Chapter 8: Descriptive Statistics - research
advertisement

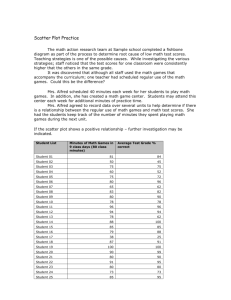
Chapter 8: Descriptive Statistics Introduction A statistic is a numerical representation of information. Whenever we quantify or apply numbers to data in order to organize, summarize, or better understand the information, we are using statistical methods. These methods can range from somewhat simple computations such as determining the mean of a distribution to very complex computations such as determining factors or interaction effects within a complex data set. This chapter is designed to present an overview of statistical methods in order to better understand research results. Very few formulas or computations will be presented, as the goal is merely to understand statistical theory. Before delving into theory, it is important to understand some basics of statistics. There are two major branches of statistics, each with specific goals and specific formulas. The first, descriptive statistics, refers to the analysis of data of an entire population. In other words, descriptive statistics is merely using numbers to describe a known data set. The term population means we are using the entire set of possible subjects as opposed to just a sample of these subjects. For instance, the average test grade of a third grade class would be a descriptive statistic because we are using all of the students in the class to determine a known average. Second, inferential statistics, has two goals: (1) to determine what might be happening in a population based on a sample of the population (often referred to as estimation) and (2) to determine what might happen in the future (often referred to as prediction). Thus, the goals of inferential statistics are to estimate and/or predict. To use inferential statistics, only a sample of the population is needed. Descriptive statistics, however, require the entire population be used. Many of the descriptive techniques are also used for inferential data so we’ll discuss these first. Lets start with a brief summary of data quality. Scales of Measurement Statistical information, including numbers and sets of numbers, has specific qualities that are of interest to researchers. These qualities, including magnitude, equal intervals, and absolute zero, determine what scale of measurement is being used and therefore what statistical procedures are best. Magnitude refers to the ability to know if one score is greater than, equal to, or less than another score. Equal intervals means that the possible scores are each an equal distance from each other. And finally, absolute zero refers to a point where none of the scale exists or where a score of zero can be assigned. When we combine these three scale qualities, we can determine that there are four scales of measurement. The lowest level is the nominal scale, which represents only names and therefore has none of the three qualities. A list of students in alphabetical order, a list of favorite cartoon characters, or the names on an organizational chart would all be classified as nominal data. The second level, called ordinal data, has magnitude only, and can be looked at as any set of data that can be placed in order from greatest to lowest but where there is no absolute zero and no equal intervals. Examples of this type of scale would include Likert Scales and the Thurstone Technique. The third type of scale is called an interval scale, and possesses both magnitude and equal intervals, but no absolute zero. Temperature is a classic example of an interval scale because we know that each degree is the same distance apart and we can easily tell if one temperature is greater than, equal to, or less than another. Temperature, however, has no absolute zero because there is (theoretically) no point where temperature does not exist. Finally, the fourth and highest scale of measurement is called a ratio scale. A ratio scale contains all three qualities and is often the scale that statisticians prefer because the data can be more easily analyzed. Age, height, weight, and scores on a 100-point test would all be examples of ratio scales. If you are 20 years old, you not only know that you are older than someone who is 15 years old (magnitude) but you also know that you are five years older (equal intervals). With a ratio scale, we also have a point where none of the scale exists; when a person is born his or her age is zero. Table 8.1: Scales of Measurement Scale Level Scale of Measurement Scale Qualities Example(s) Magnitude 4 Ratio Equal Intervals Age, Height, Weight, Percentage Absolute Zero Magnitude 3 Interval 2 Ordinal Magnitude Likert Scale, Anything rank ordered 1 Nominal None Names, Lists of words Equal Intervals Temperature Types of Distributions When datasets are graphed they form a picture that can aid in the interpretation of the information. The most commonly referred to type of distribution is called a normal distribution or normal curve and is often referred to as the bell shaped curve because it looks like a bell. A normal distribution is symmetrical, meaning the distribution and frequency of scores on the left side matches the distribution and frequency of scores on the right side. Many distributions fall on a normal curve, especially when large samples of data are considered. These normal distributions include height, weight, IQ, SAT Scores, GRE and GMAT Scores, among many others. This is important to understand because if a distribution is normal, there are certain qualities that are consistent and help in quickly understanding the scores within the distribution The mean, median, and mode of a normal distribution are identical and fall exactly in the center of the curve. This means that any score below the mean falls in the lower 50% of the distribution of scores and any score above the mean falls in the upper 50%. Also, the shape of the curve allows for a simple breakdown of sections. For instance, we know that 68% of the population fall between one and two standard deviations (See Measures of Variability Below) from the mean and that 95% of the population fall between two standard deviations from the mean. Figure 8.1 shows the percentage of scores that fall between each standard deviation. Figure 8.1: The Normal Curve As an example, lets look at the normal curve associated with IQ Scores (See Figure 8.2). The mean, median, and mode of a Wechsler’s IQ Score is 100, which means that 50% of IQs fall at 100 or below and 50% fall at 100 or above. Since 68% of scores on a normal curve fall within one standard deviation and since an IQ score has a standard deviation of 15, we know that 68% of IQs fall between 85 and 115. Comparing the estimated percentages on the normal curve with the IQ scores, you can determine the percentile rank of scores merely by looking at the normal curve. For example, a person who scores at 115 performed better than 87% of the population, meaning that a score of 115 falls at the 87th percentile. Add up the percentages below a score of 115 and you will see how this percentile rank was determined. See if you can find the percentile rank of a score of 70. Figure 8.2: IQ Score Distributions Skew. The skew of a distribution refers to how the curve leans. When a curve has extreme scores on the right hand side of the distribution, it is said to be positively skewed. In other words, when high numbers are added to an otherwise normal distribution, the curve gets pulled in an upward or positive direction. When the curve is pulled downward by extreme low scores, it is said to be negatively skewed. The more skewed a distribution is, the more difficult it is to interpret. Figure 8.3: Distribution Skew Kurtosis. Kurtosis refers to the peakedness or flatness of a distribution. A normal distribution or normal curve is considered a perfect mesokurtic distribution. Curves that contain more score in the center than a normal curve tend to have higher peaks and are referred to as leptokurtic. Curves that have fewer scores in the center than the normal curve and/or more scores on the outer slopes of the curve are said to be platykurtic. Figure 8.4: Distribution Kurtosis Statistical procedures are designed specifically to be used with certain types of data, namely parametric and non-parametric. Parametric data consists of any data set that is of the ratio or interval type and which falls on a normally distributed curve. Non-parametric data consists of ordinal or ratio data that may or may not fall on a normal curve. When evaluating which statistic to use, it is important to keep this in mind. Using a parametric test (See Summary of Statistics in the Appendices) on non-parametric data can result in inaccurate results because of the difference in the quality of this data. Remember, in the ideal world, ratio, or at least interval data, is preferred and the tests designed for parametric data such as this tend to be the most powerful. Measures of Central Tendency There are three measures of central tendency and each one plays a different role in determining where the center of the distribution or the average score lies. First, the mean is often referred to as the statistical average. To determine the mean of a distribution, all of the scores are added together and the sum is then divided by the number of scores. The mean is the preferred measure of central tendency because it is used more frequently in advanced statistical procedures, however, it is also the most susceptible to extreme scores. For example, if the scores ‘8’ ‘9’ and ‘10’ were added together and divided by ‘3’, the mean would equal ‘9’. If the 10 was changed to 100, making it an extreme score, the mean would change drastically. The new mean of ‘8’ ‘9’ and ‘100’ would be ’39.’ The median is another method for determining central tendency and is the preferred method for highly skewed distributions. The media is simply the middle most occurring score. For an even number of scores there will be two middle numbers and these are simply added together and divided by two in order to determine the median. Using the same distribution as above, the scores ‘8’ ‘9’ and ‘10’ would have a median of 9. By changing the ‘10’ to a score of ‘100’ you’ll notice that the median of this new positively skewed distribution does not change. The median remains equal to ‘9.’ Finally, the mode is the least used measure of central tendency. The mode is simply the most frequently occurring score. For distributions that have several peaks, the mode may be the preferred measure. There is no limit to the number of modes in a distribution. If two scores tie as the most frequently occurring score, the distribution would be considered bimodal. Three would be trimodal, and all distributions with two or more modes would be considered multimodal distributions. Figure 8.5: Measures of Central Tendency Interestingly, in a perfectly normal distribution, the mean, median, and mode are exactly the same. As the skew of the distribution increases, the mean and median begin to get pulled toward the extreme scores. The mean gets pulled the most which is why it becomes less valid the more skewed the distribution. The median gets pulled a little and the mode typically remains the same. You can often tell how skewed a distribution is by the distance between these three measures of central tendency. Measures of Variability Variability refers to how spread apart the scores of the distribution are or how much the scores vary from each other. There are four major measures of variability, including the range, interquartile range, variance, and standard deviation. The range represents the difference between the highest and lowest score in a distribution. It is rarely used because it considers only the two extreme scores. The interquartile range, on the other hand, measures the difference between the outermost scores in only the middle fifty percent of the scores. In other words, to determine the interquartile range, the score at the 25th percentile is subtracted from the score at the 75th percentile, representing the range of the middle 50 percent of scores. The variance is the average of the squared differences of each score from the mean. To calculate the variance, the difference between each score and the mean is squared and then added together. This sum is then divided by the number of scores minus one. When the square root is taken of the variance we call this new statistic the standard deviation. Since the variance represents the squared differences, the standard deviation represents the true differences and is therefore easier to interpret and much more commonly used. Since the standard deviation relies on the mean of the distribution, however, it is also affected by extreme scores in a skewed distribution. The Correlation The correlation is one of the easiest descriptive statistics to understand and possibly one of the most widely used. The term correlation literally means co-relate and refers to the measurement of a relationship between two or more variables. A correlational coefficient is used to represent this relationship and is often abbreviated with the letter ‘r.’ A correlational coefficient typically ranges between –1.0 and +1.0 and provides two important pieces of information regarding the relationship: Intensity and Direction. Intensity refers to the strength of the relationship and is expressed as a number between zero (meaning no correlation) and one (meaning a perfect correlation). These two extremes are rare as most correlations fall somewhere in between. In the social sciences, a correlation of 0.30 may be considered significant and any correlation above 0.70 is almost always significant. The absolute value of ‘r’ represents the intensity of any correlation. Direction refers to how one variable moves in relation to the other. A positive correlation (or direct relationship) means that two variables move in the same direction, either both moving up or both moving down. For instance, high school grades and college grades are often positively correlated in that students who earn high grades in high school tend to also earn high grades in college. A negative correlation (or inverse relationship) means that the two variables move in opposite directions; as one goes up, the other tends to go down. For instance, depression and self-esteem tend to be inversely related because the more depressed an individual is the lower his or her self-esteem. As depression increases, then, self-esteem tends to decrease. The sign in front of the ‘r’ represents the direction of a correlation. Figure 8.6: Scatter plots for sample correlations Scatter Plot. Correlations are graphed on a special type of graph called a scatter plot (or scatter gram). On a scatter plot, one variable (typically called the X variable) is placed on the horizontal axis (abscissa) and the Y variable is placed on the vertical axis (ordinate). For example, if we were measuring years of work experience and yearly income, we would likely find a positive correlation. Imagine we looked at ten subjects and found the hypothetical results listed in Table 8.2. Table 8.2: Sample Correlation Data Subject Number Experience in Years Income in Thousands Subject Number Experience in Years Income in Thousands 1 0 20 6 15 50 2 5 30 7 20 60 3 5 40 8 25 50 4 10 30 9 30 70 5 10 50 10 35 60 Notice how each subject has two pieces of information (years of experience and income). These are the two variables that we are looking at to determine if a relationship exists. To place this information in a scatter plot we will consider experience the X variable and income the Y variable (the results will be the same even if the variables are reversed) and then each dot will represent one subject. The scatter plot in Figure 8.7 represents this data. Notice how the line drawn through the data points has an upward slope. This slope represents the direction of the relationship and tells us that as experience increases so does income. Figure 8.7: Scatter Plot for Sample Data Correlation and Causality. One common mistake made by people interpreting a correlational coefficient refers to causality. When we see that depression and low self-esteem are negatively correlated, we often surmise that depression must therefore cause the decrease in self-esteem. When contemplating this, consider the following correlations that have been found in research: Positive correlation between ice cream consumption and drownings Positive correlation between ice cream consumption and murder Positive correlation between ice cream consumption and boating accidents Positive correlation between ice cream consumption and shark attacks If we were to assume that every correlation represents a causal relationship then ice cream would most certainly be banned due to the devastating effects it has on society. Does ice-cream consumption cause people to drown? Does ice cream lead to murder? The truth is that often two variables are related only because of a third variable that is not accounted for within the statistic. In this case, the weather is this third variable because as the weather gets warmer, people tend to consume more ice cream. Warmer weather also results in an increase in swimming and boating and therefore increased drownings, boating accidents, and shark attacks. So looking back at the positive correlation between depression and self-esteem, it could be that depression causes self-esteem to go down, or that low self-esteem results in depression, or that a third variable causes the change in both. When looking at a correlational coefficient, be sure to recognize that the variables may be related but that it in no way implies that the change in one causes the change in the other. Specific Correlations. Up to this point we have been discussing a specific correlation known as the Pearson Product Moment Correlation (or Pearson’s r) which is abbreviated with the letter ‘r.’ Pearson is the most commonly cited correlation but can only be used when there are only two variables that both move in a continuous linear (straight line) direction. When there are more than two variables, when the variables are dichotomous (true/false or yes/no) or rank ordered, or when the variables have a nonlinear or curved direction, different types of correlations would be used. The Biserial and Point Biserial Correlations are used when one variable is dichotomous and the other is continuous such as gender and income. The phi or tetrachoric correlations are used when both variables are dichotomous such as gender and race. And finally, Spearman’s rho correlation is used with two rank ordered variables and eta is used when the variables are nonlinear. Chapter Conclusion While this chapter only provided a quick basic summary of descriptive statistics, it should give you a good idea of how data is summarized. Remember, the goal of descriptive statistics is to describe, in numerical format, what is currently happening within a known population. We use measures such as the mean, median, and mode to describe the center of a distribution. We use standard deviation, range, or interquartile range to describe the variability of a distribution, and we use correlations to describe relationships among two or more distributions. By knowing this information and by understanding the basics of charting and graphing in descriptive statistics, inferential statistics become easier to understand. In fact, much of the information in this chapter becomes the foundation for the advanced statistics discussed in the chapter 9.