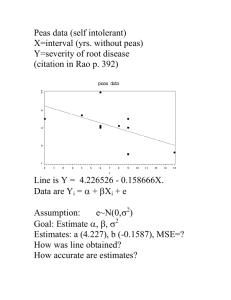
Example
Animal Studies of Side Effects
y = pressure in the pancreas,
Simple Linear Regression
Basic Ideas
x = dose,
In simple linear regression, there is an
approximately linear relation between two
variables, say
x
0
5
10
15
20
25
y
14.6
24.5
21.8
34.5
35.1
43.0
35
40
y = α + βx + ,
y
30
where
20
25
• x and y are observed;
15
• α and β are unknown;
• is a random error with mean 0.
0
5
10
15
20
25
x
Figure 1: A Scatterplot
Note: Here x is a design variable, set by the
experimenter.
Slide 1
Slide 2
Example
From the Coleman Report
Drawing the Line
Least Squares Estimators
The Problem: Given (x1, y1 ), · · · , (xn , yn ), find
a and b to minimize
y = Ave 6th Grade Verbal Score,
x = Mother0 s Education (yrs),
SS(a, b) =
x
12.38
10.34
14.08
14.20
12.3
11.46
y
37.01
26.51
36.51
40.70
37.1
33.40
n
X
i=1
(yi − a − bxi)2 .
The Solution:
sxy
,
sxx
a = ȳ − bx̄,
36
38
40
b=
28
30
32
y
34
where x̄ and ȳ are the sample means of x1 , · · · , xn
and y1 , · · · , yn ,
26
sxy =
11
12
13
14
x
Figure 2: A Scatterplot
n
X
i=1
sxx
(xi − x̄)(yi − ȳ),
n
X
i=1
(xi − x̄)2
Note: Here x is a covariate, measured with y.
Slide 3
Slide 4
Here
The Details
∂
SS(a, b) = −2n(ȳ − a − bx̄).
∂a
So,
a = ȳ − bx̄.
Recall:
SS(a, b) =
n
X
i=1
(yi − a − bxi)2 .
Differentiate:
Then
n
X
∂
SS(a, b) = −2
[yi − ȳ − b(xi − x̄)]xi ,
∂b
i=1
= −2
n
X
∂
SS(a, b) = −2
(yi − a − bxi )
∂a
i=1
n
X
∂
(yi − a − bxi)xi .
SS(a, b) = −2
∂b
i=1
Now
n
X
i=1
Solve:
∂
SS(a, b) = 0,
∂a
∂
SS(a, b) = 0.
∂b
i=1
(yi − ȳ)xi − b
(xi − x̄) = 0 =
n
X
i=1
(xi − x̄)xi
n
X
(yi − ȳ).
i=1
So,
n
X
i=1
(yi − ȳ)xi =
n
X
i=1
(yi − ȳ)(xi − x̄)
= sxy ,
Slide 5
Slide 6
Example
Coleman
a = .1312 and b = 2.8149
say, and
n
X
n
X
i=1
i=1
(xi − x̄)xi =
n
X
(xi − x̄)2
38
40
= sxx ,
34
32
30
26
and
28
∂
SS(a, b) = −2 sxy − bsxx ,
∂b
sxy
,
b=
sxx
Verbal Score
36
say. So,
a = ȳ − bx̄.
The Least Squares Line: y = a + bx.
Slide 7
11
12
13
14
Mother’s Ed
Figure 3: A Scatterplot and Least Squares Line
Slide 8
Calculating a and b
By Machine: Using Excel-for example.
Example
Dose and Response
By Hand: Recall
sxx =
n
X
i=1
(xi − x̄)2 =
n
X
i=1
x2i − nx̄2 .
Similarly,
sxy =
n
X
=
i=1
n
X
(xi − x̄)(yi − ȳ)
i=1
xiyi − nx̄ȳ.
Sums
xy
x2
14.6
0
0
5
24.5
122.5
25
10
21.8
218
100
15
34.5
517.5
225
20
35.1
702
400
x
y
0
25
43.0
1075
625
75
173.5
2635
1375
So, a, and b can be calculated from the sums of
xi, yi , xiyi , and x2i .
Slide 9
Slide 10
The Calculations
A Least Squares Line
Pressure vs. Dose
a = 15.595 and b = 1.066
40
75
x̄ =
= 12.5,
6
173.5
ȳ =
= 28.92,
6
35
sxy = 2635 − 6 × 12.5 × 28.92
25
sxx = 1375 − 6 × (12.5)2
y
30
= 466.25,
15
20
= 437.5,
b=
466.25
= 1.066,
437.5
and
0
5
10
15
20
25
x
Figure 4: A Scatterplot and Least Squares Line
a = 28.92 − 1.066 × 12.5 = 15.595.
Slide 11
Slide 12
Some Terminology
Least Squares Estimators:
sxy
b=
,
sxx
a = ȳ − bx̄.
Error Sum of Squares AKA Residual Sum of
Squares:
n
X
e2i .
SSE =
Fitted Values AKA Predicted Values:
Let
i=1
ŷi = a + bxi = ȳ + b(xi − x̄).
Residuals:
syy =
n
X
i=1
(yi − ȳ)2 .
Then
syy = SSR + SSE.
ei = yi − yˆi
Let
= yi − ȳ − b(xi − x̄)
R2 =
Then
Regression Sum of Squares:
SSR =
n
X
i=1
SSR
.
syy
100R2 = % ExplainedVariation
(ŷi − ȳ)2
Note: SSE = syy − SSR = syy − b2sxx .
= b2 sxx
Slide 13
Slide 14
Derivation of syy = SSR + SSE
syy =
n
X
=
i=1
n
X
Inference
(yi − ŷi + ŷi − ȳ)2
e2i + 2
i=1
n
X
i=1
+
n
X
i=1
ei (ŷi − ȳ)
(ŷi − ȳ)
2
Model: Now suppose
yi = α + βxi + i ,
where
1 , · · · , n ∼ind Normal[0, σ 2].
Notes -a) Here −∞ < α, β < ∞ and σ 2 > 0 are
unknown.
Here
1st = SSE,
3rd = SSR,
and
2nd = 2
n
X
i=1
b) If x1, · · · , xn are covariates, then the
conditions must hold conditionally given
x1 , · · · , x n .
c) Then
[(yi − ȳ) − b(xi − x̄)b(xi − x̄)
= 2[bsxy − b2 sxx ] = 0
Slide 15
yi ∼ Normal[α + βxi, σ 2 ],
are (conditionally) independent.
Slide 16
The Likelihood Function
That is,
sxy
,
sxx
α̂ = a = ȳ − bx̄.
β̂ = b =
The Likelihood Function is
n
Y
1
1
√
exp[− 2 (yi − α − βxi)2 ]
2
2σ
2πσ
i=1
n
1 n
1 X
exp[− 2
= √
(yi − α − βxi )2 ]
2
2σ i=1
2πσ
The Profile Likelihood Function: Then
`(α̂, β̂, σ 2 |x, y) = −
1
− n[log(σ 2) + log(2π)].
2
So, the log-likelihood function is
`(α, β, σ 2 |x, y) = −
n
1 X
(yi − α − βxi)2
2σ2
1
SSE
2σ2
The MLE of σ 2 :
i=1
∂
1
1
`=
SSE − 2 n.
∂σ2
2σ4
2σ
1
− n[log(σ 2 ) + log(2π)].
2
So,
σ̂2 =
Maximum Likelihood Estimators: α̂ and β̂ must
minimize the sum of squares. So,
SSE
.
n
Let
M SE =
MLE = LSE.
Slide 17
SSE
.
n−2
Slide 18
Means and Variances
Of The Estimators
Unbiasedness: α̂ and β̂ are unbiased; that is
E(β̂) = β,
E(α̂) = α.
Variances:
σβ̂2 =
σ2
sxx
1
x̄2 2
σα̂2 =
+
σ
n sxx
Derivation For β̂: First,
sxy =
n
X
=
n
X
i=1
i=1
since
Pn
i=1 (xi
(xi − x̄)(yi − ȳ)
So,
1
E(SxY )
sxx
n
1 X
=
(xi − x̄)E(Yi )
sxx i=1
E(β̂) =
=
=
n
1 X
sxx
1
sxx
i=1
n
X
i=1
(xi − x̄)(α + βxi)
(xi − x̄)β(xi − x̄)
1
sxx β
sxx
= β.
=
(xi − x̄)yi ,
− x̄) = 0.
Slide 19
Slide 20
Sampling Distributions
Similarly,
σβ̂2 =
=
=
1
s2xx
n
X
Var
(xi − x̄)Yi
n
1 X
s2xx
1
s2xx
α̂ ∼ Normal[α, σα̂2 ],
β̂ ∼ Normal[β, σβ̂2 ],
i=1
i=1
(xi − x̄)2σ2
and
βsxx
SSE
∼ χ2n−2 ;
σ2
and (α̂, β̂) is independent if SSE
σ2
.
=
sxx
Corollary: MSE is unbiased; that is
E(MSE ) = σ 2 .
Notes: • Unbiasedness requires (only) E(i ) = 0.
• Variance requires also, E(2i ) = σ 2 .
Note: The proof is similar to the independence of
X̄ and S 2 in the one-sample normal problem.
Note: Unbiasedness of MSE requires only
E(i ) = 0 and E(2i ) = σ 2 .
• Similarly for α̂.
Slide 21
Slide 22
Confidence Intervals
Studentization: Let
σ̂β̂2 =
MSE
sxx
T =
β̂ − β
σ̂β̂
Here
and
Then
T ∼ tn−2
So, if c is the 97.5th percentile of tn−2 , for
example, then
P [−c ≤ T ≤ c] = .95.
−c ≤ T =
β̂ − β
≤c
σ̂β̂
iff
β̂ − cσ̂β̂ ≤ β ≤ β̂ + cσ̂β̂ .
Confidence Interval For β: So,
β̂ ± cσ̂β̂
is a 95% confidence interval for β.
Confidence Interval for α: Similarly,
α̂ ± cσ̂α̂
is a 95% confidence interval for α.
0.1
i
O
Slide 23
Slide 24
Here
Example
United Data Services
Here
n = 14,
x = Units Serviced,
c = 2.180,
y = Time.
β̂ = 15.509,
sxx = 114,
150
MSE = 29.074
100
σ̂β̂2 =
29.074
= (.505)2
114
and
50
Time
So,
2
4
6
8
β̂ ± cσ̂β̂ = 15.509 ± 2.18 × .505
10
Units
= 15.51 ± 1.10
Figure 5: A Scatterplot
Slide 25
Slide 26
Testing H0 : β = 0
Review
From the Confidence Interval: Accept if
β̂ − cσ̂β̂ ≤ 0 ≤ β̂ + cσ̂β̂ .
• Least squares estimators, a and b.
• Properties of the estimators
Equivalently, reject if
|T0 | =
• Simple Linear Regression: Y = α + βx + |β̂|
> c.
σ̂β̂
Example: Dose Response.
β̂ ± cσ̂β̂ = 1.066 ± .449 and, therefore, H0 is
rejected.
Note: This is the GLRT (as in the one sample
problem).
Slide 27
• Sampling distributions
• Confidence intervals
• Testing
Today
• Estimating expected response
• Predicting a future value
Slide 28
Estimating Expected Response
Let
Let
µ̂0 = α̂ + β̂x0.
µ(x) = α + βx = E(Y |x).
Then
E(µ̂0 ) = µ0
Fix an x0 and let
σµ̂2 0 =
µ0 = µ(x0) = α + βx0
Let
Then
σ̂µ̂2 0 =
µ(x) = µ0 + β(x − x0 ).
So,
1
n
+
(x0 − x̄)2 2
σ .
sxx
1
(x0 − x̄)2 MSE .
+
n
sxx
Then
µ0 = α 0 ,
when
x0 = x − x 0 .
µ̂0 ± cσ̂µ̂0
is a level 95% confidence interval for µ0.
Slide 29
Slide 30
Predicting a Future Value
Now let
Y0 ∼ Normal[µ0 , σ̂ 2 ]
Then
∆
∼ tn−2
σ̂∆
and
Ŷ0 = µ̂0 .
and
P [−c ≤
Then
∆ := Y0 − Ŷ0 = Y0 − µ0 − (µ̂0 − µ0 ).
Here
−c ≤
So,
E(∆) = 0
2
σ∆
= σ 2 + σµ̂2 0
1
(x0 − x̄)2 2
= 1+ +
σ
n
sxx
∆
≤ c] = .95.
σ̂∆
∆
≤c
σ̂∆
iff
Ŷ0 − cσ̂∆ ≤ Y0 ≤ Ŷ0 + cσ̂∆ .
So,
P [Ŷ0 − cσ̂∆ ≤ Y0 ≤ Ŷ0 + cσ̂∆ ] = .95.
The interval
Y0 − Ŷ0 ∼
Let
2
Normal[0, σ∆
].
Ŷ0 ± cσ̂∆
is called a 95% prediction interval for Y0 .
(x0 − x̄)2 1
2
MSE .
σ̂∆
= 1+ +
n
sxx
Slide 31
Slide 32
Example
United Data Service
The Prediction Interval
Take
x0 = 4,
For this
Ŷ0 = µ̂0 = 66.198
µ0 = α + 4β.
Then
µ̂0 = 4.162 + 4 × 15.509 = 66.198.
1
(4 − 6)2 2
σ̂∆
= 1+
+
29.074
14
114
2
= (5.672)
Next
σ̂µ̂2 0
x̄ = 6
1
(4 − 6)2 +
29.074 = (1.76)2.
=
14
114
So
µ̂0 ± cσ̂µ̂0 = 66.198 ± 2.18 × 1.76
= 66.20 ± 3.84.
Slide 33
Ŷ0 ± cσ̂∆ = 66.198 ± 2.18 × 5.672
= 66.20 ± 12.36
Note: Average response versus individual
response.
Slide 34
 0
0