Correlation and SLR
advertisement

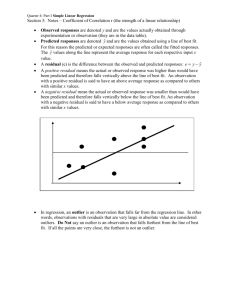
Correlation ◦ The linear association between two variables Strength of relationship based on how tightly points in an X,Y scatterplot cluster about a straight line ◦ -1 to 1unitless ◦ Observations should be quantitative No categorical variables even if recoded evaluate a visual scatterplot Independent samples Correlation does not imply causality Do not assume infinite ranges of linearity Ho: there is no linear relationship between the 2 variables Ha: there is a linear relationship between the 2 variables Simple Linear Regression ◦ Examine relationship between one predictor variable (independent) and a single quantitative response variable (dependent) ◦ Produces regression equation used for prediction ◦ Normality, equal variances, independence ◦ Least Squares Principle Do not extrapolate Analyze residuals Ho: there is no slope, no linear relationship between the 2 variables Ha: there is a slope, linear relationship between the 2 variables Positive correlation: Indicates that the values on the two variables being analyzed move in the same direction. That is, as scores on one variable go up, scores on the other variable go up as well (on average) & vice versa Negative correlation: Indicates that the values on the two variables being analyzed move in opposite directions. That is, as scores on one variable go up, scores on the other variable go down, and viceversa (on average) Correlation coefficients range in strength from -1.00 to +1.00 The closer the correlation coefficient is to either -1.00 or + 1.00, the stronger the relationship is between the two variables Perfect positive correlation of +1.00 reveals that for every member of the sample or population, a higher score on one variable is related to higher score on the other variable Perfect negative correlation of –1.00 indicates that for every member of the sample or population, a higher score on one variable is related to a lower score on the other variable Perfect correlations are never found in actual social science research Positive and negative correlations are represented by scattergrams Scattergrams: Graphs that indicate the scores of each case in a sample simultaneously on two variables r: the symbol for the sample Pearson correlation coefficient Positive Correlation 100 90 80 70 60 50 40 30 20 10 0 Score on Exam Score on Exam Negative Correlation 1 6 Hours Spent Studying 11 100 90 80 70 60 50 40 30 20 10 0 1 6 11 Hours Spent Studying The scattergrams presented here represent very strong positive and negative correlations (r = 0.97 and r = -0.97 for the positive and negative correlations, respectively) No Correlation Between Hours Spent Studying and Exam Scores 100 90 Scores on Exam 80 70 60 50 40 30 20 10 0 0 2 4 6 8 10 12 Hours Spent Studying Scattergram representing virtually no correlation between the number of hours spent studying and the scores on the exam is presented No discernable pattern between the scores on the two variables We learn it is virtually impossible to predict an individual’s test score simply by knowing how many hours the person studied for the exam The first step in understanding how Pearson correlation coefficients are calculated is to notice that we are concerned with a sample’s scores on two variables at the same time The data shown are scores on two variables: hours spent studying and exam score. These data are for a randomly selected sample of five students. To be used in a correlation analysis, it is critical that the scores on the two variables are paired. Data for Correlation Coefficient Hours Spent Studying (X variable) Exam Score (Y variable) Student 1 5 80 Student 2 6 85 Student 3 7 70 Student 4 8 90 Student 5 9 85 Each student’s score on the X variable must be matched with his or her own score on the Y variable Once this is done a person can determine whether, on average, hours spent studying is related to exam scores Definitional Formula for Pearson Correlation Finding the Pearson correlation coefficient is simple when following these steps: 1. 2. r Find the z scores on each of the two variables being examined for each case in the sample z Multiply each individual's z score on one variable with that individual's z score on the second variable (i.e., find a cross-product) 3. Sum those across all of the individuals in the sample 4. Divide by N Pearson product-moment correlation coefficient x a z score for variable X zy a paired z score for variable Y N the number of pairs of X and Y scores r = Σ(zx zy) Ν You then have an average standardized cross product. If we had not standardized these scores we would have produced a covariance. This formula requires that you standardize your variables • Note: When you standardize a variable, you are simply subtracting the mean from each score in your sample and dividing by the standard deviation What this does is provide a z score for each case in the sample Members of the sample with scores below the mean will have negative z scores, whereas those members of the sample with scores above the mean will have positive z scores Correlation coefficients such as the Pearson are very powerful statistics. They allow us to determine whether, on average, the values on one variable are associated with the values on a second variable People often confuse the concepts of correlation and causation • Correlation (co-relation) simply means that variation in the scores on one variable correspond with variation in the scores on a second variable • Causation means that variation in the scores on one variable cause or create variation in the scores on a second variable. Correlation does not equal causation. Simple Pearson correlations are designed to examine linear relations among variables. In other words, they describe average straight relations among variables Not all relations between variables are linear As previously mentioned, people often confuse the concepts of correlation and causation Example: There is a curvilinear relationship between anxiety and performance on a number of academic and non-academic behaviors as shown in the figure below • We call this a curvilinear relationship because what began as a positive relationship (between performance and anxiety) at lower levels of anxiety, becomes a negative relationship at higher levels of anxiety 70 60 50 Performance 40 30 20 10 0 1 2 3 Anxiety 4 5 The problem of truncated range is another common problem that arises when examining correlation coefficients. This problem is encountered when the scores on one or both of the variables in the analysis do not have much variance in the distribution of scores, possibly due to a ceiling or floor effect The data from the table at right show all of the students did well on the test, whether they spend many hours studying for it or not • The weak correlation that will be produced by the data in the table may not reflect the true relationship between how much students study and how much they learn because the test was too easy. A ceiling effect may have occurred, thereby truncating the range of scores on the exam Data for Studying-Exam Score Correlation Hours Spent Studying (X variable) Exam Score (Y variable) Student 1 0 95 Student 2 2 95 Student 3 4 100 Student 4 7 95 Student 5 10 100 Researchers test whether the correlation coefficient is statistically significant To test whether a correlation coefficient is statistically significant, the researcher begins with the null hypothesis that there is absolutely no relationship between the two variables in the population, or that the correlation coefficient in the population equals zero The alternative hypothesis is that there is, in fact, a statistical relationship between the two variables in the population, and that the population correlation coefficient is not equal to zero. So what we are testing here is whether our correlation coefficient is statistically significantly different from 0 What we want to be able to do with a measure of association, like a correlation coefficient, is be able to explain some of the variance in the scores on one variable with the scores on a second variable. The coefficient of determination tells us how much of the variance in the scores of one variable can be understood, or explained, by the scores on a second variable One way to conceptualize explained variance is to understand that when two variables are correlated with each other, they share a certain percentage of their variance See next slide for visual In this picture, the two squares are not touching each other, suggesting that all of the variance in each variable is independent of the other variable. There is no overlap The precise percentage of shared, or explained, variance can be determined by squaring the correlation coefficient. This squared correlation coefficient is known as the coefficient of determination r = 0.00 r² = 0.00 r = 0.30 r² = 0.09 r = 0.55 r² = 0.30 All of these statistics are very similar to the Pearson correlation and each produces a correlation coefficient that is similar to the Pearson r Phi: Sometimes researchers want to know whether two dichotomous variables are correlated. In this case, we would calculate a phi coefficient (F), which is specialized version of the Pearson r For example, suppose you wanted to know whether gender (male, female) was associated with whether one smokes cigarettes or not (smoker, non smoker) • In this case, with two dichotomous variables, you would calculate a phi coefficient • Note: Readers familiar with chi-square analysis will notice that two dichotomous variables can also be analyzed using chi square test (see Chapter 14) Point Biserial: When one of our variables is a continuous variable (i.e., measured on an interval or ratio scale) and the other is a dichotomous variable we need to calculate a point-biserial correlation coefficient This coefficient is a specialized version of the Pearson correlation coefficient For example, suppose you wanted to know whether there is a relationship between whether a person owns a car (yes or no) and their score on a written test of traffic rule knowledge, such as the tests one must pass to get a driver’s license • In this example, we are examining the relation between one categorical variable with two categories (whether one owns a car) and one continuous variable (one’s score on the driver’s test) • Therefore, the point-biserial correlation is the appropriate statistic in this instance Spearman Rho: Sometimes data are recorded as ranks. Because ranks are a form of ordinal data, and the other correlation coefficients discussed so far involve either continuous (interval, ratio) or dichotomous variables, we need a different type of statistic to calculate the correlation between two variables that use ranked data The Spearman rho is a specialized form of the Pearson r that is appropriate for such data For example, many schools use students’ grade point averages (a continuous scale) to rank students (an ordinal scale) • In addition, students’ scores on standardized achievement tests can be ranked • To see whether a students’ rank in their school is related to their rank on the standardized test, a Spearman rho coefficient can be calculated. The correlations on the diagonal show the correlation between a single variable and itself. Because we always get a correlation of 1.00 when we correlate a variable with itself, these correlations presented on the diagonal are meaningless. That is why there is not a p value reported for them The numbers in the parentheses, just below the correlation coefficients, report the sample size. There were 314 eleventh grade students in this sample From the correlation coefficient that is off the diagonal, we can see that students’ grade point average (Grade) was moderately correlated with their scores on the test (r = 0.4291). This correlation is statistically significant, with a p value of less than 0.0001 (p < 0.0001) SPSS Printout of Correlation Analysis Grade Grade Test Score 1.0000 ( 314) P= . Test Score 0.4291 1.0000 ( 314) ( 314) P = 0.000 P= . To gain a clearer understanding of the relationship between grade and test scores, we can calculate a coefficient of determination. We do this by squaring the correlation coefficient. When we square this correlation coefficient (0.4291 * 0.4291 = 0.1841), we see that grades explains a little bit more than 18% of the variance in the test scores Because of 80% percentage of unexplained variance, we must conclude that teacherassigned grades reflect something substantially different from, and more than, just scores on tests. SPSS Printout of Correlation Analysis Grades Grades Test score 1.0000 ( 314) P= . Test score 0.4291 1.0000 ( 314) ( 314) P = 0.000 P= . Same table as in previous slide Allows researchers to examine: • How variables are related to each other • The strength of the relations • Relative predictive power of several independent variables on a dependent variable • The unique contribution of one or more independent variables when controlling for one or more covariates Simple Regression • Simple regression analysis involves a single independent, or predictor variable and a single dependent, or outcome variable Multiple Regression • Multiple regression involves models that have two or more predictor variables and a single dependent variable The dependent and independent variables need to be measured on an interval or ratio scale Dichotomous (i.e., categorical variables with two categories) predictor variables can also be used • There is a special form of regression analysis, logit regression, that allows us to examine dichotomous dependent variables Regression analysis yields more information The regression equation allows us to think about the relation between the two variables of interest in a more intuitive way, using the original scales of measurement rather than converting to standardized scores Regression analysis yields a formula for calculating the predicted value of one variable when we know the actual value of the second variable Assumes the two variables are linearly related • In other words, if the two variables are actually related to each other, we assume that every time there is an increase of a given size in value on the X variable (called the predictor or independent variable), there is a corresponding increase (if there is a positive correlation) or decrease (if there is a negative correlation) of a specific size in the Y variable (called the dependent, or outcome, or criterion variable) Ŷ = bX + a Ŷ is the predicted value of the Y variable b is the unstandardized regression coefficient, or the slope a is the intercept (i.e., the point where the regression line intercepts the Y axis. This is also the predicted value of Y when X is zero) Is there a relationship between the amount of education people have and their monthly income? Education Level (X) in years Monthly Income (Y) in thousands Case 1 6 $1 Case 2 8 $1.5 Case 3 11 $1 Case 4 12 $2 Case 5 12 $4 Case 6 13 $2.5 Case 7 14 $5 Case 8 16 $6 Case 9 16 $10 Case 10 21 $8 Mean 12.9 $4.1 Standard Deviation 4.25 $3.12 Correlation Coefficient 0.83 Scatterplot for education and income: 12 11 9 10 9 10 8 7 8 6 I n c o m e 7 5 4 5 3 2 1 4 2 With the data provided in the table, we can calculate a regression. The regression equation allows us to do two things: 1) find predicted values for the Y variable for any given value of the X variable 2) produce the regression line 6 3 1 0 -1 -2 -3 -4 0 2 4 6 8 10 12 Education (in years) 14 16 18 20 22 The regression line is the basis for linear regression and can help us understand how regression works OLS is the most commonly used regression formula It is based on an idea that we have seen before: the sum of squares To do OLS: find the line of least squares (i.e., the straight line that produces the smallest sum of squared deviations from the line) Sum of Squares: Σ (observed value – predicted value)2 b r* sy sx b is the regression coefficient r is the correlation between the X and Y variables sy is the standard deviation of the Y variable sx is the standard deviation of the X variable a Y bX Y is the average value of Y X is the average value of X b is the regression coefficient The regression equation does not calculate the actual value of Y. It can only make predictions about the value of Y. So error (e) is bound to occur. e = Y - Ŷ • Error is the difference between the actual, or observed, value of Y and the predicted value of Y OR To calculate error, use one of two equations: e = Y - a + bX Y Ŷ is the actual, or observed value of Y is the predicted value of Y For the predicted value of Y: Ŷ = bX + a For the actual / observed value of Y; takes into account error (e): Y = bX + a + e Example: Is there a relationship between the amount of education people have and their monthly income? Ŷ = -3.77 + .61X For every unit of increase in X, there is a corresponding predicted increase of 0.61 units in Y OR For every additional year of education, we would predict an increase of 0.61 ($1,000), or $610, in monthly income Example: What would we predict the monthly income to be for a person with 9 years of formal education? Yˆ Yˆ Yˆ = -3.77 + .61(9) = -3.77 + 5.59 = 1.82 So we would predict that a person with 9 years of education would make $1,820 per month, plus or minus our error in prediction (e) Drawing the Regression Line To do this we need to calculate two points Yˆ Yˆ Yˆ Yˆ Yˆ Yˆ = -3.77 + .61(9) = -3.77 + 5.59 = 1.82 = -3.77 + .61(25) = -3.77 + 15.25 = 11.48 12 11 9 10 9 10 8 I n c o m e 7 8 6 7 5 5 4 3 2 1 4 2 6 3 1 0 -1 -2 -3 -4 0 2 4 6 8 10 12 Education 14 16 18 20 22 The regression line does not always accurately predict the actual Y values In some cases there is a little error, and in other cases there is a larger error • Residuals = errors in prediction In some cases, our predicted value is greater than our observed value. • Overpredicted = observed values of Y at given values of X that are below the predicted values of Y. Produces negative residuals. Sometimes our predicted value is less than our observed value • Underpredicted = observed values of Y at given values of X that are above the predicted values of Y. Produces positive residuals.