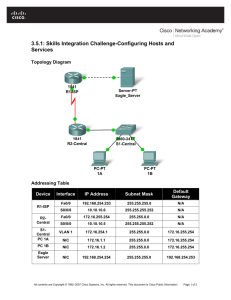
ppa07_for2e_rev2
advertisement

7 Basic Case Scenarios Beginning with this chapter we’ll dig into the real meat of packet analysis as we use Wireshark to analyze real-world network problems. We’ll begin by analyzing scenarios which you might encounter day-to-day as a network engineer, help desk technician, or application developer all derived from my real-world experience and that of my colleagues. Rather than start out with problematic traffic we’ll explore scenarios that involve normal traffic that you probably already generate daily. We’ll user Wireshark to examine traffic from Twitter, Facebook, and ESPN.com to see how these common services work. The second part of this chapter introduces a series of real-world problems. For each, I describe the situation surrounding each problem and offer the same information that was available to the analyst at the time. Having laid the groundwork we’ll turn to analysis as I describe the method used to capture the appropriate packets, and step you through the analysis process. Once analysis is complete I offer a complete a solution to the problem or point you to potential solutions, along with an overview of lessons learned. Throughout, remember that analysis is a very dynamic process and the methods I use to analyze each scenario may not be the same ones that you might use. Everybody analyzes in different ways; the most important thing is that the end result be positive. Social Networking at the Packet Level The first example we will look at is the traffic of two popular social networking websites, Twitter and Facebook. We will examine the authentication process associated with each service and see how two very similar services use two separate methods for performing the same task. We will also look at how some of the primary functions of each service works in order to gain a better understanding of the traffic we generate in our normal daily activities. Twitter Authentication One of the first things I do when I get to the office is check my Twitter feed. Whether you use Twitter to stay up to date on news in the tech community or just to complain about how mad you are at your girlfriend, it’s one of the more commonly used services on the Internet. For this scenario, you’ll find a capture of Twitter traffic in the file twitter_login.pcap. The Login Process When I teach packet analysis one of the first things I have my students do is log into a website they normally use and capture the traffic from the login process. This serves a dual purpose: it exposes the individual to more packets in general and allows them to discover insecurities in their daily activity by looking for clear text passwords traversing the wire. Fortunately, the Twitter authentication process is not completely insecure as we can see in the first few packets in the capture. As you can see in Figure 7-1, these first three packets constitute the TCP handshake between our local device (172.16.16.128) and a remote server (168.143.162.68) . The remote server is listening for our connection on port 443 , which is typically associated with SSL over HTTP, commonly referred to as HTTPS, a secure form of data transfer. Based upon this alone we can assume that this is SSL traffic. Figure 7-1: Handshake connecting to port 443 The packets that follow the handshake are part of the SSL encrypted handshake. SSL relies upon keys, which are strings of characters used to encrypt and decrypt communication between two parties. The handshake process is the formal transmission of these keys between hosts as well as the negotiation of various connection and encryption characteristics. Once this handshake is completed, secure data transfer begins. In order to find the encrypted packets that are handling the exchange of data look for the packets that say “Application Data” in the Info column of the packet details window. Expanding the SSL portion of any of these packets will display the Encrypted Application Data field, containing the unreadable encrypted data , as shown in Figure 7-2. This shows the transfer of the username and password during log in. Figure 7-2: Encrypted credentials being transmitted The authentication continues briefly until the connection begins its teardown process with a FIN/ACK at packet 16. Following authentication we would expect our browser to be redirected to our Twitter homepage, which is exactly what happens. As you can see in Figure 7-3, packets 19, 21, and 22 are part of the handshake process that sets up a new connection to the same remote server (168.143.162.68 ) but on port 80 instead of 443 . Following the completed handshake we see the HTTP GET request in packet 23 for the root directory of the web server (/) and the contents of the homepage at 172.16.16.128 in packet 24 . Figure 7-3: The GET request for the root directory of our Twitter homepage(/) once authentication has completed Sending Data with a Tweet Having logged in the next step is to tell the world what’s on our mind. Because I’m in the middle of writing a book I’ll tweet “I’m writing a book right now” and capture the traffic from posting that tweet in the file twitter_tweet.pcap. This capture file starts immediately after the tweet has been submitted. It begins with a handshake between our local workstation 172.16.16.134 and the remote address 168.143.162.100. The fourth and fifth packets in the capture comprise an HTTP packet sent from client to server. To examine this HTTP header expand the HTTP section in the packet details window of the fifth packet as shown in Figure 7-4. When you do you will immediately see that the POST method is used with the URL /status/update , as shown in Figure 7-4. We know that this is indeed a packet from the tweet because the host field contains the value twitter.com . Figure 7-4: The HTTP POST for a Twitter update Notice the information contained in the packet’s Line-based text data section shown in Figure 7-5. When you analyze this data you will see a field named authenticity token followed by a “status=” field in a URL containing the value: This+is+a+tweet+for+practical+packet+analysis%2c+second+edition The value of the status field is the tweet I’ve submitted in unencrypted, clear text. Figure 7-5: The tweet in clear text There is some immediate security concern here because some people protect their tweets and don’t intend for them to be seen by just anybody. Twitter Direct Messaging Let’s consider a scenario which has even greater security implications with the Twitter direct messaging feature (which allows one user to send presumably private direct messages to another. The file twitter_dm.pcap is a packet capture of a Twitter direct message. As you can see in Figure 7-6, direct messages aren’t exactly private. The display of packet 7 in Figure 7-6 shows that content is still sent in cleartext. This can be seen by examining the same Line-based text data field that we viewed in the previous capture. Figure 7-6: A Direct messages in the clear The knowledge that we gain here about Twitter isn’t necessarily earth shattering, but it may make you reconsider sending sensitive data via private Twitter messages over untrusted networks. Facebook Authentication Once I’ve finished reading my tweets I like to login to Facebook to see what my friends are up to so that I can live vicariously through them. As with our last example we’ll use Wireshark to capture Facebook traffic. We’ll begin with the login process captured in facebook_login.pcap. The capture begins as soon as credentials are submitted, and much like the capture of the Twitter login process, this capture begins with a TCP handshake over port 443 . Our workstation at 172.16.0.122 is initiating communication with 69.63.180.173 , the server handling the Facebook authentication process. Once the handshake completes the SSL handshake occurs and login credentials are submitted as shown in Figure 7-7. Figure 7-7: Login credentials are transmitted securely with HTTPS One difference between the Facebook authentication process and the Twitter one is that we see don’t immediately see the authentication connection teardown following the transmission of login credentials. Instead, we see a GET request for /home.php in the HTTP header of packet 12 , as highlighted in Figure 7-8. Figure 7-8: After authentication, the GET request for /home.php takes place But when will the authentication connection be torn down? After the content of home.php has been delivered as you can see with packet 64 at the end of the capture file. First the HTTP connection over port 80 is torn down (packet 62) and then the HTTPS connection over port 443 is torn down as shown in Figure 7-9. Figure 7-9: The HTTP connection is torn down followed by the HTTPS connection Facebook Private Messaging Now that we’ve examined its login authentication process let’s examine how Facebook handles private messaging. The file facebook_message.pcap contains the packets captured while sending a message from my account to another Facebook account. When you open this file you may be surprised by the few packets it contains. The first two packets comprise the HTTP traffic responsible for sending the message itself. When you expand the HTTP header of packet 2 (as shown in Figure 7-10) you will see the POST method is used with a rather long URL string as highlighted in the figure. As you can see, the string includes a reference to AJAX. Figure 7-10: This HTTP POST references AJAX which may explain the low number of packets seen here AJAX stands for asynchronous JavaScript and XML and is a client-side approach to creating interactive web applications that retrieves information from a server in the background. While you might expect that after the private message is sent to the client’s browser the session would be redirected to another page (as with the Twitter direct message), but that’s not the case. In this case, the use of AJAX probably means that the message is sent from some type of interactive pop-up rather than from an individual page, which means that no redirection or reloading of content is necessary (one of the features of AJAX). You can examine the content of this private message by expanding the line-based text data portion of packet 2 as shown in figure 7-11. Just like with Twitter it appears as though Facebook’s private messages are also sent unencrypted. Figure 7-11: The content of this Facebook message is seen in clear text We’ve now seen the authentication and messaging methods of two different web services, Twitter and Facebook, each of which takes a different approach. The choice of method can be a matter of opinion depending on your perspective. As for the authentication methods chosen, programmers might argue that the Twitter method is better because it can be faster and more efficient whereas security researchers may argue the Facebook method is more secure because it ensures that all content has been delivered and no additional authentication is required before the authentication connection closes, which may in turn make man-in-the-middle attacks (attacks where malicious users intercept traffic between two communicating parties) more difficult to achieve. We’ve examined two similar web services which operate in a much different manner with varying techniques and technologies used for their authentication methods and messaging features. The point of this analysis was not to find out exactly how Twitter and Facebook work, but simply to expose you to traffic that you can compare and contrast. This baseline should provide a good framework should you need to examine why similar services aren’t operating as they should, or are just operating slowly. ESPN Having completed my social network stalking for the morning my next task is to check up on the latest news headlines and sports scores from last night. Certain sites always make for interesting analysis and http://espn.com is one of those. I’ve captured the traffic of a computer browsing to the ESPN website in the file http_espn.pcap. This capture file contains many packets, 956 to be exact. This is simply too much data for us to manually scroll through the entire file in an attempt to discern individual connections and anomalies, so we will use some of Wiresharks analysis features to make the process easier. The ESPN home page includes a lot of bells and whistles so it’s easy to understand why it would take nearly 1000 packets to transfer that data to us. Whenever you have a large data transfer occurring its useful to know the source of that data, and more importantly, whether it’s from one or multiple sources. We can find out by using Wireshark’s conversations window (Statistics Conversations), as shown in figure 7-12. As you can see in the top row of this window there are 14 unique IP conversations, 25 unique TCP connections, and 14 unique UDP conversations, all of which are displayed in detail in the Conversations main window. There’s a lot going on here, especially for just one site. Figure 7-12: The conversations window shows several unique connections For a better view of the situation we can see the application layer protocols used with these TCP and UDP connections. Open the Protocol Hierarchy window (Statistics Protocol Hierarchy) as shown in figure 7-13. Figure 7-13: The protocol hierarchy window shows us the distribution of protocols in this capture As you can see at , TCP accounts for 97.07 percent of the packets in the capture and at that UDP accounts for the remaining 2.93 percent. As expected the TCP traffic is all HTTP, which is broken down even further into the file types transferred over HTTP. It may be confusing stating that all of the TCP traffic is HTTP when it only shows 12.66% as being TCP, but that’s because the other 87.34% is pure HTTP traffic (data transfer and control packets). All of the UDP traffic that is shown is DNS, based upon then entry under the UDP heading (). Based upon this information alone we can draw a few conclusions. For one, we know from previous examples that DNS transactions are quite small so the fact there are 28 DNS packets (as listed in the Packets column next to the Domain Name Service entry in Figure 7-13) means that we could have as many as 14 DNS transactions (divide the total number of packets by two, representing pairs of requests and responses). DNS queries don’t happen on their own though, and the only other traffic in the capture is HTTP traffic, so this tells us that it’s likely that the HTML code within the ESPN website references other domains or subdomains by DNS name, thus forcing multiple queries to be executed. Let’s see if we can find some evidence to substantiate our theories. One simple way to view DNS traffic is to create a filter. Entering dns into the filter section of the Wireshark window shows all of the DNS traffic, displayed in Figure 7-14. Figure 7-14: The DNS traffic appears to be standard queries and responses This DNS traffic shown in Figure 7-14appears to all be queries and responses. For a better view of the DNS names being queried we can create a filter that displays only the queries. To do this: Select a query in the packet list window Expand the packet’s DNS header in the packet details window Right click the Flags: 0x0100 (Standard query) field Hover over Apply as Filter, and choose Selected. This should activate the filter dns.flags == 0x0100, which shows only the queries and makes it much easier to read the records we’re analyzing. And, as we can see in Figure 7-14, there are indeed 14 individual queries (each packet represents a query), and all of the domain names seem to be associated with ESPN or the content displayed on its home page. Finally, we can verify the source of these queries by examining the HTTP requests. To do so, Select Statistics from the main drop-down menu Go to HTTP, select Requests, and click Create Stat (Make sure the filter you just created is cleared before doing this.) Figure 7-15: All HTTP requests are summarized in this window showing domains accessed The HTTP Requests window is seen in Figure 7-15.There are a variety of requests here and these account for the DNS queries we saw a few moments ago. There are exactly 14 connections here (each line represents a connection to a particular domain) so this accounts for all of the domains represented by the DNS queries. With this many connections occurring it may be in our best interest to make sure that this highly involved process is occurring in a timely manner. The easiest way to do this is view a summary of the traffic. In order to do this: Choose Statistics from the drop-down menu, and select Summary. This summary is seen in figure 7-16 and points out that the entire process occurs in about two seconds , which is perfectly acceptable. Figure 7-16: The Summary of the file tells us that this entire process occurs in two seconds It’s odd to think that our simple request to view a webpage broke into requests for fourteen separate domains and subdomains touching a variety of different servers, and that this whole process took place in only two seconds. No Internet Access 1 The first problem scenario is rather simple; a user cannot access the Internet. You have had the user verify that they cannot access any website on the Internet. The user can access all of the internal resources of the network including shares on other workstations and applications hosted on local servers. The network architecture is fairly simple as all clients and servers connect to a series of simple switches. Internet access is handled through a single router serving as the default gateway, and IP addressing information is provided by DHCP. Tapping into the Wire In order to determine the cause of the issue we can have the user attempt to browse the Internet while our sniffer is listening on the wire. The network architecture here is very simple. Using Figure 2-15 introduced in chapter two as a reference we can determine the most appropriate method for placing our sniffer. The switches on our network do not support port mirroring. We are requiring the user to perform a manual process in order to fully test the scenario we can assume that it is okay to take the user offline briefly. Having access to a tap this would be the most appropriate method for tapping into the wire. The resulting file is nowebaccess1.pcap. Analysis The traffic capture begins with an ARP request and reply, seen in figure 7-17. In packet 1 the user’s computer, having a MAC address of 00:25:b3:bf:91:ee and an IP address of 172.16.0.8, sends an ARP broadcast packet to all computers on the network segment in an attempt to find the MAC address associated with the IP address of its default gateway, 192.168.0.10. Figure 7-17: ARP request and reply for the computers default gateway A response is received in packet 2 and the user’s computer learns that 172.16.0.10 is at 00:24:81:a1:f6:79. Once this reply is received the computer now has a route to a gateway that should be able to direct it to the Internet. Following the ARP reply, the computer must attempt to resolve the DNS name of the website to an IP address using DNS in packet 3. The computer does this by sending a DNS query packet to its primary DNS server, 4.2.2.2 (Figure 7-18). Figure 7-18: A DNS query sent to 4.2.2.2 Under normal circumstances a DNS query would be responded to very quickly with a response from the DNS server. In this case that doesn’t happen. Rather than a response, we see the same DNS query sent out a second time to a different destination address. In packet 4 the second DNS query is sent to the secondary DNS server configured on the computer, which is 4.2.2.1 (Figure 7-19). Figure 7-19: A second DNS query sent to 4.2.2.1 Again, no reply is received from the DNS server and the query is sent again a second later to 4.2.2.2. This process repeats itself, alternating the destination packets between the primary and secondary configured DNS servers over the next several seconds. The entire process takes around eight seconds , which is how long it is takes before the Internet browser on the user’s computer reports that a website is inaccessible (Figure 7-20). Figure 7-20: DNS queries repeated until communication stops Based upon the packets we’ve seen we can begin pinpointing the source of the problem. We see a successful ARP request to what we believe is the default gateway router for the network so we that device is online and communicating. We also know that the user’s computer is actually transmitting packets on the network so we can assume there isn’t an issue with the protocol stack on the computer itself. The problem clearly begins to occur when the DNS request is made. In the case of this network, DNS queries are resolved by an external server on the Internet (4.2.2.2 or 4.2.2.1). This means that in order for resolution to take place correctly our router responsible for routing packets to the Internet must successfully forward the DNS queries to the server, and the server must respond back. This all has to happen before the HTTP protocol can be used to request the webpage itself. Based upon the context of our scenario we know that no other users are having issues connecting to the Internet, therefore the network router and remote DNS server don’t appear to be the source of the problem. The only thing remaining is the potential for a problem on the user’s computer itself. Upon deeper examination of the computer it is eventually found that rather than receiving a DHCP assigned address, the computer has manually assigned addressing information and the default gateway address is actually set to the wrong address. The address set as the default gateway was not a router and was incapable of forwarding the DNS query packets outside of the network. Lessons Learned The problem presented in this scenario was a result of a misconfigured client. The issue itself is quite simple but had a significant impact on the user’s workflow. Although a simple misconfiguration, in a troubleshooting scenario this could take quite some time to realize without the ability to perform a quick analysis like we’ve done here. It’s important to keep in mind that the use of packet analysis is not limited to large complex problems. We didn’t enter the scenario knowing the IP address of the networks gateway router, so Wireshark didn’t tell us exactly what the problem was, but it did tell us where to look which saved valuable time. Rather than examining the gateway router, contacting our ISP, or trying to find the resources to troubleshoot the remote DNS server we were able to focus troubleshooting on the computer itself. In a scenario where we were more familiar with the IP addressing scheme of the network the analysis would have been even faster. The problem could have been identified immediately once it was noticed that the ARP request was sent out to an IP address different than that of the gateway router. These simple misconfigurations are often the source of many network problems and can often be resolved more quickly with a bit of analysis at the packet level. No Internet Access 2 Once again we have a user who is unable to access the Internet from their workstation. We have had the user further test this issue and unlike the user in the last scenario, this user is actually able to access the Internet, they are just unable to access http://www.google.com, which is currently set to their homepage. Any other website is accessible, but when the user attempts to go to any domain hosted by Google they are directed to a browser page that says “Internet Explorer cannot display the webpage.” This issue is only affecting this individual user. Once again, this is a simple network with a few simple switches and a single router serving as the default gateway. Tapping into the Wire This scenario will require us to recreate the problem situation by having the user attempt to browse to http://www.google.com while we listen to the traffic that is generated. The network architecture presents the same situation as the previous scenario so we will once again connect a tap to the device in question in order to capture the traffic we need. The file that is created is called nowebaccess2.pcap. Analysis The capture begins with an ARP request and reply, seen in figure 7-21. In packet 1 the user’s computer, having a MAC address of 00:25:b3:bf:91:ee and an IP address of 172.16.0.8, sends an ARP broadcast packet to all computers on the network segment in an attempt to find the MAC address associated with the IP address of the host 192.168.0.102. This IP address is not the gateway router for the network segment and as of now is unknown to us. Figure 7-21: ARP request and reply for another device on the network A response is received in packet 2 and the user’s computer learns that 172.16.0.102 is at 00:21:70:c0:56:f0. Based on the last scenario, we would assume that this is the address of the gateway router so that packets can once again be forwarded to the external DNS server. In this case however, the next packet that is transmitted is not a DNS request. The first packet immediately following the ARP transaction is a TCP packet from 172.16.0.8 to 172.16.0.103 with the SYN flag set (Figure 7-22). Figure 7-22: TCP SYN packet sent from one internal host to another The SYN flag set in this TCP packet indicates that this is the first packet in the handshake process for a new TCP-based connection between the two hosts . Notably, the TCP connection that is attempting to be initiated is to port 80 on 172.16.0.102 . We know that port 80 is typically associated with HTTP traffic. This connection attempt to port 80 is abruptly halted when the host 172.16.0.102 sends a TCP packet in response (packet 4) with the RST and ACK flags set (Figure 7-23). Figure 7-23: TCP RST packet sent in response to the TCP SYN As we learned in chapter six, a packet with the RST flag set is used to terminate a TCP connection. In this case, the host at 172.16.0.8 attempted to establish a TCP connection to the host at 172.16.0.102 on port 80, but that host does not have any services configured to listen to requests on port 80. As a result of that, the TCP RST packet was sent to terminate the connection. This process repeats twice more with a SYN being sent from the user’s computer and being responded to with a RST before communication finally ends (Figure 7-24). It is at this point that the user receives a message in their browser saying that the page cannot be displayed. Figure 7-24: The TCP SYN and RST packets are seen three times in total In troubleshooting this scenario we will once again try to narrow down where we think the problem might lie. The ARP request and reply that are seen in packets one and two do present a bit of a concern since the ARP request is not for the MAC address of the gateway router, but rather, some other device that is of unknown origin to us. This is peculiar, but doesn’t give us enough information to come to a conclusion just yet. After the ARP request and reply in the communication we would expect to see a DNS query sent to our configured DNS server in order to find the IP address associated with www.google.com, but we don’t. Whenever you expect to see a particular sequence of events in a packet capture and you don’t you must examine the conditions that would cause that event to happen and ensure that your situation meets those criteria. Conversely, you must also examine the conditions that would prevent that event from happening to ensure your situation does not meet any of those criteria. In this case, a DNS query would normally happen when an application attempts to communicate to a device based upon its DNS name. The DNS name must be resolved to an IP address so that lower level protocols can address the data properly and get it to its destination. Our situation meets that criteria, so based upon that information alone there should be a DNS query present. Examining things from the other side we consider conditions which would prevent a DNS query from being made. There are two of these conditions. First, a DNS request will not be made if the device initiating the connection already has the DNS name to IP address mapping in its DNS cache. Secondly, a DNS query will not be made if the device connecting to the DNS name already has the DNS to IP address mapping manually specified explicitly in its hosts file. In this case, the problem does indeed lie in the fact that a DNS query is never sent. Both conditions which would prevent the DNS query from being sent would be a result of an issue with the computer initiating the communication. Upon further examination of the client computer it is found that the hosts file on the computer has an entry for www.google.com, associating it to the internal IP address 172.16.0.102. This erroneous entry is the source of the user’s problems. A computer will typically refer to its hosts file as an authoritative source for DNS name to IP address mappings and will check it first before querying an outside source. In this case the user’s computer checked its host file and found the entry for www.google.com in that file. Once it did that it presumed that www.google.com was actually on its own local network segment and it sent an ARP request for that host, received a response, and attempted to initiate a TCP connection to it on port 80. The remote system was not configured as a web server and would not accept the connection attempts. Once the hosts file entry was removed, the user’s computer began communicating correctly and was able to access www.google.com. You can examine you hosts file manually on a Windows system by opening C:\Windows\System32\drivers\etc\hosts, or on a Linux system by viewing /etc/hosts. This scenario is actually very common and is a technique that malware has been using for years to redirect users to websites hosting malicious code. Imagine if an attacker were to modify your host file so that every time you went to do your online banking it actually redirected you to a fake site that had been setup to steal your account credentials! Lessons Learned As you begin analyzing traffic more you will begin to learn the nuances of protocols. Not only will you learn what makes them work, but in cases like this one, you will learn what can keep them from working. Here, the DNS query not being sent was no fault of the network router, the remote web server, or even the DNS server. Rather, the misconfigured client was to blame. Examining this issue at the packet level allowed us to quickly recognize some key items that would not have been known to us otherwise. We were able to quickly spot an IP address that was unknown and also we were able to quickly determine that DNS, a key component for this communication process, was missing in the communication sequence. Using those pieces of information the client was identified as the source of the problem and a thorough check of its configuration could ensue. No Internet Access 3 One last time, we’ve encountered a user complaining of not having Internet access from their workstation. This user was able to narrow this issue down to a single website rather than the entire Internet and it appears that the user is unable to access http://www.google.com. Upon further investigation you’ve found that this issue is not limited to this individual user, but rather, nobody in the organization can access Google domains. The network has the same characteristics as the last two scenarios we’ve looked at. Tapping into the Wire This issue will require us to browse to http://www.google.com in order to generate traffic so we can troubleshoot the issue. This issue is network-wide, which means it is also affecting your computer as the IT administrator. At this point in the game you can’t necessarily rule out something like a massive malware infection so it isn’t a best practice to sniff directly from your device. In a situation like this where you cannot trust any device connected to the network a tap is once again the best solution because it allows us to be 100% passive after a brief interruption of service. The file created from this capture is nowebaccess3.pap. Analysis This packet capture begins with DNS traffic instead of the ARP traffic we are used to seeing. The first packet in the capture is to an external address and there is a reply from that address in packet two, so we can assume that the ARP process has already happened and the MAC to IP address mapping for our gateway router already exists in the ARP cache of the host at 172.16.0.8. The first packet in the capture is from the host 172.16.0.8 to the destination address 4.2.2.1 and is a DNS packet . Examining the contents of the packet, you will see that it is a query for the A record for www.google.com , seen in figure 7-25. Figure 7-25: DNS query for www.google.com A record The response to the query is received from 4.2.2.1 and is the second packet in the capture file, seen in figure 7-26. If you examine the packet details window you will see that the name server that responded to this request provided multiple answers to the query . At this point, all is well and communication is occurring as it should. Figure 7-26: DNS reply with multiple A records Now that the user’s computer has determined the IP address of the web server it can attempt to communicate with it. This process is initiated in packet three (Figure 7-27), which is a TCP packet sent from 172.16.0.8 to 74.125.95.105 . This destination address comes from the first A record provided in the DNS query response seen in packet two. The TCP packet that is sent has the SYN flag set , and it attempting to communicate to the remote server on port 80 . Figure 7-27: SYN packet attempting to initiate a connection on port 80 Based upon our knowledge of what the TCP handshake process should look like we would expect a TCP SYN/ACK packet to be sent in response. Instead of what is expected, a short duration of time elapses and another SYN packet is sent from source to destination. This process occurs one more time after approximately a second (Figure 7-28), and communication stops and the browser presents a message stating that the website could not be found. Figure 7-28: The TCP SYN packet is attempted three times in total with no response received In troubleshooting this scenario we know that workstation within our network are able to connect to the outside world because the DNS query to our external DNS server at 4.2.2.1 is successful. The DNS server responds with what appears to be a valid address and our hosts attempt to connect to one of those addresses. The local workstation we are attempting the connection from appears to be functioning as it should based upon this information. The remote server simply isn’t responding to our connection requests. In this case you would typically expect a TCP RST packet to be sent but that doesn’t happen here. There are a multitude of reasons that this might be occurring such as a misconfigured web server, a corrupted protocol stack on the web server, or a packet filtering device on the remote network (such as a firewall). These are all things that are on the remote network and are out of our control. In this case, the web server was not functioning correctly and nobody attempting to access it was able to do so. When the problem was corrected on Google’s end, communication was able to proceed as it should. Lessons Learned In this scenario the problem was not something that was in our power to correct. Our analysis determined that the issue was not with any of the hosts on our network, our router, or the external DNS server providing name resolution services to us. The issue lied outside of our network infrastructure. The cause of the problem wasn’t apparent, but sometimes finding out that the problem isn’t really OUR problem can not only relieve some stress, but can also save face when management comes knocking. I have fought with many ISP’s, vendors, and software companies who will claim that an issue is not their fault, but packets never lie and this scenario is a great example of that. Inconsistent Printer This scenario begins with a call from your IT help desk administrator who is having trouble resolving a printing issue. He has received multiple calls from users in the sales department who are reporting that the high volume sales printer in functioning inconsistently. Whenever a user sends a large print job to the printer it will print several pages and will unexpectedly stop printing before the job is done. Multiple driver configuration changes have been attempted with no positive result. The help desk staff is requesting that you take a look at the issue to ensure that this isn’t a network problem. Tapping into the Wire The common thread in relation to this problem is the printer, so we want to place our sniffer as close to the printer as we can. Obviously, we cannot install Wireshark on the printer itself. In this scenario, the switches used in the network are advanced layer three switches so we can use port mirroring. The port that the printer is connected to will be mirrored to an empty port that we will plug a laptop with Wireshark installed into. Once this is done, a user will attempt to send a large print job to the printer and the output will be monitored. The capture file that results is called inconsistent_printer.pcap. Analysis A TCP handshake between the network workstation sending the print job (172.16.0.8) and the printer (172.16.0.253) initiates the connection at the start of the capture file. Following the handshake there is a TCP packet containing data sent to the printer (Figure 7-29) containing 1460 bytes of data . The amount of data can be seen in the far right side of the Info column in the packet list window, or at the bottom of the TCP header information in the packet details window. Figure 7-29: Data being transmitted to the printer over TCP Following packet four, another data packet is sent containing 1460 bytes of data (Figure 730). This data is acknowledged by the printer , and the process continues with data being sent and acknowledgements sent in reply. Figure 7-30: Normal data transmission and TCP acknowledgements The flow of data continues normally as you continue through the packet capture until you get to the last two packets in the capture. Packet 121 is a TCP retransmission packet which is the first sign of trouble, seen in figure 7-31. Figure 7-31: These TCP retransmission packets are a sign of a potential problem A TCP retransmission packet is sent whenever a device sends a TCP packet to another device and the remote device never sends an acknowledgement back to indicate that the data is received. Once a retransmission threshold is met the sending device assumes that the remote device never received the data and retransmits. This will occur a few times before the communication process effectively stops. The mechanics and calculation of this timeout period will be discussed in more detail in the next chapter. The retransmission here is sent from the client workstation to the printer indicating that the printer never sent an acknowledgement back for data that was transmitted to it. If you expand the SEQ/ACK analysis portion of the TCP header along with everything listed under it you can view the details of why this is a retransmission. According to the SEQ/ACK analysis details processed by Wireshark, packet 121 is actually a retransmission of packet 120 . Additionally, the retransmission timeout (RTO) for the packet being retransmitted was around 5.5 seconds . When analyzing the delay between packets you will become very familiar with changing the time display format you are using in order to make it more appropriate for your situation. In this case, we are curious to see how long the retransmissions occurred after the previous packet was sent so we will change this option. Select View from the main drop-down menu Go to Time Display Format Select Seconds Since Previous Captured Packet. Once you do this you should be able to clearly see that the retransmission in packet 121 occurs 5.5 seconds after the original packet (packet 120) was sent (Figure 7-32). Figure 7-32: Viewing the time between packets is useful for troubleshooting The next packet is another retransmission of packet 120. The RTO of this packet is 11.10 seconds, which includes the 5.5 seconds from the RTO of the previous packet. Viewing the time column of the packet list window it appears as though this retransmission was sent 5.6 seconds after the previous retransmission. This appears to be the last packet in the capture file. The printer stops printing at approximately this time. In this analysis scenario we have the benefit of only dealing with two devices inside of our own network, so we just have to determine whether it is the client workstation or the printer to blame. We can see that data is flowing correctly for quite some time and then at some point the printer simply stops responding to the workstation. The workstation gives its best effort to get the data to its destination as is evident by the retransmissions, but the printer simply stops responding. This issue is reproducible and happens regardless of which computer sends a print job so we have to assume the printer is the source of the problem. After further analysis of the printer it is eventually found that the RAM in the printer was malfunctioning. Any time large print jobs were sent to the printer it would print a random number of pages, likely until certain regions of memory were accessed, and then the memory issue would cause the printer to be unable to accept any new data at which point it would stop communication with the host transmitting the print job. Lessons Learned Although this printer issue was by no means a result of a network issue we were able to use Wireshark and analyze the TCP-based data stream to pinpoint the location of the problem. This scenario centered solely on TCP traffic rather than DNS or HTTP like previous scenarios which means we had to rely solely upon the troubleshooting functions of the TCP protocol. Luckily for us, TCP is a very well designed protocol and will often leave us some useful information when two devices simply stop communicating. In this case when communication abruptly stopped we were able to pinpoint the exact location of the problem based on nothing more than TCP’s builtin retransmission functionality. As we continue through other scenarios we will rely on functionality just like this to troubleshoot other and more complex issues. Stranded in a Branch Office In the past it was common for larger organizations to treat remote branch office locations as separate entities from an IT standpoint due to the complexities and cost of setting up a large wide area network (WAN). Now that the deployment of a WAN has become much more cost effective it is in the best interest of most companies to roll branch offices into the same network deployment that encompasses central office locations. Although this can be a money saving effort it does bring additional complexities into the configuration and management of the networks different components, which is what this scenario is centered on. Our example company consists of a central headquarters (HQ) office and a newly deployed remote branch office locations. The companies IT infrastructure is mostly contained within the central office. The company operates using a Windows Server-based domain which will be extended to the branch office by using a secondary domain controller. The domain controller is responsible for handling DNS and authentication requests for users at the branch office. The domain controller is a secondary DNS server and should receive its resource record information from the upstream DNS servers at the corporate headquarters. Your deployment team is currently rolling out the new infrastructure to the branch office when you’ve found out that nobody is able to access any of the intranet web application servers on the network. These servers are located at the main office and are accessed through the WAN connection. This issue is affecting all of the users at the branch office, and is limited to just these internal servers. All users are able to access the Internet and other resources within the branch. Tapping into the Wire The problem lies in communication between the main and branch offices so there are a couple of places we could collect data from to start tracing down the problem. The problem could be with the clients inside the branch office, so we will start by port mirroring one of those computers to see what it sees on the wire. Once we’ve collected information we can use it to point towards other collection points which might help us solve the problem. The initial capture file obtained from one of the clients is called stranded_clientside.pcap. This is a complicated scenario involving multiple sites, so a simplified network map has been made available to us in figure 733. Figure 7-33: The network map shows all of the relevant components for this issue Analysis The first capture file we are examining begins when the user at the workstation address 172.16.16.101 attempts to access an application hosted on the HQ App Server, 172.16.16.200. This capture is very small and only contains two packets. It appears as though a DNS request is sent to 172.16.16.251 for the A record for “AppServer” in the first packet (Figure 7-34). This is the DNS name for the server at 172.16.16.200 in the central office. Figure 7-34: Communication begins with a DNS query for the AppServer ‘A’ record The response to this packet is not the typical DNS response we would expect. The response is a server failure , which indicates that there is something preventing the DNS query from completing successfully (Figure 7-35). Notice also that this packet does not contain any answers to the query since it is an error. Figure 7-35: The query response indicates a problem upstream We now know that communication between the users at the branch office and HQ is not occurring because of some DNS related issue. The DNS queries at the branch office are resolved by the DNS server at the address 172.16.16.251, so that’s our next stop. In order to capture the appropriate traffic from the branch DNS server we will leave our sniffer in place and simply change the port mirroring assignment so that the server traffic is mirrored to our sniffer instead of the workstation, resulting in the file stranded_branchdns.pcap. This file begins with the query and response we saw earlier along with one additional packet. This packet looks a bit odd because it is attempting to communicate to the primary DNS server at the central office (172.16.16.250) on the standard DNS server port 53 , but it is not UDP like we are used to seeing (Figure 7-36). Figure 7-36: This SYN packet uses port 53 but is not UDP In order to figure out the purpose of this packet we must think back to our discussion of DNS in chapter six. DNS uses UDP almost exclusively, but it does use TCP in a couple of cases. TCP is used when the response to a query exceeds a certain size, but in those cases we will see some initial UDP traffic that is the stimulus to the TCP traffic. The other instance when TCP is used for DNS is a zone transfer where resource records are transferred between DNS servers. This is likely the case here as it fits our scenario. The DNS server at the branch office location serves as a slave to the DNS server at the central office, meaning that it relies upon it in order to receive resource records. The application server that users in the branch office are trying to access is located inside the central office, which means that the central office DNS server is authoritative for that server. In order to the branch office server to be able to resolve a DNS request for the application server the DNS resource record for that server must be transferred from the central office DNS server to the branch office DNS server. This is likely the source of the SYN packet in this capture file. Now we know that this DNS problem is a product of a failed zone transfer between the branch and central office DNS servers. This is quite a bit more information than we had before, but we can go one step farther by figuring out why the zone transfer is failing. The possible culprits for the issue can be narrowed down to the routers between the offices or the central office DNS server itself. In order to figure this out we can sniff the traffic of the central office DNS server to see if the SYN packet is even making it to the server. I’ve not included a capture file for the central office DNS server traffic because there was none. The SYN packet never reached the server. Upon dispatching technicians to review the configuration of the routers connecting the two offices it was found that the central office router was configured to only allow UDP traffic inbound on port 53 and block TCP traffic inbound on port 53. This simple misconfiguration prevented zone transfers from occurring between servers which prevented clients within the branch office from resolving queries for devices in the central office. Lessons Learned You can learn a lot about investigation of a network communications issue by watching crime dramas on TV. Whenever a crime occurs the detectives will start directly at the source and interview those most affected by the situation. Based upon that examination leads are developed which further focus the efforts of the investigation. This process continues until a culprit is hopefully found. This scenario was a great example of that. We started by examining the victim (the workstation) and established leads by finding the DNS communication issue. Our leads led us to the branch DNS server, then to the central DNS server, and finally to the router that was the source of the problem. When you are doing analysis try thinking of packets as potential clues. The clues don’t always tell you who committed the crime, but through a few degrees of separation you can get there eventually. Ticked off Developer Some of the most common arguments that occur in information technology are those between developers and system administrators. Developers always blame shoddy network setup and malfunctioning equipment for program malfunctions and system administrators tend to blame bad code for network errors and slow communication. This scenario is no different and is focused on a dispute between a programmer and a sysadmin. The programmer in our scenario has developed an application that is responsible for tracking the sales of multiple stores and reporting back to a central database. In an effort to save bandwidth during normal business hours this is not a real-time application. Reporting data is accumulated throughout the day and is transmitted at night in the form of a comma separated value (CSV) file that can be received by the application and processed for insertion into the database. This is a newly developed application and is not functioning as it should be. The files being sent from the stores are being received by the server but the data being inserted into the database is not correct. Sections of data are missing, data is in the wrong place, and some portions of the data are missing. Much to the dismay of the sysadmin, the programmer has blamed the network for the issue. He is convinced that the files are becoming corrupted while in transit from the stores to the central data repository. This means that our goal is to prove him wrong. Tapping into the Wire There are two options for collection of this data. We can capture packets at one of the individual stores or at the central office. The issue is affecting all of the stores so it would make sense that if the issue were indeed network related then it would be at the central office since that is the only common thread among all stores. The network switches support port mirroring so we will mirror the port the server is plugged into and sniff its traffic. The traffic capture will be isolated to a single instance of a store uploading its CSV file to the collection server. This instance can be found in the capture file tickedoffdeveloper.pcap. Analysis We don’t know anything about the application the programmer has developed other than the basic flow of information on the network. When the file is initially opened it appears to start with some FTP traffic so we will want to investigate that to see if that is indeed the mechanism that is transporting this file. This is a good place to examine the communication flow graph to get a nice clean summary of the communication that is occurring. In order to do this: Select Statistics from the main drop-down menu Select Flow Graph Click OK The flow graph is seen here in figure 7-37. Figure 7-37: The flow graph gives a quick depiction of the FTP communication Based upon this flow graph we see that a basic FTP connection is setup between 172.16.16.128 and 172.16.16.121 . Since it is 172.16.16.128 that is initiating the connection we can assume that it is the client and that 172.16.16.121 is the server that compiles and processes the data. Perusing the flow graph confirms that this traffic is exclusively using the FTP protocol. We know that some transfer of data should be happening here so we can use our knowledge of FTP to locate the packet where this transfer begins. The FTP connection and data transfer is initiated by the client so we should be looking for the FTP STOR command that is used to upload data to an FTP server. The easiest way to find this is to build a filter. There are a couple of ways to build the filter we need including building a filter with the expression builder, but there is a quicker method. This capture file is littered with FTP request commands so rather than sorting through the hundreds of protocols and options in the expression builder we can build the filter we need straight from the packet list window. In order to do this we first need to select a packet with an FTP request command present. There are a lot to choose from including packets 5, 7, 11, 13, 15, and more. We will choose packet 5 since it’s near the top of our list. Select packet 5 in the packet details window Once selected, expand the FTP section in the packet details window and expand the USER section Right click on the Request Command: USER field Select Prepare a Filter Select Selected This will place a prepare a filter for all packets that contain the FTP USER request command and put it in the filter dialog. Of course, this isn’t the exact filter we want, but all that has to be done is to edit the filter by replacing the word USER with the word STOR (Figure 7-38). Figure 7-38: This filter helps identify where data transfer begins Once this filter is applied by pressing the Enter key we will see that only one instance of the STOR command exists in the capture file and it occurs at packet 64 . Now that we know where data transfer begins the filter can be cleared by clicking the Clear button above the packet list window. Examining the capture file beginning with packet 64 we can clearly see that this packet specifies the file stre4829-03222010.csv is being transferred (Figure 7-39). Figure 7-39: The CSV file is being transferred using FTP The packets following the STOR command are using a different port but are identified as being part of an FTP-DATA transmission. Thus far we have verified that data is actually being transferred but that doesn’t help us reach our goal of proving the programmer wrong. In order to do that we have to be able to verify the contents of the file are sound after traversing the network. In order to do this we are going to extract the transferred file in its entirety from the captured packets. Although this may seem a bit odd, remember, when a file is transferred across the network in an unencrypted format that means that the file is broken down into segments and reassembled when it reaches its destination. In this scenario we captured packets as they were reaching their destination but before they were processed by the application purposed with reassembling the segments. This means that the data is all there, all we have to do is reassemble it. This is achieved in a reasonably easy manner by extracting the file as a data stream. In order to do this: Select any of the packets in the FTP-DATA stream (such as packet 66) Click Follow TCP Stream The results of this are displayed in the TCP stream in Figure 7-40. Figure 7-40: The TCP stream shows what appears to be the data being transferred The data appears in clear text because it is being transferred over FTP and is not in a binary format, but we can’t ensure that the file is intact based upon viewing the stream alone. In order to extract it to its original format: Click the Save As button Specify the name of the file as it was displayed in packet 64 (Figure 7-41) Click Save Figure 7-41: Saving the stream as the original file name The result of this save operation should be a CSV file that is an exact byte-level copy of the file as it exists when transferred from the store system. The file can be verified by comparing the MD5 hash of the original file to the hash of the extracted file, which should be the same, as it is in Figure 7-42. Figure 7-42: The MD5 hashes of the original file and the extracted file are equivalent Once the files are compared we have the information needed to prove that the network is not to blame for the database corruption occurring within the application. The file is being transferred from the store to the collection server and is intact when it reaches the server, so any corruption must be occurring during the processing of the file. Lessons Learned The great thing about examining things at the packet level is that you don’t have to deal with the clutter of applications. The number of poorly coded applications in the wild greatly outnumbers the amount of good ones, but at the packet level none of that matters. In this case, the programmer was concerned about all of the mysterious components his application was dependent upon but at the end of the day his complicated data transfer that took hundreds of lines of code is still no more than FTP, TCP, and IP. Using what we know about these basics protocols we were able to ensure the communication process flowed correctly and even extract files to prove that the network is sound. At the end of the day it’s crucial to remember that no matter how complex the issue at hand, it’s still just packets. Final Thoughts In this chapter we’ve covered several basic scenarios where packet analysis has allowed us to gain a better understanding of the communication we are participating in. Using basic analysis of common protocols we were able to track down and solve network problems in a timely manner. Most of these issues could have been solved by other means but not nearly as efficiently. You will likely never encounter these same scenarios on your network but hopefully some of the analysis techniques seen here can be applied to analysis of future problems you experience.