Methods - Diabetes
advertisement

Appendix
Methods
NPL regression analysis
The NPL regression approach is a conditional logistic regression analysis in which the
family-specific NPL statistic (e.g. NPLpairs) at one or more loci are the predictor
variables. Consider a sample of m independent pedigrees and a chromosomal region with
one or more markers and a locus of interest. Let i be the pedigree-specific contribution
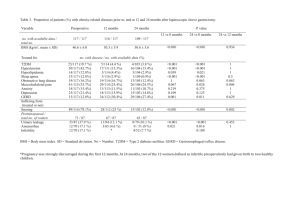
to the NPL statistic at the locus of interest. The likelihood function for a conditional
logistic regression with i as a predictor is
m
exp{ yi i }
Lik ( ; yi , )
.
i 1 1 exp{ i }
Here, yi 1 for all i and is the conditional logistic regression parameter. It can be
shown that the score test from this likelihood is asymptotically equivalent to Whittemore
and Halpern’s (Whittemore AS, Halpern J: A class of tests for linkage using affected
pedigree members. Biometrics 50:118-127, 1994) class of tests (23,24). Although
unaffected individuals can be used to help estimate the possible inheritance vectors for
that pedigree, an NPL regression analysis is an “affecteds only” analysis. The primary
advantage of the NPL regression approach is that it allows us to evaluate simultaneously,
either by joint or conditional hypothesis tests, the effects of multiple loci (i.e.
heterogeneity) and test for interactions among sets of loci (e.g. epistasis). In addition, the
NPL regression approach allows for tests of whether the magnitude of sharing at a locus
varies by environmental or other phenotypic factors (gene-phenotype interactions) by
testing interactions between the degree of sharing (IBD) at a locus and the environmental
or other phenotypic characteristics using a single measure for each pedigree (e.g. mean
BMI). For each pedigree we include the pedigree’s NPL statistic at that locus, the mean
age at T2DM diagnosis or the mean BMI, and their statistical interaction.
Ordered subsets linkage analysis
If a subset of pedigrees that are phenotypically more homogeneous can be identified, it
might be possible to improve the power of our linkage analysis. Age of onset of T2DM
and BMI are two primary traits that may define phenotypically more homogeneous
subgroups of African Americans with T2DM. A series of ordered subset analyses (OSA)
(27-29) were computed to investigate the influence of a pedigree’s mean age at T2DM
diagnosis and mean BMI on linkage analyses. Ordered subset analysis (OSA) ranks each
family by the family-level value of a covariate of interest (e.g. mean BMI) and identifies
the contiguous subset of families that maximize the evidence for linkage. For example,
consider BMI. In the OSA the mean BMI values for each pedigree were ranked from
largest to smallest. The family with the smallest mean BMI entered into the analysis and
the corresponding LOD score was computed on the target chromosome (e.g. chromosome
7) for that family. Next, a second linkage analysis on the target chromosome was
computed combining the two families with the two smallest mean BMI values. The ith
OSA analysis proceeds by computing a linkage analysis on the target chromosome using
the subset of families with the ith smallest mean BMI. This process is repeated until all
families have been added to the linkage analysis. The subset of families that yield the
largest LOD score on the target chromosome is taken as the LOD score of interest. Note
that the location that maximizes the LOD score on a chromosome will vary as the subset
of families analyzed changes. The statistical significance of the change in the LOD score
was evaluated by a permutation test under the null hypothesis that the ranking of the
covariate is independent of the family’s LOD score on the target chromosome. Thus, the
families were randomly permuted with respect to the covariate ranking and an analysis
proceeded as above for each permutation of these data. The resulting empirical
distribution of the change in the LOD scores yielded a chromosome-specific p-value
(p). In this example the family-level means were ranked in ascending order, however
we repeated the analysis ranking in descending order. The chromosome-wide p-value
(p) is for the specific analysis conducted, i.e. families ranked in increasing or decreasing
order, but not both.