Patient Anonymizer Ver. 1
advertisement

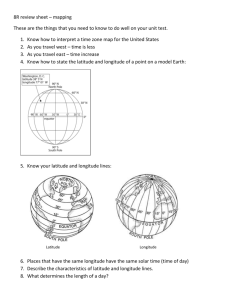
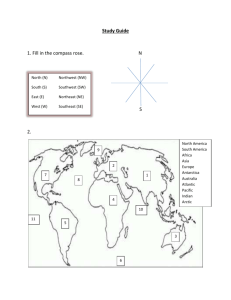
Patient Anonymizer Ver. 1 ** Created by John Cloutier, MIT ©2004 ** CONTENTS: Purpose Algorithm Interface Input File Output File Troubleshooting PURPOSE This program is designed to take a set of patient medical records, skew their location information and scrub any other patient identifiable data. ALGORITHM The anonymization algorithm uses US Census Bureau block groups to categorize residency based on age group population density. For each group a centroid was calculated, and it is this value that will be used for the anonymized longitude and latitude. Each patient’s location is skewed and then the nearest centroid location is found and substituted as the anonymized location. The output file contains only the following fields: hospital ID, syndrome ID, age, longitude and latitude. If other fields are present in the input file, they will not be output. This ensures that confidential information such as SSN, exact birth date, patient ID etc. are not distributed. INTERFACE To anonymize a patient data file, follow these steps: 1. From the drop down list, select the states from which you have patient data. Click “Import State Data” for each state you need. You may import as many states as you would like, but the more state data that is loaded, the slower the anonymization process. You may remove unneeded state data by selecting the state and clicking “Remove State Data.” 2. Choose an input file either by typing in its path or by clicking the “Browse” button to browse for the file. 3. Do the same for the output file. If you do not select an absolute path, the file will be saved in the active directory from which the program is running. 4. Choose the input and output file types. You may anonymize either a value separated file or an XML file and you may output to either format regardless of input format. If your input file is a value separated file, a combo box will appear next to the file type selection. Choose the appropriate delimiter that is used in your file. 5. Next, select the level of anonymization. You may choose values from zero to ten. 6. If you wish to anonymize several files using the same settings, simply check “Lock Parameters.” When you click “New Record” your settings will be preserved. If this box is not checked, when “New Record” is clicked all settings will return to their defaults. 7. Select the locations of the necessary data fields in your input file. The anonymizer requires the following fields: hospital ID, syndrome ID, birth date, longitude and latitude. For XML: If you selected XML as the input file format, each list will be populated with the XML tags of that file. Choose the tag from your data file that corresponds to the required fields. For example, if your XML file has a field called “hosp_identification_no,” select that entry under the list called “Hospital_id.” For CSV: If you selected CSV as the input file format, each list will be populated with numbers representing the number of fields on each line of the file. Select the location of the required fields from each list. For example, if birth date is the third field in your CSV file, choose “3” under the “Birthdate” list. If the number of fields is incorrectly listed, check to ensure you’ve selected the correct delimiter. 8. Enter the format of the patient’s birth date in the textbox. This will be used to evaluate the birth date and calculate the patient’s age. Use the following syntax: Letter Date or Time Component Presentation G Era designator Text Y Year Year M Month in year Month W Week in year Number W Week in month Number D Day in year Number D Day in month Number F Day of week in month Number E Day in week Text A Am/pm marker Text H Hour in day (0-23) Number K Hour in day (1-24) Number K Hour in am/pm (0-11) Number H Hour in am/pm (1-12) Number M Minute in hour Number S Second in minute Number S Millisecond Number Examples AD 1996; 96 July; Jul; 07 27 2 189 10 2 Tuesday; Tue PM 0 24 0 12 30 55 978 Pacific Standard Time; PST; GMT-08:00 zone -0800 Z Time zone General time zone Z Time zone RFC 822 time 9. Click “Convert” to begin the anonymization process. You may stop the conversion at any time by clicking “Stop.” This will discard any conversions made to that point. 10. To anonymize another set of patient records, click “New Record.” When you’re finished anonymizing patient records, click “Quit” to exit the program. INPUT FILE You may use either an XML or a value separated file to supply patient data. The required fields are: hospital ID, syndrome ID, birth date, longitude and latitude. It is acceptable to have additional fields or for them to be in a different order, however the above fields must ALL be present. XML: The requirements of an XML file for use with the anonymizer are more strict than those of a CSV file. The file structure must consist of a main root element such as “<patient_records>.” Each individual record should be in a separate child element using consistent syntax. It is not necessary for element tags to conform to preset wording, but all the required fields must be present. The following is an example of a compatible, well-formed XML document: <?xml version="1.0" encoding="ISO-8859-1"?> <PatientRecords> <PR> <Hospital_id>1234</Hospital_id> <Birthdate>1974-12-28 00:00:00</Birthdate> <Syndrome_id>1</Syndrome_id> <Longitude>-109.0</Longitude> <Latitude>35.0</Latitude> </PR> <PR> <Hospital_id>1234</Hospital_id> <Birthdate>1969-12-18 00:00:00</Birthdate> <Syndrome_id>1</Syndrome_id> <Longitude>-106.67</Longitude> <Latitude>34.67</Latitude> </PR> </PatientRecords> CSV: Each patient record must occupy its own line, ending with a carrage return. One each line the data fields may be separated by any of the standard set of delimiters. You may use: Comma: “,” Tab: ““ Vertical Pipe: “|” Colon: “:” Semicolon: “;” Again, the fields may be in a different order or contain additional fields, but the about required fields must be present. The following is an example of a compatible CSV file: 0 0 0 0 0 0 | | | | | | 1974-12-28 1975-03-05 1974-12-28 1975-03-05 1974-12-28 1975-03-05 00:00:00 00:00:00 00:00:00 00:00:00 00:00:00 00:00:00 |5 | |10| |5 | |10| |5 | |10| -71.0545350085774 -71.1165667504248 -71.0545350085774 -71.1165667504248 -71.0545350085774 -71.1165667504248 | | | | | | 42.3368244250354 42.2907040577867 42.3368244250354 42.2907040577867 42.3368244250354 42.2907040577867 OUTPUT FILE Your may choose to output your anonymized patient records in either XML or CSV format regardless of input file format. The file will be saved in the directory and under the name specified in the “Output file” text field. Note: file extensions do not necessarily correspond to the file format. In both cases the output file will contain the following fields in order: hospital ID, age, syndrome ID, anonymized longitude and anonymized latitude. This cannot be changed. The following is an example of an anonymized XML output file: <?xml version="1.0" encoding="ISO-8859-1"?> <PatientRecords> <PR> <Hospital_id>0 </Hospital_id> <Age> 1974-12-28 00:00:00 </Age> <Syndrome_id> 5 </Syndrome_id> <Alon> -71.0545350085774 </Alon> <Alat> 42.3368244250354</Alat> </PR> <PR> <Hospital_id>0 </Hospital_id> <Age> 1975-03-05 00:00:00 </Age> <Syndrome_id>10 </Syndrome_id> < Alon > -71.1165667504248 </ Alon > < Alat > 42.2907040577867</ Alat > </PR> The following is an example of an anonymized CSV output file: Hospital_id,Age,Syndrome_id,Alon,Alat 0,29.0,5,-71.05286531272073,42.333621006363835 0,29.0,10,-71.11408206902433,42.28593354246759 0,12.0,30,-71.05643231904209,42.29172613002231 0,13.0,10,-71.07536635297657,42.288487269779985 0,12.0,19,-71.12790005768028,42.260247997749815 0,17.0,19,-71.13829546396141,42.147621518089906 0,17.0,22,-71.04890849106302,42.464865036933254 0,12.0,19,-71.21918919728733,42.327815816270856 0,22.0,19,-71.07185562196734,42.34046375018009 TROUBLESHOOTING The anonymizer is designed to alert you to user errors that might prevent proper operation. If the program behaves erratically in spite of being set properly, the most likely cause is an invalid input file. Check to make sure your file conforms to the above guidelines. A dataset of 100,000 records should process in approximately ten minutes on a modern machine. If the program seems to hang, check your input file. When running the program, be sure to include the following JVM arguments which set the beginning and maximum memory cache size. Without them, the program will likely not run. “java AnonMain -Xms128m -Xmx256m”