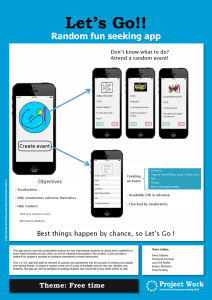
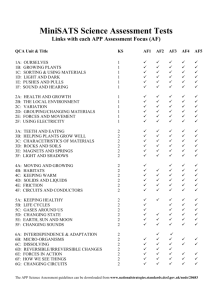
23841
advertisement

1 >>: I guess we can start. Welcome, everybody. Welcome to our consecutive XAPFest event. Now we have Jason Short. He's from the SQL group, but will talk about just data and how you can present it in the Windows phone. Without further ado, Jason. >> Jason Short: Thanks, [indiscernible]. Hello, everyone. Like [indiscernible] said, I work in SQL server, but we're not talking about SQL server tonight. Most of what we're going to be talking about is just data management within your application on the phone. And I'm going to go through a bunch of different frameworks and different principles that you can use to apply on to your application. Just a little bit about my background. I do work for SQL server and manage ability. I've been at Microsoft about two years now. Prior to that, I was in ISV for 13 years. I worked on a lot of different projects from Windows CE stuff, I was actually at the very first Windows CE developer conference, which I can tell you was a very different developer experience than what we have today. I also wrote apps for Palm, iPhone, Android, and now I'm doing Windows phone development on the side. Some of these pictures you see here on the far left here, this is a magical moment pin from Disney. I moved here from Orlando, and I think just about everyone within Orlando works for Disney at some point. I actually worked on these little embedded chips that actually were a little game that kids could play like Simon Says on the chip. And a lot of the same principles that you use in your phone apps today, we use in embedded environments as well. The hat there in the middle is actually a big, it's a 260-foot tall icon at Hollywood studios at Disney World, and I actually did the lighting controls for that, that actually control how the lights spin, depending upon how many people around. The people who are wearing the pins, it actually emits a near field communication to let the hat know how many people are around. So a lot of embedded development that you're doing on your phone, it applies to a lot of other environments. Don't just think about your phone when you're writing your apps. I also wrote the control for the E.T. adventure at Universal Studios. The E.T. character actually says good-bye to every single person on the ride, and he 2 knows their names. That's a four terabyte database that's actually recorded with actors for E.T.'s voice, and we actually have to pan that across audio. That's all SQL server that we actually do all that with. So, you know, when you're doing this type of development, don't just think hey, this is my phone today, this is what I'm going to do, you know. You never know where this stuff will go. Mostly what we're going to go through today is your core data scenarios. Anyone who's worked with databases probably has seen the acronym CRUD. And, of course, I get a meeting. And CRUD stands for just create, retrieve, update, delete. And we're going to go through each one of those for the phone, how you might think about it in the context of your application. And then we're going to go through some frameworks you can use or tools you can use to actually help you implement this within your application. AGFX, SterlingDB, SQLCE, and I'll basically go through different scenarios where each one is applicable and how you might apply them. Sometimes you'll end up using all three within an application. When you're looking at application data, you really need to go through. Ask yourselves some questions about your application, you know. Where you're getting your data. What are the APIs that you're using, what are the protocols, you know. In today's modern, you know, web connected, a lot of people think java script, JSON first. Nothing wrong with that. Some people think Odata first. There's pros and cons to both, but you need to make those decisions before you start building your app. In a lot of cases, you're consuming third party APIs. You need to make sure you get those APIs, actually play around with them a little bit, make sure you understand how they work before you build your app so you can actually understand the pros and cons to using that. When do you need your data? This is actually probably the biggest problem I see with most apps is that they don't think about when they need the data until the user's already there and waiting. So they wait until the user's sitting there and they pop up a nice busy dialoguer or the animation, and at that point it's kind of too late. The user's already sitting there impatiently and you have, you know, literally milliseconds to get their attention or they're going to leave. They'll close the app, they'll hit back, they'll do whatever. 3 So we're going to talk about that, thinking about when you need the app. How much data do you need and can you cache it. A lot of times, people don't think about what they can cache, and a lot of times they think, well, it's going to be too hard to implement, I don't want to go through all the hassle. It's really, really easy. But we're going to talk about that also. Sometimes you can cache stuff for hours. In the case of some apps, you want to cache it per run, or you may even cache it based on location. Look at 4th & Mayor, some of those type applications where it's okay to cache data that's around you, like people's addresses don't change that often. That may be something you can hold on to for a long period of time. When you those are things you need to think about. And then how long can that cache data live. Is there a maximum size? Are you willing to say, I only want to have one meg of cache. Whatever it is, after it overflows that, that's acceptable, or do you want to say, you know, I want to have a maximum age, like if I've been here within the last 30 days, the last ten hours, whatever it is. But you need to think about those while you're building your application. Just to give you a little context, a lot of what I'm going to be talking about today is around this specific application. It's called Microsoft Partner Info, and it's for Microsoft ISVs on the phone. So it has over 200 feeds of data. This data comes from RSS, from Twitter, from flicker, from all different kinds of data sources. Most of the feeds have over 12 items added to them per day, and we have about 2,400 items per day that we have to basically get to your phone somehow. And right now, if we were to just keep one day's data, it's five megs. That's not bad, but most people aren't willing to let you, you know, take up, you know, 150, 200 megs of data just for reading something on their phone. So you've got to think, you know, how do I pivot on this data. How do I determine what do I grab, when do I grab those type things. But this app was originally developed by someone else in [indiscernible] Microsoft. Because I've been in ISV for so long, I actually talked to one of the directors there and said, hey, can I help? Is there something here, you know, that I can actually help you guys with, because I wasn't very happy with the experience that I was seeing, and I was like, I can help you guys out. 4 So a lot of what we're going to talk about today are lessons that I've been learning as I've been applying this to this specific app. The biggest problems that I had with this app originally were start-up time. You know, when the user first downloaded the app, the initial data hit was very, very long in the order of 60 to 90 seconds. And that's assuming you were on WiFi. If you were on 3G, forget it. The user would have given up way before they ever got any of their data. So that, you know, initial launch time was something that wasn't thought about when the app was designed and that's something I'm going to go through. You really do need to think about that. The user responsiveness, every update was loaded on demand as a user pivoted, because there's just so many feeds. You don't want to go grab them all, and how do you determine which ones to go grab. And it's just a poor experience. When every time someone pivot, every time someone drills down, you go back to the internet. They're like, you were just there. You just got data. Why are you going back to this all over again. And then filtering data. You know, you don't want to overwhelm the user with data. You want to think about what's relevant. A good example is I have a feed of Twitter, you know. CES is going on, there's a whole bunch of Twitter streams going on. And then I have a feed from an RSS off of a blog. The Twitter's going to totally overwhelm whatever's happening in that blog. You're never going to see it because there are so many entries happening for Twitter that the user's going to just, you know, they're either going to miss it because there's so much data there, or they're not going to pay any attention to it because they just get overwhelmed. And a big part of what we've been doing with it for this app is actually looking at context and seeing, okay, there's an event going on. We should probably roll all that up, present it differently. So CES gets rolled up under an event. That way, it doesn't interfere with the rest of your data stream. So those are sometimes things that you should think about. And users are not very patient, you know. Cache first, and then load the data on demand. I'm sure everybody here's probably used a Twitter client, and you scroll up to the top and you do that force refresh. I want new data right now, and that's something that you should also think about. Sometimes users do know there's newer data there. Let me go get it. Don't make them exit your app and 5 come all the way back in in order to reload data. Sometimes it is as simple as that drag to the top type of thing. Sometimes you need to add a refresh button. Just think about it. So thinking about CRUD, when you go to build an app, you should think through your user scenarios and I tend to lump them into two big buckets. There's the core scenario. These are must-have, like we have to load data. We have to be able to display feeds. And then there's the optional, the nice to have. Like the ability to take all these feeds that are happening at CES and roll them up. It's nice feature, but what's that's going to cost? You need to go back and look. Like this particular app, just like you guys, I'm working on that on my spare time at home. And so I really have to stop and think. Okay. What's this going to cost in terms of time for me to implement, and then what about maintenance going forward. What's this really going to take to tune it, so deal with user feedback. How are you going to get the user feedback. All these types of things. You need to think about that data. And I think that's one thing that a lot of times I see developers go into apps and they start off with this great plan, and they haven't really categorized must-have versus what would be nice to have. And end up kind of floundering around and never finish their app. They never ship it. And some advice that I actually got here at XAPFest last year was ship. You know, no matter what, ship your app. You can't finish it, you'll never be done. Especially if it's a hobby type of project. You know, it's okay not to be done. If you're not a little bit embarrassed when you ship that first app, you probably waited too long. You know go ahead, ship it. Once you have something out there and you're getting feedback from people, you'll be a lot more motivated to add those new features, to go fix bugs, to actually go back and keep making your app better. That's one thing that I've done forever is just ship, ship, ship, ship. You know, you'll work it out. It's just as soon as you have actual users, you feel much more committed to the app. I mean, there's actually a couple of guys here that I know that I talked to a year ago who weren't shipping because, oh, it's not good enough. Haven't added this, I haven't added that. And now they have, and they have a very different perspective. Yeah, [indiscernible]. So we're going to go through each of the CRUD, the C-R-U-D, and I've basically 6 broken out each one of the titles to the slides based upon that. So thinking about create, you need to think about your initial data. That first time run experience is so vital to the user. You have nothing loaded. You have zero data there. What is the user going to get? Maybe they downloaded the app from the marketplace and they didn't launch it immediately. Now they're sitting on a plane, they're in airplane mode. They have no data access. What's that experience going to look like? There are a lot of apps in the marketplace today that if you do that, download it, turn on airplane mode and then go launch the app, you get a really poor experience. It's like a blank thing saying no data available. That's it. That's not a very good user experience. The user's probably going to tap, hold, uninstall right after that. They're not going to want to come back to your app. You need to think about what is that very, very first-time experience. In most cases, that initial data needs to be updatable. You need to think about, you know, where do I store that data, how do I get that data out. And we're going to go through some specific examples. But there are certain mechanisms in the phone, like you can bundle initial data with your ZAPP. You can put it as a content or a resource, but those are read-only. They're signed. So you can't update that. You can read it, but now what do you do with it? If you think, okay, look, I have my initial data here, but now I'm stuck, because I actually go and down load the data and now have to replace it. You can't do that within your ZAPP. So we're going to talk a little bit about that. And I can't stress this enough. Your initial assembly size really matters. You need to keep it as small as possible. The EXE that is actually loaded, everything that's in there is going to be jitted. So you need to think about, okay, if I keep this small, it's going to load a lot faster. As an example, this specific app, the MS partner bunch of bit maps, initial data feeds and things app. And it was taking three and a half seconds cover that up with a splash screen or something. putting them in an initial load assembly so that app, initially had a whole all just bundled into the base to load. Not bad. You could But by taking those out and we got the EXE up and running 7 as fast as possible, got the UI up and then got the data, we actually cut that down to less than half a second. So the makes a huge difference in the user experience for them to be able to get their data as quickly as possible. So really, keep it as small as possible. So to that, let's create a separate assembly. In the Microsoft Partner Info, I just created an assembly that I called initial data, and there's really, there's no code there. It's just data. That's all I have there. Because I know I'm only ever going to need this at initial run time. So why bother to put all this stuff in my base assembly? I have XML files there. Actually, I have JSON that is identical to what's going to come back from the server if the server's up. If I can reach it. If I can't reach it, I have something to fall back to. I hand it to the exact same routine. I don't need to special code anything, and the user has a good experience. So in my case, we have some systems that pull and get XML and some that get JSON. And so I just said fine, let's just take whatever it is we're going to get initially, put it within there. It's acceptable. You don't have to think, oh, I got to put this in a database and I got to be able to install the database. There's a couple people that I've talked to who got hung up on this, you know, I need a database, because that's what I'm going to have eventually once the app is up and running. No, you don't have to have a database. You just need to have somebody to get the data. You can gen the database. You can create the database. You can do it while the user is there. You just need some way to get that data to them. So think about compact format, keep it as small as possible. You could jeez up this data. You could do a lot of other things. In my case, it wasn't that big of a deal. This particular assembly is only 32K, and it cut that two and a half second off our load time. Huge difference. Yeah? >>: Is it the [inaudible]? >> Jason Short: >>: These are, it doesn't really matter. It could be either one. Question, please? >> Jason Short: The question was do I store these as resources or content? this particular example, I do store them as resources, but it really didn't In 8 matter, because I'm not using this assembly for anything but getting that data out and then I never touch it again. Question? >>: So just 32 kilobytes saved three seconds on every startup? >> Jason Short: >>: Every startup? >> Jason Short: >>: Yes. Or the first startup? >> Jason Short: >>: Yes. Every startup. Every startup. >> Jason Short: Because all of it was bundled into the core assembly before. Now that I'm separated it out into a separate assembly, it actually loads a lot faster. >>: And there's only 32K of data? >> Jason Short: Yeah. Well, what was stored in the base assembly was actually slightly larger than this, because we weren't storing it as JSON or XML. It was trying to encode the data as it's going to live on the drive eventually. But there was no reason for that so I just took it down to JSON. it's not identical data. Yes? You know. So >>: So talk a little bit more about what data is in this separate assembly and how current it is or if it gets old or how you would refresh that down the road. >> Jason Short: Sure. The question was talk a little bit about what lives here, how old is that data, and how do you refresh it later. I literally have a flag in the app that says go look at the isolated storage and check for a flag called we've run before. If the flag's not there, we've never run before. So then you set it. 9 As soon as you hit that logic, then I basically spin-off a background worker thread to go gen my actual data on the drive. That background worker thread actually goes out and pulls all this data and calls it just like as if it had come from the web. So this is just my initial data load. After that, all my normal caching rules apply. So if I say any data that we download from the web is valid for seven days, this will be valid for seven days after you initially launched. It's all time sensitive based on when the user runs. Now, in some cases, some of this data, like the feed model data, the list actual feeds, those don't change that often. We only check like every 30 days for those. Now, I take this data, I gen it on to the drive in the SterlingDB for that the that we use. But then I do actually kick off a background thread to say, hey, let's go check and see if there is an update, because you don't know when this ZAPP was published. It could have been published six months ago. So I don't treat this as it's the only data that we're going to have. I expect to throw it away as soon as possible. But if the user doesn't have WiFi, doesn't have whatever, you know, any type of data, we need to make sure they get a good experience. We need to make sure they get something there. Every data feed comes with a default article that says refresh to see the latest news. So when they hit a page, they don't just see a blank page, they see a little article that tells you, you know, refresh in order to get the most current news. >>: I guess just you refresh it, I point. I mean, I to republish your one quick follow-up. I guess when I was thinking about how was thinking about new users installing the app at some guess if you were going to refresh the data in here, you have ZAPP, is that true? >> Jason Short: Correct. The question is if you want to have a new, initial data load, you have to republish the app, absolutely. And that is something that we do periodically. We'll go back through and say, hey, we have, you know, a hundred new feeds have been added or whatever so let's actually republish the assembly. You can probably do other changes in the interim anyway. But if we didn't republish, this is going to get thrown away anyway, and we will actually refresh live. 10 So it's okay. It's just this is your good initial data set to get started from. And you're not actually using this for anything other than genning. you load this, and then you actually go out and you actually generate your database, you actually write your isolated storage files, you do whatever. don't use this for anything except that initial load. So You And another nice thing about having it as a separate assembly, you can actually create this assembly and let someone else edit it. Like in my case, I don't actually edit all the feeds. There's actually a person on the ISV team that actually does that. So I actually wrote him a Silverlight tool that he can use to go through and edit these and then just send me back. So then I just include it, rebuild. There we go, there's a ZAPP. You know, sometimes that's nice. This specific assembly, like I said, it saves over three seconds on startup each and every time you start up the app. But that initial data load, it saves over 30 seconds. >>: How does it do that? >> Jason Short: The question was how did it do that? It was when we used to start up, we used to have to go to the web in order to actually pull down that initial data feed. That was taking over 30 seconds in order to go get that data, because there's so many different feeds that it had to pull from. We're going to talk about that, like, round trips and how expensive all this stuff is. We'll get to that in a few more slides. But just because I didn't have to go make round trips and go out to the web, I saved over 30 seconds of that first user experience, which is so vital. You know, if the user doesn't like your app immediately, they're north going to come back. You need to make sure you think about that. Like I said, I'm literally taking this and using this for data generation. The code snippet here, this is what the JSON looks like. And if you were actually to connect to the live service that feeds this, it's identical. I literally just took a browser, connected to it, right click, save as, wrote to JSON. That's it. JSON is already a pretty sparse format, but you can do the same thing with XML. 11 You could do the same thing, you know. I've actually seen some apps where they do almost like screen scraping. They actually go get an HTML page and then they disassemble it and look for content on it. You could do the same thing. You just store the initial HTML file. You don't have already pre-split it apart and try to write a database. Because especially on the phone, the only database that I know of that has compatibility between the desktop and the phone is SterlingDB. So if you want to, you know, pre-populate a real database, and we're going to cover that much later down in the talk, you can actually do that with SterlingDB. So you don't have to do it this way, but this is actually just your easiest way. You treat it just like as if it was coming from the web. Sometimes you can actually use a seed algorithm. In one specific instance a gentleman that I was talking to had an app where he was actually pulling data from the web, but it was pretty predictable in terms of, you know, it was X and then a bunch of, you know, derivatives off of X kind of thing. So it was very algorithmic. So I'm like why don't you just take the first 10 or 15 values someone is going to use, pre-populate it. Build that, put it on to the drive and then you can actually start making your round trips later. So think about, you know, sometimes you do have things that are -- you know, you actually have to go get them live. Like Twitter, obviously, you're not going to be able to store a lot of data there because it's going to be so stale by the time the user installs. But you could always put an article there that basically says, you know, you're out of date. Please synch. Please get online. You can always give the user something. In this specific case, I'm just taking the JSON and building the database. This specific database is SterlingDB, which we'll cover later on down. But I literally just write routines like this. Generate the feed models. Take my SterlingDB container, loop over it, and go get, you know from the initial resource stream off of that JSON file, deserializes it just like as if it came from the web and then loop around and save it. So I didn't have to write an initial data gen routine and my data update from the web, then I have twice as many things to test, twice as many things to maintain. I don't like doing that. So to me, it just made perfect sense. I just want to write this once so it doesn't really matter where the data comes from. I'm going to use the exact same routines. Just encapsulate as much as 12 you can. Retrieve. And this is something that I'm actually surprised a lot of people, when you think about it, it makes sense. But a lot of times, you're just thinking, oh, it's like a desktop or a wireless. I'm over WiFi. But round trips on a phone are just flat-out evil. I mean, they are so slow, it's that you have very good bandwidth on a phone. Like you can download a megabyte per second. That's not the big deal. It's going to get that data, making the initial hand shake. Finding the server, doing all that initial round trip that's so expensive. It's not unusual when you're on 3G to see 250 millisecond network latency. That is very, very expensive. If you think about we have 200 feeds we pull in the Microsoft [indiscernible]. 200 feeds times 250 millisecond each DNS lookup, that's -- you're spending seconds just waiting on DNS at that point. So think about every round trip. If you can bundle that data up somehow. If you can make fewer round trip calls or hold a connection open for some period of time and continue to stream data, you have excellent bandwidth to get data down. But think about every round trip. And this is something that I see a lot of people make mistakes in their -they'll build view models or data models and they'll actually bind them to some service call. When they could have got the whole data in one chunk and stored it somewhere. But they'll actually go back and say, okay, orders and then order details. So get the order, and they know it has 12 order details. Then when the person goes to hit orders, he has to make a whole 'nother round trip. Try to collapse all that as much as you possibly can. Make it in one round trip instead of making, you know, a round trip for every single order detail. You'll see huge performance gains. And always think about your number of data sources. The more locations you're hitting, every time you hit a different service, it's not a point of failure. If you hit, like, we do 200 different feeds, any one of them could be down at any specific time. You have to plan for that, which means you have to build a lot more robust code. And I'm going to talk a little bit about how you mitigate that a little later. You need to think about that. Every service you connect to is a dependency. What happens if that service goes down? What happens if that service changes at the API? You really do need to think about those things. If your app is 13 broken because some third party changed their API, your users don't care. your app. They're going to blame you. It's So this is actually an example of in the IVS app, our initial load, we were grabbing 12 files from remote sources. By changing that to grab a single file that I aggregate every hour on a central server that we control, I actually made it 7.8 times faster. Just because of the network latency. Just the round trips, having to go look up each one of those locations. You know, you went from, I believe that's like six seconds down to under a second to be able to get that data. Huge difference from the user perspective. Same amount of data. It's just how long did it take to get it. This is what we're doing right now is consolidating at the server. Your server usually has a very high speed network connection. You know, your server usually knows everything that's happening. It can perform caching. It can perform filtering. Sometimes, you can actually say, hey, I have 200 feeds. Can you pull the most recent feed from that. You're actually saving each one of those 200 feeds from every single phone client hitting them. Now, you are actually paying that bandwidth cost. So there's always a trade-off there. But in a lot of cases, you can prebuild that data set, you can compress it, you can do other things to save your user bandwidth, to save them time. And in some cases, it makes sense to use a content delivery network. Content delivery networks are basically -- Microsoft runs one, Akamai. You know, there are several third parties. Amazon runs one. And it's basically where you put the content once and they take care of replicating it to Geo locations. They'll put a copy in Europe. They'll put a copy in Asia. They'll put multiple copies in the U.S. and then the person's phone grabs it from wherever the closest network is automatically, just through DNS. So you gain a faster response time for your user without having to actually go build ten servers all over the world. And sometimes, content delivery networks, especially like our feed list, for example, doesn't change that often. If my server were to go down, what happens to my app? Well, if I prebuild that and put it in a content delivery network, I don't have to worry about my server going down. It could be down. Everyone's going to grab it from the CDN anyway. Doesn't matter. My app will stay running. Everyone will have data. Maybe an hour out of date, big deal. 14 That's okay. >>: It's acceptable. Yeah? What does this cost? >> Jason Short: The question was, what does it cost. For some, it varies by provider. I can only speak to the ones I've used. I've used Amazon and I've used the Microsoft CDN. Microsoft CDN, you have to be an internal app in order to use it. Like you can't use it as a third party. Amazon, you can actually use it as a third party, and the price is, it's pennies per gigabyte. I mean, it is really, really incredibly cheap. For static content, in some cases, I've seen people where they'll pay Akamai -I believe the starting cost there is hundreds of dollars per month. So that may not be feasible for small apps. But with Amazon, you literally only pay for what you use. So, you know, it's very, very affordable. >>: Can I correct something that you said? access Azure can actually use the CDN now. The Azure, third parties who >> Jason Short: That's actually an excellent point. Ben just brought up a point, that Azure does actually have content delivery network now that period parties can use. And I forgot about that. You can actually declare static content within Azure to say I want this Geo replicated and you only pay per gigabyte of actually data that's downloaded. >>: 12 cents per gig. >> Jason Short: Thank you. Sometimes you can approximate what the customer wants. The data size is not as important as the round trips. In our case, we will actually take an aggregate, you know, let's say ISV feed for Australia, for example. We'll actually take all the feed data for Australia, pack it into one file, because people can get it quickly, and then filter client side to determine what to show and what not to show. There's, I believe, 17 feeds in Australia and if we were to give every person a separate feed for every one of those, we'd have to make a lot more round trips. Instead, we just smack it all together, let everybody download it and then filter in client side. It's not that big of a difference. A difference between you have 16 of the 17 is, you know, a kilobyte. You know, 15 it's why bother having all those round trips when you can actually just consolidate the data on the server. And sometimes it makes sense. Sometimes it doesn't. Depends upon your specific scenario. Lazy load your data. This has got to be the most important, if you don't take anything else away from this, take this away. Lazy load. When you look at, like, a list box in Windows phone, the list box itself is virtualized meaning if you see seven items on your screen, there are only seven plus or minus a couple dangling off the ends of your Silverlight XAML that's replicated in memory. Even if you have a million items, there's only those seven there, because you're actually windowing through that data content. But the data you bound to it, the data bound data is all loaded. So if you have a million items, all million are loaded. That's horrendous. I've seen a lot of apps that end up exceeding the amount of memory you can fit on a phone just because they're data binding. They're data binding absolutely everything to the list and they don't realize the fact that it's all being pinned in memory because you have it data bound to that list. I'm actually going to go through a couple code examples, ways you can actually implement this really, really easily. You can actually write your own very lightweight wrapper around IList of T. You don't have to implement everything that's in IList. List box actually only pulls three things that you need. You need a count, the total number of items that are in that list. That's so that you have a scroll bar that has a correct proportion. You know, if you're on item ten of ten, it shows you're at the bottom. If you're on item 10 of a million, it shows a little tiny dot there along the side. That you usually have somewhere anyway. You need an index of. So that it can actually request a specific item, like a user's jumping to it or the selected item index. And then you have to implement the this indexer. And that's where you actually do your loading and returning of data. And there are some tools to help with that. But it, like with SterlingDB, it actually already does a lazy loading for you, but we'll cover that when we talk about Sterling. Here's actually an example of the this indexer. And literally, right here where I'm actually -- in this little example, I'm just allocating the object there. You actually would go to disk and get the specific object. 16 Now, I talk to people and they say, well, but aren't I going to take an IO hit here? And the answer is yes, you are going to take an IO hit. So what do you do there? If the user -- if a normal behavior of your application is to scroll up and down wildly within your app, then you need to load everything. You know, there's nothing you can do about that, because you're going to be loading and unloading things constantly. But most applications don't have that user pattern. If your user pattern is we're going to rarely scroll down past 20 items, 30 items, wherever that number is, we only need to keep the last 20 items in memory then. You know, you can go grab, like if you're doing a Twitter feed type example, if you have 12 items on the screen and you think they might scroll back to get the next 12, load 24. That's okay. 24 is not going to kill your app. Loading a million will kill your app. So you can implement really easy here and I actually have a sample project that I actually implement this in that I'll give to [indiscernible] so he can actually attach with the notes. It's a real simple demo of how this works. Another thing that you can think about is refreshing your data in the background. Now, this is kind of a double-edged sword with me. Background agents are fantastic. I mean, I am so happy that they're there and I think that they have their place. But I think where a lot of apps abuse them is that they don't think about the fact that while I'm out and about and my phone is on my hip and I don't have WiFi, they're using my data. They're grabbing GPS. All that's expensive. It costs battery. So you really need to kind of balance that. You know, it's fantastic to have a background agent to update your live tile. Hey, we grabbed 20 new items, update your live tile so you have some more information to give the user. But you don't want to be, you know, trying to grab huge amounts of data while you're there. Sometimes it's enough to know there's new data, and the user launches your app and then you go get it. Sometimes that's okay. Sometimes you do say, oh, well, I'm going to grab, you know, the top ten posts of whatever's there. Don't try to grab the last 12 hours. If the user hasn't launched your app in the last 12 hours, they probably don't care about all that data. So think about how much data you're grabbing and when you're grabbing it. 17 The background agent data transfer will be turned off if the battery level gets too low. I'm sure you guys have all seen in Mango now, they have all the little heart sign on your phone when it goes into smart mode to save your battery. Once that happens, background agents don't run anymore. So to me, that means the phone team pretty much acknowledged that background agents suck battery. So as soon as the battery starts getting low, we need to turn these things off. So just be a good citizen of the phone and try not to be, you know, be the reason why that user's turning off their background data. And the last one here is something that is not hard, but a lot of people don't think about it. Adjust with your user behavior. If your app is a football app, and you're pulling down scores for Sunday, probably need faster updates on Sundays. You probably don't on Wednesday. You know, there's not a lot going on for football scores on Wednesday. It's okay to launch, say okay, it's Wednesday. I'm going to only pull data every 12 times I run or something. Because the one thing about the background data agents, you don't really get to schedule when it's going to run. You just get to register to run and you get to say, hey, I want to be a background agent. The OS calls you approximately every 30 minutes. You don't really have a lot of control. It's not like you could time it and say, you know, I'm going to run every 29.5 minutes. You don't have that level of control. So it's period Iraq. The OS will also look at how much background agents the user has on their system. If they have a hundred, they're not going to run all of them. They run some small portion of them. The next window, they run another small portion. Don't count on the fact you're going to be called the same number as on your phone, because different phones, people may have a different number of agents running. But if you have an app where people are using it every single day, you do need to go grab data. If it's something you're only using once a week, think about the fact I don't really need to go get this data, or I can pull it at slower intervals. You can also monitor your actual user's behavior. You can say, hey, this guy is, you know, he's on Twitter all the time. He's launching this app 22 times a day. He's checking stuff. I need to make sure I have the best user experience 18 possible and grab that data every time the background agent runs so when he launches, he's ready. Sometimes that's acceptable. But you wouldn't want to do that all the time. If the user is a hard core user, obviously they want that. They're will be to pay the battery hit for that. But if the user is only launching every two or three days, why bother pulling every single time you get run. Just think about it. >>: Can background tasks share storage with the main app? >> Jason Short: The question was can background tasks share storage with the main app. Absolutely. You have the exact same isolated storage. You have to build a separate assembly for the background agent, but you can share code. So you can actually build a third assembly that's kind of the shared code between the two and so your background agent calls the exact same code as what's running in your UI. There's inter-process communication. There's no way to say is my background agent running right now, you know, and while my app is running. But you can kind of work around that by, you know, save a flag when your app is actually running that says UI up. Or UI loaded. And when you actually close the UI, delete it. You know, that's okay. In this specific screen, you know, we have the behavior of the Facebook, Twitter, scroll to top, go grab new data. But we also added a refresh button there. And I added some analytics to look at that, and it's actually kind of amazing the number of users who hit refresh. I mean, don't assume that everyone knows that behavior of drag to top. You know, there's different cultural issues. There's different, you know, a lot of Windows phone users are not really that tech savvy. Sometimes they got it given to them by work or by their husband or spouse or whatever. So don't assume that all these behaviors we take for granted are, you know, common to everyone. Think about how can I allow other users to do this who may not necessarily find that. And I've seen a couple apps that, they actually put like the first time they run the app, they actually put a little notice up there to say hey, you can scroll to top in order to update. I think that's fantastic. Anything you can 19 give the user to let them discover your features better, then users are going to have a better experience, and that's what your app is all about. When you go to delete your data, you know, you need to think about the cache policy. Caching data on the phone is so vital for when you're in airplane mode, when you're offline, when someone's in a parking garage or when they're in a meeting that doesn't have WiFi, whatever. You know, you should think about, you know, when it's stale data too stale. A good example of this is addresses. If you're a 4th & Mayor type of app, addresses don't change that often. You could probably cache that data for a fairly long period of time before you absolutely have to go back and look it up again. If you're a NASDAQ stock exchange, you know that that data, if it's 20 minutes old, it's out of date. You need, you need to throw that data away. And you need to really decide how you're going to clean that data up. In most applications on the phone, you just delete the file. You know, if you have multiple files, you may time stamp them. You may use a naming convention, whatever. You just delete the file. In databases, typically, you don't want to do that, because deleting it actually causes a lot of expensive IO. It may try to reorder the pages, a lot of things. A lot of times you just update a flag to say it is deleted. But that complicates your logic. Now your lodger, every time you go to load an [indiscernible], say is it not deleted. So, you know, it can be a pain. But looking at some things like AGFX that we're going to talk about it, it actually makes this whole process -- you don't even have to think about it. It actually adds a nice facade on top of your object that you just say, I want this cache policy. This is how long you want it to live and you don't have to think about it again. Every time you try to get an object, it handles all of that in the background for you. So you should be conscious of it, but in most cases, you know, try to make your life easier. Use tools. Delete for background cleanup. This is actually, I think, a fantastic use of background agents. If you know that you can actually do things in the background, you free up the UI. You know, you free up the user experience. But sometimes, you have to think about this. Like I said a few minutes ago, you can't tell if a background agent's running at the same time as a UI. So if 20 you go through and delete a bunch of stuff but the UI just loaded and it showed it to the user and they click on it and blow up, that's not a good experience. So you should think about those types of things as well. How are you going to clean something up, when are you going to determine that something is cached, it's not valid. If you use something like AGFX, it's easier because it's arbitrating that stuff for you. But I think agents are a fantastic way to clean stuff up in the background. Delete. This is actually another one of my pet peeves. Sometimes, a user wants to start over. They screwed up. They got settings somewhere that they don't know what it is, you know, whatever. They haven't run your app in six months. You know, they're like, I just want to start over without having to uninstall the app and go regrab it again. You may put this in a settings page. You may put this in an about page. It doesn't need to be in their face all the time. But think about that, I want a clean experience. I want to start over. I messed up, you know. I've done a bunch of stuff and I don't know what I did or my kids played with my phone. You want to start over. Think about that. Sometimes you can just truncate the data. Sometimes you can actually go back to the initial data load assembly and say let me just re-gen all over again. Delete everything that's there, re-gen again. User has a clean experience, they're back off and running. I think that's something that a lot of apps don't have today. I actually had a to-do list app that for whatever reason, my pocket decided to launch one day, and I ended up with about, I think it was 10,000 items in the to-do list. And to delete them, it was six steps because I counted them because it was so painful I had to go through all of them. Even after the it deleted, it put it in a log area. And I had to go delete each one individually from the log area. I finally ended up uninstalling the app and reinstalling so I could get a clean experience. It's like so think about that. Think about users who have done things that they want to undo, but, you know, how do you wipe that out. Now we're going to go through some example data tools that you can use. Each one of these has its own use, its own scenario. AGFX is primarily a caching framework. But it also handles things for you like data storage and expiration. You just think in terms of your objects, and you say, this object 21 I want to have this cache policy. And you're done. Like you don't have to actually think about where's it stored, what's it named, how long is it going to live, all that type stuff. It does it for you. SterlingDB is a lightweight isolated storage database. It puts your objects in isolated storage. You don't have to think about what the file is called. You don't have to think about where is it stored and I have links to these later in the presentation, where you can go get them. And then SQLCE is a fully relational database. And it's built into Mango. It's a single file. So you have one file in your isolated storage, but you can't really just back that up and put it back. That's, you know, we'll talk about that a little bit. But, you know, that's something to think about. AGFX, data cache, data manager, it is a fantastic way to encapsulate your network API. There is an I data loader interface that you implement with AGFX, and then every object you can actually say, hey, here's how I'm going to go load this. In my specific example, I actually implemented two data loaders, one that actually goes to the web, and one that grabs from the local file. In some cases, it's really easy to just encapsulate that data for, like, in expression, as an example. Sometimes you want design time data. And you can actually, I just overrode that to say here's a static, you know, one, two, three, four. It's good enough for me to get something in design time so I can work with and I just implemented a static data loader. It also handles lazy loading for you, which is I think an under appreciated function of AGFX is the fact that when you load an object, you're not actually loading an object. You're loading the indexes for the object. So if you index two properties on an object that has a hundred, you only get those two loaded into ram until you actually grab the lazy load object. And then you actually get the full load. It goes to disk, it does everything. So the more indexes you add you, can actually really speed things up within your app. It also automates cache expiration for you. Every time you load the app and you touch one of these objects, it will automatically take care of going through and cleaning things up for you, which is fantastic. And it does it all in the background. You don't have to worry about data binding, because everything is lazy loaded. If something is currently pinned into memory, it won't delete it. 22 This is actually a fantastic framework. Here's actually, this is one of their diagrams from -- this is a code plex project, by the way. It's totally open source. You can download the code. There's also a new-get package for it to include it inside your application really easily and update. And it's out there on code plex. This is one of their diagrams. It has a generic load of T for on-demand load. So you can say when you go to load something, I want it now and it goes through and says, hey, we'll go get it for you from disk if you already have it, obviously, we don't need to go back to disk. It's very intelligent in that regard of how much it's caching in memory. There's also cache validation. You can customize the policies. You can override the way things are written. You can override the way things are loaded. It's very, very open. It's very, very flexible. It also has async handling. You can actually say, hey, I need the list of feeds, but I also want you to start updating this thing in the background. Give me what you got now so I can display something to the user and start a background fetch. Fantastic. This is what the class declaration looks like on the -- you have to implement an IDataLoader interface. In this specific -- this is my ParkList view model. And I basically implemented an IDataLoader for the ParkList context. Your ParkList is where you're getting the data from. And when you actually have the load context, the load context is what does the work. So I have this ParkList load contact so we'll actually go in and get the data or return the static data or it could go get it from disk or, you know, whatever you want to do there. But now you're totally encapsulated. When you want to get something, you just use this last line. I want a ParkList from my data manager. I have current context load the view. Go. You don't have to think about what about expiration, what if I don't have a local one, what if, you know, if it needs to go update it. It's all handled for you. And because all the objects underneath are observables, if it does get an update to it, you get a nice change notification. The UI knows how to refresh itself. Everything works very, very seamlessly. This is an example of what the cache policy looks like. When you're caching things in AGFX, there's a bunch of different pre-canned settings that you can set up. The cache then refresh is the one that I use most often. Which is basically give me back whatever's in the cache first and then go get whatever 23 it is you need to do. You can also say don't cache this thing ever, you know. Just I don't want it cached. Give me live data loads at all times. You can say valid from the cache only. This is actually fantastic when you have a specific feed or specific object that you want to make sure, like in between your background agent and the main UI, you want to make sure they're in synch. You can say I don't want cache data. I need it to be live at all times. Every time I hit this thing, make sure I have an absolutely current copy. Cached and refresh is what I use and then auto refresh. Auto refresh basically looks at the timeout that you have set there and says is this data older than what you said is valid. Yes? I'm going to go ahead and kick off a refresh in the background for you. It's going to call your ILoader. It's going to go back. You'll update everything, and because everything is again observable, your whole UI nicely updates. You don't have to worry about, oh, I got, you know, some new data. I need to go invalidate my UI. You don't have to do any of that. So just kind of a summary that the automatic cache is really, really a saver for almost any type of app. It is fantastic to just encapsulate whatever it is you're loading your data inside of there, and then you don't have to think about it. You implement it there, and you're done. The automatic expiration saves you a ton of work of having to walk through everything that's on your disk and say is this out of date, is it within date, especially if you have different contexts you want to apply to different objects. You just apply it at the object level and you're done. And the pattern of complexity here, it's not as simple as some other solutions, but it's doing a lot for you. It does take a little bit of work. They have a really fantastic tutorial on their sight of pulling weather data down from a national weather service somewhere. It is -- it's a lot of work to get set up, that initial wrap your brain around the problem, why am I setting this thing up. But once you get to the end of that tutorial, things start to click, and then you're like wow, now everywhere I need to touch this thing, it's just one line and I'm done. So it's really easy to test. It's really easy to automate. And once you get 24 the pattern down, it's really, really simple. than other solutions. It is a little bit more complex So now we're going to talk about SterlingDB. SterlingDB is another -- it's open source as well. It's done by Jeremy Likness at Wintellect. Yes? >>: So internally, this AGFX, does it have database or objects in the file system. >> Jason Short: Good question. The question is internally, is AGFX doing a database or a file system. It is an object store. So it's up to you. If you implement an object that encapsulates a feed, that's what gets cached. If you say, I don't want to cache that. I want to cache the individual entries, that's what gets cached. It's up to you when you implement the data loader, you say what objects you want to create out of that. It handles the actual storage of them. Underneath the hood, it is actually storing individual files in the isolated storage, but they're based by object types. So if you have ten objects that you're caching, there will be ten files. And it will also, if you say I want this thing to never expire, it will actually create another entry for you there. So it handles that under the hood, but it's not a database underneath the hood. Another interesting thing that it does there, the indexes that you create and the querying that you do is own LINQ so you don't have to learn SQL. You don't have to think about, you know, how do I get this data out. It's all LINQ expressions, which is kind of nice. Which I think I have a demo of that later on in here. If not, we can actually go through it afterward, if you'd like, some of the how do you query it and that type of stuff. SterlingDB, it's lightweight, it's in memory indexes, so it's very, very fast. It is not always a single file. The underlying implementation is, you know, you're supposed to be encapsulated from it. You don't have to worry about it. It also uses LINQ in order to do your queries. You don't need any SQL knowledge whatsoever. The kind of unique thing here is that all your indexes are also expressed as LINQ. So when you define an index, you have to actually say, here's my LINQ expression to generate that index off of your object model, which is very nice. 25 This is the only solution that I know of that has the same database for the desktop and Silverlight so you can actually gen your database using desktop Silverlight, take that and put it in your initial data load and all you have to do is copy it out of there, store it on the drive and load it. You're done. That's fantastic. Just for being able to say, hey, I got a same database here and I can use it in multiple locations. It also is the only one I know of that has a really clean backup API. You can call it, it's just dot backup, and you back it up to another file, and you can go store that in sky drive. You can go put that wherever you want. It's just a file at that point. So then your account with restore your is open it. really nice. user comes back, maybe they uninstall and reinstall. They have an you, something like that. You can actually say do you want to previous entries. Go get the database, put it down and all you do You just open it like a file and off you go, which is really, And just to make clear, I am not saying any of these are either/or. I combine them. Like I use AGFX with SterlingDB. I use AGFX for the data caching of the feeds. About when you break out the individual feed items, I store them in Sterling. So you don't have to have one or the other. You can actually combine these approaches. So this is an example of what the setup looks like when you go to register a database. You can actually customize these loggers. There's a Sterling default logger that only logs data when you're running in debug with an under the emulator but when you actually compiled a release, nothing gets logged so it's much faster. But you can actually customize that if you want to. If you want it to say I want to log this to a separate file but then I'm uploading to some service, you can do that. I've actually used this before with error reporting within an app, keeping track of analytics within an app. You know, you can use it for a lot of different scenarios. But all you have to do is basically, this is it. You call the engine activate and then you register a database. In this specific case, I'm using the isolated storage driver. You could even override that and create your own driver if you wanted to. You could create a 26 sky drive, you know, your own custom object there if you wanted to. really, really powerful. It's Every object that you store in Sterling is just POCO, plain old CLR object. You don't need to go decorate it with data member attributes and here's my index and here's the key and here's all these other things. This is literally one of the classes that I use. The only thing that is, you know, unique here is that you do have to have a default public constructer, because Sterling has to be able to allocate the object with nothing in it before it hydrates it. You can't have custom private constructers and things. Yes? >>: So is this equivalent to an entity framework type stuff? >> Jason Short: Good question. The question is, is this equivalent to entity framework. No. The entity framework is a mapping capability to say, I have data stored in this, but I want my entities to look different than that. They may be a subset of that. They may combine multiple entities. Entity framework is definitely much more powerful. There's no equivalent to entity framework on the phone yet. Entity framework also gives you nice things like change tracking and the ability to undo changes. You know, that's not on the phone yet. I haven't seen anything like that yet. That would actually be incredible if someone did do that. But it's not there yet. Even SQLCE today is linked to SQL. It's not EF. So this is what your indexes look like in Sterling. When you create a table, I'm literally just saying it's a feed group model and I want my key to be an INT. In my case, I'm actually using IDs for each feed to say what the primary key, if you want to think of it that way. In this case, I just say hey, I have a table definition and because this is all link, I just do the dot with index and you give it a name. You say what type it is, and then you write your lambda expression to say T dot category ID. That's my index. That's it. The very bottom one is actually an interesting way you can actually, where the A lambda true is basically is basically, I only ever want one instance of this object. Like in this case, it's just the app configuration, like how many feeds do they have, what do they want to do with them. I only ever want one of those. I don't want ten of them laying around. So you can just say true, which means basically always give me back the exact same entity. Which is 27 very, very handy. You can also define custom indexes using Tuples. So if you have a composite key would be the SQL analogy for that. If you have like an ID and a name that you want to use as a compound key, you can do that through Tuples, which is, they actually do give some very good examples of that, doing some more complex stuff, but I didn't want to put it in here. When you go to create your database, and you have an object and you want to save it, all you have to do is you call the object and you try to load it. If the object doesn't exist, you have a new one. Set whatever the options are that you want on it and you just call it dot save with the object. You don't have to go through each individual property and say, you know, I need to serialize this and serialize that. It handles all of it for you. You can actually decorate your objects. Let's say you have a computed field. Something like a sum of an order type of problem. You can actually say don't serialize this specific field, but you don't have to do that. That's up to you. This is what it looks like when you go to load. It's just a dot query and you write LINQ. Like in this case, I'm looking for a feed model where the index matches the group that I'm looking for. And I actually want to -- remember, I said they have a nice lazy value. It's literally just called lazy value. And you dot lazy value, get the value, and now you have the actual object fully loaded. If you just returned the select F here, you only have the Sterling instance of that object, which only gives you back the indexed fields. So if you have, you know, a hundred properties within your object, you only have two of them indexes, you only have those two loaded, which is fantastic for things like data binding, where if you know I'm going to use these four things to display in a list box, but everything else I only need to go get from disk later, you can actually create an index with all four of them so you get them immediately without having to touch the full object. This is an example of how you back up and restore, and you literally just call the Sterling database dot backup. Give it the object that you want, which is my specific database instance, which contains every table within my database. Give it like in this case, I'm actually backing it up to a memory stream and 28 then returning back the buffer. And then to restore it, you just call dot restore. You have to unload the engine and then just reinitialize it. Use Sterling engine and dot activate. Normally you do this, I didn't actually show this. I should have. Normally, you would do this dot activate and the actual register database during your app startup. So in your app, initialize, load, unload, those type things. That's where you normally put just little Sterling functions to say initialize, unload, those type of things. SterlingDB is all about LINQ. If you're not comfortable with LINQ which, you know, it can get complicated, you know, like this specific link Q query actually gives you that screen on the right, which is a long list selector with a jump, which if any of you ever tried to build that up by hand, it gets to be a real pain in the butt in order to figure I have a group and I have these grouped items and I need to create groupable items that are collections of these things. Single LINQ statement gives it back to you entirely. This was actually, I was talking to another developer that I met here at XAPFest and I was specifically having problems with the long list selector trying to get this grouped UI. To be performing, because I just had so many feeds I was loading. And he actually pointed me to his app that he had where he was using this, and I was like man, this is so much easier than what I was doing before, when I was trying to iterate over everything and built it up in memory and you just get it all in one shot. Really, really nice. Another -- I actually skipped over that. LinqPad. LinqPad is your best friend in these things. If you've never used LinqPad, LinqPad is a free tool for writing lambda expressions. You can use it against a SQL server. You can use it against a back-in database, but you can actually just write code and write the lambda expressions, execute it without having to go through the whole compile, edit, launch, you know, go through the whole cycle. Which I actually do have some demos we could do at the end of LinqPad if you guys are interested of how to actually generate this in LinqPad without having to go through the full cycle and load your browser and everything. Because LinqPad is a dot net app, you can actually just point to it your assemblies and it will load them. So you can actually call your real assemblies from LinqPad. It's fantastic. If you never used it, I highly recommend. I don't know why we haven't bought them yet. 29 I'm not going to go into too much detail on SQLCE. I actually be don't use SQLCE very often. Not because it's not a good product. Just because most applications on the phone are not that heavy for relational data. Most of the time, you have lightweight data. You have less than, you know, 10,000 records of whatever it is. You don't need a lot of join with join and join and join and you're trying to answer BI type logic on your phone. Normally, if you have anything like that, you're actually calling back to a server and the server's doing all that type stuff, talking to the server. Talking to a SQL back-in. But I wanted to include it here just for completeness so that everyone's aware. It is included in the phone in Mango and above. It's a single file database, but it's not the same as a desktop SQLCE app. So you can't use the same database and just copy it to your phone. It doesn't work. There are actually different formats. The one thing that just kind of grates me the wrong way is there's no schema version story for upgrades. So if you have V1 of your database and suddenly your app comes out with V2, the EXE gets upgraded, but your database doesn't. There's no automated way to say, hey, take my database from this, that version up to this version. You have to write all that code manually by yourself. Which can be complicated and you're going to end up writing a lot of SQL. And if you get it wrong, you just corrupted all your users' data. Which is very, very bad. Yes? >>: How about SQL light. >> Jason Short: The question was what about SQL light. There is an implementation, a C-sharp implementation of SQL light. SQL light's unmanaged code. But there is a C-sharp version of SQL light that you can use. Yeah. >>: I actually [inaudible] the wrappers. It was like a crappy wrapper and then there's another wrapper. I think it's on code plex. So it had bugs. >> Jason Short: My biggest problem with SQL light is you're also going to have to learn SQL. You're going to have to know SQL. And any problem that you're trying to solve in SQL, you're probably doing something wrong. You probably have too big of a problem to fit on your phone. >>: You also have to know SQL light SQL. 30 >> Jason Short: Well, there's always that. SQL light actually uses a different syntax than SQL server SQL, which is a whole 'nother -- we're not going to go there. I think it's interesting to note that the entity framework and LINQ are both query mechanisms. Like you use LINQ with entity framework. But on the phone, with SQL CE, you cannot write raw SQL. You can't say select star from table. It's not allowed. You have to use LINQ to SQL and build up with LINQ, which is something that confuses a lot of people, because it's like I've written all these SQLCE apps on the desktop and I can actually just execute a command. Why can't I do that on the phone? I don't know what the answer to that is. But you can't. Yes? >>: Is there a story of updating data [indiscernible], is that easier on SterlingDB? >> Jason Short: The question was, what about upgrading the data model in SterlingDB. If you've modified your objects, it is up to you to maintain that. And normally, the way I do that is I'll have like application configuration B1 is what I'll called the object. So if I'm going to modify that object, I treat it like an interface. You can't modify it. I create a new one and I call it application interface V2. And then you just have to loop through and say load the V1. Save as V2. As long as you provide an assignment mechanism in your code, you don't have to migrate the data. But you do have to think about it. It is true. It's not handled for you automatically. There's no solution that I know of that handles it for you automatically. Same thing with serializing even just dot net objects in general. If you serialize them and reload them, if you've changed anything, you have to handle that yourself. Another interesting thing to note with the phone is ADO.net is not supported. So there are a lot of desktop developers that come to the phone and think I already know how to write data apps because I use ADO.net. I know how to allocate objects this way. I know how to load data sets. None of that exists. So you can't use, you know, data readers and data writers. There's none of that type of stuff there. You have to work to LINQ to SQL. That is your only choice. Another thing with SQLCE, it's fairly rough developer UI experience, compared to the desktop. On the desktop, you have a nice UI, you can say I want to 31 create a table. You can get a nice table designer, you can drag things over. You get none of that with the phone right now. Hopefully, they're working on that for the next version. There's no designer, there's no EF layout tool. There's no way to build up that type of stuff. You have to actually build it from hand. And it is LINQ to SQL, not entity framework. Entity framework allows you to map your entities across multiple tables. LINQ to SQL is a much lighter weight, simpler. There's one object per table. So if you have ten tables, you have ten objects. That's what you get. You have ten columns on each one of those, you have ten properties. It's a much simpler mapping, but you end up having to manage a lot of that stuff yourself. So in summary, which one of these is best? I get asked that question. You know, which one is best, and it's like a lot of things, you know, in the software world. It depends upon your application. You know, AGFX, I think, is fantastic. If your server uses a rest API, they actually provide a web request object that makes the whole process of allocating an HTTP reader, going and connecting and all that. He handles all that for you and he just hands you the raw output of what happened. So that's fantastic. If you have a real simple rest API, it's brain dead simple to go implement. For small data applications where you're generating data, like note applications or the user's actively doing something, I think SterlingDB is fantastic. I've actually run SterlingDB with up to 14 million entries in the database and had no performance issues. No memory issues. I was actually very, very impressed that you could actually do that on the phone and not have a bunch of problems. And if you're doing heavy relational data, like you have an existing data model in an enterprise where they have orders and order details or manufacturing scenario where you have salesmen and you're actually just trying to get that data to the phone and they need to be able to access in the field, relational data is the only way you're going to do that unless you're willing to invest a lot of time in building facades and building interfaces for that. You know, it is sometimes easier just to say I have the same structure on my server as I do on my client. And there are some tools out there to do synchronization from SQL server to your client. All of them are pretty rough, I would say. Like all of them that 32 I've tested, I wouldn't use. So I can't actually endorse any of them. But I'm sure that's going to come in time, actually synching, you know, relational data. I'm sure it will get there. So these are the links to AGFX, SterlingDB and LinqPad. Like I said, LinqPad is a free tool. LinqPad is not open source, but it is a free tool. He does have a premium version, like it actually will give you ought to complete and nice dropdown list, but you have to pay for that if you want that. But all the base functionality is all there. If you want to actually query an O-data service and actually write link against it, it's all basically built in, you don't have to pay for any of that. It's just if you want nice intelli-sense and things like that, which, you know, I'm dependent upon so I paid for it. The AGFX is built by -- it's just a couple guys, Shawn Wildermuth, I think, is the main guy who works on it, but he's very responsive. I've submitted bugs to him and patches and he's taken stuff and rolled it in. It's fantastic. SterlingDB is, like official project of it does have a desk I think that's very I said, Jeremy Likness and Wintellect. But it's not an the company. It's, you know, a side project from him. But stop Silverlight version and the Windows phone version. So handy in a lot of scenarios. So when you're building your apps, always remember CRUD. Think about how you're going to create your data, where is it going to come from, where you're going to, you know, store this data. Think about how do you retrieve data, how do you query the data. How are you going to update the data and how are you going to delete it. It's a real simple acronym to remember as you're going through and thinking about your application. You know, what are you going to do here. I personally think, you know, be a good phone citizen. Your application is -that is the user's experience on the phone. If they have a crappy app on their phone, they think they have a crappy phone. That's not the case. You know, the phone's fantastic. Because I'm sure all you guys know, it comes down a lot of times to apps. And you need to be conscious of device memory. You need to be conscious of 33 battery and you really need to think about those things while you're building your app. Don't build something that's going to give of the phone a bad rep. Always ensure you have a good user experience and remember that they're the reason why your app is there. If you build something for yourself, fantastic. Load it, you don't ever have to sell it or put it up in a store or whatever. But if you're building stuff for other people, you know, you need to think about what their needs are, their desires. And any questions? One thing I would like to bring up is that if you guys want more detailed talks like when I originally approached the XAPFest guys about doing this talk, I was actually going to go into a lot more code and much more lower level how do you store this data. But as I built that slide deck and I showed it to someone, he's like I have no idea what you're talking about. So I was like okay, that's a good reality check. I need to back up and set the stage first before I could go any deeper. So if you guys are interested in more in-depth talks about any of these things, talk to the XAPFest sponsors. Talk to us. You know, we're very open to doing whatever it is, you know. It's a community-driven thing. Whatever you guys want to hear, we'll do more of. >>: Are you saying you want to come back? >> Jason Short: I'm here every time anyway. talking. You know, doesn't faze me. >>: So I don't mind coming and Request for your next is more codes. >> Jason Short: More codes. Well I have some code if you guys want to come look at stuff after we're done recording. I actually have a sample projectile give to [indiscernible]. He can put up on the blog that shows how to implement the scrollable lists with a virtual data set. It loads a million items and you can scroll through them like literally you see no hiccups. You see no anything. And we can go through other stuff. >>: Yes? The next question, is this going to be available for download somewhere? >> Jason Short: Yes. This is recording right now as we speak and it will be 34 available on resonant, I believe. >>: I think like we have two, three days turnaround. >>: And the samples will be there also. >> Jason Short: The samples, I don't know. I will post it. Can you post the samples on there? >>: We'll have the [indiscernible] and you'll get it. >>: Great. >> Jason Short: And if the samples change over time, which I'm sure they will, I'm also planning on doing some of these samples on my blog so the infinitecodex.com site, I have a blog there. I update on just random junk, whatever it is I'm working on at the time, but I'll also be posting a lot of this stuff on data virtualization, because it's just very interesting to me. >>: So there's some question of how about some of the Telerik controls for Windows? >> Jason Short: Good point, the question was what about Telerik controls for the Windows phone. Telerik actually implements the virtualization for you so you can give it a list of data and data bind and it builds that little wrapper for you. So it doesn't keep everything loaded into memory. Telerik is actually the only controls that do that. Like most of the other vendors presume you know what you're doing. And if you hand them a million items, you really did want all million items intent into memory. So Telerik actually does have some very good controls. I've actually played around with them and I was very impressed with memory footprint and how they actually managed to virtualize around what you were doing. Yes? >>: So I'm curious, is there a graph that says how big your ZAPP file is and how long it's going to take for it to load? Is there like a tipping point? So if you have big slash screen images, that's going to cost two and things like that I'm guessing? 35 >> Jason Short: The question is, is there some graph or some algorithmic way to determine what your startup time is going to be based upon your ZAPP size. No. It's not about the ZAPP size. Remember, the ZAPP is a nice convenient package that the marketplace hands to your phone, but your phone explodes that and puts it in the isolated storage. So it's not actually stored as a zip file. That's all zaps are is zip files. So it actually does unzip it and store it there. From what I can tell, the big determining factor in your launch time is the amount of code, the code path that you take, and what you touch. Because it's jitting, right. I mean, it's all dot net code, so it has to walk that path and jit everything and do the security checks, you know, do absolutely everything before it starts the execution path. So the more objects you try to touch in your start screen, if you touch absolutely everything in your app object, you touch every screen you have in your app and you try to, like, preset the IDs or something like that, that's going to take a heck of a lot longer to start. Try to minimize that startup path through your app. The app object, the application object so that you're only touching the minimum number of things you need to in order to get the screen up. That seems to be the biggest limiter that I've seen. Yes? >>: I was going to add on to this, because the app performance, separating out all your code, whether it's pages or images into different assemblies will give you a big load increase. Because what the phone does, to load the app, it will load only the assemblies it needs so if Jeff Wilcox blogged about this. So he has an about page. He puts all of that in a separate project. And all that stuff isn't loaded into memory when an app loads. >> Jason Short: That's actually a very good point. >>: The images and everything like that, you want to do the same thing that he was doing with initial data. >> Jason Short: Yeah, Jeff Wilcox has a really good blog post about looking at your app and seeing things that you rarely touch, separate them out. Like he takes his about screen, you know, very few users ever go to the about screen. 36 Get that out of there. Put it in a separate assembly so that it doesn't have to be jitted. It doesn't have to do the security check, doesn't have to do all that stuff on it. And only load it when you need it. You can still reference it. It's not reference. You can still hard code the references. You don't have to do reflection loading. You don't have to do any of that. Putting it in a separate assembly, you've gained the benefit of not having to load it. Yes? >>: I'm thinking about securing the [inaudible] is there any way to like [inaudible] encryption for you on SterlingDB or something. >> Jason Short: The question was what about security of the data or encrypting the data. All applications on the phone are already in their own isolated storage. No one else can touch your specific application. So you don't have to worry about another app on the phone. Although there are some tools you can put at your desktop to get at the isolated storage data. No, none of them actually handle the encryption for you. With SterlingDB, you can actually customize a serializer to say I want to call this first. And, you know, do some bit masking or whatever it is you want to do to obfuscate the data or encrypt the data. You can also implement G-zip there or whatever you want to do. SQLCE does have a password type option where you set a password on the file and it encrypts everything with that. I believe it's just using a simple SHA over some algorithm to -- it's using that as a key to actually encrypt your data. But as far as I know, there are no built-in encryption for the file IO. You have to do that yourself. >>: There is a method in Mango now to do the encryption. Mango has an approved way to do encryption on the phones without storing any caches or any Ks from the server to separate the data. I don't remember the space or the method, but I [indiscernible] about it. >>: A topic for another talk? >>: Yes. >>: [inaudible]. I was just thinking that an hour and a half, and I just 37 wondered a pin number or something I can secure those. [inaudible] you might want to have something. [inaudible] or higher, >> Jason Short: That's an excellent point. The point was that if you're touching sensitive data, pin data, those type things you, you may need to encrypt it for legal reasons or for corporate reasons, and as far as I know, all of the encryption algorithms in dot net are not available on the phone and I know that I had saw in the discussion list a while back when SQLCE was first coming out with Mango that SQLCE on the desktop, you can change the encryption algorithm by setting something in the connection string. You can't do that on the phone. It's not available. There's the built-in encryption, whatever that is, and that's all you got. Like you can't change it. I don't know what the specifically algorithm is that they use, but you only have one. That's all you have right now. >>: Is this [inaudible]. >> Jason Short: The question is does the phone support HTTPS. Absolutely, yes. Although it does not support NT land manager authentication which I found kind of puzzling. So if you need to authenticate to the domain, you can't. There's no code way to do that. Yes? >>: With SterlingDB, so you have a database schema update between version one and version two. Does it just support adding new stuff, or can we just like really go to town or you really shouldn't do that. How do you know that you're operating your version just in case you had a major schema change. >> Jason Short: The question was about SterlingDB and schema changes across application versions, like maybe major versions. The way I do it is I literally name my object application config V1, and basically, I treat that like it's chiselled in concrete. There's no changes to that file. If I change that file, it's got to be called application config V2. But I will always build an assignment operator to let me assign a V1 object to the V2 object and then I'll take care of, you know, hey, this property moved to here, we changed its name or we added these new things. When I go to load the object, I actually store in my app config what the last run version of the app was. And I compare that against the current version of the app. 38 And I'm running a different version than what ran last time we ran, I may need to do some upgrade logic or I may need to upgrade things. >>: You upgrade the whole database or just on the fly you read from old storer into new storer and then save? >> Jason Short: I actually have an upgrade class that I built that I actually just put a K statement in there that says what was the last version or what, you know, whatever the last version was that they said and what's my logic to get to the next -- the current, major version. And I just put it all in there. And, of course, that's in a separate assembly. >>: What if someone has like one and then three? >> Jason Short: Then basically I add the logic to say load from one to two and then go from two to three, yeah, because I always make sure that I'm only going N and N minus one in my assignments. I don't want to have to assign version one to version five objects that just, you know, it's bad compat problems. But you can keep those old, you know, back compat, you know, the V1 versions of those objects, you can move them out to a separate assembly. If you never use them, they never get loaded. >>: So even additive changes, you would add a new version, like if you add three columns and you have four column, you would ->> Jason Short: I treat them like they're concrete. They're fixed. Yes? You can't change them. >>: Would you like to see the functionality of AGFX and SterlingDB built into a platform or do you think they should remain, functionally remain separate? >> Jason Short: That's an excellent question. The question is do I think AGFX and SterlingDB should be built into the platform. Yes, I do think that we need an object store. Some sort of no SQL type storage that provides caching built into the platform. Of course, I would also like to see an isolated storage object that lets me write to my sky drive without having to actually go all this off stuff either. But I think that that is a -- it's a more difficult problem when we're trying to solve a general purpose for every developer who might possibly use a 39 platform rather than saying you have to go make these specific code changes to support us. Now you've already got it into the mindset. You're willing to spend that commitment. To say any object in your Silverlight could be stored and cached, I think that's a little harder. But I think it's doable. I think you could definitely say here's the pattern. Here's the way you extend it. And here's the best practices and now it's a DLL that's built into the system. I totally think that we could do that. I would like it. I think that's it. Thank you very much.