University of Arizona/ECE
advertisement

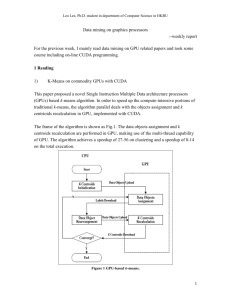
Multicores, Multiprocessors, and
Clusters
Computer Architecture
Applications
suggest how
to improve
technology,
provide
revenue to
fund
development
Applications
Technology
Co
mp
a ti b
i l i ty
Improved
technologies
make new
applications
possible
Cost of software development
makes compatibility a major
force in market
2
Crossroads
First Microprocessor Intel 4004, 1971
•
•
•
•
•
•
4-bit accumulator
architecture
8μm pMOS
2,300 transistors
3 x 4 mm2
750kHz clock
8-16 cycles/inst.
Hardware
•Team from IBM building PC
prototypes in 1979
•Motorola 68000 chosen initially, but
68000 was late
•8088 is 8-bit bus version of 8086 =>
allows cheaper system
•Estimated sales of 250,000
•100,000,000s sold
[ Personal Computing Ad, 11/81]
4
Crossroads
DYSEAC, first mobile computer!
• 900 vacuum
tubes
• memory of
512 words of
45 bits each
• Carried in two tractor trailers, 12 tons + 8 tons
• Built for US Army Signal Corps
End of Uniprocessors
e
ar
w
rd
a
H
Ha
d
ase
b
are
rdw
d
an
e
ar
w
ft
so
!
LP
I
,
Intel
Intel cancelled
cancelled high
high
performance
uniprocessor,
performance uniprocessor,
joined
joined IBM
IBM and
and Sun
Sun for
for
multiple
multiple processors
processors
6
Trends
• Shrinking of transistor sizes: 250nm (1997) Æ
130nm (2002) Æ 65nm (2007) Æ 32nm (2010)
Æ28nm(2011, AMD GPU, Xilinx FPGA)
Æ22nm(2011, Intel Ivy Bridge, die shrink of the
Sandy Bridge architecture)
• Transistor density increases by 35% per year and die size
increases by 10-20% per year… more cores!
7
Trends
Transistors: 1.43x / year
Cores: 1.2 - 1.4x
Performance: 1.15x
Frequency: 1.05x
Power: 1.04x
2004
2010
Source: Micron University Symp.
8
Crossroads
1996
When I took this class!
2002
2009
2011
Reduced ILP to 1 chapter!
Shift to multicore!
Reduced emphasis on ILP Request, Data, Thread,
Introduce thread level P.
Instruction Level
Introduce: GPU, cloud
computing, Smart phones,
tablets!
9
Introduction
• Goal: connecting multiple computers
to get higher performance
– Multiprocessors
– Scalability, availability, power efficiency
• Job-level (process-level) parallelism
– High throughput for independent jobs
• Parallel processing program
– Single program run on multiple processors
• Multicore microprocessors
– Chips with multiple processors (cores)
Parallel Programming
• Parallel software is the problem
• Need to get significant performance
improvement
– Otherwise, just use a faster uniprocessor,
since it’s easier!
• Difficulties
– Partitioning
– Coordination
– Communications overhead
Parallel Programming
• MPI, OpenMP, and Stream Processing
are methods of distributing workloads
on computers.
• Key: Overlapping program architecture
with the target hardware architecture
Shared Memory
• SMP: shared memory multiprocessor
– Small number of cores
– Share single memory with uniform memory latency (symmetric)
• SGI Altix UV 1000 (ARDC, December 2011 )
–
–
–
–
58 nodes, 928 cores
up to 2,560 cores with architectural support to 327,680
support for up to 16TB of global shared memory.
Programming: Parallel OpenMP or Threaded
Example: Sum Reduction
• Sum 100,000 numbers on 100 processor UMA
– Each processor has ID: 0 ≤ Pn ≤ 99
– Partition 1000 numbers per processor
– Initial summation on each processor
sum[Pn] = 0;
for (i = 1000*Pn;
i < 1000*(Pn+1); i = i + 1)
sum[Pn] = sum[Pn] + A[i];
• Now need to add these partial sums
– Reduction: divide and conquer
– Half the processors add pairs, then quarter, …
– Need to synchronize between reduction steps
Example: Sum Reduction
half = 100;
repeat
synch();
if (half%2 != 0 && Pn == 0)
sum[0] = sum[0] + sum[half-1];
/* Conditional sum needed when half is odd;
Processor0 gets missing element */
half = half/2; /* dividing line on who sums */
if (Pn < half) sum[Pn] = sum[Pn] +
sum[Pn+half];
until (half == 1);
Distributed Memory
• Distributed shared memory (DSM)
– Memory distributed among processors
– Non-uniform memory access/latency (NUMA)
– Processors connected via direct (switched) and non-direct (multihop) interconnection networks
– Hardware sends/receives messages between processors
Distributed Memory
•
•
•
•
URDC SGI ICE 8400
179 nodes, 2112 cores
up to 768 cores in a single rack,
scalable from 32 to tens of
thousands of nodes
– lower cost than SMP!
• distributed memory system (Cluster),
• typically using MPI programming.
Sum Reduction (Again)
• Sum 100,000 on 100 processors
• First distribute 100 numbers to each
– The do partial sums
sum = 0;
for (i = 0; i<1000; i = i + 1)
sum = sum + AN[i];
• Reduction
– Half the processors send, other half
receive and add
– The quarter send, quarter receive and
add,…
Sum Reduction (Again)
• Given send() and receive() operations
limit = 100; half = 100;/* 100 processors */
repeat
half = (half+1)/2; /* send vs. receive
dividing line */
if (Pn >= half && Pn < limit)
send(Pn - half, sum);
if (Pn < (limit/2))
sum = sum + receive();
limit = half; /* upper limit of senders */
until (half == 1); /* exit with final sum */
– Send/receive also provide synchronization
– Assumes send/receive take similar time to addition
Matrix Multiplication
C0
C1
C2
C3
C4
C5
C6
C7
C8
A0
A1
A2
A3
A4
A5
A6
A7
A8
=
X
B0
B1
B2
B3
B4
B5
B6
B7
B8
Message Passing Interface
• language-independent communications
protocol
– provides a means to enable communication
between different CPUs
• point-to-point and collective communication
• is a specification, not an implementation
• standard for communication among
processes on a distributed memory system
– does not mean that its usage is restricted
• processes do not have anything in common,
and each has its own memory space.
Message Passing Interface
• set of subroutines used explicitly to
communicate between processes.
• MPI programs are truly "multi-processing"
• Parallelization can not be done
automatically or semi-automatically as in
"multi-threading" programs
• function and subroutine calls have to be
inserted into the code
• alter the algorithm of the code with respect
to the serial version.
Is it a curse?
• The need to include the parallelism explicitly in the
program
• is a curse
– more work and requires more planning than multithreading,
• and a blessing
– often leads to more reliable and scalable code
– the behavior is in the hands of the programmer.
– Well-written MPI codes can be made to scale for
thousands of CPUs.
OpenMP
• a system of so-called "compiler directives" that are
used to express parallelism on a shared-memory
machine.
• an industry standard
– most parallel enabled compilers that are used
on SMP machines are capable of processing
OpenMP directives.
• OpenMP is not a “language”
• Instead, OpenMP specifies a set of subroutines in
an existing language (FORTRAN, C) for parallel
programming on a shared memory machine
Systems using OpenMP
• SMP (Symmetric Multi-Processor)
– designed for shared-memory machines
• advantage of not requiring communication between
processors
• allow multi-threading,
– dynamic form of parallelism in which sub-processes are
created and destroyed during program execution.
• OpenMP will not work on distributed-memory
clusters
OpenMP
compiler directives are inserted by the programmer, which allows stepwise
parallelization of pre-existing serial programs
Multiplication
for (ii = 0; ii < nrows; ii++){
for(jj = 0; jj < ncols; jj++){
for (kk = 0; kk < nrows; kk++){
array[ii][jj] = array[ii][kk] *
array[kk][jj] + array[ii][jj];
}
}
}
=
X
Multiplication
unified code: OpenMP constructs are treated as
comments when sequential compilers are used.
#pragma omp parallel for shared(array,
ncols, nrows) private(ii, jj, kk)
for (ii = 0; ii < nrows; ii++){
for(jj = 0; jj < ncols; jj++){
for (kk = 0; kk < nrows; kk++){
array[ii][jj] = array[ii]kk] *
array[kk][jj] + array[ii][jj];
}
}
}
Why is OpenMP popular?
• The simplicity and ease of use
– No message passing
– data layout and decomposition is handled automatically
by directives.
• OpenMP directives may be incorporated
incrementally.
– program can be parallelized one portion after another
and thus no dramatic change to code is needed
– original (serial) code statements need not, in general, be
modified when parallelized with OpenMP. This reduces
the chance of inadvertently introducing bugs and helps
maintenance as well.
• The code is in effect a serial code and more
readable
• Code size increase is generally smaller.
OpenMP Tradeoffs
• Cons
– currently only runs efficiently in shared-memory
multiprocessor platforms
– requires a compiler that supports OpenMP.
– scalability is limited by memory architecture.
– reliable error handling is missing.
– synchronization between subsets of threads is not
allowed.
– mostly used for loop parallelization
MPI Tradeoffs
• Pros of MPI
– does not require shared memory architectures which
are more expensive than distributed memory
architectures
– can be used on a wider range of problems since it
exploits both task parallelism and data parallelism
– can run on both shared memory and distributed
memory architectures
– highly portable with specific optimization for the
implementation on most hardware
• Cons of MPI
– requires more programming changes to go from serial to
parallel version
– can be harder to debug
Another Example
• Consider the following code fragment that finds the
sum of f(x) for 0 <= x < n.
for(ii = 0; ii < n; ii++){
sum = sum + some_complex_long_fuction(a[ii]);
}
Solution
for(ii = 0; ii < n; ii++){
sum = sum + some_complex_long_fuction(a[ii]);}
#pragma omp parallel for shared(sum, a, n) private(ii,
value)
for (ii = 0; ii < n; ii++) {
value = some_complex_long_fuction(a[ii]);
#pragma omp critical
sum = sum + value;
}
or better, you can use the reduction clause to get
#pragma omp parallel for private(sum) reduction(+: sum)
for(ii = 0; ii < n; ii++){
sum = sum + some_complex_long_fuction(a[ii]);
}
Measuring Performance
• Two primary metrics: wall clock time (response
time for a program) and throughput (jobs
performed in unit time)
– If we upgrade a machine with a new processor what do
we increase?
– If we add a new machine to the lab what do we
increase?
• Performance is measured with benchmark suites:
a collection of programs that are likely relevant to
the user
– SPEC CPU 2006: cpu-oriented (desktops)
– SPECweb, TPC: throughput-oriented (servers)
– EEMBC: for embedded processors/workloads
Measuring Performance
• Elapsed Time
– counts everything (disk and memory accesses, I/O ,
etc.) a useful number, but often not good for
comparison purposes
• CPU time
– doesn't count I/O or time spent running other programs
can be broken up into system time, and user
time
Benchmark Games
• An embarrassed Intel Corp. acknowledged Friday that a
bug in a software program known as a compiler had led the
company to overstate the speed of its microprocessor chips
on an industry benchmark by 10 percent. However,
industry analysts said the coding error…was a sad
commentary on a common industry practice of “cheating”
on standardized performance tests…The error was pointed
out to Intel two days ago by a competitor, Motorola …came
in a test known as SPECint92…Intel acknowledged that it
had “optimized” its compiler to improve its test scores. The
company had also said that it did not like the practice but
felt to compelled to make the optimizations because its
competitors were doing the same thing…At the heart of
Intel’s problem is the practice of “tuning” compiler programs
to recognize certain computing problems in the test and
then substituting special handwritten pieces of code…
Saturday, January 6, 1996 New York Times
SPEC CPU2000
Problems of Benchmarking
• Hard to evaluate real benchmarks:
– Machine not built yet, simulators too slow
– Benchmarks not ported
– Compilers not ready
• Benchmark performance is composition of
hardware and software (program, input,
compiler, OS) performance, which must all
be specified
Xe
on
3G
Hz
51
2K
B
(-O
0)
3G
Hz
51
2K
B(
op
tim
ize
d)
B
1.6
G
Hz
/1
M
B,
-O
B1
3
.6
-x
G
B
Hz
/1
MB
,Xe
O
on
3xW
3G
Hz
51
2K
B(
-x
W
)
Xe
on
Compiler and Performance
Application Set
500
450
400
350
300
250
200
150
100
50
0
Amdahl's Law
• The performance enhancement of an
improvement is limited by how much the
improved feature is used. In other words:
Don’t expect an enhancement proportional
to how much you enhanced something.
• Example:
"Suppose a program runs in 100 seconds on a
machine, with multiply operations responsible for
80 seconds of this time. How much do we have to
improve the speed of multiplication if we want the
program to run 4 times faster?"
Amdahl's Law
1. Speed up = 4
2. Old execution time = 100
3. New execution time = 100/4 = 25
4. If 80 seconds is used by the affected part =>
5. Unaffected part = 100-80 = 20 sec
6. Execution time new = Execution time unaffected +
Execution time affected / Improvement
7. 25= 20 + 80/Improvement
8. Improvement = 16
How about 5X speedup?
Amdahl's Law
• An application is “almost all” parallel: 90%.
Speedup using
– 10 processors => 5.3x
– 100 processors => 9.1x
– 1000 processors => 9.9x
Stream Processing
• streaming data in and out of an execution core without
utilizing inter-thread communication, scattered (i.e.,
random) writes or even reads, or local memory.
– hardware is drastically simplified
– specialized chips (graphics processing unit)
Parallelism
• ILP exploits implicit parallel operations within
a loop or straight-line code segment
• TLP explicitly represented by the use of
multiple threads of execution that are
inherently parallel
Time (processor cycle)
Multithreaded Categories
Superscalar
Fine-Grained Coarse-Grained
Multiprocessing
Simultaneous
Multithreading
Thread 1
Thread 3
Thread 5
Thread 2
Thread 4
Idle slot
Graphics Processing Units
• Few hundred $ = hundreds of parallel FPUs
– High performance computing more accessible
– Blossomed with easy programming environment
• GPUs and CPUs do not go back in computer
architecture genealogy to a common
ancestor
– Primary ancestors of GPUs: Graphics
accelerators
History of GPUs
• Early video cards
– Frame buffer memory with address generation for
video output
• 3D graphics processing
– Originally high-end computers (e.g., SGI)
– 3D graphics cards for PCs and game consoles
• Graphics Processing Units
– Processors oriented to 3D graphics tasks
– Vertex/pixel processing, shading, texture mapping,
ray tracing
Graphics in the System
Graphics Processing Units
• Given the hardware invested to do graphics
well, how can we supplement it to improve
performance of a wider range of applications?
• Basic idea:
– Heterogeneous execution model
• CPU is the host, GPU is the device
– Develop a C-like programming language for GPU
– Unify all forms of GPU parallelism as CUDA thread
– Programming model: “Single Instruction Multiple
Thread”
Programming the GPU
• Compute Unified Device Architecture-CUDA
– Elegant solution to problem of expressing
parallelism
• Not all algorithms, but enough to matter
• Challenge: Coordinating HOST and CPU
– Scheduling of computation
– Data transfer
• GPU offers every type of parallelism that can
be captured by the programming
environment
Programming Model
• CUDA’s design goals
– extend a standard sequential programming language,
specifically C/C++,
• focus on the important issues of parallelism—how to craft efficient
parallel algorithms—rather than grappling with the mechanics of
an unfamiliar and complicated language.
– minimalist set of abstractions for expressing parallelism
• highly scalable parallel code that can run across tens of
thousands of concurrent threads and hundreds of processor
cores.
GTX570 GPU
Up to 1536
Threads/SM
Programming the GPU
• CUDA Programming Model
– Single Instruction Multiple Thread (SIMT)
• A thread is associated with each data
element
• Threads are organized into blocks
• Blocks are organized into a grid
• GPU hardware handles thread management,
not applications or OS
GPU Threads in SM (GTX570)
• 32 threads within a block work collectively
9 Memory access optimization, latency hiding
GPU Threads in SM (GTX570)
• Up to 1024 Threads/Block
and 8 Active Blocks per SM
Programming the GPU
Matrix Multiplication
Matrix Multiplication
• For a 4096x4096 matrix multiplication
- Matrix C will require calculation of 16,777,216 matrix
cells.
• On the GPU each cell is calculated by its own thread.
• We can have 23,040 active threads (GTX570), which
means we can have this many matrix cells calculated
in parallel.
• On a general purpose processor we can only calculate
one cell at a time.
• Each thread exploits the GPUs fine granularity by
computing one element of Matrix C.
• Sub-matrices are read into shared memory from global
memory to act as a buffer and take advantage of GPU
bandwidth.
Solving Systems of Equations
Thread Organization
•If we expand to 4096 equations, we can process each row
completely in parallel with 4096 threads
•We will require 4096 kernel launches. One for each
equation
Results
CPU Configuration: Intel Xeon @2.33GHz with 2GB
RAM
*For single precision, speedup improves by at least a
GPU
Configuration: NVIDIA Tesla C1060 @1.3GHz
factor of 2X
Execution time includes data transfer from host to device
Programming the GPU
• Distinguishing execution place of functions:
_device_ or _global_ => GPU Device
Variables declared are allocated to the GPU memory
_host_ => System processor (HOST)
• Function call
Name<<dimGrid, dimBlock>>(..parameter list..)
blockIdx: block identifier
threadIdx: threads per block identifier
blockDim: threads per block
Programming the GPU
//Invoke DAXPY
daxpy(n,2.0,x,y);
//DAXPY in C
void daxpy(int n, double a,
double* x, double* y)
{
for (int i=0;i<n;i++)
y[i]= a*x[i]+ y[i]
}
Programming the GPU
//Invoke DAXPY with 256 threads per Thread Block
_host_
int nblocks = (n+255)/256;
daxpy<<<nblocks, 256>>> (n,2.0,x,y);
//DAXPY in CUDA
_device_
void daxpy(int n,double a,double* x,double* y){
int i=blockIDx.x*blockDim.x+threadIdx.x;
if (i<n)
y[i]= a*x[i]+ y[i]
}
Programming the GPU
• CUDA
• Hardware handles thread management
• Invisible to the programmer (productivity),
• Performance programmers need to know the
operation principles of the threads!
• Productivity vs. performance
• How much power to be given to the
programmer, CUDA is still evolving!
Efficiency Considerations
• Avoid execution divergence
– threads within a warp follow different execution paths.
– Divergence between warps is ok
• Allow loading a block of data into SM
– process it there, and then write the final result back out to
external memory.
• Coalesce memory accesses
– Access executive words instead of gather-scatter
• Create enough parallel work
– 5K to 10K threads
Efficiency Considerations
• GPU Architecture
– Each SM executes multiple warps in a time-sharing
fashion while one or more are waiting for memory values
• Hiding the execution cost of warps that are executed concurrently.
– How many memory requests can be serviced and how
many warps can be executed together while one warp is
waiting for memory values.
OpenMP vs CUDA
#pragma omp parallel for shared(A) private(i,j)
for (i = 0; i < 32; i++){
for (j = 0; j < 32; j++)
value=some_function(A[i][j]}
GPU Architectures
• Processing is highly data-parallel
– GPUs are highly multithreaded
– Use thread switching to hide memory latency
• Less reliance on multi-level caches
– Graphics memory is wide and high-bandwidth
• Trend toward general purpose GPUs
– Heterogeneous CPU/GPU systems
– CPU for sequential code, GPU for parallel code
• Programming languages/APIs
– DirectX, OpenGL
– C for Graphics (Cg), High Level Shader Language
(HLSL)
– Compute Unified Device Architecture (CUDA)
Easy to Learn
Takes time to master
Example Systems
2 × quad-core
Intel Xeon e5345
(Clovertown)
2 × quad-core
AMD Opteron X4 2356
(Barcelona)
Example Systems
2 × oct-core
Sun UltraSPARC
T2 5140 (Niagara 2)
2 × oct-core
IBM Cell QS20
IBM Cell Broadband Engine
128 , 128-bit registers
128-bit vector/cycle
Abbreviations
PPE: PowerPC Engine
SPE: Synergistic
Processing Element
MFC: Memory Flow
Controller
32KB,
I, D
512KB
U
LS:
Local Store
SIMD: Single Instruction
Multiple Data
300-600
cycles
CELL BE Programming Model
No direct access to DRAM from LS of SPE,
Buffer size: 16KB
• CASE STUDIES
White Spaces After Digital TV
• In telecommunications, white spaces refer to vacant
frequency bands between licensed broadcast
channels or services like wireless microphones.
• After the transition to digital TV in the U.S. in June
2009, the amount of white space exceeded the
amount of occupied spectrum even in major cities.
• Utilization of white spaces for digital communications
requires propagation loss models to detect occupied
frequencies in near real-time for operation without
causing harmful interference to a DTV signal, or other
wireless systems operating on a previously vacant
channel.
Challenge
• Irregular Terrain Model (ITM), also known as the
Longley-Rice model, is used to make predictions
of radio field strength based on the elevation
profile of terrains between the transmitter and the
receiver.
– Due to constant changes in terrain topography and variations in radio propagation,
there is a pressing need for computational resources capable of running hundreds
of thousands of transmission loss calculations per second.
ITM
• Given the path length (d) for a radio
transmitter T, a circle is drawn around T
with radius d.
• Along the contour line, 64 hypothetical
receivers (Ri) are placed with equal
distance from each other.
• Vector lines from T to each Ri are further
partitioned into 0.5 km sectors (Sj ).
• Atmospheric and geographic conditions
along each sector form the profile of that
terrain (used 256K profiles).
• For each profile, ITM involves independent
computations based on atmospheric and
geographic conditions followed by
transmission loss calculations.
GPU Strategies for ITM
• ITM requires 45 registers
• Each profile is 1KB ( radio frequency, path length, antenna heights, surface transfer
impedance, plus 157 elevation points)
reduces register count to 37
1.5 GB per
GPU
8 KB /
multiprocessor
8 KB /
multiprocessor
16
KB
How many threads / MP?
GPU Strategies for ITM
128*16 threads
16*16 threads
192*16 threads
GPU Strategies for ITM
GPU Strategies for ITM
GPU Strategies for ITM
IBM CELL BE
• Workload: 256k profiles.
• Strategies:
– Message Queue (MQ),
– DMA and double buffering with various buffer sizes (DDB-n),
– SIMD with buffer size of 16KB (DDB-16+SIMD-)
• FG: fine grained; CG: coarse grained.
– Profile level SIMDization (CG) improves performance by 7.5x over MQ
Productivity
Comparison
•
•
Productivity from code development perspective
Based on personal experience of a Ph.D. student
– with C/C++ knowledge and the serial version of the ITM code in hand,
– without prior background on the Cell BE and GPU programming environments.
•
Data logged for the “learning curve” and “design and debugging” times individually.
Instruction and Data Streams
• An alternate classification
Data Streams
Single
Instruction Single
Streams
Multiple
Multiple
SISD:
Intel Pentium 4
SIMD: SSE
instructions of x86
MISD:
No examples today
MIMD:
Intel Xeon e5345
• SPMD: Single Program Multiple Data
– A parallel program on a MIMD computer
SIMD
• Operate elementwise on vectors of data
– E.g., MMX and SSE instructions in x86
• Multiple data elements in 128-bit wide registers
• All processors execute the same
instruction at the same time
– Each with different data address, etc.
• Simplifies synchronization
• Reduced instruction control hardware
• Works best for highly data-parallel
applications
Vector Processors
• Highly pipelined function units
• Stream data from/to vector registers to units
– Data collected from memory into registers
– Results stored from registers to memory
• Example: Vector extension
– 32 × 64-element registers (64-bit elements)
– Vector instructions
• lv, sv: load/store vector
• addv.d: add vectors of double
• addvs.d: add scalar to each element of vector of double
• Significantly reduces instruction-fetch
bandwidth
Vector Processors
Example: (Y = a × X + Y)
• Conventional MIPS code
l.d
$f0,a($sp)
addiu r4,$s0,#512
load
loop: l.d
$f2,0($s0)
mul.d $f2,$f2,$f0
l.d
$f4,0($s1)
add.d $f4,$f4,$f2
s.d
$f4,0($s1)
addiu $s0,$s0,#8
addiu $s1,$s1,#8
subu $t0,r4,$s0
bne
$t0,$zero,loop
• Vector MIPS code
l.d
$f0,a($sp)
lv
$v1,0($s0)
mulvs.d $v2,$v1,$f0
lv
$v3,0($s1)
addv.d $v4,$v2,$v3
sv
$v4,0($s1)
;load scalar a
;upper bound of what to
;load x(i)
;a × x(i)
;load y(i)
;a × x(i) + y(i)
;store into y(i)
;increment index to x
;increment index to y
;compute bound
;check if done
;load scalar a
;load vector x
;vector-scalar multiply
;load vector y
;add y to product
;store the result
Matrix Multiplication
• CPU Configuration: Intel Xeon @2.33GHz with 2GB RAM
• GPU Configuration: NVIDIA Tesla C1060 @1.3GHz
• +For multiplication, matrix size larger than 4096x4096
stresses host device’s RAM
• *For single precision, speedup improves by at least a
GPU
GPU
factor of 2X
Matrix Size
256x256
512x512
1024x1024
2048x2048
4096x4096
+
CPU Time
(sec)
0.159
1.518
25.773
547.882
4556.700
Speedu
Time
p*
(sec)
71
0.002
169
0.009
682
0.037
2623
0.208
3345
1.362