Nonlinear Models in R

Nonlinear Models by nls() in R (Logistic Growth Example)
Prepared by Allison Horst for ESM 244
Bren School of Environmental Science & Management, UCSB
We’ve used R to help us find all of kind of parameters (coefficients, intercepts, etc.) to help describe linear relationships between variables. In the real world, not all relationships are linear, and we don’t always want to try to describe them linearly (after transforming data, or whatever). Sometimes we’ll want to mathematically describe a relationship between two variables using nonlinear models.
Here, we’ll learn to find parameters for nonlinear models using the nls() function in R for one type of nonlinear relationships: logistic growth. You can use the same approach to estimate parameters for any number of nonlinear relationships (exponential growth/decay, cyclical trends with sine/cosine models, etc.) – the approach is generally the same.
Estimating Nonlinear Model Parameters for Logistic Growth
** You can download the dataset ‘GremlinsData’ to follow along with this example. On the website it’s as an
Excel file – open it, save it as a .csv file, then load it into RStudio
**You will need the following packages installed and loaded to follow along:
We’ll be exploring an increase in gremlin population immediately after a rainstorm (water causes them to multiply – see more at http://en.wikipedia.org/wiki/Gremlins ).
Step 1. Explore your data
The first step in trying to fit any model is exploring the data that you have. Often, the best way to do that is with a simple plot. Here’s what the GremlinData looks like (created in ggplot):
30
20
10
0
0 5 10 15
Time (hours)
Depending on the type of data you have, you may need to do some further exploration (but we’ll stick to simple nonlinear models for now).
Step 2. Decide which type of nonlinear relationship exists
This is the most important step in the analysis. Do not just want to pick or create a model that best fits the observations (i.e., the one that results in the highest R 2 value). Model selection should be based on your conceptual understanding of the actual processes and mechanisms leading to the observed trend between the independent- and dependent-variable.
For the Gremlin example, this looks pretty clearly like logistic growth (and we’ll continue with that), but always make sure that the mathematical model you pick to describe your data is based on your conceptual understanding of the relationship between the two variables, not the “best fit” equation.
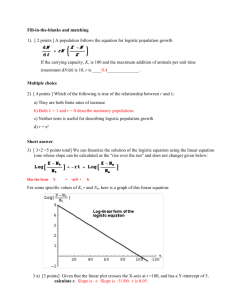
So, for the Gremlin example, we’ll use a logistic growth model to describe the change in number of gremlins over time after a rainstorm. The logistic growth equation is given below: where K is the ‘carrying capacity’ of the population – the asymptotic horizontal line that indicates the upper limit of a sustainable population size. N
0 is the initial population size, and r is the growth rate during the exponential phase of logistic growth. Often, the equation is rewritten as: by replacing K with A , and B for the ( K – N
0
)/ N
0
term in the denominator.
Step 3. Get a “Rough Estimate” of the Model Parameters
The first thing that we’ll do is estimate our model parameters (to whatever extent possible). We want to do this because the nonlinear least squares function, nls() , uses an iterative approach to estimating the model parameters (here, A , B and r ) that will start with the initial estimate you give it. If you start with parameters that are WAY off from the actual values, that iterative process may never converge.
So how do we do that for logistic regression? K (or A ) and N
0
are easy to estimate just by eyeballing the graph
(and a simple calculation gets you B ):
*#$%&'()$#
30
20
10
!
"
#$%&'()$#
0
0 5
Time (hours)
10 15
Based on the graph, I’ll estimate that the starting value N
0
~ 0, the carrying capacity K (or A ) ~ 29, so B ~ 28.
What about the growth rate constant, r ? We can estimate that from the data, too. Recall that if you take the natural log of exponentially growing data ( y ), and plot that against the time ( t ), the relationship for ln( y ) versus t should be approximately linear (so long as it really is exponential growth). The slope of that relationship between ln( y ) and t is the growth rate constant, r .
Mathematically, that’s because: y = Ae rt ln( y ) = ln( Ae rt ) ln( y ) = ln( A ) + ln( e rt
) ln( y ) = ln( A ) + rt ln( y ) = rt + ln( A )
Notice that the last equation is in the same form as y = m x + b (a linear relationship) between ln( y ) and t .
So, we can estimate r by finding the slope of the relationship between ln(Gremlins) and time during the early exponential phase of growth . Looking at the graph, I’ll estimate that exponential growth is really occurring from about time 0 h to 7 h. A plot of those first 7 points using the following code yields this scatterplot:
The relatively linear trend confirms that, yes, within that range the growth was close to exponential. To find an estimate for r , we just have to find the slope of that linear relationship:
The slope returned by that linear model gives us an estimate for r ~ 0.501.
Step 4. Use the nls() function to find the model parameters
We have our parameter estimates, but they’re rough – we want R to help us find much better estimates for A , B , and r using the nls() function.
To use the function, you need to tell R several things: (1) the actual model equation you’re going to use, written in terms of the x and y variable names for the dataset you loaded (here, ‘Time’ and ‘Gremlins’), (2) the initial estimates for the parameters (that goes in the start = ‘’ argument), (3) the dataset name where the observations are from that the nls() function will try to optimize for (data = ), and (4) optional – an argument that will return the iterations that led to the final model parameter prediction (trace = TRUE).
For this example, the code would look something like this:
Which, when called, returns the pretty self-explanatory outcome of:
To get more information (standard errors, p -values) for the parameters, use the summary(ModelName) function. You can also find the confidence intervals for each parameter using the confint(ModelName) function.
Step 5. Visualize and communicate the nonlinear model results
It can be helpful to visualize values predicted by the nonlinear model parameters to see how well they fit the observed data. Here, we’ll create a graph showing both the observations (as scatterplot points) and the predictions (as a line), then create a table with the model results.
First, store the parameters from the model output as new variables. Here’s an easy way:
Now, create a series of times over which you’ll calculate the predicted number of gremlins at any time based on your model:
Make predictions for all of those times using the logistic growth model:
Then bind the time sequence and predicted data into a single data frame:
And finally, make a great graph with both the original observations and the new predicted data from the nonlinear model you created:
The above code makes this graph (note the example figure caption):
Gremlin Population Growth Following a Rainstorm
30
20
10
0
0 5 10
Time (h)
15 20
Figure X. Gremlin population over time (h) following a rainstorm. Original observations for population are indicated by dark blue points. The light line indicates predicted population values for logistic growth with parameters fitted by nonlinear least squares. For the logistic growth model y = A /(1 + B e = r t , parameters were estimated as: A = 29.7 ( SE = 0.60, p < 0.001); B = 44.7 ( SE =
12.9, p = 0.004); and r = 0.63 ( SE = 0.05, p < 0.001).
We could also present the results of our logistic regression model in a table (here, I have also found the confidence intervals of each parameter using confint(GremlinNLM) :
Table X. Parameters for logistic growth model describing the increase in gremlin population over time following a rainstorm.
Estimates were determined iteratively by nonlinear least squares.
Gremlin Population Logistic Growth Model
Parameter Estimate
Gremlins =
A
1 + Be !
r * Time
SE 95% CI p-value
A 29.67
0.60
[28.42, 31.04] < 0.001
B 44.65
12.96
[25.74, 89.22] 0.004
r 0.63
0.05
[0.53, 0.74] < 0.001