Migrating from Cortex-M3 to Cortex-M4
advertisement

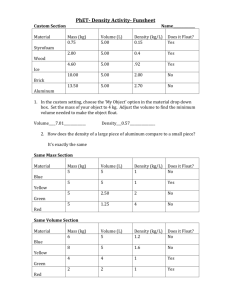
Migrating from Cortex-M3 to Cortex-M4 Roy Luo Global Technology Centre element14 (Formerly Premier Farnell) March 2011 1 Introduction The ARM Cortex-M4 processor is the latest embedded processor by ARM specifically developed to address digital signal control markets that demand an efficient, easy-to-use blend of control and signal processing capabilities in microcontroller applications. The combination of high-efficiency signal processing functionality with the low-power, low cost and ease-of-use benefits of the Cortex-M family of processors is designed to satisfy the emerging category of flexible solutions specifically targeting the motor control, automotive, power management, embedded audio and industrial automation markets. The Cortex-M4 processor extends the use of Cortex-M cores to applications that require more computational performance than available currently with Cortex-M3. The Cortex-M4 features a single-cycle multiply-accumulate (MAC) unit, optimized single instruction multiple data (SIMD) instructions, saturating arithmetic instructions and an optional single precision Floating-Point Unit (FPU). So, the Cortex-M4 is a Cortex-M3 with the DSP instruction add-ons, and migrating from Cortex-M3 to Cortex-M4 is very easy! 1.1 Why change to Cortex-M4? • Higher Performance Just like the Cortex-M3, the Cortex-M4 provides an integer performance level of 1.25 Dhrystone 2.1 MIPS per MHz, but Cortex-M4 provides higher performance on digital signal processing. Please refer to 2. Cortex-M4 Features for more information on Cortex-M4. • Digital Signal Processing Capabilities The Cortex-M4 integrates a single-cycle multiply-accumulate (MAC) unit supporting a variety of 16- and 32-bit multiplies with 32- and 64-bit accumulations and an instruction set of single-cycle SIMD (Single Instruction Multiple Data) featuring dual 16-bit and quad 8-bit operations. The Cortex-M4 FPU is an implementation of the single precision variant of the ARMv7-M Floating-Point Extension (FPv4-SP). It provides floating-point computation functionality that is compliant with the ANSI/IEEE STD 754-2008, IEEE Standard for Binary Floating-Point Arithmetic, referred to as the IEEE 754 standard. The FPU Page 1 Total: 17 Pages supports all single-precision data-processing instructions and data types described in the ARM Architecture Reference Manual. • Satisfying the Requirements of Next-Generation Products The ARM Cortex-M family is aimed at the areas such as commercial electronics and low-cost industrial control including motor control, power management, automotive electronics, and audio processing. The increasing computational loads in these areas consume an unacceptable portion of the CPU resources if all the digital signal processing tasks are handled by software. The ARM Cortex-M4 solves this issue by integrating a single-cycle multiply-accumulate (MAC) unit and an instruction set of single-cycle SIMD operations, as well as an optional FPU to satisfy the digital signal processing requirements of next-generation products. A Cortex-M4 can be regarded as a Cortex-M3 with integrated DSP extensions, which means the software from the Cortex-M3 can also function in the M4 and it is easy to implement migration from M3 to M4 without too much effort. The figures shown below illustrate the relation between these two processors. Cortex-M3 + DSP & Optional FPU = Cortex-M4 1.2 References Materials Cortex-M3 Technical Reference Manual, ARM DDI0337G, ARM Ltd. Cortex-M4 Technical Reference Manual, ARM DDI0337G, ARM Ltd. ARMv7-M Architecture Reference Manual, ARM DDI0403D, ARM Ltd. Cortex Microcontroller Software Interface Standard (see www.onarm.com). Application Note 179 – Cortex-M3 Embedded Software Development, ARM DAI0179B, ARM Ltd. Page 2 Total: 17 Pages 2 Cortex-M4 Features 2.1 32-bit Multiply-Accumulate (MAC) Unit The 32-bit hardware multiply-accumulate (MAC) unit added in the Cortex-M4 is capable of accomplishing an operation of up to 32×32+64->64 or two operations of 16×16 in a signal cycle. This high-performance unit makes digital signal processing more efficient and greatly reduces the consumption of CPU resources. The 32-bit multiply-accumulate (MAC) unit has three main features: • Wide range of multiply-accumulate instructions • Choice of 16 or 32 bit multiply and 32 or 64 bit accumulate • All instructions execute in a single cycle 2.2 Single Instruction Multiple Data (SIMD) Instructions The Cortex-M4 is integrated with a set of single-cycle SIMD instructions. The SIMD instruction set includes a series of DSP instructions such as add, subtract, multiply, multiply and accumulate, which is used to realize the implementation of the common DSP operations including FIR, IIR, complex FFT, PID, matrix addition, matrix subtraction, and matrix multiplication. With these instructions, a Cortex-M4 can offer a higher computational efficiency when running DSP programs than a Cortex-M3. The SIMD has three main features: • Quad (4 parallel) 8-bit adds or subtracts • Dual (2 parallel) 16-bit adds or subtracts • All instructions execute in a single cycle 2.3 Floating Point Unit (FPU) The FPU is an optional unit of the Cortex-M4. Manufacturers can make their own decisions on the availability of this unit according to their different requirements. The FPU fully supports single-precision add, subtract, multiply, divide, multiply and accumulate, and square root operations. It also provides conversions between fixed-point and floating-point data formats, and floating-point constant instructions. The FPU has four main features: • FP extension registers that software can view as either 32 single-precision or 16 doubleword registers • Single-precision floating-point arithmetic • Conversions among integer, single-precision floating-point, and half-precision (16-bit) Page 3 Total: 17 Pages floating point formats • Data transfers of single-precision and doubleword registers The rest of features such as NVIC (Nested Vectored Interrupt Controller), MPU (Memory Protection Unit), and DAP (Debug Access Port) are the same as the Cortex-M3. Please refer to the datasheet of the Cortex-M3 for detailed information. Page 4 Total: 17 Pages 3 Comparisons between Cortex-M3 and Cortex-M4 The table shown below lists the differences between the Cortex-M3 and M4. Cortex-M3 Cortex-M4 Architecture ARMv7-M (Harvard) ARMv7-M (Harvard) ISA Support Thumb/Thumb-2 Thumb/Thumb-2 Single cycle 16,32-bit MAC Single cycle dual 16-bit MAC DSP Extensions NA Optional Floating Point Unit NA Single precision floating point unit IEEE 754 compliant Pipeline 3-stage + branch speculation 3-stage + branch speculation Dhrystone 1.25 DMIPS/MHz 1.25 DMIPS/MHz Memory Protection Optional 8 region MPU with sub regions and background region Optional 8 region MPU with sub regions and background region Interrupts Non-maskable Interrupt (NMI) + 1 to 240 physical interrupts Non-maskable Interrupt (NMI) + 1 to 240 physical interrupts Interrupt Latency 12 cycles 12 cycles Inter-Interrupt Latency 6 cycles 6 cycles Interrupt Priority Levels 8 to 256 priority levels 8 to 256 priority levels Wake-up Interrupt Controller Up to 240 Wake-up Interrupts Up to 240 Wake-up Interrupts Sleep Modes Integrated WFI and WFE Instructions and Sleep On Exit capability. Sleep & Deep Sleep Signals Optional Retention Mode with ARM Power Management Kit Integrated WFI and WFE Instructions and Sleep On Exit capability. Sleep & Deep Sleep Signals Optional Retention Mode with ARM Power Management Kit Bit Manipulation Integrated Instructions & Bit Banding Integrated Instructions & Bit Banding Debug Optional JTAG & Serial-Wire Debug Ports. Up to 8 Breakpoints and 4 Watchpoints. Optional JTAG & Serial-Wire Debug Ports. Up to 8 Breakpoints and 4 Watchpoints. Trace Optional Instruction Trace (ETM), Data Trace (DWT), and Instrumentation Trace (ITM) Optional Instruction Trace (ETM), Data Trace (DWT), and Instrumentation Trace (ITM) 8,16-bit SIMD arithmetic Hardware Divide (2-12 Cycles) This table shows that most features of the Cortex-M3 and M4 are the same with the significant difference that Cortex-M4 has DSP extensions and an optional FPU. There is nearly no need for modification of hardware and software to migrate from M3 to M4. The next sections introduce the Cortex-M4 core in detail with emphasis on its digital signal processing capability. Page 5 Total: 17 Pages 3.1 Programmers Model 3.1.1 Operating Modes Same as the Cortex-M3, Cortex-M4 supports two modes of operation: Thread mode and Handler mode. The processor enters Thread mode on reset, or as a result of an exception return. Privileged and Unprivileged code can run in Thread mode. The processor enters Handler mode as a result of an exception. All code is privileged in Handler mode. 3.1.2 Operating States Same as the Cortex-M3, Cortex-M4 can operate in one of two operating states: Thumb and Debug State. Thumb state is the normal execution running 16-bit and 32-bit half word aligned Thumb instructions. Debug State is the state when the processor is in halting debug. 3.1.3 Instruction Set The Cortex-M4 uses the same architecture as the Cortex-M3, i.e., the ARMv7-M architecture. The instructions of these processors are from the Thumb-2 instruction set which includes 16-bit and 32-bit instructions. Additionally, the Cortex-M4 has integrated SIMD and the optional floating point instructions, which increase the total number of instructions up to 291, more than the 186 instructions of the Cortex-M3. The figure shown above illustrates the relationship between the instructions of the Cortex-M family. The Cortex-M3 ISA is upwards compatible with the Cortex-M4 ISA, and the Cortex-M4F (a Cortex-M4 processor plus FPU) is built by adding FPU instructions to the baseline Cortex-M4. Page 6 Total: 17 Pages 3.1.4 System Address Map Cortex-M3 and Cortex-M4 have the same system address map. The following figure shows the system address map: 3.1.5 Bit Banding Same as the Cortex-M3, the Cortex-M4 provides bit access to two 1MB regions of memory, one within the internal SRAM region and the other in the peripheral region. A further 32MB of address space is reserved for this purpose and each word within these regions aliases to a specific bit within the corresponding bit-band region. Reading from the alias region returns a word containing the value of the corresponding bit; writing to bit 0 of a word in the alias region results in an atomic read-modify-write of the corresponding bit within the bit-band region. 3.1.6 Core Register Comparison Same as the Cortex-M3, the Cortex-M4 has 16 general purpose registers, R0-R15, all 32-bit. R0-R12 are generally available for essentially all instructions, R13 is used as the Stack Pointer, R14 as the Link Register (for subroutine and exception return) and R15 as the Program Counter. The following figure shows the core register comparison between Page 7 Total: 17 Pages Cortex-M3 and Cortex-M4: Cortex-M3 Core Registers Cortex-M4 Core Registers 3.2 MPU Same as the Cortex-M3, the MPU is an optional component for memory protection in Cortex-M4. The processor supports the standard ARMv7 Protected Memory System Architecture model. You can use the MPU to enforce privilege/access rules, and separate processes. The MPU provides full support for: • Protection regions • Overlapping protection regions, with ascending region priority: 7 = highest priority 0 = lowest priority • Access permissions • Exporting memory attributes to the system 3.3 DSP Capability The figures shown below illustrate relative performance comparisons between the Cortex-M3 and Cortex-M4 regarding the capability of digital signal processing where both processors are operating at the same speed. Page 8 Total: 17 Pages In the following figures, the y-axis represents the relative cycle counts to execute the given function. Accordingly, the smaller the cycle count, the better the performance. Since the Cortex-M3 is used as the reference, the Cortex-M4 performance is calculated by taking the reciprocal of its relative cycle count. As an example, for the PID function, the Cortex-M4 cycle count is approximately 0.7x versus the Cortex-M3, so the relative performance is 1/0.7, or 1.4x. Cortex-M 16-bit functions cycle count Cortex-M 32-bit functions cycle count It is clear that the Cortex-M4 presents a great advantage in terms of digital signal processing compared with the Cortex-M3 for both16-bit or 32-bit operations. All the DSP Page 9 Total: 17 Pages instructions executed by the Cortex-M4 complete in a single cycle while the Cortex-M3 needs multiple instructions and multiple cycles to complete the equivalent function. Even for the PID, the most resource-consuming job among these common DSP operations, the Cortex-M4 provides a 1.4x performance improvement. As another application example, an MP3 decode requiring 20-25 MHz on a Cortex-M3 would only require 10-12 MHz on a Cortex-M4. 3.3.1 32-bit Multiply-Accumulate (MAC) The 32-bit multiply-accumulate (MAC) includes new instructions and an optimized hardware execution unit in the Cortex-M4. It is capable of accomplishing a 32 x 32 + 64 -> 64 operation or two 16 x 16 operations in a single cycle. The table shown below lists the operations that this unit can carry out. Operation Instruction Cycles 16 x 16 = 32 SMULBB, SMULBT, SMULTB, SMULTT 1 16 x 16 + 32 = 32 SMLABB, SMLABT, SMLATB, SMLATT 1 16 x 16 + 64 = 64 SMLALBB, SMLALBT, SMLALTB, SMLALTT 1 16 x 32 = 32 SMULWB, SMULWT 1 (16 x 32) + 32 = 32 SMLAWB, SMLAWT 1 (16 x 16) ± (16 x 16) = 32 SMUAD, SMUADX, SMUSD, SMUSDX 1 (16 x 16) ± (16 x 16) + 32 = 32 SMLAD, SMLADX, SMLSD, SMLSDX 1 (16 x 16) ± (16 x 16) + 64 = 64 SMLALD, SMLALDX, SMLSLD, SMLSLDX 1 32 x 32 = 32 MUL 1 32 ± (32 x 32) = 32 MLA, MLS 1 32 x 32 = 64 SMULL, UMULL 1 (32 x 32) + 64 = 64 SMLAL, UMLAL 1 (32 x 32) + 32 + 32 = 64 UMAAL 1 2 ± (32 x 32) = 32 (upper) SMMLA, SMMLAR, SMMLS, SMMLSR 1 (32 x 32) = 32 (upper) SMMUL, SMMULR 1 3.3.2 SIMD The Cortex-M4 supports SIMD instructions, which were unavailable in the previous members of the Cortex-M family. Some of the instructions in the above table belong to SIMD instructions. By working with the optimized multiply-accumulate (MAC) hardware, all these instructions are executed in a single cycle. Powered by SIMD instructions, the Cortex-M4 processor is able to carry out an operation of up to 32 x 32 + 64 -> 64 in a single cycle, freeing up processor bandwidth for other tasks rather than being consumed by sequences of multiplications and additions. Page 10 Total: 17 Pages Consider the following complex arithmetic operation where two 16 x 16 multiplies plus a 32-bit accumulation are encoded and performed by a single instruction: Sum = Sum + (A x C) + (B x D) 32-bit 32-bit 3.3.3 FPU FPU is an optional unit of the Cortex-M4 for floating point operations. Therefore it is a unit dedicated to floating-point tasks. This unit boosts performance by using hardware to handle single precision floating point operations and is compliant with IEEE 754. It is an implementation of the single precision variant of the ARMv7-M Floating-Point Extension (FPv4-SP). The FPU extends the register programming model with a register file containing 32 single-precision registers. These can be viewed as: • Sixteen 64-bit doubleword registers, D0-D15 • Thirty-two 32-bit single-word registers, S0-S31 The FPU provides three modes of operation to accommodate a variety of applications: • Full-Compliance Mode In full-compliance mode, the FPU processes all operations according to the IEEE 754 standard in hardware. • Flush-to-Zero Mode Setting the FZ bit of the Floating -point Status and Control Register, FPSCR [24], enables flush-to-zero mode. In this mode, the FPU treats all subnormal input operands of arithmetic CDP operations as zeros in the operation. Exceptions that result from a zero operand are signaled appropriately. VABS, VNEG, and VMOV are not considered arithmetic CDP operations and are not affected by flush-to-zero mode. A result that is tiny, as described in the IEEE 754 standard, where the destination precision is smaller in magnitude than the minimum normal value before rounding, is replaced with a zero. The IDC flag, FPSCR [7], indicates when an input flush occurs. The UFC flag, FPSCR [3], indicates when a result flush occurs. • Default NaN Mode Page 11 Total: 17 Pages Setting the DN bit, FPSCR [25], enables default NaN mode. In this mode, the result of any arithmetic data processing operation that involves an input NaN, or that generates a NaN result, returns the default NaN. Propagation of the fraction bits is maintained only by VABS, VNEG, and VMOV operations. All other CDP operations ignore any information in the fraction bits of an input NaN. The following table shows instruction set of the FPU. Operation Description Assembler Cycles Absolute value of float VABS.F32 1 Addition floating point VADD.F32 1 float with register or zero VCMP.F32 1 float with register or zero VCMPE.F32 1 Convert between integer, fixed-point, half-precision and float VCVT.F32 1 Divide Floating-point VDIV.F32 14 multiple doubles VLDM.64 multiple floats VLDM.32 number of floats. single double VLDR.64 3 single float VLDR.32 2 top/bottom half of double to/from core register VMOV 1 immediate/float to float-register VMOV 1 float to/from one core register VMOV 2 floating-point control/status to core register VMRS 1 core register to floating-point control/status VMSR 1 float VMUL.F32 1 then accumulate float VMLA.F32 3 then subtract float VMLS.F32 3 then accumulate then negate float VNMLA.F32 3 then subtract then negate float VNMLS.F32 3 then accumulate float VFMA.F32 3 Compare 1+2*N, where N is the number of doubles 1+N, where N is the Load two floats/one double to/from two core registers or one Move Multiply Multiply Page 12 Total: 17 Pages (fused) then subtract float VFMS.F32 3 then accumulate then negate float VFNMA.F32 3 then subtract then negate float VFNMS.F32 3 float VNEG.F32 1 and multiply float VNMUL.F32 1 double registers from stack VPOP.64 float registers from stack VPOP.32 double registers to stack VPUSH.64 float registers to stack VPUSH.32 of float VSQRT.F32 multiple double registers VSTM.64 multiple float registers VSTM.32 number of floats. single double register VSTR.64 3 single float registers VSTR.32 2 float VSUB.F32 1 Negate 1+2*N, where N is the Pop number of double registers. 1+N where N is the number of registers. 1+2*N, where N is the Push Square-root number of double registers. 1+N, where N is the number of registers. 14 1+2*N, where N is the number of doubles. 1+N, where N is the Store Subtract 3.4 Debug Same as the Cortex-M3, Cortex-M4 devices are debugged via a standard JTAG or Serial-Wire Debug (SWD) connector. A simple, standardized external connector is required to interface to a host system. 3.5 Power 3.5.1 Power Management Same as Cortex-M3, Cortex-M4 has four power modes: Active mode, Sleep mode, Standby mode, Power off mode. The following figure shows the four power modes: Page 13 Total: 17 Pages Power Modes Power Consumption Description Active mode Leakage + dynamic Running Dhrystone 2.1 benchmark Sleep mode Leakage + some dynamic CM4Core clock gated, NVIC awake Standby mode Leakage only Power still on, all clocks off Power off mode Zero power Power off 3.5.2 Comparison Based on Power It is obvious from the table shown below that the Cortex-M4 performs much better than the Cortex-M3 in terms of power efficiency. Process Cortex-M3 Cortex-M4 TSMC 90nm G 65nm low power process Optimization Type Speed Optimized Area Optimized Speed Optimized Area Optimized Standard Cell Library ARM SC9 ARM SC9 ARM SC12 ARM SC9 Integer Performance (Total DMIPS) 344 63 375 188 Frequency (MHz) 275 50 300 150 Page 14 Total: 17 Pages Power Efficiency (DMIPS/mW) TBD 12.5 24 38 Area (mm2) 0.083 0.047 0.21 0.11 FPU Area (mm2) NA NA 0.08 0.06 4 Migrating a Software Application 4.1 General Information Since the Cortex-M4 represents a superset ISA extension from the Cortex-M3, the software including system level software can be used on both platforms. Specifically, the stack, memory, code and data placement, as well as interrupts in both processors are all the same because they have the same ARM v7-M hardware and Thumb/Thumb-2 instruction set. A software migration from the Cortex-M3 to the M4 can be done very easily with few modifications. If the code is developed with C language, there is no need for any modifications. Compilers targeted for Cortex-M4 automatically invokes the 32-bit multiply-accumulate (MAC) unit and SIMD instructions to execute DSP tasks. However, there are still some considerations despite the fully compatible code. • Use word transfers only to access registers in the NVIC and System Control Space (SCS). • Treat all unused SCS registers and register fields on the processor as Do-Not-Modify. • Configure the following fields in the CCR: STKALIGN bit to 1 UNALIGN_TRP bit to 1 Leave all other bits in the CCR register as their original value. 4.2 Example Code The example shown below is a single high-level arithmetic source code statement used to implement IIR filter algorithm and the cycle counts that the Cortex-M3 and M4 consume. :y[n] = b0 * x[n] + b1 * x[n-1] + b2 * x[n-2] - a1 * y[n-1] - a2 * y[n-2] Function Cortex-M3 Cortex-M4 xN = *x++; 2 2 yN = xN * b0; 3-7 1 Page 15 Total: 17 Pages yN += xNm1 * b1; 3-7 1 yN += xNm2 * b2; 3-7 1 yN -= yNm1 * a1; 3-7 1 yN -= yNm2 * a2; 3-7 1 *y++ = yN; 2 2 xNm2 = xNm1; 1 1 xNm1 = xN; 1 1 yNm2 = yNm1; 1 1 yNm1 = yN; 1 1 Decrement loop counter 1 1 Branch 2 2 26~46 Cycles 16 Cycles To execute the same source code, the Cortex-M3 needs 26~46 cycles (note the execution time for the multiply operations is data dependent) while the Cortex-M4 only needs 16 cycles. The Cortex-M4 provides a 1.6x - 2.9x performance improvement for this IIR filter calculation. By looking into the details, the difference is found at the code lines that perform the successive multiply-accumulate operations. To execute these functions, the Cortex-M3 requires multiple instructions and consumes 3-7 cycles, while the Cortex-M4 only requires a single 1-cycle instruction. This is a real-world signal processing example showing the ISA capabilities and microarchitecture strength of the Cortex-M4 core. 5 Cortex-M4 Products It is currently known that the manufacturers including Freescale, NXP and STMicroelectronics will offer MCUs based on Cortex-M4 core. Among these suppliers, Freescale has already launched its Kinetis Cortex-M4 product line that includes the K10, K20, K30, K40 and K60 families in 2010. Designers can easily evaluate and develop Cortex-M4 products by using TWR-K40X256-KIT and TWR-K60N512-KIT Tower kit from Freescale or its distributors. 6 Summary The Cortex-M4 boasts powerful capabilities to deal with the digital signal processing tasks that were unavailable in the previous members of the Cortex-M family. Benefiting from the same hardware platform and compatible instruction set, designers can carry out migration from the Cortex-M3 to the M4 with little effort, preserving their existing software developments. The easy job of migration not only reduces the workload of developing new products, but also enables the new products to handle digital signal processing more Page 16 Total: 17 Pages efficiently with lower power consumption, making the Cortex-M4 an ideal choice for the next-generation products. Page 17 Total: 17 Pages