chapter2 - Web4students
advertisement

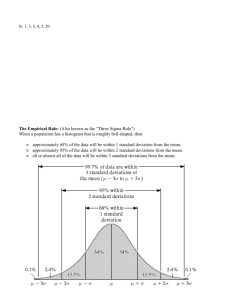
2.1 – Overview (Read the book, examples, jot down comments, do the problems suggested in the homework. Bring your questions to class or my office.) In this chapter we present a variety of basic tools that will help us in understanding a collected data. We will describe, explore and compare data sets. Two General Divisions of Statistics Descriptive: to summarize or describe characteristics of a set of data pictorially, numerically, or by tabulation. Inferential: when we use sample data to make generalizations and/or predictions about a population. Examples of Descriptive Statistics 1) The average SAT score for a certain College is 513.5 2) The final exam grades for my statistics class in the Fall 2003 ranged from 23% to 99% Examples of Statistical Inference We might infer from appropriate samples that: 1) Between 20% and 25% of American college students are married. 2) High cholesterol levels are associated with increased risk of heart disease The same number may be used for either describing a smaller distribution or making inferences about a larger distribution: 1) Nielsen reports that 24.7% of those who were interviewed watched the President’s news conference last Sunday night. 2) Probably about 24.7% of all television viewers watched the President’s news conference last Sunday night. 3) The average age of students enrolled in this class is 19.7 years 4) The average age of students enrolled at this college is probably 19.7 years Important Characteristics of Data (CVDOT) 1) Center: A representative or “average” value that indicates where the middle of the data set is located. 2) Variation: A measure of how spread out the data values are. 3) Distribution: The shape of the spread of the data. A distribution could be bell-shaped, uniform, skewed, etc. 4) Outliers: Sample values that lie very far away from the vast majority of the other sample values. (Possibly due to errors or unusual circumstances.) 5) Time: Changing characteristics of the data over time 1 2.2 – Frequency Distributions We’ll use the table from the next page to introduce the vocabulary. • Frequency distribution, classes, frequency • Advantage of a frequency distribution: makes a list more intelligible • Disadvantage of a frequency distribution: original data is lost • Lower and upper Class Limits • Class Boundaries upper limit of one class + lower limit of the next class 2 • Class Midpoints Within a class do: lower class limit + upper class limit 2 • Class Width If you are given a frequency distribution, the class width can be found by doing the difference between 2 consecutive lower class limits. If you are constructing a frequency distribution, use the following formula to find the class width: class.width l arg est.value smallest.value number.of .classes • Relative Frequency It is a percentage or fraction. class. frequency = usually as % sum.of . frequencies • Cumulative Frequency Sum of frequencies at and below a given class. Guidelines for Constructing a Frequency Distribution 1. Be sure that classes are mutually exclusive. 2. Include all in between classes, even if the frequency is zero. 3. Use the same width for all classes. Sometimes open-ended interval are impossible to avoid for first and/or last class. 4. Use between 5 and 20 classes. Usually 10 or fewer. 5. The sum of the class frequencies must equal the number of original data values. 2 2.3 – Visualizing Data Histograms • Horizontal axis: values of the data Use class boundaries for marks along the horizontal axis. • Vertical axis: frequencies. (the vertical height of the histogram should be about three-fourths of the total width) • The height of a bar represents the frequency of each class. • Both axes should be clearly labeled. • Note: We cannot reconstruct the original data set from a histogram and have sacrificed some accuracy for convenience in displaying the data. • Remember to Interpret the histogram referring to the characteristics of data CVDOT from section 2.1 Relative Frequency Histogram • Use the relative frequencies along the vertical axis • Shape should be the same as the regular histogram with the vertical axis labeled differently. Frequency Polygon Construction • Plot the points with coordinates (class midpoint, class frequency) • Connect points with line segments • Extend the first and the last segments to the left and right so that the graph begins and ends on the x-axis Ogive Construction • Plot the points with coordinates (upper class boundaries, cumulative frequency) • Connect points with line segments. • The graph begins on the x-axis with the lower boundary of the first class and ends with the upper boundary of the last class (must start at the 0% and end at 100%). • Ogives are useful for determining the number of values below some particular value. Dot Plots (see page 48, figure 2-5) • Each data value is plotted as a point (or dot) along a scale of values. • Numbers appear individually not in categories as it happens in a histogram. • Stack the values vertically when values occur more than once. • Similar to histograms because we can see the distribution of the data • We do not loose the particular values 3 Stem and Leaf Plots (see page 49) • Similar to histograms because we can see the distribution of the data • We do not lose the particular data values • STEM (consists of the leftmost digit(s)) • LEAF (consists of the rightmost digit) • Examine sidewise and see a histogram • The number of stems should be kept between 5 and 20 • If there are too many values, expand, subdividing rows into: digits from 0 to 4 and digits from 5 to 9 • If necessary, condense, that is reduce the number of rows • Since it displays the data in order, it is a fast and easy procedure for ranking data (arranging data in order) Pareto Charts (see page 51) • It is a bar graph for qualitative data • Bars are arranged in descending size • Vertical scale can represent frequencies or relative frequencies as in the histogram Pie Charts (see page 51) • Used to display qualitative data in a more understandable way so that we see what part of the total data is represented by each category. • Make a table with a column with relative frequencies (%), and a column for degrees (% of 360) Scatter Diagrams (see page 51) • Is a plot of paired (x,y) data with a horizontal x-axis, and a vertical y-axis. • The pattern of the plotted points is often helpful in determining the presence and form of some relationship between the two variables. ►►►We’ll do scatter diagrams with more detail later in chapter 9 Time-Series Graph (see figure 2-8, page 52) • Time-series data are data that have been collected at different points in time. Other Graphs Discuss the graphs on pages 53, and 54 4 2.4 – Measures of Center Measure of Center: Value representing some type of measure of the center or middle of a data set Mean (arithmetic mean) • The sum of the scores divided by the number of scores • The mean is affected by low or high values Notation: n: number of values in a data sample N: number of values in a data population x Sample mean Population mean x n x N Median • Middle value when data is arranged in ORDER • If n is odd, the median is located exactly in the middle • If n is even, it is the mean of two middle numbers • Median is not affected (is resistant) to large or small data values (is “robust”) Mode • The most frequent score or class • Sometimes a data set can be bimodal, multimodal, or have no mode Midrange • Value midway between highest and lowest data values . highest.value lowest.value 2 Round-off Rule • Carry one more decimal place than is present in the original set of data values • Round off only on the final answer. Keep several more decimal places during intermediate calculations. 5 Mean From a Frequency Distribution To find the mean of data summarized in a frequency distribution we’ll use the calculator instead of the formula: x ( f x) f , where f denotes the frequency and x represents the class midpoint. Weighted Mean Is the mean computed with the different scores assigned different weights. x ( w x) w The Best Measure of Central Tendency See table 2-10 on page 67. Skewness (see page 68) A non-symmetric distribution that extends more to one side than another Skewed to the left (negatively skewed, lopsided to the right) The histogram is much lower on the left side and the mean is left of the median which is left of the mode. Skewed to the right (positively skewed, lopsided to the left) The histogram is much lower on the right side and the mean is right of the median which is right of the mode. Symmetric (zero skewness, data not lopsided) The histogram is mirror image about the data center, and the mean = the median = the mode 6 2.5 Measures of Variation (Dispersion) Range Range = (Highest value) – (Lowest value) Only affected by 2 numbers (does not represent the whole data set) Standard Deviation Is a measure of the average variation of values about the mean Variance Is the square of the standard deviation. Notation s = Sample standard deviation s 2 = Sample variance = Population standard deviation 2 = Population variance Formulas to find the Standard Deviation Defining Formula Sample Population s ( x x) Shortcut formula 2 s n 1 (x ) n ( x 2 ) ( x ) 2 n(n 1) 2 N Grouped Data- Finding the Standard Deviation from a Frequency Distribution When dealing with grouped data we will use the calculator to find the standard deviation instead of using the formula given on page 80. 7 Comparing Variation in Different Populations The coefficient of variation (or CV) for a set of sample or population data, expressed as a percent, describes the standard deviation relative to the mean. • It is a measure of the importance of the data set’s variation. CV s 100% x CV 100% Interpreting and Understanding Standard Deviation • It measures the average variation among scores of a data set • A data set with many scores close together yields a small standard deviation • A data set with scores spread farther apart yields a larger standard deviation • It is a kind of yardstick by which we can compare one set of data with another • Range rule of thumb: range ~ 4 standard deviations (r = 4 s) s ~ range / 4 • Values that are within 2 standard deviations from the mean are considered “usual” values • Minimum “usual” value ~ mean – 2 standard deviations • Maximum “usual” value ~ mean + 2 standard deviations • Most of the data is within the interval: [(mean – 2 standard deviations) , (mean + 2 standard deviations)] • Values that are more than two standard deviations away from the mean are considered “unusual” values. 8 Empirical Rule (or 68-95-99.7 rule) If a Distribution is approximately bell shaped, then • About 68% of the scores fall within 1 standard deviation of the mean • About 95% of the scores fall within 2 standard deviations of the mean • About 99.7% of the scores fall within 3 standard deviations of the mean Chebyshev’s Theorem • It applies to any set of data, but its results are very approximate The Proportion of data lying within k standard deviations of the mean is at least 1 1 , where k is any positive integer greater than 1. k2 • At least 3/4 or 75% of all scores fall within 2 standard deviations of the mean 1 1 22 • At least 8/9 or 89% of all scores fall within 3 standard deviations of the mean 1 1 32 • At least ......... or .......... of all scores fall within 4 standard deviations of the mean • For typical data sets, it is unusual for a score to differ from the mean by more than 2 or 3 standard deviations 9 2.6 Measures of Relative Standing z-Scores (or Standard Score) • The z-score is the number of standard deviations that a given data value is above or below the mean. A score with a positive z-score is above the mean and a score with a negative z-score is below the mean. • Z-scores enable us to standardize values so that they can be compared x= x + z s then z x xx or z s Round z to 2 decimal places Note: We are using the standard deviation as a “yard stick”. • Z-scores can be used to differentiate between ordinary values and unusual values • Values with z-scores within [-2,2] are considered "ordinary" or "usual" • Values with z-scores greater than 2, or less than -2, are considered "unusual" FIGURE 2-14 10 Quartiles and Percentiles • Quartiles: Divide ranked data into 4 equal parts. (Q1, Q2, Q3) (Similar to median which divides into 2) • Percentiles: Divide ranked data into 100 parts. (P1, P2,...P99) A score in the 88th Percentile means: Student's score is higher than 88% of the scores Finding the percentile corresponding to a particular score Percentile = number.of .values.less.than.x • 100 total.number.of .values Reverse Process - Finding the score corresponding to a particular percentile What scores is at kth percentile? (1) Rank the data from lowest to highest (2) Find % of the total number = L (Locator) L nk 100 a) If L is not a whole number, round up and find the score in that position b) If L is a whole #, find the average of the scores in positions L and L+1 Interquartile Range A statistic that we will use in the next section is defined in terms of quartiles. It is the Interquartile Range, or IQR. It measures the spread of the middle 50% of the data. IQR= Q3 – Q1 11 2.7 Exploratory Data Analysis - EDA Exploratory Data Analysis is the process of using statistical tools (such as graphs, measures of center, and variation) to investigate data sets in order to understand their important characteristics. Outliers (extreme values) Outliers are values that are very far away from almost all of the other values. • An outlier can have a dramatic effect on the mean. • An outlier can have a dramatic effect on the standard deviation. • An outlier can have a dramatic effect on the scale of the histogram so that the true nature of the distribution is totally obscured. (See example page 102) Box Plots Graphs that reveal central tendency, the spread of the data, the distribution of the data, and the presence of outliers (extreme scores) • Do not show as much detailed information (as histograms or stem-and-leaf plots) • Very useful for comparing two or more data sets (use the same scale) • Used to identify the approximate shape of the distribution of a large data set. • For small data sets, boxplots can be unreliable in identifying distribution shape. (using stem and leaf plots or dot plots is more appropriate in this case) Steps for Constructing a Box Plot (1) ARRANGE data in Ascending Order (2) Find the 5-number summary Minimum value First quartile: Q1, which is the median of the observations which are to the left of the overall median Median: Q2 Third quartile: Q3, which is the median of the observations which are to the right of the overall median) Maximum value (3) Use these numbers to construct the box plot. 12 Math 116 – Chapter 2 Highlights Choosing an appropriate number to describe the data Measuring the center of a distribution The mean cannot resist the influence of extreme observations. It is not a resistant measure of the center The median is a resistant measure of the center (not affected by extreme observations). If the distribution is symmetric, the mean and median are the same. If the distribution is close to symmetric, the mean and median are very close in values. In a skewed distribution, the mean is farther out in the direction of skewness (long tail) than is the median Reports about incomes and other strongly skewed distributions usually give the median rather that the mean. Example 1: Distributions of incomes are usually skewed to the ............... Which measure of the center is more appropriate? Why? Example 2: The mean and median selling price of existing single-family homes sold in June 2002 were $163,900 and $210,900. Which of these numbers is the mean and which is the median? Explain how you know. Example 3: A class of 9th grade students takes a test designed for 6th graders. The mean and median scores are 83% and 87%. What direction is the skewness of the test scores, and which number is the mean?, median? 13 Measuring the spread of a distribution The minimum and maximum values show the full spread of the data (but they may be outliers. Also, the spread of the in-between numbers is ignored.) The quartiles mark the spread of the middle half of the data as well as the spread of the upper and lower 25% of the data. Box Plots – Five Number Summary - In a symmetric distribution, the first and third quartiles are equally distant from the median - In most distributions that are skewed to the right, the third quartile will be farther above the median than the first quartile is below it. The standard deviation measures the spread of the data by looking at how far the observations are from their mean and averaging those values. Choosing measures of center and spread The five-number summary is usually better than the mean and standard deviation for describing a skewed distribution or a distribution with strong outliers. Use the mean and standard deviation only for reasonably symmetric distributions that are free of outliers. 14