IPv6 Jumbograms: Implementation and Feasibility
advertisement

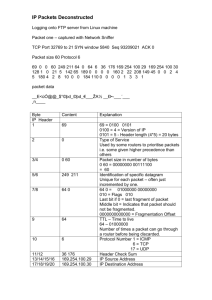
IPv6 Jumbograms Yannick Scheelen & Jeffrey Bosma University of Amsterdam System and Network Engineering (MSc) (Dated: April 2, 2012) A Jumbogram is an Internet Protocol version 6 (IPv6) packet that makes use of the 32 bit Jumbo Payload Length field that has been introduced in the optional IPv6 Hop-by-Hop Options extension header. By making use of this IPv6 Jumbo Payload option, it becomes theoretically possible to attach a payload of 4 GiB of data to a single, unfragmented IPv6 packet. In our research, we examine the possibility of practically implementing the use of Jumbograms on a network that consists of IPv6 nodes that understand and support a path Maximum Transmission Unit (MTU) greater than 65,575 bytes (that is, 65,535 bytes + 40 bytes for the IPv6 header). We examine if it is possible to practically implement Jumbograms on Local Area Networks (LANs) and Wide Area Networks (WANs), and what kind of modifications are needed to the lower and higher layers to support network traffic with jumbo sized payloads. I. INTRODUCTION With the ever growing increase of network traffic on Ethernet-based, packet-switched computer networks such as Local Area Networks (LANs) and Wide Area Networks (WANs), networking protocols are more and more pushed to their limits. The Internet Protocol version 6 (IPv6) for example is intended to be the next generation Internet protocol, succeeding the Internet Protocol version 4 (IPv4) because of its deficiencies. Probably the best known limitation of IPv4 is that an IPv4 address is constructed with 32 bits, which has lead to exhaustion of the pool of unallocated IPv4 addresses due to the growing amount of network-enabled devices connected to the Internet. Of all the limitations of IPv4, there is one in particular that is improved on by IPv6 and is of interest to the research presented in this paper: the size of the payload that can be transmitted in a single IPv6 packet. The technicalities that are responsible for the payload size limitation in IPv4 are as follows. The Total Length header field of IPv4 is 16 bits in size, limiting the maximum size of a payload in IPv4 packets on the third layer of the Open Systems Interconnection (OSI) model, known as the network layer, to 65,515 bytes (216 −21) after subtracting the size of the header (20 bytes). Roughly the same is true for a regular IPv6 packet, meaning without the Hop-By-Hop Options extension header along with the Jumbo Payload option. However, by utilizing this specific optional extension header and option, the Payload Length header field of an IPv6 packet is increased to 32 bits in size. Essentially this means that a payload of an IPv6 packet on the network layer allows for a payload size as large as 4,294,967,295 (232 − 1) bytes (4 GiB −1) to be transmitted in this single packet [1]. Such a packet is often referred to as a Jumbogram. The term Jumbogram is a concatenation of two other words. The first word, jumbo, refers to a very large thing of its kind. The second word, gram, is a partial word originating from the term datagram. A datagram is commonly considered synonymous to packets of an unreliable service (such as the connectionless properties of IPv6) on the network layer of the OSI model. Obviously, both words combined form the term (IPv6) Jumbogram. That being said, we would first like to clear up a common misnomer in thinking that a Jumbogram is the same as a Jumbo Frame. Often these two terms are used interchangeably and it is assumed that the audience is able to differentiate whether information is about Jumbograms or Jumbo Frames based on the context. However, doing so can be hard if the information lacks in detail. What we have discussed so far are Jumbograms, the IPv6 packets on the network layer that carry the Jumbo Payload option and a large sized payload, with respect to a regular IPv6 packet, of more than 64 KiB. Jumbo Frames, however, refer to the size of frames on the second layer of the OSI model, known as the data link layer. With the rise of Gigabit Ethernet networks, standardized in 802.3ab by the Institute of Electrical and Electronics Engineers (IEEE), unstandardized Jumbo Frames (Ethernet frames with an Maximum Transmission Unit (MTU) of 9000 bytes) are gaining in popularity as alternative to regular Ethernet frames (which have an MTU of 1500 bytes) as defined by the IEEE in 802.3u [2]. Unfortunately, we have seen many examples of authors that mistakingly use the term Jumbogram to indicate these large sized Ethernet frames. Having cleared up this discrepancy and defined the terminology that will be used throughout this paper, and hopefully in the work others, we will continue with research related to Jumbograms in subsection I A. A. Related Work In the areas of research that relate to Jumbograms, we did not find any substantial proof that Jumbograms have ever been part of any research that is publicly available. Although support for Jumbograms is (partially) implemented in the latest versions of commonly used operating systems, there is at the time of writing not a single application that actually makes use of this. We believe that this could be due to the little amount of information to be found on how this particular functionality of IPv6 2 should be implemented in applications, and the lack of supporting (consumer-grade) hardware that is required to transmit Jumbograms between networked nodes. The latter has to do with the maximum supported MTU size of network links between nodes to allow the sending and receiving of Jumbograms, which will be discussed in detail in section II. The information to be found about Jumbograms in the work of others is limited to several Request for Comments (RFCs) and books. In RFC 1883 about the specifications of IPv6, which was superseded in December 1998 by RFC 2460, the Jumbo Payload option was introduced to the public for the very first time. In August 1999, RFC 2675 was published as the first RFC specifically about the specifications of a Jumbogram. At the same time it obsoleted RFC 2147, published in May 1997, about the modifications required to the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) for Jumbogram support. Other than the RFCs, there are several books such as The Best Damn Cisco Internetworking Book Period by Charles Riley [3] and IPv6 Core Protocols Implementation by Qing Li et al. [4] that touch the subject briefly. Therefore, we would like improve on this by doing research about Jumbograms, mainly in performance, scaling, and usability aspects that might pose to have a beneficial value over regular IPv6 packets. B. Research questions The lack of information and implementation of Jumbograms, as discussed in subsection I A, made us curious and come up with various research questions. In this paper we will investigate the possibility and feasibility of implementing IPv6 Jumbograms on local and wide area networks by setting up a series of experimental testing environments. And, if necessary, we will research which modifications need to be made to either software or hardware implementations to enable the use of Jumbograms on these LAN and WAN networks. II. THEORY In section I we pointed out that the maximum size of an IPv4 packet is 65,535 bytes, including the IPv4 header, because the Total Length field in the IPv4 header is 16 bits in size. Because of the wide implementation of IPv4 in the past decades, almost all hardware and software implementations of the protocol apply this maximum size length for packets. With the official introduction of IPv6 in December 1998 [5], special treatment of a packet in the network is facilitated by the use of various optional extension headers. For instance, the theoretical maximum size of a payload has been greatly increased through the use of the Hop-by-Hop Options extension header and its Jumbo Payload option. All IPv6 extension headers are optional headers which are placed between the IPv6 header, which is always present in a packet, and the header of an upperlayer protocol. Figure 1 illustrates the fields in the IPv6 header. The existence of an extension header is identified by the Next Header field in the IPv6 header. With one exception, all the different extension headers are not processed or examined by any node they pass along the path until the packet reaches its destination. When the packet arrives at its destination, demultiplexing of the IPv6 Next Header field will invoke the destination node to process the information that is inside the extension headers. As mentioned earlier, there is one exception: the Hop-By-Hop Options extension header. The Hop-By-Hop Options header can include optional information that must be examined by every IPv6 compatible node it passes along the packet’s delivery path. The header is identified in the Next Header field in the IPv6 header with a value of 0. Figure 2 illustrates the fields in the Hop-by-Hop Options header. As mentioned before, the Payload Length field in the IPv6 header is just 16 bits in size, which would mean that the maximum payload an IPv6 packet can carry is limited to just 65,535 bytes; almost identical to an IPv4 packet be it minus the length of its header. However, this value can be greatly increased when using one of the options in the Hop-By-Hop Options extension header. The Hop-By-Hop Options header in an IPv6 packet allows for an option which is called the Jumbo Payload. This Jumbo Payload option includes a new 32 bit Payload Length field which would allow for the transmission of IPv6 packets with payloads between 65,536 and 4,294,967,295 bytes in length. So, an IPv6 packet that contains this Hop-By-Hop Options header with the Jumbo Payload option present, and which contains a payload larger than 65,535 bytes, is defined as a Jumbogram. Figure 3 illustrates the fields in the Jumbo Payload option. It contains three fields: 1. Option Type: 8 bit value 0xC2 (hexadecimal). 2. Opt Data Len: 8 bit value 0x04 (hexadecimal). 3. Jumbo Payload Length: 32 bit integer. This field indicates the total length of the IPv6 packet, excluding the IPv6 header but including the Hop-ByHop Options header, all the other extension headers that are optionally present, and any headers of upper-layers. This value must be greater than 65,535 bytes. If it would be less, the packet would not contain a Jumbo Payload. In order for an IPv6 node to understand this Jumbo Payload option, the Payload Length field in the IPv6 header must be set to the value 0 and the value of the Next 3 Header field must be set to 0 too, indicating the presence of a Hop-By-Hop Options header. As mentioned earlier, each IPv6 node that the Jumbogram passes, has to process the Hop-By-Hop Options header in order to compute the total size of the IPv6 packet. It has to do so because one of the core requirements of Jumbograms is that each and every node on the packet’s destination path has to support it. When a node does not understand the Jumbo Payload Option, the Jumbogram is dropped instantly and an Internet Control Message Protocol version 6 (ICMPv6) message will be returned to the sender. When a node does understand the Jumbo Payload option, it has to be able to correctly detect any possible format errors in the packet’s header and send an ICMPv6 message back to the sender indicating where an error has occurred. In order for an IPv6 node to process a Jumbogram, it has to be able to actually support packets with a payload of more than 65,535 bytes. One important restriction of a packet containing a Jumbo Payload option, is that it can not include a Fragmentation extension header, because this would beat the entire purpose of a Jumbogram. This means that a Jumbogram has to be able to be processed by an IPv6 node as a whole, single packet. This is where the link MTU comes in to play. The link’s MTU is the physical limit of bytes that a node can process. Since the minimum size of a Jumbogram is 65,536 bytes, any node that processes a Jumbogram needs to have a link MTU of more than 65,575 bytes, being 65,535 bytes for the jumbo payload data and 40 bytes for the IPv6 header. The minimum link MTU for an IPv6 node is 1280 bytes, as defined in RFC 2460 [5]. To ensure that every host on the packet’s path supports the Jumbo Payload Option, Path MTU Discovery is performed on the path. Path MTU Discovery, as described in RFC 1981 [6], is a mechanism that allows a node to discover the path’s maximum MTU size. If a node would not implement Path MTU Discovery, the IPv6 link MTU of 1280 bytes would have to be used. Because the minimum required path MTU for Jumbograms is 65,535 and every host on the packet’s path has to understand and support the Jumbo Payload option, Path MTU Discovery is used to ensure that every single node on the path is compatible and that the Jumbogram can traverse the network. The IEEE Ethernet 802.3u standard has employed a 1,518 bytes MTU since it was first created. The reason for this is because DIX Ethernet frames have a maximum Protocol Data Unit (PDU) size of 1,500 bytes. Ethernet 802.3 frames consisting of Logical Link Control (LLC) encapsulation have a PDU size of 1,497 bytes, while Ethernet 802.3 frames consisting of LLC and Service Network Access Point (SNAP) encapsulation have a PDU size of 1,492 bytes. Along with additional frame header fields, the maximum frame size becomes 1518 bytes. To maintain backward compatibility, every Ethernet link, ranging from 10 Mbit/s to 100 Gbit/s, employs this same standard frame size of 1,518 bytes. This is done to pre- vent any OSI layer 2 fragmentation or reassembly when communication occurs between different link sized Ethernet devices. This 1,518 bytes MTU limit has been fully adopted in every Ethernet device. In recent years, we have seen the introduction of Jumbo Frames by various vendors and because of its increasing popularity, it is becoming widely adopted in Ethernet-based devices. The Ethernet standard, however, still has not been extended to allow a link MTU of up to 9,000 bytes. Besides maintaining backwards compatibility, the lack of standardization of Jumbo Frames is one of the main reasons as to why only a handful of network are actively using Jumbo Frames. Another reason are the expenses necessary of upgrading existing network infrastructures to have the hardware supporting Jumbo Frames. Related to our research, where a path MTU of over 64 KiB is a necessity, numerous intermediating logic circuits along the network path would have to be upscaled, to accommodate for the required path MTU. When upper-link layer protocols such as TCP and UDP need to support the IPv6 jumbo payloads, some modifications have to be made to the implementation of these protocols. TCP does not use a length field in its header to indicate the length of an individual packet. Instead, TCP has a Maximum Segment Size (MSS) field that announces to the other node what the maximum amount of TCP data is that it can transmit per segment. The MSS value in the TCP MSS option is a 16 bit field, limiting the maximum value to 65,535. The maximum amount of TCP data in an IPv6 packet without the Jumbo Payload option is 65,515 bytes (65,535 minus the 20 byte TCP header). For the jumbo payloads to be supported, the MSS value has to be set to the maximum of 65,535 bytes, essentially causing the MSS size to be treated as infinite [1]. UDP, however, uses a Length field in its header to specify the size of packet (header and the payload data). In RFC 2675, a modification similar to that of TCP is advised. The Length field in the UDP header is 16 bits in size, indicating a maximum value of 65,535 bytes, similar to IPv4 and TCP’s MSS. For UDP to support jumbo payloads, this value should be set to the value 0, indicating the presence of a jumbo payload. Initially this would result in a error since the minimum UDP length is 8 bytes (the UDP header alone is composed of 8 bytes, thus excluding payload data). If a node wishes to send a UDP packet containing a jumbo payload, the actual size of the packet is computed by looking at the Payload Length field in the Jumbo Payload option, plus the length of the UDP header, plus the length of all the other IPv6 extension headers that are present in the packet. IPv6 compatible routers do not fragment an IPv6 packet themselves, in contrary to what is the general case for IPv4 routers. With IPv6, Path MTU Discovery is used in order to determine the maximum MTU size of the path to the packet’s destination, and fragmentation of the 4 IPv6 packet going over this link to the router is adjusted accordingly by the sender. After all the fragments have been received by the recipient, reassembly is done to yield the original IPv6 packet before fragmentation. As stated earlier, Jumbograms should never be fragmented. An IPv6 packet containing a Fragment header can never be considered a Jumbogram. According to the Jumbogram specification RFC [1], there are no security concerns when employing Jumbograms on a network. However, in 2008, an exploit using IPv6 Jumbograms was discovered for the Linux kernel [7] that was made possible because improper checking on the Hop-By-Hop Options header was done, causing it to panic. Other concerns, however, are raised because of the sheer maximum size a Jumbogram can be. A full-sized Jumbogram of 4 GiB will clog up a 1 Gb/s network link for over 30 seconds, and if the TCP checksum fails, the receiver can request retransmission of the packet. Obviously this can cause Denial of Service (DoS) related issues even with a single sender. Bit offset 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 32 64 96 128 160 192 224 256 288 Version Traffic Class Payload Length Flow Label Next Header Hop Limit Source Address Destination Address Figure 1: IPv6 Header Format Bit offset 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 32 64 96 Next Header Hdr Ext Len Options and Padding Optional: additional Options and Padding Figure 2: Hop-by-Hop Options Header Format Bit offset 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 32 (Hop-by-Hop Options Header) Option Type Jumbo Payload Length Opt Data Len Figure 3: Jumbo Payload Option Format III. EXPERIMENT With all the theoretical information gathered in section II, we now continue with the implementation of Jumbograms in an experimental environment. We have decided to outline the entire process of experiments that were conducted and will explain the outcomes. This way, we hope that others gain more insight in the structure of our experiments and at the same time clarify the choices that were made. All experiments were performed on GNU/Linux operating systems, regular Ubuntu 11.10, Debian Wheezy and CentOS 5.7 installations to be precise, running the latest unmodified Linux kernel (v3.2.x). Any modifications that were made to the configuration are explained below. To actually create and transmit a Jumbogram, we made use of two different programs. Initially we used a Python program called Scapy[8]. Scapy is a powerful, interactive packet manipulation program which allows us to create and transmit custom packets on the data link and network layers of the OSI model. Among many other packet types, it has built-in support for IPv6 packets, including the IPv6 extension headers and their options. The second program we used is SendIP[9]. SendIP is similar to Scapy with respect to allowing us to create and transmit 5 various different types of packets. In contrast to Scapy, SendIP is ran from a regular command line interface and configuration of a packet is done entirely with the use of appended parameters. Therefore, it is possible to create simple shell scripts to transmit arbitrary packets onto a network. Both programs provide default header field values and adjust these values to the structure of a packet accordingly. In an effort to capture the transmitted Jumbograms, we made use of Wireshark, which is a network protocol analyzer and allows us to capture and interactively browse the traffic. It has wide support for a large amount of different networking protocols such as IPv6, IPv6 extension headers and their options. Throughout all the experiments version 1.6.5 of Wireshark was used. As explained in section II, to be able to transmit such an IPv6 packet, a link MTU greater than 65,575 bytes is required. At time of writing there are not many implementations, either hardware of software, that support such a large link MTU. However, we discovered that the loopback interface of the aforementioned operating systems, and probably also that of other modern Linux distributions, can be configured with a very large link MTU. For example, we could easily configure the loopback interface with an MTU value of 1,000,000,000 bytes (1GB). In our experimental setup we configured the loopback interface with an MTU of 150,000 bytes, which is still a hundred times more than the amount of 1500 bytes specified by the Ethernet standard. By doing so, the link MTU requirement of a Jumbogram is met for experiments using the loopback interface. We initially used Scapy to create and transmit a Jumbogram with its destination address being that of the loopback interface. To create a Jumbogram in Scapy, we came up with the following command: Jumbogram = IPv6 ( d s t= ’ : : 1 ’ , nh=0 , p l e n =0)/ IPv6ExtHdrHopByHop ( o p t i o n s =[Jumbo ( jumboplen =100000) ] ) /Raw( RandString ( 9 9 9 6 0 ) ) This command first creates, in the variable Jumbogram, an IPv6 packet with its destination address set to ::1, and the Next Header (nh) and Payload Length (plen) fields set to 0. It then appends a Hop-by-Hop Options extension header (IPv6ExtHdrHopByHop), including the Jumbo Payload option (Jumbo) with its Jumbo Payload Length field (jumboplen) set to 100,000 bytes (100 KB). Then finally it attaches a jumbo payload (Raw ) composed of 99,960 arbitrary characters (RandString) where each character represents a single byte. Note that we are omitting any upper-layer protocols such as UDP and TCP because this would only add more complexity. Refer to figure 4 in appendix A for an overview of the header field values for the created Jumbogram. Transmitting the Jumbogram is done with the following command: send ( Jumbogram ) To be able to verify what was actually transmitted, Wireshark was setup in capturing mode in advance. When transmitting the created Jumbogram we ran into a problem. Without patching Wireshark, it is unable to handle packets with a size larger than 65,535 bytes and will generate the following error message upon receipt of a larger packet: “File contains a record that’s not valid.” We decided to see what would happen if the size of the attached payload were decreased so that it can be handled by Wireshark. To transmit such a packet, we utilized the same packet creation command in Scapy as before, however, this time the value for the RandString function was replaced with a smaller value such that the entire packet would not be larger than 65,535 bytes. According to theory this packet will not be a considered a valid Jumbogram since it lacks in size (because it is too small). After transmitting this packet it immediately appeared in Wireshark, however, classified as a malformed packet. Some experiments later, it turns out that whenever the Payload Length field in the IPv6 header is not set to 0, but for instance the maximum value of 65,535, Wireshark no longer classifies the packet as malformed. So at this point, an invalid Jumbogram, of which the Payload Length field is not set to 0 and the size of the payload is too small, currently yields the best results in Wireshark. Continuing along this line of reasoning, we wondered what would happen if we would patch Wireshark to increase the maximum packet capture size and then transmit a valid Jumbogram the way we did initially using Scapy. We hoped that by doing so we would resolve the “record not valid” error message in Wireshark, while at the same time cause the transmitted Jumbogram no longer to be classified as a malformed packet. Patching Wireshark was done as follows. In the source code of Wireshark we searched for occurrences of code that had a statically configured value of 65,535, essentially limiting the maximum packet capture size to this number of bytes. For all these occurrences, only the ones that involve the size limitation were changed to 150,000 as to minimize the risk of breaking other parts of Wireshark. The exact same was done for libpcap (version 1.2.1), a library that provides a framework for low-level network monitoring, which is a dependency of Wireshark. Compiling the source code for both resulted in new binaries that we used to continue our experiment with. After starting up the modified version of Wireshark, we transmitted a valid Jumbogram as was initially done using Scapy. Although the packet did not generate an error message in Wireshark and showed up in the list of captured packets, the Jumbogram was unfortunately again classified as malformed. However, just as before when transmitting a packet with its Payload Length field in the IPv6 header not set to 0, only this time using a payload of more than 65,535 bytes, the resulting packet is no longer classified as malformed. So it seems that whenever the Payload Length field in the IPv6 header is set to 0, the value that is specified in RFC 2675 about Jumbograms, Wireshark considers the packet to be mal- 6 formed. When it is not set to 0, Wireshark will not mark the packet as being malformed, but will also not interpret it as a Jumbogram because it does not capture any of the payload data that is beyond the first 65,527 bytes. We started to wonder if this problem may somehow have been caused by the way Scapy builds a Jumbogram. We decided to try SendIP to transmit a Jumbogram, identical in size of the aforementioned efforts with Scapy, to see what results it would yield when it is captured by Wireshark. To transmit a Jumbogram using SendIP, a file making up for the payload data was created in advance using the dd program, as shown below. dd i f =/dev / z e r o o f =99960 b y t e s . p a y l o a d bs =99960 count=1 Ignoring that in fact the file is sparse, it essentially consists of 99,960 bytes worth of zeros. This file is incorporated in the SendIP command used to transmit a Jumbogram: s e n d i p −v −p i p v 6 −6 l 0 −p hop −Hj 100000 −f 99960 b y t e s . p a y l o a d : : 1 This command will again result in a malformed packet being captured by Wireshark. Changing the -6l 0 parameter in the command to -6l 65535 will set the Payload Length field in the IPv6 header to 65,535, as done before in Scapy, and will cause Wireshark to no longer classify the packet as malformed. So basically a Jumbogram formatted according to RFC 2675, no matter if transmitted by either Scapy or SendIP, will result in a malformed packet in Wireshark. We suspected that the problems we are facing could very well have been restricted to Wireshark only, and in fact are transmitting valid Jumbograms. Therefore, we decided to try something completely different: sending and receiving Jumbograms between two User-Mode Linux (UML) instances. For this experiment we created another setup containing a simple network of two UML instances. The connecting interfaces of both instances are configured with a link MTU of 150,000 and IPv6 addresses, and connected to a single UML switch to allow network connectivity in between. Both UML instances ran Debian Squeze installations running the Linux kernel version 2.6.32. Scapy was installed on one host to form the sending end-point of the network. On the other host, the receiving endpoint, a simple Python script was ran which utilizes a raw socket to interface with the low-level networking stack. This allowed us to capture any network traffic starting from the data link layer of the OSI model and upwards. Essentially this script does the exact same as what Wireshark does, however, it does not interpret the data that is captured but only writes it to a file for later inspection. The script code of the Python raw socket sniffer can be found in appendix B. With both hosts up and running, we first transmitted a Jumbogram, with the Scapy command shown earlier, to the receiving host running the Python script. Unfortunately, the result was disappointing. The size of the captured file indicated that the amount of transfered data was in the order of 1,500 bytes. We then tried transmitting an invalid Jumbogram to the receiving host with the Payload Length field in the IPv6 header set to 65,535. Again, the capture file indicated that the amount of transfered data (roughly 1,500 bytes) does not even come close to that of a Jumbogram. We firmly believe that the small portion of the transmitted Jumbogram that reaches the other host is due to the hard-coded limitation in the UML switch, which just happens to have the size of a regular Ethernet frame. So at this point either the Jumbogram we are trying to transmit does not conform to the implementation in the Linux kernel, although its format is based on what is defined in RFC 2675; or the implementation of Jumbograms in the Linux kernel is incomplete or non-functional. After these unsuccessful attempts to set up a working virtual experimental environment, we resorted to a final option: InfiniBand. One of the main reasons why IPv6 Jumbograms have been introduced in 1999, is because of the fact that, back then, networking interfaces such as HIPPI [10] and Myrinet [11] were the de facto standard in supercomputing and High Performance Clusters (HPCs). With the eye on the future it was deemed possible that these interfaces, which have a theoretically unlimited MTU limit, would benefit greatly from the transport of large unfragmented packets, especially if transport of large chunks of data had to be made efficient. So the actual application of Jumbograms was directed to these supercomputers and HPCs. However, in the course of the first decade of 2000, interfaces such as Myrinet and HIPPI have become legacy and have mainly been replaced by InfiniBand [12]. InfiniBand is a switched fabric communications link, which adopted many of the features the previously mentioned interfaces had. Today it is widely implemented in almost all of the TOP500 supercomputers, mainly because of its low latency and high throughput features. One of the ways the newer InfiniBand interconnects achieve this high throughput, is through either what is called Remote Direct Memory Access (RDMA), direct memory access from the memory of one computer into that of another or channel-based communication (send/receive). What this means for our research is that we had to find a way to send IP packets over the InfiniBand adaptors. By default, InfiniBand does not provide IP transmission capabilities, because of its superior alternatives of communication. However, for legacy reasons, RFC 4391 [13] and RFC 4392 [14] have introduced IP over InfiniBand (IPoIB). To make use of the IPoIB implementation, we decided to go with the open source OpenFabrics Enterprise Distribution (OFED) [15] software. The OFED stack includes software drivers, core kernel-code, middleware, and user-level interfaces and also introduces the IPoIB protocol we needed in its stack. Our InfiniBand setup consisted of 2 servers running CentOS 5.7 (Linux kernel version 2.6.38). They were directly connected with Mellanox Technologies MT26428 7 (ConnectX VPI PCI Express 2.0 5 Giga-Transfers (GTs) per second - InfiniBand QDR 10 Gigabit) adapters. The Quad Data Rate (QDR) 10 Gigabit links (4x 10 Gigabit) use 8B/10B encoding (every 10 bits sent carry 8 bits of data) making its maximum transmission rate 32 Gbit/s. In theory, InfiniBand boasts an unlimited MTU feature. IPoIB can run over multiple InfiniBand protocols, either over a reliable connection or unreliable datagram. The reliable connection can theoretically achieve an unlimited MTU by making use of Generic Segmentation Offloading (GSO). GSO employs large buffers and lets the underlying network interface card split the data up in smaller packets. For sending and receiving Jumbograms, 2 separate offloads are needed: Large Send Offloading (LSO) and Large Receive Offloading (LRO). What LSO does is presenting a ’virtual’ MTU to the host operating system by employing these large buffers, making the operating system think that a high MTU is present. The large packets are then directly delivered to the underlying InfiniBand fabric which will segment them after all and send them to the receiving node. The receiving InfiniBand adapter will make use of LRO to revert the process, reassemble the packets and deliver them to the host operating system. This entire mechanism is ideal for allowing our interfaces to send and receive IPv6 Jumbograms. Unfortunately, in recent implementations the reliable connection uses an MTU of 64 KiB, while the underlying InfiniBand network fabric uses a 2 KiB MTU. This means that packets of up to 64 KiB can be used, which will all still be segmented to 2 KiB packets using the GSO mechanism. Effectively the maximum MTU we could set was 65,520 bytes, which is the limit for IPv4 packets on the IPoIB protocol. Despite the fact that IPoIB has full IPv6 support, the Jumbo Payload option has apparently not been adopted into the standards, what meant that we could not use InfiniBand to transmit Jumbograms at the time of experimenting. IV. hardware, leading to very few implementations of those frames on the current Internet infrastructure. So it is clearly unthinkable that packets of 64 KiB and up will be supported in the near future. So we focus on IPv6 Jumbograms in the context of large datacenters, where the communication between supercomputers, HPCs and the interconnects between them might be improved. However, as section II detailed, the latest supercomputers will primarily consist of InfiniBand adapters because of its superior concept of data transmission when compared to Ethernet. Now, not every supercomputer and HPC is equipped with the new (and more expensive) InfiniBand adapters, and that leads us to what we believe might be the only place for Jumbograms in the current, and future, networking infrastructure: legacy. Hypothetically, the speed of large data transmissions can be vastly improved by using large, unfragmented packets. It reduces CPU and network interface card overhead by eliminating the need for packet segmentation and reassembly and when Ethernet equipped supercomputers or HPCs need to communicate, either mutually or with newer systems equipped with IPoIB enabled InfiniBand adapters, they could benefit from the concept of large IPv6 packets. However, it will require an update of the Ethernet standards and the IPoIB protocol to facilitate the support of higher MTU limits. As long as the standards will not conform to the MTU limit requirement, there can be no use for, or implementation of, Jumbograms. To conclude, we believe that the entire concept of Jumbograms has been superseded by superior data transmission technologies such as RDMA or channel-based communication. At the time of the publication of the IPv6 Jumbograms RFC (2675), Jumbograms were targeted mainly on the supercomputing technologies that existed then with the eye on the future, not knowing that soon after, newer technologies such as Fiber Channel would become the inexpugnable de facto standard. CONCLUSION A part of the problem of implementing IPv6 Jumbograms, is that the Internet in its current form is so vastly rooted with the Ethernet technology and its baggage of the 1500 bytes MTU limit, that there is no place for unfragmented packets of 64 KiB and up. We even see that datacenters and HPCs are mostly still running on Ethernet technology. As long as there will be no shift from Ethernet to another alternative technology, such as InfiniBand, there is no place for IPv6 Jumbograms. This shift is unthinkable for the current Internet, which kind of ’just happened’. In the past 20 years the Internet has expanded tremendously and pretty much every device that connects to it has conformed to the Ethernet standards. This standard still employs the 1500 bytes MTU limit today and we notice that even a shift from regular Ethernet frames to Jumbo Frames (9000 bytes MTU limit) has proven to be very demanding on current V. FURTHER RESEARCH Compared to the Ethernet protocol, IPoIB a is very immature protocol. It has the theoretical possibility of supporting the virtual MTU limits required for transmitting IPv6 Jumbograms. We encourage the developers and maintainers of IPoIB software implementations to have support for the Jumbo Payload option included in future releases, replacing the current limit of the 16 bit IPv6 Payload Length header field. Furthermore, it is advised that popular packet analysis software such as libpcap, tcpdump and Wireshark consider working support for IPv6 Jumbograms. If and only if the aforementioned software implementations get the necessary updates, benchmarking the performance of data transmission using Jumbograms compared to either regular IPv6 packet transmission and newer technologies such as 8 RDMA, will provide with a better insight of whether or not Jumbograms have a place in the future of datacenters. VI. ACKNOWLEDGMENTS We would like to take this opportunity to thank Jaap van Ginkel and Anthony van Inge of the University of Amsterdam (UvA) for approving this ambitious research [1] D. Borman, S. Deering, and R. Hinden, “RFC 2675: IPv6 Jumbograms,” August 1999. http://tools.ietf.org/ html/rfc2675. [2] M. Mathis, “Raising the Internet MTU.” http://staff. psc.edu/mathis/MTU/. [3] C. Riley, The Best Damn Cisco Internetworking Book Period. Syngress, November 2003. [4] Q. Li, T. Jinmei, and K. Shima, IPv6 Core Protocols Implementation. Morgan Kaufmann, 2007. [5] S. Deering and R. Hinden, “RFC 2460: Internet Protocol, Version 6 (IPv6) Specification,” December 1998. http: //tools.ietf.org/html/rfc2460. [6] J. McCann, S. Deering, and J. Mogul, “RFC 1981: Path MTU Discovery for IPv6,” August 1996. http://tools. ietf.org/html/rfc1981. [7] I. I. S. Systems, “Linux kernel IPv6 Jumbogram Denial of Service,” November 2008. http://www.iss.net/security_center/reference/ vuln/IPv6_Linux_Jumbogram_DoS.htm. [8] Secdev, “Scapy,” 2012. http://www.secdev.org/ project and motivating us along the way. The brainstorming sessions have allowed us to think of new and different angles trying to tackle the difficult implementation of Jumbograms. Furthermore, we would like to thank Ralph Koning from the System And Network Engineering research group for providing us with the InfiniBand equipment, and allowing us to fully configure it at will to learn more about the suitability of the IPoIB protocol in our experiments. projects/scapy/. [9] M. Ricketts, “SendIP,” August 2010. http://is2.antd. nist.gov/ipv6/sendip.html. [10] A. N. S. Institute, “ANSI X3T9.3,” March 1989. http: //hsi.web.cern.ch/HSI/hippi/spec/introduc.htm. [11] Myricom, “ANSI/VITA 26-1998,” 1998. http://www. myricom.com/scs/myrinet/overview/. [12] Compaq, IBM, Hewlett-Packard, Intel, Microsoft, and S. Microsystems, “InfiniBand,” 1999. http://www. infinibandta.org. [13] J. Chu and V. Kashyap, “RFC 4391: Transmission of IP over InfiniBand (IPoIB),” April 2006. http://www. ietf.org/rfc/rfc4391.txt. [14] V. Kashyap, “RFC 4392: IP over InfiniBand (IPoIB) Architecture,” April 2006. http://www.ietf.org/rfc/ rfc4392.txt. [15] O. Alliance, “Openfabrics Enterprise Distribution,” 2012. http://www.openfabrics.org. 9 Appendix A: IPv6 Jumbogram Format Bit offset 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 32 64 96 128 160 192 224 256 288 320 352 352 ... Version Traffic Class Payload Length: 0 Flow Label Next Header: 0 Hop Limit Source Address Destination Address Next Header Hdr Ext Len Option Type: 0xC2 Opt Data Len: 0x04 Jumbo Payload Length: 65,535 < [Value] < 4,294,967,296 Jumbo Payload, other IPv6 extension header, or upper-layer protocol header ... Figure 4: IPv6 Jumbogram Format Appendix B: Python Raw Socket Sniffer import s o c k e t , f c n t l s = s o c k e t . s o c k e t ( s o c k e t . AF PACKET, s o c k e t .SOCK RAW, s o c k e t . n t o h s ( 0 x86DD ) ) while True : # Uncomment f o r w r i t i n g c a p t u r e d d a t a t o a f i l e named ’ c a p t u r e ’ : f i l e = open ( ’ c a p t u r e ’ , ’ a ’ ) f i l e . write ( s . recvfrom (150000) [ 0 ] ) f i l e . close () # Uncomment f o r p r i n t i n g c a p t u r e d d a t a i n h e x a d e c i m a l s t r i n g n o t a t i o n : #p r i n t r e p r ( s . r e c v f r o m ( 1 5 0 0 0 0 ) [ 0 ] )