11
12
13
14
15
16
18
19
21
23
24
25
26
27
28
29
31
32
34
35
37
39
Cost
60
60
200
100
100
120
140
150
140
160
200
180
180
200
220
220
240
200
260
260
150
280
300
300
320
200
350
400
Draw a scatterplot of (Spaces From Go, Cost).
Does there appear to be an association between the two variables?
Find a “Line of Best Fit” – y = mx+b.
What does b represent? What does m represent?
Are there any unusual points? What are they?
Predict the cost of a “new” property that is 50 spaces from Go.
20
Measure The Correlation
For each of the following scatterplots:
Draw a symmetrical ellipse that characterizes the data.
Draw the major and minor axes of the ellipse
length of the minor axis
Calculate r 1
length of the major axis
21
Matching Descriptions to Scatter Plots I
Match each of the five scatterplots to the description of its regression line and correlation
coefficient. The scales on the axes of the scatterplots are the same.
H. r 0.83 , $y 2.1 1.4 x
I. r 0.31 , $y 7.8 0.5x
r 0.96 , $y 2.1 1.4 x
K. r 0.83 , $y 11.8 1.4 x
L. r 0.41 , $y 1.4 1.4 x
J.
22
Matching Descriptions to Scatter Plots II
For the nine points on the following scatterplot, r 0.71 , r 2 0.5 , and the equation of the leastsquares regression line is y 4.00 1.00 x .
A tenth point is added to the original nine. Match each of the following points with the
correlation coefficient that would result if that point were added. Do not calculate the new
correlation coefficient but rather reason out which r must go with each point.
Points
(a) (3,7)
(b) (2,6)
(c) (10,0)
(d) (10,6)
(e) (10,14)
(f) (100,0)
(g) (100,6)
Correlation coefficients
I. -0.84
II. -0.70
III. 0.02
IV. 0.22
V. 0.71
VI. 0.73
VII. 0.96
23
Matching Descriptions to Scatter Plots III
Analyze the four data sets (from Anscombe, 1973) in the following table.
What do they have in common?
Why are they of interest?
What do they illustrate?
Data Set I
x
y
10
8.04
8
6.95
13
7.58
9
8.81
11
8.33
14
9.96
6
7.24
4
4.26
12
10.84
7
4.82
5
5.68
Data Set 2
x
y
10
9.14
8
8.14
13
8.74
9
8.77
11
9.26
14
8.10
6
6.13
4
3.10
12
9.13
7
7.26
5
4.74
Data Set 3
x
y
10
7.46
8
6.77
13
12.74
9
7.11
11
7.81
14
8.84
6
6.08
4
5.39
12
8.15
7
6.42
5
5.73
Data Set 4
x
y
8
6.58
8
5.76
8
7.71
8
8.84
8
8.47
8
7.04
8
5.25
19
12.50
8
5.56
8
7.91
8
6.89
24
What Is R-Squared (Really!)?
Our goal is to find a model to predict y.
Plot the data set (x,y).
One-Variable Model
1. Calculate y (the mean of y)
2. Draw the y line.
This is our One-Variable Model.
3. Draw the vertical segments representing y y (the deviations from the mean).
4. Draw squares representing y y
5. Shade the squares and calculate
2
(the squared deviations from the mean).
y y
2
(the total squared variability in this model).
We will use this as our measure of the One-Variable Model
variability.
Two-Variable Model
^
1. Calculate y (the least-squares regression line of (x,y))
^
2. Draw the y line.
This is our Two-Variable Model.
^
3. Draw the vertical segments representing y y (the residuals from the LSRL).
2
^
4. Draw squares representing y y (the squared residuals).
2
^
5. Shade the squares and calculate y y (the total squared variability in this model).
We will use this as our measure of the Two-Variable Model
variability.
Measuring the Quality of the Model
1. Calculate
that is
2. Calculate
2
^
y y y y (the amount of variability in the One-Variable Model
explained by the Two-Variable Model)
2
y y
2
2
^
y y
(the percentage of variability in the One-Variable
2
y y
Model that is explained by the Two-Variable Model)
This is r2.
25
AP Statistics - Two Variable Statistics Project
Find a data set with at least 25 paired data points that represent some variables that might
realistically have an association. You will write a report, using Word, including, but not limited
to, the following.
Discuss your data and the source of the data. Include why you find this data interesting and what
type of relationship (or association) you expect to find BEFORE you ever plot the data and why
you expect this relationship.
Using Fathom, plot the data and find:
the regression equation.
the correlation coefficient
the coefficient of determination.
a residual plot
Be sure each graph is appropriately titled and labeled.
Discuss the meaning of all parts of the regression equation as they relate to your data.
Interpret both the correlation coefficient and the coefficient of determination as they
relate to your data.
What information does the residual plot give you?
Explain why you would or would not use the regression equation to predict value of the
response variable.
Are there any influential points? If not, how do you know? If so, how would you deal
with those points?
If there are any categorical variables present, indicate them on your graph and discuss
what significance, if any, they have to the association.
Which of the data values have the smallest and largest residual? Interpret the meaning of
these residuals.
Was your expectation about the relationship accurate or not? If it was accurate, why do
you think you accurately predicted the nature of the relationship? If not, why not?
Remember to incorporate your graphs into the discussion portion of your project. Treat
this as you would a paper for English. Presentation will count.
26
AP Statistics - Two Variable Statistics Project Rubric
Presentation:
Your report is done in Word and your displays are done in Fathom
and pasted into your Word document. Graphical displays are to be
complete (titled, axes labeled and scaled, sized appropriately) and
arranged in a logical format on the page. Your report is titled. All
narratives are in complete sentences and written in paragraph form
with correct punctuation and spelling.
Fathom:
Plot the data.
Find the regression equation.
Find the correlation coefficient.
Find the coefficient of determination.
Find a residual plot.
½ point
½ point
½ point
½ point
Discussion:
Discuss your data and the source of the data. Include why you find this
data interesting and what type of relationship (or association) you
expect to find BEFORE you ever plot the data and why you expect this
relationship. Was your expectation about the relationship accurate or
not? If it was accurate, why do you think you accurately predicted the
nature of the relationship? If not, why not?
Interpretation:
Discuss the meaning of all parts of the regression equation as they
relate to your data. (slope and intercept)
Interpret both the correlation coefficient and the coefficient of
determination as they relate to your data.
What information does the residual plot give you?
Explain why you would or would not use the regression equation to
predict value of the response variable.
Are there any influential points? If not how do you know? If so, how
would you deal with those points?
If there are any categorical variables present indicate them on your
graph and discuss what significance, if any, they have to the association.
Which of the data values have the smallest and largest residual?
Interpret the meaning of these residuals.
TOTAL
½ point
2 points
2 points
½ point
1 point
1 point
½ point
½ point
10 points
27
M & M Statistics
Exponential Decay
1. Count the number of M&M Minis in your tube - Place that number in Trial Number 0.
2.
(a) Place the M&M Minis in the tube.
(b) Shake.
(c) Pour on the table.
(d) Remove the M&M Minis with no M facing Up.
(e) Count the remaining M&M Minis.
(f) Place that number in Trial Number 1.
3. Continue step 2 (increasing the trial number by 1) until there is only 1 M&M left.
Trial Number
Number of Minis Left
0
1
2
4. Draw a scatterplot of:
(Trial Number, Number of M&M Minis)
3
4
5
6
7
8
9
5. Transform the data and draw a scatterplot of:
(Time, log(Number of M&M's))
6. Find the LSRL of the transformed data.
LSRL _______________________________
r2 ____________
7. Undo the transformation and find the model
________________________________
28
Interspecies Scaling for Mammals
Mouse
Rat
Rabbit
Monkey
Dog
Human
Elephant
Weight
(Kg)
0.03
0.32
3.97
6.55
16
68
2,500
Heart Rate
(beats per minute)
580
320
170
150
120
25
Find an appropriate model and predict the heart rate of a human.
29
Multiple Choice Practice
1.
2.
30
3.
4.
31
Free Response Practice
Lunchtime
Does how long children spend at the lunch table help predict how much food they eat?
Data was collected on 20 toddlers who were observed over several months at a nursery school.
Both time (in minutes) spent at the lunch table and calories consumed were collected.
A computer printout of the linear regression is shown below.
(a) What is the equation of the least-squares regression line (in context)?
(b) Find the value of and explain the meaning of the slope in the context of the problem.
(c) Find the value of and explain the meaning of the y-intercept in the context of the problem.
(d) Find the value of and explain the meaning of the correlation in the context of the
problem.
(e) Predict the number of calories consumed by a toddler who spends 30 minutes at the
lunch table.
32
Free Response Practice
2006 FR#2 – Soapsuds
A manufacturer of dish detergent believes the height of soapsuds in the dishpan depends on the
amount of detergent used. A study of the suds’ height for a new dish detergent was conducted.
Seven pans of water were prepared. All pans were of the same size and type and contained the
same amount of water. The temperature of the water was the same for each pan. An amount of
dish detergent was assigned at random to each pan, and that amount of detergent was added to
that pan. Then the water in the dishpan was agitated for a set of amount of time, and the height
of the resulting suds were measured.
A plot of the data and the computer printout from fitting a least-squares regression line to the
data are shown below.
(a) Write the equation of the fitted regression line. Define any variables used in this equation.
(b) Note that s = 1.99821 in the computer output. Interpret this value in the context of the
study.
(c) Identify and interpret the standard error of the slope.
33
2012 FR#1 – Sewing Machines
1. The scatterplot below displays the price in dollars and quality rating for 14 different sewing
machines.
a) Describe the nature of the association between price and quality rating for the sewing
machines.
b) One of the 14 sewing machines substantially affects the appropriateness of using a linear
regression model to predict quality rating based on price. Report the approximate price
and quality rating of that machine and explain your choice.
c) Chris is interested in buying one of the 14 sewing machines. He will consider buying only
those machines for which there is no other machine that has both higher quality and
lower price. On the scatterplot reproduced below, circle all data points corresponding to
machines
that
Chris will
consider
buying.
34
Sampling & Experimentation
Triple Blind Study
Participant doesn’t know what he is taking
Physician doesn’t know what the participant is taking
Statistician doesn’t know what he is doing
35
Topic II – Sampling and Experimentation
Planning and conducting a study (10%-15%)
Data must be collected according to a well-developed plan if valid information on a conjecture is to be
obtained. This includes clarifying the question and deciding upon a method of data collection and
analysis.
A. Overview of methods of data collection
1. Census
2. Sample survey
3. Experiment
4. Observational study
B. Planning and conducting surveys
1. Characteristics of a well-designed and well-conducted survey
2. Populations, samples, and random selection
3. Sources of bias in sampling and surveys
4. Sampling methods, including simple random sampling, stratified random sampling,
and cluster sampling
C. Planning and conducting experiments
1. Characteristics of a well-designed and well-conducted experiment
2. Treatments, control groups, experimental units, random assignments, and
replication
3. Sources of bias and confounding, including placebo effect and blinding
4. Randomized block design, including matched pairs design
D. Generalizability of results and types of conclusions that can be drawn from observational
studies, experiments, and surveys
36
Newspaper/Magazine/Web Articles
Answer the following questions:
1. Was this an experiment or an observational study?
2. What were the explanatory and response variables?
3. What was the sample size?
4. If it is an observational study, is there a confounding effect lurking in the background? If
so, what is it?
5. If it was an experiment,
(a) Was there a control group? Was there a placebo?
(b) Was it run blind?
(c) Was it run double blind?
(d) What factors were used and at what levels were they used?
6. What was the conclusion of the study? Do you believe it? Why or why not?
37
38
An Exercise in Sampling: Rolling Down the River
A farmer has just cleared a new field for corn. It is a unique plot of land in that a river
runs along one side. The corn looks good in some areas of the field but not others. The farmer is
not sure that harvesting the field is worth the expense. He has decided to harvest 10 plots and
use this information to estimate the total yield. Based on this estimate, he will decide whether to
harvest the remaining plots.
Part I.
A. Method Number One: Convenience Sample
The farmer began by
choosing 10 plots that would be
easy to harvest. They are marked
on the grid below:
Since then, the farmer has had second thoughts about this selection and has decided to
come to you (knowing that you are an AP statistics student, somewhat knowledgeable, but far
cheaper than a professional statistician) to determine the approximate yield of the field.
You will still be allowed to pick 10 plots to harvest early. Your job is to determine which
of the following methods is the best one to use and to decide if this is an improvement over the
farmer’s original plan.
B. Method Number Two: Simple Random Sample
Use your calculator or a random number table to choose 10 plots to harvest. Mark them
on the grid below, and describe your
method of selection.
39
C. Method Number Three: Stratified Sample
Consider the field as grouped in vertical columns (called strata). Using your calculator or a
random number table, randomly choose one plot from each vertical column and mark these plots
on the grid.
D. Method Number Four: Stratified Sample
Consider the field as grouped in horizontal rows (also called strata). Using your calculator
or a random number table, randomly choose one plot from each horizontal row and mark these
plots on the grid.
40
OK, the crop is ready. Below is a grid with the yield per plot. Estimate the average yield per plot
based on each of the four sampling techniques.
Observations:
1) You have looked at four different methods of choosing plots. Is there a reason, other than
convenience, to choose one method over another?
2) How did your estimates vary according to the different sampling methods you used?
3) Compare your results to someone else in the class. Were your results similar?
4) Pool the results of all students for the mean yields from the simple random samples and make
a class boxplot. Repeat for means from vertical strata and from horizontal strata. Compare the
class boxplots for each sampling method. What do you see?
5) Which sampling method should you use? Why do you think this method is best?
6) What was the actual yield of the farmer’s field? How did the boxplots relate to this actual
value?
41
Part II:
The farmer was very impressed with the results of your study and seeks to improve the
yield of that part of the field the following year. Believing that irrigation is the answer, a new
system was installed. The following year’s yield was:
Redo your sampling using a SRS, vertical stratification, and horizontal stratification. Be certain to
mark on the grids the plots you choose.
A. Simple Random Sample:
B. Stratified Sample (vertically):
42
C. Stratified Sample (horizontally):
Observations:
1) Compare the class boxplots of the sample means obtained from the SRS and the two methods
of stratified sampling.
2) Based on the results of both activities, under what conditions is it more useful to use stratified
sampling?
3) Based on the results of both activities, under what conditions is it more useful to use a simple
random sample?
43
Teacher Notes for Rolling Down The River
The purpose of this exercise is to allow students to see the effects of different methods of sampling in
different situations.
Part I.
A. Convenience Sample
This is rarely a good choice. Although it is attractive to the farmer to harvest the plots as easily as
possible, it often leads to large bias in the result.
B. Simple Random Sample
With simple random sampling, all possible sets of 10 plots have an equal chance of being selected. By using
this impartial selection method, higher yield plots should be balanced out by lower yield plots. However, it
may be the case, since all possible combinations are possible, that all of the selected plots have a high yield
or that all of the selected plots have a low yield. Thus there is large variability in the sample statistic.
C/D. Stratification
When there is some factor that can influence or affect the response, (in this case the river has an effect on
the yield), then using a stratified sample should reduce some of the variability in the means of repeated
samples. However, it is necessary to choose the strata correctly. Strata should be constructed so that
within the strata the data are very similar (homogeneous) while the individual strata contain sets of data
that are as different as possible (heterogeneous). The farmer should be consulted as to the direction of
the strata. His experience would determine the best approach.
Note: The data were purposely set up so that the effects of proper stratification would be startling. This
does not mean to suggest that a crop grown near a river would necessarily result in such a large difference
in yields.
Observations / Answer Key:
1) One needs to choose a method that will give the best estimate of the yield. This can be affected by
factors that cannot be controlled: e.g. the placement of the river. That’s why one shouldn’t choose the ten
plots chosen by the farmer.
2) The student will see that the farmer’s sample yields a very low estimate compared to the other
methods used.
3) Comparing results with a peer helps the student verify that the sampling was done correctly. This does
not mean the students will have the same sample, but each student should use the same process of
drawing a sample for a given method. Some methods will produce highly variable results while others are
much more consistent.
4) The variability of the means of the sample yields, as shown by the length of the boxplot and the width
of the middle 50%, will reduce drastically once the student has stratified appropriately. Thus the strata that
are effective are the vertical ones, in which the values in each stratum are similar. This stratification
reduces the variation in the sample means since the values chosen for a particular stratum vary little from
sample to sample relative to the variability in the population.
5) Vertical stratification should be used since the sample would then include higher yielding plots as well as
lower yielding ones.
6) The actual yield is 5004. The class boxplot for the means resulting from the vertical stratification should
be centered near 5004/100 or about 50.
Part II.
Observations / Answer Key:
1) Since the river effect has been cancelled out by the irrigation process, there is no discernable pattern in
the yield (in effect, the data are randomly distributed). Therefore, there should be no improvement in
using a stratified random sample over a SRS. The boxplots should be centered near the total yield divided
by 100 (7603/100 or approximately 76).
2) It is more useful to stratify when one suspects that there is some outside factor affecting the response
variable.
3) It is more useful to use a SRS when there is no reason to stratify; that is, when there is no reason to
expect that an outside factor is affecting the response variable. It certainly is easier and is often less
expensive to use a SRS.
44
Helicopters
Question:
Do long-rotor paper helicopters take a different length of time to fall,
on average, than short-rotor paper helicopters?
Materials:
1. Paper to construct helicopters – both long rotor and short
rotor
2. Scissors
3. Stapler
4. Paper clip
5. Stopwatch
Procedure:
1.
Construct one long-rotor helicopter and one short-rotor helicopter (see diagram and
instructions)
2.
Each type of helicopter will be dropped 10 times from the ceiling to the floor.
Team
Trial Number
Type of Rotor
(Long or Short)
Time
(sec.)
Dropper
Timer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
45
Helicopter Construction Instructions
1. Cut out the rectangular shape of the helicopter on the solid lines.
2. Cut one-third of the way in from each side of the helicopter to the vertical dashed lines
on the solid line.
3. Fold both sides toward the center creating the base. The base can be stapled at the top
and bottom. Try to be consistent about where the staples are placed. Use a paper clip to
add some weight to the body.
4. For long-rotor helicopters, cut down from the top along the solid center line to the
horizontal dashed line.
5. For short-rotor helicopters, proceed as in step 4, but cut the rotors off along the
horizontal line marked.
6. Fold the rotors in opposite directions.
46
47
I. Graphical Analysis
1.
Using long- and short-rotor helicopter descent times construct an appropriate display to
compare the flight times.
2.
Calculate appropriate summary statistics for each of the two sets of data.
3.
Using the graphical and numerical information, compare the shape, center, and spread of
the distributions including outliers and any other unusual features.
II. Inferential Statistics
1.
What is the population about which inference can be made?
2.
What is the appropriate inference procedure for comparing the mean descent times for
the two helicopters? (e.g.: paired t-test, two independent sample t-test, z-test, etc.)
3.
State and justify the assumptions necessary to apply this inference procedure.
4.
Construct a 95% confidence interval for the difference in the mean descent time for each
helicopter. Discuss and interpret the meaning of the confidence interval.
5.
Use an appropriate significance test to determine whether or not there is a difference in
the true mean descent times of the two helicopters.
6.
How do the results of the test of significance relate to the observations you made using
your confidence intervals?
48
Multiple Choice Practice
1.
2.
3.
49
Free Response Practice
2010 FR#1 – Bird Deterrent
50
Free Response Practice
1997 FR#2 – Fish Tanks
51
Free Response Practice
2008 FR#2 – School Board Survey
52
Anticipating Patterns
53
Topic III – Anticipating Patterns
Exploring random phenomena using probability and simulation (20%-30%)
Probability is the tool used for anticipating what the distribution of data should look like under a given
model.
A. Probability
1. Interpreting probability, including long-run relative frequency interpretation
2. “Law of Large Numbers” concept
3. Addition rule, multiplication rule, conditional probability, and independence
4. Discrete random variables and their probability distributions, including binomial
and geometric
5. Simulation of random behavior and probability distributions
6. Mean (expected value) and standard deviation of a random variable and linear
transformation of a random variable
B. Combining independent random variables
1. Notion of independence versus dependence
2. Mean and standard deviation for sums and differences of independent random
variables
C. The normal distribution
1. Properties of the normal distribution
2. Using tables of the normal distribution
3. The normal distribution as a model for measurements
D. Sampling distributions
1. Sampling distribution of a sample proportion
2. Sampling distribution of a sample mean
3. Central Limit Theorem
4. Sampling distribution of a difference between two independent sample proportions
5. Sampling distribution of a difference between two independent sample means
6. Simulation of sampling distributions
7. t-distribution
8. Chi-square distribution
54
Why Do We Really Buy Cereal?
1. Inside each box of Rice Krispies is a toy guitar and there are six
colors of guitars available. 2nd-Grader Emma Grace really
needs to get the red one. How many boxes does Emma Grace’s
Grampa have to buy in order for Emma Grace to get her wish?
2. Assuming Kelloggs is not trying to horde any specific color (we'll
assume they are randomly distributed), we may simulate this
situation by randomly generating six colors.
3. Assign each color an integer from one to six. (Let's say red is
four.)
4. Using a die, a random number table, or the TI-84, simulate this
situation by generating random integers from one to six. When you get a four, circle it.
5. On the average, how many boxes did it take to get the red one?
6. Now Emma Grace has decided what she really needs is to get the all the guitars. How
many boxes does Emma Grace's Grampa have to buy in order for Emma Grace to get her
latest wish?
55
Weird Dice
1999 AP Statistics FR#5
Die A has four 9’s and two 0’s on its faces. Die B has four 3’s and two 11’s on its faces. When
either of these dice is rolled, each face has an equal chance of landing on top. Two players are
going to play a game. The first player selects a die and rolls it. The second player rolls the
remaining die. The winner is the player whose die has the higher number on top.
Suppose you are the first player and you want to win the game. Which die would you select?
Justify your answer.
Simulate the game by creating and rolling the “Weird” dice.
Winner
Die A
Die B
Tally
Simulation with the TI-83+
Die A will be stored in L1
{0,0,9,9,9,9} L1
Die B will be stored in L2
{3,3,3,3,11,11} L2
Roll Die A (select a random value from L1
L1(randInt(1,6))
The result will be a random value from L1, either 0 or 9.
Roll Die B (select a random value from L2)
L2(randInt(1,6))
The result will be a random value from L2, either 3 or 11.
Compare Die A with Die (Does Die A beat Die B?)
L1(randInt(1,6)) > L2(randInt(1,6))
The result will be true (1) or false (0).
Simulate the comparison n (use 100 as an example) times.
seq(L1(randInt(1,6)) > L2(randInt(1,6)), X, 1, 100, 1)
The result will be a list of 100 1’s and 0’s representing A beating B and B beating
A.
Determine the number of times Die A beats Die B.
sum(seq(L1(randInt(1,6)) > L2(randInt(1,6)), X, 1, 100, 1))
The result will be the number of times Die A beats Die B.
Determine the probability of Die A beating Die B.
sum(seq(L1(randInt(1,6)) > L2(randInt(1,6)), X, 1, 100, 1))/100
56
Law of Large Numbers
Flip a thumbtack 25 times. Record the results in the following table. (Tip Up – 1, Tip Down – 0)
Trial Number
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Tip Up [1] , Tip Down [0]
Using your calculator:
Assign the flip numbers to List1.
Record your results in List 2. (Enter the data)
Assign the cumulative sum in List3.
Assign the probability in List4.
Make a lineplot of (trial number, probability).
seq( X , X ,1, 25,1) L1
cumSum( L2 ) L3
L3 / L1 L4
57
The Central Limit Theorem
Store 0 in rand
0 rand
[This seeds the random number generator and allows everyone to have the same population.]
Create a population.
Determine the characteristics of your population.
Center - Mean
Shape (Histogram)
Spread – Standard Deviation
Run PGRM CLT
o Population is in L1
o Number of Samples is ___________.
o Sample Size is ___________.
o Your population is stored in LPOP, samples are temporarily stored in LTEMP, and
sample means x are stored in LXBAR.
Determine the characteristics of your sample means.
Shape (Histogram)
Center - Mean x
Spread – Standard Deviation x
Is there a relationship between the characteristics of the population and the
characteristics of the sample?
Determine the characteristics of x .
o
Add your x in the row corresponding to your sample size.
Sample Size (n)
o
o
o
Standard Deviation of Sample Means x
Draw a scatterplot of n, x .
What relationship seems to exist?
What type of transformation will make this relationship linear?
58
Multiple Choice Practice
1.
2.
59
3.
4.
5.
60
Shirt Sizes
2003 AP STATISTICS FR QUESTION #3
Men’s shirt sizes are determined by their neck sizes. Suppose that men’s neck sizes are
approximately normally distributed with mean 15.7 inches and standard deviation 0.7 inch. A
retailer sells men’s shirts in sizes S. M, L, XL, where the shirt sizes are defined in the table below.
Shirt Size
Neck Size
S
14 neck size 15
M
15 neck size 16
L
16 neck size 17
XL
17 neck size 18
(a) Because the retailer only stocks the sizes listed above, what proportion of customers will find
that the retailer does not carry any shirts in their sizes?
(b) Find the proportion of men whose shirt size is M.
(c) Of 12 randomly selected customers, what is the probability that exactly 4 will request size M?
61
Skunk Spinner
2003 AP STATISTICS FR #5 (B)
100
200
500
Contestants on a game show spin a wheel like the one shown in the figure above. Each of the
four outcomes on this wheel is equally likely and outcomes are independent from one spin to the
next.
• The contestant spins the wheel.
• If the result is a skunk, no money is won and the contestant’s turn is finished.
• If the result is a number, the corresponding amount in dollars is won. The contestant can then
stop with those winnings or can choose to spin again, and his or her turn continues.
• If the contestant spins again and the result is a skunk, all of the money earned on that turn is
lost and the turn ends.
• The contestant may continue adding to his or her winnings until he or she chooses to stop or
until a spin results in a skunk.
(a) What is the probability that the result will be a number on all of the first three spins of the
wheel?
(b) Suppose a contestant has earned S800 on his or her first three spins and chooses to spin the
wheel again. What is the expected value of his or her total winnings for the four spins?
(c) A contestant who lost at this game alleges that the wheel is not fair. In order to check on the
fairness of the wheel, the data in the table below were collected for 100 spins of this wheel.
Result
Skunk
$100
$200
$300
Frequency
33
21
20
26
Based on these data, can you conclude that the four outcomes on this wheel are not equally
likely? Give appropriate statistical evidence to support your answer.
62
Free Response Practice
2012 FR#2 – Spin The Pointer
2. A charity fundraiser has a Spin the Pointer game that uses a spinner like the one illustrated in
the figure below.
A donation of $2 is required to play the game. For each $2 donation, a player spins the pointer
once and receives the amount of money indicated in the sector where the pointer lands on the
wheel. The spinner has an equal probability of landing in each of the 10 sectors.
(a) Let X represent the net contribution to the charity when one person plays the game once.
Complete the table for the probability distribution of X.
x
$2
$1
-$8
P( x)
(b) What is the expected value of the net contribution to the charity for one play of the game?
(c) The charity would like to receive a net contribution of $500 from this game. What is the
fewest number of times the game must be played for the expected value of the net contribution
to be at least $500?
(d) Based on last year’s event, the charity anticipates that the Spin the Pointer game will be played
1,000 times.
The charity would like to know the probability of obtaining a net contribution of at least $500 in
1,000 plays of the game. The mean and standard deviation of the net contribution to the charity
in 1,000 plays of the game are $700 and $92.79, respectively. Use the normal distribution to
approximate the probability that the
charity would obtain a net contribution of at least $500 in 1,000 plays of the game.
63
Free Response Practice
2010 FR#2 – Radio Station Programming
A local radio station plays 40 rock-and-roll songs during each 4-hour show. The program
director at the station needs to know the total amount of airtime for the 40 songs so that time
can also be programmed during the show for news and advertisements. The distribution of the
lengths of rock-and-roll songs, in minutes, is roughly symmetric with a mean of 3.9 minutes and a
standard deviation of 1.1 minutes.
(a) Describe the sampling distribution of the sample mean song lengths for random samples of 40
rock-and-roll songs.
(b) If the program manager schedules 80 minutes of news and advertisements for the 4-hour
(240-minute) show, only 160 minutes are available for music. Approximately what is the
probability that the total amount of time needed to play 40 randomly selected rock-and-roll
songs exceeds the available airtime?
64
Free Response Practice
1998 FR#6 – Pearls
The manager of a cultured pearl farm has received a special order for two pearls between 7
millimeters and 9 millimeters in diameter. From past experience, the manager knows that the
pearls found in his oyster bed have diameters that are normally distributed with a mean of 8
millimeters and a standard deviation of 2 millimeters. Assume that every oyster contains one
pearl.
The manager wants to know how many oysters he should expect to open to find two pearls of
the appropriate size for this special order. Complete the following parts to design a simulation to
answer the manager’s question.
(a) Determine the probability of finding a pearl of the appropriate size in an oyster selected at
random. (Express this probability as a number between 0 and 1. Round this probability to the
nearest tenth.)
(b) Describe how you would use a table of random digits to car out a simulation to deter mine
the number of oysters needed to find two pearls of the appropriate size. Include a description of
what each of the digits 0. 1. 2. 3. 4. 5. 6. 7. 8. and 9 will represent in your simulation.
(c) Perform your simulation 3 times. (That is, run 3 trials of you simulation.) Start at the upper
left most digit in the first row of the table and move across. Make your procedure clear so that
someone can follow what you did. You must do this by marking directly on or above the table.
48747
51269
58249
22684
77576
97842
76595
87073
80993
02409
74872
48327
32588
73694
52010
37565
57431
37976
38392
97751
88856
52457
29251
81333
84422
17857
23882
01257
77848
10264
80016
52352
73613
40615
98037
37890
21392
57648
63910
81230
71950
22930
47051
09596
38561
22494
43776
63016
10241
69580
00369
10503
73572
03413
06181
65
(d) The results of two 100-trial simulations, one searching for two pearls between 7 millimeters
and 9 millimeters and the other searching for two pearls between 4 millimeters and 6.5
millimeters are shown below.
Identify which distribution, A or B, represents the search for two 7 millimeter to 9 millimeter
pearls. Explain your reasoning.
(e) Use the appropriate distribution in part (d) to compute an estimate of the expected number
of oysters opened to find two pearls between 7 millimeters and 9 millimeters in diameter.
66
Statistical Inference
67
Topic IV – Statistical Inference
Estimating population parameters and testing hypotheses (30%-40%)
Statistical inference guides the selection of appropriate models.
A. Estimation (point estimators and confidence intervals)
1. Estimating population parameters and margins of error
2. Properties of point estimators, including unbiasedness and variability
3. Logic of confidence intervals, meaning of confidence level and intervals, and
properties of confidence intervals
4. Large sample confidence interval for a proportion
5. Large sample confidence interval for the difference between two proportions
6. Confidence interval for a mean
7. Confidence interval for the difference between two means (unpaired and paired)
8. Confidence interval for the slope of a least-squares regression line
B.
Tests of Significance
1. Logic of significance testing, null and alternative hypotheses; p-values; one- and
two-sided tests; concepts of Type I and Type II errors; concept of power
2. Large sample test for a proportion
3. Large sample test for a difference between two proportions
4. Test for a mean
5. Test for a difference between two means (unpaired and paired)
6. Chi-square test for goodness of fit, homogeneity of proportions, and independence
(one- and two-way tables)
7. Test for the slope of a least-squares regression line
68
What Percentage of the Earth’s Surface is Water?
Make a small dot on your thumb.
Toss the globe beach ball from person to person,
determining whether your dot was in water or land.
Null Hypothesis:
Alternative Hypothesis:
Test Statistic:
Conditions:
Decision Rule:
Sample Data:
Water
Land
69
Female Mathematicians
A company has 11 mathematicians on its staff, 3 of whom are women. The president of the
company is concerned about the small number of women mathematicians. The president learns
that about 40 percent of the mathematicians in the United States are women, and asks you to
investigate whether or not the number of women mathematicians in the company is consistent
with the national pool.
70
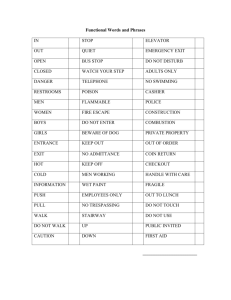
"ALL ANIMALS ARE EQUAL, BUT SOME ANIMALS ARE MORE
EQUAL THAN OTHERS."
Statistical Inference with Barnum’s Animal Crackers
Questions:
How many types of animals are there?
How many animals are in a box?
Null Hypothesis:
Alternative Hypothesis:
Test Statistic:
Conditions:
71
Inference With Animal Crackers
Animal
Number
Bear (on all fours)
Bear (standing)
Bison
Camel
Cougar
Elephant
Giraffe
Gorilla
Hippopotamus
Hyena
Kangaroo
Koala
Lion
Monkey
Rhinoceros
Seal
Sheep
Tiger
Zebra
72
Inference with Animal Crackers
Bear (on Bear
all fours) (standing)
Bison Camel
Cougar Elephant Giraffe Gorilla Hippo Hyena Kangaroo Koala
Lion
Monkey Rhino Seal
Sheep Tiger
Zebra
73
Distracted Driving
Are drivers more distracted when using a cell phone than when talking to a passenger in the car?
Researchers wanted to find out, so they designed an experiment. Here are the details.
In a study involving 48 people, 24 people were randomly assigned to drive in a driving simulator while using a cell
phone. The remaining 24 were assigned to drive in the driving simulator while talking to a passenger in the
simulator. Part of the driving simulation for both groups involved asking drivers to exit the freeway at a particular
exit. In the study, 7 of the 24 cell phone users missed the exit, while 2 of the 24 talking to a passenger missed the
exit. (from the 2007 AP* Statistics exam, question 5)
Let’s start by summarizing the data from this study. Each of the 48 people in the experiment can
be classified into one of the four cells in the table below based on the experimental condition to
which they were assigned and whether they missed the designated exit. Use information from the
previous paragraph to complete the table.
Distraction
Cell phone
Passenger
Yes
No
Missed
exit?
To analyze data, we begin by making one or more graphs.
Which is more distracting?
Which is more distracting?
100%
25
80%
Percent
Frequency
20
15
10
5
60%
40%
20%
0
0%
Cell phone
Passenger
Type of Distraction
Missed exit
Cell phone
Didn't miss exit
Passenger
Type of distraction
Missed exit
Didn't miss exit
Two types of Excel bar graphs are shown above. Explain the difference in what the two graphs
display. Then tell which one you prefer and why.
Next, we add numerical summaries. We might be interested in comparing the counts, percents, or
proportions of people in the two groups who missed the freeway exit.
Fill in the missing entries in the table below for the passenger group.
Cell phone
group
Passenger
group
Number
Missed exit
Proportion
Percent
7
0.292
29.2
In the distracted driving experiment, 29.2% of the 24 drivers talking on cell phones missed the freeway
exit, compared with only 8.3% of the 24 drivers who were talking to passengers. This seems like a pretty
large difference—almost 21% higher for the drivers who used cell phones. Researchers might be tempted
to conclude that the different experimental conditions—talking on a cell phone and talking to a
74
passenger—actually caused the observed difference in the percent of drivers who missed the freeway exit.
There is another possibility, however.
Suppose that the two experimental conditions—talking on a cell phone and talking to a passenger—
actually have the same effect on drivers’ distraction. In that case, the 9 people in this experiment who
missed the freeway exit would have done so no matter which group they were assigned to. Likewise, the
39 people who did not miss the exit would have had the same result whether they talked on a cell phone
or to a passenger. This leads us to the other possibility: if the two experimental conditions actually have
the same effect on drivers’ distraction, then the difference in the percents that missed the exit in the two
groups could simply have been due to chance. That is, the difference could be a result of which 24 people
just happened to be assigned to each group. In the next activity, you will examine whether this second
possibility seems plausible.
Activity: Could the observed difference be due to the chance assignment of people to
groups?
Materials: Standard deck of playing cards for each group of 3-4 students
What would happen if we reassigned the 48 people in this experiment to the cell phone and passenger
groups many times, assuming that the group assignment had no effect on whether each driver missed the
exit? Let’s try it and see.
1. Get a standard deck of playing cards from your teacher. Make sure that your deck has 52 cards, not
including jokers.
2. We need 48 cards to represent the 48 drivers in this study. In the original experiment, 9 people missed
the exit and 39 people didn’t miss the exit. If the group assignment had no effect on drivers’ distraction,
these results wouldn’t change if we reassigned 24 people to each group at random. For a physical
simulation of these reassignments, we need 9 cards to represent the people who will miss the exit and 39
cards to represent the people who won’t miss the exit. With your group members, discuss which cards
should represent which outcomes. When you have settled on a plan, designate one member of your
group to share your plan with the class.
3. After each group presents its plan, the class as a whole will decide which plan to use. Record the
details here.
4. Now you’re ready to simulate the process of reassigning people to groups. “Shuffle up and deal” two
piles of 24 cards—the first pile representing the cell phone group and the second pile representing the
passenger group. Record the number of drivers who missed the exit in each group.
5. Repeat this process 9 more times so that you have a total of 10 trials. Record your results in the table
provided.
Trial
Number who missed exit
in cell phone group
Number who missed exit
in passenger group
1
2
3
4
5
6
7
8
9
10
75
In the original experiment, 7 of the 24 drivers using cell phones missed the freeway exit, compared to only
2 of the 24 drivers who were talking to a passenger. How surprising would it be to get a difference this
large or larger simply due to chance if the effects of the two experimental conditions on drivers’
distraction were actually the same? You can estimate the chance of this happening with the results of
your simulation.
6. In how many of your 10 simulation trials did 7 or more drivers in the cell phone group miss the exit?
Why don’t you need to consider the number of people in the “talking to a passenger group” who missed
the exit?
7. Combine results with your classmates. In what percent of the class’s simulation trials did 7 or more
people in the cell phone group miss the freeway exit?
8. Based on the class’s simulation results, do you think it’s possible that cell phones and passengers are
equally distracting to drivers, and that the difference observed in the original experiment could have been
due to the chance assignment of people to the two groups? Why or why not?
Here are the results of 1000 trials of a computer simulation, like the one you did with the playing cards,
showing the number of drivers who missed the exit in the cell phone group.
9. In the computer simulation, how often did 7 or more drivers in the cell phone group miss the exit when
there is no difference in the effects of the experimental conditions? Do you think the results of the
original experiment could be due to chance and not to a difference in the effects of cell phone use and
talking to a passenger on driver distraction? Explain your reasoning.
76
Inference and Hypothesis Testing
Decision
Fail to Reject H0
Reject H0
H0 True
The Truth
H0 False
77
M & M Statistics
Is the Color Distribution of M&Ms homogenous across different types?
Color
Brown Yellow Red Blue Orange Green
Type
Milk Chocolate
Peanut
Peanut Butter
Null Hypothesis:
Alternative Hypothesis:
Test Statistic:
Conditions:
Decision Rule:
78
Multiple Choice Practice
1.
2.
79
3.
4.
5.
80
Free Response Practice
2012 FR#4 – Television Commercials
A survey organization conducted telephone interviews in December 2008 in which 1,009
randomly selected adults in the United States responded to the following question.
At the present time, do you think television commercials are an effective way to promote a new
product?
Of the 1,009 adults surveyed, 676 responded “yes.” In December 2007, 622 of 1,020 randomly
selected adults in the United States had responded “yes” to the same question. Do the data
provide convincing evidence that the proportion of adults in the United States who would
respond “yes” to the question changed from December 2007 to December 2008?
2010 FR#5 – Fish Lengths
81
Free Response Practice
2009 FR#5 – Heart Attack Response
82
Free Response Practice
2006B FR#4 – Manual Dexterity
83
Free Response Practice
2006B FR#6 – Manual Dexterity
84
85
Free Response Practice
2010 FR#6 – Hurricane Damage
86
87
88