Notes 3.2 Least Squares Regression
advertisement

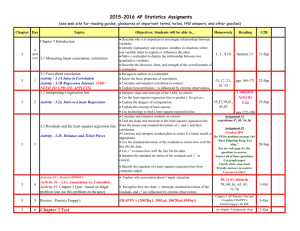
Notes 3.2 Least Squares Regression Tapping on cans Don’t you hate it when you open a can of soda and some of the contents spray out of the can? Two AP®Statistics students, Kerry and Danielle, wanted to investigate if tapping on a can of soda would reduce the amount of soda expelled after the can has been shaken. For their experiment, they vigorously shook 40 cans of soda and randomly assigned each can to be tapped for 0 seconds, 4 seconds, 8 seconds, or 12 seconds. Then, after opening the can and cleaning up the mess, the students measured the amount of soda left in each can (in ml). Here are the data and a scatterplot. The scatterplot shows a fairly strong, positive linear association between the amount of tapping time and the amount remaining in the can. The line on the plot is a regression line for predicting the amount remaining from the amount of tapping time. Tapping on cans The equation of the regression line in the previous Example is Problem: Identify the slope and y intercept of the regression line. Interpret each value in context. Tapping on cans For the soda example, the equation of the regression line is soda = 248.6 + 2.63 (tapping time). If we shook a can in the same way as the students did in their project and tapped on it for 10 seconds, the predicted amount of soda remaining would be ml. Extrapolation and Tapping on Cans Should we predict how much soda will be left after 60 seconds of tapping? No! We have data only for cans that were tapped between 0 and 12 seconds. We don’t know if the linear pattern will continue beyond these values. In fact, if we did make a prediction for 60 seconds of tapping, we would get 406.4 ml, over 50 ml more than the can originally contained (355 ml)! Tapping on cans Problem: Find and interpret the residual for the can that was tapped for 4 seconds and had 260 ml of soda remaining. Tapping on cans Here is a scatterplot showing the tapping time and amount of soda remaining for the 40 cans. The least-squares regression line, is shown on the scatterplot. The point in red is for the can that was tapped for 8 seconds and had 255 ml remaining after it was opened. The predicted amount remaining is The residual is therefore y – = 255 – 269.64 = –14.64 ml. The amount of soda remaining in this can is 14.64 ml less than expected, based on the tapping time. Tapping on cans For the can tapping data, the standard deviation of the residuals is When we use the least-squares regression line to predict the amount of soda remaining using the amount of tapping time, our predictions will typically be off by about 5 ml. Tapping on cans Suppose that we wandered in during the can tapping experiment and found a partially-full can. Without measuring the contents, how could we predict how much soda is left in the can? We don’t know how long it was tapped, so our best guess would be the mean amount remaining in all the cans: y = 264.45 ml. The first scatterplot shows the squared prediction errors when using the mean amount y as our prediction. When using y as our predicted value, the sum of the squared prediction errors is 6506. We could make much better predictions if we knew the tapping time. How much better? The second scatterplot shows the squared prediction errors when using the least-squares regression line. The sum of the squared residuals when using the least-squares regression line is 951.3 (the same quantity we used to calculate the standard deviation of the residuals, other than a small difference due to rounding error). This means that only = 14.6% of the variation in amount of soda remaining is unaccounted for by the least-squares regression line. The remaining variation is due to other factors, such as how vigorously the can was shaken. Therefore, 1 – = 85.4% of the variability in amount of soda remaining is accounted for by the linear model relating amount of soda remaining to tapping time. Does seat location affect grades? Many people believe that students learn better if they sit closer to the front of the classroom. Does sitting closer cause higher achievement, or do better students simply choose to sit in the front? To investigate, an AP®Statistics teacher randomly assigned students to seat locations in his classroom for a particular chapter. At the end of the chapter, he recorded the row number (row 1 is closest to the front) and test score for each student. Least-squares regression was performed on the data. A scatterplot with the regression line added, a residual plot, and some computer output from the regression are shown below. Problem: (a) What is the equation of the least-squares regression line that describes the relationship between row number and test score? Define any variables that you use. (b) Interpret the slope of the regression line in context. (c) Find the correlation. (d) Is a line an appropriate model to use for these data? Explain how you know. Back to the track! Here is a scatterplot with the least-squares regression line for predicting the long-jump distance from sprint time and a scatterplot with the least-squares regression line for predicting sprint time from long-jump distance. Does committing more turnovers lead to more points? In the National Basketball Association, there is a strong positive association between the number of turnovers a player has and the number of points that he scores. A turnover is when a player loses the ball to the other team. Could a player increase his point totals by turning the ball over more frequently? No! Turning the ball over to the other team doesn’t cause a player to score more points. Instead, there is another variable that influences both turnovers and points: playing time. Players who are on the court more often tend to score more points and have more turnovers than players who don’t get much playing time. HW: pg. 193: 35, 37, 39, 41, 45 HW: pg. 193 43, 47, HW: 49, 52 48, 50, 55, 58 HW: 59, 61, 63, 65, 69, 71-78