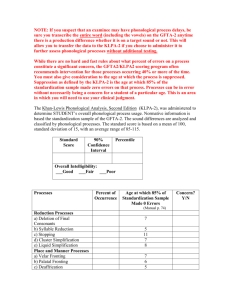
Word form retrieval in language production
advertisement

28-Gaskell-Chap28 3/10/07 7:13 PM Page 471 CHAPTER 28 Word form retrieval in language production Antje S. Meyer and Eva Belke M ODELS of word production often distinguish between processes concerning the selection of a single word unit from the mental lexicon and the retrieval of the associated word form (e.g. Butterworth, 1980; Garrett, 1980; Levelt, 1989). In the present chapter we will first explain the motivation for this distinction and then discuss the retrieval of word forms in more detail. 28.1 Lexical selection and word form retrieval Evidence supporting the distinction between lexical selection and word form retrieval comes from a variety of sources. First, contextual speech errors that involve entire words differ in important respects from errors involving individual segments. The interacting words in whole-word errors, such as threw the window through the clock (Fromkin 1973)1, typically appear in different phrases and are members of the same syntactic category. By contrast, the words involved in sound errors (caught torses instead of taught courses) tend to belong to the same phrase, often appear adjacent to each other, and often differ in syntactic category (Dell, 1986; Garrett, 1975; 1980; see also Meyer, 1992). Based on this and related evidence Garrett (1975; 1980) proposed that speakers first generated a representation capturing the content of the utterance, where the planning units corresponded roughly to clauses, and then generated the syntactic surface structure of the 1 All speech errors, except for those marked otherwise, stem from Fromkin (1973). utterance and its morphological and phonological form using phrases as planning units (see also Bock and Levelt, 1994; Levelt, 1989). Experimental studies support the view that speakers use different planning spans at different planning levels, and specifically that the planning span is wider at the semantic-syntactic level than at the phonological level (e.g. F. Ferreira and Swets, 2002; Jescheniak, Schriefers, and Hantsch, 2003; Meyer, 1996; Smith and Wheeldon, 1999). Second, speakers sometimes experience “tip of the tongue” (TOT) states, i.e. they have a strong feeling of knowing a word, have access to its meaning and syntactic properties (e.g. its grammatical gender), but cannot retrieve the complete phonological form (e.g. Brown and McNeill, 1966; Vigliocco et al., 1997). Sometimes, information about the length of the word, its stress pattern, or some of its phonemes is available. TOT states demonstrate that the lexical representations of words consist of several components, which must be retrieved in separate processing steps. This view is supported by neuropsychological evidence: There are case studies of braindamaged patients who are considerably more impaired in accessing the semantic properties of words than the phonological properties, and of patients who show the opposite pattern. These dissociations constitute strong evidence for the assumption of separate semantic and phonological representations of words (e.g. Cuetos et al., 2000; Caramazza et al., 2000; see also Caramazza and Miozzo, 1997; Dell, Schwartz et al., 1997). Finally, there is a substantial body of experimental evidence concerning the time course of lexical access, demonstrating that information about the semantic and syntactic properties of words becomes available slightly before their 28-Gaskell-Chap28 3/10/07 7:13 PM Page 472 472 · CHAPTER 28 Word form retrieval in language production phonological forms (e.g. Indefrey and Levelt, 2004; Jescheniak et al., 2002; Schmitt et al., 2000; Schriefers et al., 1990; van Turennout et al., 1998). While models of lexical retrieval generally agree on the broad distinction between semanticsyntactic and word form retrieval processes, they differ with regard to the precise architecture of the system. Important issues that are currently under debate are, first, the relationship between semantic, syntactic, and morphophonological units and, second, the time-course of the activation of these units. In the family of models proposed by Dell and collaborators (e.g. Dell 1986; 1988; Dell, Burger, and Svec, 1997) and by Levelt and collaborators (e.g. Levelt 1989; 1992; Levelt et al., 1991; 1999), access to morphophonological units is syntactically mediated. For instance, in Levelt’s model, speakers first select a syntactic word unit (a lemma) and then the associated morphological and phonological units. Similarly, in Dell’s model, activation spreads from conceptual to syntactic to morphophonological units. By contrast, the Independent Network model of language production proposed by Caramazza and colleagues (Caramazza, 1997; Caramazza and Miozzo, 1997) consists of three networks for lexical-semantic, phonological and syntactic information, respectively. Lexicalsemantic representations directly and in parallel activate syntactic representations and phonological representations; i.e. word form activation is not syntactically mediated. Neuropsychological evidence supporting this view comes from studies of patients who are unable to access the grammatical representations of certain types of word but can access their phonological properties (e.g. Caramazza and Miozzo, 1997). Experimental evidence from healthy speakers concerns the representation of homophones, such as buoy/boy or bat (animal/baseball bat). According to models assuming syntactic mediation, these word pairs have distinct semantic and syntactic representations but a shared morphophonological representation. Given that word frequency is commonly assumed to affect the speed of word form retrieval, these models predict that a lowfrequency member of a homophonous pair, such as buoy, should be produced as fast as its highfrequency sibling (boy in the example). By contrast, in the Independent Network model, the members of homophonous word pairs have distinct lexical-semantic representations, which are linked to distinct word form representations. Therefore, a low-frequency word with a highfrequency homophonous sibling should be produced as slowly as an equally low-frequency word without such a sibling. In the empirical studies both patterns of results have been observed (Caramazza et al., 2001; 2004; Jescheniak and Levelt, 1994; Jescheniak, Meyer, and Levelt. 2003; Miozzo et al., 2004; see also Shatzman and Schiller, 2004). With respect to their assumptions about the time course of the retrieval of different types of information, models can be broadly classified as serial stage vs. cascaded models. According to serial stage models (e.g. Bloem and La Heij, 2003; Levelt, 1989; Levelt et al., 1999; Roelofs, 1992; 1997a; 1997b; see also Levelt, 1999), word planning consists of a set of discrete stages that are completed in a specific temporal order. This view entails that information about the morphophonological form of a word only becomes available after a superordinate representation (a concept in Bloem and La Heij’s (2003) model and a lemma in the models proposed by Levelt et al., (1999) and by Roelofs, 1992; 1997a; 1997b) has been selected to be part of the utterance. By contrast, according to cascaded models, word planning consists of processing steps that are temporally ordered but may overlap in time (e.g. Caramazza, 1997; Dell 1986; Dell, Burger, and Svec, 1997; Humphreys et al., 1988; MacKay, 1987; Stemberger, 1985). On this view, conceptual activation suffices for word form information to become activated. The selection of concepts or lemmas is not a necessary condition for word form retrieval. Some cascaded models of lexical access (e.g. Dell, 1986; Dell, Schwartz et al., 1997; MacKay, 1987; Rapp and Goldrick, 2000; Stemberger, 1985) assume feedback from lower to higher levels of processing, such that, for instance, the ease of retrieving the forms of words can affect which words speakers might choose. Researchers have used a variety of techniques to decide between these views (e.g. Bloem and La Heij, 2003; Costa et al., 2000; Costa et al., 1999; Cutting and Ferreira, 1999; V. S. Ferreira and Griffin, 2003; Jescheniak, Hahne, and Schriefers et al., 2003; Jescheniak and Schriefers, 1998; Levelt et al., 1991; Peterson and Savoy, 1998; Rahman et al., 2003; Rapp and Goldrick, 2000). In our view, the bulk of the evidence suggests cascaded processing, possibly with some feedback between adjacent processing levels (see also Dell and O’Seaghdha 1991; 1992; Dell, Burger, and Svec, 1997; Harley, 1984; Rapp and Goldrick, 2000). In sum, in all current models of word production the processes and representations involved in word form retrieval are distinguished from those involved in accessing the semantic and syntactic properties of words. Current controversies concern the relationships between these different types of representations and processes. 28-Gaskell-Chap28 3/10/07 7:13 PM Page 473 Morphological encoding · 473 Below, word form retrieval will be considered in more detail. Following the distinctions in linguistic theory, it is usually divided into three components, morphological, phonological, and phonetic encoding, which we will discuss in turn. 28.2 Morphological encoding Many words (e.g. spoon, umbrella) consist of a single morpheme. Other words consist of two or more morphemes (which are discrete units contributing to the word meaning; see Spencer, 1991), for instance a modifier and a head noun (pancake), a verb stem and an affix (eating) or a prefix, a stem, and an affix (disrespectful). There is abundant informal evidence that speakers have access to morphological knowledge. For instance, speakers can produce and understand novel compounds (banana guard, e-shopping) and inflect them according to the rules of the language (e-shopper’s nightmare). In addition, the way speakers syllabify and stress words reflects their morphological structure. For example, we say dis.ad.van.tage (but di.saster) rather than di.sad.van.tage, preserving the integrity of the affix dis-. Finally, speakers sometimes commit errors such as a hole full of floors (V. S. Ferreira and Humphreys, 2001), in which noun stems exchange leaving an affix behind, or errors such as his dependment—his dependence on the government (MacKay, 1979), in which bound morphemes are attached to incorrect stems (see also Cutler,1980; Pillon, 1998). These errors demonstrate that stems and affixes are retrieved independently of each other (see also Marslen-Wilson, Chapter 11 this volume). Levelt et al. (1999) distinguished three ways in which complex forms could be called upon in word production: by a single concept, linked to a lemma and a diacritic (e.g. boy + plural), by a single concept linked to two lemmas (as in semantically opaque compounds, such as butterfly or parachute), and by multiple concepts mapping onto multiple lemmas (as in semantically transparent compounds, such as woodwork or pancake). In their model, all complex forms are composed from their constituent morphemes. Roelofs (1996; 1998) studied the production of Dutch compounds and verb–particle combinations (such as look up, shut down) using a method called “implicit priming.” Participants first learnt to associate pairs of words (such as highway– bypass, passenger–bystander, rule–bylaw). On each of the following test trials, the first member of a pair (e.g. highway) was presented and the participants produced the second member (bypass) as quickly as possible. Each word pair was tested several times in random order. The crucial feature of the paradigm is that items are combined in such a way that the responses in a block of trials are either related (as in the example, where all response words begin with by-) or unrelated. A robust finding is that participants produce the response words faster when they share one or more word-initial segments than when they are unrelated (Meyer 1990; 1991). The most important result of Roelofs’ experiments was that the implicit priming effect was stronger when the responses shared a complete morpheme (as in the above example) than when they merely shared a syllable including the same number of segments (as in bible, biker, biceps). Thus, there was a specific morphological priming effect. Roelofs and Baayen (2002) showed that the size of this priming effect was the same for transparent compounds (such as sunshine) as for opaque compounds (such as butterfly), demonstrating that the effect did not have a semantic basis. A morphological priming effect was found when the responses shared a word-initial morpheme but not when they shared a word-final morpheme (Roelofs 1996; 1998). This demonstrates that speakers build compounds and verb–participle combinations by selecting the component morphemes and concatenating them, beginning with the wordinitial morpheme. Using a similar paradigm, Janssen et al. (2002; 2004) investigated how Dutch speakers generate inflected verb forms. In line with the results of the speech error research, they concluded that speakers built these forms by inserting stems and affixes into independently generated morphological frames (see also V. S. Ferreira and Humphreys, 2001). The implicit priming experiments carried out by Roelofs and collaborators demonstrate the autonomy of a morphological planning level from a semantic and phonological level. Further evidence for the autonomy of morphological representations stems from studies by Zwitserlood and collaborators, who used short-lag and longlag priming paradigms (Dohmes et al., 2004; Zwitserlood et al., 2000; 2002). In these experiments the morphological priming effects were distinct from semantic and phonological priming effects in both their magnitude and their longevity. Corroborating Roelofs and Baayen’s (2002) findings, Zwitserlood et al. (2002) also found morphological priming effects of approximately equal strength for semantically transparent and opaque compounds. This argues against models of the mental lexicon that do not include morphological representations but view 28-Gaskell-Chap28 3/10/07 7:13 PM Page 474 474 · CHAPTER 28 Word form retrieval in language production similarity effects as arising from semantic and phonological overlap, because such models would predict stronger effects for transparent than opaque compounds (see Plaut and Gonnerman, 2000 for further discussion). A much-discussed issue in the current literature on morphological processing in language production concerns the generation of derived verb forms, in particular English past tense forms. Irregular forms, such as went and was, must obviously be stored in the mental lexicon. Stemberger (2002; 2004a) and Stemberger and Middleton (2003) carried out extensive analyses of speech errors involving complex verb forms (over-tensing errors, such as I didn’t broke it, and over-regularization errors, such as I singed), and concluded that irregular verb forms were stored as part of the same phonological network as simple forms (break, sing) and that during the retrieval of an irregular form, the phonological representation of the base form became activated and competed with the correct irregular form. Regular verb forms could, in principle, be derived in two ways: They could be retrieved from the mental lexicon as units, with their internal structure being represented, or they could be generated by rule. We know of no experimental studies involving healthy English speakers addressing this issue. However, there are case studies demonstrating that the ability to process regular forms or the ability to process irregular forms can be selectively impaired in braindamaged patients. This double dissociation can be viewed as evidence for the involvement of separate processing mechanisms in the generation of regular and irregular forms. However, Lambon Ralph and colleagues (Bird et al., 2003; Braber et al., 2005; Lambon Ralph et al., 2005) proposed that the patients’ profiles in the generation of regular and irregular forms might be linked to their semantic or phonological processing deficits. For instance, the production of irregular forms relies strongly on semantic knowledge because there is often little phonological overlap between the base and the past tense form (e.g. go–went, be –was). Hence one might expect patients with semantic deficits to be more impaired in the generation of these forms than in the generation of regular forms. By contrast, many English regular forms are phonologically more complex than the most common irregular forms, and therefore patients with a phonological deficit should be more impaired in the production of regular than irregular forms. Lambon Ralph and colleagues (e.g. Braber et al., 2005) argued that the patient data largely confirm these predictions. However, Miozzo (2003), Tyler et al. (2004), and Ullman et al. (2005) argued that the patients’ performance could not be fully explained by reference to their semantic and phonological deficits, and therefore postulated separate mechanisms for processing regular and irregular forms. 28.3 Representation of phonological knowledge According to all models of word production, speakers generate the phonological forms of words out of sublexical components rather than retrieving them as units from the mental lexicon. Phonological decomposition must be postulated because the pronunciation of words in connected speech often differs from their citation forms. Connected speech consists of phonological words, which can encompass one or more morphemes, for instance two morphemes of a compound or, in English, a head morpheme and an unstressed function word (e.g. Levelt, 1992; Wheeldon and Lahiri, 1997; 2002). Importantly, phonological words are the domain for stress assignment and syllabification, and segments can assume different positions from the position taken in the citation forms. For example, the phrases demand it or got to can be produced as single phonological words and would be syllabified as de.man.dit and go.to, respectively. In some contexts, phonological segments are deleted (as in go.to) or assimilated (as in handbag pronounced as ham.bag; Inkelas and Zec, 1990; Nespor and Vogel, 1986; Selkirk, 1986). Clearly, speakers can only generate these connected speech forms if at some point during the course of utterance planning individual sounds are available as planning units. Another argument for the assumption of phonological decomposition is that speakers often make speech errors that involve a single segment (some kunny kind) or a cluster of two or three segments that do not correspond to a complete morpheme (stedal peel guitar). Such sound errors are far more frequent than word errors (Boomer and Laver, 1968; Fromkin, 1971; Shattuck-Hufnagel, 1979; 1983). For a number of reasons, most sound errors cannot be viewed as articulatory errors. For instance, the errors are usually phonotactically well-formed, i.e. they result in sound sequences that are permissible in the speaker’s language (Boomer and Laver, 1968; Dell et al., 2000; Fromkin, 1971; Wells, 1951; but see Mowrey and MacKay, 1990 for evidence that some errors yield phonetically and phonotactically ill-formed sequences); and sometimes the left context is altered to accommodate the error 28-Gaskell-Chap28 3/10/07 7:13 PM Page 475 Representation of phonological knowledge · 475 (e.g. a meeting arathon instead of an eating marathon). This shows that the errors must arise during the planning rather than the articulation of the utterances. Considerable research effort has been directed at determining which sublexical processing units are involved in phonological encoding. Most sound errors (sixty to ninety per cent of the errors in different corpora; e.g. Meyer, 1992) involve single segments. Approximately ten per cent of the sublexical errors involve consonant clusters (e.g. clamage dame), usually word onsets, which are replaced as units or replace a single segment. However, there are also errors in which clusters are divided (e.g. sprive for perfection), which suggests a dual representation of clusters, as units and in terms of their constituents (Berg, 1989; 1991; Dell, 1986; Stemberger, 1983, Stemberger and Treiman, 1986). Errors involving single phonological features (e.g. glear plue sky) are quite rare, but the segments involved in segmental errors tend to share more phonological features than would be expected on the basis of chance estimates (Fromkin, 1971; Garcia-Albéa et al., 1989; Garrett, 1975; ShattuckHufnagel, 1983; Stemberger, 1991a; 1991b). Thus, phonological features apparently do not function as processing units that are independently selected during phonological encoding, but they are visible to the encoding processes (see also Goldrick, 2004). Finally, there are very few errors that involve complete syllables. Therefore, syllables, like phonological features, probably do not function as units that are independently selected during phonological encoding (e.g. Meyer, 1992). However, as will be explained below, syllables play an important role as parts of the metrical structure and as processing units during phonetic encoding. Further evidence demonstrating that speakers generate the phonological forms of words by combining phonological segments comes from experimental studies. Some of these studies used the implicit priming paradigm described above, in which participants repeatedly produce sets of related or unrelated words. Meyer (1990; 1991) found that speakers produced the response words faster when the words shared one or more wordinitial segment than when they were unrelated. The size of this implicit priming effect increased with the number of shared segments. Roelofs (1999) found no priming when the response words began with similar sounds, i.e. with segments that shared most of their phonological features (as in bed, bell, pet, pen). This supports the view that speakers generate phonological forms out of segments, not individual features. Other studies have used versions of the picture–word interference paradigm, where speakers name target pictures which are accompanied by related or unrelated spoken or written distractor words (e.g. Damian and Martin, 1999; Jerger et al., 2002; Meyer and Schriefers, 1991; Starreveld and La Heij, 1996). For instance, a speaker might see a picture of a dog and simultaneously hear the word doll, which is phonologically similar to the picture name, or the unrelated word chair. In these experiments, distractors that share word-initial or word-final segments with the target facilitate target-naming relative to unrelated distractors. In experiments with Dutch and English speakers Schiller (1998; 2000) used masked primes and found that phonologically related primes facilitated the naming of target pictures relative to unrelated ones. The size of this facilitatory effect depended on the number of segments shared by prime and target, but it did not depend on whether or not the set of shared segments corresponded to a full syllable of the target (but see Ferrand et al., 1996, who obtained an effect of syllabic structure in French2. This suggests that phonological facilitation arises because the prime preactivates some of the processing units that need to be selected to produce the target. The processing units appear to be segments, not syllables. In addition to retrieving the words’ segments, speakers must generate or retrieve their metrical structure. Levelt (1992; Levelt et al., 1999) argued that the syllable structure of words does not have to be stored in the mental lexicon because it can always be derived on the basis of universal and language-specific syllabification rules. The basic rule is to assign each vowel to a different syllable and to treat the intervening consonants as syllable onsets unless that violates universal or language-specific phonotactic constraints. Therefore, Levelt and colleagues postulated an on-line syllabification process, which assigns segments to syllables. In addition, even languages with relatively varied stress patterns tend to have a default pattern that applies to most words, or to most words within a syntactic class. For instance, in most English words, stress falls on the first syllable that includes a full vowel (e.g. Cutler and Norris, 1988). Levelt et al. (1999; see also Roelofs, 1997b) therefore proposed that the lexical entries for words following the default stress pattern does not include any metrical information. For the remaining words, they postulated 2 Ferrand et al. (1997) reported a syllable-structure effect for English, but they used word naming and lexical decision, not picture-naming tasks. 28-Gaskell-Chap28 3/10/07 7:13 PM Page 476 476 · CHAPTER 28 Word form retrieval in language production lean metrical representations, specifying the number of syllables and the stress pattern. In other models the metrical structure is lexically specified for all words. Most commonly, hierarchical metrical structures are postulated consisting of syllables and syllable constituents (e.g. Dell, 1986; Shattuck-Hufnagel, 1987; 1992; Stemberger, 1985). In many models, metrical frames not only serve as a means of representing prosodic structure but also support the ordering of segments, as will be explained below. Syllable frames with specified syllable constituents have been invoked to explain important properties of segmental ordering errors, in particular the observation that misplaced segments typically move from their correct position to the corresponding position in a new syllable. For instance, a segment stemming from a syllable onset will typically assume a new onset position (as in some kunny kind instead of some funny kind) rather than a coda position. However, this syllable position constraint can also largely be explained as resulting from the tendency of sound errors to involve word onsets, rather than word-internal segments, and from the tendency to involve phonologically similar rather than dissimilar segments (e.g. Dell et al., 2000; Shattuck-Hufnagel 1987). In addition, there is experimental evidence from paradigms using repetition tasks and primed picture-naming tasks suggesting that the parsing of words into consonantal and vocalic elements (the CV structure) is explicitly represented in a structural frame (e.g. Costa and SebastiánGallés, 1998; Sevald et al., 1995; but see Meijer, 1996). This view is supported by speech error analyses showing that segmental ordering errors tend to involve syllables with the same rather than different CV structures (Stemberger, 1990; Vousden et al., 2000; see also Hartsuiker, 2002). However, in a priming study with Dutch speakers, Roelofs and Meyer (1998) did not obtain any evidence for the representation of CV structure; and they argued that the effects of CV structure seen in other studies might arise during the syllabification process rather than demonstrating the existence of stored CV representations. 28.4.1 Segmental retrieval representations According to all current models of word form retrieval, activation spreads from a word or morpheme to the corresponding phonological segments, which are eventually selected to be part of the phonological representation. The models differ in their assumptions about the time-course of the segmental activation and selection processes and in whether or not they assume feedback between the segmental and the morpheme level. In Dell’s (1986) model, all segments of a syllable are activated and selected in parallel. The segments are marked with respect to the syllable positions they are to take, and they are ordered when they are associated to the correspondingly labeled positions in syllable frames. The segments of successive syllables of a morpheme are activated in sequence. Thus, in this and related models (e.g. MacKay, 1987), segmental ordering is achieved through two mechanisms: through the association of segments to the positions of frames and through the timing of the activation of the segments. An alternative view is that all segments of a word are activated simultaneously but are selected in sequence (e.g. O’Seaghdha and Marin, 2000; Sullivan and Riffel, 1999; Wilshire and Saffran, 2005). A third proposal, by Levelt et al. (1999) and Roelofs (1997a; 1997b), is that all segments of a word are activated and selected in parallel, but that the subsequent syllabification process is sequential, proceeding from the onset to the end of the phonological word. The order of the segments within each morpheme is specified in labeled links between the segments and the morpheme3. Finally, there are models in which the segments of a word are activated and selected in sequence (e.g. Dell et al., 1993; Hartley and Houghton, 1996; Sevald and Dell, 1994; Vousden et al., 2000). Most of the empirical evidence about the time-course of segmental activation and selection comes from priming and interference experiments. Several studies have compared the effects of primes or distracters that shared word-initial or word-final segments with the targets (for a recent review see Wilshire and Saffran, 2005). As mentioned, phonologically related distractor words facilitate the naming of target pictures The results of speech error analyses and the experimental evidence reviewed above demonstrate that speakers generate phonological forms by retrieving individual segments and assigning them to positions in metrical structures. In the following section, we discuss how these tasks are accomplished in different models of word form retrieval. 3 In the implemented version of the model (Roelofs 1992; 1997a) activation spreads in parallel from a morpheme to its segments. When the activation of a segment exceeds a threshold, a verification mechanism is triggered that checks whether the selection of the segment is licensed, i.e. whether it is appropriately linked to the target morpheme, and selects the segment when this is the case. 28.4 Building phonological 28-Gaskell-Chap28 3/10/07 7:13 PM Page 477 Building phonological representations · 477 relative to unrelated ones (e.g. Meyer and Schriefers, 1991). If word-initial segments are activated and selected before word-final ones, one might expect to see differences in the magnitude of effects of distractors that share wordinitial or word-final segments with the target. One might also expect to see maximal facilitatory effects of beginning- and end-related distractors at different stimulus onset asynchronies relative to the onset of the target picture; a beginningrelated distractor might need to be presented slightly earlier than an end-related one to be maximally effective. Some studies found such differences (e.g. Meyer and Schriefers, 1991; Sevald and Dell, 1994; Sullivan and Riffel, 1999; see also Wheeldon, 2003), but others failed to find them (e.g. Collins and Ellis, 1992; O’Seaghdha and Marin, 2000; see Wilshire and Saffran, 2005). Stronger evidence for the assumption that phonological encoding encompasses a sequential component comes from studies in which participants repeatedly produce phonologically related or unrelated words. For instance, in the implicit priming paradigm described above, participants are faster to produce sets of words that share one or more word-initial segments than unrelated sets of words. No difference is seen between sets of words that share word-final segments or are unrelated (Meyer 1990; 1991). Roelofs (2004) showed that the implicit priming effect and the effect of an additional phonologically related or unrelated distracter were additive, and concluded that these effects had different origins. Taken together, the results of the priming studies suggest that phonological encoding includes an early parallel component, the activation of phonological segments, and a following sequential component, which is likely to be the selection or syllabification of the segments. Current theories of word form retrieval differ in their assumptions about the information flow between the morphological and the segmental level. In the model proposed by Levelt et al. (1999), information spreads from a morpheme to the phonological segments, but not in the opposite direction. Many other models (e.g. Dell, 1986; 1988; Dell, Burger, and Svec, 1997; Dell, Schwartz et al., 1997) assume feedback between adjacent processing levels. TA number of findings seem to support the latter assumption. Most of them concern properties of speech errors observed in healthy and brain-damaged speakers. For instance, malapropisms (replacements of target words by phonologically related ones, as in a routine promotion instead of proposal, or deep freeze structure instead of deep phrase structure) tend to obey a syntactic category constraint, i.e. the incorrect word tends to belong to the same syntactic category as the target (e.g. Harley and MacAndrew, 2001); semantic errors tend to be more similar in their phonological form than expected on the basis of chance estimates (e.g. Dell 1986; 1990; Dell and Reich, 1981), and sound errors tend to result in existing words rather than non-words (e.g. Baars et al., 1975). These effects can readily be explained if bidirectional links between phonemes and morphemes are assumed. However, they can also be seen as demonstrating the operation of an efficient output monitor that has access to the phonological form of the planned utterance and is sensitive to syntactic and lexical constraints, as proposed by Levelt et al. Other evidence, which represents a more serious challenge to the view that the morphemeto-segment links are unidirectional, concerns the effects of the phonological neighborhood on word production: Words from dense neighborhoods (i.e. words that are phonologically similar to many other words) are produced faster and more accurately than words from sparser neighborhood (Stemberger, 2004b; Vitevitch, 2002; Vitevitch and Sommers, 2003; but see Vitevitch and Stamer, forthcoming). Based on the experimental evidence and results of computer simulations, Dell and Gordon (2003; see also Gordon, 2002; Gordon and Dell, 2001) concluded that effects of neighborhood density had a lexicalsemantic and a phonological component. In other words, form-related neighbors facilitate the selection of a target word unit as well as the selection of its phonological segments. As Dell and Gordon (2003) point out, these findings challenge noninteractive accounts of word production. In such models, form-related neighbors of a target become activated through the monitoring system. For instance, when a speaker prepares to say cap, the related morphemes cat and map become activated because the phonological representation of cap is processed by the speech comprehension system in the same way as a word spoken by a different speaker would be processed (e.g. Levelt, 1989; Postma, 2000). Therefore the neighbors of the target may become available as likely error outcomes, but there is, in noninteractive models, no mechanism through which this would facilitate the correct selection of the target word or of its segments (see also Vitevitch et al., 2004; Goldrick, Chapter 31 this volume). 28.4.2 Retrieval of metrical information Most models of phonological encoding represent metrical information lexically in frames, which 28-Gaskell-Chap28 3/10/07 7:13 PM Page 478 478 · CHAPTER 28 Word form retrieval in language production are retrieved in parallel with the words’ segments. An exception is the model proposed by Levelt et al. (1999), where metrical information is only stored for words with irregular stress pattern but is generated by rule for words that are stressed according to the default rule of the language. Very few experimental studies have investigated how stress patterns are generated or retrieved. Roelofs and Meyer (1998) used the implicit priming paradigm to study the retrieval of metrical frames for words with irregular stress patterns. They obtained an implicit priming effect when the response words shared initial segments as well as the metrical structure, i.e. when they had the same number of syllables and the same stress pattern. No implicit priming effect was seen when the words shared initial segments but differed in stress or length, or when they only had the same metrical structure, but did not share the word-initial segments. As Roelofs and Meyer (1998) argued, this pattern suggests that the metrical frame for irregularly stressed words is retrieved in parallel with the set of segments, and that both must be known for an implicit priming effect to arise (see also Schiller et al., 2004). 28.4.3 Combining metrical and segmental information In most models, the combination of metrical and segmental information is viewed as a process of inserting segments into the positions of independently retrieved metrical frames. In Dell’s (1986) model, the phonological form of a word is generated in the following way. Encoding begins when the word is granted current node status, which means that it receives an extra boost of activation. The next word in the utterance is activated to a lesser degree. Activation spreads from the current node via morpheme and syllable nodes to nodes representing syllable constituents (onset, nucleus, coda), and, in the case of complex constituents (e.g. /st/, /pr/), to segments within constituents, and finally to phonological features. If the word includes several morphemes, the first morpheme is assigned current node status first. At the syllable level, the first syllable is initially the current node and receives extra activation, which is passed on to the subordinate units. Thus, all segments of a syllable become activated at the same time, but the segments of successive syllables reach their activation maxima in succession, according to their order in the utterance. Each activated unit sends a proportion of its activation back to the associated superordinate node. The phonological segments are marked with respect to the syllable positions they can assume. In parallel with the activation of the segments, syntactic rules build a syllable frame with the labeled positions onset, nucleus, and coda. After a number of time steps, which depends on the speech rate, the most highly activated onset, nucleus, and coda segment are selected and associated to the corresponding slots. The activation of these segments is then reset to zero, and the next syllable becomes the current syllable. Dell, Burger, and Svec (1997) proposed a general model of serial order in language production, consisting of (1) a network of stored lexical representations, which are termed content nodes, (2) structural frames representing syntactic rules (e.g. the order of onset, nucleus, and coda in a syllable), and (3) a simple plan network consisting of nodes for past, present, and future representations. The nodes of the plan are linked to content nodes—for instance, at the phonological level, to the onset, nucleus and coda of a syllable. The nodes of the plan induce strong activation of the current lexical representation (e.g. the nucleus), rapid deactivation of past representations (the onset), and some pre-activation of future representations (the coda), so that the content nodes reach their activation maxima at different moments in time and become selected in sequence. The implemented version of the model accounts well for the relative frequencies of different types of serial ordering error (anticipations and perseverations) observed under different speaking conditions and in different groups of speakers. One important finding it explains is a striking relationship between speakers’ overall error rate and the proportion of those errors which are anticipations: whenever the overall rate of errors decreases (e.g. after practice of the materials or at slow rather than faster speech rates), the proportion of anticipations among the errors increases. There are a number of similar spreading activation models, which share important properties with Dell’s models (e.g. Dell, 1988; Eikmeyer and Schade, 1991; Hartley and Houghton, 1996; MacKay, 1982; 1987; Roelofs, 1992; Stemberger, 1985; 1990). They all distinguish between structural frames and content units which are associated to the positions of the frames, and assume that the ordering of units is achieved by the joint action of two mechanisms: the association of units to frames and the time-course of the activation and deactivation of the units. The models differ in (1) the types of content units, for instance in the representation of consonant clusters; (2) the types of metrical frame, for instance in whether they postulate one syllable frame for 28-Gaskell-Chap28 3/10/07 7:13 PM Page 479 Generating the phoentic code of words · 479 all utterances or different frames for words differing in length and CV structure; (3) the processing mechanisms, for instance in whether there are unidirectional feedforward links or bidirectional links between units; or whether they assume only activation and passive decay or lateral inhibition between units as well (see Dell, Burger, and Svec, 1997 for further discussion). As mentioned, metrical frames are invoked in many models as ordering devices for simultaneously activated segments. This is not the case for the model proposed by Levelt et al. (1999) and Roelofs (1997b), where metrical frames are stipulated only for those words that deviate from the main stress pattern of the language. As explained above, segmental ordering is achieved through the labeled links between morphemes and segments. The segments of a word are activated in parallel, and segments are selected if they are appropriately linked to the superordinate node. As in the other models mentioned above, segments are combined into syllables, but this is not achieved by assigning them to positions within syllable frames, but through a rulebased sequential syllabification process. Where possible, stress is assigned by rule. This approach allows for a straightforward treatment of resyllabification processes. As explained earlier, the syllabification of words in context is often different from the syllabification of the citations forms. Models in which segments are marked lexically with respect to the syllable positions they assume in each word need to invoke additional post-lexical processes to explain how segments are assigned to new syllable positions in connected speech. By contrast, in the model proposed by Roelofs and by Levelt et al., the affiliation of segments to syllables is determined on-line. In connected speech, the segments of morphemes which are part of the same phonological word are syllabified together and are assigned directly to the appropriate syllables (see Roelofs, 1997b for further discussion). There are models of serial ordering in speech production that represent frames in a more implicit, distributed fashion (Vousden et al., 2000; for further discussion see Goldrick, Chapter 31 this volume) or do not assume structural frames at all. A model of the latter type is the parallel distributed processing (PDP) model proposed by Dell et al. (1993). PDP models learn to map input strings onto output strings. They commonly consist of at least three layers—an input layer, a layer of hidden units, and an output layer. Rulelike knowledge is an emergent property of the network’s growing ability to map input signals onto output signals. This knowledge is encoded in the links that mediate the mapping from input to output. The PDP model of phonological encoding proposed by Dell et al. maps from lexical units via a hidden layer to output representations (phonological features) in a simple recurrent network. The network virtually pronounces words by generating a series of phoneme representations. Dell et al. augmented the basic feedforward architecture outlined above by two layers of “state units.” On a given processing cycle, these layers make copies of the state of activation in the hidden unit layer and in the output layer, respectively. The state units feed back their copies to the hidden layer on the next processing cycle. This provides the network with a form of memory for preceding processing cycles, which is crucial for the generation of an ordered sequence of segments (Elman, 1990). Dell et al. showed that their model accounted well for important properties of speech errors, such as the observation that they usually result in phonotactically wellformed strings, that vowels tend to interact with vowels and consonants with consonants, and that syllable onsets are affected more often than codas. However, other findings remain unaccounted for. For instance, the model cannot explain segmental exchanges, such as Yew Nork, because each part of the error (the anticipation of one segment and the perseveration of the other) are treated as a separate incidents (see also Goldrick, Chapter 31 below) for a discussion of PDP models). 28.5 Generating the phonetic code of words The word form representation generated during phonological encoding is generally considered to be fairly abstract in that it consists of discrete and context-independent segments. By contrast, articulatory gestures overlap in time, and how a segment is realized depends on which segments precede and follow it (e.g. Browman and Goldstein, 1992). Therefore, the phonological representation must be transformed into a phonetic representation that determines the movements of the articulators to be carried out for each word. How speakers generate the phonetic codes of words has not been widely studied within psycholinguistics (but see Fowler, Chapter 29 this volume, and Port, Chapter 30), and most models of word form retrieval do not include phonetic encoding. Crompton (1982) and Levelt (1992) suggested that speakers had access to a syllabary, a store of pre-assembled gestural scores for frequent syllables. Low-frequency syllables are 28-Gaskell-Chap28 3/10/07 7:13 PM Page 480 480 · CHAPTER 28 Word form retrieval in language production assembled out of the scores corresponding to individual segments. The syllable-sized motor programs are still fairly abstract representations of the speech movements; they do not, for instance, capture any intersyllabic coarticulatory influences or any effects of loudness, pitch, or speech rate on the way syllables are produced. Therefore, further fine-tuning of the gestures must occur during motor planning. Access to a mental syllabary would dramatically reduce the planning effort for phonetic encoding, in particular in languages where a large proportion of all frequently occurring words is composed of a relatively small number of frequent syllables. For instance Schiller et al. (1996) estimated that the 500 most frequent syllable types of Dutch (which has approximately 12,000 different syllable types) suffice to produce eighty per cent of all word tokens. In the model proposed by Levelt et al. (1999) and by Roelofs (1997b), phonetic encoding involves the selection syllable units. As soon as the first phonological syllable has been generated, phonetic encoding can begin. Activation spreads the phonological segments to all syllables that include the segments. An activated syllable is selected if its links to the segments match the syllable positions computed during syllabification. Exactly when a syllable node is selected depends on its level of activation relative to the activation levels of all other syllable nodes which are activated at the same time. Metrical information is used to set parameters for the loudness, pitch, and duration of the syllables. Experimental support for a mental syllabary was first obtained by Levelt and Wheeldon (1994). They used a symbol-association task to elicit words that were selected to vary orthogonally in word frequency and in the frequency of their constituent syllables. For instance, speakers were trained to produce koning (‘king’) upon presentation of the string “//////”, to say advise (‘advice’) upon presentation of the string of “<<<<<<”, and so on. Levelt and Wheeldon found that the participants were faster to produce high-frequency than low-frequency words and, importantly, that they were faster to produce words consisting of high-frequency than of low-frequency syllables. The syllable frequency effect was carried primarily by the frequency-second syllable of the words. This suggests that the retrieval of the second syllable was initiated slightly later than that of the first syllable, and that the participants initiated the responses only after they had retrieved both syllables. In Levelt and Wheeldon’s experiment, syllable and segmental frequency could not be separated. However, Cholin et al. (forthcoming; see also Cholin, 2004) also obtained a small but significant syllable frequency effect when Dutch speakers produced pseudo-words consisting of high- or low-frequency syllables which were carefully matched for segmental frequency. In this study, only the frequency of the first syllable of disyllabic pseudo-words affected the speech onset latencies, implying that the participants began to speak as soon as the first syllable had been fully planned (see also Meyer et al., 2003). A number of other studies have also reported syllable frequency effects in word production tasks carried out by healthy speakers and speakers with aphasia or apraxia of speech (e.g. Aichert and Ziegler, 2004; Laganaro, 2005; Perea and Carreiras, 1998; but see Wilshire and Nespoulous, 2003). However, the interpretation of these results is complicated by the fact that word and non-word reading or repetition tasks, rather than picture naming or association tasks, were used. In a recent study Cholin et al. (2004) found a stronger implicit priming effect when the segments shared by the response words within a set corresponded to a complete syllable in all words (as in beacon, beadle, beaker) than when this was not the case (as in beacon, beadle, beatnik, where the third item is the odd man out). This finding contrasts with the finding of picture–word interference and priming studies mentioned above that the size of facilitatory effects from phonologically related distracters and primes does not depend on whether or not the primed segments correspond to a syllable in the target. Cholin et al. concluded that the syllable-match effect in their implicit priming experiments arose because the participants aimed to prepare for the words not only on the phonological but also, where possible, on the phonetic level. They could only select a syllable program when the first syllable was the same for all words. Thus, the results support the view that syllables are planning units at the phonetic level. 28.6 A model of word form retrieval We have discussed the tasks to be carried out during morphological, phonological and phonetic encoding, we have reviewed key empirical findings, and we have discussed how these can be accounted for within various theoretical frameworks. In this section, we describe, by way of summary, how word forms are retrieved in one specific model, the model proposed by Levelt et al. (1999; see also Roelofs, 1997a). We chose 28-Gaskell-Chap28 3/10/07 7:13 PM Page 481 A model of word form retrieval · 481 feedforward direction only. There is also decay of activation. In WEAVER, the form encoder follows simple selection rules, which are implemented in a parallel distributed manner. Attached to each node are production rules (condition– action pairs) which select nodes if they are appropriately connected to the superordinate target node. The verification and selection process is triggered when the activation level of the node reaches a threshold. The morphological encoder selects one or more morphemes, depending on which lemma, or lemmas, and diacritics have been selected. All morphologically complex forms are composed out of their constituent morphemes. Activation spreads in parallel from a morpheme to the associated segments. The order of the segments is captured in the links between segments and morphemes. Segments are selected if they are appropriately linked to the morpheme. For words with irregular stress pattern a simple metrical frame, encoding the number of syllables and the position of the stressed syllable, is selected as well. The string of selected segments constitutes this model because it is, in our view, the most comprehensive model of word form retrieval presently available, though some of its assumptions are probably incorrect. Most importantly, the model is likely to be too serial: as explained above, there is now good evidence for cascading of information between levels of processing and for limited feedback between processing levels. However, the components of the model are well specified, and it captures the main steps of word planning from the selection of a lemma to the generation of the articulatory code. A unique feature of the model is its on-line syllabification process, which allows for the generation of connected speech forms of words. Finally, though this has not been shown in detail in this chapter, the implemented version of the model (WEAVER and WEAVER++; e.g. Roelofs, 1992; 1996; 1997a; 1997b; 1998; 1999; 2002; 2003; 2004) offers an accurate account of a large number of key experimental findings from a variety of paradigms. Word form retrieval begins when a morpheme receives activation from a lemma (see Figure 28.1). Activation spreads through the network in guitar sg NUMBER OF word form stratum 2 1 w s Σ Σ g i On Nu σʼ diacritic feature node <guitar> METRIC ω lemma node NAME OF HAS NUMBER σʼʼ morpheme node 3 4 t a: On segment nodes Co Nu Nu On Nu On [gi] [ta:] [ta] syllable program syllabary [ta:s] [gi] [ta:] [ta:s] [ta] Figure 28.1 Memory representation of the word form of guitar (see Roelofs, 1997a). nodes 28-Gaskell-Chap28 3/10/07 7:13 PM Page 482 482 · CHAPTER 28 Word form retrieval in language production the input to a sequential syllabification process which groups them into syllables and either links them to the retrieved metrical structure or assigns stress by rule. In morphologically complex words and in connected speech, the segments of adjacent morphemes may be syllabified together, which allows for the assignment of segments to syllable positions that do not correspond to the positions in the citation forms. The syllabified phonological representation is the input to the phonetic encoding processes. During phonetic encoding, syllable program nodes are selected based on the types and order of the segments in the phonological syllables, and metrical information is used to set the parameters for loudness, pitch contour, and word durations. 28.7 Concluding remarks Current models of word form retrieval converge on central assumptions. They all distinguish between morphological, phonological, and phonetic representations and processes; they all assume morphological and phonological decomposition, and agree on the main processing units at these levels. In addition, they all postulate the same basic retrieval mechanisms: activation and selection of units. One might summarize the state of the art by saying that word form retrieval in language production is reasonably well understood. What remains to be done? Most of the psycholinguistic research on word form retrieval has concerned the development of functional models of single word retrieval in speakers of Germanic languages. It is high time to extend the area of investigation in several directions. First, there is a need for systematic crosslinguistic investigations of word form retrieval. The core assumptions endorsed by current models of word form retrieval—for instance that there are several planning levels, that there is decomposition into unit smaller than words, and that processing can be described in terms of the activation and selection of units—should hold for speakers of other languages as well. However, the precise nature and relative difficulty of the tasks speakers carry out during word form retrieval must depend on properties of their language. For instance, for speakers of Germanic languages, the main processing units at the phonological level appear to be phonological segments, not syllables. Chen et al. (2002; see also Chen, 2000) showed that the reverse holds for speakers of Mandarin Chinese. As they explain, this difference is likely to be related to the fact that Mandarin Chinese has fewer syllables than the Germanic languages, clear syllable boundaries, and no resyllabification, i.e. the syllable positions of segments are not altered in connected speech relative to the citation forms. Thus, syllables would appear to be far more useful phonological processing units in Mandarin Chinese than in English or Dutch, and this seems to be reflected in the units speakers use. Systematic crosslinguistic research is required to understand which processing principles are common to speakers of all languages and how speakers adapt to language-specific requirements (see also Costa et al., Chapter 32 this volume). Second, there is a need to consider how speakers generate word forms in context. There is some empirical work on the generation of phonological words (e.g. Wheeldon and Lahiri, 1997; 2002) and on the time-course of segmental retrieval in short phrases, such as the blue kite (e.g. Costa and Caramazza, 2002; Schriefers and Teruel, 1999); but within psycholinguistics, there is hardly any empirical research on the generation of larger prosodic units, such as phonological and intonational phrases (but see F. Ferreira, 1993; Levelt, 1989; Meyer, 1994; Watson and Gibson, 2004; see also Port, Chapter 30 below). We know that speakers generate these units (see also Kraljic and Brennan, 2005; Schafer et al., 2000) but we do not know much about how they do this—for instance about how and when pragmatic and syntactic variables affect phonological and phonetic planning. Finally, an exciting and rapidly expanding new area of research is the investigation of the neurological basis of language production through neurophysiological and imaging techniques (e.g. Hickok and Poeppel, 2004; Indefrey and Levelt, 2004; Indefrey, Chapter 33 below). The challenge is to determine exactly where in the brain the processes postulated in functional models happen, how the areas involved in word production are related, and exactly when during the process of speech planning each of them becomes activated. References Aichert, I., and Ziegler, W. (2004) Syllable frequency and syllable structure in apraxia of speech. Brain and Language, 88: 148–59. Baars, B., Motley, M., and MacKay, D. G. (1975) Output editing for lexical status in artificially elicited slips of the tongue. Journal of Verbal Learning and Verbal Behavior, 14: 382–91. Berg, T. (1989) Intersegmental cohesiveness. Folia Linguistica, 23: 245–80. 28-Gaskell-Chap28 3/10/07 7:13 PM Page 483 References · 483 Berg, T.(1991) Phonological processing in a syllable-timed language with pre-final stress: evidence from Spanish speech error data. Language and Cognitive Processes, 6: 265–301. Bird, H., Lambon Ralph, M. A., Seidenberg, M. S., McClelland, J. L., and Patterson, K. (2003) Deficits in phonology and past-tense morphology: what’s the connection? Journal of Memory and Language, 48: 502–26. Bloem, I., and La Heij, W. (2003) Semantic facilitation and semantic interference in word translation: implications for models of lexical access in language production. Journal of Memory and Language, 48: 468–88. Bock, K., and Levelt, W. (1994) Language production: grammatical encoding. In M. A. Gernsbacher (ed.), Handbook of Psycholinguistics, pp. 945–84. Academic Press, San Diego, Calif. Boomer, D. S., and Laver, J. D. M. (1968) Slips of the tongue. British Journal of Disorders of Communication, 3: 1–12. Braber, N., Patterson, K., Ellis, K., and Lambon Ralph, M. A. (2005) The relationship between phonological and morphological deficits in Broca’s aphasia: further evidence from errors in verb inflection. Brain and Language, 92: 278–287. Browman, C. P., and Goldstein, L. (1992) Articulatory phonology: an overview. Phonetica, 49: 155–180. Brown, R., and McNeill, D. (1966) The “tip-of-the-tongue” phenomenon. Journal of Verbal Learning and Verbal Behavior, 5: 325–337. Butterworth, B. (1980). Some constraints on models of language production. In B. Butterworth (ed.), Language Production, vol. 1: Speech and Talk, pp. 423–59. Academic Press, London. Caramazza, A. (1997) How many levels of processing are there in lexical access? Cognitive Neuropsychology, 14: 177–208. Caramazza, A., Bi, Y. C., Costa, A., and Miozzo, M. (2004) What determines the speed of lexical access: homophone or specific-word frequency? A reply to Jescheniak et al. (2003) [Jescheniak, Meyer, and Levelt, 2003]. Journal of Experimental Psychology: Learning, Memory, and Cognition, 30: 278–282. Caramazza, A., Costa, A., Miozzo, M., and Bi, Y. (2001) The specific-word frequency effect: implications for the representation of homophones in speech production. Journal of Experimental Psychology: Learning, Memory, and Cognition, 27: 1430–1450. Caramazza, A., and Miozzo, M. (1997) The relation between syntactic and phonological knowledge in lexical access: evidence for the “tip-of-the-tongue” phenomenon. Cognition, 64: 309–343. Caramazza, A., Papagno, C., and Ruml, W. (2000) The selective impairment of phonological processing in speech production. Brain and Language, 75: 428–450. Chen, J. T. (2000) Syllable errors from naturalistic slips of the tongue in Madarin Chinese. Psychologia, 43: 15–26. Chen, J. T., Chen, T. M., and Dell, G. S. (2002) Word-form encoding in Mandarin Chinese as assessed by the implicit priming task. Journal of Memory and Language, 46: 751–781. Cholin, J. (2004) Syllables in Speech Production: Effects of Syllable Preparation and Syllable Frequency. Nijmegen, Max Planck Institute, The Netherlands. Cholin, J., Levelt, W. J. M., and Schiller, N. O. (forthcoming) Effects of syllable frequency in speech production. Cognition. Cholin, J., Schiller, N. O., and Levelt, W. J. M. (2004) The preparation of syllables in speech production. Journal of Memory and Language, 50: 47–61. Collins, A. F., and Ellis, A. W. (1992) Phonological priming of lexical retrieval in speech production. British Journal of Psychology, 83: 375–388. Costa, A., and Caramazza, A. (2002) The production of noun phrases in English and Spanish: implications for the scope of phonological encoding in speech production. Journal of Memory and Language, 46: 178–198. Costa, A., Caramazza, A., and Sebastián-Gallés, N. (2000) The cognate facilitation effect: implications for models of lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26: 1283–1296. Costa, A., Miozzo, M., and Caramazza, A. (1999) Lexical selection in bilinguals: do words in the bilingual’s two lexicons compete for selection? Journal of Memory and Language, 41: 365–397. Costa, A., and Sebastián-Gallés, N. (1998) Abstract phonological structure in language production: evidence from Spanish. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24: 886–903. Crompton, A. (1982) Syllables and segments in speech production. In A. Cutler (ed.), Slips of the Tongue and Language Production, pp.109–62. Mouton, Berlin. Cuetos, F., Aguado, G., and Caramazza, A. (2000) Dissociation of semantic and phonological errors in naming. Brain and Language, 75: 451–460. Cutler, A. (1980) Errors of stress and intonation. In V. Fromkin (ed.), Errors of Linguistic Performance: Slips of the Tongue, Ear, Pen, and Hand, pp. 67–80. Academic Press, New York. Cutler, A., and Norris, D. (1988) The role of strong syllables in segmentation for lexical access. Journal of Experimental Psychology: Human Perception and Performance, 14: 113–121. Cutting, J. C., and Ferreira, V. S. (1999) Semantic and phonological information flow in the production lexicon. Journal of Experimental Psychology: Learning, Memory, and Cognition, 25: 318–344. Damian, M. F., and Martin, R. C. (1999) Semantic and phonological codes interact in single word production. Journal of Experimental Psychology: Learning, Memory, and Cognition, 25: 345–361. Dell, G. S. (1986) A spreading-activation theory of retrieval in sentence production. Psychological Review, 93: 283–321. Dell, G. S. (1988) The retrieval of phonological forms in production: tests of predictions from a connectionist model. Journal of Memory and Language, 27: 124–142. Dell, G. S. (1990) Effects of frequency and vocabulary type on phonological speech errors. Language and Cognitive Processes, 5: 313–349. 28-Gaskell-Chap28 3/10/07 7:13 PM Page 484 484 · CHAPTER 28 Word form retrieval in language production Dell, G. S., Burger, L. K., and Svec, W. R. (1997) Language production and serial order: a functional analysis and a model. Psychological Review, 104: 123–147. Dell, G. S., and Gordon, J. K. (2003) Neighbors in the lexicon: friends or foes? In N. O. Schiller and A. S. Meyer (eds.), Phonetics and Phonology in Language Comprehension and Production, pp. 9–37. Mouton de Gruyter, Berlin. Dell, G. S., Juliano, C., and Govindjee, J. (1993) Structure and content in language production: a theory of frames constraints in phonological speech errors. Cognitive Science, 17: 149–195. Dell, G. S., and O’Seaghdha, P. G. (1991) Mediated and convergent lexical priming in language production: comment. Psychological Review, 98: 604–614. Dell, G. S., and O’Seaghdha, P. G. (1992) Stages of lexical access in language production. Cognition, 42: 287–314. Dell, G. S., Reed, K. D., Adams, D. R., and Meyer, A. S. (2000) Speech errors, phonotactic constaints, and implicit learning: a study of the role of experience in language production. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26: 1355–1367. Dell, G. S., and Reich, P. A. (1981) Stages in sentence production: an analysis of speech error data. Journal of Verbal Learning and Verbal Behaviour, 20: 611–629. Dell, G. S., Schwartz, M. F., Martin, N., Saffran, E. M., and Gagnon, D. A. (1997) Lexical access in aphasic and nonaphasic speakers. Psychological Review, 104: 801–838. Dohmes, P., Zwitserlood, P., and Bölte, J. (2004) The impact of semantic transparency of morphologically complex words on picture naming. Brain and Language, 90: 203–212. Eikmeyer, H. J., and Schade, U. (1991) Sequentialization in connectionist language production models. Cognitive Systems, 3: 128–138. Elman, J. L. (1990) Finding structure in time. Cognitive Science, 14: 213–252. Ferrand, L., Segui, J., and Grainger, J. (1996) Masked priming of word and picture naming: the role of syllabic units. Journal of Memory and Language, 35: 708–723. Ferrand, L., Segui, J., and Humphreys, G. W. (1997) The syllable’s role in word naming. Memory and Cognition, 25: 458–470. Ferreira, F. (1993) Creation of prosody during sentence production. Psychological Review, 100: 233–253. Ferreira, F., and Swets, B. (2002) How incremental is language production? Evidence from the production of utterances requiring the computation of arithmetic sums. Journal of Memory and Language, 46: 57–84. Ferreira, V. S., and Griffin, Z. M. (2003) Phonological influences on lexical (mis)selection. Psychological Science, 14: 86–90. Ferreira, V. S., and Humphreys, K. R. (2001) Syntactic influences on lexical and morphological processing in language production. Journal of Memory and Language, 44: 52–80. Fromkin, V. A. (1971) The non-anomalous nature of anomalous utterances. Language, 47: 27–52. Fromkin, V. A. (1973) Speech Errors as Linguistic Evidence. Mouton, The Hague. Garcia-Albéa, J. E., del Viso, S., and Igoa, J. M. (1989) Movement errors and levels of processing in sentence production. Journal of Psycholinguistic Research, 18: 145–161. Garrett, M. F. (1975) The analysis of sentence production. In G. H. Bower (ed.), The Psychology of Learning and Motivation, vol. 9: pp. 133–77. Academic Press, New York. Garrett, M. F. (1980) Levels of processing in sentence production. In B. Butterworth (ed.), Language Production, vol. 1: Speech and Talk, pp. 177–220. Academic Press, New York. Goldrick, M. (2004) Phonological features and phonotactic constraints in speech production. Journal of Memory and Language, 51: 586–603. Gordon, J. K. (2002) Phonological neighborhood effects in aphasic speech errors: spontaneous and structured contexts. Brain and Language, 82: 113–145. Gordon, J. K., and Dell, G. S. (2001) Phonological neighborhood effects: evidence from aphasia and connectionist modeling. Brain and Language, 79: 21–23. Harley, T. A. (1984) A critique of top-down independent levels models of speech production: evidence from non-plan-internal speech errors. Cognitive Science, 8: 191–219. Harley, T. A., and MacAndrew, S. B. G. (2001) Constraints upon word substitution speech errors. Journal of Psycholinguistic Research, 30: 395–418. Hartley, T. A., and Houghton, G. (1996) A linguistically constrained model of short-term memory for nonwords. Journal of Memory and Language, 35: 1–31. Hartsuiker, R. (2002) The addition bias in Dutch and Spanish phonological speech errors: the role of structural context. Language and Cognitive Processes, 17: 61–96. Hickock, G., and Poeppel, D. (2004) Dorsal and ventral streams: a framework for understanding aspecits of the functional anatomy of language. Cognition, 92: 67–99. Humphreys, G. W., Riddoch, M. J., and Quinlan, P. T. (1988) Cascade processes in picture identification. Cognitive Neuropsychology, 5: 67–103. Indefrey, P., and Levelt, W. J. M. (2004) The spatial and temporal signatures of word production components. Cognition, 92: 101–144. Inkelas, S., and Zec, D. (1990) The Phonology–Syntax Connection. University of Chicago Press, Chicago. Janssen, D. P., Roelofs, A. R., and Levelt, W. J. M. (2002) Inflectional frames in language production. Language and Cognitive Processes, 17: 209–344. Janssen, D. A., Roelofs, A., and Levelt, W. J. M. (2004) Stem complexity and inflectional encoding in language production. Journal of Psycholinguistic Research, 33: 365–381. Jerger, S., Martin, R. C., and Damian, M. F. (2002) Semantic and phonological influences on picture naming by children and teenagers. Journal of Memory and Language, 47: 229–249. Jescheniak, J. D., Hahne, A., and Schriefers, H. (2003) Information flow in the mental lexicon during speech planning: evidence from event-related brain potentials. Cognitive Brain Research, 15: 261–276. 28-Gaskell-Chap28 3/10/07 7:13 PM Page 485 References · 485 Jescheniak, J. D., and Levelt, W. J. M. (1994) Word frequency effects in speech production: retrieval of syntactic information and of phonological form. Journal of Experimental Psychology: Learning, Memory, and Cognition, 20: 824–843. Jescheniak, J. D., Meyer, A. S., and Levelt, W. J. M. (2003) Specific-word frequency is not all that counts in speech production: comments on Caramazza, Costa et al., and new experimental data. Journal of Experimental Psychology, 29: 432–438. Jescheniak, J. D. and Schriefers, H. (1998) Discrete serial versus cascaded processing in lexical access in speech production: further evidence from the coactivation of near-synonyms. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24: 1256–1273. Jescheniak, J. D., Schriefers, H., Garrett, M. F., and Friederici, A. D. (2002) Exploring the activation of semantic and phonological codes during speech planning with event-related potentials. Journal of Cognitive Neuroscience, 14: 951–964. Jescheniak, J. D., Schriefers, H., and Hantsch, A. (2003) Utterance format affects phonological priming in the picture-word task: implications for models of phonological encoding in speech production. Journal of Experimental Psychology: Human Perception and Performance, 29: 441–454. Kralijc, T., and Brennan, S. E. (2005) Prosodic disambiguation of syntactic structure: for the speaker or for the addressee? Cognitive Psychology, 50: 194–231. Laganaro, M. (2005) Syllable frequency effect in speech production: evidence from aphasia. Journal of Neurolinguistics, 18: 221–235. Lambon Ralph, M. A., Braber, N., McClelland, J. L., and Patterson, K. (2005) What underlies the neuropsychological pattern of irregular > regular past tense verb production? Brain and Language, 93: 106–119. Levelt, W. J. M. (1989) Speaking: From Intention to Articulation. MIT Press, Cambridge, Mass. Levelt, W. J. M. (1992) Accessing words in speech production: stages, processes and representations. Cognition, 42: 1–22. Levelt, W. J. M. (1999) Models of word production. Trends in Cognitive Sciences, 3: 223–232. Levelt, W. J. M., Roelofs, A., and Meyer, A. S. (1999) A theory of lexical access in language production. Behavioural and Brain Sciences, 22: 1–38. Levelt, W. J. M., Schriefers, H., Vorberg, D., Meyer, A. S., Pechmann, T., and Havinga, J. (1991) The time course of lexical access in speech production: a study of picture naming. Psychological Review, 98: 122–142. Levelt, W. J. M., and Wheeldon, L. (1994) Do speakers have access to a mental syllabary? Cognition, 50: 239–269. MacKay, D. G. (1979) Lexical insertion, inflection, and derivation: creative processes in word production. Journal of Psycholinguistic Research, 8: 477–498. MacKay, D. G. (1982) The problems of flexibility, fluency, and speed–accuracy trade-off in skilled behaviour. Psychological Review, 89: 483–506. MacKay, D. G. (1987) The Organization of Perception and Action: A Theory for Language and Other Cognitive Skills. Springer, New York. Meijer, P. J. A. (1996) Suprasegmental structures in phonological encoding: the CV structure. Journal of Memory and Language, 35: 840–853. Meyer, A. S. (1990) The time course of phonological encoding in language production: the encoding of successive syllables. Journal of Memory and Language, 29: 524–545. Meyer, A. S. (1991) The time course of phonological encoding in language production: phonological encoding inside a syllable. Journal of Memory and Language, 30: 69–89. Meyer, A. S. (1992) Investigation of phonological encoding through speech error analyses: achievements, limitations, and alternatives. Cognition, 42: 181–211. Meyer, A. S. (1994) Timing in sentence production. Journal of Memory and Language, 33: 471–492. Meyer, A. S. (1996) Lexical access in phrase and sentence production: results from picture-word interference experiments. Journal of Memory and Language, 35: 477–496. Meyer, A. S., Roelofs, A., and Levelt, W. J. M. (2003) Word length effects in object naming: the role of a response criterion. Journal of Memory and Language, 48: 131–147. Meyer, A. S., and Schriefers, H. (1991) Phonological facilitation in picture-word interference experiments: effects of stimulus onset asynchrony and types of interfering stimuli. Journal of Experimental Psychology: Learning, Memory, and Cognition, 17: 1146–1160. Miozzo, M. (2003) On the processing of regular and irregular forms of verbs and nouns: evidence from neuropsychology. Cognition, 87: 101–127. Miozzo, M., Jacobs, M. L., and Singer, N. J. W. (2004) The representation of homophones: evidence from anomia. Cognitive Neuropsychology, 21: 840–866. Mowrey, R. A., and MacKay, I. R. A. (1990) Phonological primitives: electromyographic speech error evidence. Journal of the Acoustical Society of America, 88: 1299–1312. Nespor, M., and Vogel, I. (1986) Prosodic Phonology. Foris, Dordrecht, The Netherlands. O’Seaghdha, P., and Marin, J. W. (2000) Phonological competition and cooperation in form-related priming: sequential and nonsequential processes in word production. Journal of Experimental Psychology: Human Perception and Performance, 26: 57–73. Perea, M., and Carreiras, M. (1998) Effects of syllable frequency and syllable neighborhood frequency in visual word recognition. Journal of Experimental Psychology: Human Perception and Performance, 24: 134–144. Peterson, R. R., and Savoy, P. (1998) Lexical selection and phonological encoding during language production: evidence for cascaded processing. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24: 539–557. Pillon, A. (1998) Morpheme units in speech production: evidence from laboratory-induced verbal slips. Language and Cognitive Processes, 13: 465–498 Plaut, D. C., and Gonnerman, L. M. (2000) Are nonsemantic morphological effects incompatible with a distributed connectionist approach to lexical processing? Language and Cognitive Processing, 15: 445–485. 28-Gaskell-Chap28 3/10/07 7:13 PM Page 486 486 · CHAPTER 28 Word form retrieval in language production Postma, A. (2000) The detection of errors during speech production: a review of speech monitoring models. Cognition, 77: 97–131. Rahman, R. A., van Turenout, M., and Levelt, W.J.M. (2003) Phonological encoding is not contingent on semantic feature retrieval: an electrophysiological study. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29: 850–860. Rapp, B., and Goldrick, M. (2000) Discreteness and interactivity in spoken word production. Psychological Review, 107: 460–499. Roelofs, A. (1992) A spreading-activation theory of lemma retrieval in speaking. Cognition, 42: 107–142. Roelofs, A. (1996) Serial order in planning the production of successive morphemes of a word. Journal of Memory and Language, 35: 854–876. Roelofs, A. (1997a) The WEAVER model of word-form encoding in speech production. Cognition, 64: 249–284. Roelofs, A. (1997b) Syllabification in speech production: evaluation of WEAVER. Language and Cognitive Processes, 12: 657–693. Roelofs, A. (1998) Rightward incrementality in encoding simple phrasal forms in speech production: verb–particle combinations. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24: 904–919. Roelofs, A. (1999) Phonological segments and features as planning units in speech production. Language and Cognitive Processes, 14: 173–200. Roelofs, A. (2002) Spoken language planning and the initiation of articulation. Quarterly Journal of Experimental Psychology: Section A, 55: 465–483. Roelofs, A. (2003) Goal-referenced selection of verbal action: modeling attentional control in the Stroop task. Psychological Review, 110: 88–125. Roelofs, A. (2004) Seriality of phonological encoding in naming objects and reading their names. Memory and Cognition, 32: 212–222. Roelofs, A., and Baayen, H. (2002) Morphology by itself in planning the production of spoken words. Psychonomic Bulletin and Review, 9: 132–138. Roelofs, A., and Meyer, A. S. (1998) Metrical structure in planning the production of spoken words. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24: 922–939. Schafer, A. J., Speer, S. R., Warren, P., and White, S. D. (2000) Intentional disambiguation in sentence production and comprehension. Journal of Psycholinguistic Research, 29: 169–182. Schiller, N. O. (1998) The effect of visually masked syllable primes on the naming latencies of words and pictures. Journal of Memory and Language, 39: 484–507. Schiller, N. O. (2000) Single word production in English: The role of subsyllabic units during phonological encoding. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26: 512–528. Schiller, N. O., Fikkert, P., and Levelt, C. C. (2004) Stress priming in picture naming: an SOA study. Brain and Language, 90: 231–240. Schiller, N. O., Meyer, A. S., Baayen, H., and Levelt, W. J. M. (1996) Comparison of lexeme and speech syllables in Dutch. Journal of Quantitative Linguistics, 3: 8–28. Schmitt, B. M., Münte, T. F., and Kutas, M. (2000) Electrophysiological estimates of the time course of semantic and phonological encoding during implicit picture naming. Psychophysiology, 37: 473–484. Schriefers, H., Meyer, A. S., and Levelt, W. J. M. (1990) Exploring the time course of lexical access in language production: picture–word interference studies. Journal of Memory and Language, 29: 86–102. Schriefers, H., and Teruel, E. (1999) Phonological facilitation in the production of two-word utterances. European Journal of Cognitive Psychology, 11: 17–50. Selkirk, E. O. (1986) On derived domains in sentence phonology. Phonology Yearbook, 371–405. Sevald, C. A., and Dell, G. S. (1994) The sequential cuing effect in speech production. Cognition, 53: 91–127. Sevald, C. A., Dell, G. S., and Cole, J. (1995) Syllable structure in speech production: are syllables chunks or schemas? Journal of Memory and Language, 34: 807–820. Shattuck-Hufnagel, S. (1979) Speech errors as evidence for a serial-ordering mechanism in sentence production. In W. E. Cooper and E. C. T. Walker (eds.), Sentence Processing: Psycholinguistic Studies presented to Merrill Garrett, pp. 295–342. Springer, New York. Shattuck-Hufnagel, S. (1983) Sublexical units and suprasegmental structure in speech production planning. In P. F. MacNeilage (ed.), The Production of Speech, pp. 109–36. Springer, New York. Shattuck-Hufnagel, S. (1987) The role of word-onset consonants in speech-production planning: new evidence from speech error patterns. In S. Keller and M. Gopnick (eds.), Motor and Sensory Processes of Language, pp. 17–51. Erlbaum, Hillsdale, NJ. Shattuck-Hufnagel, S. (1992) The role of word structure in segmental serial ordering. Cognition, 42: 213–258. Shatzman, K. B., and Schiller, N. O. (2004) The word frequency effect in picture naming: contrasting two hypotheses using homonym pictures. Brain and Language, 90: 160–169. Smith, M., and Wheeldon, L. (1999) High level processing scope in spoken sentence production. Cognition, 73: 205–246. Spencer, A. (1991) Morphological Theory. Blackwell, Cambridge, Mass. Starreveld, P. A., and La Heij, W. (1996) Time-course analysis of semantic and orthographic context effects in picture naming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 22: 896–918. Stemberger, J. P. (1983) The nature of /r/ and /l/ in English: evidence from speech errors. Journal of Phonetics, 11: 139–147. Stemberger, J. P. (1985) An interactive activation model of language production. In A. W. Ellis (ed.), Progress in the Psychology of Language, vol.1: pp. 143–86. Erlbaum, Hillsdale, NJ. Stemberger, J. P. (1990) Wordshape errors in language production. Cognition, 35: 123–157. Stemberger, J. P. (1991a) Radical underspecification in language production. Phonology, 8: 73–112. Stemberger, J. P. (1991b) Apparent anti-frequency effects in language production: the addition bias and phonological underspecification. Journal of Memory and Language, 30: 161–185. 28-Gaskell-Chap28 3/10/07 7:13 PM Page 487 References · 487 ED: Please check & confirm as initials is not provided. Stemberger, J. P. (2002) Overtensing and the effect of regularity. Cognitive Science, 26: 737–766. Stemberger, J. P. (2004a) Phonological priming and irregular past. Journal of Memory and Language, 50: 82–95. Stemberger, (2004b) Neighborhood effects on error rates in speech production. Brain and Language, 90: 413–422. Stemberger, J. P., and Middleton, C. S. (2003) Vowel dominance and morphological processing. Language and Cognitive Processes, 18: 369–404. Stemberger, J. P., and Treiman, R. (1986) The internal structure of word-initial consonant clusters. Journal of Memory and Language, 25: 163–180. Sullivan, M. P., and Riffel, B. (1999) The nature of phonological encoding during spoken word retrieval. Language and Cognitive Processes, 14: 15–45. Tyler, L. K., Stamatakis, E. A., Bright, P. et al., (2004) Processing objects at different levels of specificity. Journal of Cognitive Neuroscience, 16: 351–362. Ullman, M. T., Pancheva, R., Love, T., Yee, E., Swinney, D., and Hickok, G. (2005) Neural correlates of lexicon and grammar: evidence from the production, reading, and judgement of inflection in aphasia. Brain and Language, 93: 185–238. van Turennout, M., Hagoort, P., and Brown, C. M. (1998) Brain activity during speaking: from syntax to phonology in 40 milliseconds. Science, 280: 572–574. Vigliocco, G., Antonini, T., and Garrett, M. F. (1997) Grammatical gender is on the tip of Italian tongues. Psychological Science, 8: 314–317. Vitevitch, M. S. (2002) The influence of phonological similarity neighborhoods on speech production. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28: 735–747. Vitevitch, M. S., Armbrüster, J., and Chu, S. (2004) Sublexical and lexical representations in speech production: effects of phonotactic probablility and onset density. Journal of Experimental Psychology: Learning, Memory, and Cognition, 30: 514–529. Vitevitch, M. S., and Sommers, M. S. (2003) The facilitative influence of phonological similarity and neighborhood frequency in speech production in younger and older adults. Memory and Cognition, 31: 491–504. Vitevitch, M. S., and Stamer, M. K. (forthcoming) The curious case of competition in Spanish speech production. Language and Cognitive Processes. Vousden, J. I., Brown, G. D. A., and Harley, T. A. (2000) Serial control of phonology in speech production: a hierarchical model. Cognitive Psychology, 41: 101–175. Watson, D., and Gibson, E. (2004) The relationship between intonational phrasing and syntactic structure in language production. Language and Cognitive Processes, 19: 713–755. Wells, R. (1951) Predicting slips of the tongue. Yale Scientific Magazine, 3: 9–30. Wheeldon, L. R. (2003) Inhibitory form priming of spoken word production. Language and Cognitive Processes, 18: 81–109. Wheeldon, L. R., and Lahiri, A. (1997) Prosodic units in speech production. Journal of Memory and Language, 37: 356–381. Wheeldon, L. R., and Lahiri, A. (2002) The minimal unit of phonological encoding: prosodic or lexical word. Cognition, 85: B31–B41. Wilshire, C. E., and Nespoulous, J. L. (2003) Syllables as units in speech production: data from aphasia. Brain and Language, 84: 424–447. Wilshire, C. E., and Saffran, E. M. (2005) Contrasting effects of phonological priming in aphasic word production. Cognition, 95: 31–71. Zwitserlood, P., Bölte, J., and Dohmes, P. (2000) Morphological effects on speech production: evidence from picture naming. Language and Cognitive Processes, 15: 563–591. Zwitserlood, P., Bölte, J., and Dohmes, P. (2002) Where and how morphologically complex words interplay with naming pictures. Brain and Language, 81: 358–367. 28-Gaskell-Chap28 3/10/07 7:13 PM Page 488