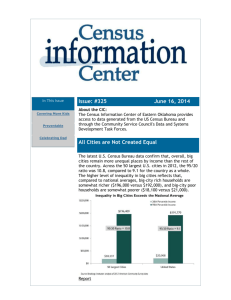
XI. Results from Prior NSF Research
advertisement

6347895 Project Summary Broader Impact: Census Research Data Centers (RDCs), based in Ann Arbor, Berkeley, Boston, Chicago, Durham, Ithaca, Los Angeles, New York City, and Washington provide approved scientists with access to confidential Census data for research that directly benefits both the Census Bureau and society. The RDC directors, administrators, board members and researchers, together with the Center for Economic Studies and the Longitudinal Employer-Household Dynamics (LEHD) Program, constitute a collaborative research network that is building and supporting a secure distributed computer network that enables research that is critical to our economic and civic prosperity and security (dmc). The network operates under physical security constraints dictated by Census and the Internal Revenue Service. The constraints essentially eliminate the possibility of distributing the computations to facilities outside of the Bureau’s main computing facility. Instead, the researchers use the RDCs as supervised remote access facilities that provide a secure, encrypted connection to the RDC computing network (int). The research conducted in RDCs and at LEHD over the past decade has made important contributions to our understanding of essential social, economic, and environmental issues that would not have been possible without use of the confidential data accessible via the RDC network. It is difficult to overstate the significance of this research, which has used more than 30 years of longitudinally integrated establishment micro-data from the Census Business Register and Economic Censuses; confidential micro-data from all the major Census surveys (Current Population Survey, Survey of Income and Program Participation, American Housing Survey), confidential micro-data from the Decennial Censuses of Population in 1990 and 2000; longitudinally integrated Unemployment Insurance wage records, ES-202 establishment data, and Social Security Administration data; federal tax information linked to major surveys; environmental data on air quality linked to Business Register and Economic Census data; Medicaid data linked to the Survey of Income and Program Participation; and many others (dmc). Intellectual Merit for the National Priority Area of Economic Prosperity and Vibrant Civil Society: We propose to address the technical and logistical issues raised by the creation, maintenance, and growth of the RDC network while maintaining the confidentiality guaranteed to participants in Census data. Over the next four years, we expect that the RDCs and LEHD will lead a new wave of research with the development of innovative, large-scale linked data products that integrate Census Bureau surveys, censuses and administrative records with data from state governments and surveys conducted by private institutions. Both CES and LEHD have extensive experience in creating these products. The RDC network researchers will enhance that experience and contribute their own expertise to the data linking research. The newly created data will be richer than any presently available to researchers with no increase in respondent burden. They will also raise complicated and vexing issues regarding disclosure avoidance and participant privacy (dmc). Intellectual Merit for the National Priority Area of Advances in Science and Engineering: The second part of our proposal, the creation of synthetic versions of these confidential data sets, will increase the accessibility of these data to social science researchers while preserving the confidentiality of private information. Synthetic and partially-synthetic data are new confidentiality protection techniques that rely on computationally intensive sampling from the posterior predictive distribution of the underlying confidential data. The result is micro-data that preserve important analytical properties of the original data and are, thus, inference-valid. The synthetic versions of confidential data are for public use. At the same time, ongoing research within the RDCs using the gold-standard confidential data will constantly test the quality of the synthesized data and allow for continuous improvement (int). As a result a continuous feedback relationship will be established between the research activities conducted in RDCs on confidential Census Bureau data and the quality of the Bureau’s public use data products—namely, the synthetic micro data created by these projects. In order to accomplish these computationally-intensive activities, as well as to allow researchers to engage in such innovative research as agent-based simulations and geo-spatial analysis, we will install a supercluster of SMP nodes optimized for the applications of creating linked data, analyzing the goldstandard data, and processing the data to produce multiply-synthesized public use data sets (int). Two industry partners, Intel and Unisys, have promised to directly support the creation of this supercluster by donating 256 Itanium 2 processors and providing the computing crossbars, cluster infrastructure, and disk storage arrays at manufacturer’s cost. The Linux-based system will be integrated and tuned by the proposal team from Argonne National Laboratories. The synthetic data specialists on the proposal team will port existing multi-threaded data synthesizers and develop new ones (int). 6347895 Project Description and Coordination Plan Page 1 I. Introduction Disciplines that rely on empirical validation require that appropriate resources be available to support rigorous, scientific, empirical research. Thanks to previous National Science Foundation investments, enormously rich new datasets on household and business-level data, previously collected by the federal government but unavailable to most researchers, have been created – and are becoming more broadly available to the scientific community. These data have already begun to open up new avenues of research, such as analysis of the geospatial characteristics of social activity and agent-based simulation and modeling. But the full return on investment will not be achieved until without solving two critical problems: first, providing access to these confidential and highly sensitive data, and second, providing sufficient computer resources to support such access, The solutions to these problems will not only bear immediate fruit to the social sciences in terms of increasing access to these new data– but will also bear future fruit in terms of providing access to other sensitive datasets in areas such as health care and biological research. Our proposal addresses these two challenges by creating a multi-layered confidentiality protection system that integrally links the Census Research Data Center network and the Bureau’s public use products. We propose to develop and enhance methods for creating new public-use products based on the idea of inference-valid synthetic data (Rubin 1993) and partially synthetic data (Abowd and Woodcock, 2001; Reiter 2003). Inference-valid synthetic data solves the confidentiality protection problem by replacing the confidential micro-data with draws from the posterior predictive distribution conditional on these micro-data. Thus, the synthetic data can preserve most of the distributional characteristics of the original data while dramatically reducing the risk of disclosure of confidential information on any individual or business in the original census, sample or administrative data. Since we will always use the term “synthetic data” in this sense, we do not always use the qualifier “inference-valid.” The distinction between synthetic and partially-synthetic data is elaborated below. The scientific research community has voiced legitimate concerns about the quality of synthetic data— especially empirical researchers familiar with the elaborate multivariate distributions embodied in a complicated integrated micro-data product. It is along this dimension that our proposal is truly unique and innovative. We propose that the creation and testing of the synthetic data be undertaken by that very research community in direct collaboration with the Census Bureau. To accomplish this ambitious mission, we rely upon the RDC-network and the LEHD Program to create and use gold-standard versions of the confidential Census micro-data in accordance with the existing access and approval protocols. These data would be available within the secure network of RDCs for approved projects. Researchers would, as a condition for working in the RDCs, directly assist in the testing of synthetic data by archiving the meta-data and results from their studies in the model database that the proposal would create within the RDC network. We recognize that the creation and testing of synthetic data places enormous computational demands on the RDC network. Our proposal addresses this second challenge of increased computational demands by proposing the installation of a supercluster computer to be designed, tested, and implemented by the proposal team in collaboration with critical industry partners. We will use the expertise of the Argonne National Laboratories and specialists within the LEHD Program and the RDC network to develop the appropriate parallel statistical computing environment, which will then be used by the RDC-based researchers and the data synthesizers. The feedback loop between the synthetic data and the models built on the gold-standard confidential data will permit creation of new public-use synthetic micro-data. The loop will also permit the continuous improvement of these synthetic data as new models are tested using the gold-standard confidential data and the current version of the synthetic data. II. Overview of the Role of the RDC-Network Social science research relies significantly, if not principally, on detailed micro-data collected from the primary agents of the economy and society: households and businesses. When these data are collected the agency that assumes custody of the data has a dual responsibility. On the one hand, it must facilitate the research that motivated the collection of the data. On the other hand, it normally has an ethical and legal obligation to protect the privacy and confidentiality of the respondents who provided the actual micro-data. The execution of this dual responsibility results in two distinct, but related, outcomes. The custodian develops public-use products from the data and, at the same time, enforces an access control protocol for the underlying confidential micro-data. Over the course of the twentieth century the United States Bureau of the Census became the leading custodian of American micro-data, primarily through its role as the collector of the Decennial Census of Population and Housing and the Economic Censuses (Office of Management and Budget, 2003). In the context of the Census Bureau, the dual responsibility cited above has concrete expressions. The Bureau publishes data in the form of a 6347895 Project Description and Coordination Plan Page 2 variety of public-use products ranging from printed reports to detailed micro-data. These are authorized by Chapters 3, 5, and 9 of Title 13 of the U.S. Code. The Bureau’s legal responsibilities to protect the confidentiality of the respondents are embodied in Chapter 1, Sub-chapter 1, Section 9, which prohibits: (1) the use of the information furnished under the provisions of this title for any purpose other than the statistical purposes for which it is supplied; or (2) making any publication whereby the data furnished by any particular establishment or individual under this title can be identified; or (3) permitting anyone other than the sworn officers and employees of the Department or bureau or agency thereof to examine the individual reports. Violation of these prohibitions can result in prison terms of up to five years and fines up to $250,000 for each offense. The prohibitions have been consistently interpreted by the Bureau and the courts to divide all of its data products into two mutually exclusive categories: (1) public-use products, which are published without copyright or any other restriction on how they may be used, and (2) confidential data products, which may only be used by sworn employees of the Bureau under the Bureau’s direct supervision. Section 24 of Chapter 1, Subchapter 2 makes provision for temporary employees who are granted what is now called “Special Sworn Status” and who may use the Bureau’s confidential data for work directly related to a statutorily authorized Census activity. The most direct consequence of the Census Bureau’s dual responsibility to publish statistics and to protect confidentiality is that the overwhelming bulk of the micro-data that it has collected over the course of the twentieth century remains confidential. All micro-data collected from businesses are confidential. Except for the one and five percent public-use micro samples, all micro-data from the Decennial Census of Population and Housing are confidential. The Bureau does produce public-use micro-data from its demographic survey programs, which are often conducted with another government agency. These include the Current Population Survey, the Survey of Income and Program Participation, the American Community Survey, and the Consumer Expenditure Survey. These survey-based public-use micro-data products are heavily used by statisticians, social scientists, health scientists, demographers, geographers, public policy researchers, and many others around the world (Duncan et al. 1993). There is widespread recognition that the Census Bureau’s confidential data represent a national asset of enormous value whose proper stewardship demands both scrupulous adherence to strict standards of confidentiality protection and vigorous efforts to ensure that the data are fully used by the American public (Duncan et al. 1993). The inherent tension between protecting the confidentiality of the underlying micro-data, as well as the privacy of the respondents, and providing extensive public-use products from those same data has led the Bureau to cultivate a direct relationship with the academic research community. This relationship is at the heart of the present research proposal. Academic researchers agree to undertake research projects that meet the Bureau’s statutory mission, as described in Title 13 and, in particular, Chapter 5. These researchers undertake their projects under the direct supervision of the Bureau, either at its headquarters or in a Research Data Center (RDC), formally acting as employees with Special Sworn Status (SSS). During their research the academics provide direct benefits to the Bureau in the form of new public-use data products and improvements to existing censuses and surveys. The Center for Economic Studies (CES) at the Census Bureau has welcomed academic researchers since 1981. Most of the original CES-based external researchers used confidential business micro-data. CES now operates an RDC at its offices in Upper Marlboro, MD. The first RDC located outside of the Bureau’s suburban DC headquarters was opened in Boston in 1994, funded in part by a grant from the National Science Foundation and now operated by the NBER in Cambridge, MA. The RDC network was expanded to include the Carnegie-Mellon RDC (opened in 1996; to close in 2004), the California Census RDC (opened in 1998 with sites in Berkeley and Los Angeles); the Research Triangle RDC (operated by Duke University, opened in 1999); the Michigan Census RDC (operated by the University of Michigan, opened in 2001); the Chicago Census RDC (operated by Northwestern University, opened in 2001); and the newest addition the New York Census RDC (with sites at Baruch College and Cornell University, to open in 2004). Except for the Carnegie Mellon RDC, all of these facilities were initially partially funded by the NSF. In addition to the RDCs, Census has operated the Longitudinal Employer-Household Dynamics Program in its Suitland, MD headquarters. This program has developed integrated household and business data products under the scientific direction of an academic research team and with significant NSF support from a social data infrastructure grant to Cornell University. The terms and conditions of academic research access to Census confidential micro-data have been refined over the last decade, since the opening of the Boston RDC. These terms provide the legal and technological constraints under which the access operates. Prior review of all projects and conduct of the research by SSS employees working in a Census supervised facility are the fundamental tenets of the RDC-based researcher access. 6347895 Project Description and Coordination Plan Page 3 Because the confidential micro-data under the Bureau’s stewardship come from a variety of sources and are often commingled in the underlying data files, the review and access protocols are subject to a variety of statutes— most notably Title 13 (discussed above), Title 26 (Internal Revenue Service), and Title 42 (Social Security Administration). Combining Census (Title 13) data with data from different administrative sources requires the cover of a “Memorandum of Understanding” (MOU) between the Census Bureau and the other statutory data custodian(s). Because of the commingling of Census (Title 13) and IRS (Title 26) data, particularly in the Bureau’s business micro-data, the MOUs and a general policy memo jointly issued by Census and IRS on September 15, 2000 mandate that the IRS be granted prior review authority for all projects that access commingled Federal Tax Information (FTI, Title 26 data) and Census (Title 13) data. This prior review ensures that the project meets the Census Bureau’s statutory mission, as delineated in Title 13, Chapter 5 and that the researcher’s access to the data is limited to the minimal amount of FTI necessary to undertake the project. In addition, the presence of commingled Title 26 data in the Bureau’s confidential data files mandates that all the IRS data security provisions (see IRS Publication 1075 and citations therein) be enforced in the RDCs. This latter requirement to a large degree dictates the physical characteristics of the RDC computing network and prohibits any meaningful distributed processing. The process for reviewing, approving, conducting, and certifying projects has evolved since the creation of the CES, the RDCs, and the LEHD Program. This evolution has been difficult and costly for the same reasons that there is a tension between the provision of data products and the protection of data confidentiality in the Bureau’s mission. A viable process has to be transparent: it must be evident to a disinterested third party how any researcher (internal or external) defines and conducts a research project using confidential Census data. More importantly, the process must stand up to public scrutiny by potentially hostile observers: there must be an auditable trail from application to certification that permits Census and the other statutory data custodians (e.g., IRS) to demonstrate that their stewardship has been lawful and prudent. Transparency and auditability require that the process be formal and subject to written rules. The September 15, 2000 “Criteria for the Review and Approval of Census Projects that Use Federal Tax Information” has provided the general framework for determining whether a project’s predominant purpose is consistent with Title 13, Chapter 5. This framework, while important and necessary, has led to very real resource and management costs. At the same time as there has been heightened awareness and formalization of the legal conditions under which the Bureau nurtures access to its confidential data, there has also been a significant degradation of the Bureau’s ability to produce public-use micro-data. Massive increases in the computational power available to an individual snooper as well as comparably massive increases in the quantity of identifiable data distributed over the Internet (e.g., exact names, locations and dates of significant events like births, deaths, and marriages; exact names and addresses of businesses) have combined to place increasingly draconian restrictions on the detail provided in public-use micro-data (see Sweeney 2001 Elliot 2001 and related articles in Doyle et al. 2001). The prospect of greatly reduced access to public-use household and individual data as well as the diminution of the already miniscule prospects for public-use business data leads us to propose a significant enhancement of the collaboration between the Census Bureau and the academic research community. Our proposal builds on the existing RDC and LEHD structures and is rooted in the Bureau’s core mission of providing public-use data products while maintaining the confidentiality of the underlying micro-data. We provide a framework that is fully consistent with the September 15, 2000 criteria document and is both transparent and comprehensively auditable. Equally important, our proposal integrates the provision of public-use data products with the scientific use of confidential micro-data in a manner that creates a permanent, formal, and essential feedback relationship between the two activities. III. Completing the Loop: The Integration of Census Micro and Aggregate Data Products and the RDC Network Current data products developed and used by the scientific research community can be classified into three basic types: (i) public use aggregate tabulations from micro-data on businesses, households/persons and/or integrated business/employee data; (ii) public use micro-data on households/persons; and (iii) confidential microdata on businesses, households/persons, and/or integrated data made accessible through the Census/NSF RDC network. Our proposal ambitiously integrates all of these data products in a manner that will dramatically increase the quantity and quality of public-use products (especially micro-data) and dramatically increase the usefulness and access to the confidential data inside the RDC network. As described below in much more detail, the proposal outlines a fully integrated data production and research access system that will create synthetic data as a part of its regular research activities. These synthetic data will be made available to the general scientific research community 6347895 Project Description and Coordination Plan Page 4 in a variety of methods. The proposal outlines the potential of making publicly available inference-valid synthetic micro-data on businesses and integrated business/worker data for the first time. The key here is the synthetic data. When the scientific research community has access to micro-data along the lines we propose, it will revolutionize research on businesses and households and their interaction. As outlined below, pilot projects have already demonstrated that program is feasible in this context. However, there are a large number of difficult statistical and confidentiality protection issues that remain unresolved, particularly for applications involving business micro-data and for applications using longitudinal data, integrated data and geospatial data. Much of the proposed project is devoted to addressing these unresolved issues. A fundamental component is the use of the RDC network as the central laboratory for developing and testing our proposed synthetic data methods. Using the RDCs as laboratories directly enhances the researcher access to the confidential micro-data in the RDC network so that the scientific benefits associated with the individual RDC projects are also a direct outcome of supporting the RDC-network through this proposal. To understand laboratory role of the RDC consider a prototypical project. A researcher develops an idea that can only be investigated with the micro-data available in the RDC network. The researcher write a proposal, obtain funding and, critically, make a compelling case that the project has the Title 13 benefits to the Census Bureau explained above. The researcher must meet all of these conditions prior to using any of the confidential micro-data. Once the project is approved and started, all of the analysis must be completed at a secure RDC location. When the project is completed, the researcher must leave behind a fully documented version of the methods and data used (so, amongst other things, the analysis could be replicated by another researcher) and also make a full report on the Title 13 benefits. Consider the benefits to such a researcher of having public-use synthetic data (or limited access synthetic micro-data available through an electronic network). First, in the development of both the research idea and the demonstration of Title 13 benefits, access to the synthetic data significantly enhances the researcher’s capabilities. Second, while the project is ongoing, testing and exploration of alternative specifications could be more ambitious if the project proceeded in parallel using both the “gold-standard” and the synthetic micro data. Third, the full documentation of methods and data in a meta-data system available to the research community for purposes of further work and/or replication is both easier and more accessible if the project proceeds with the synthetic data in such a parallel fashion. Fourth, the full report on Title 13 benefits is enhanced by the parallel analysis as the researcher would be able to explore data and methodological issues in a much richer manner. Such parallel analyses act as key “observations” in developing methods for certifying and maintaining the inference-validity of the synthetic data. This completes the loop. The parallel analysis provides direct evidence on the degree to which and over what dimensions the synthetic data are indeed inference-valid. The joint products over time are (i) improved access and functionality of the RDC system and (ii) high quality public-use synthetic micro-data. Does completing this loop eventually yield such rich and complete synthetic micro-data that most social science research could be conducted with the public-use synthetic micro data? Would success imply that the need for RDCs would diminish over time? While we are optimistic that the public-use synthetic data will be analytically valid for a wide range of applications, we are also certain that the answer to both of these questions is “no.” It will always be important to have access to the confidential gold-standard micro-data on the RDC network. First, confidentiality restrictions make it difficult to create synthetic data on some dimensions that are required for analysis (e.g., analysis of some specific geographic location and/or sector of activity or analysis of the workers transiting from welfare to work in the metropolitan area and the firms that employ such workers). Second, there are still many open questions on the production of synthetic data. It may be that for certain classes of models (e.g., linear models) and applications, the synthetic data completely summarize the original confidential micro-data. However, for other classes of models and applications (e.g., non-linear models), we may establish that the best available synthetic data have severe limitations. Finally, the full integration of the vast range of data for which we propose creating synthetic data is a very ambitious agenda and, by itself, will take a substantial period of time. Moreover, what we can contemplate now certainly does not reflect the future imagination and creativity of the research community to develop ideas that require even richer and more complex integrated data. Put simply, we anticipate that the research community will demand access to the gold-standard data for the indefinite future–both for the direct results from such research and in the further development of new synthetic data. We further anticipate that because researcher access to the confidential micro-data is so essential to the Census Bureau’s quality assurance for its public-use products, particularly public-use synthetic data, the feedback relationship between RDC-based research and the Census Bureau’s statutory mission will substantially enhance their cooperation and sense of common mission. The fully integrated synthetic data production and access system is described in detail below. The key point of this overview is that the range of data products actively used by the scientific research community would be dramatically enhanced with public-domain (and perhaps some restricted-access) synthetic micro-data. 6347895 Project Description and Coordination Plan Page 5 IV. A Selection of Research Projects from the RDC Network and LEHD Most of the RDCs have, since their inception, pursued matching projects with highly confidential administrative and Census survey data sets. Indeed, most indicated that they would pursue this objective as part of their initial NSF grant establishing the RDC. While there are substantial logistical, legal, and administrative hurdles to overcome, these projects have nonetheless been undertaken, results disseminated to the wider community, and use made of the results in both state and Census data programs. Further, recent work has looked beyond the matching of administrative and Census data, to data records from engineering and sociology, promoting a highly effective interdisciplinary center of study for researchers on the west coast of the US (Table 1). The LEHD Program was created in 1998 explicitly for the purpose of longitudinally integrating Census household and economic data using administrative records. Its flagship products include the integration of quarterly unemployment insurance wage records from twenty-two states (covering 60% of the workforce) with quarterly micro-data on establishments from the ES-202 system, demographic data from the Social Security Administration and Census 2000, and economic data from Business Register, Economic Censuses and Annual Surveys. The flagship public use product is the Quarterly Workforce Indicators (http://lehd.dsd.census.gov). A research team at LEHD is developing synthetic data based on the 1990-1996 Surveys of Income and Program Participation, complete W-2 earnings histories, and complete Social Security Administration benefit and disability histories. The “results of prior NSF research section of the proposal contains a catalogue of the data products produced by this program. Table 1 Selection of RDC-based Research Projects with Data Matching Project Principal Title Data matched No. Investigators Chicago RDC 299 Mazumder, B (FRB Using Earnings Data from the SIPP to Study the SIPP to SSA-DER and SSA-SER Chicago) Persistence of Income Inequality in the U.S. 275 Lubotsky, D (U of How Well Do Immigrants Assimilate into the U.S. March CPS and SIPP to SSA-SER Illinois) Labor Market? 406 Heckman, J, et al Hedonic Models of Real Estate and Labor Markets ACS and other surveys, linked (U of Chicago, internally using GIS Argonne Natl Labs, FRB Chicago) Boston RDC Pending Liebman, J Measuring Income and Poverty from a Multi-year SIPP to SSA-SER, MEF, MBR, (Harvard U) Perspective SSR, and proposed link to LBD Research Triangle RDC 345 Sloan, F, D Ridley, Alcohol Markets and Consumption LBD, BR, HRS to, Behavioral Risk (Duke U) Factor Surveillance System Survey, CARDIA 418 Sloan, F. et al Markets for local sports and recreation facilities LBD, LRD, Economic Census, (Duke U & American Housing Survey, Research Triangle Decennial Census, Census of Institute) Government, phone directories. 196 Chen, S & W van An Evaluation of the Impact of the Social Security SIPP matched to SSA data der Klaauw, W Disability Insurance Program on Labor Force Duke and NC State Participation in the 1990s California RDC 429 D Card et al (UC Using Matched Employee Data to Examine Labor State UI records matched to DWS Berkeley) Market Dynamics and the Quality of DWS/CPS Data 70 Hildreth, A& V J Income receipt from welfare transitions SIPP matched to State UI data and Hotz, UCB, UCLA MEDS 269 Simcoe, T, & E Taxis and Technology: Contracting with Drivers and Census of Taxicab & Livery Rawley,, UC the Diffusion of Computerized Dispatching Companies to data from hardware Berkeley firms supplying technology for computerized taxicab dispatch New York RDC Pending Lu, H H,& N G Earned Income Credit pickup rate (temp) Decennial Census to IRS data 6347895 Bennett Pending Goldstein, J and Bennett, N.G. Pending Freeman, L. Project Description and Coordination Plan Page 6 Multiple race reporting in the 2000 Census (temp) 2000 Decennial Census to 1990 Decennial Census Spatial assimilation of immigrants (temp) NYCHVS to tract data from 1990 and 2000 Decennial Census Pending A Caplin,, J Leahy Family characteristics and health outcomes (temp) 1990 and 2000 Decennial Census Pending Ellen, I, G et al School choices of native-born and immigrant students 2000 PUMS to administrative data (temp) Pending Mollenkopf, J., How do the dynamics of multi-ethnic families differ ISGMNY matched to 2000 Census Kasinitz, P. from immigrant and other families? (temp) Pending Groshen, E. (FRB- Alternative aggregate measures of wages (temp) LRD, LBD with Community Salary NY) Surveys for 3 cities Michigan RDC 409 Carter, G.R. III, From Exclusion to Destitution: Residential Decennial Census to 1996 National Young, A.A. Jr. (U Segregation, Affordable Housing, and the Racial Survey of Homeless Assistance of Michigan) Composition of the Homeless Population Providers and Clients 419 Morash, M., Bui, Race, Ethnicity, and Sex Differences in Estimates and 2000 Decennial Census to National H., Zhang, Y. Explanations of Crime Victimization and Crime Crime Victimization Survey (Michigan State U) Reporting 13 Prestergard. D.M. Evaluating the Economic Impact of an Economic LRD to NIST/MEP (Cleveland State U) Development Program: Measuring the Performance of the Manufacturing Extension Program Pending Shapiro, M. Matching ISR Surveys to Census Data HRS and PSID to LBD and LEHD Glossary: BLS BR CPS DWS Bureau of Labor Statistics Business Register (formerly the SSEL) Current Population Survey (U.S. Census) bi-annual survey administered by the U.S. Census Bureau for the BLS with the aim of understanding the factors affect the displacement of workers from their previous employment HRS Health and Retirement Survey ISGMNY Immigrant Second Generation in Metropolitan New York. A random sample survey of 4,000 individuals aged 18-32 from five immigrant backgrounds (Dominican, South American, West Indian, Chinese, and Russian) and three native-born backgrounds (Puerto Ricans, African-Americans, and white Americans) taken at the same time as the 2000 Census. LBD Longitudinal Business Database LRD Longitudinal Research Database (predecessor to LBD) MBR Master Beneficiary Record (SSA) MEF Master Earnings File (SSA) MEDS State of California Medicaid Records (State of California) NIST National Institute of Standards and Technology NIST/MEP NIST’s Manufacturing Extension Partnership NYCHVS New York City Housing and Vacancy Survey PSID Panel Study of Income Dynamics PUMS Public Use Micro Sample of the Census SER Summary Earnings Records (SSA) SIPP Surveys of Income and Program Participation (U.S. Census) SSA Social Security Administration SSR Supplemental Security Record (SSA) GIS Geographic Information Systems ACS American Housing Survey 6347895 Project Description and Coordination Plan Page 7 V. Other RDC-based Proposed Research Activities Geospatial matching Many important social science applications of micro-data involve examination of the relationship between economic agents, both businesses and households, and their surroundings. The impact of location specific characteristics on behavior is the subject of numerous studies, most commonly the impact of location specific characteristics involving government policy and geopolitical boundaries, i.e., governmental tax districts, air quality regulatory zones, etc. Hedonic models have been applied to real estate, where housing characteristics include school district quality or other location related (dis)amenities. Business clustering and geographical markets are just a few relevant industrial organization topics. Racial discrimination is a major social science topic where geo-spatial identification is critical. All of these studies require, to varying levels of detail, the ability to match the individual micro data response to its physical location within a geographic information system (GIS). Robust application of GIS tools to micro-data would allow information to be generated for each establishment or household on the physical proximity of that economic agent to the study-relevant components. For example, for a study of business clustering and geographical markets the amount of geo-spatial information that must matched to each micro record can be large, e.g. distances to other nearby supporting or competing businesses or to relevant households (markets). Other important geo-spatial relationships include the proximity of physical infrastructure, e.g. roads, rail spurs, etc. This creates a potentially large “many to many” assignment problem. The notion of how to define “nearby” is a subject of analysis itself. Creating these geo-spatial characteristics, including those that are geo-physical, requires substantial computing power and would be amenable to parallel processing. Agent-based modeling and simulation Agent-based modeling and simulation (ABMS) uses micro-scale rules to computationally determine macroscale patterns (Bonabeau 2002). ABMS is primarily done for highly non-linear systems that are difficult to model using traditional techniques. The focus of ABMS in social science is designing artificial adaptive agents that behave like human agents (Arthur 1991, Holland and Miller 1991). In this case, the micro-rules describe the behavior of individual people and the macro-scale outcomes include results such as market prices, supply availabilities and group consensus. ABMS has been successful in deriving meaningful macro-scale results from micro-scale data in a variety of contexts ranging from medical care units (Riano 2002) to energy markets (North 2001). ABMS systems operate at the level of individual behavior. This makes such models easily factorable for parallel execution (Resnick 1994). ABMS systems factored in this way can make full use of available cluster computers. The non-linear behavior embedded in most ABMS systems means that this approach is highly appropriate for the analysis of sensitive personal micro-data. The complexities of the non-linear outputs from ABMS, combined with other standard census checks, will effectively mask all identifiable personal information. VII. Organization of CES, the National RDC Network and LEHD Three inter-related Census Bureau activities lie at the heart of this proposal. The oldest of these is CES, whose acting director Ron Jarmin is a Co-PI of this proposal. CES is the archival repository of the Census Bureau’s main economic sampling frame, census and survey products. Researchers at CES have built and maintained historical Business Registers (formerly called the Standard Statistical Establishment List, SSEL), Economic Censuses (all sectors authorized for census by the Department of Commerce), Annual Surveys, and many specialized economic surveys. CES also administers the Census RDC network. Many of the data files built by CES can be used only in RDCs. A description of the CES-maintained files, many of which originate in other parts of Census, can be found at http://www.ces.census.gov/ces.php/home. Over the last 20 years CES has created and improved longitudinally linked establishment-level micro data. The two best known products of this type are the original Longitudinal Research Database (LRD), which contains longitudinally linked records from the Census of Manufactures and the Annual Survey of Manufactures, and the Longitudinal Business Database (LBD), which contains longitudinally linked records from the Business Register/SSEL. These flagship CES products are an important component of the research program in this proposal. Research using these data was some of the first to identify the tremendous amount of dynamism in the US economy (Davis and Haltiwanger 1990, 1992). Most of the data linking projects described above use the LBD to bridge to other Census business data. Synthesizing a version of the LBD is a high priority for the proposal team. CES operates the RDC-network and employs the administrator in each of the 9 RDCs. The RDC-network, however, is a much broader activity. It is held together by the RDC directors, who coordinate the activities at their own facility and across RDCs using regularly scheduled conference calls. The process of nurturing proposals and 6347895 Project Description and Coordination Plan Page 8 educating potential users about the Census data and its research uses is a collaborative effort of the RDC directors, administrators, review panels and Census staff (at CES, LEHD and in other areas). The RDCs hold an annual meeting at one of the RDC locations to discuss management and research issues. The LEHD Program at Census was founded in 1998 with seed money from the Census Bureau, the National Science Foundation, the National Institute on Aging and the Russell Sage Foundation. In five years it has grown from a staff of 1 (plus senior research fellows Abowd, Haltiwanger and Lane) to a staff of 28 (some are regular Census employees, others are contractors). LEHD is the part of Census charged with creating integrated micro-data that combines information from the Census Bureau’s Demographic and Economic directorates, usually with the essential use of administrative records. The flagship product of LEHD is a set of infrastructure files described in the “results from prior NSF research” section. Research using these data has begun to identify the consequences of a changing economy on both firms and workers (Bowlus and Vilhuber, 2002; Abowd et al. 2002, Abowd, Lengermann and McKinney 2002, Andersson et al. 2002). Because of the joint efforts of CES and the RDC directors, much of the framework for implementing the projects at the heart of this proposal is already in place. But, the maintenance of the RDC network and, therefore, of the essential organization of this proposal requires recognition of the laboratory role of the RDCs and their sustained funding. Every RDC has contributed at least one member of the senior scientific team in this proposal. Every RDC has written a letter of support for the research program proposed herein or joins the proposal as one of the directly funded work units. Finally, two of the proposal’s senior scientists have been senior research fellows at LEHD since its inception. CES, the RDCs and LEHD are now functioning as a well-integrated scientific network. This network is absolutely essential for the research activities described herein and the continued viability of Census’s public-use data products. Census Bureau Access Modalities Research using confidential Census data is driven by the RDC access modality. Researchers work over a dedicated, encrypted connection to the Census-operated RDC computing network (in Bowie, MD). Researchers must perform their work in the supervised space operated by the RDC. The RDC administrator must conduct a detailed disclosure avoidance control before any results (final or intermediate) may be physically removed from the RDC. From the researcher’s perspective, beyond the obvious cost of traveling to an RDC, there are many other barriers to access. The typical researcher has limited knowledge of the requirements for access and even more limited knowledge about the micro data. This limited knowledge often requires multiple proposal submissions before the researcher satisfies the legal and feasibility requirements for working with the confidential micro-data. Moreover, given the nature of the micro data, there are substantial learning costs once access has been granted. These barriers to access can be reduced somewhat with education, training and enhanced documentation. However, the current proposal offers the possibility of substantial reductions in the costs of access and, in turn, much greater access by the research community. To understand these benefits, it is worth elaborating on each barrier to access and how this proposal can help alleviate key aspects of these costs. First, the most important point to emphasize is that access to the confidential micro data can only be for valid Title 13, Chapter 5 statistical purposes. While CES and Census have developed extensive documentation of valid Title 13 purposes and the RDC-network offers assistance and training on Title 13, it is fair to say that the research community still struggles to understand fully the nature and importance of this part of the U.S. Code that provides the statutory basis for the Census Bureau’s operations. As such, many proposals to CES do not adequately state their Title 13 purposes. While many of these projects have potential Title 13 justification, the typical proposal requires several iterations to meet these requirements. A second, related, point is that in the typical proposal received by CES, the researchers are not sufficiently familiar with the pitfalls and nuances associated with analyzing the micro-data. Researchers often must revise proposals to address feasibility and core measurement issues. A third point is that since most of these micro-data have not been developed as public use files, the editing, imputation and documentation of these data (especially business establishment data) do not meet the standards of conventional public-use data like those associated with household surveys. CES has partially remedied this shortcoming with substantial documentation and data editing, but there has been less standardization of the treatment of missing/erroneous data than for Census public-use micro-data products. Instead, individual statistical/research projects have made their own idiosyncratic data adjustments. There is “knowledge” capital that has been accumulated over time and shared among users but researchers still experience substantial learning costs in working with the confidential micro-data. Our proposal will dramatically increase the accessibility of the micro-data at Census by creating a multi-layered access system that will give researchers access to public-use synthetic data that will substantially lower the learning and proposal preparation costs of access to the gold-standard data. In the next section, we outline this multi-layered access system. We conclude with implementation and dissemination issues. 6347895 Project Description and Coordination Plan Page 9 VIII. Multi-layered Confidentiality Protection A. Public use synthetic data: These are micro data files constructed by synthesizing the underlying confidential data using an appropriate probability distribution. Though the files would contain synthetic or virtual data, not real data, it is possible to draw valid inferences about the unit of observation. The synthetic data would share many of the same statistical properties as the real data. (Rubin 1993, Raghunathan et al. 2003) B. Multiply-imputed partially synthetic data: This is a variant on approach A, sometimes referred to as pseudosynthetic data, where synthetic data are generated using a probability distribution that conditions on actual values of the confidential micro data; that is, the synthetic observation has a (potentially) identifiable source in the original confidential data. This approach requires additional procedures to assure confidentiality protection. (Little 1993, Abowd and Woodcock 2001, Reiter 2003) C. Gold-standard confidential data: These files contain micro data prepared and documented to public use standards with complete missing data and data edit models. Gold-standard confidential data are the normal product released for use in RDCs, for approved projects. These data are Title 13 (and sometimes Title 26 or Title 42) confidential. The gold-standard files are used to support the public use files by allowing rapid, straightforward verification of statistical results generated from the first two methods. The feedback between the public use files and the gold-standard files continually improves the quality of the public use products. D. Raw confidential data: These are the original archival data files upon which the other layers are built. In this case, confidentiality would result from the restrictions put on their use rather than from features built into the files themselves. That is, the files could be accessed at RDCs if Title 13, Chapter 5 benefits were sufficient. Synthetic data Synthetic data (also called virtual data) originated in confidentiality protection papers by Rubin (1993) and Feinberg (1994). The synthetic data samples can be designed for ease of analysis. Repeat the process of synthesizing the population and sampling from the synthetic population to create a set of M synthetic samples. Raghunathan et al. (2003) provide appropriate Bayesian formulae for the statistical analysis of synthetic samples. Synthetic data have the property that observations in the synthetic sample bear no necessary relation to observations in the actual sample, the one from which the posterior predictive distribution was estimated. Some techniques exclude the originally sampled units when constructing the synthetic samples. Other techniques allow the originally sampled units to occur in a synthetic sample if they are selected for that sample. All data in the synthetic samples are draws from the posterior predictive distribution. Hence, there are no observations in the synthetic samples that contain the actual data from the original sample, except for the variables constructed from the sampling frame information. Following Duncan and Lambert (1986) we can assess the confidentiality protection afforded by the synthetic data along two dimensions: identity disclosure and attribute disclosure. Identity disclosure is protected so long as the synthetic observation, which normally contains information from both the sampling frame and the posterior predictive distribution, cannot be used to re-identify the unit in the synthetic sample in the population. For synthetic samples of households, identity disclosure protection is very straightforward to provide. The standard technique is to coarsen enough of the information in the sampling frame variables to ensure that the most detailed tabulation of individuals or households that can be produced from the synthetic population has multiple units (usually at least three) in each populated cell. Alternative techniques include swapping and other confidentiality edits. We note that protection against identity disclosure is necessitated by the presence of variables derived from the sampling frame information. Since conventional public use files always coarsen this information as a standard confidentiality protection, the identity disclosure protection problem in synthetic household data is not generally considered a technically challenging problem. Attribute disclosure protection, however, remains a potentially important problem for synthetic household samples. An attribute disclosure occurs if a confidential characteristic of a unit in the synthetic sample can be correctly associated with the actual unit in the population. Duncan and Lambert (1989), Lambert (1993), and Trottini and Fienberg (2002) model the control of attribute disclosure using a loss function for the snooper’s estimates of sensitive attributes. Attribute disclosure risk is assessed based on that loss function. Duncan and Keller-McNulty (2000) provide a Bayesian framework for assessing the attribute disclosure risk of masked and synthetic data that use the inverse squared error as an estimate of the snooper’s loss. Reiter (2004) applies these methods to the attribute disclosure risk control problem arising from synthetic data. 6347895 Project Description and Coordination Plan Page 10 Following Duncan et al. (2001) we recognize that there is a tradeoff between the usefulness of a data product and the disclosure risk that the product presents. Efficient data dissemination methods seek the production possibility frontier of this tradeoff. Hence, they deliberately compromise data usefulness for confidentiality protection, for a given level of resources devoted to collection and dissemination. We consider here the applicability of this tradeoff to synthetic household data. We elaborate on these concerns below in our discussion of layered confidentiality protection. The usefulness of a set of M synthetic samples of household data is determined by the valid inferences that can be drawn from the posterior predictive distribution. Raghunathan et al. (2003) and Yancey et al. (2002) have suggested related criteria for making this assessment. There are two essential issues, common to all statistical methods: bias and precision. An inference based on synthetic data is biased if it differs substantially from inferences based upon actual samples. The precision of an inference based upon synthetic data depends only upon the between sample variability in the estimated quantity.1 If one could be relatively certain of controlling bias in the synthetic data, then the precision of inferences could always be improved by generating additional synthetic populations to sample from. One cannot, unfortunately, easily control bias in synthetic data. This problem is not unique to synthetic data. Confidentiality protection systems: for tabular data, primary and complementary cell suppression are known to introduce substantial bias that synthetic data may eliminate without decreasing the precision of inferences (Dandekar and Cox 2002). Controlling the bias in synthetic data requires feedback from the analysis to the synthesizer. The analyst must regularly ask for an assessment of the inferential bias based on analysis of the underlying confidential data. The data synthesizer must collect these assessments and modify the methods for estimating the posterior predictive distribution. For synthetic samples of businesses, identity disclosure protection is problematic even in synthetic data. Most business sampling frames (including all of those used by the Census Bureau) have self-representing ultimate sampling units (called “certainty cases” in Census samples). Re-identification of a certainty case in a synthetic sample is trivial; however, re-identification of a unit in a business sample is not always an identity disclosure. For example, in the Census Bureau’s County and Zipcode Business Patterns the existence of unique establishments in certain geographic and/or industrial classifications is published. We consider the problem of identity disclosure protection in synthetic business samples to be a high priority in our proposed research program. Attribute disclosure protection for business samples is also complicated by self-representing and large (in some sense) units. Standard practice (e.g., County and Zipcode Business Patterns, Current Employment Statistics) requires coarsening or suppressing attributes when there is a risk of attribute disclosure at the publication level. While the technical problems of identity and attribute disclosure control in synthetic data can be addressed by known methods in statistics and substantial computing power, two important perception issues remain. First, the research community is justifiably suspicious of synthetic data because the properties are not yet well-studied and because the use of this technique may further limit access to underlying confidential data without broadening general data access. Second, statistical agencies are justifiably suspicious of synthetic data because they must declare simultaneously that confidentiality protections applied to the synthetic data have eliminated all actual responses from the public use product but the data themselves can still be used to make valid statistical inferences. We are fully cognizant of both of these problems in our proposal. The layered confidentiality protection system is designed to address the researchers’ concerns about inference validity and improved access to confidential data. As we show below, current practice is inefficient: more data usefulness can be achieved at no additional confidentiality risk by using the mixture of data products that we propose. The statistical agencies’ problem requires some education of the data-using public. The production of synthetic data requires a substantial investment of resources by the data provider. Essentially all of the steps necessary to produce public-use micro data must be performed on the underlying confidential micro data. In addition, multiple methods of estimating the posterior predictive distribution must be developed. These estimation methods must be designed to allow subject matter concerns to influence the posterior distribution just as they would have influenced data editing and variable creation in a standard public use file. These methods must also be designed to allow the data to “speak for themselves.” The posterior predictive distribution is an elaborate joint probability distribution among all of the confidential variables in the original sample, given the data in the sampling frame. Needless to say, the estimation of such a distribution is challenging even accounting for the massive computing power that can be harnessed for the effort. Researcher skepticism is just one manifestation of Shannon’s (1948) information principle. The originally collected data represent information about the target population to the extent that they are not predictable from less information about that same population. Synthetic data consist of draws from an estimated posterior predictive distribution conditional on a relatively small amount of 1 Rhagunathan and Rubin (2000) demonstrate that the correct precision measure for the pure synthetic data case does not include a term for within sample variance of the estimated quantity. 6347895 Project Description and Coordination Plan Page 11 information about the population; namely, the data in the sampling frame. The information in the original sample is transmitted to the synthetic data via this posterior distribution. Research skepticism is justified to the extent that the estimated posterior predictive distributions used to synthesize the data might hide important relations that a direct use of the confidential data would reveal. This is especially important for biased negative results from the synthetic data since such results may discourage further research. As we make clear in our discussion of the layered confidentiality protection system, feedback from the synthetic data on the data synthesizer is essential to develop research confidence in these products and to ensure their continuous improvement. This feedback is designed to estimate and reduce the bias in the synthetic data while maintaining the maximum feasible level of precision. Researcher skepticism based on the intrinsic difficulty of producing forecasts for variables in most micro data bases is misplaced. A draw from the posterior predictive distribution is not a “forecast” in this sense. A better analogy is a stochastic simulation. It is straightforward to provide examples in which the posterior predictive distribution perfectly reproduces the information in the underlying confidential micro data (see, e.g., Feinberg et al. 1998). These examples tend to be for much simpler problems than one encounters in practice. The crux of the researcher concern about synthetic data removing too much information from the underlying confidential data lies in the implementation of data synthesizers using variants of Gibbs samplers or sequential multivariate regression models (see Raghunathan et al. 2001 and 2003). These implementations rely on having good quality conditional distributions for every variable (continuous and discrete) and every distinct cell of the sampling frame. An important part of our research program focuses on the interaction of data users and data providers to refine this part of the data synthesizer. Testing of nonlinear models and of models with important timing discontinuities is critical. Although these techniques are not yet in widespread use, the Survey of Consumer Finances (Kennickell 1998) makes use of multiple imputations for confidentiality protection using methods very similar to those we propose here. Intermediate public use and confidential data products As promising as synthetic data are for the front end of a layered confidentiality protection system, we also propose developing a series of related intermediate products that combine some features of synthetic data with traditional confidentiality protection systems and with newer micro-data-based confidentiality protection systems that are based on other probability models. The term “masking” is used in many contexts (see Domingo-Ferrer and Torra 2001 and Abowd and Wookcock 2001). There is not yet a standard vocabulary for these products in the statistical disclosure limitation literature. Normally, masking means some variant of the matrix mask (see Domingo-Ferrer and Torra 2001) for linear methods. For nonlinear methods there is no general definition of which we are aware. Whenever masking is used as part of confidentiality protection, one must take care to understand the precise definition. The term “swapping” is used more consistently. Swapping generally means exchanging all the values of a set of variables between two different observations conditional on a match for another set of variables, as is done in the 1990 and 2000 Decennial Census public use micro-data samples. Swapping is a special case of a matrix mask. The term “shuffle” means reusing all the values of every variable but not exchanging them in pairs. The values from one source observation are shuffled to many different destination observations (see Sarthy et al., 2002 ). New masking and shuffling algorithms share two important features: (1) the resulting confidentialityprotected product has the same structure as the underlying confidential data product, and (2) every observation in the masked/shuffled data has a true source record in the underlying confidential data (although not necessarily vice versa). We can, once again, use the Duncan and Lambert identity and attribute disclosure dichotomy to assess these methods. Because there is a true source record in the underlying confidential micro data, all of these methods require conventional assessments of their ability to control identity disclosures. In general, the same coarsening and suppression techniques applied to the variables in the sampling frame can be used to measure and control this risk. Controlling attribute disclosure risk is very similar to the synthetic data case. Reiter (2004) discusses this case briefly. Abowd and Woodcock (2001) and more recently Raghunathan et al. (2003) propose data masking methods based on multiply imputing the values of every confidential data item given all other confidential and nonconfidential data, including variables from the sampling frame that are not collected as a part of the survey or administrative record extraction. Both approaches use the sequential regression multivariate imputation (SRMI) technique developed by Raghunathan et al. (2001). Both can accommodate generalized linear models for (a transform of) every variable in the underlying confidential data. Thus, both can handle a mixture of discreet and continuous data. Abowd and Woodcock focus on methods that can be applied to linked survey and administrative data with multiple populations/sampling frames. Raghunathan et al. focus on single population methods; however, it is clear that their methods could be extended to linked data with multiple populations. The basic difference between 6347895 Project Description and Coordination Plan Page 12 the two approaches is that Abowd and Woodcock take a draw from the conditional posterior predictive distribution for each confidential variable given the realized values of all of the other variables (confidential and nonconfidential). Hence, their preferred method, “masking” or more precisely, “multiply-imputed partially synthetic data,” must be subjected to further analysis to assess its ability to control identity and attribute disclosure. Reiter’s (2003) partially synthetic data has the same feature and he derives the correct standard error formula. The confidentiality protection system proposed by Raghunathan et al (2003) uses the SRMI technique to take a draw from the complete posterior predictive distribution of the confidential data given the non confidential variables (e.g., information from the sampling frame). Thus, the Raghunathan et al. technique is a full synthetic data method. We propose to use both methods in our layered confidentiality protection system. The Abowd and Woodcock and Reiter methods have already been specialized to complex integrated statistical systems like LEHD and CES routinely produce. For this reason, several of the PIs have already undertaken extensive development work on potential public use files based on these methods. First, work is already underway developing a prototype multiply-imputed synthesizer for the core LEHD infrastructure files, described below in the “Results from previous NSF research” section. This confidentiality protection system uses the SRMI method. Second, the LEHD Program, in conjunction with an interagency committee that includes the Social Security Administration, Internal Revenue Service, Congressional Budget Office and other parts of the Census Bureau, is developing a public use file containing data from the Survey of Program Participation (1990-1996 panels) and Social Security administrative/tax data (W-2 information separately by employer, Summary Earnings Records, Master Beneficiary Records, Supplemental Security Records and Form 831 Disability Records). The confidentiality protection of this public use file is particularly challenging because the SIPP source records cannot be re-identifiable in the existing SIPP public use files; that is, this new public use file must be used independently from the existing SIPP public use files. Third, Reiter has applied these techniques to data from the Current Population Survey. The development of these partially synthetic multiply-imputed files has provided much needed experience in developing the layers of our confidentiality program. We illustrate using the SIPP-SSA files. Since this public use file is targeted at retirement and disability research for national programs, all geography has been removed from the public use portion. Of course, geography is still present in the internal files available within the secure RDC facilities. Removal of geography was necessary to limit the potential for re-identifying SIPP source records in the existing SIPP public use files. Preserving marital relations as well as basic demographic and education variables provided the maximum extent to which conventional identity disclosure control methods could be used. The interagency committee thought that linking a handful of extremely coarse demographic and educational variables from the SIPP to the massive amounts of administrative and tax data was not the most effective method of providing access to these data. As an alternative, a layered approach was adopted. Successive, confidential versions of the linked data including a long list of proposed variables from the SIPP and all of the administrative variables from SSA (including tax data) were developed. Researchers at Census, SSA, IRS, and CBO are studying the variables in these files, deemed gold-standard files because they contain all of the original confidential data. Once the research teams are satisfied that the gold-standard files adequately provide for the study of statistical models relating the variables of interest from the SIPP and the administrative data, a variety of masked potential public use files will be produced using the methods described in this section of the proposal. The same research teams will then assess the bias and loss of precision from the various techniques. Other research teams will assess the identity and attribute disclosure risks from each of the methods. The team will then be equipped with reasonable quantitative measures of the disclosure risks, scientific biases, and losses of precision associated with feasible implementations of these new confidentiality protection techniques. It is expected that a public use product will be available within two years. Interim products include full RDC support for the gold-standard files, which contain links that permit RDC use of any variable in the existing public-use SIPPs. The SIPP-SSA public use file is not a static product. We fully expect the interaction of RDC-based researchers with the data to provide much needed feedback to the process of variable selection and confidentiality protection for such files. IX. Dissemination and Adoption The cornerstone of our dissemination system is the virtual RDC, a replica of the research environment on the RDC network using synthetic data and the exact programming environment of the RDC network. The virtual RDC can be used for primary research, since the synthetic data are inference valid. More importantly, it can be used as an incubator for proposals to analyze the confidential data. The proposal development process, which can now take more than a year, would be improved and simplified using the virtual RDC. A researcher would benefit from the fact that the structure of the synthetic data and the structure of the gold-standard confidential data were identical. 6347895 Project Description and Coordination Plan Page 13 The researcher would develop the proposal in the same environment as a real RDC, thus guaranteeing that the tools needed to do the modeling were available and working properly. Some of the PIs and senior scientists on this proposal have participated in the development and use of the Cornell Restricted Access Data Center (CRADC, part of CISER at Cornell). The CRADC, which was developed under the NSF Social Data Infrastructure grant that supported LEHD, is our model for the virtual RDC. Authorized users access data from authorized providers using a “window” on the CRADC machines (which appear to be a Windows desktop to the user). The CRADC provides a complete research and reporting environment that fully supports collaboration among authorized users of the same data.2 Although the CRADC is a reasonable model for a virtual RDC, our proposal goes farther. Real RDCs operate with “thin client” interfaces to the RDC computing network, a specialized Linux environment. The virtual RDC will provide an exact replica of the supercluster computing system that we will implement to create the synthetic data and support the complex modeling on the gold-standard and synthetic data. The Census Bureau has agreed to support an advisory panel of ten experts and users as a part of its internal disclosure research program. One of the PIs (Abowd) is participating in the organization of this group, which will be already in place at the start date of the work proposed here. Their role will be to provide regular (3 times/year) feedback on which data sets should be synthesized and the quality of the synthesizers. The LEHD program also has such a panel run under the auspices of NIA. Abowd teaches “Social and Economic Data” at Cornell University in a distance learning equipped classroom. He will make the class available to graduate students at any RDC host institution who is a potential RDC user (thesis or RA). The course covers many of the data sets used in the RDCs. It also covers data protection law, secure access protocols (including RDCs), confidentially protection systems, RDC proposal development, and appropriate statistical tools. The RDC coordinators on the proposal will make appropriate arrangements for their institutions to subscribe to the course using each institutions distance learning facility. If there is over-subscription, we will investigate means of expanding the availability via recorded lectures and asynchronous distance learning. X. Implementation of the Computing Environment Five of the senior scientists on the proposal (Abowd, Raghunathan, Reiter, Roehrig and Vilhuber) have extensive experience implementing different components of the statistical software required to create the synthetic data. Bair and Boyd bring the expertise of the Argonne National Labs in designing and implementing parallel cluster systems. They also bring the expertise required to implement the geographical linking and the agent-based modeling and simulation. The Center for Economic Studies, directed by Co-PI Jarmin, designed and manages the RDC network. LEHD and the RDCs bring significant specialized computational skills to the research effort. What is missing is a comprehensive computing environment in which to perform the proposed work. The current RDC-network is a cluster of six 4-processor Xeon systems attached to a 10TB storage array network. The system runs SuSE Linux on each node. The nodes are coupled with gigabit Ethernet. Each node runs an independent copy of the operating system. Statistical software, including SAS, Stata and other specialized programs, compilers and libraries are maintained on the system. The computational demands of the present proposal would swamp this system. As a part of this proposal, we have assembled an industry support team that will permit us to add a supercluster to the RDC-network while remaining fully compliant with the security provisions of that network. From a computational viewpoint, the programming used in the data synthesizers provides an ideal problem for configuring and optimizing a supercluster of SMP nodes with relatively many processors on each node. The reason for this choice is that the statistical programming for the data synthesizers doesn't decompose into threads the same way as problems optimized for clusters like Jazz at ANL or Velocity at Cornell. These clusters have only a few (one to four) processors per node and many nodes. The data synthesizers rely on a statistical programming language (SAS) whose data handling and core statistical modules are taken as given. The multi-threading comes from applying the SAS MP-connect option to two aspects of the problem: (1) multiple statistical models fit from the same input data and (2) parallel production of the “implicates" of the synthetic data. Optimal performance for the statistical modeling normally means keeping all the threads on the same node when they are sharing the input data set, which will be (partially) cached in the memory of the node. Using multiple nodes on this part of the processing, requires creating many local copies of large input files on other nodes, which isn’t usually worth the time spent to do it. Optimal performance for the implicate production usually means distributing these calculations to as many nodes as needed in order to have one node working on each implicate. In prototypes we have used 64-bit nodes because the 2 Technically, all of the Census products on the CRADC are “public use” files; that is, they have been approved by the Census Disclosure Review Board for general distribution. 6347895 Project Description and Coordination Plan Page 14 matrices built by SAS in their statistical modules routinely violate the 2GB memory limit of 32-bit systems. Since this is the part of the code we take as “given,” the solution is to use a 64-bit environment with sufficient memory, where the matrix limit problem disappears. The characteristics of the data synthesizers discussed here are based on the computations in Abowd and Woodcock (2001) and extensions programmed at Census by the LEHD staff. In view of the security requirements, which dictate that the supercluster must either run SuSE Linux or be fully compatible, and the computational requirements, which dictate that the system must run 64-bit SAS, we approached Intel, Unisys, and SAS to assemble a proposed computing environment. Intel donated 256 Itanium 2 processors. Unisys configured a modular supercluster using their ES-7000 server and Myrinet cluster interface. Each node on the supercluster has 16 Itaniums with 32GB of memory running under a single image of SuSE Linux. The proposal budget allows for the immediate implementation of a four node cluster with this architecture (64 processors). The PIs will seek additional funding to complete the 256-processor supercluster. SAS has committed to delivering the required version (9.2 for Linux IA-64) in beta by the proposed start date of the grant. Letters from Intel, Unisys and SAS are in the supplemental documents to this proposal. Ray Bair of the ANL cluster computing team is a senior scientist on this proposal. The ANL team will implement and optimize the supercluster after it has been installed at Census. Parallel computing can dramatically reduce the time to solution as well as increase the size of problems being addressed. Argonne National Laboratory has considerable experience configuring and operating such clusters. They currently operate 350-node and 512node Linux clusters which are used for large-scale applications and parallel computing research. The extensive experience gained from this computing environment across a wide range of applications will be leveraged for the Census Bureau applications. Argonne also has experience with porting complex and large-scale military, scientific and engineering simulation models to a parallel processing environment using a wide range of parallel computers (e.g., Cray, IBM, Linux Networx, NEC, SGI). Additionally, Argonne staff has a long history of forefront research on programming models for parallel applications. XI. Results from Prior NSF Research Dynamic Employer-Household Data and the Social Data Infrastructure, National Science Foundation, SES-9978093 to Cornell University, September 28, 1999 – September 27, 2004, $4,084,634. (PI: John M. Abowd, Co-PIs: John Haltiwanger and Julia Lane). The LEHD program is an integral part this grant since $2.5 million of the award was subcontracted to that program. The LEHD program has created a vast array of new micro data and time series products at Census. These include (1) the Quarterly Workforce Indicators, a system of employment flows, job flows, and earnings measures provided at very detailed geographic and industrial bases for very detailed age and sex groups, 1990-2003. Full quarterly production began in September 2003 (see lehd.dsd.census.gov); (2) the supporting infrastructure files for the QWI (a) the Individual Characteristics File: Records for every individual in the system (approximately 65% of US workforce) with demographic data, place of residence latitude/longitude (1999-2001), links to other LEHD files including 2000 Decennial Census, SIPP (19901996 panels), CPS (1976-2001 March), Census Numident (provides sex, birth date, death date, place of birth from SSA records). Except for place of residence, data cover the period 1990-2001, updated quarterly; (b) the Employment History File: records for every employer-individual pair in the system with earnings data from state Unemployment Insurance wage records for CA, CO, FL, GA, IA, ID, IL, KS, MD, MN, MO, MT, NC, NJ, NM, OR, PA, TX, VA, WA, WI, and WV. Six more states have agreed to join as soon as funding is available (AK, DE, KY, MI, ND, OK). Data cover the period 1990-2003, updated quarterly; (c) the Employer Characteristics File: Records for every employer in the system with full ES-202 data, summary data from the UI wage records, SIC and NAICS industry coding, federal EIN, and location geo-coded to the latitude/longitude. Data cover the period 19902003, updated quarterly. The Human Capital Project produces a system of micro-data files with full-time, full-year annual earnings estimates for each individual in his/her dominant employer during each year (1990-2003, updated annually). Additional variables include the LEHD estimate of the individual’s human capital and the decomposed wage components upon which the estimate is based The supporting infrastructure files for the Human Capital Project: (a) EIN/Census File Number links to the Business Register (formerly known as the SSEL); (b) EIN/Census File Number links to the 1997 and 1992 Economic Censuses; (c) establishment micro-data summarizing the distribution of human capital at in-scope establishments (those in the states affiliated with the QWI project). Integrated SIPP/Social Security Administration data: for the 1990-1996 panels, information from every Detailed Earnings Record (W-2) for every respondent providing a valid SSN, Social Security benefit and application information from the Master Beneficiary Record, the 831 File, and the Supplemental Security Record. These data are being used to prepare files for RDC use and to develop a new public use file. The Sloan Project: a collaborative study with five of the Sloan Industry centers (steel, food retail, trucking, semiconductors, and software). The objective is to provide a better understanding of productivity, job and wage outcomes at the micro and industry level 6347895 Project Description and Coordination Plan Page 15 and in so doing help Census update its measurement methodology. The project combines the expertise of Sloan Industry Center experts with the LEHD infrastructure data and in turn with the expertise in the Census industry operating divisions. This project takes a bottoms-up approach as the Sloan industry experts have considerable knowledge of individual businesses and associated trends in their industries. Integrated IRS/DOL Form 5500 data: records from the public use Form 5500 have been integrated into the LEHD business file system using the federal EIN and supplementary information. Data are being developed on employee benefit plan coverage. A detailed geocoding system capable of geo-coding business and residential addresses to the latitude/longitude from 1990 forward. California Census Research Data Center, SES 9812174, to the University of California at Berkeley, September 1, 1998 – August 31, 2004, $687,300. New York Research Data Center, SES-0322902, to the National Bureau for Economic Research, August 1, 2003 to July 31, 2004, $300,000. Michigan Census Research Data Center, SES-0004322, to the University of Michigan, August 31, 2002 – August 31, 2004, $300,000. Triangle Research Data Center: Supplement, SES9900447, to Duke University July 1999 – June 2002, $300,000 and renewal July 2002 – 2004, $200,000. Expanding Access to Census Data: The Boston Research Data Center (RDC) and Beyond, SBR-9311572, to the National Bureau for Economic Research, September 1, 1993 - July 31, 1997, $404,991. Boston Data Research Center – Renewal, SBR9610331, to the National Bureau for Economic Research, May 15, 1997 – April 30, 1999, $188,080. Chicago Research Data Center, SES 0004335, to the Northwestern University, August 2001 – August 2004, $300,000. Each of these grants has provided basic support to the operations of the respective RDCs. Research conducted in these RDCs has led to over 100 research papers in economics, sociology, public, environmental, and occupational health, urban studies, and political science (see Research Produced at NSFSupported RDCs in the References Cited section). There are dozens of research projects as well as a pipeline of proposals under review in all these fields at these RDCs. National Bureau of Economic Research Summer Institute Supplement grant SES 0314087 (to SES9911686) to the National Bureau of Economic Research, April 1, 2003 – September 30, 2003, $10,000, funded a research conference in Washington, D.C. that brought together the researchers involved in the heretofore distinct LEHD and RDC projects with their sponsors and collaborators at Census. This conference provided the impetus for the increased cooperation and integration of these two Census micro-data projects necessary to undertake the proposal you see here. Workshop on Confidentiality Research, National Science Foundation Grant SES-0328395 awarded to the Urban Institute, June 1, 2003 – May 31, 2004, $43,602 (PI: Julia Lane, Co-PIs: John Abowd and George Duncan), supported a workshop that was conducted in June 2003 and issued a report to NSF. Coordination Plan Specific roles of PI, Co-PIs, and Other Senior Personnel The plan coordinates the activities of the nine RDCs, the LEHD Program, Argonne National Laboratory, Cornell, Carnegie-Mellon, Duke, and Michigan, teams as they relate to the activities of this proposal. The RDCs and the LEHD Program have a designated senior scientist whose role is to coordinate these activities. Their roles are listed below. John M. Abowd, Cornell University, General grant coordinator, Cornell RDC coordinator, directs the Cornell and LEHD components of the synthetic data collaboration. Ron S. Jarmin, U.S. Bureau of the Census, CES RDC coordinator, Directs the CES component of the synthetic data collaboration, supervises the Census staff who operate the RDC network Trivellore E. Raghunathan, University of Michigan, Directs the Michigan component of the synthetic data collaboration. Stephen R. Roehrig, Carnegie-Mellon University, Directs the CMU component of the synthetic data collaboration. Since CMU’s RDC will close before this grant work starts, it is not one of the supported RDCs. Roehrig will do algorithmic development on his Carnegie-Mellon workstation. These algorithms will be tested using the Cornell Restricted Access Data Center (initially) and the virtual RDC (when ready). Tested algorithms will be transmitted to the RDC network through the Cornell RDC, where the administrator will be the Censusmandated human interface. Roehrig has a limited travel budget that will permit occasional trips to the Washington RDC to work on site. 6347895 Project Description and Coordination Plan Page 16 Matthew D. Shapiro, University of Michigan, Michigan RDC co-coordinator Neil Bennett, CUNY Baruch, New York Baruch RDC coordinator. Gale Boyd, Argonne National Laboratories, Chicago RDC coordinator, directs the geo-spatial integration and agent-based modeling and simulation research components of the proposal. Boyd’s research component will be accomplished by collaborating with other Chicago RDC-based researchers. The support of the Chicago RDC through its lab fee includes support for this coordination activity. See the Cornell budget justification for a general explanation. Marjorie McElroy, Duke University, Duke RDC coordinator. Wayne Gray, Clark University, Boston RDC coordinator. John Haltiwanger, University of Maryland, LEHD coordinator Andrew Hildreth, University of California, California Census RDC coordinator (includes both Berkeley and Los Angeles). Margaret C. Levenstein, University of Michigan, Michigan RDC co-coordinator. Jerome P. Reiter, Duke University, Directs the Duke component of the synthetic data research program. Reiter will work in the Duke RDC. Ray Bair, Argonne National Laboratories, Team leader for the ANL team that will optimize the RDC supercluster. The ANL team will work at the Chicago RDC. Lars Vilhuber, Cornell University, Senior scientist on the Cornell data synthesizing team. Responsible for integration of the different data components. A central tenet of the proposal is that the core RDC activities need to be supported in order to preserve the network of access points to the critical confidential micro-data that contribute to the basic scientific knowledge and provide the input models and data preparation for our synthetic data development. Since the RDCs receive a lab fee each year to assist in the proposed work, the coordinator for each RDC does not appear explicitly in the budget. See the budget justification for Cornell University for an explanation of how the lab fee supports the operations of the RDCs. Each year of the proposal the PIs and senior scientists performing the RDC coordination role will, as part of the operation of the RDC, assist a wide variety of scholars in preparing proposals to use the RDCs. The active commitment of this group of senior scientists is required to ensure that the RDC network is fully utilized. Each proposal involves preliminary discussions, a pre-proposal submission to Census, a feasibility and Title 13 assessment, review by the RDC review board, review by the Census review board, approval, research, data-basing of the project meta-data, and certification. Many of these steps iterate. The RDC-based PIs and senior scientists will specify and implement a meta-database into which all RDCbased projects will be archived. The meta-data will include specifications for all input data sets, a complete, reusable program streams for producing all major statistical results (some disclosable, some confidential) emanating from the project, the disclosure-proofed result file and its supporting data. The project meta-database specs will be completed within the first year and implemented retro-actively on all RDC projects active at the time this grant is awarded. All future RDC users will be required to use the meta-database to archive their results. The ANL team will take charge of creating a high-performance supercluster. The supercluster must be acquired quickly. Each of the cooperating industry sponsors (Intel, Unisys, and SAS) are aware of the requirements and will respond quickly to the acquisition RFP that Census will be required to issue before the supercluster can be acquired. (Census must own and operate the RDC-network computers as required by Title 13 and IRS publication 1075.) The ANL team will assist in writing the specifications for the acquisition and assessing all bids. It is anticipated that the Intel/Unisys will be successful. This will allow the acquisition of the supercluster during the first months that the grant is in progress. The ANL team will spend much of the first year tuning and optimizing the supercluster, with the assistance of RDC-network staff and the vendors, particularly SAS. Some testing will also be performed at Cornell and at ANL. Specific computing tasks are outlined below. Benchmarking. The applications placed on the cluster will be benchmarked for performance against the current computing environment of a single server, and in terms of the number of optimum number of processors for particular models and problem sizes. Benchmark results will provide guidance for supercluster users and reference points for code improvements. Training. Researchers will need to be trained to run their applications on the supercluster. Training will take the form of short seminars and documentation which will present the types of applications suited for a distributed cluster computer, the architecture of the machine, essentials of running a job, and tools to be used in adapting applications to this environment. 6347895 Project Description and Coordination Plan Page 17 Tools Development. Tools will be developed and procured to assist the researchers in porting their application to a distributed environment and to minimize the transition process. Parallel tools for clusters range from high-level (full scientific application analysis) to low level where the programmer has explicit control over all parallelism. In addition, a series of code performance analysis tools (e.g., Jumpshot) will provide the researcher with metrics on the execution itself, which help to locate and explain performance problems in the code and suggest avenues for improvement. The GeoViewer is an object-oriented geographic information system (GIS) developed by Argonne that can be leveraged as needed for this large-scale matching application. Since Argonne owns the code, this GIS application can be customized for RDC-network applications and integrated with other code modules as needed. Computing Environment Task Outline 1. 2. 3. 4. 5. 6. Distributed cluster procurement System setup, software installations and security configuration System checkout, configuration and creation of administrative procedures Tool development and deployment Training development (mini-courses and documentation) and delivery Porting applications and benchmarking How the project will be managed across institutions and disciplines The data synthesizing projects will work as a coordinated team. Abowd will do the coordination. The team will meet weekly by video conference call to review the work plan and discuss issues that have arisen for the research effort. Generally, Abowd will coordinate the creation of RDC projects that provide access to each of the gold-standard data sets to be synthesized. Abowd’s team at the Cornell RDC and inside LEHD will port the existing synthesizers to the RDC-network for review and use by the other teams. Raghunathan and Reiter, working with teams at the Michigan and Research Triangle RDCs, respectively, will develop appropriate synthesizers for data sets assigned to their teams. Roehrig’s team at CMU, which does not have access to an RDC, will develop algorithms in support of all the synthesizing teams. Roehrig’s team will also assist in developing algorithms for assessing the identity and item disclosure risk associated with a particular synthetic data product. Each synthetic data product will go through the following cycle. 1. Identification of the data product to be synthesized (All PIs and senior scientists working with the advisory panel). At this step the costs and potential benefits of each product are evaluated so that the grant’s resources are spent on the projects that are within its means and yield the greatest research benefits. 2. Assignment of a synthesizing team consisting of a senior scientist from this proposal, Census staff at CES, LEHD and selected RDCs, external researchers with projects authorized to use the candidate data 3. Certification of the gold-standard file by the synthesizing team and appropriate Census staff (CES or LEHD). At this point the structure and content of the gold-standard file are locked. 4. Production of a trial synthetic version by the assigned team. 5. Testing of the trial synthetic data product using models from the RDC meta-database and the active RDC researchers on the project team. 6. Disclosure risk assessment of the synthetic data product by a team at one of the RDCs working jointly with the Census Disclosure Review Board 7. Assessment of the tests, then either return to 3 and repeat or release and go to 8 8. Installation of the synthetic data product in the virtual RDC for use by the general research community. 9. Solicitation of RDC projects to further test the validity of the synthetic data product. These researchers can develop their proposals using the virtual RDC. The proposal must include a complete set of results from the synthetic data in RDC meta-database format. 10. Acceptance of some projects to test the synthetic data on the gold-standard. 11. Execution of those projects and certification of their results 12. Assessment of the projects in step 11, then return to step 1 with a proposal to enhance this product based on the tests. Identification of the specific coordination mechanisms The RDC network will be the primary coordination mechanism for the grant. The RDC executive directors meet regularly by conference call. Several executive directors are PIs or senior scientists on this proposal (Bennett, 6347895 Project Description and Coordination Plan Page 18 Hildreth, and Levenstein). They will keep the work of this grant on the active agenda of the RDC executive directors. The complete senior scientific staff of this proposal will meet monthly by video conference to discuss progress on all of the grant’s activities. Each team will make periodic detailed reports on the products they are developing. The necessary video conference equipment will be acquired by each RDC (or exists already at the host organization). The grant will acquire an MCU to support the multipoint conferences. So that Census staff at CES and LEHD can participate, the MCU will have both IP and ISDN capabilities. The budget justification for Cornell describes the MCU equipment. Each RDC location will decide whether to install a workstation based H.323 compatible video conference unit or use the facilities of the host organization/university. The virtual RDC will be maintained at Cornell University. This facility will be expanded as more synthetic data become available. The specifications for mirroring the virtual RDC will be developed and published. 6347895 References Cited Page 1 Abowd, John M. and Lars Vilhuber. “The Sensitivity of Economic Statistics to Coding Errors in Personal Identifiers,” Journal of Business and Economics Statistics, forthcoming. Abowd, John M., John Haltiwanger and Julia Lane, “Integrated Longitudinal Employee-Employer Data for the United States,” American Economic Review Papers and Proceedings, Vol. 94, No. 2 (May 2004): forthcoming. Abowd, John M., John Haltiwanger, Ron Jarmin, Julia Lane, Paul Lengermann, Kristin McCue, Kevin McKinney, and Kristin Sandusky “The Relation among Human Capital, Productivity and Market Value: Building Up from Micro Evidence,” in Measuring Capital in the New Economy, C. Corrado, J. Haltiwanger, and D. Sichel (eds.), (Chicago: University of Chicago Press for the NBER, forthcoming), working paper version LEHD Technical Paper TP-2002-14 (final version December 2002). Abowd, John M, Paul Lengermann and Kevin McKinney, “Measuring the Human Capital Input for American Businesses,” LEHD Technical Paper TP-2002-09 (last revised August 2002). Abowd, John M. and Simon Woodcock, “Disclosure Limitation in Longitudinal Linked Data,” in Confidentiality, Disclosure and Data Access: Theory and Practical Applications for Statistical Agencies, P. Doyle, J. Lane, J. Theeuwes, and L. Zayatz (eds.), (Amsterdam: North Holland, 2001), 215-277. Andersson, Fredrik, Harry Holzer and Julia Lane “The Interactions of Workers and Firms in the Low-Wage Labor Market Urban Institute Research Report available online at http://www.urban.org/url.cfm?ID=410608 (December 2002), cited on February 23, 2004. Arthur, W. B. (1991). “Designing Economic Agents that Act Like Human Agents: A Behavioral Approach to Bounded Rationality.” American Economic Review Papers and Proceedings (May): 353-359. Bonabeau, E., “Agent-based modeling: Methods and techniques for simulating human systems” Proceedings of the National Academy of Sciences of the USA, vol. 99, suppl. 3, pp. 7280-7287, National Academy of Sciences of the USA, Washington, DC, USA: May 14, 2002. Bowlus, Audra and Lars Vilhuber, “Displaced workers, early leavers, and re-employment wages” LEHD Technical Paper TP-2002-18 (last revised November 2002). Card, D.E., Hildreth, A.K.G., and Shore-Sheppard, L.D. “The Measurement of Medicaid Coverage in the SIPP: Evidence from California 1990-1996”, NBER Working Paper 8514 (2001). Forthcoming: Journal of Business and Economic Statistics. Dandekar, Ramesh A. and Lawrence H. Cox, Synthetic Tabular Data: an alternative to complementary cell suppression for disclosure limitation of tabular data. Manuscript (2002). Davis, Steven J. and John Haltiwanger “Gross Job Creation and Destruction: Microeconomic Evidence and Macroeconomic Implications,” NBER Macroeconomics Annual 1990, O. Blanchard and S. Fischer, eds. (Cambridge: MIT Press, 1990), pp. 123-68. Davis, Steven J. and John Haltiwanger “Gross Job Creation, Gross Job Destruction and Employment Reallocation,” Quarterly Journal of Economics 107 (1992): 819-63. Domingo-Ferrer, Josep and Vicenc Torra, “Disclosure Control Methods and Information Loss,” in Confidentiality, Disclosure and Data Access: Theory and Practical Applications for Statistical Agencies, P. Doyle, J. Lane, J. Theeuwes, and L. Zayatz (eds.), (Amsterdam: North Holland, 2001), 91-110. 6347895 References Cited Page 2 Doyle, Pat, Julia Lane, Jules Theeuwes, and Laura Zayatz “Introduction,” in Confidentiality, Disclosure and Data Access: Theory and Practical Applications for Statistical Agencies, P. Doyle, J. Lane, J. Theeuwes, and L. Zayatz (eds.), (Amsterdam: North Holland, 2001), 1-15. Duncan, George and Stephen R. Roehrig, “Mediating the Tension Between Information Privacy and Information Access: The Role of Digital Government”, in Public Information Technology: Policy and Management Issues, Idea Group Publishing, Hershey, PA, 2002. Duncan, George, Karthik Kannan and Stephen R. Roehrig, Final Report on the American FactFinder Disclosure Audit Project for the U.S. Census Bureau, confidential report to the U.S. Bureau of the Census, 2000. Duncan, George T., Thomas B. Jabine, and Virginia A. de Wolf, eds. Private Lives and Public Policies: Confidentiality and Accessibility of Government Statistics, National Academy Press, Washington, 1993. Duncan, George T., Stephen E. Fienberg, Ramayya Krishnan, Rema Padman, and Stephen R. Roehrig, “Disclosure Limitation Methods and Information Loss for Tabular Data,” in Confidentiality, Disclosure and Data Access: Theory and Practical Applications for Statistical Agencies, P. Doyle, J. Lane, J. Theeuwes, and L. Zayatz (eds.), (Amsterdam: North Holland, 2001), 135-166. Duncan, George T. and Diane Lambert “Disclosure Limited Data Dissemination,” Journal of the American Statistical Association, 81:393 (March 1986): 10-18. Duncan, George and Diane Lambert, “The risk of disclosure for micro-data,” Journal of Business and Economic Statistics, 7 (1989): 207-217. Duncan, G. R. Krishnan, R. Padman P. Reuther and Roehrig, S., “Exact and Heuristic Methods for Cell Suppression in Multi-Dimensional Linked Tables,” accepted for Operations Research. Duncan, G., S. Fienberg, R. Krishnan R. Padman, and S. Roehrig, S. “Disclosure Limitation Methods and Information Loss for Tabular Data”, in Confidentiality, Disclosure and Data Access: Theory and Practical Applications for Statistical Agencies, P. Doyle, J.I. Lane, J.J.M. Theeuwes and L.V. Zayatz, eds, NorthHolland, 2001. Duncan, G. and S. Keller-McNulty, “Bayesian Insights on Disclosure Limitation: Mask or Impute,” Bayesian Methods with Applications to Science, Policy, and Official Statistics Selected Papers from ISBA 2000: The Sixth World Meeting of the International Society for Bayesian Analysis, (2000), available online at http://www.stat.cmu.edu/ISBA/165f.pdf, cited on February 23, 2004. Dutta Chowdhury, S., G. Duncan, R. Krishnan and S. Mukhergee and S. Roehrig, “Disclosure Detection in Multivariate Categorical Databases: Auditing Confidentiality Protection Through Two New Matrix Operators”, Management Science December 1999. Elliot, Mark. “Disclosure Risk Assessment,” in Confidentiality, Disclosure and Data Access: Theory and Practical Applications for Statistical Agencies, P. Doyle, J. Lane, J. Theeuwes, and L. Zayatz (eds.), (Amsterdam: North Holland, 2001), 75-90. Entwisle, Barbara "The Contexts of Social Research," in Nancy M.P. King, Gail E. Henderson and Jane Stein (eds.), Reexamining Research Ethics: From Regulations to Relationships. (Chapel Hill, NC: University of North Carolina Press 1999), pp. 153-160. Feinberg, Stephen E. “A Radical Proposal for the Provision of Micro-Data Samples and the Preservation of Confidentiality,” Carnegie-Mellon University Department of Statistics Technical Report No. 611 (December 1994). 6347895 References Cited Page 3 Feinberg, Stephen E, U.E. Makov, and R.J. Steele “Disclosure Limitation Using Perturbation and Related Methods for Categorical Data,” Journal of Official Statistics, 14:4 (1998): 385-397. Feldstein, Martin and Jeffrey Liebman. “Social Security,” Handbook of Public Economics, Volume 4, 2002. Hildreth, A.K.G. and Lee, D.S. "A Guide to Fuzzy Name Matching: Application to Matching LRB/FMCS to ES-202 Data", mimeo, Department of Economics, University of California-Berkeley, September 2003. Holland, J. and J. Miller (1991). “Artificial Adaptive Agents in Economic Theory.” AEA Papers and Proceedings (May): 365-370. Kennickell, Arthur B. “Multiple Imputation in the Survey of Consumer Finances,” SCF Working Paper presented at the 1998 meetings of the American Statistical Association, available online at http://www.federalreserve.gov/Pubs/OSS/oss2/papers/impute98.pdf, cited on February 23, 2004. Lambert, Diane “Measures of disclosure risk and harm (Disc: p333-334),” Journal of Official Statistics, 9 , (1993): 313-331. Liebman, Jeffrey. "The Optimal Design of the Earned Income Tax Credit," in Making Work Pay: The Earned Income Tax Credit and Its Impact on American Families, edited by Bruce D. Meyer and Douglas HoltzEakin. New York: Russell Sage Foundation Press. ct on American Families, 2002. Liebman, Jeffrey B. “Redistribution in the Current U.S. Social Security System,” NBER Working Paper, 2003, available online at http://papers.nber.org/papers/w8625.pdf, cited on February 23, 2004. Liebman, Hildreth, A.K.G. and Lee, D.S. “A Guide to Fuzzy Name Matching: Application to Matching NLRB/FMCS to ES-202 Data”, Report for Labor Market Information Division (LMID), Sacramento, California. Mimeo, Department of Economics, University of California (2003). Little, Roderick J. A., “Statistical analysis of masked data” (Disc: p455-474) (Corr: 94V10 p469), Journal of Official Statistics, 9 ,(1993): 407-426 Mayer, Thomas S. “Privacy and confidentiality Research at the US Census Bureau: Recommendations Based on a Review of the Literature,” Research Report Series Survey Methodology 2002-01, available online at http://www.census.gov/srd/papers/pdf/rsm2002-01.pdf, cited on February 23, 2004. Mazumder, Bhashkar. “Revised Estimates of Intergenerational Income Mobility in the United States,” Federal Reserve Bank of Chicago Working Paper, available online at http://www.chicagofed.org/publications/workingpapers/papers/wp2003-16.pdf, cited on February 23, 2004. North, M., “Towards strength and stability: agent-based modeling of infrastructure markets,” Social Science Computer Review, pp. 307-323, Sage Publications, Thousand Oaks, California, USA: Fall 2001. Raghunathan, T. E., J. M. Lepkowski, J.VanHoewyk and P. Solenberger, “A Multivariate Technique for Multiply Imputing Missing Values Using a Sequence of Regression Models,” Survey Methodology, 2001, 27:85-95. Raghunathan, T.E., J.P. Reiter, and D.B. Rubin, “Multiple Imputation for Statistical Disclosure Limitation,” Journal of Official Statistics, 19 (2003): 1-16. Raghunathan, T.E. and D.B. Rubin, “Multiple Imputation for Disclosure Limitation,” Technical Presentation (available from the authors on request) 2000. Reiter, J. “Inference for Partially Synthetic Public Use Microdata Sets,” Survey Methodology, 29 (2003): 181-188. Reiter, J. “Releasing multiply-imputed, synthetic public use microdata: An illustration and empirical study.” Journal of the Royal Statistical Society, Series A (forthcoming, 2004). 6347895 References Cited Page 4 Resnick, M., Turtles, Termites, and Traffic Jams: Explorations in Massively Parallel Microworlds, MIT Press, Cambridge, Massachusetts, USA: 1994. Riano, D., Prado, S., A. Pascual and S. Martin, “A multi-agent system model to support palliative care units,” Proceedings of the 15th IEEE Symposium on Computer-Based Medical Systems, pp. 35-40, IEEE, Piscataway, New Jersey, USA: June 4-7, 2002. Rindfuss, Ronald “Conflicting Demands Confidentiality Promises and Data Availability,” IHPD Update: Newsletter of the International Human Dimensions Programme on GlobalEnvironmental Change (February 2002), article 1, available online at http://www.ihdp.unibonn.de/html/publications/update/update02_02/Update02_02_art1.html, cited on February 23, 2004. Rubin, Donald B. “Satisfying Confidentiality Constraints Through the Use of Synthetic Multiply-imputed Microdata,” Journal of Official Statistics, 91 (1993): 461-8. Sarathy, Rathindra, Krishnamurthy Muralidhar and Rahul Parsa, “Perturbing Nonnormal Confidential Attributes: The Copula Approach,” Management Science 48:12 (December 2002): 1613-27. Shannon, Claude E. “The Mathematical Theory of Communication,” Bell System Technical Journal, 27 (1948): 379423, 623-656. Sweeney, Latanya. “Information Explosion,” in Confidentiality, Disclosure and Data Access: Theory and Practical Applications for Statistical Agencies, P. Doyle, J. Lane, J. Theeuwes, and L. Zayatz (eds.), (Amsterdam: North Holland, 2001), 43-74. Trottini, Mario and Stephen E. Fienberg, Modelling User Uncertainty for Disclosure Risk and Data Utility. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 10(5), (2002):511-528. Tax Information Security Guidelines for Federal, State, and Local Agencies: Safeguards for Protecting Federal Tax Returns and Return Information, IRS Publication 1075, June 2000. Yancey, William E., William E. Winkler and Robert H. Creecy, “Disclosure Risk Assessment in Perturbative Microdata Protection,” Research Report Series Statistics 2002-01, available online at http://www.census.gov/srd/papers/pdf/rrs2002-01.pdf, cited on February 23, 2004. 6347895 References Cited Page 5 Research Produced at NSF-Supported RDCs Berkeley RDC Card, D, Hildreth, A., and Shore-Sheppard, L., “The Measurement of Medicaid Coverage in the SIPP: Evidence from California, 1990-1996”, NBER Working Paper 8514, 2001. Forthcoming: Journal of Business and Economic Statistics. Dinardo, John and David Lee, “Do Unions Cause Business Failures?” revised March 2003. Previous version: The Impact of Unionization on Establishment Closure: A Regression Discontinuity Analysis of Representation Elections, with John DiNardo, NBER Working Paper #8993, June 2002. Lubotsky, D. “The Labor Market Effects of Welfare Reform”, Forthcoming: Industrial and Labor Relations Review. Lubotsky, D. “Chutes or Ladders? A Longitudinal Analysis of Immigrant Earnings”. Forthcoming: The Journal of Political Economy. Van Biesebroeck, J. “Productivity Dynamics with Technology Choice: An Application to Automobile Assembly”, Review of Economic Studies, 70, 2003. Boston RDC 2000-2004 Black, S. & L. Lynch, "How to Compete: The Impact of Workplace Practices and Information Technology on Productivity," Review of Economics and Statistics, August 2001, 83(3) 434-45. Black, S. & L. Lynch, "What's Driving the New Economy?: the Benefit of Workplace Innovation," Economic Journal, February 2004, 114(493), 97-116. Black, S., L. Lynch & A. Krivelyova, "How Workers Fare When Employers Innovate," Industrial Relations, January 2004, 43(1), 44-66. Black, S. and L. Lynch, "Measuring Organizational Capital in the New Economy," in Carol Corrado, John Haltiwanger and Dan Sichel, editors, Measuring Capital in the New Economy, University of Chicago Press, forthcoming. Black, S. and L. Lynch, "The New Economy and the Organization of Work," in Derek Jones, ed., The Handbook of the New Economy, Academic Press, 2003. Dumais, G., G. Ellison & E. Glaeser, "Geographic Concentration as a Dynamic Process," Review of Economics and Statistics 84 (2), 193-204, May 2002. Bertrand, M. and S. Mullainathan, "Enjoying the Quiet Life? Corporate Governance and Managerial Preferences," Journal of Political Economy, 2003, 111(5), 1043-75. Bernard, A. & J.B. Jensen, "Why Some Firms Export," The Review of Economics and Statistics, forthcoming 2004. Bernard, A., J. Eaton, J.B. Jensen & S. Kortum, "Plants and Productivity in International Trade," American Economic Review 2003, Vol. 93, No. 4, September, 1268-1290. Bernard, A. & J.B. Jensen, "Entry, Expansion and Intensity in the U.S. Export Boom, 1987-1992," Review of International Economics forthcoming. 6347895 References Cited Page 6 Bernard, A. & J.B. Jensen, "Exceptional Exporter Performance: Cause, Effect, or Both?" Journal of International Economics, February 1999, 47(1), 1-25 Berman, E. & L. Bui, "Environmental Regulation and Productivity: Evidence from Oil Refineries," Review of Economics and Statistics, August 2001, 83(3), 498-510. Berman, E. & L. Bui, "Environmental Regulation and Labor Demand: Evidence from the South Coast Air Basin," Journal of Public Economics, February 2001, 79(2), 265-95. Feldstein, M. & J. Liebman, "The Distributional Effects of an Investment-based Social Security System," in M. Feldstein & J. Liebman, eds. The Distributional Aspects of Social Security and Social Security Reform, 2002, NBER Conference Report series, Chicago and London: University of Chicago Press. Liebman, J., "Redistribution in the Current U.S. Social Security System," in M. Feldstein & J. Liebman, eds. Distributional Aspects of Social Security and Social Security Reform, 2002, NBER Conference Report series, Chicago and London: University of Chicago Press Becker, R. & J.V. Henderson, "Effects of Air Quality Regulations on Polluting Industries," Journal of Political Economy, 2000, 108, 379-421. Reprinted in Economic Costs and Consequences of Environmental Regulation, W.B. Gray (ed.), Ashgate Publishing Limited, 2001. ____________, "Effects of Air Quality Regulation", American Economic Review, Vol. 86, no. 4 (September 1996): 789-813. Henderson, J.V., "Marshall's Scale Economies," Journal of Urban Economics, 53(1), 1-28, January 2003. Davis, J. & J.V. Henderson, "Evidence on the Political Economy of the Urbanization Process," Journal of Urban Economics, 53(1), 98-125, January 2003. Beardsell, M. & J.V. Henderson, "Spatial Evolution of the Computer Industry in the USA," European Economic Review, 43(2), February 1999, 431-56. Berry, Steve, Sam Kortum and Ariel Pakes, “Environmental Change and Hedonic Cost Functions for Automobiles,” Proceeding of the National Academy of Sciences, Vol. 93, No.23, pp. 12731-12738. Cooper, R. & A. Johri, "Learning by Doing and Aggregate Fluctuations," Journal of Monetary Economics, 49(8), November 2002, 1539-66. Villalonga, B., "Diversification discount or premium? New evidence from BITS establishment-level data," Journal of Finance, forthcoming. Ioannides, Y. & J. Zabel, "Neighborhood Effects and Housing Demand," April 2000, Journal of Applied Econometrics, Sept.-Oct. 2003, 18(5), 563-84. Downes, T. & J. Zabel, "The Impact of School Characteristics on House Prices: Chicago 1987-1991," Journal of Urban Economics, July 2002, 52(1), 1-25. Ono, Y., "Outsourcing Business Services and the Role of Central Administrative Offices," Journal of Urban Economics, Vol. 53, No. 3, pp. 377-395, May, 2003. Gray, W. & R. Shadbegian, "Plant Vintage, Technology, and Environmental Regulation," Journal of Environmental Economics and Management, November 2003, 46(3), 384-402. Gray, W., ed., Economic Costs and Consequences of Environmental Regulation, Ashgate Publications, 2002. 6347895 References Cited Page 7 Gray, Wayne B. and Ronald J. Shadbegian, "Environmental Regulation, Investment Timing, and Technology Choice", Journal of Industrial Economics, June 1998, pp. 235-256 (also NBER Working Paper 6036, May 1997). Gray, Wayne B. and Ronald J. Shadbegian, "Pollution Abatement Costs, Regulation, and Plant-Level Productivity", in Economic Costs and Consequences of Environmental Regulation, 2002 (also NBER Working Paper 4994, January 1995). Kahn, M., "City Quality-of-Life Dynamics: Measuring the Costs of Growth," Journal of Real Estate Finance and Economics, March-May 2001, 22(2-3), 339-52. Kahn, Matthew, “Particulate Pollution Trends in the United States,” Regional Science and Urban Economics v27, n1 (February 1997): 87-107 Kahn, M., "The Silver Lining of Rust Belt Manufacturing Decline," Journal of Urban Economics, November 1999, 46(3), 360-76. Kahn, M., "Smog Reductions Impact on California County Growth," Journal of Regional Science, August 2000, 40(3), 565-82. Lynch, Lisa M.; Black, Sandra E “Beyond the Incidence of Employer-Provided Training,” Industrial and Labor Relations Review v52, n1 (October 1998): 64-81 Mead, C.I., "The Impact of Federal, State, and Local Taxes on the User Cost of Capital," Proceedings: Ninetysecond Annual Conference on Taxation, National Tax Association, 2000, 487-92, Washington, D.C.: National Tax Association. Okamoto, Y., "Multinationals, Production Efficiency, and Spillover Effects: The Case of the U.S. Auto Parts Industry," Weltwirtschaftliches Archiv., 1999, 135(2), 241-60. Rajan, R., P. Volpin, & L. Zingales, "The Eclipse of the U.S. Tire Industry," in Kaplan, S., ed., Mergers and productivity, 2000, 51-86, NBER Conference Report series. Chicago and London: University of Chicago Press. Schuh, Scott and Robert Triest, “Gross Job Flows and Firms,” American Statistical Association Proceedings of the Government Statistics Section, 1999. Schuh, S. & R. Triest, "The Role of Firms in Job Creation and Destruction in U.S. Manufacturing," Federal Reserve Bank of Boston New England Economic Review, March-April 2000, 0(0), 29-44. Shadbegian, Ronald J. and Wayne B. Gray, "What Determines Environmental Performance at Paper Mills? The Roles of Abatement Spending, Regulation, and Efficiency" Topics in Economic Analysis & Policy, November 2003. Tootell, G., R. Kopcke & R. Triest, "Investment and Employment by Manufacturing Plants," Federal Reserve Bank of Boston New England Economic Review, 2001, 0(2), 41-58. Unpublished papers Davis, James, “Headquarters, Localization Economies and Differentiated Service Inputs,” Mimeo, December 2000. Freeman, Richard and Morris Kleiner, “The Last American Shoe Manufacturers: Changing the Method of Pay to Survive Foreign Competition,” Mimeo, March 1998. 6347895 References Cited Page 8 Gray, Wayne and Ronald Shadbegian, “Technology Change, Emissions Reductions, and Productivity,” Mimeo, January 2001. Gray, Wayne and Ronald Shadbegian, “When is Enforcement Effective – or Necessary?” Mimeo, August 2000. Hwang, Margaret and David Weil, “Who Holds the Bag?: The Impact of Information Technology and Workplace Practices on Inventory,” Mimeo, December 1997. Kahn, Matthew, “Does Smog Regulation Displace Private Self Protection?” Mimeo, January 1998. Kiel, Katherine and Jeffrey Zabel, “The Impact of Neighborhood Characteristics on House Prices: What Geographic Area Constitutes a Neighborhood?” Mimeo, March 2000. Lynch, Lisa and Anya Krivelyova, “How Workers Fare When Workplaces Innovate,” Mimeo, June 2000. Mead, C. Ian, “An empirical examination of the Determinants of New Plant Location in Four Industries,” Mimeo, November 2000. Ono, Yukako, “Outsourcing Business Service and the Scope of Local Markets,” Mimeo, July 2001. Schuh, Scott and Robert Triest, “Job Reallocation and the Business Cycle: New Facts for an Old Debate,” Mimeo, June 1998. Shadbegian, Ronald, Wayne Gray and Jonathan Levy, “Spatial Efficiency of Pollution Abatement Expenditures,” Mimeo April 2000. Chicago RDC Boyd, G., G. Tolley, and J. Pang, "Plant Level Productivity, Efficiency, and Environmental Performance: An Example from the Glass Industry," Environmental and Resource Economics. 23(1):29-43 (Sept. 2002). Boyd, G., and J. Pang, "Estimating the Linkage between Energy Efficiency and Productivity," Energy Policy 28:289-96 (2000). Boyd, G., and J. Pang, “Estimating the Linkage between Energy Efficiency and Productivity,” Energy Policy 28:289-96 (2000). Boyd, G., and J. McClelland, “The Impact of Environmental Constraints on Productivity Improvement and Energy Efficiency in Integrated Paper Plants,” The Journal of Economics and Environmental Management 38:121146 (1999). Boyd, G., J. Dowd, J. Freidman, and J. Quinn, “Productivity, Energy Efficiency, and Environmental Compliance in Integrated Pulp and Paper and Steel Plants,” ACEEE Industrial Summer Study, Grand Island, NY (Aug. 14, 1995). Boyd, G., J. McClelland, and M. Ross, “The Impact of Environmental Constraints on Productivity Improvement and Energy Efficiency in Integrated Paper and Steel Plants,” Proceedings of the 18th IAEE International Conference, Into the 21st Century: Harmonizing Energy Policy, Environment, and Sustainable Economic Growth, Washington, DC (July 5-8, 1995). Boyd, G., and J. McClelland, “Strategies for Reconciling Environmental Goals, Productivity Improvement and Increased Energy Efficiency in the Industrial Sector: An Analytic Framework,” Proceedings, Energy Efficiency and the Global Environment: Industrial Competitiveness and Sustainability, Newport Beach, CA, sponsored by Southern California Edison Company (Feb. 8-9, 1995). 6347895 References Cited Page 9 Bock, M., G. Boyd, S. Karlson, and M. Ross, “Best Practice Electricity Use in Steel Minimills,” Iron and Steel Maker, pp. 63-67 (May 1994). Boyd, G., S. Karlson, M. Neifer, and M. Ross, “Energy Intensity Improvements in Steel Minimills,” Contemporary Policy Issues XI(3):88-99 (July 1993). Boyd, G., S. Karlson, M. Neifer, and M. Ross, “Vintage Effects in the Steel Industry: The Potential for Energy Intensity Improvements,” Western Economics Association International 67th Annual Conference, San Francisco, CA (July 9-13, 1992). U.S. Department of Energy, The Interrelationship between Environmental Goals, Productivity Improvement, and Increased Energy Efficiency in Integrated Paper and Steel Plants, USDOE/PO-055 Technical Report 5 (June 1997). Boyd G., M. Bock, S. Karlson, and M. Ross, Vintage-Level Energy and Environmental Performance in Manufacturing Establishments, ANL/DIS/TM-15 (May 1994). Bock, M.J., G. Boyd, D. Rosenbaum, and M. Ross, Case Studies of the Potential Effects of Carbon Taxation on the Stone, Clay, and Glass Industries, ANL/EAIS/TM-91 (Dec. 1992). Boyd, G., M. Neifer, and M. Ross, Modeling Plant Level Industrial Energy Demand with the Longitudinal Research Database and the Manufacturing Energy Consumption Survey Database, ANL/EAIS/TM-96 (Jan. 1992). Syverson, Chad. "Product Substitutability and Productivity Dispersion." Review of Economics and Statistics, 2004. Syverson, Chad. "Market Structure and Productivity: A Concrete Example." Syverson, Chad. "Prices, Spatial Competition, and Heterogeneous Producers: An Empirical Test" Conference Proceedings (published paper) Boyd, G., "Parametric Approaches for Measuring the Efficiency Gap between Average and Best Practice Energy Use," 2003 ACEEE Summer Study on Energy Efficiency in Industry: Sustainability and Industry: Increasing Energy Efficiency and Reducing Emissions (July 29-Aug. 1, 2003). Submitted under review Boyd, G., "A Statistical Model for Measuring the Efficiency Gap between Average and Best Practice Energy Use: The ENERGY STAR(tm) Industrial Energy Performance Indicator," submitted to Journal of Industrial Ecology. Paper was also presented to 2003 International Society for Industrial Ecology Second International Conference, University of Michigan, Ann Arbor, MI (June 29-July 2, 2003) Oral Presentations Boyd, G., "Development and Testing Experience with the Energy Performance Indicator (EPI)," ENERGY STAR(r) Corn Refiners Industry Focus Meeting, Washington, DC (December 2003) Boyd, G., and T. Hicks, "Energy Performance Indicators," ENERGY STAR(r) Motor Vehicle Industry Focus Meeting and ENERGY STAR(r) Brewery Industry Focus Meeting, Washington, DC (June 2002). 6347895 References Cited Page 10 Hubbard, Tom "Hierarchies and the Organization of Specialization" Carnegie-Mellon University, February 2004 Columbia University, January 2004 American Economic Association, January 2004 University of Pennsylvania–The Wharton School, December 2003 Yale University, December 2003 University of Chicago, December 2003 University of California, Los Angeles, November 2003 University of Indiana, October 2003 University of Toronto, September 2003 University of California, San Diego, September 2003 Hubbard, Tom "Specialization, Firms, and Markets: The Division of Labor Within and Between Law Firms" Federal Reserve Bank of Chicago, May 2003 Dartmouth College, April 2003 Cornell University, April 2003 U.S. Department of Justice, April 2003 University of Virginia, April 2003 University of California, Los Angeles, April 2 003 National Bureau of Economic Research, January 2003 INSEAD, November 2002 London School of Economics, November 2002 University of Chicago, November 2002 Yale University, November 2002 New York University, November 2002 Bureau of the Census, September 2002 European Economic Association, July 2002 Stanford Institute for Theoretical Economics, June 2002 Michigan RDC Conference Presentations Christopher Kurz and James Levinsohn, ““Plant-Level Responses to Administered Trade Protection” Midwestern Economics Association, Chicago, IL March 2004. Christopher Kurz, “Production Sharing at the Plant Level” Midwestern Economics Association, Chicago, IL March 2004. Triangle RDC P. J. Cook and J. Ludwig, "The Effects of Gun Prevalence on Burglary: Deterrence vs Inducement" in J Ludwig and PJ Cook (eds.) Evaluating Gun Policy Washington, DC: Brookings Institution Press, 2003: 74-118. Submitted under review Chen, Susan and Wilbert van der Klaauw, "The Effect of Disability Insurance on Labor Supply of Older Individuals in the 1990s" Unpublished Manuscript, January 2004 (submitted for publication). Presented at the University of Michigan Economics of Aging Seminar, March 2004. Cutler, David, Edward Glaeser and Jacob Vigdor, "The Decline and Rise of the Immigrant Ghetto," North American Regional Science Council annual meeting November 2003. 6347895 References Cited Page 11 UCLA RDC Publications Ellis, Mark, Richard Wright, and Virginia Parks (2003) “Work together, live apart? Geographies of Residential and Workplace Segregation in Los Angeles” Forthcoming, Annals of the Association Of American Geographers Ellis, M. and Odland, J. “Intermetropolitan Variation in the Labor Force Participation of White and Black Men in the United States”, Urban Studies, 38, 2001. Moretti, Enrico "Workers' Education, Spillovers and Productivity: Evidence from Plant-Level Production Functions" AER, forthcoming. Moretti, E., “Estimating the Social Return to Higher Education: Evidence from Longitudinal and Repeated CrossSection Data”, Forthcoming: Journal of Econometrics. Robert Pedace and David Fairris "The Impact of Minimum Wages on Job Training: An Empirical Exploration with Establishment Data,". Southern Economic Journal, Vol. 70, No. 3 (2004). (CES Discussion Paper 03-04) John R. Logan, Richard D. Alba, and Wenquan Zhang. 2002. "Immigrant Enclaves and Ethnic Communities in New York and Los Angeles" American Sociological Review 67 (April):299-322. Wright, R. and Ellis, M. “Race, Region and the Territorial Politics of Immigration”, International Journal of Population Geography, 6, 2000. Unpublished Papers Holloway, Steven R., Mark Ellis, Richard Wright, Margaret Hudson (2003) “Partnering “Out” and Fitting In: Residential Segregation and the Neighborhood Contexts of Mixed-Race Households” (under review). Krivelyova, Anya and Lisa Lynch, “Changes in the Demand for Labor – The Role of Skill Biased Organizational Change,” Mimeo, September 2000. Valdez, Zulema. 2003. “Beyond Ethnic Entrepreneurship: Ethnicity and the Economy in Enterprise”. Center for USMexican Studies, Working Paper Series, usmex_02_07. http://repositories.cdlib.org/usmex/usmex_02_07. Under review at American Sociological Review. Valdez, Zulema. 2002. “Two Sides of the Same Coin? The Relationship between Socioeconomic Assimilation and Ethnic Entrepreneurship among Mexicans in Los Angeles”, in Latina/o Los Angeles: Global Transformations, Settlement, and Activism. Edited by Enrique C. Ochoa and Gilda Laura Ochoa. Volume currently under review at Rutgers University Press. Valdez, Zulema. 2003. “From the Enclave to the Ethnic Economy: The Effects of Ethnic Agglomeration and Ethnic Solidarity on Entrepreneurship”. Under review at International Migration Review. Wright, Richard, Mark Ellis and Virginia Parks (2003) “Re-placing Whiteness in Spatial Assimilation Research” (under review). 6347895 References Cited Page 12 New York City Baruch RDC The Baruch RDC is scheduled to open in 2004. It has not yet begun accepting proposals. Cornell RDC The Cornell RDC is scheduled to open in 2004. John Abowd will transfer many of his approved projects from the LEHD computers to the Cornell RDC. His participation in the LEHD Program is documented in the main proposal.