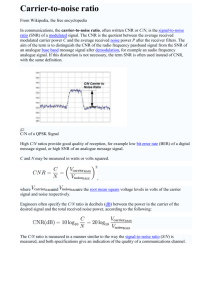
PyiPhyoMaung_FYP
advertisement

SIM UNIVERSITY SCHOOL OF SCIENCE AND TECHNOLOGY PERFORMANCE ANALYSIS AND COMPARISON OF ADAPTIVE CHANNEL EQUALIZATION TECHNIQUES FOR DIGITAL COMMUNICATION SYSTEM STUDENT : PYI PHYO MAUNG (M0706331) SUPERVISOR : DR LIM BOON LUM PROJECT CODE: JUL2009/ENG/003 A project report submitted to SIM University in partial fulfillment of the requirements for the degree of Bachelor of Electronics Engineering May 2010 ______________________________________________________________________________ ABSTRACT The objective of this project is to study, analyze and compare on three different types of adaptive channel equalization techniques such as Least Mean Square (LMS), Recursive Least Square (RLS) and Gradient Adaptive Lattice Algorithm. This report consists of four main chapters which are Chapter 2 LMS algorithm, Chapter 3 RLS algorithm, Chapter 4 Gradient Adaptive Lattice algorithm and Chapter 5 Comparison Study. Much of these chapters are concerned with a detailed mathematical analysis of three algorithms. Mathematical analysis is a very important tool, since it allows many properties of the adaptive filter to be determined without expending the time or expense of computer simulation or building actual hardware. In this project, simulation and analysis use the MATLAB software. Simulation is often used as a method to verify the mathematical analysis. The goals of the analysis in these chapters are to determine the rate of convergence, misadjustment, tracking, robustness, computational complexity and structure of the algorithms. -2- ______________________________________________________________________________ ACKNOWLEDGEMENTS Firstly, I would like to express my sincere and heartfelt appreciation to my project supervisor, Dr. Lim Boon Lum for his exceptional guidance, invaluable advice and wholehearted support in matters of practical and theoretical nature throughout the project. His constant time check and meet ups had certainly motivated me in the completion of the project. Throughout my report writing period, he provided encouragement, sound advice, good teaching, good company, and lots of good ideas. The completion of the Final Year Project would not be possible without his excellence supervision. Secondly, I am indebted to my employer, Institute of Microelectronics (A*Star) for allowing me to further study towards Bachelor Degree. I owe a favor to my reporting officer; Dr. Selin Teo and colleagues for allowing me to take time off and exam leave from work during the course of study. Lastly, I would like to thank all the lectures and friends in UniSIM and also to my parent, my wife and my daughter who have given their fullest support me throughout this endeavor. -3- ______________________________________________________________________________ TABLE OF CONTENTS ABSTRACT .................................................................................................................... - 2 ACKNOWLEDGEMENTS ............................................................................................ - 3 TABLE OF CONTENTS ................................................................................................ - 4 LIST OF FIGURES ........................................................................................................ - 6 LIST OF TABLES .......................................................................................................... - 8 CHAPTER 1 ................................................................................................................... - 9 Introduction ..................................................................................................................... - 9 1.1 Background ................................................................................................. - 9 1.2 Review of Literature ................................................................................... - 9 1.3 Objective and Scope ................................................................................. - 12 CHAPTER 2 ................................................................................................................. - 13 The Least Mean Squares (LMS) Algorithm ................................................................. - 13 2.1 Introduction ..................................................................................................... - 13 2.2 Derivation of the LMS Algorithm .................................................................. - 14 2.2.1 Basic Idea of Gradient Search Method .................................................... - 14 2.2.2 Derivation of the LMS Algorithm ........................................................... - 16 2.2.3 Definition of Gradient search by Steepest Descent Method .................... - 21 2.3 Simulation Results .......................................................................................... - 25 2.3.1 Simulation Model..................................................................................... - 25 2.3.2 Channel Model 1 ...................................................................................... - 26 2.3.3 Channel Model 2 ...................................................................................... - 28 2.3.4 Channel Model 3 ...................................................................................... - 30 2.3.5 Channel Model 4 ...................................................................................... - 32 2.3.6 Observation & Analysis ........................................................................... - 34 CHAPTER 3 ................................................................................................................. - 36 The Recursive Least Squares (RLS) Algorithm ........................................................... - 36 3.1 Introduction ..................................................................................................... - 36 3.2 Derivation of the RLS Algorithm ................................................................... - 37 3.3 Simulation Results .......................................................................................... - 46 3.3.1 Channel Model 1 ...................................................................................... - 46 3.3.2 Channel Model 2 ...................................................................................... - 48 3.3.3 Channel Model 3 ...................................................................................... - 50 3.3.4 Channel Model 4 ...................................................................................... - 52 3.3.5 Observation & Analysis ........................................................................... - 54 CHAPTER 4 ................................................................................................................. - 56 The Gradient Adaptive Lattice (GAL) Algorithm ........................................................ - 56 4.1 Introduction ..................................................................................................... - 56 4.2 Derivation of the Gradient Adaptive Lattice Algorithm ................................. - 57 4.3 Simulation Results .......................................................................................... - 74 -4- ______________________________________________________________________________ 4.3.1 Channel Model 1 ...................................................................................... - 74 4.3.2 Channel Model 2 ...................................................................................... - 76 4.3.3 Channel Model 3 ...................................................................................... - 78 4.3.4 Channel Model 4 ...................................................................................... - 80 4.3.5 Observation & Analysis ........................................................................... - 82 CHAPTER 5 ................................................................................................................. - 84 Comparison Study......................................................................................................... - 84 5.1 Simulation Results .......................................................................................... - 84 5.2 Observation and Analysis ............................................................................... - 88 5.3 Summary ......................................................................................................... - 90 CHAPTER 6 ................................................................................................................. - 92 Project Management ..................................................................................................... - 92 6.1 Project Plan and Schedule ............................................................................... - 92 6.2 Project Tasks Breakdown and Gantt chart ...................................................... - 94 CHAPTER 7 ................................................................................................................. - 96 REVIEW & REFLECTIONS ....................................................................................... - 96 7.1 Skills Review .................................................................................................. - 96 7.2 Reflections ...................................................................................................... - 97 7.3 Conclusions ..................................................................................................... - 98 References ..................................................................................................................... - 99 Appendix – A .............................................................................................................. - 101 Signal-Flow Graphs .................................................................................................... - 101 Appendix – B .............................................................................................................. - 102 Abbreviations .............................................................................................................. - 102 Appendix – C .............................................................................................................. - 103 Principal Symbols use in LMS ................................................................................... - 103 Principal Symbols use in RLS .................................................................................... - 104 Principal Symbols use in GAL ................................................................................... - 105 - -5- ______________________________________________________________________________ LIST OF FIGURES Fig-2.1 Block diagram representation of the LMS algorithm....................................... - 13 Fig-2.2 The LMS Adaptive Filter ................................................................................. - 16 Fig-2.3 Block Diagram of Adaptive Equalizer Experiment ......................................... - 25 Fig-2.4 Learning Curve of Channel Model 1................................................................ - 27 Fig-2.5 Channel Model and Equalizer Response of LMS Algorithm (Channel Model 1) .. 27 Fig-2.6 Learning Curve of LMS Algorithm (Channel Model 2) .................................. - 29 Fig-2.7 Channel and Equalizer Response of LMS Algorithm (Channel Model 2) ...... - 29 Fig-2.8 Learning Curve of LMS Algorithm (Channel Model 3) .................................. - 31 Fig-2.9 Channel and Equalizer Response of LMS Algorithm (Channel Model 3) ...... - 31 Fig-2.10 Learning Curve of LMS Algorithm (Channel Model 4) ................................ - 33 Fig-2.11 Channel and Equalizer Response of LMS Algorithm (Channel Model 4) .... - 33 Fig 3.1 - Block diagram representation of the RLS algorithm ..................................... - 36 Fig 3.2 – Transversal filter with time-varying tap weights ........................................... - 38 Fig-3.3 Learning Curve of RLS Algorithm (Channel Model 1) ................................... - 47 Fig-3.4 Channel and Equalizer Response of RLS Algorithm (Channel Model 1) ....... - 47 Fig-3.5 Learning Curve of RLS Algorithm (Channel Model 2) ................................... - 49 Fig-3.6 Channel and Equalizer Response of RLS Algorithm (Channel Model 2) ....... - 49 Fig-3.7 Learning Curve of RLS Algorithm (Channel Model 3) ................................... - 51 Fig-3.8 Channel and Equalizer Response of RLS Algorithm (Channel Model 3) ....... - 51 Fig-3.9 Learning Curve of RLS Algorithm (Channel Model 4) ................................... - 53 Fig-3.10 Channel and Equalizer Response of RLS Algorithm (Channel Model 4) ..... - 53 Fig 4.1 - Block diagram representation of the Lattice Structure................................... - 56 Fig 4.2 - Forward Prediction Error Filter ...................................................................... - 58 Fig 4.3 - Backward Prediction Error Filter ................................................................... - 60 Fig 4.4 - Single Stage Lattice Predictor ........................................................................ - 63 Fig 4.5 - Multistage Lattice Predictor ........................................................................... - 64 Fig 4.6 - Desired-response estimator using a sequence of m backward prediction errors ... 71 - -6- ______________________________________________________________________________ Fig-4.7 Learning Curve of Lattice Algorithm (Channel Model 1) ............................... - 75 Fig-4.8 Channel and Equalizer Response of Lattice Algorithm (Channel Model 1).... - 75 Fig-4.9 Learning Curve of Lattice Algorithm (Channel Model 2) ............................... - 77 Fig-4.10 Channel and Equalizer Response of Lattice Algorithm (Channel Model 2).. - 77 Fig-4.11 Learning Curve of Lattice Algorithm (Channel Model 3) ............................. - 79 Fig-4.12 Channel and Equalizer Response of Lattice Algorithm (Channel Model 3).. - 79 Fig-4.13 Learning Curve of Lattice Algorithm (Channel Model 4) ............................. - 81 Fig-4.14 Channel and Equalizer Response of Lattice Algorithm (Channel Model 4).. - 81 Fig-5.1 Comparison Learning Curve of Channel Model 1 at SNR 20dB ..................... - 84 Fig- 5.2 Equalizer and Channel Model 1 response at SNR 20dB ................................. - 84 Fig-5.3 Comparison Leaning Curve of Channel Model 2 at SNR 20dB ...................... - 85 Fig- 5.4 Equalizer and Channel Model 2 response at SNR 20dB ................................. - 85 Fig-5.5 Comparison Learning Curve of Channel Model 3 at SNR 20dB ..................... - 86 Fig- 5.6 Equalizer and Channel Model 3 response at SNR 20dB ................................. - 86 Fig-5.7 Comparison Learning Curve of Channel Model 4 at SNR 20dB ..................... - 87 Fig- 5.8 Equalizer and Channel Model 4 response at SNR 20dB ................................. - 87 - -7- ______________________________________________________________________________ LIST OF TABLES Table- 2.1 Mean Square Error of LMS Algorithm ....................................................... - 34 Table- 2.2 Rate of Convergence of LMS Algorithm .................................................... - 34 Table- 3.1 Mean Square Error of RLS Algorithm ........................................................ - 54 Table- 3.2 Rate of Convergence of RLS Algorithm ..................................................... - 54 Table- 4.1 Mean Square Error of GAL Algorithm ....................................................... - 82 Table- 4.2 Rate of Convergence of GAL Algorithm .................................................... - 82 Table - 5.1 Mean Square Error of LMS, GAL & RLS Algorithms .............................. - 88 Table - 5.2 Number of Iterations to Converge in LMS, GAL & RLS Algorithms ....... - 89 Table - 6.1 Project Tasks Breakdown ........................................................................... - 94 Table - 6.2 Gantt chart .................................................................................................. - 95 - -8- ______________________________________________________________________________ CHAPTER 1 Introduction 1.1 Background Many problems encountered in communications and signal processing every day. These are removing noise and distortion due to physical processes that are time varying or unknown or possibly both. These types of processes represent some of the most difficult problems in transmitting and receiving information. The area of adaptive signal processing techniques provides one approach for removing distortion in communications, as well as extracting information about unknown physical processes. A short consideration of some of these problems show that distortion is often present regardless of whether the communication is conversation between people or data between physical devices. One of the first applications of adaptive filtering in telecommunications was the equalization of frequency-dependent channel attenuation in data transmission. The frequency response of most data channels does not vary significantly with time. However, this response is frequently not known in advance. Hence, it is necessary for the data transmission system designer to build in the means to adapt to the channel characteristics, and perhaps also track time-varying characteristics. 1.2 Review of Literature The purpose of adaptive channel equalization is to compensate for signal distortion in a communication channel. Communication systems transmit a signal from one point to another across a communication channel, such as an electrical wire, a fiber-optic cable, or -9- ______________________________________________________________________________ a wireless radio link. During the transmission process, the signal that contains information might become distorted. To compensate for this distortion, we can apply an adaptive filter to the communication channel. The adaptive filter works as an adaptive channel equalizer. It monitors channel conditions continuously and to readjust itself when required so as to provide optimum equalization. System Input x Channel System Output Adaptive Filter y Error e(n) Σ + Desired Response d(n) Delay Version Fig 1.1 - Block diagram representation of Adaptive Channel Equalization In general, an adaptive channel equalizer has a finite number of parameters that are adjusted by adaptive algorithms to optimize some performance criterion. An adaptive equalization filter adjusts to minimize the mean square error between actual and desired response at the filter output. In a wireless environment, the channel model is highly dependent on the physical location of the reflectors. As objects move, the channel model must change accordingly. In particular, if either the transmitter or receiver is mobile, every channel coefficient will gradually change, and the adaptive channel equalizer must change accordingly. - 10 - ______________________________________________________________________________ The most common adaptive algorithms which used in channel equalizer are Least Mean Square (LMS), Recursive Least Square (RLS) and Gradient Adaptive Lattice Structure. Different algorithms have different performances and some disadvantages. In the final analysis, the choice of one algorithm over another is determined by one or more of the following factors: 1. Rate of convergence 2. Misadjustment 3. Tracking 4. Robustness 5. Computational Complexity 6. Structure The rate at which an adaptive filter converges to the system is important, particularly in situations where the signal statistics are varying in time. Unfortunately, speed of adaption is typically inversely proportional to computational complexity. Misadjustment measures the offset between the actual signal and the signal produced by the adaptive filter. Misadjustment is usually inversely proportional to both speed of adaption and computational complexity. When an adaptive filtering algorithm operates in a non-stationary environment, the algorithm is required to track statistical variations in the environment. The tracking performance of the algorithm is influenced by rate of convergence and the steady-state fluctuation due to algorithm noise. - 11 - ______________________________________________________________________________ For an adaptive filter to be robust, the small disturbances can only result in small estimation errors. The disturbances may arise from a variety of factors, internal or external to the filter. Computational complexity measures the amount of computation which must be expended at each time step in order to implement an adaptive algorithm and is often the governing factor in whether real-time implementation is feasible. The structure of algorithm determines the manner of information flow which is implemented in hardware form. An algorithm whose structure exhibits high modularity, parallelism, or concurrency is well suited for implementation using very large-scale integration (VLSI). 1.3 Objective and Scope The objective of this project is to study, analysis and comparison on three different types of adaptive channel equalization technique such as Least Mean Square (LMS), Recursive Least Square (RLS) and Gradient Adaptive Lattice Structure. The main focus of this project is to analyze and investigate the advantages and shortfall of the three techniques and also to determine an improving solution to provide a better channel equalization. The project will include the following main tasks: 1. Study and analyze on Least Mean Square (LMS) algorithm 2. Study and analyze on Recursive Least Square (RLS) algorithm 3. Study and analyze on Gradient Adaptive Lattice algorithm 4. Simulate on MATLAB software and comparison 5. Evaluate and Implement to get better performance based on simulation result - 12 - ______________________________________________________________________________ CHAPTER 2 The Least Mean Squares (LMS) Algorithm 2.1 Introduction The Least Mean Square (LMS) algorithm, introduced by Widrow and Hoff in 1960, is a linear adaptive filtering algorithm, which uses a gradient-based method of steepest decent. The LMS algorithm uses the estimates of the gradient vector from the available data and incorporates an iterative procedure that makes successive corrections to the weight vector in the direction of the negative of the gradient vector which eventually leads to the minimum mean square error. The LMS algorithm consists of two basic processes. These are filtering process and adaptive process. A filtering process involves computing the output of a linear filter in response to an input signal and generating an estimation error by comparing this output with a desired response. An adaptive process involves the automatic adjustment of the parameters of the filter in accordance with the estimation error. The combination of these two processes working together constitutes a feedback loop. Input vector X(k) Y(k) Transversal Filter w (k ) Adaptive weightControl Mechanism Output Error e(k) - Σ + Desired Response d(k) Fig-2.1 Block diagram representation of the LMS algorithm - 13 - ______________________________________________________________________________ The LMS algorithm is the simplest and is the most universally applicable adaptive algorithm to be used. This algorithm uses a special estimate of the gradient that is valid for the adaptive linear combiner. This algorithm is important because of its simplicity and ease of computation. It does not require explicit measurement of correlation functions, nor does it involve matrix inversion. Accuracy is limited by statistical sample size, since the weight values found are based on real-time measurements of input signals. 2.2 Derivation of the LMS Algorithm 2.2.1 Basic Idea of Gradient Search Method min w wopt 2 where is eigenvalue equal to v00 in the univariable case The first derivative, d 2 w wopt .....................................................................(2.1) dw The second derivative, d 2 2 dw 2 Simple Gradient Search Algorithm with only a single weight, wk 1 wk k ..........................................................................(2.2) From equation (2.1) k d dw w wk 2 wk wopt Substitute in equation (2.2) wk 1 wk 2 wk wopt ................................................................(2.3) Rearranging equation (2.3) wk 1 1 2 wk 2wopt .............................................................(2.4) - 14 - ______________________________________________________________________________ The equation (2.4) is a linear, first order, constant-coefficient, ordinary difference equation. For few iterations, starting with initial guess w0 , The first three iterations, w1 1 2 w0 2wopt w2 1 2 w0 2wopt 1 2 1 2 w3 1 2 3 w0 2 wopt 1 2 1 2 1 2 From above result, generate for k th iterations: k 1 wk 1 2 w0 2wopt 1 2 k n n 0 1 2 w0 2wopt k 1 1 2 1 1 2 k 1 2 w0 wopt wopt 1 2 k k wk wopt 1 2 w0 wopt k wk wopt 1 2 w0 wopt ................................................................(2.5) k - 15 - ______________________________________________________________________________ 2.2.2 Derivation of the LMS Algorithm Y(k) Xk Z-1 Xk wN w3 w2 w1 Z-1 X k2 Xk1 Xk(N1) - LMS ALGORITHM ek + dk Fig-2.2 The LMS Adaptive Filter Weight Vector w0 w 1 W w2 ........................................................................................(2.6) wN 1 - 16 - ______________________________________________________________________________ Input Signal Vector xk x k 1 X k xk 2 ...................................................................................(2.7) xk ( N 1) Output Signal Vector Yk W T X k X kT W Yk w0 w1 xk x k 1 wN 1 xk 2 xk ( N 1) w2 N 1 Yk wi xk i ...................................................................................(2.8) i 0 Error signal ek d k Yk ek d k W T X k ek2 d k W T X k 2 ek2 d k2 2d kW T X k W T X k X kT W ek2 d k2 d k2 2 d k X kT W W T X k X kT W 2 P T W W T RW d k xk d x k k 1 where P d k x k 2 ; cross correlation between d k and X k d k x k ( N 1) - 17 - ______________________________________________________________________________ xk xk x x k 1 k R xk 2 xk MSE x k x k 1 x k 1 x k 1 xk xk 2 ek2 ; auto correlation matrix of X k x k ( N 1) x k ( N 1) d k2 2 P T W W T RW ........................................................(2.9) With stationary X k and d k , to minimize d k2 2 P T W W T RW W W W W 0 0 2 P 2 RW 0 The gradient Vector of the performance function is 2P 2RW ................................................................................(2.10) To optimize, is to get Wiener Solution Let 0 to get Wopt 2 P 2 RWopt 0 2 RW opt 2 P Wopt R 1 P (Wiener Solution)..........................................................(2.11) For min , W Wopt min d k2 2PT Wopt Wopt T RWopt min d k2 2 P T R 1 P P T R T R R 1 P min d k2 2 P T R 1 P P T R T P R is symmetric; R= R T R T R 1 T R 1 min d k2 2 P T R 1 P P T R 1 P - 18 - ______________________________________________________________________________ min d k2 P T R 1 P min d k2 PT Wopt .....................................................................(2.12) When W Wopt , W Wopt 2PTW W T RW 2PTWopt Wopt T RWopt W T RW Wopt RWopt T 2P T W Wopt W Wopt RW Wopt 2 P T R 1 RW Wopt T W Wopt RW Wopt 2Wopt RW Wopt T T W Wopt RW Wopt T define V W Wopt , V V T RV min ...........................................................................(2.13) (V ) 2 RV .............................................................................(2.14) V when 0 , V Vopt , W Wopt 2 RVopt 0 ...................................................................................(2.15) Finding eigenvalues / eigenvectors for a square matrix R, a vector q is called an eigenvector of R. If q 0 , R q q ; is called an eigenvalues of R R q q 0 R I q 0 So, is an eigenvalues for non-zero q If R I is singular RQ Q Q is eigenvector matrix of R - 19 - ______________________________________________________________________________ q00 q Q = 10 q20 q01 q02 q11 ...................................................................(2.16) 0 0 is eigenvalues matrix = 0 0 0 0 1 2 0 .......................................(2.17) n R Q 1 Q Normal form The eigenvector matrix Q can be made orthogonal QT Q I Q 1 QT ................................................................................(2.18) From equation (2.13) min V T RV min V T QQ 1V min V ' V ' T where V ' Q 1V QT V Summary of 3 coordinate systems principal Natural: W min W Wopt T RW Wopt Translation: V W Wopt min V T RV Rotation: V ' QTV Q 1V , V QV ' min V ' T V ' - 20 - ______________________________________________________________________________ 2.2.3 Definition of Gradient search by Steepest Descent Method The weights are adjusted in the direction of the gradient at each step which the function is guaranteed to be reduced in value. The direction in which function decreases most rapidly is determined by the negative of the gradient of function at the current point. Wk 1 Wk k Wk 1 Wk 2 RV Wk 1 Wk 2RWopt Wk Wk 1 Wk 2RWopt 2 RW k Subtract both side Wopt ; Wk 1 Wopt Wk Wopt 2RWopt 2RWk Wk 1 Wopt I 2R Wk Wopt .................................................................(2.19) Transforming to the principal coordinate system, Translation: V W Wopt Equation (2.19) become Vk 1 I 2R Vk ..........................................................................................(2.20) Rotation: V QV ' , Vk 1 QVk'1 , Vk QV k' QVk'1 I 2R QVk' Multiply with Q 1 both sides, Q 1QVk'1 Q 1 I 2 R QVk' Vk'1 Q 1 IQ 2Q 1 RQ Vk' .........................................................................(2.21) Recall equation (2.16) and (2.17) R QQ 1 , Q 1 RQ Substitute in equation (2.21) and Q 1 IQ I Vk'1 I 2 Vk' After n th iteration, compare with equation (2.5) Vk' I 2 V0' k - 21 - ______________________________________________________________________________ 1 2 0 k ' Vk 1 21 k 1 22 k V ' 0 The steepest descent algorithm is stable and convergent When Limk I 2 0 k 1 2 p 1 ; p is eigenvalues where p = 0, 1, 2, 3,…, N-1 1 1 2 p 1 2 2 p and 2 p 0 ......................................................(2.22) From equation (2.22), 2 2 p p 1 max is maximum eigenvalue 1 max .............................................................................................(2.23) From equation (2.22) 2 p 0 p 0 0 ..................................................................................................(2.24) Combine equation (2.23) and (2.24) 0 1 max ........................................................................................(2.25) Effects on the weight –vector solution Referring to equation (2.10) 2P 2RW Let k = the gradient estimation at k th iteration Define k k N k ....................................................................................(2.26) - 22 - ______________________________________________________________________________ Where N k the gradient estimation noise vector at kth iteration ( vector of size L+1) k the gradient estimation at the kth iteration with the gradient estimation noise Steepest descent formula without noise, Wk 1 Wk k Steepest descent formula with gradient noise, Wk 1 Wk k ....................................................................................(2.27) Substitute equation (2.26) into equation (2.27) Wk 1 Wk k N k ................................................................................(2.28) Wk 1 Wk k N k Subtract Wopt both sides, Wk 1 Wopt Wk Wopt k N k Translate coordinate vector, V W Wopt , Vk 1 Vk k N k Recall equation (2.14), 2RV Vk 1 Vk 2RVk N k Equation (2.28) become, Vk 1 I 2R Vk N k ..............................................................................(2.29) Relate to principal coordinate using V QV ' , N QN ' and N ' Q 1 N QVk'1 I 2 R QVk' N k Multiply with Q 1 both sides, Vk'1 Q 1 IQ 2Q 1 RQ Vk' Q 1 N k Vk'1 I 2 Vk' N k' ..............................................................................(2.30) - 23 - ______________________________________________________________________________ Consider the first three iterations, V1' I 2 V0' N 0' V2' I 2 V1' N1' V2' I 2 V0' I 2N0' N1' 2 V2' I 2 V0' I 2N0' N1' 2 V3' I 2 V2' N 2' V3' I 2 V0' I 2 N0' I 2N1' N 2' 3 2 V3' I 2 V0' I 2 N 0' I 2N1' N 2' 3 2 Equation (2.30) obtained at kth iteration, k 1 Vk' I 2 V0' I 2 N k' i 1 ...................................................(2.31) k i i 0 Recall equation (2.25), is in the stability range 0 1 max , Multiply equation (2.25) with 2max 0 2max 2 .................................................................................................(2.32) Subtract equation (2.32) from 1, 1 1 2max 1 2 1 1 2max 1 For the worse case of equation (2.31), k Then the first term of equation (2.31) becomes negligible, the steady-state effects of gradient noise on the weight vector solution is Vk' I 2 N k' i 1 ...........................................................................(2.33) i i 0 - 24 - ______________________________________________________________________________ 2.3 Simulation Results 2.3.1 Simulation Model This simulation studies the use of the LMS algorithm for adaptive equalization of a linear dispersive channel that produces distortion. This simulation uses 4 different channel models which have 13th order complex signal, 10th order real and 3rd order real signal. Fig-2.3 shows the block diagram of the system model used to carry out the simulation in MATLAB software. Random-number generator (1) provides the test signal x(n), used for probing the channel. Random-number generator (2) serves as the source of additive white noise v(n) that corrupts the channel output. These two random-number generators are independent of each other. Random-number Generator (2) v(n) X(n) Random-number Generator (1) Σ Channel Adaptive Equalizer y Error e(n) Delay Version Σ + Desired Response d(n) Fig-2.3 Block Diagram of Adaptive Equalizer Experiment The adaptive equalizer has the task of correcting for the distortion produced by the channel in the presence of the additive white noise. By using suitable delay, randomnumber generator (1) also supplies the desired response to the adaptive equalizer in the form of a training sequence. - 25 - ______________________________________________________________________________ 2.3.2 Channel Model 1 Simulation Condition Channel transfer function: H(z) = [ (0.10-0.03j) + (-0.20+0.15j) z 1 + (0.34+0.27j) z 2 + (0.33+0.10j) z 3 + (0.40-0.12j) z 4 + (0.20+0.21j) z 5 + (1.00+0.40j) z 6 + (0.50-0.12j) z 7 + (0.32-0.43j) z 8 + (-0.21+0.31j) z 9 + (-0.13+0.05j) z 10 + (0.24+0.11j) z 11 + (0.07-00.06j) z 12 ] Number of tap of LMS adaptive filter: 25 Delay of desired response: 18 Misadjustment of output: 10% Signal-to-noise ratio SNR: 3dB, 10dB & 20dB Number of run for averaging: 100 Number of iteration: 2000 - 26 - ______________________________________________________________________________ Learning Curve of LMS Algorithm 2 Channel Model 1 SNR 3 SNR 10 SNR 20 1.8 1.6 Mean Square Error 1.4 1.2 1 0.8 0.6 0.4 0.2 0 0 200 400 600 1000 1200 800 Number of Iteration 1400 1600 1800 2000 Fig-2.4 Learning Curve of Channel Model 1 Channel Response & Equalizer Response 3.5 3 Channel Model 1 SNR 3 SNR 10 SNR 20 LMS Algorithm Channel Model 1 Frequency Response 2.5 2 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig-2.5 Channel Model and Equalizer Response of LMS Algorithm (Channel Model 1) - 27 - ______________________________________________________________________________ 2.3.3 Channel Model 2 Simulation Condition Channel transfer function: H(z) = [ (0.6) + (-0.17) z 1 + (0.1) z 2 + (0.5) z 3 + (-0.19) z 4 + (0.01) z 5 + (-0.03) z 6 + (0.2) z 7 + (0.05) z 8 + (0.1) z 9 ] Number of tap of LMS adaptive filter: 19 Delay of desired response: 14 Misadjustment of output: 10% Signal-to-noise ratio SNR: 3dB, 10dB & 20dB Number of run for averaging: 100 Number of iteration: 2000 - 28 - ______________________________________________________________________________ Learning Curve of LMS Algorithm 2 Channel Model 2 SNR 3 SNR 10 SNR 20 1.8 1.6 Mean Square Error 1.4 1.2 1 0.8 0.6 0.4 0.2 0 0 200 400 600 800 1000 1200 Number of Iteration 1400 1600 1800 2000 Fig-2.6 Learning Curve of LMS Algorithm (Channel Model 2) Channel Response & Equalizer Response 2.5 2 Channel Model 2 SNR 3 SNR 10 SNR 20 LMS Algorithm Frequency Response Channel Model 2 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig-2.7 Channel and Equalizer Response of LMS Algorithm (Channel Model 2) - 29 - ______________________________________________________________________________ 2.3.4 Channel Model 3 Simulation Condition Channel transfer function: H(z) = [ (0.6) + (-0.17) z 1 + (0.1) z 2 + (0.5) z 3 + (-0.5) z 4 + (-0.01) z 5 + (-0.03) z 6 + (0.2) z 7 + (-0.05) z 8 + (0.1) z 9 ] Number of tap of LMS adaptive filter: 19 Delay of desired response: 14 Misadjustment of output: 10% Signal-to-noise ratio SNR: 3dB, 10dB & 20dB Number of run for averaging: 100 Number of iteration: 2000 - 30 - ______________________________________________________________________________ Learning Curve of LMS Algorithm 2 Channel Model 3 SNR 3 SNR 10 SNR 20 1.8 1.6 Mean Square Error 1.4 1.2 1 0.8 0.6 0.4 0.2 0 0 200 400 600 800 1000 1200 Number of Iteration 1400 1600 1800 2000 Fig-2.8 Learning Curve of LMS Algorithm (Channel Model 3) Channel Response & Equalizer Response 2.5 2 Channel Model 3 SNR 3 SNR 10 SNR 20 LMS Algorithm Frequency Response Channel Model 3 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig-2.9 Channel and Equalizer Response of LMS Algorithm (Channel Model 3) - 31 - ______________________________________________________________________________ 2.3.5 Channel Model 4 Simulation Condition Channel transfer function: H(z) = 1+2.2 z 1 +0.4 z 2 Number of tap of LMS adaptive filter: 5 Delay of desired response: 3 Misadjustment of output: 10% Signal-to-noise ratio SNR: 3dB, 10dB & 20dB Number of run for averaging: 100 Number of iteration: 2000 - 32 - ______________________________________________________________________________ Learning Curve of LMS Algorithm 2 Channel Model 4 SNR 3 SNR 10 SNR 20 1.8 1.6 Mean Square Error 1.4 1.2 1 0.8 0.6 0.4 0.2 0 0 200 400 600 800 1000 1200 Number of Iteration 1400 1600 1800 2000 Fig-2.10 Learning Curve of LMS Algorithm (Channel Model 4) Channel Response & Equalizer Response 4 Channel Model 4 SNR 3 SNR 10 SNR 20 3.5 Frequency Response 3 LMS Algorithm Channel Model 4 2.5 2 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig-2.11 Channel and Equalizer Response of LMS Algorithm (Channel Model 4) - 33 - ______________________________________________________________________________ 2.3.6 Observation & Analysis The Fig- 2.4, 2.6, 2.8 and 2.10 are learning curves of four different channel models with three different SNR values. By observing the learning curves, all channel models have lower mean square error at 20dB and better rate of convergence at 3dB. But the mean square error is very high at 3dB. It means better SNR value gives smaller mean square error. Mean Square Error of LMS Algorithm Channel Model 3dB 10dB 20dB 1 1.1 0.5 0.18 2 1 0.45 0.25 3 0.85 0.41 0.18 4 1 0.38 0.09 Table- 2.1 Mean Square Error of LMS Algorithm Estimate Number of Iterations ( LMS Algorithm ) Channel Model 3dB 10dB 20dB 1 200 500 1000 2 180 250 400 3 200 300 500 4 80 160 200 Table- 2.2 Rate of Convergence of LMS Algorithm By observing rate of convergence at 20dB, channel model 1 has slower rate of convergence than channel model 4. Because channel model 1 is complex signal and it - 34 - ______________________________________________________________________________ takes longer time to converge. Channel model 4 is real value signal with 3rd order. Therefore, channel model 4 converges very fast. The results of learning curves confirm that the rate of convergence and mean squared error of the adaptive equalizer is highly dependent on the signal-to-noise ratio (SNR) and type of channel model. The Fig- 2.5, 2.7, 2.9 and 2.11 show the comparison between channel model and equalizer response. The mean square error of 10dB is about twice of 20dB but the equalizer response at 10dB is comparable to the equalizer response at 20dB. The equalizer response at 20dB is the best tracking and gives an approximate inversion of the channel response because of its lower mean square error. However, there are some differences due to the existence of the 10% misadjustment. Based on the learning curves and channel response Vs equalizer response simulation results, the equalizer perform very well at better SNR values. - 35 - ______________________________________________________________________________ CHAPTER 3 The Recursive Least Squares (RLS) Algorithm 3.1 Introduction The RLS algorithm as a natural extension of the method of least squares to develop and design of adaptive transversal filters such that, given the least squares estimate of the tapweight vector of the filter at iteration n 1 . Therefore, we may compute the updated estimate of the vector at iteration n upon the arrival of new data. The derivation based on a lemma in matrix algebra known as the matrix inversion lemma. An important feature of this algorithm is that its rate of convergence is typically an order of magnitude faster than that of the simple LMS algorithm. However, this improvement of performance is achieved at the expense of an increase in computational complexity of the RLS algorithm. Input vector x(i) y(i) wH (n 1)x(i) Transversal Filter w ( n 1) Output Adaptive weightControl Mechanism Σ Error e (i) + Desired Response d(i) Fig 3.1 - Block diagram representation of the RLS algorithm - 36 - ______________________________________________________________________________ 3.2 Derivation of the RLS Algorithm The Matrix Inversion Lemma Let A and B be two positive-definite M-by-M matrices C is positive-definite M-by-N matrix D is positive-definite N-by-M matrix Define A B 1 CD 1C H .....................................................................................(3.1) According to matrix inversion lemma, inverse of matrix A as A1 B BC D C H BC 1 C H B ...................................................................(3.2) To prove the matrix inversion lemma, multiply eq(3.1) by eq(3.2) AA1 B 1 CD 1C H B BC D C H BC 1 CH B AA 1 B 1 B B 1 BC D C H BC C H B CD 1C H B 1 CD C BC D C BC C B 1 H 1 H To show that AA1 I . Since D C H BC D C H BC ....................................(3.3) H 1 I and B 1 B I Rewrite eq(3.3) AA1 I C D C H BC C H B CD 1 D C H BC D C H BC C H B 1 1 CD 1C H BC D C H BC C H B 1 AA1 I C CD 1 D C H BC CD 1C H BC D C H BC 1 C H B AA1 I C CD 1 D CD 1C H BC CD 1C H BC AA1 I C CD 1 D D C H BC 1 C H B D C H BC 1 C H B ...............................................................(3.4) Since D 1 D I , the second term from right hand side of eq(3.4), Therefore AA1 I - 37 - C CD 1D 0 ______________________________________________________________________________ RLS Algorithm Z-1 Z-1 Z-1 w1 ( i ) w 0 (i ) x(i M 1) x(i M 2) x(i 1) x (i) wM 1 (i ) wM 2 ( i ) dˆ ( i X i ) e( i ) + d( i ) Fig 3.2 – Transversal filter with time-varying tap weights Input vector xi x i 1 X i xi 2 xi ( M 1) Weight vector w0 w 1 W w2 wM 1 n i exponential weighting factor, i = 1,2,3,…., n - 38 - ______________________________________________________________________________ e(i ) d (i ) y (i ) d (i) w H (n 1) x(i) ...........................................................................(3.5) Define Cost function n n n i ei n wn 2 2 ,n 1 i 1 where is regulation parameter, 0 n n ni e 2 i n wT n wn ...............................................................(3.6) i 1 Substitute eq (3.5) into eq (3.6) n n i d i w H n xi n w H n wn n 2 i 1 w n i d 2 i 2d i w H n xi w H n xi n 2 n H n wn i 1 n n n i d 2 i 2d i w H n xi n i w H n xi x T i wn n w H n wn i 1 i 1 n n n n i d 2 i 2 n i d i w H n xi w H n n i xi x T i n wn ...(3.7) i 1 i 1 i 1 The expression for n can be made more concise by introducing Rn (auto-correlation matrix) and z n (cross-correlation matrix) Rn n i xi x T i n .......................................................................(3.8) n i 1 - 39 - ______________________________________________________________________________ n z n n i d i xi ......................................................................................(3.9) i 1 eq (3.8) and (3.9) substitute in eq (3.7) n n ni d 2 i 2w H n z n w H n Rn wn .............................................(3.10) i 1 partial derivative of n with respect to w n n 2 z n 2 Rn wn w setting n 0, to determine optimal weight 0 2Rnwn zn optimal weight is wn R 1 n z n ..........................................................................................(3.11) Reformulate the required computations to make easy, the solution will start at iteration (n-1) eq (3.8) become Rn n i xi x T i n n i 1 Rn n i xi x T i xi x T i n n 1 i 1 - 40 - ______________________________________________________________________________ Rn n i 1 xi x T i xi x T i n n 1 i 1 n 1 Rn n i 1 xi x T i n 1 xn x T n i 1 n 1 Rn n i 1 xi x T i n 1 xn x T n ...........................................(3.12) i 1 the expression inside the bracket on the right hand side of eq: (3.12) equals Rn 1 Rn Rn 1 xn x T n ..........................................................................(3.13) Similarly for eq(3.9), Reformulate the required computations to make easy, the solution will start at iteration (n-1) n z n n i d i xi i 1 z n n i d i xi d n xn n 1 i 1 n 1 z n n i 1 d i xi d n xn .........................................................(3.14) i 1 the expression inside the bracket on the right hand side of eq: (3.14) equals z n 1 zn zn 1 d nxn .............................................................................(3.15) - 41 - ______________________________________________________________________________ To compute wn optimal weight vector in accordance with eq (3.11), we have to determine R 1 n by using matrix inversion lemma. Assumed auto-correlation matrix R(n) is nonsingular and invertible. Eq(3.13): Rn Rn 1 xn x T n Eq(3.1) : A B 1 CD 1C H Make following identifications: A Rn B 1 Rn 1 C xn D 1 1 Apply matrix inversion lemma to eq (3.13) Referring to eq(3.2): A1 B BC D C H BC 1 C H B , inverse of Rn is R 1 n 1 R 1 n 1 1 R 1 n 1 xn 1 x T n 1R 1 n 1xn 1 R 1 n 1 1 x T n 1 R 1 n 1 1 R 1 n 1xn x T n 1 R 1 n 1 ...................................(3.16) 1 1 x T n R 1 n 1xn For convenience of computation, Let Pn R 1 n .................................................................................................(3.17) - 42 - ______________________________________________________________________________ k n 1 Pn 1 xn .....................................................................(3.18) 1 1 x T n Pn 1xn Substitute eq(3.17) and eq(3.18) into eq(3.16) R 1 n 1 R 1 n 1 Pn 1 Pn 1 1 R 1 n 1xn x T n 1 R 1 n 1 1 1 x T n R 1 n 1xn 1 Pn 1xn x T n 1 Pn 1 1 1 x T n Pn 1xn Pn 1 Pn 1 k n x T n1 Pn 1 ......................................................(3.19) Rearranging eq(3.18) k n 1 Pn 1 xn 1 1 x T n Pn 1xn k n 1 1 x T n Pn 1xn 1 Pn 1xn k n 1k n x T nPn 1xn 1 Pn 1xn k n 1 Pn 1xn 1k nx T n Pn 1xn k n 1 Pn 1 1k nx T nPn 1 xn ...................................(3.20) the expression inside the bracket on the right-hand side of eq(3.20) is equal to eq(3.19), Pn eq(3.20) become k n P n x n ......................................................................(3.21) - 43 - ______________________________________________________________________________ substitute eq(3.17) into eq(3.21) Gain vector k n R 1 n x n .................................................................................(3.22) Time Update for the tap-weight vector From eq(3.11) wn R 1 n z n substitute eq(3.17) and eq: (3.15) into eq(3.11) wn Pnz n Pn zn 1 d nxn Pnzn 1 Pn d nxn ............................................................(3.23) Substitute eq(3.19) into eq(3.23); only first term Pn on right-hand side wn 1 Pn 1 k n x T n 1 Pn 1 z n 1 Pn d n xn Pn 1z n 1 k nx T nPn 1z n 1 Pnd nxn Since Pn R 1 n and Pn 1 R 1 n 1 , wn R 1 n 1z n 1 k n x T n R 1 n 1z n 1 R 1 n d n xn ...................(3.24) substitute eq(3.22) and eq(3.11) into eq(3.24) k n R 1 n x n and wn R 1 n z n wn R 1 n 1z n 1 k n x T n R 1 n 1z n 1 R 1 n d n xn - 44 - ______________________________________________________________________________ wn 1 k n x T n wn 1 R 1 n d n xn wn 1 k n x T n wn 1 k n d n wn 1 k n d n x T n wn 1 .............................................................(3.25) substitute eq(3.5) into eq(3.25), en d n x T n wn 1 wn wn 1 k n en ..........................................................................................(3.26) eq(3.26) for the adjustment of the tap-weight vector eq(3.5) for the a priorio estimation error Summary of RLS Initialize the algorithm by setting w0 0 P0 1 I , where is regulation parameter, 0 For each instant time, n = 1,2,3,…, compute n Pn 1 x n k n n x T n n en d n x T n wn 1 wn wn 1 k n en Pn 1 Pn 1 k n x T n1 Pn 1 - 45 - ______________________________________________________________________________ 3.3 Simulation Results This simulation studies the use of RLS algorithm with the exponential weighting factor 0.999 , for the adaptive equalization of a linear dispersive communication channel. The simulation model is the same model as LMS algorithm simulation model in Section 2.3. (Fig-2.3) 3.3.1 Channel Model 1 Simulation Condition Channel transfer function: H(z) = [ (0.10-0.03j) + (-0.20+0.15j) z 1 + (0.34+0.27j) z 2 + (0.33+0.10j) z 3 + (0.40-0.12j) z 4 + (0.20+0.21j) z 5 + (1.00+0.40j) z 6 + (0.50-0.12j) z 7 + (0.32-0.43j) z 8 + (-0.21+0.31j) z 9 + (-0.13+0.05j) z 10 + (0.24+0.11j) z 11 + (0.07-00.06j) z 12 ] Number of tap of RLS adaptive filter: 25 Delay of desired response: 18 Misadjustment of output: 10% Signal-to-noise ratio SNR: 3dB, 10dB & 20dB Number of run for averaging: 100 Number of iteration: 2000 Exponential weighting factor 0.999 Regulation parameter = 0.01 - 46 - ______________________________________________________________________________ Learning Curve of RLS Algorithm 2 SNR 3 SNR 10 SNR 20 Channel Model 1 1.8 Mean Square Error 1.6 1.4 1.2 1 0.8 0.6 0.4 0.2 0 0 200 400 600 800 1000 1200 Number of Iteration 1400 1600 1800 Fig-3.3 Learning Curve of RLS Algorithm (Channel Model 1) Channel Response & Equalizer Response 3.5 3 Channel Model 1 SNR 3 SNR 10 SNR 20 RLS Algorithm Channel Model 1 Frequency Response 2.5 2 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig-3.4 Channel and Equalizer Response of RLS Algorithm (Channel Model 1) - 47 - ______________________________________________________________________________ 3.3.2 Channel Model 2 Simulation Condition Channel transfer function: H(z) = [ (0.6) + (-0.17) z 1 + (0.1) z 2 + (0.5) z 3 + (-0.19) z 4 + (0.01) z 5 + (-0.03) z 6 + (0.2) z 7 + (0.05) z 8 + (0.1) z 9 ] Number of tap of RLS adaptive filter: 19 Delay of desired response: 14 Misadjustment of output: 10% Signal-to-noise ratio SNR: 3dB, 10dB & 20dB Number of run for averaging: 100 Number of iteration: 2000 Exponential weighting factor 0.999 Regulation parameter = 0.01 - 48 - ______________________________________________________________________________ Learning Curve of RLS Algorithm Mean Square Error 2 SNR 3 SNR 10 SNR 20 Channel Model 2 1.5 1 0.75 0.5 0.25 0 0 200 400 600 800 1000 1200 Number of Iteration 1400 1600 1800 Fig-3.5 Learning Curve of RLS Algorithm (Channel Model 2) Channel Response & Equalizer Response 2.5 2 Channel Model 2 SNR 3 SNR 10 SNR 20 RLS Algorithm Frequency Response Channel Model 2 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig-3.6 Channel and Equalizer Response of RLS Algorithm (Channel Model 2) - 49 - ______________________________________________________________________________ 3.3.3 Channel Model 3 Simulation Condition Channel transfer function: H(z) = [ (0.6) + (-0.17) z 1 + (0.1) z 2 + (0.5) z 3 + (-0.5) z 4 + (-0.01) z 5 + (-0.03) z 6 + (0.2) z 7 + (-0.05) z 8 + (0.1) z 9 ] Number of tap of RLS adaptive filter: 19 Delay of desired response: 14 Misadjustment of output: 10% Signal-to-noise ratio SNR: 3dB, 10dB & 20dB Number of run for averaging: 100 Number of iteration: 2000 Exponential weighting factor 0.999 Regulation parameter = 0.01 - 50 - ______________________________________________________________________________ Learning Curve of RLS Algorithm SNR 3 SNR 10 SNR 20 2.5 Mean Square Error 2.25 2 Channel Model 3 1.75 1.5 1.25 1 0.75 0.5 0.25 0 0 200 400 600 800 1000 1200 Number of Iteration 1400 1600 1800 Fig-3.7 Learning Curve of RLS Algorithm (Channel Model 3) Channel Response & Equalizer Response 2.5 2 Channel Model 3 SNR 3 SNR 10 SNR 20 RLS Algorithm Frequency Response Channel Model 3 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig-3.8 Channel and Equalizer Response of RLS Algorithm (Channel Model 3) - 51 - ______________________________________________________________________________ 3.3.4 Channel Model 4 Simulation Condition Channel transfer function: H(z) = 1+2.2 z 1 +0.4 z 2 Number of tap of RLS adaptive filter: 5 Delay of desired response: 3 Misadjustment of output: 10% Signal-to-noise ratio SNR: 3dB, 10dB & 20dB Number of run for averaging: 100 Number of iteration: 2000 Exponential weighting factor 0.999 Regulation parameter = 0.01 - 52 - ______________________________________________________________________________ Learning Curve of RLS Algorithm Mean Square Error 2 SNR 3 SNR 10 SNR 20 Channel Model 4 1.5 1 0.5 0 0 200 400 600 800 1000 1200 Number of Iteration 1400 1600 1800 Fig-3.9 Learning Curve of RLS Algorithm (Channel Model 4) Channel Response & Equalizer Response 4 Channel Model 4 SNR 3 SNR 10 SNR 20 3.5 Frequency Response 3 RLS Algorithm Channel Model 4 2.5 2 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig-3.10 Channel and Equalizer Response of RLS Algorithm (Channel Model 4) - 53 - ______________________________________________________________________________ 3.3.5 Observation & Analysis The Fig- 3.3, 3.5, 3.7 and 3.9 are learning curves of four different channel models with three different SNR values. By observing the learning curves, all channel models have lower mean square error and faster rate of convergence at 20dB. It means better SNR value gives smaller mean square error and faster rate of convergence in RLS algorithm. The steady-state values of mean square error is very high in the first few iterations and jump down immediately after this. The mean square error is high at 3dB but the rate of convergence is comparable to the rate of convergence at 10dB. Mean Square Error of RLS Algorithm Channel Model 3dB 10dB 20dB 1 0.95 0.43 0.1 2 0.82 0.38 0.25 3 0.85 0.35 0.13 4 0.8 0.35 0.09 Table- 3.1 Mean Square Error of RLS Algorithm Estimate Number of Iterations ( RLS Algorithm ) Channel Model 3dB 10dB 20dB 1 150 120 100 2 100 100 80 3 100 100 60 4 80 60 20 Table- 3.2 Rate of Convergence of RLS Algorithm - 54 - ______________________________________________________________________________ At SNR 20dB, the mean square error of channel model 1 (complex) and channel model 4 (real) are 0.1 and 0.09 respectively. The RLS algorithm gives smaller mean square error and it does not depend on type of channel. However, the rate of convergence of complex channel is slower than the real value channel. The results of learning curves confirm that the rate of convergence is very fast in RLS algorithm and mean squared error of the adaptive equalizer is highly dependent on the signal-to-noise ratio (SNR) and independent on the type of channel. The Fig- 3.4, 3.6, 3.8 and 3.10 show the comparison between channel model and equalizer response. The equalizer response of channel model 2, 3, and 4 (real) is better tracking and gives an approximate inversion of the channel response compare to the equalizer response of channel model 1 (complex). The misadjustment (10%) also does not significantly differences in channel model 2, 3 and 4 (real). - 55 - ______________________________________________________________________________ CHAPTER 4 The Gradient Adaptive Lattice (GAL) Algorithm 4.1 Introduction The gradient adaptive lattice algorithm is a natural extension of the least mean square filter in that both types of filter rely on a stochastic gradient approach for their algorithmic implementations. The Fig- 4.1 shows the basic structure for the estimation of a desired response which is based on a multistage lattice structure that performs both forward f(n) and backward b(n) predictions. Firstly, we may derive the recursive order updates for the multistage lattice predictor. Then, we may derive the corresponding updates for the desired-response estimator. Stage 1 f 0 ( n) Stage M Σ f M 1 (n) f1 ( n) 1 M 1* M* fM (n) Σ Input Signal x(n) b0 (n) Z-1 h 0* Σ b1 ( n ) b M 1 ( n) Z-1 Σ h 1* hM* 1 h M* Σ Σ Σ bM (n) YM(n)=Estimate of desired response d(n) Fig 4.1 - Block diagram representation of the Lattice Structure The order-recursive adaptive filters derived from the stochastic gradient approach are simple to design, but approximate in nature. The simplicity of design results from the fact that each stage of the lattice predictor is characterized by a single reflection coefficient. - 56 - ______________________________________________________________________________ The lattice filters can be viewed as stage-by-stage orthogonalization of input data. This property results in faster convergence than the tapped-delay-line implementation of LMS filter. When a lattice filter is used as a linear predictor, the predictor order can be increased simply by adding another lattice section without changing any of the previous section. The tapped-delay-line implementation of the linear predictor does not have this useful modularity property. The lattice filters have become popular in the adaptive signal processing because of their fast convergence and modularity property. 4.2 Derivation of the Gradient Adaptive Lattice Algorithm Levinson-Durbin Algorithm Let a m = the tap weight (m+1) x 1 vector of a forward prediction error filter of order m B* a m = the tap weight (m+1) x 1 vector of a backward prediction error filter of order m and their complex conjugate a m1 = the tap weight m x 1 vector of a forward prediction error filter of order m-1 B* a m 1 = the tap weight m x 1 vector of a backward prediction error filter of order m and their complex conjugate m = constant (reflection coefficient) f m (n) = forward prediction error bm (n) = backward prediction error - 57 - ______________________________________________________________________________ Z-1 am,0 (n) x(n 2) x(n 1) x(n ) am,1 (n) x (n M ) x(nM1) Z-1 Z-1 am,2 (n) am,M1(n) am,M (n) fm-1(n) Fig 4.2 - Forward Prediction Error Filter A forward predictor may modify into a backward predictor by reversing the sequence in which its tap weights are positioned and also taking the complex conjugates of them. Order updated equation of a forward prediction-error filter 0 a a m m1 m B* .....................................................................(4.1) 0 a m1 In expended form am,0 am 1,0 0 a a* m,1 am 1,1 m 1, m 1 m * am, m 1 am 1, m 1 am 1,1 am, m 0 am* 1, 0 Equivalently am,0 am1,0 m am* 1,m , then am* 1,m 0 am,m am1,m m am* 1,0 , then am1,m 0 am,k am1,k m am* 1,mk , k 0, 1, 2, , m ....................................(4.2) - 58 - fm(n) ______________________________________________________________________________ Let m k l , m l k , then substitute in eq (4.2), am* 1,m 0 and am1,m 0 am,ml am1,ml m am* 1,l , l 0, 1, 2, , m ...................................(4.3) Complex conjugate both side of eq(4.3) am* ,ml am* 1,ml m* am1,l , l 0.1, 2, , m .....................................(4.4) In expended form am* , m 0 am 1, 0 * * a am , m 1 am 1, m 1 m 1,1 m* * * am ,1 am 1,1 am 1, m 1 a* am* 1, 0 0 m,0 am* ,m am* 1,m m* am1,0 , then am* 1,m 0 am* ,0 am* 1,0 m* am1,m , then am1,m 0 Order updated equation of a backward prediction-error filter 0 a B* a m B* m* m1 ....................................................................(4.5) 0 a m1 - 59 - ______________________________________________________________________________ x(n 2) x(n 1) x(n ) Z-1 am* ,M (n) am* ,M1(n) x (n M ) x(nM1) Z-1 Z-1 am*,M2(n) am* ,1 (n) am* ,0 (n) bm-1(n) Fig 4.3 - Backward Prediction Error Filter Order-update Recursions for the prediction errors Let f m (n) = the forward prediction error produced at the output of the forward predictionerror filter of order m f m1 (n) = the forward prediction error produced at the output of the forward predictionerror filter of order m-1 bm (n) = the backward prediction error produced at the output of the backward prediction- error filter of order m bm 1 (n 1) = the delayed backward prediction error produced at the output of the backward prediction-error filter of order m-1 M = stage of lattice predictor m = reflection coefficient x(n) = sample value of tap input in transversal filter at time n - 60 - bm(n) ______________________________________________________________________________ x m1 (n) = (m+1) x 1 tap input vector x m ( n) x m1 (n) .....................................................................................(4.6) x(n m) Equivalent form x ( n) x m1 (n) .....................................................................................(4.7) x m (n 1) Consider the forward prediction-error filter of order m Form the inner product of the (m+1) x 1 vector a m and x m1 (n) by pre-multiplying x m1 (n) by Hermitian transpose of a m (1) Multiply the left hand side of eq(4.1) and the left hand side of eq(4.6), f m (n) a m x m1 (n) ........................................................................................(4.8) H (2) Multiply the first term on the right hand side of eq(4.1) and the right hand side of eq(4.6), a H m1 0 x m1 (n) a H m1 a m1 x m (n) x m ( n) 0 x(n m) H f m1 (n) ..........................................................................(4.9) (3) Multiply the second term on the right hand side of eq(4.1) and the right hand side of eq(4.7), - 61 - ______________________________________________________________________________ 0 a BT m1 x m1 ( n) 0 a BT m1 a m1 x m (n 1) x ( n) x m (n 1) BT .....................................................................(4.10) bm1 (n 1) Combine the results of multiplication eq(4.8), eq(4.9) and eq(4.10), f m (n) f m 1 (n) m* bm 1 (n 1) .....................................................................(4.11) Consider the backward prediction-error filter of order m B* Form the inner product of the (m+1) x 1 vector a m 1 and x m1 (n) by pre-multiplying B* x m1 (n) by Hermitian transpose of a m 1 (1) Multiply the left hand side of eq(4.5) and the left hand side of eq(4.6), bm (n) a m x m1 (n) .......................................................................................(4.12) BT (2) Multiply the first term on the right hand side of eq(4.5) and the right hand side of eq(4.7), 0 a BT m1 x m1 ( n) 0 a a m1 x m (n 1) BT m1 x ( n) x m (n 1) BT bm1 (n 1) .....................................................................(4.13) (3) Multiply the second term on the right hand side of eq(4.5) and the right hand side of eq(4.6), - 62 - ______________________________________________________________________________ a H m1 0 x m1 (n) a x m ( n) 0 x(n m) H m1 a m1 x m (n) H f m1 (n) ..........................................................................(4.14) Combine the results of multiplication eq(4.12), eq(4.13) and eq(4.14), bm (n) bm1 (n 1) m f m1 (n) ....................................................................(4.15) Matrix form of combined eq(4.11) & eq(4.15) f m (n) 1 m* f m 1 (n) b ( n) , m 1, 2,, M .......................................(4.16) m m 1 bm 1 (n 1) bm1 (n 1) z 1 bm1 (n) f m1 (n) Σ fm(n) Σ bm(n) * bm1(n) Z-1 Fig 4.4 - Single Stage Lattice Predictor - 63 - ______________________________________________________________________________ Multistage Lattice Predictor Stage 1 f0 (n) Stage M f M1 (n) f1(n) Σ 1 m 1* m* Σ f M (n) Input Signal x(n) b0 ( n) Σ Z-1 b1 ( n ) bM1 (n) Z-1 Σ bM (n) Fig 4.5 - Multistage Lattice Predictor Assume that input data are wide-sense stationary and m is complex value m* m Define Cost function is Jm 1 2 2 f m (n) bm (n) .........................................................................(4.17) 2 Substitute eq(4.11) & eq(4.15) into eq(4.17), m* bm1 (n 1) m bm* 1 (n 1) and m f m1 (n) m* f m*1 (n) Jm 2 1 2 f m 1 (n) m* bm 1 (n 1) bm 1 (n 1) m f m 1 (n) 2 Jm 2 1 2 2 f m 1 (n) 2 f m 1 (n) m* bm 1 (n 1) m* bm 1 (n 1) bm 1 (n 1) 2 2 bm 1 (n 1) m f m 1 (n) m f m 1 (n) - 64 - 2 ______________________________________________________________________________ Re-arrange above equation as: Jm 2 1 2 2 2 f m 1 (n) m* bm 1 (n 1) bm 1 (n 1) m f m 1 (n) 2 f m 1 (n) m* bm 1 (n 1) bm 1 (n 1) m f m 1 (n) ...........(4.18) Differentiating eq(4.18), J m with respect to the reflection coefficient m , f m1 (n)bm* 1 (n 1) bm1 (n 1) f m*1 (n) J m 1 2 2 E m f m 1 (n) E m bm 1 (n 1) m 2 m m m f m 1 (n)bm* 1 (n 1) m* bm 1 (n 1) f m*1 (n) m m J m 2 2 m E f m1 (n) E bm1 (n 1) f m1 (n)bm* 1 (n 1) m bm* 1 (n 1) f m1 (n) m m J m 2 2 m E f m1 (n) E bm1 (n 1) 2 E bm1 (n 1) f m*1 (n) ............................(4.19) m To optimize the reflection coefficient, 0 , eq(4.19) become m ,o 2 E bm1 (n 1) f m*1 (n) E f m1 (n) 2 E bm1 (n 1) 2 ..................................................................(4.20) Eq(4.20) for the optimum reflection coefficient m,o is also known as Burg Formula. Replacing the expectation operator E with time average operator 1 n , thus we get the n i 1 Burg estimate for the reflection coefficient m,o for stage m in the lattice filter. Eq (4.20) become - 65 - ______________________________________________________________________________ 2 ̂ m (n) 1 n bm1 (i 1) f m*1 (i ) n i 1 1 n 2 2 f m1 (i ) bm1 (i 1) n i 1 n ̂ m (n) 2 bm1 (i 1) f m*1 (i ) i 1 f n i 1 (i ) bm1 (i 1) 2 m 1 2 ...........................................................................(4.21) Reformulate this estimator into an equivalent recursive structure For denominator of eq(4.21) Define total energy of both forward and backward prediction errors n m1 (n) f m1 (i) bm1 (i 1) i 1 n 1 2 2 .......................................................................(4.22) m1 (n) f m1 (i) bm1 (i 1) f m1 (n) bm1 (n 1) ................................(4.23) i 1 2 2 n 1 2 2 Since m1 (n 1) f m1 (i ) bm1 (i 1) , eq(4.23) become i 1 2 2 m1 (n) m1 (n 1) f m1 (n) bm1 (n 1) ..........................................................(4.24) 2 2 For numerator of eq(4.21) n n 1 i 1 i 1 bm1 (i 1) f m*1 (i) bm1 (i 1) f m*1 (i) bm1 (n 1) f m*1 (n) ...........................(4.25) Substituting eq(4.24) and (4.25) into eq(4.21) - 66 - ______________________________________________________________________________ n 1 ˆ m (n) 2 bm1 (i 1) f m*1 (i ) 2bm1 (n 1) f m*1 (n) i 1 m1 (n 1) f m1 (n) bm1 (n 1) 2 ..................................................(4.26) 2 Form the recursively computing the estimate ˆ m (n) , use the time-varying estimate ˆ m (n 1) in place of m to rewrite eq(4.11) and (4.15) f m (n) f m 1 (n) ˆm* (n 1) bm 1 (n 1) f m1 (n) f m (n) ˆ m* (n 1) bm1 (n 1) ......................................................................(4.27) bm (n) bm 1 (n 1) ˆm (n 1) f m 1 (n) bm1 (n 1) bm (n) ˆ m (n 1) f m1 (n) .......................................................................(4.28) Rearrange 2nd numerator term of eq(4.26), bm1 (n 1) f m*1 (n) f m*1 (n)bm1 (n 1) 2bm 1 (n 1) f m*1 (n) bm 1 (n 1) f m*1 (n) f m*1 (n)bm 1 (n 1) ......................................(4.29) Substitute eq(4.27) and (4.28) into eq(4.29) 2bm1 (n 1) f m*1 (n) bm1 (n 1) f m (n) ˆ m* (n 1) bm1 (n 1) f m*1 (n)bm (n) ˆ m (n 1) f m1 (n) * bm1 (n 1) f m* (n) ˆ m (n 1) bm* 1 (n 1) f m*1 (n)bm (n) ˆ m (n 1) f m1 (n) bm1 (n 1) f m* (n) ˆ m (n 1) bm1 (n 1) f m*1 (n)bm (n) ˆ m (n 1) f m1 (n) 2 ˆ m (n 1) f m1 (n) bm1 (n 1) 2 2 2 f m*1 (n)bm (n) bm1 (n 1) f m* (n) ..(4.30) - 67 - ______________________________________________________________________________ Add the extra term ˆm (n 1) m1 (n 1) in eq(4.30) and substitute eq(4.24) ˆ m (n 1) m1 (n 1) f m1 (n) bm1 (n 1) 2 2 ˆ m (n 1) m1 (n 1) f m*1 (n)bm (n) bm1 (n 1) f m* (n) ˆm (n 1) m 1 (n) ˆm (n 1) m 1 (n 1) f m*1 (n)bm (n) bm 1 (n 1) f m* (n) ..........(4.31) Rearranging eq(4.21) to become recursively and substitute eq(4.22), n Eq(4.21): ̂ m (n) 2 bm1 (i 1) f m*1 (i ) i 1 f n i 1 (i ) bm1 (i 1) 2 m 1 2 n ˆ m (n) 2 bm1 (i 1) f m*1 (i ) i 1 m1 (n) n 2 bm1 (i 1) f m*1 (i ) ˆ m (n) m1 (n) i 1 n 1 2 bm1 (i 1) f m*1 (i ) ˆ m (n 1) m1 (n 1) .................................................................(4.32) i 1 Substitute eq(4.31) and (4.32) into numerator of eq(4.26) n 1 2 bm1 (i 1) f m*1 (i ) 2bm1 (n 1) f m*1 (n) i 1 ˆ m (n 1) m1 (n 1) ˆ m (n 1) m1 (n) ˆ m (n 1) m1 (n 1) f m*1 (n)bm (n) bm1 (n 1) f m* (n) ˆ m (n 1) m1 (n) f m*1 (n)bm (n) bm1 (n 1) f m* (n) ............................................(4.33) - 68 - ______________________________________________________________________________ Combine numerator and denominator of eq(4.26) using eq(4.33) and eq(4.24) n 1 Eq(4.26) : ˆ m (n) ˆ m (n) ˆ m (n) 2 bm1 (i 1) f m*1 (i ) 2bm1 (n 1) f m*1 (n) i 1 m1 (n 1) f m1 (n) bm1 (n 1) 2 2 ˆ m (n 1) m1 (n) f m*1 (n)bm (n) bm1 (n 1) f m* (n) m1 (n) ˆ m (n 1) m1 (n) f m*1 (n)bm (n) bm1 (n 1) f m* (n) m1 (n) m1 (n) ˆ m (n) ˆ m (n 1) f * m 1 (n)bm (n) bm 1 (n 1) f m* (n) , m 1, 2, , M . .....................(4.34) m 1 (n) Modification to recursive formulas of Gradient Lattice Filter Let = step-size parameter = constant (0 1) m = the sum of squared forward and backward prediction errors m bm (n) 2 f m (n) 2 .......................................................................(4.35) m1 (n) = total energy of both forward and backward prediction errors (define Eq 4.22) Recall the eq(2.2), Simple Gradient Search method used in LMS algorithm with only a single weight wk 1 wk k ..........................................................................(2.2) where k w - 69 - ______________________________________________________________________________ Apply Gradient- based method for updating the reflection coefficients ˆ m (n) ˆ m (n 1) m ..............................................................(4.36) where m m m .........................................................................(4.37) Substitute eq(4.35) into eq(4.37), m m bm (n) 2 m 2 f m ( n) Apply chain rule for partial derivatives of backward and forward prediction errors m 2bm (n) m bm (n) 2 f m (n) m f m (n) ................................................(4.38) Substitute eq(4.11) & eq(4.15) into eq(4.38) m 2bm (n) m bm1 (n 1) m f m 1 (n) 2 f m (n) m f m 1 (n) m* bm 1 (n 1) m 2bm (n) f m*1 (n) 2 f m* (n) bm 1 (n 1) m 2 f m*1 (n)bm (n) bm 1 (n 1) f m* (n) .............................................................(4.39) Substitute eq(4.39) into eq(4.36) ˆ m (n) ˆ m (n 1) 2 f m*1 (n)bm (n) bm 1 (n 1) f m* (n) .......................................(4.40) Eq(4.40) introduce 2 (step-size parameter) with a single weight. For forward and backward prediction, 2 (step-size parameter) need to divide by total energy m1 (n) , that control the adjustment applied each reflection coefficient in progressing from current iteration to the next iteration. - 70 - ______________________________________________________________________________ Eq(4.40) become, ˆ m (n) ˆ m (n 1) 2 f m*1 (n)bm (n) bm1 (n 1) f m* (n), m 1, 2, , M . ..........(4.41) m 1 (n) Re-write Eq(4.24) in the form of a single-pole averaging filter that operates on the square prediction errors m1 (n) m 1 (n 1) 1 f m 1 (n) bm1 (n 1) 2 2 .....................................(4.42) Desired-Response Estimator Backward Prediction Errors bm1(n) bm (n) hˆ 1* hˆm* 1 hˆm* Σ Σ Σ b0 (n) b1 (n) ĥ0* Ym(n)=Estimate of desired response d(n) Fig 4.6 - Desired-response estimator using a sequence of m backward prediction errors Let b m (n) = backward prediction error vector * h m ( n) = weight vector h m (n 1) = updated weight vector * - 71 - ______________________________________________________________________________ d * (n) b m (n)h m (n 1) = desired response vector H * h m (n 1) = adjustment weight vector * ym (n) = output signal, estimate of desired response d(n) em* (n) = estimation error 2 b m (n) = squared Euclidean norm of b m (n) m y m ( n) h k ( n) b k ( n) * k 0 y m ( n) m 1 h * k k 0 (n) b k (n) hm* (n) bm (n) ym (n) ym (n 1) hm* (n) bm (n) ................................................................................(4.43) Estimation error is defined by em* (n) d * (n) y m (n) em* (n) d * (n) b m (n)h m (n) .....................................................................................(4.44) H * Squared Euclidean Norm m b m (n) bk (n) 2 2 k 0 b m ( n) 2 m 1 b ( n) b k 0 2 k m ( n) 2 b m (n) b m1 (n) bm (n) ...................................................................................(4.45) 2 2 2 Re-write Eq(4.45) in the form of a single-pole averaging filter - 72 - ______________________________________________________________________________ b m ( n) 2 b m 1 (n) 1 bm (n) ...................................................................(4.46) 2 2 Time update for the mth regression coefficient h m (n 1) h m (n 1) h m (n) .................................................................................(4.47) * * 1 * b m (n)b m (n) h m (n 1) h m (n) H b m ( n) 2 where * 1 1 b m ( n) 2 b m (n)b m (n) b m (n) b m (n)h m (n 1) b m (n)h m (n) ...................................................(4.48) H 2 H b m ( n) * * H * Substitute d * (n) b m (n)h m (n 1) , H 1 b m ( n) * b m (n) d * (n) b m (n)h m (n) H 2 * ..................................................................(4.49) Apply eq(4.44), em* (n) d * (n) b m (n)h m (n) H 1 b m ( n) 2 * b m (n)e* (n) ...............................................................................................(4.50) Equivalent right hand side of eq(4.47) and eq(4.50), h m (n 1) h m (n) * * 1 b m ( n) 2 bm (n) em* (n) .................................................................(4.51) eq(4.51) introduce 2 (step-size parameter) that control the adjustment applied each iteration h m (n 1) h m (n) * * 2 b m ( n) 2 bm (n) em* (n) .................................................................(4.52) - 73 - ______________________________________________________________________________ 4.3 Simulation Results This simulation studies the use of Gradient Adaptive Lattice algorithm with the step-size parameter 0.001 and the constant 0.9 , for the adaptive equalization of a linear dispersive communication channel. The simulation model is the same model as LMS algorithm simulation model in Section 2.3. (Fig-2.3) 4.3.1 Channel Model 1 Simulation Condition Channel transfer function: H(z) = [ (0.10-0.03j) + (-0.20+0.15j) z 1 + (0.34+0.27j) z 2 + (0.33+0.10j) z 3 + (0.40-0.12j) z 4 + (0.20+0.21j) z 5 + (1.00+0.40j) z 6 + (0.50-0.12j) z 7 + (0.32-0.43j) z 8 + (-0.21+0.31j) z 9 + (-0.13+0.05j) z 10 + (0.24+0.11j) z 11 + (0.07-00.06j) z 12 ] Number of tap of Lattice adaptive filter: 25 Delay of desired response: 18 Misadjustment of output: 10% Signal-to-noise ratio SNR: 3dB, 10dB & 20dB Number of run for averaging: 100 Number of iteration: 2000 Step-size parameter, : 0.001 Constant, lying in the range (0,1) : 0.9 - 74 - ______________________________________________________________________________ Learning Curve of Lattice Algorithm 2 Channel Model 1 SNR 3 SNR 10 SNR 20 1.8 1.6 Mean Square Error 1.4 1.2 1 0.8 0.6 0.4 0.2 0 0 200 400 600 1000 1200 800 Number of Iteration 1400 1600 1800 2000 Fig-4.7 Learning Curve of Lattice Algorithm (Channel Model 1) Channel Response & Equalizer Response 3.5 Channel Model 1 SNR 3 SNR 10 SNR 20 3 Frequency Response 2.5 Lattice Algorithm Channel Model 1 2 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig-4.8 Channel and Equalizer Response of Lattice Algorithm (Channel Model 1) - 75 - ______________________________________________________________________________ 4.3.2 Channel Model 2 Simulation Condition Channel transfer function: H(z) = [ (0.6) + (-0.17) z 1 + (0.1) z 2 + (0.5) z 3 + (-0.19) z 4 + (0.01) z 5 + (-0.03) z 6 + (0.2) z 7 + (0.05) z 8 + (0.1) z 9 ] Number of tap of Lattice adaptive filter: 19 Delay of desired response: 14 Misadjustment of output: 10% Signal-to-noise ratio SNR: 3dB, 10dB & 20dB Number of run for averaging: 100 Number of iteration: 2000 Step-size parameter, : 0.001 Constant, lying in the range (0,1) : 0.9 - 76 - ______________________________________________________________________________ Learning Curve of Lattice Algorithm 2 SNR 3 SNR 10 SNR 20 1.8 Channel Model 2 1.6 Mean Square Error 1.4 1.2 1 0.8 0.6 0.4 0.2 0 0 200 400 600 1000 1200 800 Number of Iteration 1400 1600 1800 2000 Fig-4.9 Learning Curve of Lattice Algorithm (Channel Model 2) Channel Response & Equalizer Response 2.5 2 Channel Model 2 SNR 3 SNR 10 SNR 20 Lattice Algorithm Frequency Response Channel Model 2 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig-4.10 Channel and Equalizer Response of Lattice Algorithm (Channel Model 2) - 77 - ______________________________________________________________________________ 4.3.3 Channel Model 3 Simulation Condition Channel transfer function: H(z) = [ (0.6) + (-0.17) z 1 + (0.1) z 2 + (0.5) z 3 + (-0.5) z 4 + (-0.01) z 5 + (-0.03) z 6 + (0.2) z 7 + (-0.05) z 8 + (0.1) z 9 ] Number of tap of Lattice adaptive filter: 19 Delay of desired response: 14 Misadjustment of output: 10% Signal-to-noise ratio SNR: 3dB, 10dB & 20dB Number of run for averaging: 100 Number of iteration: 2000 Step-size parameter, : 0.001 Constant, lying in the range (0,1) : 0.9 - 78 - ______________________________________________________________________________ Learning Curve of Lattice Algorithm 2 SNR 3 SNR 10 SNR 20 1.8 Channel Model 3 1.6 Mean Square Error 1.4 1.2 1 0.8 0.6 0.4 0.2 0 0 200 400 600 1000 1200 800 Number of Iteration 1400 1600 1800 2000 Fig-4.11 Learning Curve of Lattice Algorithm (Channel Model 3) Channel Response & Equalizer Response 2.2 2 Lattice Algorithm 1.8 Channel Model 3 Channel Model 3 SNR 3 SNR 10 SNR 20 Frequency Response 1.6 1.4 1.2 1 0.8 0.6 0.4 0.2 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig-4.12 Channel and Equalizer Response of Lattice Algorithm (Channel Model 3) - 79 - ______________________________________________________________________________ 4.3.4 Channel Model 4 Simulation Condition Channel transfer function: H(z) = 1+2.2 z 1 +0.4 z 2 Number of tap of Lattice adaptive filter: 5 Delay of desired response: 3 Misadjustment of output: 10% Signal-to-noise ratio SNR: 3dB, 10dB & 20dB Number of run for averaging: 100 Number of iteration: 2000 Step-size parameter, : 0.001 Constant, lying in the range (0,1) : 0.9 - 80 - ______________________________________________________________________________ Learning Curve of Lattice Algorithm 2 SNR 3 SNR 10 SNR 20 1.8 1.6 Channel Model 4 Mean Square Error 1.4 1.2 1 0.8 0.6 0.4 0.2 0 0 200 400 600 800 1000 1200 Number of Iteration 1400 1600 1800 2000 Fig-4.13 Learning Curve of Lattice Algorithm (Channel Model 4) Channel Response & Equalizer Response 4 Channel Model 4 SNR 3 SNR 10 SNR 20 3.5 Frequency Response 3 2.5 Lattice Algorithm Channel Model 4 2 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig-4.14 Channel and Equalizer Response of Lattice Algorithm (Channel Model 4) - 81 - ______________________________________________________________________________ 4.3.5 Observation & Analysis The Fig- 4.7, 4.9, 4.11 and 4.13 are learning curves of four different channel models with three different SNR values. By observing the learning curves, all channel models have almost same mean square error at each SNR value. For example, channel model 1 and channel model 2 have 1.05 (MSE) at 3dB SNR, 0.45 and 0.43 (MSE) at 10dB. Therefore, GAL algorithm gives almost same mean square error and does not depend on the type of channel model. The better SNR value gives smaller mean square error. Mean Square Error of Lattice Algorithm Channel Model 3dB 10dB 20dB 1 1.05 0.45 0.18 2 1.05 0.43 0.22 3 0.98 0.4 0.15 4 0.88 0.42 0.08 Table- 4.1 Mean Square Error of GAL Algorithm Estimate Number of Iterations ( Lattice Algorithm ) Channel Model 3dB 10dB 20dB 1 200 400 600 2 160 220 380 3 180 220 380 4 60 100 180 Table- 4.2 Rate of Convergence of GAL Algorithm - 82 - ______________________________________________________________________________ The rate of convergence depends on both SNR values and type of channel model. By observing different channel models, channel model 4 (real) is faster converging than channel model 1 (complex). By observing different SNR values, the rate of convergence at 20dB is slower than the rate of convergence at 3dB. The results of learning curves confirm that the rate of convergence is fast in channel model 4 (real) at 3dB SNR value. But the mean squared error of the adaptive equalizer is highly dependent on the signal-to-noise ratio (SNR) and independent on the type of channel. The Fig- 4.8, 4.10, 4.12 and 4.14 show the comparison between channel model and equalizer response. The equalizer response of all channel models has better tracking at 10dB and 20dB. The equalizer response at 3dB can not give approximate inversion of the channel response. Between channel response and equalizer response have some differences due to the existence of the 10% misadjustment. Based on the learning curves and channel response Vs equalizer response simulation results, the equalizer perform very well at real channel model with better SNR values. - 83 - ______________________________________________________________________________ CHAPTER 5 Comparison Study 5.1 Simulation Results Learning Curve of SNR 20dB LMS RLS Lattice 1.8 1.6 1 0.8 1.2 Channel Model 1 0.7 0.6 1 0.5 0.4 0.8 0.3 0.2 0.6 0.1 50 0.4 100 150 200 250 300 350 400 450 0.2 0 0 100 200 300 400 500 600 Number of Iteration 700 800 900 Fig-5.1 Comparison Learning Curve of Channel Model 1 at SNR 20dB Channel Response & Equalizer Response 3.5 Channel Model 1 LMS RLS Lattice 3 2.5 Frequency Response Mean Square Error 1.4 0.9 SNR 20dB Channel Model 1 2 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 1 Fig- 5.2 Equalizer and Channel Model 1 response at SNR 20dB - 84 - ______________________________________________________________________________ Learning Curve of SNR 20dB 1.4 1.2 LMS RLS Lattice Channel Model 2 0.6 0.5 0.4 0.8 0.3 0.2 0.6 0.1 100 200 300 400 500 600 0.4 0.2 0 100 200 300 400 500 600 Number of Iteration 700 800 900 Fig-5.3 Comparison Leaning Curve of Channel Model 2 at SNR 20dB Channel Response & Equalizer Response 2.5 2 Channel Model 2 LMS RLS Lattice SNR 20dB Channel Model 2 Frequency Response Mean Square Error 1 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 Fig- 5.4 Equalizer and Channel Model 2 response at SNR 20dB - 85 - 1 ______________________________________________________________________________ Learning Curve of SNR 20dB 1.8 LMS RLS Lattice 1.6 0.3 1.4 Channel Model 3 0.2 1 0.15 0.8 0.1 0.6 0.05 0.4 100 200 300 400 500 600 700 0.2 0 0 100 200 300 400 500 600 Number of Iteration 700 800 900 Fig-5.5 Comparison Learning Curve of Channel Model 3 at SNR 20dB Channel Response & Equalizer Response 2.5 2 Channel Model 3 LMS RLS Lattice SNR 20dB Channel Model 3 Frequency Response Mean Square Error 0.25 1.2 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 Fig- 5.6 Equalizer and Channel Model 3 response at SNR 20dB - 86 - 1 ______________________________________________________________________________ Learning Curve of SNR 20dB 0.6 LMS RLS Lattice Channel Model 4 0.22 0.2 0.18 0.16 0.4 0.14 0.12 0.1 0.3 0.08 0.06 0.04 0.2 0.02 0 50 100 150 200 250 0.1 0 100 200 300 400 500 600 Number of Iteration 700 800 900 Fig-5.7 Comparison Learning Curve of Channel Model 4 at SNR 20dB Channel Response & Equalizer Response 4 Channel Model 4 LMS RLS Lattice 3.5 3 Frequency Response Mean Square Error 0.5 2.5 2 SNR 20dB Channel Model 4 1.5 1 0.5 0 0 0.1 0.2 0.3 0.4 0.5 0.6 Normalized Frequency 0.7 0.8 0.9 Fig- 5.8 Equalizer and Channel Model 4 response at SNR 20dB - 87 - 1 ______________________________________________________________________________ 5.2 Observation and Analysis The simulation for comparison study uses the 20dB SNR value. The Fig 5.1, 5.3, 5.5 and 5.7 are the learning curve of channel model 1, 2, 3 and 4 respectively. Based on section 5.1 simulation results, two tables (Table 5.1 Mean Square Error and Table 5.2 Number of Iterations to Converge) are generated. For the Mean Square Error, RLS algorithm gives the smallest error among the three algorithms. RLS algorithm can perform very well in the complex channel (channel model 1) compare to LMS and GAL. When RLS gives error 0.11, LMS and GAL give error 0.3 and 0.26 respectively. It means the error of LMS is 2 times and the error of GAL is 1.5 times higher than RLS algorithm. In the real channel (channel model 2, 3 and 4), the difference of mean square errors are not significant. The performance of all algorithms is same in the real channel model. Mean Square Error Channel Model 1 Channel Model 2 Channel Model 3 Channel Model 4 LMS 0.3 0.27 0.17 0.082 GAL 0.26 0.26 0.15 0.075 RLS 0.11 0.23 0.12 0.062 Table - 5.1 Mean Square Error of LMS, GAL & RLS Algorithms For the rate of convergence, RLS algorithm is the fastest among the three algorithms. In channel model 1 (complex) and channel model 2 & 3 (real), the rate of convergence of RLS algorithm is about the same. Therefore, RLS algorithm supports significant rate of convergence for both complex and real channel model. The channel model 4 converges faster than other three channels because of its simplicity. - 88 - ______________________________________________________________________________ Number of Iterations to Converge Channel Model 1 Channel Model 2 Channel Model 3 Channel Model 4 LMS 600 350 470 250 GAL 550 350 450 220 RLS 75 80 90 25 Table - 5.2 Number of Iterations to Converge in LMS, GAL & RLS Algorithms The Fig 5.2, 5.4, 5.6 and 5.8 show the comparison between channel response and equalizer response of different algorithm. The equalizer response of channel model 3 & 4 is better tracking and gives an approximate inversion of the channel response because of its small error. In the all real channel models, the tracking of RLS and LMS are almost same. In the channel model 1, the equalizer response of RLS gives the best tracking and approximate inversion of the channel model because of the smallest error. - 89 - ______________________________________________________________________________ 5.3 Summary The LMS algorithm has the slowest rate of convergence and high MSE. However, the computational complexity is simple and easily understandable. It uses transversal structure. The LMS algorithm is an important member of the family of stochastic gradient algorithms. The stochastic gradient means it is intended to distinguish the LMS algorithm from the method of steepest descent, which uses a deterministic gradient in a recursive computation. The LMS algorithm does not require measurements of the pertinent correlation functions and matrix inversion. Therefore, this algorithm is simple and standard benchmarked against other algorithms. The GAL algorithm has slightly faster rate of convergence and lower MSE than LMS algorithm. However, the computation is more complex than LMS algorithm. This algorithm uses multistage lattice structure and also a member of the family of stochastic gradient algorithms. The derivation of GAL algorithm involves the investigating Levinson-Durbin algorithm, which computes a set of reflection coefficient and use it directly in the lattice structure. The reflection coefficients provide a very convenient parameterization of many naturally produced information signals. The main advantages of lattice structure are low round off noise in fixed word length implementation and relative insensitivity to quantization noise. - 90 - ______________________________________________________________________________ The RLS algorithm has the fastest rate of convergence and lowest MSE among the three algorithms. The computation is very complex compare to others. The derivation is based on a lemma in matrix algebra known as the matrix inversion lemma. This algorithm uses transversal structure. The fundamental difference between the RLS algorithm and LMS algorithm is the stepsize parameter in the LMS algorithm is replaced by the inverse of the correlation matrix of the input vector in the RLS algorithm. The RLS algorithm has two limitations which are lack of numerical robustness and excessive computational complexity. The selection of algorithm depends on the application of usage. The selection for one application may not be suitable for another. The application require to use better performance and lower error, then it has to pay for high cost such as computational cost, performance and robustness. - 91 - ______________________________________________________________________________ CHAPTER 6 Project Management 6.1 Project Plan and Schedule At the beginning of the project, the proper planning is very important as it contributes the success of the project. Time management factor is the “rule” of having a good graded project. I have to juggle between my project and my full-time job. The proper plan of this project is not only my contribution but also my project supervisor, Dr. Lim, did his part to meet up regularly with me and constantly reminding me as not to have lapsed on the planned schedule. Project tasks are divided into nine sections: 1. Project Selection & Commencement Briefing 2. Literature search 3. Preparation of Capstone Project Proposal 4. Study and Analyze on LMS, RLS and Gradient Adaptive Lattice 5. Preparation of Interim Report 6. Simulation on MATLAB software and Comparison Study 7. Evaluation and Implementation on current disadvantages 8. Preparation for final report 9. Preparation for oral presentation Task 1, schedule for 2 weeks to complete. This task is selecting the project that offer from University. After getting the approval, the school gives briefing on the project relating on all submission dates and rules. Task 2, schedule for 3 weeks to complete. This task is doing literature search of the project after 1st meeting with project supervisor. The literature searches mainly focus on library reference books and online IEEE journals. - 92 - ______________________________________________________________________________ Task 3, schedule for 2 weeks to complete. This task is preparing the proposal that shows how much understand on the project based on literature search. This task is very important because of the judgment on continue the project. Task 4, schedule for 6 weeks to complete. In this task, focus on study and analyze on LMS, RLS and Gradient Adaptive Lattice algorithm that I studied in ENG313 Adaptive Signal Processing module. Task 5, schedule for 3 weeks to complete. In this task, prepare Interim Report and present the progressive of study and analyze process of task 4. Task 6 & 7, schedule for 13 weeks to complete. These two tasks are very important and main tasks for this entire project. Fortunately, these 13 weeks are fall in school holiday. So, I will give more time on simulation and implementation parts. Task 8 & 9, schedule for 14 weeks to complete. In these tasks, prepare final report and oral presentation based on the analysis, simulation and implementation of task 4, 6 & 7. These two tasks also can consider as important task because final report is the show case of the entire project and judge how much effort to put in the project. The project commenced on 19th July 2009 with a submission date on the 17th May 2010. Below Table 6-1 is the Project Task breakdown throughout the few months. - 93 - ______________________________________________________________________________ 6.2 Project Tasks Breakdown and Gantt chart Performance Analysis and Comparison of Adaptive Channel Equalization Technique for Digital Communication System Tasks Description 1. Project Selection & Commencement Briefing 2. Literature Search 2.1 Research on IEEE online journals, relevant reference books 2.2 Analyze and study relevant books and journals 3. Preparation of Capstone Project Proposal 4. Study and Analyze on LMS, RLS & Gradient Lattice 5. Preparation of Interim Report 6. Simulation on MATLAB and Comparison 7. Evaluation and Implementation on current disadvantages 8. Preparation of Final Report 8.1 Writing skeleton of final report 8.2 Writing literature review 8.3 Writing introduction of report 8.4 Writing main body of report 8.5 Writing conclusion of further study 8.6 Finalizing and amendments of report 9. Preparation of oral presentation 9.1 Review and extract important notes for presentation 9.2 Create poster and prepare for presentation Start Date End Date 19-Jul09 2-Aug09 2-Aug09 9-Aug09 23Aug-09 6-Sep09 18-Oct09 8-Nov09 20Dec-09 7-Feb10 7-Feb10 14-Feb10 21-Feb10 28-Feb10 21-Mar10 4-Apr10 18-Apr10 18-Apr10 2-May10 1-Aug09 22Aug-09 8-Aug09 22Aug-09 5-Sep09 17-Oct09 7-Nov09 19Dec-09 6-Feb10 17-Apr10 13-Feb10 20-Feb10 27-Feb10 20-Mar10 3-Apr10 17-Apr10 15May-10 1-May10 15May-10 Table - 6.1 Project Tasks Breakdown - 94 - Duration (weeks) Resources 2 3 1 Library resources (reference books) 2 Web resources (IEEE journals, source codes & related reference books) 2 6 3 6 7 10 1 Personal Computer 1 1 3 2 2 4 2 2 MATLAB Software ______________________________________________________________________________ Table - 6.2 Gantt chart - 95 - ______________________________________________________________________________ CHAPTER 7 REVIEW & REFLECTIONS 7.1 Skills Review For this project, a great deal of knowledge of both mathematical derivations and simulations are required to make it possible. Skills like project management and information researches are greatly enhanced over the period of the entire project. I have to say Project Management skill is the most important in making the project a successful one. I studied PMJ300 Project Management module in the course of study that gives me understanding of the theory. When I am planning and scheduling this project, it gives me full picture of what is the Project Management. The tight schedule of juggling between part time studies and a full time job makes it difficult. These were overcome as proper planning and scheduling were carried out. At the beginning of project, a lot of researches were done over the reference books from Singapore Polytechnic Library and IEEE journals to know more about adaptive channel equalization. A lot of time was spending on Project Overview and Literature Review as of knowing what was already available in the area of study. Mathematical derivation and modeling skills are required for this project which I have studied the skills from the HESZ2001 module. MATLAB programming skill also requires using in simulation of the model to analyze and compare with other model. At the completion of this project, my Project Management skill, Research skill, Mathematical derivation and modeling skill and MATLAB programming skill are significantly improved. - 96 - ______________________________________________________________________________ 7.2 Reflections In this Final Year Project (FYP), SIM University had given me the opportunity to realize my strengths and weakness. There were several problems that I have faced throughout the entire project. My weakness would be the understanding of adaptive signal processing theory at the beginning stage and explanation on simulation results at the end of the project. I believe that my understanding of adaptive signal processing in the course of study was not in depth enough. However, after doing some researches and read up the reference books, I manage to figure out and complete the task. For MATLAB programming, I started by running simple programs like without noise (SNR) and using real value channel model. Then, I edit slowly and research in further simulation, analyzing and comparing what was needed to fulfill the project. My strengths would be the time management and able to source for solutions once I have encounter problems in the project. The time management is actually not easy for the students especially like me having full time job and family. During literature research and preparation proposal period, it has been hard to understand the principles even though various resources are available. However, it was solved step by step consulting with my project supervisor and friends. It proved that I have the strength to solve the issue arose. Upon completion of the project, I am having better understand on my strengths and weakness. - 97 - ______________________________________________________________________________ 7.3 Conclusions The use of an adaptive filter offers a highly attractive solution to the problem as it provides a significant improvement in performance over the use of a fixed filter designed by conventional methods. And the use of adaptive filters also provides new signal processing capabilities. Thus, the adaptive filters have been successfully applied in such diverse fields as communication, control, radar, sonar, seismology and biomedical engineering. The subject of adaptive filters constitutes an important part of signal processing and the applications are used in wide range of area. Therefore, a lot of researchers are still doing further research and implementing on the different algorithms and techniques. I would consider this project is success as I had met the objectives of the project and completed all the tasks that I set in the project proposal. Three different algorithms are studied and analyzed by using mathematical derivation and simulation on MATLAB software. Throughout the duration of the entire project, I had picked up many valuable skills, knowledge and exposure in the field of adaptive signal processing. In the past three and half years in SIM University, my skills and knowledge had been tested as when the problems arise. I have learnt to solve them from various researches and understanding the route of error. Lastly, the project management skill, report writing skill and oral presentation skill would benefit me and enhance me for my future and my career. - 98 - ______________________________________________________________________________ References [1] Simon Haykin, “Adaptive Filter Theory”, Fourth Edition, Prentice-Hall, 2002. [2] Widrow, B., and S.D.Stearns, “Adaptive Signal Processing”, Prentice Hall, 1985. [3] Bellanger, M., “Adpative Digital Filters and Signal Analysis”, Marcel Dekker, 1987. [4] Leon H. Sibul, “Adaptive Signal Processing”, IEEE press, 1987. [5] Odile Macchi, “Adaptive Processing The Least Mean Squares Approach with Applications in Transmission”, John Wiley & Sons, 1995. [6] Michael L.Honig, “Adaptive Filters, Structures, Algorithms and Applications”, Kluwer, 1984. [7] Boca Raton, “Adaptive Signal Processing in Wireless Communications”, CRC, 2009. [8] Jinho Choi, “Adaptive and Iterative Signal Processing in Communications”, Cambridge University Press, 2006. [9] S.Thomas Alexander, “Adaptive Signal Processing, Theory and Applications”, Springer-Verlag, 1986. [10] Patrik Wahlberg, Thomas Magesacher, “LAB2 Adaptive Channel Equalization”, Department of Electrical and Information Technology, Lund University, Sweden, 2007. [11] Janos Levendovszky, Andras Olah, “Novel Adaptive Channel Equalization Algorithms by Statistical Sampling”, World Academy of Science, Engineering and Technology, 2006. - 99 - ______________________________________________________________________________ [12] David Gesbert, Pierre Duhamel, “Unimodal Blind Adaptive Channel Equalization: An RLS Implementation of the Mutually Referenced Equalizers”, IEEE, 1997. [13] Georgi Iliev and Nikola Kasabov, “Channel Equalization Using Adaptive Filtering with Averaging”, Department of Information Science, University of Otago [14] Bernard Widrow and Michael A.Lehr, “Noise Canceling and Channel Equalization”, The MIT PRESS, Cambridge, Massachusetts, London, England [15] Jusak Irawan, “Adaptive Blind Channel Equalization for Mobile Multimedia Communication”, Journal Teknik Elektro Vol. 6, No.2, September 2006: 73 – 78 [16] Muhammad Lutfor Rahman Khan, Mohamed H.Wondimagegnehu and Tetsuya Shimamura, “Blind Channel Equalization with Amplitude Banded Godard and Sato Algorithms”, Journal of Communications, Vol 4, No.6, July 2009. [17] Otaru, M.U.; Zerguine, A.; Cheded, L., “Adaptive channel equalization: A simplified approach using the quantized-LMF algorithm”, IEEE International Symposium on Volume 18, Issue 21, May 2008 Page(s):1136 – 1139,10.1109/ISCAS.2008.4541623 [18] Pedro Inacio Hubscher and Jose Carlos M.Bermudez, “An Improved Statistical Analysis of the Least Mean Fourth (LMF) Adaptive Algorithm”, IEEE Transactions on Signal Processing, Vol 51, No. 3, March 2003. [19] H.C.So and Y.T.Chan, “Analysis of an LMS Algorithm for Unbiased Impulse Response Estimation”, IEEE Transcations on Signal Processing, Vol 51, No. 7, July 2003. - 100 - ______________________________________________________________________________ Appendix – A Signal-Flow Graphs In constructing block diagrams involving matrix quantities, the following symbols are used: a c Σ b The symbol denotes an adder with c = a + b. a + c Σ - b The symbol denotes a subtractor with c = a - b. x h y The symbol denotes a multiplier with y = x h. x(n) Z -1 The symbol denotes the input sample delay operator. - 101 - x(n-1) ______________________________________________________________________________ Appendix – B Abbreviations GAL Gradient-adaptive lattice ISI Inter Symbol Interference LMS Least Mean Square MSE Mean Square Error RLS Recursive Least Square SNR Signal-to-noise ratio VLSI Very large-scale integration - 102 - ______________________________________________________________________________ Appendix – C Principal Symbols use in LMS X(k) Input signal vector Y(k) Output signal vector from transversal filter W(k) Weight vector Wopt(k) Optimal weight vector N(k) Noise vector e(k) Estimated Error d(k) Desired response Mean square error min Minimum mean square error Eigenvalue max Maximum eigenvalue R Auto correlation matrix of X(k) P Cross correlation matrix between d(k) and X(k) Q Eigenvector matrix of R Eigenvalues matrix k Gradient vector Step-size parameter - 103 - ______________________________________________________________________________ Principal Symbols use in RLS X(i) Input signal vector Y(i) Output signal vector from transversal filter W(i) Weight vector wn Optimal weight vector e(i) Estimated Error d(i) Desired response Exponential weighting factor n Cost function Regulation parameter, 0 R(n) Auto correlation matrix z(n) Cross correlation matrix k(n) Gain vector P(n) Inverse of auto correlation matrix, R 1 n n Vector - 104 - ______________________________________________________________________________ Principal Symbols use in GAL am B* am Tap weight (m+1) x 1 vector of a forward prediction error filter of order m Tap weight (m+1) x 1 vector of a backward prediction error filter of order m and their complex conjugate a m1 Tap weight m x 1 vector of a forward prediction error filter of order m-1 B* Tap weight m x 1 vector of a backward prediction error filter of order m a m 1 and their complex conjugate m Constant (reflection coefficient) m,o Optimum reflection coefficient ˆ m (n) Reflection coefficient after replacing the expectation operator with time average operator f m (n) 1 n , n i 1 Forward prediction error produced at the output of the forward predictionerror filter of order m f m1 (n) Forward prediction error produced at the output of the forward predictionerror filter of order m-1 bm (n) Backward prediction error produced at the output of the backward prediction-error filter of order m bm 1 (n 1) Delayed backward prediction error produced at the output of the backward prediction-error filter of order m-1 M Stage of lattice predictor x(n) Sample value of tap input in transversal filter at time n - 105 - ______________________________________________________________________________ x m1 (n) * (m+1) x 1 tap input vector h m (n) Weight vector h m (n 1) Updated weight vector d * (n) Desired response vector h m (n 1) Adjustment weight vector ym (n) Output signal, estimate of desired response d(n) em* (n) Estimation error Step-size parameter Constant (0 1) m The sum of squared forward and backward prediction errors m1 (n) Total energy of both forward and backward prediction errors m Gradient vector Jm Cost function * * - 106 -