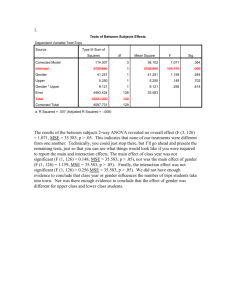
lp-minimization does not necessarily outperform l1
advertisement

`p -minimization does not necessarily outperform `1 -minimization? Le Zheng Department of Electrical Engineering, Columbia University Joint work with Arian Maleki and Xiaodong Wang Columbia University 1 / 26 N n y w A y = Axo + w xo : k-sparse vector in R k sparse signal Model x N A: n × N design matrix y: measurement vector in Rn w: measurement noise in Rn 2 / 26 `p -regularized least squares Many useful heuristic approaches: I LPLS o minimize x I 1 ky 2 − Axk22 + λkxkpp 0≤p≤1 Facts: o NP-hard except for p = 1 o Its performance is of great interest Chen, Donoho, Saunders (96), Tibshirani (96), Ge, Jiang, Ye (11) 3 / 26 Folklore of compressed sensing Global minimum of LPLS for p < 1 outperforms LASSO I Lots of empirical result I Some theoretical results Our goal: Evaluating the validity scope of this folklore 4 / 26 Related work Nonasymptotic analysis: I R. Gribonval, M. Nielsen: `p is better than `1 I Chartrand et al, Gribnoval et al., Saab et al., Foucart et al., Davies et al: Sufficient conditions I Peng, Yue, and Li: Equivalence of `0 and `p (noiseless setting) Asymptotic analysis: I Stojnic, Wang et al. : Nice analysis; Sharp only for δ → 1. I Rangan et al., Kabashima et al: Replica analysis. 5 / 26 Our analysis framework Setup: n N I δ= I xo,i ∼ (1 − )δ(xo,i ) + G(xo,i ). G(xo,i ) o k ≈ N = ρn xo,i Ai,j ∼ N (0, n1 ) Asymptotic setting: N → ∞ 11 N n y k sparse signal I w A x 6 / 26 What do we know about LASSO? 7 / 26 Noiseless setting Phase transition of LASSO Fix: δ= n N and = 1 kxo k0 N 0.9 0.8 Let: 0.7 0.6 ε λ → 0 and N → ∞ 0.5 0.4 Noiseless measurements: 0.3 0.2 y = Axo 0.1 0 0 0.2 0.4 δ 0.6 0.8 1 Question: For what values of (δ, ), `1 recovers k-sparse solution exactly? Donoho (05), Donoho-Tanner (08), Donoho, M., Montanari (09), Stojnic (09), Amelunxen et al. (13) 8 / 26 Noisy observations Noise: effect of noise on phase transition curve 0.01 0.009 0.008 Noisy setup: MSE 0.007 I xo : k-sparse I Ai,j ∼ N (0, 1/n) I y = Axo + w I 2 w ∼ N (0, σw I) 0.006 0.005 0.004 iid 0.003 0.002 0.001 0 I MSE = limN →∞ surely 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 σ2w kx̂−xo k2 2 N almost Donoho, M., Montanari, IEEE Trans. Info. Theory (11) 9 / 26 Back to LPLS LPLS o minimize x 1 ky 2 − Axk22 + λkxkpp 0≤p≤1 Disclaimer: o Analysis is based on F Approximate message passing (Rigorous) F Replica (Nonrigorous) 10 / 26 Noiseless setting: global minimum Fix: δ= n N and = kxo k0 N Phase transition of `p Phase transition of LPLS: 1 I =δ p=1 p<1 0.9 0.8 Main features: 0.7 Much higher than LASSO I Same for every 0 ≤ p < 1 I Same for every G ε 0.6 I 0.5 0.4 0.3 0.2 0.1 0 0 0.2 0.4 δ 0.6 0.8 1 Zheng, Maleki, Wang (15) 11 / 26 How about noisy setting? x̂p (λ) = arg min 12 ky − Axk22 + λkxkpp LPLS: x How to compare different ps? Given G and σw kx̂p (λ)−xo k2 2 N F λ∗p , arg minλ limN →∞ F Compare MSE , limN →∞ 2 kx̂p (λ∗ p )−xo k2 N for different p 0.1 p=0 p=1 0.09 0.08 0.07 0.06 MSE I 0.05 0.04 0.03 0.02 0.01 0 0 0.1 0.2 0.3 0.4 0.5 λ 0.6 0.7 0.8 0.9 1 12 / 26 How about noisy setting? LPLS: x̂p (λ) = arg min 12 ky − Axk22 + λkxkpp x Given G and σw kx̂p (λ)−xo k2 2 N I λ∗p , arg minλ limN →∞ I Compare MSE , limN →∞ 2 kx̂p (λ∗ p )−xo k2 N for different p 0.01 0.009 0.008 MSE 0.007 0.006 0.005 0.004 p=0 p=0.3 p=0.6 p=0.9 p=1.0 0.003 0.002 0.001 0 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 σ2w 13 / 26 How about noisy setting? Under the assumption of Replica: Theorem There exists σh > 0 s.t. ∀σw < σh optimal-λ LPLS with p = 0 outperforms the other values of p. Furthermore, there exists σu > 0 s.t. for ∀σw > σu , optimal-λ LASSO outperforms every 0 ≤ p < 1. 0.01 0.009 0.008 MSE 0.007 0.006 0.005 0.004 p=0 p=0.3 p=0.6 p=0.9 p=1.0 0.003 0.002 0.001 0 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 σ2w 14 / 26 How do we get the results? 15 / 26 How do we get the results? Under the assumption of Replica: Theorem As N → ∞, (x̂j (λ, p), xj ) converges in distribution to (ηp (X + σ` Z; λ), X) where X ∼ pX and Z ∼ N (0, 1), then the following holds: 1 2 σ`2 = σw + E(ηp (X + σ` Z; λ) − X)2 . δ 5 p=0 p=0.5 p=0.8 p=1.0 4 3 ηp(u,λ) 2 1 0 −1 −2 −3 −4 −5 −5 −4 −3 −2 −1 0 1 2 3 4 5 u T. Tanaka (02), Guo, Verdú (05), Rangan, Fletcher, Goyal (12) 16 / 26 How do we get the results? 2 Replica: σ`2 = σw + 1δ E(ηp (X + σ` Z; λ) − X)2 2 Define Ψλ,p (σ 2 ) = σw + 1δ E(ηp (X + σZ; λ) − X)2 I MSE = E(ηp (X + σ` Z; λ) − X)2 I Smaller σ`2 : smaller MSE I Best performance: find λ that has the smallest stable fixed point 2 2 2 2 , p ( 2 ) l2 2 17 / 26 How do we get the results Define: λ∗ (σ 2 ) = arg minλ E(ηp (X + σZ; λ) − X)2 2 Ψλ∗ ,p (σ 2 ) = σw + 1δ E(ηp (X + σZ; λ∗p (σ)) − X)2 Lemma: The stable fixed point of Ψλ∗ ,p (σ 2 ) is inf λ σ`2 (λ) Challenges: I Existence of multiple stable fixed points I ηp does not have explicit form for 0 < p < 1 18 / 26 Conclusions Noiseless setting: I The global miminum of `p -minimization (0 ≤ p < 1) performs much better than that of `1 -minimization. I The global miminum of `p -minimization (0 ≤ p < 1) is not affected by p or G. Noisy setting: I For small σw , `0 -minimization outperforms the other `p -minimization (0 < p ≤ 1). I For large σw , LASSO outperforms `p -minimization (0 ≤ p < 1). I The global miminum of `p -minimization (0 ≤ p ≤ 1) is affected by p and G. 19 / 26 Practical and analyzable algorithms? (To some extent addressed in our paper) http://arxiv.org/abs/1501.03704 20 / 26 Supplementary stuff State evolution for `1 -minimization: t21 t21 2f 1 t2 t2 21 / 26 Supplementary stuff State evolution for `p -minimization (p < 1): t21 t21 2f 2 2f 3 2f 1 t2 2f 2 t2 22 / 26 Supplementary stuff State evolution for `p -minimization (p < 1): ( 2 2 w ) + ( 2 ) 2 w 2 ˜2 2 23 / 26 Supplementary stuff Comparison of state evolution for `p -minimization: 0.2 p=0 p=1 optimal p 0.18 0.16 0.14 Ψ * λ ,p (σ2) 0.12 0.1 0.08 0.06 0.04 0.02 0 0 0.05 0.1 0.15 0.2 σ2 24 / 26 Supplementary stuff Comparison of `p -minimization: 1 p=0 p=0.25 p=0.5 p=0.75 p=0.9 p=1 0.9 0.8 0.7 ε 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.2 0.4 δ 0.6 0.8 1 25 / 26 Supplementary stuff Comparison of `p -minimization: 1 p=0 p=0.25 p=0.5 p=0.75 p=0.9 p=1 0.9 0.8 0.7 ε 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.2 0.4 δ 0.6 0.8 1 26 / 26