Computational Neuroscience: from Neurons to Networks
advertisement

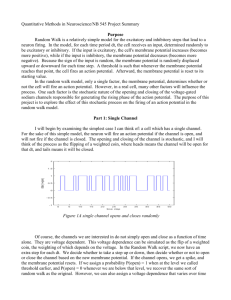
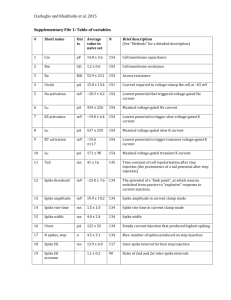
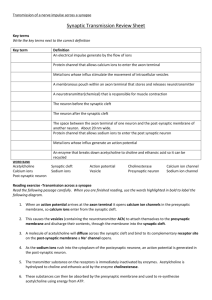
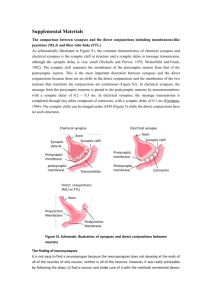
Literature Theoretical Neuroscience Computational and Mathematical Modeling of Neural Systems Peter Dayan and L. F. Abbott MIT Press 2001/2005 Principles of Neural Science Kandel ER, Schwartz JH, Jessell TM 4th ed. McGraw-Hill, New York. 2000 Spiking Neuron Models Single Neurons, Populations, Plasticity Wulfram Gerstner and Werner M. Kistler Cambridge University Press (August 2002) http://icwww.epfl.ch/~gerstner/SPNM/SPNM.html Links Munich Bernstein Center for Computational Neuroscience http://www.bccn-munich.de/ Scholarpedia (Computational Neuroscience) http://www.scholarpedia.org/article/Encyclopedia_of_Computational_Neuroscience GEneral NEural SImulation System http://www.genesis-sim.org/GENESIS/ NEURON for empirically-based simulations of neurons and networks of neurons http://neuron.duke.edu/ http://www.neuron.yale.edu/ Single compartment models: membrane Dayan & Abbott 2000 V : membrane potential Ie : external current Rm : membrane resistance Q : charge V : membrane potential Cm : membrane capacitance Neuronal surface: 0.01-0.1 mm2 Approx. 109 singly charged ions necessary for resting potential –70 mV. Single compartment models Dayan & Abbott 2000 Ek : reversal potential gk : conductance C : membrane capacitance Equivalent circuit of a single compartment neuron model. Synaptic conductance (s) depends on activity of a pre-synaptic neuron. Voltage-dependent conductance (v) depend on membrane potential V. Hodgkin-Huxley model Ek : reversal potential gk : conductance m, n, h : gating variables Hodgkin-Huxley: system of four non-linear differential equations Hodgkin-Huxley model Potassium current: gK n4 (u(t)-EK) Gating variable n describes the process of transition of an “activation particle” from the open to the closed state and vice versa. Probability of being open: n Probability of being closed: 1-n For a potassium channel (delayedrectifier K+) to open, 4 activation particles have to open ! n4. " and # are voltage-dependent rate constants and describe how many transitions can occur between both states. Hodgkin-Huxley model differential equations of the gating variables can be rewritten as voltage dependent low-pass filters different time scales: time constant of m never exceeds 1ms, other variables show slower time constants of roughly equal magnitude gating variables vary between 0 and +1, n0(u)$1-h0(u) Hodgkin-Huxley model generation of an action potential: m opens the sodium channel (fast, transient conductance) the membrane potential rises both h and m are non-zero ! Na+ influx this causes the spike then h closes the sodium channel (slow) n opens the potassium channel (slow, persistent conductance) the membrane potential decreases => combination of Na and K currents causes the action potential Some features of the Hodgkin-Huxley model Refractory period: if the interval between current pulses is too short, a new action potential cannot be generated. Rebound firing: a hyperpolarizing current causes a “rebound spike”. Activation function: steady-state firing rate as a function of somatic input current Hodgkin-Huxley model Gerstner & Kistler 2002 Response of the Hodgkin-Huxley model to step current input. Three regimes: I: no action potential is initiated (inactive regime). S: a single spike is initiated by the current step (single spike regime). R: periodic spike trains are triggered by the current step (repetitive firing). Stability: fixed points and limit cycles Wanted: stable and unstable regions depending on parameters 1)! Find a fixed point 2)! Linearize 3)! Determine whether it is stable Useful: phase plane analysis BUT: only for two variables (some theorems do not hold for higher dimensions) Try to simplify model to just two differential equations u˙ = ( F(u,w) + RI ) /" w˙ = G(u,w) /" w To check for stability, compute eigenvalues of the linearized system. Eigenvalues and Eigenvectors An eigenvector of a given linear transformation is a vector whose direction is not changed by that transformation. The corresponding eigenvalue is the proportion by which an eigenvector's magnitude is changed. Ax = "x ( A # "E ) x = 0 The eigenvectors x of the matrix A fulfil these equations, with % being the corresponding eigenvalue. E is the unit matrix. The eigenvalues are computed by solving for the determinant. det(A " #E) = 0 FitzHugh Nagumo model: Phase plane analysis Simpler model: FitzHugh-Nagumo 1 3 u˙ = u " u " w + I 3 w˙ = # $ (b0 + b1u " w) Phase plane analysis Linearization of the system at the intersection (fixed point) by Taylor expansion to first order. Solving for the eigenvalues: both eigenvalues must have real parts smaller than zero. => Necessary and sufficient condition for stability of the fixed point. trace determinant Phase plane analysis Parameters: b0=2, b1=1.5, &=0.1 Fixed point for I=0 at u=-1.54, w=-0.32 For this fixed point, the stability condition is fulfilled. Stable solution for Phase plane analysis I=2: instable fixed point, limit cycle Phase plane analysis http://www.scholarpedia.org/article/FitzHugh-Nagumo_Model Different regimes separated by the null-clines Phase plane analysis Many of the properties of the Hodgkin-Huxley model are easily explained by the FitzHugh-Nagumo model “Excitation Block” in the FitzHughNagumo model The mechanism of rebound firing explained by phase plane analysis http://www.scholarpedia.org/article/FitzHugh-Nagumo_Model FitzHugh-Nagumo vs. Hodgkin-Huxley Similarity of a reduced version of the Hodgkin-Huxley model and the FitzHugh-Nagumo model Reduced Hodgkin-Huxley FitzHugh-Nagumo Numerical simulation in MATLAB 1)! Script-based numerical simulations Uses MATLAB programming language Various solvers for ordinary differential equations available Sometimes much more flexible than Simulink Requires some programming skills 2)! Simulink-based numerical simulations Simulink graphical user interface Very convenient for rapid development Provides inbuilt visualization (scopes) Subsystems for modular architectures Vectorization for simulation of large numbers of neurons Numerical simulation du " = E + R# I $ u dt Basic differential equation. d u u( t ) # u( t # $t ) " $t dt Express the derivative by a difference. ui := u(t i ) t i+1 := t i + "t u˙ i+1 = ( E + R" Ii # ui ) /$ "d u% ui+1 ) ui u˙ i+1 = $ ' ( # d t & i+1 *t + ui+1 = ui + u˙ i+1 , *t For convenience, use indices. Calculate derivative dui+1/dt at time ti+1 from values at time ti. Integration step: calculate ui+1 from the known value ui and the derivative. (Euler one-step method) Note: for good convergence, 't has to be much smaller than (. Levels of Abstraction Level I-III Uses Hodgkin-Huxley style membrane equations or even more detailed equations for ion channel dynamics and synaptic transmission. Level IV Linear-nonlinear cascades, phenomenological model, easier to fit to experimental data. Level V Only conditional probability of a response R depending on a stimulus S is considered. Herz et al., Science 314, 2006 Leaky integrate and fire model Membrane potential between spikes follows a linear differential equation (lowpass filter, time constant (=RC). At threshold ), the neuron fires a spike (usually modelled as Dirac pulse), and the membrane potential is reset to ur. Thus, the time course of the membrane potential in response to a constant current I0 can be calculated analytically by integrating the differential equation. The solution is: Leaky integrate and fire model To calculate the firing rate of the neuron in response to a constant input current, we simply set u(t)= ), and calculate the time between two successive spikes. The firing rate is then f=1/!t. In many applications, an absolute refractory time tabs is introduced to account for the fact that two spikes cannot follow each other immediately. Spike rate adaptation Many real neurons show spike rate adaptation, i.e., the firing rate in response to a constant current decreases over time ((=100ms). The original integrate and fire neuron can be modified to account for this behaviour by adding an additional current with a time-dependent conductance grsa (modelled as K+ conductance). When the neuron fires, the conductance is increased by a constant amount. Refractory period Instead of introducing an artificial absolute refractory period, a more realistic relative refractory period can be simulated by the same mechanism as spike rate adaptation, but with a much shorter time constant ((=2ms) and larger increase of the leak conductance following an action potential. Synaptic transmission Information is collected via the dendritic tree. Increase in membrane potential leads to an action potential at the axon hillock. The action potential is actively moving along the axon. It arrives at the synapses, causes release of neurotransmitters. Neurotransmitters open ion channnels at the postsynaptic neuron. This leads to a change in conductance, and consequently to a change in the membrane potential of the postsynaptic neuron. Synaptic transmission: mechanism Action potential causes Ca2+ channels to open. Calcium influx causes vesicles to fuse with the membrane and release transmitter. Transmitter causes receptor channels to open, an excitatory postsynaptic potential (EPSP) can be observed . Synaptic transmission: transmitters and receptors Excitatory Transmitter: glutamate Results in opening of Na+ and Ka+ channels at the postsynaptic membrane Reversal potential is at 0 mV (i.e., at 0 mV, no EPSP is visible) Ionotropic glutamate receptors: AMPA, kainate, NMDA AMPA: "-amino-3-hydroxy-5-methylisoxazole-4-propionic acid NMDA: N-methyl-D-aspartate AMPA short time constant (2 ms) NMDA long time constants (rise: 2 ms, decay 100 ms) voltage dependent: Mg2+ blocks channel at –65 mV and opens upon depolarization needs extracellular glycine as cofactor Metabotropic glutamate receptors: indirectly gate channels through second messengers Synaptic transmission: transmitters and receptors Inhibitory Transmitter: GABA and glycine Results in opening of Cl- channels at the postsynaptic membrane Reversal potential is at -70 mV (i.e., at -70 mV, no IPSP is visible) GABA-receptors: GABAA (ionotropic) and GABAB (metabotropic) GABAA longer time constant 10 ms, Cl- conductance GABAB Opening of K+ channels, reversal potential –80 mV Single channel conductance of glycine is larger (46 pS) than that of GABA (30 pS) Basic equation for synaptic input du Cm = gl " ( E l # u) + gs " w s " ps " ( E s # u) dt ps : fraction of open channels d ps ps = # + &% ( t # t k ) ws : synaptic weight dt $s k E : synaptic resting potential s !s : synaptic time constant Basic differential equation of the leaky integrate and fire model with synaptic input. The fraction of open channels determines the synaptic conductivity. The product of conductivity and difference between membrane potential and synaptic resting potential determines the synaptic current. Synaptic transmission: change in conductance Synapse as change in input current: the effective afferent current I(t) of a neuron depends on the input from N synapses with weights wi. The kth spike arrives at time tik at synapse i. More realistic: change in conductance; involves not only the arriving spikes, but also the membrane potential of the postsynaptic neuron. If the reversal potential of the synapse uE is sufficiently high (true for excitatory synapses, e.g. uE=0), then the dependence of the postsynaptic current on the membrane potential can be neglected. The effect of inhibitory spikes depends on the membrane potential of the postsynaptic neuron. For inhibitory synapses, this is not the case: uE is usually equal to the reversal potential of the neuron itself. Synaptic transmission: modelling Synaptic transmission can be modelled by lowpass filter dynamics. The dynamics of the EPSP can be described by one or multiple time constants. Synaptic transmission Train of input spikes (from one or more neurons, s is linear!) Change in conductance s (blue) Change in input current (red) Membrane potential Output spikes Synaptic transmission: shunting inhibition excitation only “silent” inhibition shunting inhibition Strong inhibitory inputs do not need to generate an IPSP to affect output. Inhibition changes the conductance of the membrane: the neuron becomes leakier! Spike timing Spike timing makes a difference! Left: unsynchronized input spikes (i.e., spikes do not occur at the same time) from 3 neurons do not cause the postsynaptic cell to fire Right: the same number of input spikes, again from 3 neurons, lead to firing of the postsynaptic cell, if spike times are synchronized From real spikes to spike events Get spikes from measured data: Determine a threshold for spike discrimination Detect maxima above threshold Distribution of inter-spike intervals Probability distribution of time between action potentials (interspike interval, ISI) shows two peaks. This indicates that the neuron responded to some external events. Another way to look at it: scatter plot of successive ISIs. How can we describe spiking in terms of statistics? Probabilistic spike generation Independent spike hypothesis: The generation of each spike is a random process driven by an underlying continuous signal r(t) and independent of all other spikes. The resulting spike train is thus a Poisson process. The neural response function !(t) is the sum of spikes with each spike being modelled as Dirac pulse "(t). k "(t) = %# (t $ t i ) i=1 The spike count can thus be expressed as integral over time: n= The firing rate is the expectation of the neural response function: t2 r(t)dt The average spike count is then n = t1 For small time intervals, the expected spike count thus becomes " # t2 t1 " (t)dt r(t) = "(t) n = r(t)" #t If !t is small enough, the probability of more than one spike occurring can be ignored and thus P (1 spike in [ t - "t /2,t + "t /2[) = r(t)# "t Poisson spikes Probability that a neuron discharges n spikes in the time interval !t can be described by the Poisson distribution (r: mean firing rate): (r# "t) n $r#"t #e P("t,n) = n! Probability that the next spike occurs before the time interval T has passed: P(t < T) = 1 " P(T,0) = 1 " e "r#T Hence, the probability to find an ISI of T is: P(T) = d dT P(t < T) = r" e #r"T The mean duration between events is thus The mean spike count is This is the exponential distribution. T = $ # 0 T" P(T)dT = 1/r n = r" #t and the variance is "n2 = r# $t Thus, for Poisson spike trains, the Fano factor is "n2 =1 F= n Poisson spikes Example of simulated Poisson spike trains Interspike intervals are exponentially distributed Distribution of inter-spike intervals An alternative to the exponential distribution (see, e.g., Shadlen & Newsome 1998). is the Gamma distribution (assume that the neuron discharges only after k events, or, in other words, only every k'th time): T k "1 k "r$T P(T) = $r $e #(k) k can thus be conceived as neuronal threshold. Empirical probability distribution of ISIs of a real neuron fitted with the gamma distribution. Reliability of Spiking Neurons Ermentrout et al. 2008, after Mainen et al. 1995 Noisy input as trigger for reliable spiking Neurons are sensitive to changes in input rather than input per se. From spikes to firing rate Compute the instantaneous firing rate from spike events ti : time of i th spike f: firing rate The instantaneous firing rate is assumed to be constant between spikes. Technically, however, it does not exist between spikes. From spikes to firing rate Convolution (Faltung): Dayan & Abbott 2000 Different methods to approximate firing rate. A: spike train, B: discrete rate, bins of 100ms, C: sliding window (100ms), D: Gaussian window ("=100ms), E: alpha function window (1/#=100ms) From spikes to firing rate Top: Firing rate computed via interspike interval or convolution with a Gaussian window (corresponding to a probability distribution of each spike). Bottom: synaptic current computed from spike train or from firing rate. From spiking neurons to firing rate The current due to synaptic input is approximately described by leaky integration of the incoming spikes. The average firing rate r can be expressed as convolution (filtering) of the spike train with a window function (kernel) W(t), or as sum over the window functions at the times where spikes occur. The sum over the incoming spikes can thus be replaced by the respective firing rate, if the interspike intervals are short compared to the synaptic time constant. The firing rate of the postsynaptic neuron is determined by the neuron’s response function F(I(t)), which can be approximated by a threshold-linear function for the ideal integrateand-fire neuron. From spiking neurons to firing rate Firing rate networks come in various flavours. Usually, the dynamics are modelled by a single time constant, which may vary among neuron populations or for different types of synapses. The time constant describes either the dynamics of synaptic transmission, or that of the neuron itself. In the latter case, the time constant will usually will smaller than the membrane time constant. A combination of both is possible, of course. From spiking neurons to firing rate N1 NMDA synapse N2 Injected current I(t) For long synaptic time constants, the spike rate response of the postsynaptic neuron is determined by the synaptic time constant Feedforward network input units synaptic weights output unit The simplest case of a network is a feedforward network with n input units and a single output unit. ri(t) : firing rate of input unit i % n ( ˙I ( t ) = ' # w " r ( t ) $ I ( t )* / + = ( w ! r( t ) $ I ( t )) / + i i & i=1 ) I(t) : synaptic current of the output unit y ( t ) = [ I ( t )] wj + y(t) : firing rate of the output unit : synaptic weight of the ith input []+ : linear-threshold nonlinearity The synaptic weighting of the n inputs can be written as vector dot product (scalar product). a b In Euclidean geometry, the dot product can be visualized as orthogonal projection: If b is a unit vector, then the dot product of a and b is the orthogonal projection of of a on b. For our simple network, the steady state is reached when Feedforward network input units synaptic weights For our simple network, the output will become maximal, if the input vector and the weight vector are collinear. output unit In the steady state, this network is very similar to the so-called perceptron. The main difference is the non-linearity, which is a ! function for the perceptron (i.e., the output is either 0 or 1). The perceptron is a binary linear classifier, i.e. it responds with 1 if the input vector is on one side of the decision boundary (a hyperplane), and with 0 if it is on the other. Simple two-dimensional case with equal weights Boundary at Feedforward network input units synaptic weights output unit More than one output unit: the weights can be written as a matrix equation. First, recall that the dot product can be rewritten as matrix multiplication: Multiple outputs can be easily expressed by matrix multiplication: To understand the operation performed by the network, we consider the simple twodimensional case. The weights have been chosen so that the matrix W implements a rotation of the input space (x: 2D input; y: 2D output). In the general case (n inputs, m outputs), the network performs a transformation and/or projection of the ndimensional input vector onto an m-dimensional output vector. Attractor networks An attractor network is a network of nodes (i.e., neurons in a biological network), often recurrently connected, whose time dynamics settle to a stable pattern. Chris Eliasmith (2007), Scholarpedia, 2(10):1380. N nodes connected such that their global dynamics becomes stable in a M dimensional space (usually N>>M) Different kinds of attractors: point, line, ring, plane, cyclic, chaotic … y(t) activity of the network e(t) external input W,V weight matrices Stable state for Attractor networks Stable state for Trivial solution: I1=I2=0 Usually, attractor networks are symmetric, i.e. With F(x) = [ x ] + we check whether there is a solution for I1>0 and I2>0 Stable solutions for v=1-w : I1=I2 v=0.2, w=0.8 v=0.1, w=0.8 Attractor networks A specific application of firing rate models are continuous attractor networks, which are used in the literature for various purposes. Examples: short term memory, working memory, spatial navigation in the head direction cell system and the entorhinal grid cell system, coordinate transformation in the parietal cortex, gain modulation in the pursuit system … Continuous attractor networks are sometimes called neural fields. The shape of the kernel wij determines the behaviour of the network. Common kernels are built of one Gaussian (blue) or two Gaussians (green). If the kernel becomes negative, inhibitory synapses are required, and often modelled as two separate kernels, one for inhibition and one for excitation. Dale’s law: one neuron can make only excitatory or only inhibitory synapses. Attractor networks excitatory units inhibitory unit One example is the proposed use of attractor networks in short term memory for spatial navigation, specifically in the head direction cell system. Sharp et al. 2001 Vi : net activation or average ‘membrane potential’ of unit i Ei : weighted input Fi : firing rate Si : synaptic drive wij: synaptic weights *i : position of unit i Some properties of attractor networks Continuous attractors can be supplied with external input that is subsequently retained in memory. Bump shifts to the external input and remains at that position. If the external input is subsequently removed, the population response of the network retains its value. Some properties of attractor networks Continuous attractors are insensitive to noise. Uniform input noise does not change the shape of the bump. Even if the external input is almost hidden in noise, the attractor network will still detect it. Some properties of attractor networks Gain-modulated receptive field of a single unit in a network of 500 cells. The result (lines in A) is the same as multiplying by fixed factors (squares in A). Input is shown in B. Thus, the relation between input and bump height is multiplicative (Salinas & Abbott 1996). C and D show the outpus of two types of feed-forward networks, which is not multiplicative. Some properties of attractor networks Continuous attractors can fuse external input in various ways depending on the strength and shape of the input. Low input amplitude: The bump shifts to the closer of the two external inputs, even though it is smaller. For higher overall input activity, the bump doesn’t shift anymore, but switches to the higher of the two bumps. The cognitive map 1978 Muller et al. 1987 O’Keefe & Dostrovsky 1971: Place cells in the rat hippocampus Head direction cell network Sharp et al. 2001 Head direction cells fire whenever the animal’s head points to a specific spatial direction. This works without vision, and is dependent on an intact vestibular system. Head direction pathway: Tegmentum (DTN) Mammillary bodies (LMN) Thalamus (ADN) Postsubiculum (Post) Entorhinal cortex (EC) The temporal lobe The hippocampus and surrounding areas Bird & Burgess 2008 The temporal lobe The hippocampus and its connections Bird & Burgess 2008 Head direction cell network McNaughton et al. 2006 The simplest network consists of two recurrently connected populations of neurons (rings), each of them receiving velocity input (Xie et al. 2002). Due to the asymmetric connectivity between rings, an initially stable “bump” of activity will move, if velocity input is given to the rings. Head direction cell network Xie et al. 2002 A snapshot of the traveling bumps in two rings. The dashed lines denote the synaptic variables and the solid lines represent the firing rate. Neural activity (f) and synaptic activation (s) profiles of two rings in the stationary (a) and the moving state (b). This model constitutes the minimal model achieving both short-term memory and integration properties. Head direction cell network Goodridge & Touretzky 2000 The head direction cell system is supposed to perform path integration, i.e., to convert self-velocity to selforientation. It has been proposed that one or more regions of the HD pathway contain continuous attractors. Head direction cell network ccw cw VN LMN AD PoS Goodridge & Touretzky 2000 The LMN layer receives input from angular velocity units. The connections from LMN to AD are asymmetric, so that during movement the two bumps from LMN result in an asymmetric bump in AD, which shifts the bump in PoS. LMN are PoS are modelled as continuous attractors. Head direction cell network Goodridge & Touretzky 2000 The LMN layer receives input from angular velocity units. The connections from LMN to AD are asymmetric, so that during movement the two bumps from LMN result in an asymmetric bump in AD, which shifts the bump in PoS. LMN are PoS are modelled as continuous attractors. Head direction cell network Boucheny et al. 2005 Since intrinsic recurrent connections in the head direction cell network are questionable, Boucheny et al. proposed a three-population network without recurrent connections. What about distances and places? Best et al. 2001 Leutgeb et al. 2005 In rats, so-called place cells have been found in the hippocampus. These cells respond selectively when the rat is at a certain position within the arena. How to get a place cell “map”? McNaughton et al. Nat Rev Neurosci 7, 2006 Leutgeb et al. Curr Opin Neurobiol 15, 2005 The group of Edvard Moser recently discovered the so-called grid cells in the medial entorhinal cortex of the rat. How to get place cells from grid cells The group of Edvard Moser recently discovered the so-called grid cells in the medial entorhinal cortex of the rat. McNaughton et al. Nat Rev Neurosci 7, 2006 One dimensional simplification simulated entorhinal grid cells simulated place cells Each entorhinal grid cell layer can be conceived as oscillator driven by self-motion. Place cells encode the relative phase of grid cell populations. Entorhinal grid cell and place cell simulation: each layer EN1-5 consists of a continuous attractor network of 300 rate neurons (after Bucheny, Brunel, Arleo. J Comp Neurosci 18, 2005) Place cell layer (n=100) receives a weighted linear combination of EN1-5 (see McNaughton et al. Nat Rev Neurosci 7, 2006) What are place cells good for? What are place cells good for, if they only provide an information about our current location? The hippocampus is the crucial structure for remembering the current past (episodic memory). Place cells might be the glue between the current position and other properties of this position (e.g., an object, which can be seen, or another previous experience at that place). Bird & Burgess 2008 The standard place cell experiment Revisiting the rat to learn for the human Muller et al. 1987 Task: search for food pellets in the arena Assumption: effective strategy requires remembering pellet locations Rats perform a task possibly involving spatial memory while place cells are recorded Exploring with place cells Can we use place cells for navigation and spatial exploration? physical feedback grid cell layer current location motor command “place cell” layer desired location border cell layer Basis for the model: a place-cell like attractor network in a closed sensorimotor loop. Assumptions: Place cells indicate the desired rather than the current location. Staying in one location increases the inhibitory synaptic weight, and will push the neural activity away from that location. Modelling explorative behaviour Computational model of explorative behavior Toroidal geometry as in McNaughton et al. 2006 Assumptions ‘Place cell’ activity indicates desired location rather than current location Effective exploration leaves a memory trace of visited locations Exploring with place cells Can we use place cells for navigation and spatial exploration? Simulated trajectory of an agent during spatial exploration of a closed space. The basis for the simulation is place-cell like attractor network, which is put in a closed sensorimotor loop. Modelling explorative behaviour Model produces realistic exploratory behavior and simulates features of place cell activity seen in rats Visuo-spatial hemi-neglect Kerkhoff 2001 After lesions of the right temporoparietal or ventral frontal cortex Attention Corbetta et al. 2008 The Dorsal and Ventral Attention Systems ‘Attention’ model Network Outline retina MSO MSO V1 inhibitory interneurons superior colliculus Simple model for visuo-spatial neglect recurrent winner-takes-all ‘Attention’ model left two right target retina MSO V1 SC } attention left } no preference } right Healthy system: distribution of attention to one hemisphere ‘Attention’ model target left two right retina MSO V1 SC } neglect } healthy Lesioned system: attention always in one hemisphere