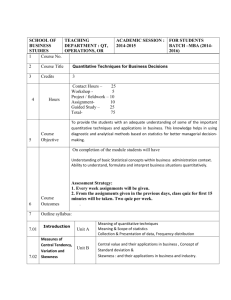
PY3 revision booklet
advertisement

UNIT PY3 – PSYCHOLOGY: RESEARCH METHODS AND ISSUES IN RESEARCH This Unit develops the candidate’s knowledge, application and evaluation of research methods acquired in PY2. The Unit assesses the candidate's knowledge, understanding and evaluation of research methods, data analysis and issues in research. This includes the consideration of scientific and ethical issues in the design and implementation of an investigation. UNIT PY3 – PSYCHOLOGY: RESEARCH METHODS CARRY OVER FROM PY2 Candidates should be able to: • Define and offer advantages and disadvantages of qualitative and quantitative research methods including laboratory experiments, field experiments, natural experiments, correlations, observations, questionnaires, interviews and case studies. • Issues of reliability and ways of ensuring reliability (split-half, test-retest, interrater). • Issues of validity (experimental and ecological) and ways of ensuring validity (content, concurrent, construct). • Ethical issues relating to research including a lack of informed consent, the use of deception, a lack of the right to withdraw from the investigation, a lack of confidentiality, a failure to protect participants from physical and psychological harm. • Define and offer advantages and disadvantages of different sampling methods including opportunity, quota, random, self-selected (volunteer), stratified and systematic. • Define and offer advantages and disadvantages, and draw conclusions from the following ways of describing data, including: - Development of a coding system - Mean - Scattergraphs - Content analysis - Median - Bar charts - Categorisation - Mode - Histograms - Range UNIT PY3 – PSYCHOLOGY: RESEARCH METHODS AND ISSUES IN RESEARCH Research Methods Aims and hypotheses (directional, non-directional and null hypotheses) Design issues relating to specific research methods, and their relative strengths and weaknesses Operationalisation of independent variables, dependent variables and covariables Ways of overcoming confounding variables Ethical issues and ways of overcoming these issues Procedures, including sampling and choice of apparatus Appropriate selection of descriptive and inferential statistics for analysis of data Levels of measurement which include, nominal level, ordinal level, interval and ratio level - Levels of significance Statistical tests including Chi-squared Test, Sign Test, Mann Whitney U Test, Wilcoxon Matched Pairs, Signed Ranks Test, and Spearman’s Rank Order Correlation Coefficient. Issues relating to findings and conclusion, including reliability and validity Issues in Research • The advantages of the use of the scientific method in psychology • The disadvantages of the use of the scientific method in psychology • Ethical issues in the use of human participants in research in psychology • Ways of dealing with ethical issues when using human participants in research in psychology • Ethical issues in the use of non-human animals in research in psychology • Ethical issues arising from two applications of psychology in the real world (e.g. advertising, military) 2 AIMS AND HYPOTHESIS The experimental method is the method of investigation most often used by psychologists. The essence of the experimental method is that involves a generally high level of control over the experimental situation, and the manipulation of whatever aspect of the situation is of primary interest. It can be used for laboratory experiments in controlled conditions or for field experiments carried out under more natural conditions. (A) Let’s say, for example, we wanted to investigate if studying with a background of music affects students’ academic performance. We could set up an experiment. We might select two groups of students. Group A would study material with a background of music. Group B would study the same material. We could then test the students on the material they have been studying and compare the scores. The findings would tell us something about the performance of students and from these students we could draw our conclusions. Most laboratory experiments start with someone thinking of an experimental hypothesis. This is simply a prediction or expectation of what will happen. For example in (A), you might make one of three hypotheses: 1. Working with a background of music improves students’ learning. 2. Working with a background of music reduces students’ learning. 3. Working with a background of music affects/influences students’ learning. Numbers 1 and 2 are examples of what we call a directional hypothesis (also called ‘one-tailed’) This is because 1. and 2. point in the direction of what we predict will happen. In research, we will usually formulate a directional hypothesis if we have sound grounds for believing this will be the out come – for example, if previous research this is the likely outcome of the experiment. Number 3 is an example of what we call a non-directional hypothesis (also called ‘twotailed’). This is because we are not suggesting what the likely outcome will be but only that there is likely to be an outcome – in this case that working to a background of music will have some kind of effect on students’ learning but we are not predicting in which direction. We would normally choose a non-directional hypothesis when there is no previous research predicting the likely outcome of the experiment. There is a second kind of hypothesis we can make, and it is called the null hypothesis. The null hypothesis simply states that playing background music will have no effect on the students’ learning. In a sense, the aim of most laboratory experiments is to decide whether the findings obtained by the experiment are more in line with the experimental hypothesis or with the null hypothesis. In research our aim is usually to disprove the null hypothesis. 3 THE EXPERIMENTAL METHOD Drinking coffee makes you feel more alert? Most people believe this to be true but psychologists are not going to accept this statement is true until they test it out. After all, most people in the world believed the Sun revolved round the Earth until the theory/hypothesis was tested and it was demonstrated that the Earth in fact revolves round the Sun. So, the rule is: state your hypothesis, then find a way to test it. In psychology we like to use, when we can, what is called the experimental method. BTW, the caffeine in your coffee does reduce reaction times (i.e. makes people react faster), especially at lower doses – for example, one or two cups of coffee per day, The experimental method refers to the research method where select a number of participants, then put them in a situation where we can change one condition (the independent variable) and watch its effect (the dependent variable) on the behaviour of the participants. For example, we may select a group of participants, set them a number of tasks, and then test their reaction times. We then take the same or a similar group of participants, get them to drink a couple of cups of coffee, then test their reaction times on the same tasks. If there is any change in the reaction times, we can assume that it is the caffeine that has made the difference. Hypothesis: The amount of revision that students do affects their level of exam success. independent variable dependent variable The experimenter manipulates an IV to see its effect on the DV. The IV is the variable that’s manipulated or altered by the experimenter to see its effect on the DV. The DV is the measured result of the experiment. Any change in the DV should be as a result of the manipulation of the IV. For example, the amount of revision time (IV) could be manipulated to see its effect on reaction time (DV). Extraneous variables (as we shall see) are any other variables that may have an effect on the DV. For example, if it turned out that some of the students in our revision group were getting extra revision from a tutor at home, we would exclude them from our experiment because we would not be able to assess the effect of this variable on their performance. Controls are employed to prevent extraneous variables spoiling the results, Any extraneous variables that aren’t controlled can become confounding variables, so called because they ‘confound’ (confuse) the results. For example, what if we discovered that one of the participants in the caffeine (IV)-reaction times (DV) took a splash of whisky in their coffee, we would have to exclude him/her! 4 There are several types of experiment as described below. Laboratory experiments take place in controlled environments Psychologists like laboratory experiments because the researcher can control most of the variables. There’s control over the ‘who, when, where and how’. This is usually done in a laboratory using standardised procedures but they can be conducted anywhere provided it’s in a control environment. Participants should also be randomly allocated to experimental groups. Examples of ‘laboratory’ experiments include: Asch (1951), Milgram (1963) and Bandura’s (1965) bobo doll study. Advantages of laboratory experiments High degree of control: experimenters can control all variables in the situation. The IV and DV can be precisely defined (operationalised) and measured - for example, the amount of caffeine given (IV) and the reaction times (DV). This leads to greater accuracy and objectivity. Replication: other researchers can easily repeat/replicate the experiment and check the results. This is an important feature of the experimental method. Cause and effect: it should be possible to determine the cause-effect relationship between the IV and the DV – caffeine does cause faster reaction times – provided that the experiment is well-designed. Technical equipment: it’s easier to use complicated technical equipment in a laboratory. Stronger effects outside the laboratory? Laboratory experiments are often criticised for being artificial, but it may be the case that some laboratory effects are even stronger outside the lab than those recorded within it. For example, Milgram’s study of obedience (1963) demonstrated high levels of obedience in the lab situation, but it is likely that the effects are even stronger outside the laboratory where obedience is associated with social pressure and the likelihood of painful sanctions from authority figures. Weaknesses of laboratory experiments o Experimenter/researcher bias: sometimes an experimenter’s expectations about the study can affect the results. There is always the temptation to see what you expect to see. Participants may be influenced by these expectations. o Problems operationalising the IV and DV: sometimes in order to gain a precise measure of behaviour, the measure itself becomes too specific and does not relate to wider behaviour. For example, Bandura’s measures of aggression towards the bobo doll involved only a very narrow range of the kind of hostile behaviour of which children are capable, e.g. excluding another child from the group. o Low external (ecological) validity: the high degree of control can make the experimental situation feel artificial and unlike real life. Did all of Milgram’s participants really believe they were giving potentially fatal electric shocks? As 5 such, it may be difficult to generalise results to other settings and to the real world. A laboratory setting can be a strange and intimidating place. As such, people may be overly worried about their surroundings and not act in a way that is representative of their normal everyday behaviour. o Demand characteristics: sometimes participants try to guess the purpose of the experiment and then act according to the ‘demands’ of the experiment. Some of Milgram’s participants probably guessed that nobody was actually being shocked and tried to give the experimenter what they thought he wanted. In contrast, participants may guess the purpose of the experiment and act in a deliberately contradictory way, the so-called ‘screw you’ effect. Field experiments are performed in the ‘real world’ A field experiment is an experiment performed in the ‘real world’ rather than in a laboratory. However, the IV is still manipulated by the experimenter and as many other variables as possible are controlled. For example, if we wish to test whether people are likely to obey authority figures, we could dress in four different ways, stand outside a railway station, drop a piece of litter on the ground, point to a passerby and say, “Pick that up.” We could dress in (a) everyday clothes, (b) as a milkman, (c) as a soldier, and (d) as a policeman. We could count the number of times passers-by (our participants) followed the instruction to pick our litter up. Name the IV and the DV. Natural experiments take advantage of a situation where the ‘natural IV’ can be expected to have some effect on the DV In natural experiments, the IV occurs naturally; it is not manipulated by the experimenter. The experimenter records the effects on the DV. For example, we might study the effect of being raised in care on teenagers’ academic performance in school. Do teenagers raised in care do better or worse or the same as teenagers not raised in care? An advantage here is that the effect of an IV (being raised in care) can be studied where it would be unethical to deliberately manipulate it (e.g. putting children in care for years just to see the effect on their academic performance!). Strictly speaking, a natural experiment is a quasi-experiment because the random allocation of participants is not possible. Advantages of field experiments and of natural experiments High ecological validity – since these experiments take place in the ‘real world’, or a naturally occurring environment, results are more likely to relate to everyday behaviour and can be generalised to other settings. No demand characteristics – often participants are unaware that an experiment is taking place, so there are no demand characteristics. 6 Weaknesses of field experiments and of natural experiments Less control over the variables: it is far more difficult to control extraneous variables, either ‘in the field’ or in naturally occurring situations. Replication: it is difficult to precisely replicate field or natural experiments since the conditions will never be precisely the same again. Ethics: there are ethical issues (e.g. informed consent, deception) when participants aren’t aware they are taking part in an experiment, e.g. the passers-by at the railway station instructed to pick up litter. This applies more to field experiments because in the natural experiments the IV occurs naturally and isn’t being manipulated by the experimenter. Sample bias: since participants aren’t randomly allocated to groups, there may be some sample bias. Time-consuming and expensive: experiments in the real world can often take more time and involve more costs than those in the laboratory. Researchers often have to consider many other aspects of the design and how it may affect other people in the vicinity of the experiment, which they don’t have to do in the comfort of their own laboratory. ‘Lord of the Flies’ – A Social Identity Experiment The ‘Robbers Cave Experiment’ is a classic social psychology experiment conducted with two groups of 11-year old boys at a state park in Oklahoma, and demonstrates just how easily an exclusive group identity is adopted and how quickly the group can degenerate into prejudice and antagonism toward outsiders. Researcher Muzafer Sherif actually conducted a series of 3 experiments. In the first, the groups banded together to gang up on a common enemy. In the second, the groups banded together to gang up on the researchers! By the third and final experiment, the researchers managed to turn the groups on each other. 7 STUDIES USING CORRELATIONAL ANALYSIS Let’s consider this hypothesis: Older people are more forgetful. We can’t say that old age causes forgetfulness but we suspect that there is a relationship between old age and becoming more forgetful. In research, we have a particular way of investigating the relationship between two variables where we cannot say that one variable causes a change in the other variable. This is called correlational analysis. Correlational analysis simply means analysing the relationship between two variables (e.g. old age and forgetfulness) and measuring the strength of that relationship. Here are 5 hypotheses where correlational analysis would be appropriate. Can you explain why? a) Good-looking people are more successful in their careers. b) Playing violent video games encourages real-life violence. c) The longer you spend revising, the less worried you become. d) The better the teaching, the more successful the students. e) Sales of ice-cream increase as the temperature increases. Correlational analysis isn’t a research method as such; it is a method of analysing the data. It involves measuring the strength of the relationship between two or more variables (co-variables) to see if a trend or pattern exists between them. Name the co-variables in the hypotheses above. A positive correlation is where one variable increases as the other variable increases – e.g. ice cream sales increase as the temperature increases. A negative correlation is where one variable increases as the other variable decreases – e.g. as the temperature goes up, the sale of woolly jumpers goes down If there is no correlation between two variables, they are said to be uncorrelated. 8 A correlation coefficient refers to a number between -1 and +1 and states how strong a correlation is. If the number is close to +1 then there is a positive correlation. If the number is close to -1 then there is a negative correlation. If the number is close to 0 then the variables are uncorrelated. Advantages of correlational analysis Allows predictions to be made: once a correlation has been found, we can make predictions about one variable from the other (.e.g. if we find the correlation coefficient between the sales of ice-cream and the rise in temperature is +0.98, we can safely buy in lots of ice cream because we know we can easily sell them on the beach on a hot day.) Allows the quantification of relationships: correlations can show the strength of the relationship between two co-variables (rise in temperature and the sales of ice cream) in quantifiable terms. A correlation of +0.9 means a high positive correlation; a correlation of +0.3 indicates a fairly weak positive correlation. No manipulation: correlations do not require the manipulation of behaviour, and so can be a quick and ethical method of data collection and analysis. Weaknesses of correlational analysis o Correlation can never show that one variable caused the other variable to change: it cannot be assumed that one variable caused the other. There may be a strong relationship between the rise in temperature and the sales of ice cream but we cannot assume that the rise in temperature caused the rise in the sales of ice cream. There is no cause and effect in correlation, only relationship. o Extraneous relationships: other variables may influence both the co-variables. For example, most holidays are taken in the (hot?) summer and people tend to eat ice cream when they are on holiday. Therefore, the variable ‘holiday’ is related to both temperature and to ice cream sales. o Quantification problem: it is worth noting that sometimes correlations that appear to be quite low (e.g. +0.28) can be meaningful or significant if the number of scores recorded is quite high. Conversely, with a large number of recorded scores, correlations that are quite high (e.g. +0.76) are not always statistically significant or meaningful You must be aware of this when interpreting correlation co-efficient scores. o Correlational analysis only works for linear relationships: correlations measure only linear (straight-line) relationships. For example, we know that a person’s feelings of aggression increase in relation to a rise in temperature, but when the temperature rises past a particular point, the feelings of aggression begin to decrease (because the person becomes exhausted). This means the relationship between aggression and temperature is curvilinear, so correlational analysis would not be appropriate. 9 When carrying out correlational analysis the data is summarised by presenting the data in a scattergram (or scattergraph). It is important that the scattergram has a title and both axes are labelled. From the scattergram we may be able to say whether there is a strong positive correlation, a weak positive correlation, no correlation, a weak negative correlation or a strong negative correlation but we can not make a conclusion about the hypothesis. Test Yourself 1. 2. 3. 4. 5. Outline two conclusions that can be draw from this scattergram. Suggest an appropriate experimental hypothesis for this investigation. Suggest an appropriate null hypothesis for this investigation. Outline one strength and on weaknesses of correlational analysis. Suggest an alternative way that one of the variables could have been measured. 10 STATISTICAL TESTS In research, psychologists often gather a lot of data. They need to analyse the data. They often employ a statistical test to analyse the data, to find out if the data is significant or meaningful.In the examination, you are likely to be asked a question such as: Explain why the …………………….. test was used to analyse these results. [2] In order to choose the correct test, you need to correctly answer three questions: _ What are you testing for? Association (correlation) OR Difference _ What type of data do you have? Nominal, Ordinal, Interval (or Ratio) _ Do you have related or unrelated data? Independent measure or repeated measures or Matched pairs. When you have this information you can select the test by using the graph below. Design Nominal data Ordinal data Interval data Repeated measures Sign test Wilcoxen T Wilcoxen T Matched pairs Sign test Wilcoxen T Wilcoxen T Independent measures Chi square Mann Whitney U Mann Whitney U Correlation Chi square Spearmans Rank Spearmans Rank 11 DIFFERENT KINDS OF DATA There are different kinds of data, and before we go on to look at the different statistical tests, we need to know what the different kinds of data are. Nominal data occur when the data are in separate groups or category; in other words, the groups are ‘named’. For example, if we divide the participants into supporters of Liverpool, Arsenal, Chelsea and Manchester United, this would provide nominal data. Ordinal data occur when the data are ordered in some way. For example, we might ask our participants to put a list of football teams in order of liking: 1st, 2nd, 3rd, 4th and so on. The ‘difference’ between items is not the same, i.e. a participants might like the firstnamed team a lot more than he likes the second-named team, but there might only be a small difference between his second-named team and his third-named team. Interval data are measured using units of equal intervals, such as when counting correct answers, or using any ‘public’ unit of measurement. An interval scale is one in which intervals at different points on the scale are equal. Examples are the Celsius and Fahrenheit temperature scales. The difference between 20 and 22 degrees is the same as the difference between 15 and 17 degrees. Ratio data occurs when there is a true zero point, as in most measures of physical quantities. A ratio scale is similar to an interval scale except that whereas the zero point in an interval scale is arbitrary, the ratio scale has a true zero point. Temperature measured in degrees Kelvin is a ratio scale. It has a true zero point, whereas the zero point on the Celsius scale is arbitrarily placed as the freezing point of water. Other substances have different freezing points, and any of them or none could have been chosen. Quantities such as milligrams of alcohol consumed in a day, or hours of work done on a task, height and weight are also ratio scales. LEVELS OF SIGNIFICANCE - PROBABILITY What do we mean by ‘probability’? Are you more likely to die from a car accident or from being struck by a bolt of lightning? There’s another way to ask this question. What are your chances of being struck by a bolt of lightning? And still another way: what is the probability of being struck by a bolt of lighting? Probability is a proportion based on how often an outcome occurs. Sometimes the level of probability is easy to work out. For example: what are your chances of rolling the number 6 each time you roll a die? Of 12 course you immediately said it’s 1/6 (one in six). But how did you work it out? Here’s what you did. What is the probability of getting a 6 on a single throw of a dice? The probability of any particular outcome is a fraction (proportion) of all possible outcomes Probability of Outcome A = Number of outcomes classified as A = 1 = 1/6 Number of all possible outcomes 6 How can probability help us in psychology? In Psychology, as in all other sciences, we like to draw conclusions. Another word for conclusions is inferences. And that is what ‘inferential’ statistics is about. What inferences can we draw from our data? Let’s see if our newly-invented anti-ageing cream works. First let’s get a random sample of participants, all of whom are 40 year old. There must be no bias in our sample. Let’s measure how old they ‘look’ and get an average/mean score. Now they must apply our anti-ageing cream for the next four weeks. At the end of this period let’s measure how old they look again and work out the average/mean score. Now we will analyse the scores to see if there is a significant difference. Is the difference between ‘before’ and ‘after’ big enough for me to conclude that the anti-ageing cream works? Level of significance - the magic 5% You will note that most psychology reports have a line like this: The level of significance was 5%..... In statistics, a result is called statistically significant if it is unlikely to have occurred by chance. "A statistically significant difference" simply means there is statistical evidence that there is a difference; it does not mean the difference is necessarily large, important, or significant in the common meaning of the word. The significance level is usually represented by the Greek symbol, α (alpha). Popular levels of significance are 5%, 1% and 0.1%. For example, if someone argues that "there's only one chance in a thousand this could have happened by coincidence," a 0.1% level of statistical significance is being implied. The lower the significance level, the stronger the evidence. 13 With our anti-ageing cream, if we can meet the 5% level of significance, which is pretty ‘freaky’, we can be pretty sure that our treatment has worked and we’d better get on with marketing it as quickly as possible! We can define a ‘freaky’ score as one that occurs less than 5% of the time. These scores are very unlikely to be obtained by 40 years old who have not taken our treatment. Scores like this provide evidence that our treatment works. Scores that meet the 5% target can be relied on as evidence that supports the alternative hypothesis; anything less than 5% and it’s safer to accept the null hypothesis. Note: if you look at the tables for Chi-squared, the Sign test, Spearman rho, the MannWhitney U test, and the Wilcoxon test in Psychology A2 The Complete Companion (Nelson Thornes)(306-310), you will see that every table is headed by ‘Critical values of…. at the 5% level. 14 The Control of Extraneous Variables Let us return to our investigation of whether background music helps learning, hinders learning, or has no effect on learning. Let’s use two groups of students. Let’s call working in silence Condition 1 and working with a background of music Condition 2. We will need to control a number of extraneous variables to ensure that these variables do not turn into confounding variables. After all, we want to focus on how background music might influence learning and not on any other variables. Extraneous variables might include the ages of the students, difficulty of the material being studied, intelligence of the students, and so on. If we discovered after carrying out the experiment that the students in Condition 1 were considerably brighten that the students in Condition 2, we could no longer be sure that any differences in learning were due to the presence of music in the background. Intelligence might be acting as a confounding variable. In any experiment, the IV (music or silence) is manipulated and the DV (amount of learning) is measured. It is assumed that the IV causes any change or effect in the DV. Any other variables that may affect the DV are called extraneous variables. If they do affect the DV, becoming confounding variables. Extraneous variables must be carefully and systematically controlled so they don’t vary across any of the experimental conditions or, indeed, between participants. When designing an experiment, researchers should consider three main areas where extraneous variables may arise. 1) Participant variables: participants’ age, intelligence, personality and so on should be controlled across the different groups taking part. 2) Situational variables: the experimental setting and surrounding environment must be controlled. This may even include the temperature or noise effects. 3) Experimenter variables: the personality, appearance and conduct of the researcher. Any change in these across the conditions of the experiment might affect the results. For example, would a female experimenter have recorded lower levels of obedience than the male experimenters in Milgram’s obedience to authority studies? Extraneous variables are not a problem unless they become confounding variables. If they aren’t carefully controlled, they may confound the results. If this happens, we can no longer be sure that it is the IV which has affected the DV and not something else. The presence of confounding variables reduces/minimises the value of any findings from the experiment and render the conclusions invalid. In designing or criticizing an experiment, check for participant variables, check for situational variables, and check for experimenter/researcher variables. 15 RELATIONSHIPS Investigator effects occur when some aspect of the investigator (e.g. appearance, gender, ethnicity, attitude) influences the participants’ answers and responses. Single blind (when the participant does not know the purpose of the investigation), and double blind procedures (when neither the participant nor the investigator know the purpose of the investigation) can help reduce investigator effects. For example, in drug trials the participant will not know if he has been given the real drug or a placebo. In a double blind, neither will the investigator. Demand characteristics occur when the participants try to guess the purpose of the study and then try to give the ‘right’ results. Of course, the participant may not wish to give ‘right’ responses but instead: o tries to annoy the research by giving the ‘wrong’ responses – the ‘screw you’ effect; o acts unnaturally out of nervousness; o gives socially desirable answers in order to ‘look good’. Operationalising the Variables, including the IV and the DV They say that eating chocolate makes people feel happier. Let’s investigate this. Our aim is to investigate whether or not eating chocolate makes people feel happier. We will need a hypothesis. Let’s formulate a directional hypothesis because we’re pretty sure that it does. So we have: Eating chocolate makes people feel happier. We now need to test this statement because a hypothesis is a testable statement. A question arises: how are we going to carry out our test? In this experiment, the IV (independent variable) is eating chocolate and the DV (dependent variable) is the level of happiness. How are we going to ‘operationalise’ the IV and the DV? The term ‘operationalise’ means being able to define the variables simply and easily in order to manipulate them (IV) and measure them (DV). Sometimes this is easy. For example, if we were measuring the effect of alcohol consumption on reaction times we could operationalise the IV as the number of alcohol units consumed and we could operationalise the DV as the speed of response to a flashing light. However, on other occasions this is more difficult. In our eating chocolate experiment it is easy to decide on the amount of chocolate given but it is not so easy to decide how we will measure the participants’ level of happiness. The researcher has to make a judgement on how to measure the variables and decide if these measurements are actually measuring the intended variables. 16 Both IV and DV need to be ‘operationalised’ accurately and objectively to maintain the integrity of any research study. Without accurate operationalisation, results may not be reliable or valid, and certainly could not be checked or replicated. RELIABILITY AND VALIDITY Researchers try to produce results that are both reliable and valid. If results are reliable, they are said to be consistent. Imagine buy a new thermometer. You used it to test the temperature of your bath water; two minutes later you test the temperature again and it is wildly different from your first test. Two minutes later you test the water again and this time the thermometer tells you a third thing different from the first and second times. The results would not be consistent. The thermometer would be unreliable and you would probably chuck it away. Reliability in science is essential. If a study is repeated/replicated using the same method, design and measurements, you expect to get similar results. If this occurs, the results can be described as reliable. If results are unreliable, they cannot be trusted and must be ignored. However, results can be reliable (i.e. consistent) but still not accurate. Our thermometer may keep on giving a reading of 20c no matter what the temperature outside really is. In this case the thermometer would be reliable but not accurate; in fact it would be reliably inaccurate! Research results must also measure what they’re supposed to be measuring (i.e. validity). Of they do this and they are accurate, they are said to be valid. In effect, the measures can be described as ‘true’. For example, is your teacher assessing/marking/measuring your work according to the guidelines issued by the examination board? If not, their marking may be reliable (consistent) but it is not going to be valid (accurate). BTW, some psychologists argue that Milgram’s results in the shocking obedience experiments are not valid. They argue that what Milgram was actually measuring was how much trust the participants put in the authority figure (the experimenter) and not how far the participants were willing to obey the authority figure. There are a number of ways we can test reliability and test validity: Internal reliability: is a test consistent within itself? For example, a set of scales should measure the same weight between 50 and 150 grams as between 150 and 200 grams. External reliability: does the test measure consistently over a period of time? An IQ (intelligence) test should produce roughly the same measure/score for the same participant at different time intervals. This is called the test-retest method. Obviously you would have to ensure that participants don’t remember the answers from the previous test, or use another version of the IQ test to assess intelligence. 17 Examination hint: In PY2 you studied three ways to test reliability (split-half, test-retest, interrater). Review these for PY3. Internal validity: Results are internally valid if they have not been affected by an confounding variables. Are the results valid within the experimental setting. Internal validity can be improved by: (a) (b) (c) (d) Ensure there are no investigator/experimenter/researcher effects. No demand characteristics Use standardised instructions. Use a random sample. External (ecological) validity: It is one thing to discover something thorough an experiment carried out in a laboratory; it is another thing to be sure that these discoveries are also true about the world beyond the laboratory. In other words, can the results of the experiment be generalised to the wider population or to different settings or to different historical times? For example, Asch’s (1951) conformity experiment involving the comparison of lines found a significant level of conformity, but twenty years later when the same experiment was carried out using British students there was practically no conformity. And since both experiments involved only male participants, can we safely generalise Asch’s results to include females? Check Milgram (1963) for external validity. 18 SELECTING PARTICIPANTS - SAMPLING Most experiments in psychology use fewer than 100 participants, but experimenters generally want their findings to apply to a much larger group. Thus, the participants used in an experiment consist of a sample drawn from some larger population. This larger population is known as the target population. If we want the findings from a sample to be true of a population, then those included in the sample must be a representative sample of the target population. There are a number of ways in which we can select our sample. The following are amongst the sampling methods most often employed in research in psychology. Random sampling is the best-known method of sampling. This is where every member of the target population has an equal chance of being selected. The easiest way to do this is to place all the names from the target population into a hat and draw out the required sample number. Computer programmes can also generate random lists. This will provide a sample selected in an unbiased way. However, it can still result in a biased sample. For example, if ten boys’ and girls’ names were placed in a hat, there is a (small chance) that first ten drawn from the hat could be boys’ names. The selection would have been in biased but the sample would still be biased. Adv: A random sample is likely to be representative and therefore the results can be generalised to a wider population. Disadv: It is sometimes difficult to get details of the wider population in order to select a random sample. Opportunity sampling involves selecting participants who are readily available and willing to take part. This could simply involve asking anybody who is passing. Or, if you were investigating stress amongst teachers, you might simply visit your teachers’ staff room and invite any teachers you find there to take part. A surprising number of university research studies (75%) use undergraduates as participants simply for the sake of convenience. Volunteer sampling involves people volunteering to participate in the experiment. They selected themselves as participants (self-selected sample). This sampling method was used by Stanley Milgram (1963) in his obedience experiments. Adv: Opportunity and volunteer sampling are the easiest, most practical and cheapest methods to ensure large samples. Disadv: These methods are likely to produces sample that are biased in some important way. Thus the findings may be less easily generalised to the wider/target population. Volunteers may be more motivated and thus perform differently than randomly selected participants. 19 ETHICAL ISSUES & WAYS OF DEALING WITH THEM The key to conducting research in an ethical way is expressed in the following Principles: “The essential principle is that the investigation should be considered from the standpoint of all participants; foreseeable threats to their psychological well-being, health, values and dignity should be eliminated.” In other words, every effort should be made to ensure that participants do not experience pain, stress or distress. The British Psychological Society (BPS) publishes a Code of Ethics that all psychologists should follow (BPS 2007). The informal basis of the code is ‘do unto others as you would be done by’. In addition, most research institutions such as universities have their own ethical committees that meet to consider all research projects before they commence. Informed consent – presumptive consent – prior general consent Most ethical problems in human research stem from the participant being typically in a much less powerful position than the experimenter. One way of dealing with this is to make sure that participant is told precisely what will happen in the experiment, before requesting that he or she give voluntary informed consent to take part. In the case of young children, their parents or guardians can provide the necessary consent. As a rule of thumb, the more potentially serious the risks, the more participants need to know. Milgram (1992) proposes two compromise solutions to the problem of not being able to obtain informed consent. These are presumptive consent and prior general consent. In presumptive consent, a large number of people are asked about how acceptable (or otherwise) they feel and experimental procedure is. These people would not be taking part in the experiment (if it went ahead), but their views could be taken as evidence of how people in general would react to participation. Prior general consent could be obtained from people who might, subsequently, serve as participants. Before volunteering to join a pool of volunteers, they would be explicitly told that sometimes participants are misinformed about a study’s true purpose and sometimes experience emotional stress. Only those who agreed to take part would then participate in the experiment. Retrospective consent involves asking the participants for consent after they have participated in the study. Of course, a major problem here is that they may not agree to it and ye they have already taken part. 20 Right to withdraw It is very important that participants have the right to withdraw from an experiment at any time. They should not have to explain why they are withdrawing if they choose not to. In addition, they have the right to insist that any data they have provided during the experiment should be destroyed. The right to withdraw is now considered standard practice, but this was not the case in the past. You will recall that Milgram’s (1974) participants were plainly told (verbal prods) that they had to continue giving the electric shocks to the learner, Mr. Wallace. Debriefing At the end of the experiment, the experimenter should provide what is known as debriefing. These are two aspects to debriefing: 1. Participants should be informed about the aims, findings and conclusions of the investigation 2. The researcher should take steps to reduce any distress that may have been caused by the experiment. The debrief is particularly important if deception has been used. Participants should leave the study feeling the same (or better) about themselves than when they started the study. Debriefing does not provide a justification for any unethical aspects of the procedure. Milgram’s (1974) research on obedience to authority is an example of good debriefing. All of the participants were reassured that they had not actually given any electric shocks. They then had a long discussion with the experimenter and the person who had apparently received the shocks. Those participants who had been willing to give severe shocks were told that their behaviour was normal under the circumstances. Finally, all of the participants were given a detailed report on the study. Another important aspect of ethical research is confidentiality. This means that information about the individual participants should not be revealed for any reason. It is usual in psychology for published accounts of the research to refer to group means (averages), but not to give personal information about the names and performance of individual people. If the experimenter cannot guarantee confidentiality, then this should certainly be made clear to the participants before the start of the experiment. Deception - when can it be justified? Voluntary consent is very desirable, and it is important to try to avoid deception. However, there are many experiments where informed consent would make the experiment worthless – think of Milgram, Asch, Hofling. These are experiments where deception is unavoidable. 21 Researchers are guilty of ‘active deception’ when they deliberately mislead the participants over some aspect of the investigation. In Milgram’s study of obedience, the participants were false told it was a study of learning and memory, and they were deceived into thinking they were given real electric shocks. Zimbardo (1973) employed ‘passive deception’ which means withholding important information from the participants. Zimbardo did not inform half of the participants they would be arrested at home in order to make the experience of being prisoners feel more realistic. In observational research, observations should only be made in public places where people might expect to be seen by strangers. When is deception justified? There are various factors that need to be taken into account. First, deception is more acceptable if the effects of the deception are not damaging. Second, it is easier to justify the use of deception in studies that are important in teaching us something important about human behaviour. Third, deception is more justifiable where there are no other, deception-free, ways of studying an issue. If, during the research process, it becomes clear that there are negative consequences as a result of the research, the research should be stopped and every effort should be made to correct these adverse consequences. 22 DESIGNING AN EXPERIMENT Design issues relating to specific research methods, and their relative strengths and weaknesses Let’s say, for example, we wanted to investigate if studying with a background of music affects students’ academic performance. We have decided that our experimental hypothesis will state: Studying with a background of music affects students’ learning. We have chosen a non-directional hypothesis because frankly we do not know whether it does or doesn’t. We now have to choose an experimental design. There are three main types of experimental design, each of which has its strengths and weaknesses. Let’s consider them. REPEATED MEASURES DESIGN The same participants are tested in the two (or more conditions) of the experiment. Each participant repeats the study in each condition. In our experiment we would select one group of participants. First they would study in silence. Then we would assess how much they had learned. Then they would study with a background of music. Then we would assess how much they had learned. We would then compare how much they had learned under each condition (findings/data), and from this information we would draw our conclusions. Advantages of repeated measures o No group differences – the same person/s is/are measured in both conditions; there are no individual differences between the groups. Extraneous variables are reduced and kept constant (controlled) between the conditions. o Fewer participants are needed – half as many participants are needed with repeated measures when compared to independent groups design. If you need 20 scores, then 10 participants undertaking both conditions (silence and music) will be enough in repeated measures. With independent groups design, if you need 20 scores, you will need 10 participants in the silent condition and 10 participants in the music condition (10 + 10 = 20). It’s not always easy to get participants for psychology experiments and finding more participants can be time-consuming. Weaknesses of repeated measures Order effects: when participants repeat a task, results can be affected by what we call order effects. On the second task (condition) participants may either: Do worse because they grow tired or bored, or improve through practice in the first condition. 23 This can be controlled by what we call counter-balancing, where half of the participants do Condition A followed by Condition B, and the other half do Condition B followed by Condition A. This counter-balancing procedure is known as ‘ABBA’ for obvious reasons. Lost participants: if a participant drops out of the study, they are ‘lost’ from both conditions. Guessing the aim of the study: by participating in all conditions of the experiment, it’s far more likely that the participant may guess the purpose of the study. This may make demand characteristics more common. For example, our students who have been studying in silence, then find themselves studying to music. Why? they ask... Why? Takes more time: a gap may need to be given between conditions, perhaps to try and counter the effects of tiredness or boredom. If participants are taking part in both conditions of the experiment, different materials need to be produced for each condition. This may not mean much in our music v. silence experiment, but in a memory test you could not simply use the same list of words for both conditions. Inevitably, these issues involve more time and money. INDEPENDENT GROUPS DESIGN Different participants are used in each of the conditions. Each group of participants is independent of the other. Participants are usually randomly allocated to each condition to try to balance out any differences. In our experiment, we would recruit a group of let’s say 20 participants. We would allocate 10 to Condition A and 10 to Condition B by random selection. Following the study period, we would then assess how much each group had learned under each condition, compare the findings/data, and from this information we would draw our conclusions. Advantages of independent groups o There are no order effects – since no participant is repeating the same task, results are no affected by fatigue/tiredness or boredom. Nor do they have the opportunity to improve through practice. o Demand characteristics are reduced – participants take part in one condition only. This means there is less chance of participants guessing the purpose of the study. o Time is saved – both sets of participants can be tested at the same time; this saves time and money. 24 Weaknesses of independent groups More participants are needed because you need the same number of different participants for Condition A and Condition B. In repeated measures, all of the participants undertake both conditions. Group differences: any differences between the groups may be due to individual differences amongst the participants. This can be reduced by using random selection so that every participant has an equal chance of being in either group. Get out the hat! MATCHED PAIRS DESIGN Matched pairs design is a simple variation on independent groups. We will still have two groups but this time the participants will not be randomly allocated. Instead we will try to match pairs of participants so that one of the pair appears in Group A and the other appears in Group B. We will only do this when we have an important reason to do it. For example, let’s say we are studying identical twins (monozygotic – hatched from one egg), and we wanted to assess how they’d been affected by the way they’d been brought up. We might decide to put Bob, Jane and Tom in one group and Bob’s brother, Jane’s sister, and Tom’s brother in the other group. In other words, we’d match the pairs by placing them in different groups. We typically match for age, gender and ethnicity. Advantages of matched pairs o Group differences - participant variables are more closely matched between conditions than in the independent groups design. In addition, the advantages described for independent groups apply to matched pairs. Weaknesses of matched pairs Matching is difficult - it is impossible to match all the variables. The one variable missed might be the crucial variable. Time-consuming - it takes a long time to accurately match participants on all variables. This task can become almost a research study in itself. Studies involving identical twins are often criticised because the number of participants (set of twins) is usually small. Examination hint: You’ll notice that many of the weaknesses of one sort of experimental design are advantages of other experimental designs. For example, a weakness of independent groups design is likely to be an advantage of repeated measures design. 25 DESCRIPTIVE STATISTICS Appropriate selection of descriptive analysis of data (A) QUANTITATIVE DATA involves the NUMERICAL ANALYSIS of data, i.e. working with numbers. MEASURES OF CENTRAL TENDENCY are used to illustrate the average values of data. These include: (a) the MEAN (all the scores added and divided by the number of scores). What is the mean of: 7, 4, 6, 5, 5, 7, 8? Strength: It includes ALL the information from the raw scores and is one of the most powerful methods. It is a very sensitive measure. Weakness: It is less useful if some of the scores are SKEWED. That is if there are some very high and/or low scores in the distribution of scores, e.g. 2, 6, 19, 22, 23, 25, 26, 57, 90. (The median should be used instead). (b) the MEDIAN is the middle or central score in a list of rank-ordered scores. For example, 2, 6, 19, 22, 23, 25, 26, 57, 90. What is the median in 2, 3, 4, 6, 8, 9, 12, 13? Strength: It is not affected by extreme scores (outliers), Weakness: It is not as sensitive as the mean because the raw scores are not used in the calculation. (c) the MODE is the most common or ‘popular’ number in a set of scores: 3, 5, 8, 14, 15, 15, 15, 17, 17, 18, 21, 24 = 15 Strength: It is not affected by extreme scores (outliers). It sometimes makes more sense. The average number of children in a British family is better described as 2 (the mode) rather 2.4 children (the mean). Weakness: There can be more than one mode in a set of data. It tells us nothing about the other scores. (B) QUALITATIVE DATA involves people’s experiences, descriptions and meanings. Qualitative data is often secured through questionnaires, survey and INTERVIEWS. The data cannot be numerically analysed unless we attach multiple-choice, True/False, rating scales (say 1-5) to the responses 26 There is no agreed way to code qualitative data but analysis often involves the categorisation of common themes, and the use of illustrative quotations. Advantage: Qualitative data is mainly collected from open-ended questions where participants are invited to give an answer using their own words. Such data is less likely to be biased by the interviewer’s pre-conceived ideas. Disadvantage: The interpretation of interview data is open to subjective interpretation. In addition, the analysis of the data can be extremely time-consuming. (C) GRAPHS and CHARTS illustrate patterns in data at a glance. The strength of a correlation can be seen in a SCATTERGRAPH. A perfect positive correlation is +1’ a perfect negative correlation is –1. A BAR CHART shows data in the form of CATEGORIES that the researcher wishes to compare. These categories should be placed on the X-axis. The columns of the bar chart should be the same widths and separated by a space; the space/s illustrates that the data is ‘discrete’, not continuous. 27 A HISTOGRAM is used for CONTINUOUS DATA, e.g. test scores. The continuous scores or values should ascend along the X-axis; the frequency of the values is shown on the Y-axis. There should be no spaces between the columns/bars since the data is continuous. The column width for each value on the X-axis should be the same. 28 A FREQUENCY POLYGON (or LINE GRAPH) is very similar to a histogram because the data on the X-axis must be continuous. A frequency polygon can be illustrated by drawing a line from the midpoint top of each bar/column in a histogram. The main advantage of a frequency polygon is that two or more frequency distributions can be displayed on the same graph for comparison. For example, we might wish to compare grades gained by males and females on the same graph. The STANDARD DEVIATION CURVE allows us to see how scores are distributed. It also allows us to interpret an individual’s score. 29 RESEARCH METHODS & RESEARCH DESIGN STRUCTURED QUESTIONS Followed by ANSWERS INVESTIGATION 1 A group of 20 five-year-old children on a housing estate have attended a special early-years education project since they were three years old. At the time their parents volunteered for the programme, a control group of 20 children was found by selecting every tenth family from a list of 200 other families on the estate. The two groups were fairly similar in IQ score at the start of the project. The researchers predict that, among other things, the IQ scores of the project group will now be higher than that of the control group. The IQ of the two groups at age 5 is measured using a standardised test. The mean of all 40 children is 100. The following results are found: Above mean Below mean Special project 16 4 Control group children 12 8 Questions 1. 2. 3. 4. 5. 6. What is the independent variable in this study? What is the dependent variable in this study? Suggest a directional hypothesis for this study. Suggest a non-directional hypothesis for this study. Suggest a null hypothesis for this study. Has the control group been randomly selected? Give a reason for you answer. 7. Describe one important way in which the two groups differ. Why does this difference matter? 8. This test is reliable. What is meant by a test being reliable? 9. Suggest one possible confounding variable. 10. Name two ethical considerations that might me made before publishing the results of this research. 30 INVESTIGATION 2 A psychologist carries out research in two teaching departments at a college. The departments are of roughly equal size, one specializing in catering subjects and other in social work. The catering department is run on traditional lines where the Head of the Department takes all the major decisions and consults with her senior staff who pass on the management decisions to more junior lecturers. The social work department is organised into small team units that take responsibility for quite major decisions within their area of work. The researcher is interested in job satisfaction and staff-management relationships. She uses the following methods: Unstructured interview with each member of staff A structured questionnaire on job satisfaction A week of participant observation in each department (she does a small amount of teaching for each department, but members of staff know her true purpose). Questions 1. What advantages does the interview have over either of the other two methods used in this research? (2 marks) 2. Explain one advantage of a structured questionnaire. (1) 3. Explain one possible disadvantage of participant observation. (1) 4. The interview and the questionnaire might both involve the problem social desirability responding. What do you understand by this phrase? (1) 5. The researcher’s structured questionnaire employed forced choices. What do you understand by forced choices? (1) 6. Suggest one non-directional hypothesis for this investigation. (1) 7. Suggest one directional hypothesis for this investigation. (1) 8. How has the researcher dealt with the issue of informed consent? (1) 9. What other ethical consideration might be involved? (1) 10. How might demand characteristics influence this investigation? (1) INVESTIGATION 3 15 volunteers are given Rorschach ink-blot tests. These are abstract patterns participants are asked to look at. They are then asked to report on what the shapes look like to them. Their responses are analysed for aggressive content by two trained raters whose final rating score is on a scale from one to 25. A check is made that one rater is scoring at about the same level as the other. 31 The participants are then given tasks which are impossible to complete. This is intended to create frustration and therefore aggression. The Rorschach tests and ratings for aggression are then repeated. It is expected that the frustration will increase aggression. Differences between pre- and post-treatment scores are significant at the 5% level. Questions 1. In what way could this sample be biased? 2. a) What are demand characteristics? b) Briefly comment on ways in which demand characteristics might occur in this study. 3. Outline one possible aim of this investigation. 4. State the hypothesis in this study. 5. Is the hypothesis one-tailed or two-tailed? 6. Participants might become annoyed because they believed their time was being wasted. What kind of variable would this be? 7. What is an operational definition? What is the researcher’s operational definition of aggression this study? 8. Describe two weaknesses of unstructured tests like the Rorschach. 9. Outline one other method by which aggression could have been assessed. 10. Is the data gleaned from this investigation qualitative or quantitative? INVESTIGATION 4 A group of 12 people with alcohol problems, attending a clinic, volunteer to take part in an experimental therapeutic programme. For each volunteer, a second alcoholic is selected who is like the volunteer on several important characteristics. After three months of the programme, both groups are assessed by two methods. One is a structured and standardised questionnaire, completed by participants. The other is a clinical interview, conducted by a therapist. The treatment group shows a strong and significant improvement, as measured by the questionnaire, but this improvement is not so marked as measured by the therapists’ interview rating. Correlation between the questionnaire score and interview ratings is 0.87. Questions 1. a) What sort of experimental design is used here? b) State one advantage of the experimental design used. 2. Outline two weaknesses of the clinical interview? 3. Describe two problems that may occur when constructing any questionnaire. 32 4. Give two reasons why the questionnaire might have produced greater evidence of improvement than the interview. 5. What can we learn from the correlation coefficient of interview ratings and questionnaire scores? 6. A placebo group could have been used in this research. a) Why might this have been useful? b) What procedure might have been used with the placebo group? 7. Twelve alcoholics volunteered to take part in the therapeutic programme. Describe one limitation of volunteer samples. 8. If every alcoholic had been given an equal opportunity to take part In the programme, what kind of sample would that be? 9. Suggest one confounding variable for this investigation. 10. After six months, the programme shows obvious success. Ethically, what should now happen to the control group and why? (1) INVESTIGATION 5 A researcher who is interested in stress wishes to test the hypothesis that individuals who are generally more anxious tend to have worse health records. It is decided to administer two standardised tests to a sample of individuals in a variety of occupations who respond to a newspaper advertisement for participants. One test is a measure of general anxiety level and a high score indicates high anxiety. The other test measures general state of health, including visits to doctors, days off sick, and so on. A high score on this test indicates good general health. The participants are tested alone in a small sound-proof cubicle. The questionnaires are scored by two pairs of assistants. One pair score only the health questionnaires and the other pair score only the anxiety questionnaires. Both pairs are unaware of the nature of the hypothesis being tested. After testing, each participant was given full information about the research and assured that their results would remain anonymous. The correlation coefficient between the two measures – anxiety level & health level – is –0.32. Questions 1. Would this research design count as an experiment? Give reasons for your answer. 2. Are the researchers studying a random sample of participants? Justify your answer. 3. Why are the assistants who score each questionnaire a) not told about the research hypothesis? 33 b) given only one kind of questionnaire to score? 5. Why is it important that participants were tested alone? 6. What is meant by a negative correlation? Why was a negative correlation expected from the use of the two tests in this study? 7. Would you call the correlation found in this study ‘fairly strong’ or ‘fairly weak’? 8. Why can a ‘weak’ correlation still be called ‘significant’? 9. What is the point of debriefing all participants at the end? 10. The researcher assumes that high levels of anxiety are one of the causes of poorer health. What alternative explanation of the result is possible? INVESTIGATION 6 The researcher argues that when people solve anagrams, they do not just passively rearrange letters until a word emerges. The theory is that people are active problemsolvers and that they generate possible words that might fit some of the letters before, and whilst arranging the letters. The research was designed to support this theory. One group of 10 participants is asked to solve two sets of six anagrams. One set is of common words and the other set is of uncommon words. The set of words for the anagrams are selected at random from larger sets of frequently and infrequently occurring words. The two conditions are counter-balanced. The time taken to solve each anagram was measured by a stopwatch and recorded. Results appear in the table below. Anagram results 1. Median solution time (in seconds) for six anagrams Participant 2. A B C D E F G H I J Common words Uncommon words 14 23 35 15 27 5 25 32 17 21 27 85 32 30 130 13 60 125 33 28 34 Questions 3. 4. 5. 6. What are the independent and dependent variables in this experiment? What kind of experimental design is being employed? What are the two conditions of this experiment? If the researcher had used two different groups, one for each condition, Why could this have been unsatisfactory? 7. Apart from changes in noise and lighting levels, suggest two random variables that might affect participants’ performances. 8. The researchers asked experimenters to use a standardised procedure that included explaining the task in exactly the same words to each participant. Give two reasons for this approach. 9. In the data, median values are given. Why is the median, in this case, preferable to the mean? 10. What is meant by level of significance? 11. Do you think the difference between the two sets of times in the table will be shown to be significant? Give reasons. 12. Do you perceive any ethical problems associated with this investigation? INVESTIGATION 7 A researcher wished to establish which of two new types of word-processing packages (Wordpal & Wordmate) was easier to learn and which seemed more ‘friendly’. 37 experienced secretaries already using word processors were obtained by asking for volunteers in a wide variety of work settings. For technical reasons, only 12 were tested with Wordmate, whereas 25 were tested on Wordpal. Using their previous word-processing knowledge, plus on-screen information, the secretaries were asked to produce a letter with the program they were given to use. Measures were taken of the total time taken to complete the letter perfectly and of their evaluation of the programme using a previously piloted questionnaire. The researchers calculated the standard deviation of the letter completion times and, from this, they found each secretary’s standard score. The mean and standard deviations are shown in the table below. The scores appeared to be drawn from a normal distribution. Mean completion time (mins) Standard Deviation 36.1 22.8 19.8 10.1 35 The time taken to produce a letter with Wordpal was significantly lower than the time taken to produce a letter with Wordmate. Questions 1. Why can the sample gathered can be considered biased? 2. a) What was the IV in this study? b) What were the two DVs in this study? 3. What experimental design is used here, and what is one of its advantages? 4. a) Explain what is meant by piloting a questionnaire. b) Why is it important to pilot a questionnaire? 5. Explain what is meant by standard deviation. 6. How would a null hypothesis explain the results? 7. Give some explanation of why letter completion times may have differed so much, apart from the differences between the two word-processing packages themselves. 8. One secretary does so badly with the programme used that he/she wants To withdraw and have the results destroyed. How would you advise the researcher to proceed in these circumstances? INVESTIGATION 8 Two teachers were interested in studying the effects of listening to music on students’ revision and subsequent examination performance. Previous research suggests that listening to music whilst revising has a negative effect on exam performance. One class volunteered to participate in the experiment. When revising for History, the students listened to background music; whereas they revised for Geography in silence. Finally, all the participants sat a mock examination in Geography in the morning and then History in the afternoon. Each exam was marked by the class’s teacher. The maximum mark was 100%. All the participants were thanked for their help and thoroughly debriefed. Table 1 Student exam performance against background music/silence Exam mark (%) against background music/silence History Mark (listening to music) 70 69 68 Geography Mark (silence) 96 92 91 36 67 66 65 47 47 25 22 20 1. 2. 3. 4. What kind of research method was used in this investigation? What kind of research design was used in this investigation? Suggest an appropriate null hypothesis for this study? For this study, which is more appropriate: a directional or a non-directional hypothesis? Justify your choice. 5. Name the two conditions of this experiment. 6. Name the dependent variable. 7. Identify the type of sampling used in this study. 8. Explain one advantage and one disadvantage of this method of sampling. 9. What measure of central tendency – mean, median or mode is most suitable to describe the data in Table 1? Justify your choice. 10. Other than ethical issues, explain two ways in which the design of this study might have been improved. 90 89 65 64 50 47 47 45 (1 mark) (1 mark) (1 mark) (1 + 2 marks) (2 marks) (1 mark) (1 mark) (2 marks) (1 + 2 marks) (2 marks) 37 ANSWERS FOR STRUCTURED QUESTIONS INVESTIGATION 1 - ANSWERS 1. 2. 3. 4. 5. attendance at the project or not amount of improvement in IQ scores children who attend the project will improve IQ scores attending the project will make a difference to IQ scores any change in IQ scores will be by chance, and not because of attendance at the project 6. No. This is not random sampling because every child does not have an equal chance of being selected. (Every 10th child was selected, so this is systematic sampling.) 7. Control group parents didn’t volunteer. Project parents may be particularly interested in their children’s education and therefore might stimulate their children at home, outside the project. Children know they are being specially treated. 8. Reliable means that the test produces the same results again and again. It means the test is consistent. 9. Parents give extra lessons at home to the control group. 10. Permission to publish should be sought from parents. Children’s identities should be confidential and anonymous. INVESTIGATION 2 – ANSWERS 1. Unstructured, therefore richer, perhaps more genuine information. Quicker than participant observation and less likely to cause bias through researcher’s deeper personal involvement. 2. Structured questionnaire keeps participants on topic, and responses are easier to analyse. 3. In participant observation, participants may change their usual behaviour because they know they are being observed; demand characteristics; socially desirable behaviour. 4. Social desirability means that participants may give responses that show themselves in a good light, especially if the truth is likely to be embarrassing. 5. Forced choices means the participants must choose from the range of answers offered by the researcher, e.g. true/false; yes/no; multiple choice. 6. Management styles influence job satisfaction and staff-management relationships. 7. Management styles influence job satisfaction and staff-management relationships for better or worse. (two-tailed hypothesis) 8. Participants are aware of the nature of the research & have consented to take part. 9. Details of the participants must be kept confidential and even destroyed when the investigation has been completed. 10. The researcher may be popular with some of her colleagues and unpopular with others this might influence their responses. 38 INVESTIGATION 3 – ANSWERS 1. They are volunteers. 2. a) Individual, personal reactions to the researcher b) Desire to please researcher by withholding aggressive responses 3. To investigate the relationship between frustration and aggression 4. Post treatment scores will be higher than pre-treatment scores; a directional hypothesis. 5. One-tailed (predicts only one outcome) 6. Confounding variable 7. Steps taken to measure what is being investigated The responses scored on Rorschach rating scale 8. Subjective interpretation of participants’ responses; Low reliability – results not consistent. 9. Physiological responses – before and after impossible tasks 10. Quantitative – a rating scale is used. INVESTIGATION 4 – ANSWERS 1. a) Independent groups b) Less chance of order effects, or participants guessing the purpose of the investigation. 2. Demand characteristics; unstructured and therefore less reliable. 3. Questions may be unclear and ambiguous; questions may produce socially desirable responses rather than truth. 4. Participants might try to “look good” on the questionnaire. Therapist can perhaps get closer to truth in interview. 5. Good agreement between methods (questionnaire and interview) because correlation is high. 6. a) Participants in the experimental programme might improve solely because they know they are expected to, or because they are getting special attention. b) They would be treated as normal, nothing special done, and they would be unaware that any programme was taking place. 7. Volunteers are more likely to change their behaviour to please the researcher and come up with the results he wants. 8. Random sampling – everyone given equal opportunity to participate. 9. Some of the alcoholics may decide to go “on the wagon” for reasons that have nothing to do with the therapeutic programme. 10. The control participants should also join the programme if they wish. They would now be disadvantaged if treatment was withheld, since it is now seen as effective. 39 INVESTIGATION 5 - ANSWERS 1. No. Independent variable not manipulated 2. No. The participants are volunteers. 3. a) can’t bias rating in favour of expected results b) can’t guess research aim 4. To reduce random errors. To be able to check rater reliability. 5. Responding to the questionnaire with others around might well have an unwanted effect on a variable like anxiety. Remember that demand characteristics can refer not only to the researcher and the setting of an experiment, but also to other unwanted effects. 6. As one variable increases, the other decreases. (inverse relationship) In this study, higher anxiety scores are expected to be paired with lower health Scores. Hence the correlation coefficient -0.32. 7. Fairly weak 8. Depends on the size of the sample. With a high sample size, a low correlation may be significant, e.g. 10% of 10 doesn’t prove much; 10% of 50.000 might be very significant. 9. To return participants to normal; remove negative impressions, feelings about performance, lowered self-esteem, etc.; to inform of exact research aims. 10. People already in poor healthy may (understandably) be more anxious about it. INVESTIGATION 6 - ANSWERS 1. IV: common or uncommon wordsDV: median solution time 2. Repeated measures (same participants doing both/all conditions) 3. 1. solving anagrams from common words 2. solving anagrams from uncommon words 4. Different participants would have different variables, e.g. IQ 5. Anxiety; timing errors; unfamiliarity with certain words. 6. We do not wish variation in wording and approach to be responsible for any changes observed. Experimenters cannot be tempted to give help or clues to the design. 7. In this case, the mean would be distorted in value by the last, very high value. 8. level of significance means the level of probability; the higher the probability, the greater the level of significance. (an 80% chance is better than a 60% chance) 9. Yes! 9 out of 10 uncommon word times are longer than common word times. And differences are mostly quite large. 10. None. INVESTIGATION 7 - ANSWERS 1. Volunteers; already experienced 2. IV: Wordpal and Wordmate DVs: time taken and evaluation 3. Independent samples; no order effects; participants can’t guess aims of research 40 4. a) pilot = trying out a draft version on an initial sample b) to ensure questions are clear and unambiguous so final version is improved; check reliability (consistency) 5. Standard deviation is a measure of dispersion (spread of scores around the mean) in a sample of scores 6. A null hypothesis would suggest that the different in completion times of the letter were not due to the different word-packages but due to other unidentified variables or simply due to chance 7. One sample is much smaller than the other; could just be sample differences in the secretaries used. 8. Participant has the right to have results withdrawn. Researcher might attempt to persuade secretary that confidence is absolute, but must concede, give in, if persuasion fails. INVESTIGATION 8 - ANSWERS 1. field experiment (in school; IV’s and DV) 2. repeated measures design (all participants did both conditions) 3. any differences in academic performance will occur by chance, and not be caused by the Independent Variables 4. a directional hypothesis – listening to music during exam revision has a negative effect on exam performance – previous research supports this hypothesis 5. revising with music playing; revising in silence 6. academic performance as measured in percentage marks 7. volunteer sample 8. advantage, easy to obtain sample – disadvantage, potentially biased as volunteers usually better motivated than general population 9. the mean (a) it includes all the information from the raw scores (b) it shows the difference between the sets of scores very clearly (c) there are no extreme scores to skew the mean/averages 10. (a) a random sample would have reduced the possibility of bias (b) independent groups could have sat the examinations at the same time in the morning; they would have also found it more difficult to guess the purpose of the experiment (c) teachers should not have marked their own classes because there is the danger of rater bias. 41 PUTTING CORRELATION TO THE TEST 1 A researcher has conducted a correlational study to investigate the relationship between how good people think their memory is and how well they do on a memory test. The first variable was ‘self rating of memory’ and was measured by asking people to rate their memory on a 10 point scale (where 1 = very poor and 10 = excellent). The second variable was ‘actual memory’ and this was measured by showing them a video of a minor road accident and asking them a series of 10 eye-witness questions. Results were as follows: 1 (a) Sketch an appropriately labelled scattergraph displaying the results. (b) Outline one conclusion that can be drawn from this scattergraph 2 Suggest one problem with the way ‘self rating of memory’ has been measured in this investigation. 3 Describe and evaluate two other ways in which ‘actual memory’ might be measured. 2 A researcher carried out a correlation of GCSE performance and A level performance. 1. Outline one strength of carrying out this correlation. 2. Outline one weakness of carrying out this correlation. 3. Explain what is a meant by a negative correlation. 42 4. Explain what is meant by a directional hypothesis. 5. If the researcher found a correlation coefficient of +0.8 what does this mean? 6. Explain what is meant by a zero correlation. 7. What type of data do correlations always analyse and what is a strength of such data? 4 A researcher has conducted a correlational study to investigate the relationship between stress and health. The first co-variable was measured by asking people to rate how stressed they felt on a 10 point scale (where 1 = not at all and 10 = very). The second co-variable was measured by asking people to rate how healthy they felt on a 10 point scale (where 1 = not healthy and 10 = very healthy. Results were as follows: 1. (a) Sketch an appropriately labelled scattergraph displaying the results. (b) Outline one conclusion that can be drawn from this scattergraph. 2. Suggest one problem with the way that health has been measured in this investigation. 3. Describe and evaluate one other way in which health might be measured. 4. Outline one strength of carrying out this correlation. 43 A researcher conducted a study to investigate the relationship between students’ television behaviour and studying habits. The researcher investigated whether there was a correlation between the average number of hours of television watched by A level students weekly and average number of hours weekly spent studying outside of the classroom. 5 The scattergraph below displays the results. 1. Outline one conclusion that can be drawn from this scattergram. 2. Suggest an appropriate directional hypothesis for this correlation 3. If a researcher found a correlation coefficient of -0.3 what does this mean? 4. (a) Outline an alternative way of measuring one of the co-variables (b) Explain the effect that this alternative measure might have on the results of the investigation. 5. If a researcher found a positive correlation between the number of cups of coffee drunk and the level of stress reported by a group of participants, could it be concluded that drinking coffee makes people stressed? Explain your answer. 44