1. Ad Hoc DFT Guidelines - IC
advertisement

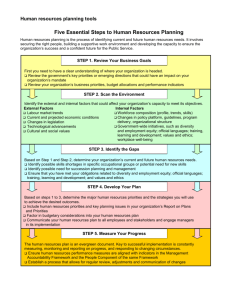
Design for Testability Cheng-Wen Wu Department of Electrical Engineering National Tsing Hua University 101, Sec. 2, Kuang Fu Rd. Hsinchu, Taiwan R.O.C. 1. Ad Hoc DFT Guidelines There is definitely no single methodology which solves all VLSI testing problems; there also is no single DFT technique which is effective for all kinds of circuits. DFT techniques can largely be divided into two categories, i.e., ad hoc techniques and structured (systematic) techniques. The latter will be discussed in Sec. 3, which include major internal scan approaches; while the former are the subject of this section, which are basically ad hoc DFT guidelines. Some important guidelines are listed below. 1. Partition large circuits into smaller subcircuits to reduce test costs. One of the most important step in designing a testable chip is to first partition the chip in an appropriate way such that for each functional module there is an effective (DFT) technique to test it. Partitioning certainly has to be done at every level of the design process, from architecture to circuit, whether testing is considered or not. Conventionally, when testing is not considered, designers partition their objects to ease management, to speed up turn-around time, to increase performance, and to reduce costs. We stress here that the designers should also partition the objects to increase their testability. T1 T2 Mode 1 S 0M C2 C1 Normal Test C1 Test C2 T1 T2 0 0 1 0 1 0 S 1 M 0 0 1 M S 1 0 S M Figure 1: Circuit partitioning. Partitioning can be functional (according to functional module boundaries) or physical (based on circuit topology). In general, either way is good for testing in most cases. Partitioning can be done by using multiplexers (see Fig.1) and/or scan chains (see Sec. 3). Maintaining signal integrity is a basic guideline on partition for testability, which helps localize faults. After partitioning, modules should be completely testable via their interface. 2. Employ test points to enhance controllability & observability. Another important DFT technique is test point insertion. Test points include control points (CPs) and observation points (OPs). The former are active test points, while the latter are passive ones. There are test points which are both CPs and OPs. OP C1 . . . C2 . . . M CP1 C3 CP2 CP3 CP4 Figure 2: Test point insertion. After partitioning, we still need a mechanism of directly accessing the interface between the modules. Test stimuli and responses of the module under test can be made accessible through test points. Test point insertion can be done as illustrated in Fig. 2, and can be accessed via probe pads and extra or shared (multiplexed) input/output pins. Before exercising test through test points which are not PIs and POs, we should investigate into additional requirements on the test points raised by the use of test equipments. 3. Design circuits to be easily initializable. This increases predictability. A power-on reset mechanism is the most effective and widely used approach. A reset pin for all or some modules also is important. Synchronizing or homing sequences for small finite state machines may be used where appropriate (a famous example is the JTAG TAP controller--see the chapter on Boundary Scan). 4. Disable internal one-shots (monostables) during test. This is due to the difficulty for the tester to remain synchronized with the DUT. A monostable (one-shot) multivibrator produces a pulse of constant duration in response to the rising or falling transition of the trigger input. It has only one stable state. Its pulse duration is usually controlled externally by a resistor and a capacitor (with current technology, they also can be integrated on chip). One-shots are used mainly for 1) pulse shaping, 2) switch-on delays, 3) switch-off delays, 4) signal delays. Since it is not controlled by clocks, synchronization and precise duration control are very difficult, which in turn reduces testability by ATE. Counters and dividers are better candidates for delay control. 5. Disable internal oscillators and clocks during test. To guarantee tester synchronization, internal oscillator and clock generator circuitry should be isolated during the test of the functional circuitry. Of course the internal oscillators and clocks should also be tested separately. 6. Provide logic to break global feedback loops. Circuits with feedback loops are sequential ones. Effective sequential ATPGs are yet to be developed, while combinational ones are relatively mature now. Breaking the feedback loops turn the sequential testing problem into a combinational one, which greatly reduces the testing effort needed in general. Specifically, test generation becomes feasible, and fault localization becomes much easier. Breaking global feedback loops are especially effective, since otherwise we are facing the problem of testing a large sequential circuit (such as a CPU), which can frequently be shown to be very hard or even impossible. Scan techniques and/or multiplexers which are used to partition a circuit can also be used to break the feedback loops. The feedback path can be considered as both the CP and the OP. 7. Partition large counters into smaller ones. Sequential modules with long cycles such as large counters, dividers, serial comparators, and serial parity checkers require very long test sequences. For example, a 32-bit counter requires 232 clock cycles for a full state coverage, which means a test time of more than one hour only for the counter, if a 10 MHz clock is used. Test points should be used to partition these circuits into smaller ones and test them separately. 8. Avoid the use of redundant logic. This has been discussed in the chapters on combinational and sequential ATPG. 9. Keep analog and digital circuits physically apart. Mixed analog and digital circuits in a single chip is gaining attraction as VLSI technologies keep moving forward. Analog circuit testing, however, is very much different from digital circuit testing. In fact, what we mean by testing for analog circuits is really measurement, since analog signals are continuous (as opposed to discrete or logic signals in digital circuits). They require different test equipments and different test methodologies, therefore they should be tested separately. To avoid interference or noise penetration, designers know that they should physically isolate the analog circuit layout from the digital one which resides on the same chip, with signals communicated via AD converters and/or DA converters. For testing purpose, we require more. These communicating wires between the analog and digital modules should become the test points, i.e., we should be able to test the analog and digital parts independently. 10. Avoid the use of asynchronous logic. Asynchronous circuits are sequential ones which are not clocked. Timing is determined by gate and wire delays. They usually are less expensive and faster than their synchronous counterpart, so some experienced designers like to use them. Their design verification and testing, however, are much harder than synchronous circuits. Since no clocking is employed, timing is continuous instead of discrete, which makes tester synchronization virtually impossible, and therefore only functional test by application board can be used. In almost all cases, high fault coverage cannot be guaranteed within a reasonable test time. 11. Avoid diagnostic ambiguity groups such as wired-OR/wired-AND junctions and high-fanout nodes. Apart from performance reasons, wired-OR/wired-AND junctions and high-fanout nodes are hard to test (they are part of the reasons why ATPGs are so inefficient), so they should be avoided. 12. Consider tester requirements. Tester requirements such as pin limitation, tristating, timing resolution, speed, memory depth, driving capability, analog/mixed-signal support, internal/boundary scan support, etc., should be considered during the design process to avoid delay of the project and unnecessary investment on the equipments. The above guidelines are from experienced practitioners. They are not meant to be complete or universal. In fact, there are drawbacks for these techniques: high fault coverage cannot be guaranteed; manual test generation is still required; design iterations are likely to increase. 2. Syndrome-Testable Design Syndrome testing [10, 11] is an exhaustive method, and is only for combinational circuits, so it is not considered as an efficient method. The idea of introducing control inputs to make circuits syndrome testable (to be explained below) however can be applied effectively in many DFT situations other than syndrome testing. Definition 1 The syndrome of a boolean function f is S ( f ) k( f ) , where k is the number of 1s (minterms) in f 2n and n is the number of independent input variables. Exhaustive Patterns Patterns UUT Syndrome Register Comparator (Counter) Reference syndrome Figure 3: A typical syndrome testing set-up. Go/No-go By the definition, 0≦S(f) ≦1. A circuit is is said to be syndrome testable iff fault, , S(f)≠ S( fα). To use syndrome testing, the DUT must be syndrome testable. Furthermore, since the method is exhaustive (we have to evaluate all 2n input combinations), it is applicable only to circuits with small number of inputs, e.g., n 20. For large circuits, we can partition them with scan chains and/or multiplexers. A typical syndrome testing set-up is shown in Fig. 3. According to the definition, the syndromes of primitive gates can easily be calculated, as shown in Tab. 1. Gate ANDn S 1 2n ORn 1- 1 2n XORn NOT 1 2 1 2 Table 1: Syndromes of primitive gates. The overall syndrome of a fanout-free circuit can then be derived in a recursive manner. For example, consider a circuit having 2 blocks, f and g, with unshared inputs. Its overall syndrome can be obtained according to Tab. 2. O/p gate S OR s f Sg S f Sg AND S f Sg XOR S f S g 2S f S g NAND 1 S f Sg NOR 1 S f Sg S f Sg Table 2: Recursive calculation of syndromes. Example 1 Calculate the syndrome of the following circuit. 1 3 4 4 1 3 S2 1 4 4 1 S3 8 S 4 1 ( S S 3 S 2 S 3 ) 7 / 32 S1 1 S S1 S 4 21 / 128 Exercise 1 Show that for blocks with shared inputs (circuits having reconvergent fanouts): S ( f g ) S f S g S ( fg ) S ( fg ) S f S g S ( fg ) 1 S ( f g ) S ( fg ) S ( fg ) From the above discussion, syndrome is a property of function, not of implementation. Definition 2 A logic function is unate in a variable xi if it can be represented as an sop or pos expression in which the variable xi appears either only in an uncomplemented form or only in a complemented form Theorem 1 A 2-level irredundant circuit realizing a unate function in all its variables is syndrome-testable. Theorem 2 Any 2-level irredundant circuit can be made syndrome-testable by adding control inputs to the AND gates. Example 2 1 1 Let f xz yz . Then S . If z / 0, then f a y. S S . 2 2 Syndrome untestable . S1 S S2 S4 S3 Now add a control input c f cxz yz , where when in normal operation mode 1 c normal i/p when in test mode 3 1 S , f y , and S S . Syndrome testable. 8 2 Note that the modification process doubles the test set size. 3. Scan Design Approaches Although we have not formally presented the scan techniques, their purpose and importance have been discussed in the previous sections, namely, they are effective for circuit partitioning; they provide controllability and observability of internal state variables for testing; they turn the sequential test problem into a combinational one. There are four major scan approaches that we will discuss in this section, i.e., MUXed Scan [12] Scan path [13,14]; LSSD [15, 16]; Random access [17]. 3.1 MUXed Scan This approach is also called the MUX Scan Approach, in which a MUX is inserted in front of every FF to be placed in the scan chain. It was invented at Stanford in 1973 by M. Williams & Angell, and later adopted by IBM--heavily used in IBM products. X y Combinational Logic Z Y State Vector Figure 4: A finite state machine model for sequential circuits. A popular finite state machine (FSM) model for sequential circuits is shown in Fig. 4, in which X is the PI vector, Z the PO vector, Y the excitation (next state) vector, and y the present state vector. The excitation vector is also called the pseudo primary output (PPO) vector, and the present state vector is also called the pseudo primary input (PPI) vector. To make elements of the state vector controllable and observable, we add the following items to the original FSM (see Fig.5): C/L Z X SI M FF M FF M FF L1 D Q D SO C T DI L2 Q SI T C Figure 5: The Shift-Register Modification approach. a TEST mode pin (T); a SCAN-IN pin (SI); a SCAN-OUT pin (SO); a MUX (switch) in front of each FF (M) When the test mode pin T=0, the circuit is in normal operation mode; when T=1, it is in test mode (or shift-register mode). This is clearly shown in Fig.5. The test procedure using this method is as follows: Switch to the shift-register (SR) mode (T=1) and check the SR operation by shifting in an alternating sequence of 1s and 0s, e.g., 00110 (a simple functional test). Initialize the SR-load the first pattern from SI Return to the normal mode (T=0), apply the test pattern, and capture the response. Switch to the SR mode and shift out the final state from SO while setting the starting state for the next test. Go to if there is a test pattern to apply. This approach effectively turns the sequential testing problem into a combinational one, i.e., the DUT becomes the combinational logic which usually can be fully tested by compact ATPG patterns. Unfortunately, there are two types of overheads associated with this technique which the designers care about very much: the hardware overhead (including three extra pins, multiplexers for all FFs, and extra routing area) and performance overhead (including multiplexer delay and FF delay due to extra load). Since test mode and normal mode are exclusive of each other, in test mode the SI pin may be a redefined input pin, and the SO pin may be a redefined output pin. The redefinition of the pins can be done by a multiplexer controlled by T. This arrangement is good for a pin-limited design, i.e., one whose die size is entirely determined by the pad frame. The actual hardware overhead varies from circuit to circuit, depending on the percentage of area occupied by the FFs and the routing condition. 3.2 Scan Path This approach is also called the Clock Scan Approach, in which the multiplexing function is implemented by two separate ports controlled by two different clocks instead of a MUX. It was invented by Kobayashi et al. in 1968, and reported by Funatsu et al. in 1975, and adopted by NEC. It uses two-port raceless D-FFs: each FF consists of two latches operating in a master-slave fashion, and has two clocks (C1 and C2) to control the scan input (SI) and the normal data input (DI) separately. The logic diagram of the two-port raceless D-FF is shown in Fig.6 . The test procedure of the Clock Scan Approach is the same as the MUX Scan Approach. The difference is in the scan cell design and control. The MUX has disappeared from the scan cell, and the FF is redesigned to incorporate the multiplexing function into the register cell. The resulting two-port raceless D-FF is controlled in the following way: Normal mode: C2 = 1 to block SI; C1 = 0 →1 to load DI. SR (test) mode: C1 = 1 to block DI; C2 = 0 →1 to load SI. C2 SI DI DO SO C1 L2 L1 2-port raceless master-slave D FF Figure 6: Logic diagram of the two-port raceless D-FF. This approach is said to achieve a lower hardware overhead (due to dense layout) and less performance penalty (due to the removal of the MUX in front of the FF) compared to the MUX Scan Approach. The real figures however depend on the circuit style and technology selected, and on the physical implementation. 3.3 Level-Sensitive Scan Design (LSSD) This approach was introduced by Eichelberger and T. Williams in 1977 and 1978. It is a latch-based design used at IBM, which guarantees race- and hazard-free system operation as well as testing, i.e., it is insensitive to component timing variations such as rise time, fall time, and delay. It also is claimed to be faster and have a lower hardware complexity than SR modification. It uses two latches (one for normal operation and one for scan) and three clocks. Furthermore, to enjoy the luxury of race- and hazard-free system operation and test, the designer has to follow a set of complicated design rules (to be discussed later), which kill nine designers out of ten. Definition 3 A logic circuit is level sensitive (LS) iff the steady state response to any allowed input change is independent of the delays within the circuit. Also, the response is independent of the order in which the inputs change D C D L L +L C C D 0 0 0 1 L 1 0 0 1 1 1 +L L Figure 7: A polarity-hold latch. DI +L1 C DI C SI A SI +L2 +L1 L1 L2 +L2 B A B Figure 8: The polarity-hold shift-register latch (SRL). LSSD requires that the circuit be LS, so we need LS memory elements as defined above. Fig. 7 shows an LS polarity-hold latch. The correct change of the latch output (L) is not dependent on the rise/fall time of C, but only on C being `1' for a period of time greater than or equal to data propagation and stabilization time. Fig. 8 shows the polarity-hold shift-register latch (SRL) used in LSSD as the scan cell. The scan cell is controlled in the following way: Normal mode: A=B=0, C=0 1. SR (test) mode: C=0, AB=10 01 to shift SI through L1 and L2. The SRL has to be polarity-hold, hazard-free, and level-sensitive. To be race-free, clocks C and B as well as A and B must be nonoverlapping. This design (similar to Scan Path) avoids performance degradation introduced by the MUX in shift-register modification. If pin count is a concern, we can replace B with A C , i.e., NOR(A,C). Figure 9: LSSD structures. C/L Z X C A L1 L1LSSD SIDouble-latch L2 L2 L1 L2 SO C/L Z X C A SI Single-latch L1 L1 LSSD L2 L2 L1 L2 SO B B LSSD design rules are summarized as follows: Internal storage elements must be polarity-hold latches. Latches can be controlled by 2 or more nonoverlapping clocks that satisfy: A latch X may feed the data port of another latch Y iff the clock that sets the data into Y does not clock X. A latch X may gate a clock C to produce a gated clock Cg, which drives another latch Y iff Cg, or any other clock C’g produced from Cg, does not clock X. There must exist a set of clock primary inputs from which the clock inputs to all SRLs are controlled ither through (1) single-clock distribution tree or (2) logic that is gated by SRLs and/or nonclock primary inputs. In addition, the following conditions must hold: All clock inputs to SRLs must be OFF when clock PIs are OFF. Any SRL clock input must be controlled from one or more clock PIs. No clock can be ANDed with either the true or the complement of another clock. Clock PIs cannot feed the data inputs to latches, either directly or through combinational logic. Every system latch must be part of an SRL; each SRL must be part of some scan chain. A scan state exists under the following conditions: Each SRL or scan-out PO is a function of only the preceding SRL or scan-in PI in its scan chain during the scan operation. All clocks except the shift clocks are disabled at the SRL inputs. Any shift clock to an SRL can be truned ON or OFF by changing the corresponding clock PI. A network that satisfies rules - is level-sensitive. Race-free operation is guaranteed by rules .&. Rule allows a tester to turn off system clocks and use the shift clocks to force data into and out of the scan chain. Rules & are used to support scan. The advantages associated with LSSD are: 1. Correct operation independent of AC characteristics is guaranteed. 2. FSM is reduced to combinational logic as far as testing is concerned. 3. Hazards and races are eliminated, which simplifies test generation and fault simulation. There however are problems with LSSD (or previously discussed scan approaches): 1. Complex design rules are imposed on designers--no freedom to vary from the overall schemes, and higher design and hardware costs (4-20% more hardware and 4 extra pins). 2. No asynchronous designs are allowed. 3. Sequential routing of latches can introduce irregular structures. 4. Faults changing combinational function to sequential one may cause trouble, e.g., bridging and CMOS stuck-open faults. 5. Function to be tested has been changed into a quite different combinational one, so specification language will not be of any help. 6. Test application becomes a slow process, and normal-speed testing of the entire test sequence is impossible. 7. It is not good for memory intensive designs. 3.4 Random Access This approach uses addressable latches whose addressing scheme is similar to high-density memory addressing, i.e., an address decoder is needed. It provides random access to FFs via multiplexing--address selection. The approach was developed by Fujitsu [Ando, 1980], and was used by Fujitsu, Amdahl, and TI. Its overall structure is shown in Fig. 10. C/L X C SI L1 L1 Z L1 L1 addr decoder Figure 10: The Random Access structure and its cell design. The difference between this approach and the previous ones is that the state vector can now be accessed in a random sequence. Since neighboring patterns can be arranged so that they differ in only a few bits, and only a few response bits need to be observed, the test application time can be reduced. Also, it has minimal impact on the normal paths, so the performance penalty is minimized. Another advantage of this approach is that it provides the ability to `watch' a node in normal DI CKI SI +L CK2 Addr SO (C = CK1 & CK2) operation mode, which is impossible with previous scan methods. The major disadvantage of the approach is that it needs an address decoder, thus the hardware overhead (chip area and pin count) is high. As a summary, for all scan techniques, 1) test patterns still need to be computed by ATPG; 2) test patterns must be stored externally, and responses must be stored and evaluated, so large (non-portable) test fixture are still required. Therefore, there is a growing interest in built-in self-test (BIST). A typical CMOS scan cell design is shown in Fig.11. C DI SI MUX Latch on FF Q SO B Q DI SI SO A Figure 11: A typical CMOS scan cell. Problems 1. For the positive-edge triggered DFF with Reset discussed in the text, formulate CO(C) and SO(C). 2. Consider the two-bit binary adder consisting of two full-adder cells as shown below. (a) Calculate CC0(C1)and CC1(C1). (b) Discuss syndrome testabilities for a/0, a/1, b/0, and b/1, respectively. (c) Use PODEM to derive a test for a/0. (d) The dotted box defines a full adder cell, i.e., a single-bit adder stage. The same architecture obviously can be used to construct an n-bit binary adder for any positive integer n by copying the cells and extending to the left of the array. Show that for any adder so constructed, 8 test patterns are sufficient for detecting all single stuck faults (independent of n). 3. Calculate the syndromes for the carry and sum outputs of a full adder cell. Determine whether there is any single stuck fault on any input for which one of the outputs is syndrome-untestable. If there is, suggest an implementation--possibly with added inputs--which makes the cell syndrome-testable. 4. Consider the random-access scan architecture. How would you organize the test data to minimize the total test time? Describe a simple heuristic for ordering these data. 5. We have seen the application of scan chains to FSMs. They can be applied to combinational networks too. A combinational network can be represented with a directed acyclic graph (DAG), where edges stand for signals and nodes for computational elements. Consider the DAG shown below. (a) Show that we can assign scan latches to the edges so that |T|=8, and all nodes will be tested pseudo-exhaustively. (b) What is the minimum number of latches to fulfill the task? Project Cellular multipliers may be classified by the format in which data words are accessed, namely serial form and parallel form. The choice lies more or less in speed (or throughput) and silicon area, which are the major factors contributing to the performance and cost of the circuit. Bit-serial multipliers can further be divided into bit-sequential ones and serial-parallel ones. A bit-sequential multiplier accepts its operands bit by bit; while a serial-parallel one takes one input in serial and the other in parallel. Both types produce outputs in series. They have about the same area (hardware) and time complexities. Design a 4-bit unsigned bit-serial integer multiplier in either bit-sequential or serial-parallel form. Give the block diagram of the multiplier, which is an array of four basic cells. Give the schematic of the cell, which consists of a full adder and a few primitive gates, flip-flops, and latches. Explain how the multiplier works. Enter your design into a CAD environment, using, e.g., Verilog, VHDL, or any schematic capture tool. Verify your design by your functional patterns until you are confident that the design is correct. Now use a fault simulator to derive the fault coverage of your functional patterns. Discuss the results. If your functional patterns do not achieve a fault coverage of more than 90%, use a sequential ATPG to make up the difference. Can you improve the stuck-at fault coverage to 100% (excluding redundant faults)? Repeat the above experiment, but now use MUX scan approach in your design. Discuss the difference. Repeat the above two experiments for 8-bit and 16-bit multipliers. Draw a conclusion on your experiments.