Peas data (self intolerant) X=interval (yrs. without peas) Y=severity
advertisement
 X=interval (yrs. without peas) Y=severity")
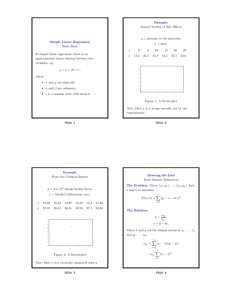
Peas data (self intolerant) X=interval (yrs. without peas) Y=severity of root disease (citation in Rao p. 392) Line is Y = 4.226526 - 0.158666X. Data are Yi = α + βXi + e Assumption: e~N(0,σ2) Goal: Estimate α, β, σ2 Estimates: a (4.227), b (-0.1587), MSE=? How was line obtained? How accurate are estimates? Notes: (1) Expected value (mean) of Y at a given X is α + βX = “intercept” + (“slope” times X). (2) Variance is constant (same at all X) Estimates: I will minimize the sum of the squared vertical deviations from the points to the line by adjusting a and b. “Error sum of squares”=SSE(a,b) = n ∑ (Y − a − bX ) i i =1 2 i Minimum at a and b that make the derivatives 0: Derivative with respect to a: n − 2∑ (Yi − a − bX i ) = 0 i =1 Divide by n: Y − a − bX = 0 or a = Y − bX ******** n so now, minimize ∑ (Y − Y ) − b( X i =1 i i − X )) 2 . n − 2∑ ((Yi − Y ) − b( X i − X ))( X i − X ) = 0 i =1 n n b = ∑ (Yi − Y )( X i − X ) / ∑ ( X i − X ) 2 **** i =1 i =1 Compute Sxy = numerator of b, Sxx = denominator of b, take ratio b=Sxy/Sxx. X = 7.1, Y = 3.1 x 0 4 6 6 6 8 9 9 9 14 == 71 Xd -7.1 -3.1 -1.1 (___) -1.1 0.9 1.9 1.9 1.9 6.9 y 3.5 3.7 5.0 3.0 3.1 3.1 1.5 3.0 3.5 1.6 ==== 31.0 yd XY XX YY 0.4 -2.84 50.41 0.16 0.6 -1.86 9.61 0.36 1.9 -2.09 1.21 3.61 (___) (____) (____) (___) 0.0 0.00 1.21 0.00 0.0 0.00 0.81 0.00 -1.6 -3.04 3.61 2.56 -0.1 -0.19 3.61 0.01 0.4 0.76 3.61 0.16 -1.5 -10.35 47.61 2.25 ====== ====== ==== -19.50 122.90 9.12 Sxy Sxx Syy b = ________ a= ___________ MSE=? Use MSE = SSE/df df = degrees of freedom = n-2 (here)=____ n 2 ( Y − Y ) − b ( X − X )) i i = SSE = ∑ i =1 n n ∑ (Y − Y ) i =1 i 2 − 2b ∑ ( X i − X )(Yi − Y ) + b i =1 n 2 ∑(X i =1 =Syy – 2(Sxy/Sxx)Sxy+(Sxy/Sxx)2Sxx Combine last two terms: SSE= Syy – (S2xy/Sxx) = _____ for peas MSE = SSE/df= ____ for peas i − X )2 Run peas experiment again. Same X values and, of course, different Y values. Now we have another intercept a and slope b! Repeat many times – “population” of (a,b) pairs. What do histograms of a and b look like? (1) They will look normal (2) Mean of sample intercepts (a’s) is true population intercept α. “unbiased” (3) Mean of sample slopes (b’s) is true population slope β. “unbiased” (4) Variance of a’s is 2 1 X σ 2( + ) n S xx σ2 (5) Variance of b’s is S xx Summary: 2 1 X a ~ N (α , σ 2 ( + )) ****** n S xx b ~ N (β , σ2 ) S xx ****** Words: Total Sum of Squares or SS(total): Syy Regression Sum of Squares or SS(regression): S2xy/Sxx Note that SSE = SS(total)-SS(regression) SS(total) and SS(regression) sometimes called “corrected” sums of squares. Mean Squared Error (MSE= estimate of σ2) Standard error of ___ <- slope, intercept, etc.) This is always the square root of the variance of ___ with MSE substituted in for the unknown σ2. From St 511: Standard error of Y is ______ Compute standard error _____of the intercept for peas data Compute standard error____ of the slope for peas data. Test the hypothesis that interval (X) has no effect on average root disease severity. Conclusion ________ Put a 95% confidence interval on the drop in severity that you would get, on average, by adding a year to any given interval. data peas; input x y @@; cards; 0 3.5 4 3.7 6 5.0 6 3.0 6 3.1 8 3.1 9 1.5 9 3.0 9 3.5 14 1.6 10 . ; proc reg; model Y = X/P CLM; run; Analysis of Variance Source Model Error Corrected Total DF Sum of Squares Mean Square 1 8 9 3.09398 6.02602 9.12000 3.09398 0.75325 Root MSE Dependent Mean Coeff Var 0.86790 3.10000 27.99682 F Value Pr > F 4.11 0.0773 R-Square Adj R-Sq 0.3393 0.2567 Parameter Estimates Variable Intercept x DF 1 1 Parameter Estimate Standard Error t Value 4.22653 -0.15867 0.61991 0.07829 6.82 -2.03 Pr > |t| 0.0001 0.0773 ANOVA S(total) = Syy measures variation of Y around its mean. SSE measures the variation around the fitted line Therefore SS(regression) measures the amount of variation in Y “explained by” X. The proportion of variation explained by X is called r2. It is SS(regression)/SS(total). The square root of r2, r, is the correlation between Y and X. -1<r<1. Regression F test: Mean square = SS/df on each line of ANOVA. F ratio is (regression mean square)/(error mean square). F is testing the null hypothesis that nothing besides the intercept is helpful in explaining the variation in Y, that is, all slopes are 0. In “simple linear regression” (fitting a line) there is only 1 slope so F and t are testing the same thing. Note that F = t2. This is NOT true in “multiple” regression. Question: Do we have statistical evidence (at 5% “level”) that interval does affect infection? What does “level” mean? Question: Have we proved, shown, or even suggested that there is no effect of interval? Question: Suppose we KNOW without looking at the data that increasing interval cannot make infection worse. Do we now have evidence of an effect? Prediction: I want to estimate what would happen, on average, if I left fields without peas (or other legumes) for 10 years (I have no data there). Prediction is easy: a+b(10)=4.23-1.59 = 2.64 I want to put a confidence interval on this prediction. Confidence interval is always estimate +/- (t)(standard error of estimate) Estimate is 2.64 t has n-2 = 8 df. Variance of a+bX0 is 1 ( X 0 − X )2 σ ( + ) n S xx 2 So… plug in MSE and take square root (note that X0 is our 10 here). In SAS, add X=10 and missing value (.) for Y. data peas; input x y @@; cards; 0 3.5 4 3.7 6 5.0 6 3.0 6 3.1 8 3.1 9 1.5 9 3.0 9 3.5 14 1.6 10 . ; proc reg; model Y = X/P CLM; run; Dep Var Predicted Std Error y Value Mean Predict 3.5000 3.7000 5.0000 3.0000 3.1000 3.1000 1.5000 3.0000 3.5000 1.6000 . 4.2265 3.5919 3.2745 3.2745 3.2745 2.9572 2.7985 2.7985 2.7985 2.0052 2.6399 0.6199 0.3664 0.2876 0.2876 0.2876 0.2834 0.3122 0.3122 0.3122 0.6059 0.3562 95% CL Mean 2.7970 2.7470 2.6112 2.6112 2.6112 2.3038 2.0787 2.0787 2.0787 0.6080 1.8185 5.6560 4.4367 3.9378 3.9378 3.9378 3.6106 3.5184 3.5184 3.5184 3.4024 3.4612 Residual -0.7265 0.1081 1.7255 -0.2745 -0.1745 0.1428 -1.2985 0.2015 0.7015 -0.4052 . Predicting an individual future Y: Our target is now α + βX0 + e, not just α + βX. Our estimate is still a+bX0, but now we have missed the target by (α −a)+ (β-b)X0 + e, not just (α −a)+ (β-b)X0. We know that the variance of e is σ2 and the variance of [(α −a)+ (β-b)X0] is 1 ( X 0 − X )2 σ ( + ) so n S xx the variance of the sum of these two items is 1 ( X 0 − X )2 σ ( + + 1) n S xx 2 2 and the standard error of our predicted individual Y is thus 1 ( X 0 − X )2 MSE ( + + 1) n S xx Example: At X0=10 we have 1 (10 − 7.1) 2 MSE ( + + 1) = _______ 10 122.9 proc reg; model Y = X/P CLI; run; Dep Var Predicted Std Error y Value Mean Predict 3.5000 3.7000 5.0000 3.0000 3.1000 3.1000 1.5000 3.0000 3.5000 1.6000 . 4.2265 3.5919 3.2745 3.2745 3.2745 2.9572 2.7985 2.7985 2.7985 2.0052 2.6399 0.6199 0.3664 0.2876 0.2876 0.2876 0.2834 0.3122 0.3122 0.3122 0.6059 0.3562 95% CL Predict 1.7670 1.4195 1.1661 1.1661 1.1661 0.8519 0.6716 0.6716 0.6716 -0.4357 0.4765 6.6860 5.7643 5.3830 5.3830 5.3830 5.0625 4.9254 4.9254 4.9254 4.4461 4.8032 Residual -0.7265 0.1081 1.7255 -0.2745 -0.1745 0.1428 -1.2985 0.2015 0.7015 -0.4052 . Problems: Only one variable to explain Y Only straight lines for prediction Formulas are unpleasant. Solution: Move to matrix notation. Formulas easy to write down, amenable to computer algorithms. Can fit curves and multiple variables.