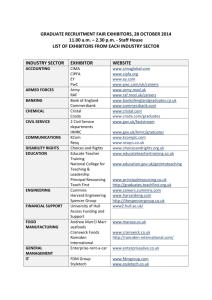
The Hull Method for Selecting the Number of Common Factors
advertisement

This article was downloaded by: [University of Groningen] On: 17 November 2011, At: 06:45 Publisher: Psychology Press Informa Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer House, 37-41 Mortimer Street, London W1T 3JH, UK Multivariate Behavioral Research Publication details, including instructions for authors and subscription information: http://www.tandfonline.com/loi/hmbr20 The Hull Method for Selecting the Number of Common Factors a b Urbano Lorenzo-Seva , Marieke E. Timmerman & Henk A. L. Kiers b a Research Center for Behavior Assessment, Universitat Rovira i Virgili b University of Groningen Available online: 19 Apr 2011 To cite this article: Urbano Lorenzo-Seva, Marieke E. Timmerman & Henk A. L. Kiers (2011): The Hull Method for Selecting the Number of Common Factors, Multivariate Behavioral Research, 46:2, 340-364 To link to this article: http://dx.doi.org/10.1080/00273171.2011.564527 PLEASE SCROLL DOWN FOR ARTICLE Full terms and conditions of use: http://www.tandfonline.com/page/termsand-conditions This article may be used for research, teaching, and private study purposes. Any substantial or systematic reproduction, redistribution, reselling, loan, sub-licensing, systematic supply, or distribution in any form to anyone is expressly forbidden. The publisher does not give any warranty express or implied or make any representation that the contents will be complete or accurate or up to date. The accuracy of any instructions, formulae, and drug doses should be independently verified with primary sources. The publisher shall not be liable for any loss, actions, claims, proceedings, demand, or costs or damages Downloaded by [University of Groningen] at 06:45 17 November 2011 whatsoever or howsoever caused arising directly or indirectly in connection with or arising out of the use of this material. Multivariate Behavioral Research, 46:340–364, 2011 Copyright © Taylor & Francis Group, LLC ISSN: 0027-3171 print/1532-7906 online DOI: 10.1080/00273171.2011.564527 Downloaded by [University of Groningen] at 06:45 17 November 2011 The Hull Method for Selecting the Number of Common Factors Urbano Lorenzo-Seva Research Center for Behavior Assessment Universitat Rovira i Virgili Marieke E. Timmerman and Henk A. L. Kiers University of Groningen A common problem in exploratory factor analysis is how many factors need to be extracted from a particular data set. We propose a new method for selecting the number of major common factors: the Hull method, which aims to find a model with an optimal balance between model fit and number of parameters. We examine the performance of the method in an extensive simulation study in which the simulated data are based on major and minor factors. The study compares the method with four other methods such as parallel analysis and the minimum average partial test, which were selected because they have been proven to perform well and/or they are frequently used in applied research. The Hull method outperformed all four methods at recovering the correct number of major factors. Its usefulness was further illustrated by its assessment of the dimensionality of the Five-Factor Personality Inventory (Hendriks, Hofstee, & De Raad, 1999). This inventory has 100 items, and the typical methods for assessing dimensionality prove to be useless: the large number of factors they suggest has no theoretical justification. The Hull method, however, suggested retaining the number of factors that the theoretical background to the inventory actually proposes. To date, exploratory factor analysis (EFA) is still a widely applied statistical technique in the social sciences. For example, Costello and Osborne (2005) carried out a literature search in PsycINFO, and found over 1,700 studies that Correspondence concerning this article should be addressed to Urbano Lorenzo-Seva, Centre de Reserca en Avalució i Mesura de la Conducta, Universitat Rovira i Virgili, Departament de Psicologia, Carretera Valls s/n, 43007 Tarragona, Spain. E-mail: urbano.lorenzo@urv.cat 340 Downloaded by [University of Groningen] at 06:45 17 November 2011 THE HULL METHOD 341 used some form of EFA over a 2-year period. A common problem in EFA is to decide how many factors need to be extracted. This decision is not trivial because an incorrect number of extracted factors can have substantial effects on EFA results (see, e.g., Comrey, 1978; Fava & Velicer, 1992; Levonian & Comrey, 1966; Wood, Tataryn, & Gorsuch, 1996). Underfactoring, which is an underestimation of the number of factors, makes the factor loading patterns artificially complex and, therefore, the factors difficult to interpret (see Comrey, 1978). On the other hand, overfactoring, which means overestimating the number of factors, might suggest the existence of latent variables with little theoretical or substantive meaning (Fabrigar, Wegener, MacCallum, & Strahan, 1999, Fava & Velicer, 1992; Wood et al., 1996). An objective procedure would be of great help in taking the important decision about the number of factors. This sort of procedure has been available since the early stages of factor analysis. In empirical practice, it is generally advised to use an objective procedure combined with reasoned reflection (see, e.g., Henson & Roberts, 2006; Kahn, 2006). This implies that objective procedures should be viewed as tools that can help to find potentially interesting solution(s) and that the final selection decision should be based on substantive information and the interpretability of the model parameters. In order to select a sensible procedure for identifying the number of common factors, one first needs to decide what the optimal number of common factors is. From a purely theoretical perspective of the common factor model, one could argue that this number is the number of common factors required to reproduce the reduced population correlation matrix (i.e., the correlation matrix with communalities on its diagonal). However, in empirical practice, it is rather unlikely that a common factor model with a limited number of factors (i.e., much fewer than the number of observed variables) would hold exactly at the population level. To formalize this idea of model error, one could use the framework based on major and minor factors, which was put forward by MacCallum and Tucker (1991). That is, each observed variable is considered to be composed of a part that is consistent with the common factor model (with a limited number of factors) and a part that is not. The latter model error can be represented by minor factors (based on the middle model of Tucker, Koopman, & Linn, 1969). From this perspective, the optimal number of factors to be extracted coincides with the number of major factors. This appears to be highly reasonable because common factor models in the social sciences are an approximation to reality (Browne & Cudeck, 1992), as is now widely recognized. The task, therefore, seems to identify the number of major factors rather than the number of major and minor factors. In empirical data sets, minor factors are easily found because (small) subsets of observed variables have common parts that are independent of the remaining observed variables. Cattell and Tsujioka (1964) referred to this phenomenon Downloaded by [University of Groningen] at 06:45 17 November 2011 342 LORENZO-SEVA, TIMMERMAN, KIERS as bloated specifics. For example, consider two typical items in a personality inventory: (a) “When travelling by train, I avoid speaking to unknown people” and (b) “When traveling by train, I feel anxious.” Item (a) would typically be related to an Extraversion dimension, and item (b) to an Emotional stability dimension. The items pertain to different substantive dimensions, but they share a common part because both items contain the same situation in which the action happens. To fully account for this dependency in a common factor model, one would need a “train factor” as well as the Extroversion and Emotional stability factors. Commonly, only the latter two would be of substantive interest, and it would be desirable to ignore the train factor. If such a factor indeed results from a relatively small subset of observed variables, the factor accounts for a relatively small portion of the common variance, from which the term “minor factor” stems. This property of minor factors enables them to be identified. In this article, we propose that the Hull method be used to select the number of major factors. The method is based on the principle that a model should have an optimal balance of fit and number of parameters. The performance of the Hull method is assessed in a simulation study and compared with four other procedures. In addition, its usefulness is illustrated with the assessment of the dimensionality of the Five-Factor Personality Inventory (Hendriks, Hofstee, & De Raad, 1999). This inventory has 100 items (20 per factor), and typical methods to assess its dimensionality prove to be useless: they suggest to retain a large number of factors that would have not a theoretical interpretation. The Hull method, however, suggested to retain the number of factors that actually the theoretical background of the inventory proposes. REVIEW OF PROCEDURES FOR SELECTING THE NUMBER OF FACTORS Several procedures have been proposed for selecting the number of common factors, based either on common factor models or on principal components (PCs). From a theoretical perspective, PC-based methods should not be used in a common factor analytic context. However, the fundamental differences between PCs and common factors are often hidden in empirical analyses. This is so because principal component analysis (PCA) and EFA can yield similar results, for example, when the ratio between the number of observed variables per factor (component) is large (Bentler & Kano, 1990) and communalities are high (Widaman, 1993). In empirical practice, PC-based methods appear to be even more popular for indicating the number of common factors than their common factor-based counterparts (Costello & Osborne, 2005). Therefore, we review both types of methods in the following sections. THE HULL METHOD 343 Downloaded by [University of Groningen] at 06:45 17 November 2011 Kaiser’s Rule Kaiser (1960) proposed that only those PCs associated with eigenvalues larger than one should be interpreted. Kaiser (1960) observed that, according to Guttman’s (1954) proofs, the eigenvalues-greater-than-1.00 criterion ought to provide a conservative estimate of the number of PCs. However, it is well known that Kaiser’s rule tends to overestimate the number of PCs and common factors quite severely (e.g., Fabrigar et al., 1999; Lance, Butts, & Michels, 2006; Lawrence & Hancock, 1999; Velicer, Eaton, & Fava, 2000; Zwick & Velicer, 1986). This is due to sampling error because Kaiser’s rule assumes that the population correlation matrix is available, which is only reasonable when the sample size approaches infinity (Glorfeld, 1995). Moreover, when it is used to determine the number of common factors, the additional, usually unreasonable, assumption that the unique variances are zero, must hold. The rule was expected to systematically result in reliable components, but Cliff (1988) proved that this was not true. It is therefore surprising that this criterion is quite popular in applied research: Costello and Osborne (2005) found that most of the 1,700 studies that used some form of EFA applied Kaiser’s rule. As Thompson and Daniel (1996) noted, “This extraction rule is the default option in most statistics packages and therefore may be the most widely used decision rule, also by default” (p. 200). Parallel Analysis Parallel Analysis (PA; Horn, 1965) can be regarded as a modification of Kaiser’s rule, which takes into account sampling variability (Kaiser, 1960). The central idea of Horn’s PA is that PCs are associated with eigenvalues that are larger than the ones associated with the dimensions derived from random data. PA requires a number of randomly drawn data matrices to be generated, usually from a normal distribution of the same order as the empirical data matrix. Then, the eigenvalues of the associated correlation matrices are computed. Finally, each empirical eigenvalue is compared with the distribution of random eigenvalues for the same position (i.e., the first empirical eigenvalue is compared with the distribution of the first random eigenvalue, the second empirical eigenvalue is compared with the distribution of the second random eigenvalue, etc.). PCs related to empirical eigenvalues larger than a given threshold in the distribution of random eigenvalues should be extracted. Because the average of the distribution (Horn, 1965) tends to overestimate the number of factors (Glorfeld, 1995; Harshman & Reddon, 1983), the more conservative 95th percentile is more popular at present. Horn’s PA has been refined so that it can be used to analyze multiple correlation matrices and average eigenvalues across matrices (e.g., Hayton, Allen, & Scarpello, 2004). It can also be used with sampling Downloaded by [University of Groningen] at 06:45 17 November 2011 344 LORENZO-SEVA, TIMMERMAN, KIERS bootstrap techniques instead of Monte Carlo analyses (Lattin, Carroll, & Green, 2003, pp. 114–116). Different variants of PA have been extensively studied. In general, Horn’s (1965) PA seems to perform well (Peres-Neto, Jackson, & Somers, 2005; Velicer et al., 2000; Zwick & Velicer, 1986) and is therefore a highly recommended procedure in applied research (e.g., Hayton et al., 2004; Kahn, 2006; Lance et al., 2006; Worthington & Whittaker, 2006). Even academic journals have editorialized in favor of PA (Educational and Psychological Measurement; Thompson & Daniel, 1996). From a technical point of view, it is not difficult to generalize PA to the context of EFA. Humphreys and Ilgen (1969) proposed a variant of PA for assessing the number of common factors. In this variant, eigenvalues of the reduced correlation matrix are computed for the empirical and the randomly generated matrices, where the squared multiple correlations are used as estimates of communalities. However, although Humphreys and Montanelli (1975) reported that this variant performed well in a simulation study, some authors have questioned its use (e.g., Crawford & Koopman, 1973). Steger (2006) concluded that not enough is known about the PA of the common factor model to recommend it for general use. In empirical practice, researchers also tend to apply Horn’s (1965) PA when they intend to identify the number of common factors (e.g., Finch & West, 1997; Reddon, Marceau, & Jackson, 1982). Scree Test The scree test (Cattell, 1966) is based on the principle that a model should have an optimal balance of fit and number of parameters. It uses a so-called scree plot, which is a plot of the successive eigenvalues of the observed correlation matrix versus the number of eigenvalues. As such, the fit is defined in terms of percentage of explained variance of PCs and the number of parameters as the number of PCs. The elbow in the scree plot indicates the optimal number of components. One of the main drawbacks of the scree test is that it is subjective, and overestimation is frequent (Fava & Velicer, 1992). Furthermore, the optimal number of PCs is sometimes not clearly indicated in empirical practice as scree plots may lack a clear elbow (Joliffe, 1972, 1973). Finally, although the scree test generally indicates the number of components accurately, its performance is rather variable (Zwick & Velicer, 1986). In empirical practice, the scree test is used to indicate the number of common factors, even though it is not designed for this purpose. The scree test can be adapted to the context of EFA by considering the eigenvalues from the reduced correlation matrix. It is important for the reduced correlation matrix to be nonnegative definite because otherwise the successive eigenvalues are not THE HULL METHOD 345 directly related to the variance explained by the successive factor. To ensure a nonnegative definite reduced correlation matrix, Minimum Rank Factor Analysis (Ten Berge & Kiers, 1991, Ten Berge & Socan, 2004) could be used. Downloaded by [University of Groningen] at 06:45 17 November 2011 Minimum Average Partial Test The Minimum Average Partial (MAP) test (Velicer, 1976) is a statistical method for determining the number of PCs. It uses the partial correlation matrix between residuals after a particular number of PCs have been extracted. The main idea is that if the number of extracted PCs is optimal, all nonresidual variation is captured by the extracted PCs, and the average partial correlation among residuals would be small. Therefore, Velicer proposed to extract the number of PCs that gives the minimum average partial correlation. Although the MAP test can only be used to identify the number of PCs, it is frequently used to identify the number of common factors (e.g., Eklöf, 2006). In a simulation study, the MAP test was generally good at indicating the number of components (Zwick & Velicer, 1986). Information Criteria To determine the number of common factors in a maximum likelihood (ML) factor analysis, Akaike (1973) proposed an Information Criterion-based method (AIC). Because the number of factors appeared to be overestimated in large samples, Schwarz (1978) proposed a corrected version known as the Bayesian Information Criterion (BIC). Both the AIC and BIC are based on the likelihood of the model, which expresses the goodness-of-fit, and the number of parameters. The model associated with the lowest AIC or BIC is considered the optimal model. In order to use AIC and BIC to select the number of factors, it is common to fit a series of common factor models, starting with a number of factors equal to one. The number of factors is successively increased with one until the value of AIC or BIC starts to increase. The AIC and BIC can be obtained with any ML extraction algorithm (e.g., Jennrich & Robinson, 1969; Jöreskog, 1977). Multivariate normality is an essential assumption in ML analysis, so AIC and BIC should not be applied to data if the assumption does not hold. BIC is frequently used to assess the fit of the model in the context of confirmatory factor analysis (see, e.g., Worthington & Whittaker, 2006). In a simulation study of common pathway models, Markon and Krueger (2004) found that BIC outperforms AIC in larger samples and in the comparison of more complex models. To the best of our knowledge, to date no simulation study of EFA has examined how well AIC and BIC can determine the number of common factors. 346 LORENZO-SEVA, TIMMERMAN, KIERS Downloaded by [University of Groningen] at 06:45 17 November 2011 HULL METHOD: CONVEX HULL-BASED HEURISTIC FOR SELECTING THE NUMBER OF MAJOR FACTORS None of the methods described so far appear to be generally good at determining the number of common factors. In this section, we propose to follow an alternative approach, which has led to successful model selection methods in, for instance, multiway data analysis and PCA. The approach, then, has been applied before, but the application that we propose here in the context of EFA is new. A fundamental problem in multiway data analysis is the selection of an appropriate model and the associated number or numbers of components. For example, in three-way component analysis, a number of components has to be selected for each mode in the data array (e.g., pertaining to different subjects, measured on different variables and in different conditions). To solve this intricate model selection problem, Ceulemans and Kiers (2006) proposed a numerical convex hull-based heuristic. The heuristic aims at identifying that multiway model with the best balance between goodness-of-fit and the degrees of freedom. The name hull was used because the method literally deals with the convex hull of a series of points in a two-dimensional graph. In fact, the main idea is that the fit values are plotted against the number of parameters (or components) in the two-dimensional graph. This results in plots with many points not nicely placed on a monotonically increasing curve. The idea is then to first find the convex hull (i.e., the curve consisting of line segments touching the cloud on the top of it). A next step then is to study the hull for a big jump followed by a small jump (elbow), and the number of components to retain is indicated by the sharpest such elbow. The hull heuristic has been shown to be a powerful tool for solving various deterministic model selection problems (Ceulemans & Kiers, 2009; Ceulemans, Timmerman, & Kiers, 2011; Ceulemans & Van Mechelen, 2005; Schepers, Ceulemans, & Van Mechelen, 2008), suggesting that the hull heuristic is a promising approach in the context of EFA as well. Therefore, we propose a new method that uses the hull heuristic approach to find an optimal balance between fit and degrees of freedom, combined with a statistical approach to guarantee that no overextraction takes place. As we explain shortly, the method is specifically designed to identify the number of common factors. We denote this method Hull, after the hull heuristic. The numerical convex hull-based heuristic (Ceulemans & Kiers, 2006) can be regarded as a generalization of the scree test. Consider a screelike plot of a goodness-of-fit measure (indicated as f value in what follows) versus the degrees of freedom (df); this plot is denoted as the hull plot here. An example of a hull plot can be found in Figure 1. Each point in the plot represents the combination of goodness-of-fit and degrees of freedom obtained in the different Downloaded by [University of Groningen] at 06:45 17 November 2011 THE HULL METHOD 347 FIGURE 1 Heuristic of the numerical convex hull-based model for the five-factor personality inventory (FFPI) in a Dutch sample. possible factor solutions (i.e., the factor solution when a single factor is extracted, when two factors are extracted, and so on until the maximum number of factors considered). Solutions in the hull plot that are on or close to an elbow in the higher boundary of the convex hull of the plot are favored. The Hull analysis is performed in four main steps: 1. 2. 3. 4. The range of factors to be considered is determined, The goodness-of-fit of a series of factor solutions is assessed, The degrees of freedom of the series of factor solutions is computed, and The elbow is located in the higher boundary of the convex hull of the hull plot. The number of factors extracted in the solution associated with the elbow is considered the optimal number of common factors. To implement the method, we have to select the range of numbers of common factors to be considered, a goodness-of-fit measure, the degrees of freedom, and a heuristic to locate the elbow (see the following section). The Range of Number of Factors to Be Considered In order to be able to detect an elbow in the hull plot it is necessary to have a certain trend on either side of an elbow. For example, to detect that there is an elbow for the one-factor solution, the one-factor solution must be compared with the zero-factor and two-factor solutions. In addition, to guard against under- and Downloaded by [University of Groningen] at 06:45 17 November 2011 348 LORENZO-SEVA, TIMMERMAN, KIERS overextraction, it is necessary to consider only a convenient range of number of factors; obviously the elbow identified on the convex hull depends on the range of factor solutions considered. Before defining the convenient range (i.e., the lowest and highest numbers of factors to consider), we note that by definition the elbow cannot be located in either the first or the last position of the boundary of the convex hull. Therefore, the Hull method will never indicate the lowest and highest numbers of factors in the range. Clearly, the lowest number of factors to consider must be zero because in this case the Hull method can only potentially indicate a single factor solution. To guard against overfactoring, we propose to identify the highest number of factors that need to be considered based on Horn’s (1965) PA. The idea is that, whatever the optimal number of factors is finally assumed to be, factors associated to eigenvalues lower than random eigenvalues should never be retained. As in Reddon et al. (1982), this is done by taking the number of factors suggested by Horn’s PA as the upper bound. Then, the highest number of factors to consider in the hull plot is taken as the number of factors indicated by Horn’s PA plus one. Indices for Assessing the Goodness-of-Fit of a Factor Solution In EFA, a large number of fit indices may be considered when applying the Hull method. Here, we discuss four indices associated with different factor extraction methods and test them in a simulation study (see later). We selected three wellknown fit indices based on the chi-square statistic, and we propose a fourth, which can be used with any extraction method. Note that the Hull method is not restricted to these measures, and alternatives can be considered. Bentler (1990) proposed the comparative fit index (CFI) as a measure of the improvement of fit by comparing the hypothesized model with a more restricted baseline model. The commonly used baseline model is a null or independent model in which the observed variables are uncorrelated. The values of CFI are in the range [0, 1], where a value of 1 indicates a perfect fit. Steiger and Lind (1980) proposed the root mean square error of approximation (RMSEA): it is based on the analysis of residuals and reflects the degree of misfit in the proposed model. The values of RMSEA range from zero to positive infinity, with a value of zero indicating exact model fit and larger values indicating poorer model fit. The computation of these indices is restricted to methods in which a chi-square statistic is available, that is, when an ML or unweighted least square (ULS) factor extraction method is applied. Another popular index is the standardized root mean square residual (SRMR; see, e.g., Hu & Bentler, 1998). SRMR is a measure of the mean absolute correlation residual: the overall difference between the observed and the predicted Downloaded by [University of Groningen] at 06:45 17 November 2011 THE HULL METHOD 349 correlations. Ideally, these residuals should be zero for acceptable model fit. The SRMR can be used with any factor extraction method, including ML, ULS, principal axis factor analysis, and minimum rank factor analysis (Ten Berge & Kiers, 1991; Ten Berge & Sočan, 2004). We now propose an alternative goodness-of-fit index that can be used with any extraction method. This index expresses the extent to which the common variance in the data is captured in the common factor model. The index is denoted as CAF (common part accounted for). To explain CAF, we first consider the decomposition used in a common factor analysis. Let R be an observed correlation matrix of order m m. A common factor analysis aims at decomposing R as Oq C O q; R D Aq A0q C U C q D R (1) where q is the number of factors extracted, Aq is a loading matrix of order O q is a residual matrix, m q, U is a diagonal matrix of unique variances, O and Rq is the model-implied correlation matrix. The off-diagonal elements of O q can be regarded as an estimate of the model error at the residual matrix the population level when q factors are extracted. At the population level, the residual matrix will be free of common variance if q is larger than or equal to the true number of factors. Therefore, a measure that expresses the amount of common variance in the residual matrix reflects the fit of the common factor model with q components, and larger amounts of common variance indicate a worse fit. A measure that expresses the amount of common variance in a matrix is found in the KMO (Kaiser, Meyer, Olkin) index (see Kaiser, 1970; Kaiser & Rice, 1974). The KMO index is commonly used to assess whether a particular correlation matrix R is suitable for common factor analysis (i.e., if there is enough common variance to justify a factor analysis). The KMO index is given as m m X X rij2 g.R/ D i D1 j D1.i ¤j / m m X X rij2 C aij2 i D1 j D1.i ¤j / i D1 j D1.i ¤j / m X m X ; (2) where rij is the correlation among the variables i and j , and aij is their partial correlation. Hence, KMO expresses the relative magnitude of the observed correlation coefficients and the partial correlation coefficients. Values of g.R/ close to one indicate that there is a substantial amount of common variance in the correlation matrix, whereas values equal to zero mean that there is no common variance. 350 LORENZO-SEVA, TIMMERMAN, KIERS Now, we propose to express the common part accounted for by a common factor model with q common factors as 1 minus the KMO index of the estimated residual matrix, namely, Downloaded by [University of Groningen] at 06:45 17 November 2011 CAFq D 1 O q /: g. (3) The values of CAFq are in the range [0, 1] and if they are close to zero it means that a substantial amount of common variance is still present in the residual matrix after the q factors have been extracted (implying that more factors should be extracted). Values of CAFq close to one mean that the residual matrix is free of common variance after the q factors have been extracted (i.e., no more factors should be extracted). A noteworthy characteristic of CAFq is that it enables the goodness-of-fit to be assessed when q D 0 (implying that no factors still have to be extracted). In this situation the correlation matrix and the residual matrix Oq D O q. would coincide, that is, R D 0 C Degrees of Freedom The degrees of freedom in an EFA of a correlation matrix that involves m variables and q factors is the number of unique variances plus the number of entries in the pattern matrix minus the number of entries that are set to zero by an orthogonal transformation of the factors (see, e.g., Basilevsky, 1994, p. 356). The degrees of freedom when factor analyzing a correlation matrix is df D mq 1 q.q 2 1/; (4) where the factors are assumed to be orthogonal. If a covariance matrix is considered, the degrees of freedom would be df C m. However, as the constant m would be added to all the possible factor solutions (i.e., for any value of q), this difference would not affect the performance of Hull. A Heuristic to Locate the Elbow To select the elbow on the higher boundary of the convex hull, we follow the proposal made by Ceulemans and Kiers (2006), namely, to maximize sti D .fi fi 1 /=.df i df i 1 / : .fi C1 fi /=.df i C1 df i / (5) The largest value of st indicates that allowing for df i degrees of freedom (instead of df i 1 ) increases the fit of the model considerably, whereas allowing for more than df i hardly increases it at all. The i -th solution is at the elbow of the convex THE HULL METHOD 351 hull because it is the solution after which the increase in fit levels off. The i -th solution is related to a break or discontinuity in the convex hull and is detected as an elbow. Downloaded by [University of Groningen] at 06:45 17 November 2011 Stepwise Overview of the Procedure for Selecting the Optimal Number of Factors The numerical convex hull-based method for selection can be summarized in eight steps: 1. A PA is performed to identify an upper bound for the number of factors J to be considered. To decrease the probability of underfactoring, we suggest a conservative threshold, such as the 95th percentile. Take J to be equal to the PA-indicated number plus 1. 2. Factor analyses are performed for the range of dimensions .j D 0; : : : ; J /, and the fj and df j values are computed for each factor solution, where fj is a goodness-of-fit index and df j the degrees of freedom. 3. The n solutions are sorted by their df values (this is equivalent to sorting the solutions by the number of extracted factors) and denoted by si .i D 1; : : : ; n/. 4. All solutions si are excluded for which a solution sj .j < i / exists such that fj > fi . The aim is to eliminate the solutions that are not on the boundary of the convex hull. 5. Then all the triplets of adjacent solutions are considered consecutively. The middle solution is excluded if its point is below or on the line connecting its neighbors in a plot of the goodness-of-fit versus the degrees of freedom. 6. Step 5 is repeated until no solution can be excluded. 7. The sti values of the “hull” solutions are determined. 8. The solution with the highest sti value is selected. SIMULATION STUDY To compare the performance of our newly proposed Hull method with existing methods, we performed a simulation study. We aim to control the amount of common variance in the artificial data sets and introduce a certain amount of model error due to the presence of minor dimensions. Manipulation of Conditions in the Simulation Study In this simulation study we manipulated five experimental factors: (a) the number of major factors, (b) the number of measured variables, (c) the sample size, 352 LORENZO-SEVA, TIMMERMAN, KIERS Downloaded by [University of Groningen] at 06:45 17 November 2011 (d) the level of interfactor correlations, and (e) the level of common variance. The levels for each factor were the following: (a) The number of major factors .q/ ranged from 1 to 5. (b) The number of measured variables .m/ manipulated was related to the number of major factors. Two levels were considered: small .m=q D 5/ and large .m=q D 20/. (c) Samples were of four sizes: very small .N D 100/, small .N D 200/, medium .N D 500/, and large .N D 2,000/. (d) The interfactor correlations were of three sizes: no correlation .® D :0/, low correlation .® D :20/, and moderate correlation .® D :40/. (e) The common variance of major factors had two levels: low (36% of the overall variance was common variance) and high (64% of the overall variance was common variance). In the following section, we explain how the different characteristics were introduced into the artificial data sets. Data Construction The simulation study constructs random data matrices X of N observations on m variables, which are related to q major factors. The data were generated according to the middle model of Tucker et al. (1969), which is rather popular in simulation research (e.g., MacCallum & Tucker, 1991; MacCallum, Tucker, & Briggs, 2001; Stuive, Kiers, & Timmerman, 2009; Zwick & Velicer, 1986). The simulated data were constructed as X D wmajorƒmajor major C wminorƒminor minor C wunicity ; (6) where ƒmajor and ƒminor are loading matrices; major and minor are factor score matrices; is a matrix containing unique scores; and, finally, wmajor, wminor, and wunicity are weighting values that are used to manipulate the variances of the major, minor, and unique parts of the data. Matrix ƒmajor .m q/ relates the measured variables to the major factors and consists of only zeros and ones. Each row contains a single value of one, denoting the relationship between the observed variable with a single major factor. For reasons of simplicity, all columns had the same number of ones, so each major factor was defined by the same number of measured variables. Matrix ƒminor .m c/, with c being the number of minor factors, is the minor loading matrix. The number of minor factors was taken as c D 3 q. The elements of ƒminor were randomly drawn from a uniform distribution on the interval [ 1, 1]. The variance related to the Downloaded by [University of Groningen] at 06:45 17 November 2011 THE HULL METHOD 353 minor factors was kept constant and the minor factors accounted for 15% of the overall variance. The matrices major .q N / and minor .c N / contain the random scores on the major and minor factors, respectively. As explained earlier, the interfactor correlation was manipulated. For a given level of interfactor correlation, it was kept constant across all factors. The matrix .m N / contains the random unique scores. All random scores were drawn from multivariate normal distributions N.0; I/. The five conditions were manipulated in an incompletely crossed design, with 500 replicates per cell. For the conditions m=q D 5 and N D 100, only three major factor values were considered (q D 1, q D 2, and q D 3): the conditions with q D 4 and q D 5 were excluded because the ratio between the number of variables (minimally 20) and sample size was so unfavorable that the factor extraction method frequently failed to converge. The remaining conditions were examined in a fully crossed design, which yielded (5 (number of major factors) 2 (number of observed variables) 4 (sample sizes) 3 (interfactor correlations) 2 (major factor variance) 500 (replicates)) 2 (number of major factors) 1 (number of observed variables) 1 (sample size) 3 (interfactor correlations) 2 (major factor variance) 500 (replicates)) D 114,000 simulated data matrices. Methods for Determining the Number of Factors in Data The aim of the study was to compare the performances of the Hull method and existing methods in identifying the number of major factors. We selected existing methods that are promising and/or frequently used in empirical practice. We excluded those methods that had already been proven to perform poorly (i.e., Kaiser’s [1960] rule) and which require subjective judgement to be applied (i.e., the scree test). Each simulated data matrix was analyzed with the following methods: 1. The Hull method, using the four goodness-of-fit indices presented earlier: CFI (Hull-CFI), RMSEA (Hull-RMSEA), SRMR (Hull-SRMR), and CAF (Hull-CAF). 2. The MAP test (Velicer, 1976). Although the MAP test is designed to assess the number of PCs, it is frequently applied to assess the number of common factors. To assess whether this practice is useful, we included the MAP test in our comparison. 3. Horn’s (1965) PA. PA can be implemented in several different ways. As not enough is known about PA of the common factor model to recommend its general use (Steger, 2006), and PCA-related implementations are much more popular, we used the latter. We considered a variant of PA that Downloaded by [University of Groningen] at 06:45 17 November 2011 354 LORENZO-SEVA, TIMMERMAN, KIERS appeared to be highly efficient in Peres-Neto et al. (2005) and which they refer to as Rnd-Lambda. It is implemented as follows: (a) 999 random correlation matrices are computed as the correlation matrices of the randomized values within variables in the data matrix, (b) the p value for each empirical eigenvalue is then estimated as (number of random values equal to or larger than the observed C1)/1000, and (c) the number of eigenvalues related to a p value lower than a given threshold are considered the optimal number of dimensions to be retained. In our study, we used a threshold p value < .05. 4. AIC (Akaike, 1973) and BIC (Schwarz, 1978). Some of the methods required an EFA to be carried out on the correlation matrix and, to this end, we systematically used exploratory maximum likelihood factor analysis. Results For each simulated data matrix, we recorded whether each of the analysis methods indicated the correct number of major factors (i.e., the value of q). To clarify the presentation of the results, we first focus on the methods that showed an overall performance that was moderate to good (that is, an overall success rate higher than 70%). These methods appeared to be PA, BIC, HullCAF, Hull-CFI, and Hull-RMSEA. Table 1 shows the percentage of successes for those five overall moderate-to-good performing methods within each condition of the simulation experiment and across all conditions. As can be seen in Table 1, the overall success rate of PA and BIC was moderate: 81% and 76%, respectively. The success rates of PA were good (between 92% and 98%) when m=q was low, the sample size was very small or small (i.e., 100 or 200, respectively), and/or the communality of the major factors was high. BIC performed well (i.e., 91% or more correct) when sample sizes were small or medium (i.e., 200 and 500, respectively). The initial inspection of the results revealed that the three Hull variants (Hull-CAF, Hull-CFI, and Hull-RMSEA) performed relatively well, with overall success rates between 89% and 96% (not shown in Table 1). Of the three, the Hull-CFI was the most successful. A close inspection of the results revealed that Hull variants sometimes indicated that 0 factors should be extracted. Hull-CAF was the most affected variant and showed this outcome in 3,911 of the 114,000 data matrices analyzed. This was mainly observed when the m=q ratio was small, and the number of major factors was 1 (3,414 times) or 2 (374 times). If Hull variants were forced to indicate at least one factor, the overall success of Hull-CAF improved from 89% to 92%. All the results in Tables 1 and 2 were computed when Hull variants were forced to indicate at least one factor. THE HULL METHOD 355 TABLE 1 Percentages of Correctly Indicated Number of Major Factors for Methods With an Overall Success Rate Higher Than 70% Condition Level PA BIC Hull-CAF Hull-CFI Hull-RMSEA h2 majors Low High Very small Small Medium Large Low Large 0 20 40 1 2 3 4 5 70 92 93 93 78 62 98 62 82 82 79 83 82 82 80 79 81 71 81 79 92 91 43 82 69 79 77 72 73 81 80 73 72 76 88 96 85 92 94 95 88 97 94 93 89 96 89 92 92 91 92 95 100 93 97 98 99 95 100 99 99 93 100 99 98 96 93 97 85 98 77 90 97 99 85 99 95 94 86 100 92 92 88 84 91 Downloaded by [University of Groningen] at 06:45 17 November 2011 N m=q ˆ q Overall Note. PA D parallel analysis; BIC D Bayesian information criterion; Hull-CAF D hull based on the Common Part Accounted For index; Hull-CFI D hull based on the Comparative Fit Index; Hull-RMSEA D hull based on the Root Mean Square Error of Approximation index. As can be seen in Table 1, the experimental conditions appeared to affect the four Hull variants in different ways. The performance of Hull-RMSEA was particularly affected (success rates between 77% and 84%) when the sample size was very low or when the number of major factors was large (five). The performances of Hull-CFI and Hull-CAF also decreased when the number of major factors and interfactor correlations increased, but they were affected to a lesser extent than Hull-RMSEA. Hull-CFI was especially successful (100%) when m=q was large, the communality of the major factors was large, and the number of major factors was one. One interesting outcome is that no method in the simulation study was systematically superior across all the simulation conditions considered. For example, even though the overall success of PA was limited, it was still the most successful method when m=q was low or when the sample size was very small. The sample size condition proved to have considerable impact on the performance of the methods. The performances of the three Hull variants improved as the sample size increased, as would be expected of a statistically proper behaving statistic. The performance of BIC dropped dramatically from medium (500) to 356 LORENZO-SEVA, TIMMERMAN, KIERS TABLE 2 Percentages of Correctly Indicated Number of Major Factors for Methods With an Overall Success Rate Higher than 70%: Interaction Among Conditions m/q D 5 N q PA BIC Hull-CAF Hull-CFI 1 2 3 4 5 200 1 2 3 4 5 500 1 2 3 4 5 2,000 1 2 3 4 5 100 98 94 88 78 100 100 100 98 96 100 100 100 100 100 100 100 100 100 100 100 92 68 44 31 100 99 90 73 60 97 100 99 94 93 56 66 86 97 100 100 75 77 76 71 100 79 86 87 84 100 84 90 92 90 100 86 93 94 92 100 94 90 83 76 100 98 96 93 87 100 100 98 95 92 100 100 100 98 95 Downloaded by [University of Groningen] at 06:45 17 November 2011 100 m/q D 20 Hull-RMSEA PA 100 59 59 54 47 100 83 82 77 71 100 98 96 91 86 100 100 99 97 92 93 95 97 — — 80 85 88 93 94 55 53 55 57 61 32 22 19 22 23 BIC Hull-CAF Hull-CFI Hull-RMSEA 100 100 100 — — 97 100 100 100 100 33 95 100 100 100 0 0 0 1 22 94 96 94 — — 93 97 99 99 98 93 97 98 99 100 90 96 98 99 100 99 100 99 — — 100 100 100 100 100 100 100 100 100 100 99 100 100 100 100 98 98 98 — — 99 100 100 99 94 100 100 100 100 99 100 100 100 100 100 Note. PA D parallel analysis; BIC D Bayesian information criterion; Hull-CAF D hull based on the Common Part Accounted For index; Hull-CFI D hull based on the Comparative Fit Index; Hull-RMSEA D hull based on the Root Mean Square Error of Approximation index. Dashes indicate the conditions that are not computed in the simulation study. large (2,000) sample sizes. The performance of PA also consistently decreased with increasing sample size. The number of variables for each major factor (i.e., m=q) also had a considerable impact: when the proportion was low, PA was the most successful method. However, when the proportion was large, only the Hull variants were successful. The correlation among the major factors also affected method performance: when the correlations were low or moderate, only the three Hull-based methods were reasonably successful (i.e., success rates larger than 85%). Of the three, Hull-CFI performed the best (i.e., success rates of 99% and 93%, respectively). Finally, a large number of major factors had a negative impact on all the methods, and only Hull-CFI and Hull-CAF were successful (i.e., success rates larger than 90%) when there were five major factors. Applied researchers may be interested in knowing whether there is any interaction between the sample size, the expected number of major factors, and the proportion m=q. Table 2 shows the performance of PA, BIC, and the three successful Hull variants. As the interfactor correlations and communality of major factors cannot be manipulated for empirical data, we aggregated the Downloaded by [University of Groningen] at 06:45 17 November 2011 THE HULL METHOD 357 data across these experimental conditions. As can be observed in Table 2, the five methods were affected quite differently by the experimental manipulations. It is interesting, for example, to note that BIC performed well, except when the sample was large (and much worse if the proportion m=q was also large). PA performed very well when the m=q ratio was small. However, when the m=q ratio was large, PA performed increasingly worse as the sample size increased. Hull-CFI performed excellently (success rates between 99% and 100%) when the m=q ratio was large and very well when the m=q ratio was small and the sample size larger than 100 (success rates between 87% and 100%). Hull-CAF performed very well (success rates between 90% and 100%) when the proportion m=q was large and reasonably when the m=q ratio was small and the sample size larger than 100 (success rates between 79% and 100%). Hull-RMSEA performed very well (success rates between 94% and 100%) when the m=q ratio was large but relatively badly when the m=q ratio was low, the sample size lower than 500, and there was more than one major factor (success rates between 47% and 83%). Finally, we studied the three methods that showed rather low overall success rates: Hull-SRMR (55%), MAP (51%), and AIC (44%). Even though their overall success rate was low, it is interesting that they still performed very well in some of the experimental conditions. Hull-SRMR was very successful (success rates between 84% and 100%) when m=q was large, the number of major factors was below three, and the sample was large .N > 100/. MAP was particularly successful (success rates between 85% and 100%) when m=q was low and the sample large .N > 200/. AIC showed good success rates (success rates between 94% and 97%) when m=q was low, the sample was very small, and the number of major factors was between one and three. ILLUSTRATIVE EXAMPLE The Five-Factor Personality Inventory (FFPI) is a Dutch questionnaire developed to assess the Big Five model of personality (Hendriks et al., 1999). The FFPI consists of 100 Likert-type items rated on a 5-point scale. The FFPI assesses a person’s scores on the following content dimensions: Extraversion, Agreeableness, Conscientiousness, Emotional Stability, and Autonomy. The FFPI is a balanced questionnaire designed so that variance due to acquiescence response can be isolated in an independent dimension (Lorenzo-Seva & RodríguezFornells, 2006). Overall, six dimensions are usually extracted, which have a clear substantive meaning (one dimension related to acquiescence response and five dimensions related to content factors). Hendriks et al. constructed the test using a sample of 2,451 individuals. This data set is used here to test the Hull method for selecting the number of factors. Downloaded by [University of Groningen] at 06:45 17 November 2011 358 LORENZO-SEVA, TIMMERMAN, KIERS We performed Horn’s (1965) PA with the 95th percentile threshold. The PA analysis suggested that 11 dimensions were related to a variance larger than random variance. As a result, we considered the solutions ranging from 0 common factors to 12 common factors. We analyzed the interitem correlation matrices using minimum rank factor analysis (Ten Berge & Kiers, 1991). As a goodness-of-fit index, we used the CAF. Figure 1 (already introduced in the Hull Method section) shows the hull plot related to this data set: the plot is based on the CAF versus the degrees of freedom for the 13 solutions. When the numerical convex hull-based method for selection was applied to this plot, five “hull” solutions were provided (i.e., five solutions were placed on the convex hull), which are indicated by larger points in Figure 1. The scree test values sti the three “hull” solutions are given in Table 3. The solution with six common factors is associated with the maximal sti value, indicating that this solution should be selected. The Spanish version of the FFPI was validated using a sample of 567 undergraduate college students enrolled on an introductory course in psychology at a Spanish university (Rodríguez-Fornells, Lorenzo-Seva, & Andrés-Pueyo, 2001). We also applied the Hull method to this data set to assess whether the method TABLE 3 Number of Factors q, Goodness-of-Fit Values f, Degrees of Freedom df, and Scree Test Values st for the 5 Solutions on the Higher Boundary of the Convex Hull in Figure 1 q 0 1 2 3 4 5 6 7 8 9 10 11 12 * * * * * f df st .052 .096 .129 .169 .223 .300 .377 .398 .408 .417 .427 .437 .443 0 100 199 297 394 590 585 679 772 864 955 1,045 1,134 — — — — — — 2.542 2.054 — — — 1.755 — Note. The Scree Test value (st) is only computed for the solutions placed on the convex hull—the dashes indicate the solutions that are not placed on the convex hull; * D solutions on the higher boundary. THE HULL METHOD 359 Downloaded by [University of Groningen] at 06:45 17 November 2011 still suggested that 6 dimensions should be extracted if a different, smaller sample was selected. With this data set, Horn’s (1965) PA suggested that 11 dimensions were related to a variance larger than random variance. Applying the numerical convex hull-based model for selection to this plot yielded four “hull” solutions. The scree test values st indicated that the sixth dimensional factor solution should be selected. DISCUSSION We have proposed a new method for assessing the number of major factors that underlies a data set. The Hull method is based on the numerical convex hull-based heuristic (Ceulemans & Kiers, 2006). It uses Horn’s (1965) PA to determine an upper bound for the number of factors to be considered as possible optimal solutions. The Hull method can be based on different goodness-of-fit indices, which yield different Hull variants. We have illustrated the Hull method with an empirical example. To assess its comparative performance, we carried out a simulation study in which both major and minor factors were considered. In empirical research, it is reasonable to expect that data sets will contain these two kinds of factors. Four variants of the Hull method were compared with four other methods for indicating the number of common factors. Of these four, two (MAP and PA) were designed to indicate the number of principal components. They were included because they are frequently used in applied research in the context of EFA. The Hull variants were very successful and detected the number of major factors on a high number of occasions (between 85% and 94%). Hull-CFI (i.e., Hull based on CFI) and, to a somewhat lesser extent, Hull-CAF (i.e., Hull based on KMO) were the most successful methods. Hull-CFI can be applied only when ML and ULS factor extraction are used, whereas Hull-CAF can be used with any factor extraction method. In empirical practice, we would advise that HullCFI be applied with ML or ULS extraction methods and Hull-CAF with any other extraction method to indicate the number of major factors, except when the number of observed variables per factor is small (five in our simulation study). In these cases, PA seems to be an excellent alternative. As mentioned earlier, Hull assesses the goodness-of-fit of a series of factor solutions. In principle, the Hull method is not necessarily tied to a particular index, and different fit indices could be used. We considered four indices (CAF, CFI, RMSEA, and SRMR). Our results indicate that the fit index used affects the performance of the Hull method. The CFI and CAF appeared to be the most successful indices, whereas the performance of SRMR was unacceptable (55% of overall success). Our advice is to use Hull in conjunction with one of these two indices mainly because in our intensive tests they performed well. Downloaded by [University of Groningen] at 06:45 17 November 2011 360 LORENZO-SEVA, TIMMERMAN, KIERS However, researchers could use other fit indices as long as they are properly tested. As researchers do not usually consider extracting as many factors as observed variables, we propose that Hull should do the same. Hull, therefore, takes as an upper bound the number of factors suggested by PA plus one. To check the appropriateness of this decision, in a previous simulation study we also computed Hull-CAF with all the possible numbers of factors to be extracted (i.e., any value between 1 and m 1). The overall success rate (defined as whether the correct number of major factors was indicated) was extremely low (46%). This outcome reinforces our suggestion that Hull must look for a relatively low number of factors and that taking PA C1 as the upper bound of the number of factors to be extracted is a useful decision. Of the methods considered, Horn’s (1965) PA was also moderately successful (81%), especially when the number of measured variables per factor was low. It should be pointed out that although our implementation was related not to the common factor model but to the principal component model, it performed relatively well (especially when the number of variables per factor was low). This is an interesting result because applied researchers assessing the number of common factors usually use this type of implementation. In our simulation study, we used equal communalities across variables in the population to ensure that the major factors were well defined in the data set (i.e., we did not want major factors to be easily confused with minor factors). Because a PCA solution yields biased loadings (compared with EFA loadings), where bias increases consistently with decreasing communalities, the overall loading pattern is the same as the one obtained in EFA (when communalities are similar, as they were in our case). In this situation, our implementation of PA based on PCA could in fact be expected to perform well even if we proposed a common factor model. Further research is needed to study the performance of this implementation of PA in a common factor context when the measured variables have different levels of communalities. BIC was not very successful overall. This was due to the fact that it performed very badly when the sample size was large (2,000 in our simulation study). As AIC (Akaike, 1973) had been observed to overestimate the number of dimensions in large samples, Schwarz (1978) proposed BIC as a refined version of AIC. BIC, then, was expected to improve the performance of AIC (44% of success in our simulation study) and, although in our study it was a clear improvement on AIC, in large samples it still seems to have difficulties. MAP (Velicer, 1976) performed badly in the overall results (51% of success). It should be pointed out that MAP had not been previously tested in the context of the common factor model or in situations in which major and minor dimensions were present in the data. This method was mainly successful when m=q was low and the sample was large .N > 200/. Downloaded by [University of Groningen] at 06:45 17 November 2011 THE HULL METHOD 361 We do not wish to end without one final comment. We have proposed an objective procedure for assessing the dimensionality of data sets and have tested it with other procedures. We believe that these objective criteria are useful for inexperienced researchers and in the early stages of exploratory factor analysis. However, they should never be interpreted rigidly: they are helpful tools for making an initial selection of interesting solutions. For the final selection decision, substantive information and the interpretability of the results should also be taken into account. To blindly retain a particular number of factors just on the say-so of a criterion is bad practice and should always be avoided. To facilitate the use of all the four variants of Hull considered here in empirical practice, we have developed a Windows program. A copy of this program, a demo, and a short manual can be obtained from us free of charge or downloaded from the following site: http://psico.fcep.urv.cat/utilitats/factor/ ACKNOWLEDGMENTS Research was partially supported by a grant from the Catalan Ministry of Universities, Research and the Information Society (2009SGR1549) and by a grant from the Spanish Ministry of Education and Science (PSI2008-00236). We are obliged to Jos ten Berge for his helpful comments about an earlier version of this article. REFERENCES Akaike, H. (1973). Information theory and an extension of the maximum likelihood principle. In B. N. Petrox & F. Caski (Eds.), Second International Symposium on Information Theory (p. 267). Budapest, Hungary: Akademiai Kiado. Basilevsky, A. (1994). Statistical factor analysis and related methods: Theory and applications. New York, NY: Wiley. Bentler, P. M., & Kano, Y. (1990). On the equivalence of factors and components. Multivariate Behavioral Research, 25, 67–74. Browne, M. W., & Cudeck, R. (1992). Alternative ways of assessing model fit. Sociological Methods and Research, 21, 230–258. Cattell, R. B. (1966). The scree test for the number of factors. Multivariate Behavioral Research, 1, 245–276. Cattell, R. B., & Tsujioka, B. (1964). The importance of factor-trueness and validity, versus homogeneity and orthogonality, in test scales. Educational and Psychological Measurement, 24, 3–30. Ceulemans, E., & Kiers, H. A. L. (2006). Selecting among three-mode principal component models of different types and complexities: A numerical convex hull based method. British Journal of Mathematical and Statistical Psychology, 59, 133–150. Ceulemans, E., & Kiers, H. A. L. (2009). Discriminating between strong and weak structures in threemode principal component analysis. British Journal of Mathematical and Statistical Psychology, 62, 601–620. Downloaded by [University of Groningen] at 06:45 17 November 2011 362 LORENZO-SEVA, TIMMERMAN, KIERS Ceulemans, E., Timmerman, M. E., & Kiers, H. A. L. (2011). The CHull procedure for selecting among multilevel component solutions. Chemometrics and Intelligent Laboratory System, 106, 12–20. Ceulemans, E., & Van Mechelen, I. (2005). Hierarchical classes models for three-way three-mode binary data: Interrelations and model selection. Psychometrika, 70, 461–480. Cliff, N. (1988). The eigenvalues-greater-than-one rule and the reliability of components. Psychological Bulletin, 103, 276–279. Comrey, A. L. (1978). Common methodological problems in factor analytic studies. Journal of Consulting and Clinical Psychology, 46, 648–659. Costello, A. B., & Osborne, J. W. (2005). Best practices in exploratory factor analysis: Four recommendations for getting the most from your analysis. Practical Assessment, Research & Evaluation, 10(7), 1–9. Crawford, C. B., & Koopman, P. (1973). A note on Horn’s test for the number of factors in factor analysis. Multivariate Behavioral Research, 8, 117–125. Eklöf, H. (2006). Development and validation of scores from an instrument measuring student test-taking motivation. Educational and Psychological Measurement, 66, 643–656. Fabrigar, L. R., Wegener, D. T., MacCallum, R. C., & Strahan, E. J. (1999). Evaluating the use of exploratory factor analysis in psychological research. Psychological Methods, 4, 272–299. Fava, J. L., & Velicer, W. F. (1992). The effects of overextraction on factor and component analysis. Multivariate Behavioral Research, 27, 387–415. Finch, J. F., & West, S. G. (1997). The investigation of personality structure: Statistical models. Journal of Research in Personality, 31, 439–485. Glorfeld, L. W. (1995). An improvement on Horn’s parallel analysis methodology for selecting the correct number of factors to retain. Educational and Psychological Measurement, 55, 377–393. Guttman, L. (1954). Some necessary conditions for common-factor analysis. Psychometrika, 19, 149–161. Harshman, R. A., & Reddon, J. R. (1983). Determining the number of factors by comparing real with random data: A serious flawand some possible corrections. Proceedings of the Classification Society of North America at Philadelphia, 14–15. Hayton, J. C., Allen, D. G., & Scarpello, V. (2004). Factor retention decisions in exploratory factor analysis: A tutorial on parallel analysis. Organizational Research Methods, 7, 191–205. Hendriks, A. A. J., Hofstee, W. K. B., & De Raad, B. (1999). The Five-Factor Personality Inventory (FFPI). Personality and Individual Differences, 27, 307–325. Henson, R. K., & Roberts, J. K. (2006). Use of exploratory factor analysis in published research: Common errors and some comment on improved practice. Educational and Psychological Measurement, 66, 393–416. Horn, J. L. (1965). A rationale and test for the number of factors in factor analysis. Psychometrika, 30, 179–185. Hu, L., & Bentler, P. M. (1998). Fit indices in covariance structure modeling: Sensitivity to underparameterized model misspecification. Psychological Methods, 3, 424–453. Humphreys, L. G., & Ilgen, D. R. (1969). Note on a criterion for the number of common factors. Educational and Psychological Measurement, 29, 571–578. Humphreys, L. G., & Montanelli, R. G. (1975). An investigation of the parallel analysis criterion for determining the number of common factors. Multivariate Behavioral Research, 10, 193–205. Jennrich, R. I., & Robinson, S. M. (1969). A Newton-Raphson algorithm for maximum likelihood factor analysis. Psychometrika, 34, 111–123. Joliffe I. T. (1972). Discarding variables in a principal component analysis I: Artificial data. Applied Statistics, 21, 160–173. Joliffe I. T. (1973). Discarding variables in a principal component analysis II: Real data. Applied Statistics, 22, 21–31. Downloaded by [University of Groningen] at 06:45 17 November 2011 THE HULL METHOD 363 Jöreskog, K. G. (1977). Factor analysis by least-squares and maximum-likelihood methods. In K. Enslein, A. Ralston, & H. S. Wilf (Eds.), Statistical methods for digital computers (Vol. 3, pp. 127–153). New York, NY: Wiley. Kahn, J. H. (2006). Factor analysis in counseling psychology research, training, and practice. The Counseling Psychologist, 34, 684–718. Kaiser, H. F. (1960). The application of electronic computers to factor analysis. Educational and Psychological Measurement, 20, 141–151. Kaiser H. F. (1970). A second generation of Little Jiffy. Psychometrika, 35, 401–415. Kaiser, H. F., & Rice, J. (1974). Little Jiffy, Mark IV. Educational and Psychological Measurement, 34, 111–117. Lance, C. E., Butts, M. M., & Michels, L. C. (2006). The sources of four commonly reported cutoff criteria: What did they really say? Organizational Research Methods, 9, 202–220. Lattin, J., Carroll, D. J., & Green, P. E. (2003). Analyzing multivariate data. Belmont, CA: Duxbury Press. Lawrence, F. R., & Hancock, G. R. (1999). Conditions affecting integrity of a factor solution under varying degrees of overextraction. Educational and Psychological Measurement, 59, 549–578. Levonian, E., & Comrey, A. L. (1966). Factorial stability as a function of the number of orthogonally rotated factors. Behavioral Science, 11, 400–404. Lorenzo-Seva, U., & Rodríguez-Fornells, A. (2006). Acquiescent responding in balanced multidimensional scales and exploratory factor analysis. Psychometrika, 71, 769–777. MacCallum, R. C., & Tucker, L. R. (1991). Representing sources of error in the common-factor mode: Implications for theory and practice. Psychological Bulletin, 109, 502–511. MacCallum, R. C., Tucker, L. R., & Briggs, N. E. (2001). An alternative perspective on parameter estimation in factor analysis and related methods. In R. Cudeck, S. du Toit, & D. Söorbom (Eds.), Structural equation modeling: Present and future (pp. 39–57). Linkolnwood, IL: Scientific Software International, Inc. Markon, K. E., & Krueger, R, F. (2004). An empirical comparison of information: Theoretic selection criteria for multivariate behavior genetic models. Behavior Genetics, 34, 593–609. Peres-Neto, P. R., Jackson, D. A., & Somers, K. M. (2005). How many principal components?: Stopping rules for determining the number of non-trivial axes revisited. Computational Statistics Data Analysis, 49, 974–997. Reddon, J. R., Marceau, R., & Jackson, D. N. (1982). An application of singular value decomposition to the factor analysis of MMPI items. Applied Psychological Measurement, 6, 275–283. Rodríguez-Fornells, A., Lorenzo-Seva, U., & Andrés-Pueyo, A. (2001). Psychometric properties of the Spanish adaptation of the Five-Factor Personality Inventory. European Journal of Psychological Assessment, 17, 133–145. Schepers, J., Ceulemans, E., & Van Mechelen, I. (2008). Selecting among multi-mode partitioning models of different complexities: A comparison of four model selection criteria. Journal of Classification, 25, 67–85. Schwarz, R. (1978). Estimating the dimension of a model. Annals of Statistics, 6, 461–464. Steger, M. F. (2006). An illustration of issues in factor extraction and identification of dimensionality in psychological assessment data. Journal of Personality Assessment, 86, 263–272. Steiger, J. H., & Lind, J. M. (1980, June). Statistically based tests for the number of common factors. Paper presented at the annual meeting of the Psychometric Society, Iowa City, IA. Stuive, I., Kiers, H. A. L. & Timmerman, M. E. (2009). Comparison of methods for adjusting incorrect assignments of items to subtests: Oblique multiple group method versus confirmatory common factor method. Educational and Psychological Measurement, 69, 948–965. doi:10.1177/ 0013164409332226 Ten Berge, J. M. F., & Kiers, H. A. L. (1991). A numerical approach to the approximate and the exact minimum rank of a covariance matrix. Psychometrika, 56, 309–315. Downloaded by [University of Groningen] at 06:45 17 November 2011 364 LORENZO-SEVA, TIMMERMAN, KIERS Ten Berge, J. M. F., & Socan, G. (2004). The greatest lower bound to the reliability of a test and the hypothesis of unidimensionality. Psychometrika, 69, 613–625. Thompson, B., & Daniel, L. G. (1996). Factor analytic evidence for the construct validity of scores: A historical overview and some guidelines. Educational and Psychological Measurement, 56, 2, 197–208. Tucker, L. B., Koopman, R. F., & Linn, R. L. (1969). Evaluation of factor analytic research procedures by means of simulated correlation matrices. Psychometrika, 34, 421. Velicer, W. F. (1976). Determining the number of components from the matrix of partial correlations. Psychometrika, 41, 321–327. Velicer, W. F., Eaton, C. A., & Fava, J. L. (2000). Construct explication through factor or component analysis: A review and evaluation of alternative procedures for determining the number of factors or components. In R. D. Goffin & E. Helmes (Eds.), Problems and solutions in human assessment: Honoring Douglas N. Jackson at seventy (pp. 41–71). Boston, MA: Kluwer. Widaman, K. F. (1993). Common factor analysis versus principal component analysis: Differential bias in representing model parameters? Multivariate Behavioral Research, 28, 263–311. Wood, J. M., Tataryn, D. J., & Gorsuch, R. L. (1996). Effects of under- and overextraction on principal axis factor analysis with varimax rotation. Psychological Methods, 1, 354–365. Worthington, R. L., & Whittaker, T. A. (2006). Scale development research: A content analysis and recommendations for best practices. The Counseling Psychologist, 34, 806–838. Zwick, W. R., & Velicer, W. F. (1986). Comparison of five rules for determining the number of components to retain. Psychological Bulletin, 99, 432–442.