1. Open elearning.tamu.edu 2. log in and choose the course “intro to
advertisement

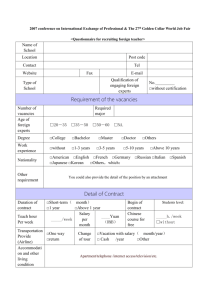
1. Open elearning.tamu.edu 2. log in and choose the course “intro to Econometrics” 3. download “Data Sets for Homework” onto your desktop 4. On the desktop, right click “DataSets.zip”, choose “Zipgenius” – “Extract here, to DataSets”. 5. Open “DataSets”, right click on “STATAData.zip”, choose “Zipgenius” – “Extract here, to STATAData”. 6. On the desktop, double click “Software from ECON-SERV” to open the file. 7. Double click on “StataSE 10” and wait for the windows “Do you want to run this file?” then choose “Run”. 8. In the Stata/SE 10.1, click on “File” on the top, choose “Open…” 9. In the new windows, choose “desktop” - “DTATAData” – “CEOSAL2.DTA”. (How to read the STATA data) This data is about the relationship (or correlation) between the CEO’s salary and the number of years as CEO. Or: use "C:\Documents and Settings\ws**\Desktop\CEOSAL2.DTA", clear 10. From the top of STATA, choose “Data” – “Data Editor” (what does the data look like? This is the sample of the data. What is the population?) Or: edit open the Data Editor where data can be entered or edited edit salary ceoten open the Data Editor with only the variables salary and ceoten visible and available for editing. browse open the Data browser. You cannot edit data here. browse salary ceoten if grad == 1 open the Data Browser showing only the variables ‘salary’ and ‘ceoten’ for observations which attend the graduate school. 11. In the “Data Editor”, double click on “salary”, there will be a new window “Variable Properties”. You can see or change the “variable name” and its “label” (for better explain the variable). Also, you can do the same thing for other variables. Or: rename salary compensation label variable age "in years, how old" order salary ceoten college grad 12. For the variable like “college”, “grad”, these are binary variables whose values are either 0 or 1. 13. “lsalary”, “lsales”, “lmktval” are all the log value for “salary”, “sales”, “mktval”. You can generate these variables by using the commond “generate” or “gen”. gen lsalary_new = log(salary) 14. “comtensq”, “ceotensq” are the square values for variable “comten” and “ceoten”. gen comtensq_new = comten^2 15. “profmarg” is the percentage value by dividing “profits” by “sales”. gen profmarg_new = profits/sales*100 16. If you do not want the new created variables, you can use “drop” to delete them. drop lsalary_new comtensq_new profmarg_new **attention: you need to close the “Data Editor” to use commands. 17. To have a whole view of the dataset, you can use “describe” or “summarize”. They will show different tables to explain the data. describe (or des) summarize (or sum) In the “describe” table, you can see how many observations, variables in the data set. Also, you can see the detailed information about “variable name”, “storage type” (help data_types) and “variable label”. In the “summarize” table, you can see the how many observations (in case there will be missing value), mean, standard deviation, minimum, maximum value for each variable. Or you can just see the summarization for some specific variables. summarize salary ceoten 18. You can also get the mean for each variable by using “mean” with more options. mean salary mean salary if college == 1 mean salary if college == 1 & grad == 1 mean salary ceoten if college == 1 & grad ==1 mean college (how many percentage people attend college in the sample) Answer the following questions: 1. How many observations are in the sample? How many variables? (what does the average mean for the 0-1 variable?) 2. Find the average salary along with its standard deviation in the sample, what are the highest and lowest salaries? 3. Among those CEOs who are in their first year as CEO, what is the average salary? 19. use “count” to compute number of observations. count (number of observations in the whole sample) count if salary > 1000 (number of CEOs whose salary are higher than 1000) count if salary > 1000 & grad == 1 (number of CEOs who attend the graduate school and the salary are higher than 1000) 20. also, you can list these observations which satisfy some conditions (when the number of observations is small.) list if salary > 3000 list if salary > 2000 & grad == 1 list salary age college grad ceoten if salary > 2000 & grad == 1 list salary age college grad ceoten in 1/10 Answer the following questions: 1. How many CEOs are in their first year as CEO? 2. Among those CEOs who are in their first year as CEO, how many of them attend the graduate school? 21. Since in some cases, you want to see what the correlation between two variables is, then you can plot the relationship between the salary and the years of tenure as CEO. Click on “graphics” on the top of STATA, choose “twoway graphs”—“Create…” Choose “salary” in the “Y variable”, “ceoten” in the “X variable”. Then “accept” – “OK”. 22. Or you can see the correlation between these two variables numerically by “correlate”. correlate salary ceoten correlate salary ceoten college 23. Other commands you can try: sort salary tabulate grad tabulate grad if salary >1000 replace comtensq = comtensq^(1/2) replace comtensq = comtensq^2 24. relational operators: == is equal to != is not equal to > is greater than < is less than >= is greater than or equal to <= is less than or equal to **attention: A double equals sign, “= =”, denotes the logical test, “Is the value on the left side the same as the value on the right?” To Stata, a single equals sign means something different: “Make the value on the left side be the same as the value on the right.” The single equals sign is not a relational operator and cannot be used within if qualifiers. Single equals signs have other meanings. They are used with commands that generate new variables, or replace the values of old ones, according to algebraic expressions. Single equals signs also appear in certain specialized applications such as weighting and hypothesis test. 25. Logical operators: & and | or ! not 26. Arithmetic operators: + add - subtract * multiply / divide ^ raise to power CLEAR