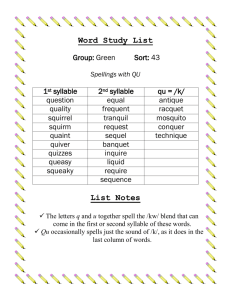
Phonetics and Phonology (I)
advertisement
")
ELL2019S (2009) Phonetics and Phonology 1. Introduction: articulatory phonetics and the organs of speech Articulatory phonetics is the study of the production of sounds: how the organs of speech are used to produce them. Acoustic phonetics deals with propagation (transmission): what happens in the air between the mouth of the speaker and the ear of the hearer. Auditory phonetics deals with the hearing process and how speech sounds are interpreted by the brain of the recipient. Articulatory phonetics is the most basic of these. The ‘vocal organs’: the lungs, the vocal folds, the tongue, the lips, etc., aren’t primarily organs of speech at all. The lungs.1 Most speech sounds in all languages, and all speech sounds in most languages, are made by interfering with outgoing breath from the lungs. The larynx. Inside the larynx are the first of the structures that can interfere with the airstream: the vocal folds (sometimes called vocal cords).2 Their most important function is to produce voice: a very rapid opening and closing in the airstream. 1 2 Ladefoged (3rd ed) pp. 1, 146, 129 Ladefoged pp. 1-2, 191, 210, 251, 272 1 2 3 The supralaryngeal vocal tract: a tube-like cavity (the pharynx)3 branching into two other cavities: the nasal cavity and the oral cavity. The pharynx stretches from the top of the larynx to the back of the nasal cavity, serving to contain a volume of air that can be made to vibrate in sympathy with the vibration of the vocal folds. The nasal cavity. If with the vocal folds vibrating the soft palate ( = velum)4 is lowered so that the pharynx and nasal and oral cavities are connected, all the air in the connected cavities vibrates with characteristic nasal effect. NB distinguish nasal5 from nasalised6 sounds. The oral cavity. Much more important for speech than the nasal cavity, because variable in dimensions and shape, and because it contains independently mobile organs that can obstruct the airstream in various ways. Its variability of shape is due partly to the mobility of (i) the lower jaw, and (ii) the lips, but overwhelmingly to the tongue,7 by far the most important organ of speech (NB no accident that the word for ‘tongue’ in many lgs is also the words for ‘language’.) The oral cavity bounded at the top by the palate:8 dome-shaped structure of which the front part is bony and fixed, and the back part (the soft palate) is moveable. In phonetics the term palate is used by itself to refer exclusively to the hard palate; the soft palate is called the velum. It is also important to distinguish the alveolar ridge9 and the uvula.10 The tongue is divided for descriptive convenience into four major parts: tip blade — alveolar ridge front — palate back — velum the blade, the front, and the back being the parts lying beneath, and articulating with, the respective parts of the roof of the mouth as mentioned. 2. The articulatory description of consonants At the various places of articulation, interference with the airstream may be brought about in different ways. To specify a consonant in articulatory terms we need to specify not just a PLACE of articlation but also a MANNER of articulation. Basically there are three possibilities: Ladefoged pp. 1, 4 Ladefoged p.4 5 Ladefoged pp. 8-9, 89-95 6 Ladefoged pp. 91-92, 95, 167 7 Ladefoged pp. 13-14, 78-80 8 Ladefoged p. 4, 161-2 9 Ladefoged pp. 3-4 10 Ladefoged p. 4 3 4 4 1. Complete CLOSURE of the air passage at a particular place. There are three different types of sound involving complete closure: STOPS, ROLLS (TRILLS) and FLAPS. Examples of STOPS are: bilabial [p], [b], [m], alveolar [t], [d], [n], velar [k], [], []. When the closure is made within the oral cavity it may or may not be accompanied by VELIC closure. If it isn’t, the airstream will go out entirely through the nose, giving nasal sounds such as [m], [n] and []. When there IS velic closure the airstream can’t get out through the nose, but nor can it get out immediately through the mouth, which is blocked. Since the lungs are still pushing air upwards, the air is compressed within the totally enclosed cavity, and when the mouth closure is removed this compressed air explodes out of the mouth, as in pie, buy, tie, die, etc. This kind of sound, which has compression and explosion, is called a plosive. Sometimes with these sounds, instead, instead of removing the mouth closure, we remove the velic closure instead, and the compressed air explodes up into the nose and out that way. This is called nasal plosion. It happens in English when a nasal sound follows one of the other stops, as in acne, Agnes, Stepney, Edna, cabman. Say these words and notice how the pent-up air explodes behind the soft palate and into the nose. ROLLS (TRILLS) consist of several rapidly repeated closures and openings of the air passage, as in the rolled r-sounds of Scottish English or Italian (or in the human imitation of a cat’s purr). For this sound the tongue makes several quick taps against the alveolar ridge. The speed with which these closures and openings are made demands the particpation of a particularly elastic organ, and this effectively restricts the places at which they can be made. Basically the tongue-tip and the uvula are the parts of the oral apparatus with the necessary elasticity, so we can have rolls only where the tongue tip and the uvula can reach. The uvular roll is commonly found in a number of European languages as an r-sound. (The lips can also be made to roll in a similar way – brrrrr – but this is not found as a speech-sound.) The speed of each closure and opening in a roll is clearly much greater than for the stops, and it is this speed that characterises FLAPS and distinguishes them from the stops. Flaps consist of a single fast opening and closing of the air passage. In a word like mirror the rr may be made as an alveloar flap: one fast tap of the tongue-tip against the alveolar ridge. So flaps (also called ‘taps’) are rolls with only one roll. 2. A NARROWING of the passage at a particular place, so that air forced through the narrowing causes audible friction. When two speech organs are brought very close together, the air forcing its way through the resulting very narrow passage becomes turbulent, and this turbulence is heard as friction noise. Sounds having such friction are called FRICATIVES ( = spirants). Some fricatives are made with a rather high-pitched, hissy kind of friction (e.g. s and sh), and such sounds are called SIBILANTS. Others, the non-sibilant fricatives, have a less hissy, more diffuse kind of friction noise, like f [f] and th []. 3. More OPEN positions (‘approximation’), which don’t result in friction, but which are nonetheless perceptually different from sounds made with no obstruction of the airstream at all. If two parts of the oral vocal apparatus are not so close together that they cause friction they may nevertheless be palying a major part in shaping the cavities through which the air flows. Say a long vvvvvvvvv and hear the friction coming from the labiodental narrowing. Now very gently lower the lip away from the teeth until the friction just disappears; you are left with a non-fricative sound, but one that is still labiodental in effect because the lip-teeth approximation makes a difference in sound: lower the lip 5 right away from the teeth and notice the difference. Such a sound is called an approximant ( = frictionless continuant). 3. The articulatory description of vowels The primary cardinal vowels11 11 Ladefoged pp. 198-201 6 4. Phonetic transcription Alphabetic writing, although essentially phonographic (i.e. the use of the letters bears some relation to the sounds of speech), is very often inconsistent and illogical, and more or less useless as it stands for phonetic transcription.12 This is especially true of English. What is required is a phonetic alphabet, which gives one fixed value to each of the symbols it uses. Phonetic alphabets use the letters of the normal alphabet, but supplement them with specially designed symbols, and additional marks called diacritics. Look at the following passages, given in normal writing, and then in phonetic transcription. (i) The North Wind and the Sun were disputing which was the stronger, when a traveller came along wrapped in a warm cloak. They agreed that the one who first succeeded in making the traveller take his cloak off should be considered stronger than the other. Then the North Wind blew as hard as he could, but the more he blew the more closely did the traveller fold his cloak around him, and at last the North Wind gave up the attempt. Then the Sun shone out warmly, and immediately the traveller took off his cloak. And so the North Wind was obliged to confess that the Sun was the stronger of the two. A basic transcription of the above, giving citation-form pronunciations of the individual words: i i i 12 Ladefoged pp. 25-33 7 i _________________________________________________________ (ii) For three hundred yards the two children alternately walked and trotted beside the travellers; but then the boy ran ahead, for a gate now barred the road. He heaved it off its latch, then pushed it wide back and open; and stood there, staring at the ground, with a hand outstretched. The older gentleman felt in his greatcoat pocket, and tossed a farthing down. The boy and his sister both scrambled for it as it rolled on the ground, but the boy had it first. Now once more they both stood, with outstretched small arms, the palms upwards, heads bowed, as the rear of the cavalcade passed. A basic transcription of the above, giving citation-form pronunciations of the individual words: 8 ____________________________________________________________ Some points about phonetic transcriptions: 1. Transcriptions differ as to how ‘broad’ or ‘narrow’ they are. There is no limit to the amount of phonetic detail that might in principle be given. 2. There is an important distinction to be drawn between transcribing, however broadly or narrowly, a particular individual’s utterance on a particular occasion, and transcribing, however broadly or narrowly, a piece of a given language as generally spoken in a given accent. 3. The transcriptions above do not represent any actual individual’s utterance of these passages on any actual occasion. The were not made by listening to how someone actually pronounced them. They represent a very generalised pronunciation (in a certain accent) of the individual words concerned. 5. The consonants13 of English oral stops14 (plosives): i i i i 13 Ladefoged pp. 49-66 9 p = voiceless bilabial plosive b = voiced bilabial plosive t = voiceless alveolar plosive d = voiced alveolar plosive k = voiceless velar plosive = voiced velar plosive affricates:15 i i i i 14 15 Ladefoged pp. 49-55 Ladefoged pp. 11, 63, 165, 166-7 10 = voiceless palatoalveolar affricate = voiced palatoalveolar affricate (Notice that English has only two affricate sounds and that, on this evidence, they are not especially common.) 11 fricatives:16 i i i i i i i i i i i i i i i i i i = voiceless labiodental fricative = voiced labiodental fricative = voiceless interdental fricative = voiced interdental fricative = voiceless alveolar fricative = voiced alveolar fricative = voiceless palatoalveolar fricative = voiceless glottal fricative ( = voiced palatoalveolar fricative – no example in either text) 16 Ladefoged pp. 61-63 12 nasal stops: i i i i = bilabial nasal stop = alveolar nasal stop = velar nasal stop 13 approximants:17 i i i i = alveolar lateral approximant = centralised approximant = palatal approximant = labiovelar approximant ____________________________________________________________________ The most important distinction among consonants is between the obstruents18 and the resonants ( = sonorant consonants). The obstruents are the oral stops, the affricates and the fricatives (i.e. the consonants that involve an obstruction of the airstream). Obstruents characteristically come in voiced/voiceless pairs (English [h] is an exception). In contrast, resonants (nasals and approximants) are inherently voiced. Because there is no obstruction of the airstream, if there is no voicing then, all other things being equal, there is no useful sound. NB (1) Although the nasals are called stops, the stoppage, which is in the mouth, does not obstruct the air, which exits unimpeded 17 18 Ladefoged pp. 64-66 Ladefoged pp. 62-63, 89-90 14 through the nose. NB (2) It is of course possible to send voiceless breath through the articulatory posture for a resonant with enough force to induce friction. If e.g. you produce a voiceless [m] with sufficient pressure (don’t try this in public when suffering from nasal catarrh) you produce what might be called a voiceless bilabial nasal fricative. But a vbnf is not (in English at any rate) a speech sound, but a sigh. However, some resonants with induced friction are speech sounds: a voiceless alveolar lateral fricative, symbolised [], is a regular sound in Welsh, for instance (and which is therefore not referred to as a ‘resonant with induced friction’, but as a fricative). In English, the palatal approximant [j] frequently becomes absorbed into a preceding glottal fricative ([h]), and the result is a voiceless palatal fricative ([]). E.g. ‘huge’ [] is often pronounced []. But the general principle holds. Some variant realisations of English obstruents p b t d k The pairs at the same place of articulation are ultimately distinguished as fortis (‘voiceless’) vs lenis (‘voiced’). Lenis sounds are (i) produced with less pressure, (ii) regularly shorter than fortis sounds. The reason ‘voiceless’ and ‘voiced’ are in scare quotes here is that although fortis obstruents are always voiceless, lenis obstruents may be voiced (especially in the environment of other voiced sounds, e.g. when intervocalic), but very often are not. The [z] in lazy [] is fully voiced (contrast the [s] in lacy []). But the [z] in dogs [] will not usually involve any more voicing than the [s] in cats []. Nonetheless the [z] and the [s] here are still distinct: [z] is lenis and [s] is fortis. Lenis vs fortis would therefore be preferable to voiced vs voiceless as general terms (i.e. in contexts where no actual utterances are in question) for distinguishing these pairs. But for better or worse the latter are traditional pbtdk Basically plosives (stop plus plosive release). p, t, k aspirated initially in a stressed syllable E.g. proton is stessed on the first syllable; the second syllable is unstressed. So the [t] here is not initial in a stressed syllable, and is therefore not aspirated: []. (Note the diacritic for showing which syllable is stressed.) But attack is stressed on the second syllable, which begins with [t]. So here [t] is initial in a stressed syllable, and will be aspirated: [] (note the diacritic for showing aspiration). p,t,k cause devoicing or voiceless spirantisation of a following approximant. Compare how you pronounce lay with how you pronounce play. In the latter the [l] will either be devoiced: [], or spirantised ( = turned into a fricative): []. Note the diacritic for devoicing and the special symbol for a voiceless alveolar lateral fricative. An initial [s] suppresses aspiration. In this environment the distinction between the voiced and voiceless members of the pairs [p,b], [t,d], [k,] is neutralised. So in top [] the [t] is aspirated (monosyllabic words, if stressed at all, can only be stressed on their only syllable), vs stop [], where the [t] is unaspirated because of the preceding [s]. Note that in this environment an unaspirated [t] is equivalent to a 15 devoiced [d], i.e. []. The fortis/lenis distinction here is inoperative: there is no possibility of contrast between words beginning [sp, st, sk] and words beginning [sb, sd, s]. Say top, and then dop. They are very different. Now try saying stop and then *sdop. Is there any difference at all? If not, you understand what is meant by saying that the [t]/[d] distinction is neutralised in this environment. Sometimes, especially intervocalically, the stop is not completely formed, giving a short fricative sound, e.g. supper [], lacking [] ( = voiceless bilabial fricative, = voiceless velar fricative). Incomplete plosives: when one follows another usually only one plosive release is heard, e.g. in apt the p is incomplete []; also when following a nasal or lateral, especially when homorganic (at the same place of articulation), e.g. goodness [n], bottle [l] . In these cases the plosion of the stop merges with the following resonant, and the stop is said to be nasally or laterally released (transcribed with the appropriate superscript letter). Glottalisation: a glottal stop sometimes accompanies or even replaces some of the oral stops. E.g. in what a hope! [] the vowel may be cut off by glottal closure, the p is then formed, the glottal stop released, and the p exploded normally. Complete replacement by glottal stop: whiteness [n], that bus [], back gate [], black car []. , , , Palatoalveolar fricatives and affricates ( an affricate is a stop followed by fricative release, never incomplete). Some instances derive from sequences sj zj tj dj respectively e.g sure measure venture endure; pronunciations with the palatoalveolar sound may alternate with these. This is a very natural process of assimilation, but may be resisted, especially word initially (do you say [ ], [[ ] for tune, tube)? On the other hand, nobody (?) says [] for sugar. This obstruent is glottal , not oral. Its occurrence is restricted: it must always be followed by a vowel, and tends to be deleted from unstressed syllables. It might therefore be seen, not as a consonant sound in its own right, but as a voiceless anticipation of the following vowel, and transcribed accordingly. 16 ‘The North Wind and the Sun’, showing: i main stress in words of more than one syllable (superscript vertical stroke immediately in front of the stressed syllable); ii aspiration of voiceless plosives when onset of stressed syllable (superscript h after the symbol for the plosive), e.g. came (l. 2), attempt (l. 8); iii aspiration of voiceless plosives when onset of stressed syllable realised as induced devoicing (super- or subscript ring over (under) the symbol in question) of following approximant, e.g. traveller (l. 2), cloak (l. 3); iv aspiration realised on following approximant as spirantisation ( = fricativisation), e.g. disputing (l. 1), cloak (l. 4); v non-aspirated (voiceless) plosives after [s] treated sometimes as devoiced realisations of the corresponding voiced plosive, e.g. stronger (l. 2) (contrast stronger in l. 5); vi voiceless glottal fricative treated sometimes as devoiced onset to the following vowel, e.g. his (l. 4) (contrast his in l. 7); vii coda [l], i.e. ‘dark’ ( = velarised) [l] as [] (fold in l. 7); viii fronted [k] between front vowels as palatal [c] (making in l. 4); ix unreleased plosives (superscript upper right corner), e.g. did (l. 6), at (l. 7); x substitution of glottal for oral stop (out in l. 8); xi affricate formed by fusion of stop + jod (immediately in l. 9). xii variable devoicing of ‘voiced’ obstruents in any position except intervocalically (was in l. 10). Notes: (ii), (iii)/(iv) and (vii) are automatic, i.e. non-optional phonetic features of the accent of English in question (and of many others). An aspirated plosive will cause either (iii) or (iv) to a following approximant, depending on how forcefully the cluster is produced. A devoiced but nonspirantised approximant will be strictly soundless. Unlike for [l], the IPA provides no special symbol for a spirantised []. The pairs of transcriptions referred to at (v) and (vi) are notational variants: there is no difference of pronunciation represented by the different transcriptions of stronger or his. As for (v), given neutralisation of the p/b, t/d, k/g distinctions 17 after [s], it is arbitrary that the sound actually occurring in this position should be interpreted as an unaspirated p/t/k rather than as a devoiced b/d/g. (NB the difference between unvoiced (= voiceless) and devoiced ( = basically voiced, but without voicing in a given context.) Re (viii): [k] is fronted (further forward in the mouth) in the environment of front vowels (you’ll soon find out what a ‘front vowel’ is). If fronter than velar, but not front enough to be palatal, it may be represented as [] (subscript plussign) or [k+]. (ix) – (xii) are ‘optional’, in the sense that the pronunciations represented here are frequent, or even in some cases usual, but may be avoided. (xi) may be seen as arising through the sequence [di] (followed by vowel) > [dj] > [] (compare previous transcriptions of immediately). OK, here we go: i i i 18 i 19 6. The vowels of English The monophthongs19 of a variety of (Southern British) English 19 Ladefoged p. 74. On English vowels in general, see ch. 4 20 The short monophthongs of a variety of (Southern British) English i i i i _______________________________________________ The long monophthongs (with length marked) i i i i 21 Note: ‘short’ and ‘long’ here mean that, other things being equal, when pronounced carefully, in isolation, a word or syllable with a ‘short’ vowel will in fact have a shorter vowel than a word or syllable with a ‘long’ vowel. (In this sense, vowels are sometimes said to be ‘lexically’ short or long, to reflect that we are talking about how they would be transcribed for purposes of indicating in a dictionary the pronunciation of individual words.) So the vowels in cat [], head [] sip [], soot [] are shorter than the vowels in cart [], heed [], seep [], suit []. But note that in actual speech both ‘short’ and ‘long’ vowels may be relatively longer or shorter in particular contexts. For instance, vowels regularly lengthen before voiced consonants, which means that the vowel in use [j] (verb) is longer than the vowel in use [s] (noun), even though it’s the ‘same’ (lexically long) vowel in each case, just as the vowel in fish [] is shorter than the vowel in fizz [], even though both have the vowel [], and [] is lexically short. In rapid connected speech all vowels are liable to be shortened, including ‘long’ ones. To help with indicating these subtleties, where necessary, the IPA has a diacritic for ‘half long’, as in the transcription of use (noun) and fizz above. Diphthongs are lexically long; the length marks are not used with diphthongs except ad hoc to indicate extra length. So e.g. the extra length of the vowel in rise [] is a case of lengthening the already (lexically) long diphthong in rice []. Historically, diphthongs arise by the ‘breaking’ (i.e. failure to maintain the same articulatory posture throughout its length) of a long monophthong. 22 7. Phonetics and phonetic transcription beyond English ‘The North Wind and the Sun’ in another language (phonetics is not just about English!): French (Parisian): t l a Some of the symbols here you have not encountered before: French has a number of sounds that don’t occur in English. Notice particularly : (i) French has vowels represented by the symbols for the cardinal low front ([a]) and mid-high front ([e]) vowels, and has a distinction between [e] and []. (ii) French has three front rounded vowels corresponding to the front unrounded vowels [i], [e], []. The IPA symbols for these are [y], [], [] respectively. Usually, front vowels are unrounded, back vowels are rounded. But lip-rounding is a variable independent of tongue position, and both front rounded and back unrounded vowels are possible, although somewhat rare. Alongside the primary cardinal vowels there is a set of secondary cardinal vowels, where the front vowel at a given height has the liprounding associated with the corresponding cardinal back vowel at the same height. 23 ______________________________________________________________________ Some secondary cardinal vowels (y) () () __________________________________________________________________ (iii) French has a set of nasalised vowels. These are represented by the corresponding oral vowel symbol, plus the nasalisation diacritic. If the above passage is written out as a piece of prose, we see that standard French spelling is as useless as English when it comes to representing pronunciation: La bise et le soleil se disputaient, chacun assurant qu’il était le plus fort, quand ils ont vu un voyageur qui s’avançait, enveloppé de son manteau. Ils sont tombés d’accord, que celui qui arriverait le premier a faire ôter son manteau au voyageur, serait regardé comme le plus fort. Alors la bise s’est 24 mise à souffler de toute sa force; mais plus elle soufflait, plus le voyageur serrait son manteau autour de lui; et à la fin la bise a renoncé à le lui faire ôter. Alors le soleil a commencé à briller, et au bout d’un moment le voyageur, réchauffé, a ôté son manteau. Ainsi la bise a dû reconnaître que le soleil était le plus fort des deux. What is striking here is the number of orthographic letters that correspond to nothing in the phonetics. 8. The Phonology of Connected Speech 8.1 Introduction 8.1.1 There may be big differences between the citation-form pronunciation of a word and the pronunciation of the same word in connected speech. As far as English is concerned, the main differences can be understood in terms of four phonological processes,20 which may occur separately or in various combinations: (i) insertion: the addition of a sound to the citation-form sequence; (ii) assimilation, whereby a sound changes in order to become more like a neighbouring sound; (iii) reduction: replacing a ‘full’ consonant or vowel with a ‘reduced’ version; (iv) the deletion or complete loss of sounds or combinations of sounds; The third and fourth of these, reduction and deletion, may be seen as different stages of one overall process. Complete loss may also be the final outcome of assimilation. 8.1.2 ‘Connected speech’, in this context, does not necessarily refer to long stretches of speech. The phonological phenomena in question arise in fast and/or casual speech, but may be evident in single-word utterances. For instance, the reduction of the second vowel in photograph ] is a connectedspeech phenomenon even though it happens here in a single word, which might occur as a one-word utterance. 8.1.3 There is by no means necessarily one definitive connected-speech pronunciation of a word. Take the phrase fish and chips. The citation form may be given as ] (note the spaces, showing that this transcription represents a slow, careful pronunciation of the individual words). In connected speech, one thing that is likely to happen is that the [d] will delete, because it is in the middle of a sequence of three consonants: ] (note the lack of spaces in the transcription, indicating that we are now considering a single phonetic unit as pronounced, without reference to word boundaries). Another thing that is likely to happen is that the second vowel will reduce, because it is unstressed: [d]. Or, thirdly, both processes may occur together, giving []. Fourthly, because the schwa finds itself next to a resonant consonant capable of becoming 20 But see § 10 below for some remarks on what is meant by a ‘process’ in this context. 25 syllabic, it is likely to be deleted, giving []. So, apart from the citation form, we have four possible connected-speech pronunciations of and. 8.2 Relexification 8.2.1 Although it is useful to analyse connected-speech pronunciations as derived from citation-form pronunciations, it is important to realise that the latter are in certain respects artificial and that in real life, for most purposes, connected speech is the only kind of speech there is. A pronunciation like [] occurs overwhelmingly more frequently than ]. In the course of time this can give rise to relexification, whereby a connected-speech pronunciation becomes the citation form. 8.2.2 Compare the words sandwich and Christmas. Like fish and chips both (at least as far as spelling is concerned) seem to contain a medial sequence of three consonants. In both cases a two-consonant pronunciation is much more likely, with the second, as written, corresponding to nothing in the pronunciation: ], []. The question is whether the d of sandwich and the t of Christmas should figure in the phonetic citation form. This comes down to whether in your slowest and most careful pronunciation you would say ] and []. For me, ] is OK, but *[] is not. In my speech Christmas has been relexified without the medial [ (NB not by me personally – it occurred at some point in the history of the variety of English I happen to speak). I.e. the pronunciation [] does not involve a connected-speech deletion. It may have done so historically, but, in this variety, there is no longer a possible pronunciation that retains the [. As it happens, the Oxford English Dictionary concurs with these judgements: it gives the pronunciations ] for sandwich but [] for Christmas (and indeed says that in the past Christmas has sometimes been spelled without the t). But other speakers may consider that in their most careful pronunciation Christmas has a medial [t]. Every, family and buttery (adj.) all historically had three syllables. Every has been relexified as a disyllable [] (no one ever says []); family is often (usually?) [] but can still also be []; buttery is always []. Frequency of usage is an important factor here. 8.2.3 Because spelling tends to lag behind changes in pronunciation, phonetic relexification is liable to bring about a mismatch between pronunciation and spelling. Given such a mismatch, one of two things is likely to happen eventually. Either the change in pronunciation may be wholly or partially reversed to realign it with the spelling (a ‘spelling pronunciation’), or – more rarely – the spelling may eventually be changed to fit the new pronunciation. Two English place names illustrate these possibilities. Daventry is a town in Northamptonshire, whose name was within living memory pronounced []. Now it is invariably . Conversely, Wyrardisbury is a village in Buckinghamshire whose name was and is pronounced . Nowadays it is spelt Wraysbury. Changes in the pronunciation of proper names are especially liable to speedy lexification – your name, after all, is what you are called – but note that the complex reductions that may characterise the connected-speech pronunciation of proper names are not necessarily typical of other words. 8.2.4 When a connected-speech relexification is enshrined in spelling, the result may be a doublet, i.e. a pair of words originally one that has split into two. ] is a connected-speech pronunciation of courtesy (deletion of the unstressed second vowel): this pronunciation has given a separate word curtsey (a curtsey being a kind of courtesy). Once this has happened, the reduced form ceases or 26 almost ceases to be available as a connected-speech variant of the original word: courtesy is rarely pronounced ] any more, because that would be the word curtsey. 8.2.5 Or there may be a split that gives rise to what are perceived, totally or partially, as separate word forms without any accompanying semantic differentiation. In ordinary English speech, auxiliary verbs when combined with personal pronouns, or with personal pronouns and the negative marker not, almost always occur in forms distorted by connected-speech processes that have come to compete with the citation forms themselves. I am, he is not, we have, I shall, they do not etc., are usually I’m, he isn’t, we’ve, I’ll, they don’t etc. In some cases there are alternative reductions: for he is not do you say he isn’t or he’s not? Granted that there are separate spellings available for the reduced forms, the question is whether e.g. he can’t is just a (very common) way of pronouncing he cannot, or whether it has to some extent an independent existence. Some people say ‘he can’t’ but write he cannot, at least in anything like a formal context. Some people would in appropriate contexts read he cannot aloud as ‘he can’t’. For such speakers the reduced forms still have the status of spoken variants of the full forms, even though the connected-speech variants can be written as if they were different lexical items. And no doubt one wouldn’t expect can’t to have its own dictionary entry alongside cannot. For other speakers, who depending on context sometimes both say and write can’t, sometimes cannot, the two are on the way to separation. In some instances this process is helped along by the degree of divergence between the two forms: he won’t is quite an idiosyncratically long way from he will not, with a vowel change and a consonant loss that don’t conform to a general pattern of connected-speech changes. 8.2.6 The forms I’ll, she’ll, we’ll etc. which reduce both I shall and I will, she shall and she will etc., have contributed to the confusion that reigns over the difference between shall and will. Does I shall go tomorrow mean anything different from I will go tomorrow? Historically it did, and theoretically it still does, according to some grammarians. But most English-speakers today are extremely vague about what the difference might be. What people actually say, most of the time, is I’ll. Any incipient confusion between I shall and I will is magnified by the conflation of the two in the connected-speech form. 8.2.7 Something similar accounts for the ‘substandard’ substitution of of for have in John should never of done it, he must of been out of his mind. Note that have has two distinct functions as an English verb. There is lexical have, as in I have three eggs. And there is auxiliary have, which forms ‘perfect’ tenses of the verb, as in I have boiled three eggs. Of substitutes exclusively for auxiliary have: no one ever says *I of three eggs. The point about auxiliary have is that, except for special emphasis or contrast, it never takes stress, and in most contexts reduces to ], as in she could have (could’ve) tried harder, or just [v], as in I’ve. The preposition of has connected-speech forms that overlap with these: ] or just [], as in cup of tea ()]. The of-for-have phenomenon arises from a faulty interpretation (or re-interpretation) of what citation form a perceived ] is connected with, facilitated by the fact that both of and auxiliary have are small and semantically negligeable ‘function’ words. (The difference between a ‘faulty’ interpretation and a re-interpretation is entirely a matter of acceptance: if and when sufficient speakers of sufficient social standing come to say and write John should never of done it, then we have a re-interpretation: a change in the language rather than a vulgar error.) 27 9. Phonological processes in connected speech: reduction, deletion, assimilation, epenthesis ‘The North Wind and the Sun’ showing vowel reduction in connected speech: 1 5 10 15 20 28 Notes: Reduction to schwa is a function of lack of stress. Notice how often a schwa immediately precedes a stressed syllable. No lexically short vowels (except [], which in this accent functions as an equivalent to schwa, and is not further reduced) survive with their full quality unless they are stressed. The indefinite article (a) is reduced throughout to schwa. Its citation-form pronunciation ([]) only occurs as a citation form, or under contrastive stress, as in ‘that’s a ([]) book, but it’s not the book’. Two instances of the citation-form pronunciation of the definite article [] survive: the other (l. 9) and the attempt (l. 15). In all other cases the is []. In this accent [] is retained in connected speech as the prevocalic allomorph of the article. The reason is that [i] is one of the two vowels (the other is [u]) with a consonantal counterpart: in this case the glide [j]. Before another vowel [i] generates an offglide that serves to break the vocalic hiatus: [], []. Other and attempt here thus begin with a very light [j]-sound. But NB it is not a full [j], which is treated as a regular consonant, and takes the regular preconsonantal allomorph: contrast [] the ale with [] the Yale (key, alumnus…) The latent [] of stronger (l. 20) surfaces before a vowel, because it is free to become the onset of the vowel’s syllable. The syllabification here is: [....] 29 As above, plus consonant reductions, assimilations and deletions (deletion sites indicated ad hoc by *): * 5 m * 10 * * ** 15 *** ** * 20 30 Notes: Just as reduction of vowels to schwa is the first stage of a process whose second stage is outright vowel deletion, so glottalisation of stops is the first step towards outright consonant deletion. Either may happen, depending on how fast/carelessly you’re speaking. Compare [] (l. 7) with [] (l. 12) The very common word and is very frequently reduced in casual speech to a syllabic nasal, as in l. 1. and the to [], as in l. 3. The deletion of the [t] in [] (l. 7) has caused the resulting [ss] sequence to fuse into one long [s]. Similarly, the assimilation of [n] to [m] in [m] (l. 8) has caused lengthening of the [m]. Using the length mark to indicate a long consonant is logical but, unfortunately, unusual; by convention the length mark is usually reserved for vowels, and long consonants are indicated by doubling the consonant symbol ([mm]) – which, if as is usual the ligature is not used in this context – leaves you no way of indicating as phonetically different a sequence of two identical consonants. 31 Consonantal epenthesis in English: 1. prince triumph Corinth length amongst once warmth nymph tenth 2(a) hear wear star stir clear store director hearing wearing starry stir up clear up store away director of (b) ma ma and pa saw saw an accident Russia Russia and Poland draw draw a circle Laura Laura Ashley diploma diploma in drama idea idea of his Accents of English vary as to whether they are rhotic or non-rhotic. Rhotic accents essentially have an r-sound (whether it be a trill or an approximant) wherever there is an r in the spelling. Non-rhotic accents do not have an r in syllable codas.21 Hence, in 2(a) above, the alternation between a form with a pronounced r (in this accent phonetically []) and a form without. The fact that non-rhoticity gives rise to such alternations explains the so-called ‘intrusive r’ phenomenon illustrated in 2(b). A syllable coda consists of the consonant(s) that may appear after the vowel of a syllable. Non-rhotic speakers pronounce the r in red, arrow, hurry, because they appear before the vowel of the syllable, but not in art, bird, father, where the r is after the vowel. Rhotic speakers pronounce r wherever it occurs. More on this later. NB certain South African English speakers, although basically non-rhotic, sometimes pronounce a phrasefinal or even word-final r. I.e. although they would never have an r sound in bird, they might do in burr. 21 32 Assimilation22 Assimilation is the process whereby one sound becomes more like an adjacent sound. It is, in general, the single most important phonological process. The interaction of assimilation and epenthesis: We say that in English a regular noun forms its plural by adding –s. Thus bat ~ bats, tiger ~ tigers, tank ~tanks, field ~fields. Sometimes we spell the plural ending –es: in such cases the e may or may not correspond to something extra in the pronunciation. So class ~ classes, church ~ churches, where the plural has two syllables as compared with one in the singular, but potato ~ potatoes, where the e seems to be purely orthographic (= present in the spelling, but not corresponding to anything in the pronunciation). Looking at the matter phonetically, things are rather more complicated. Phonetically there are three variants of the –(e)s plural ending:[s], [z] and [z]. How are they distributed? [z] occurs when the singular form ends in [s], [z], [], [], [] or [] (i.e. when it ends in a sibilant sound). So: glass []~ glasses [], phase [] ~ phases [], splash [] ~ splashes [z], [] ~ [], [] ~ [z], etc. [s] occurs when the singular ends in a voiceless sound other than a sibilant. So: [] ~ [s], [t] ~ [ts] etc. [z] occurs when the singular ends in a voiced sound other than a sibilant. So: lamb [lm] ~ lambs [lmz], [] ~ [z], [fild] ~ [fildz], [] ~ [z], etc. As speakers of English we are not usually aware that there are three different regular plural endings. Psychologically there is just one: -(e)s. The reason that there are phonetically three endings is that the precise phonetic form taken by –(e)s must adapt itself to the particular phonetic environment it finds itself in, which will be different in different cases. But, given that we feel these to be three different versions of the ‘same’ thing, can we establish one of them as the basic form of which the others are variants? 22 If we take [z] to be the basic form, we can say that it appears in full when preceded by a sibilant, that the [] is dropped after anything but a sibilant, and that the [z] changes to an [s] after a voiceless non-sibilant (manner – in this case, voicing – assimilation). If we take [s] to be the basic form, we can say that it appears as such after a voiceless non-sibilant, that it voices to [z] after a voiced non-sibilant (again, manner assimilation), and that if the singular ends in a sibilant, the [z] is preceded by an inserted [] (epenthesis). If we take [z] to be the basic form, we can say that it appears as such after a voiced non-sibilant, that it unvoices to [s] after a voiceless non-sibilant (voicing assimilation again), and that epenthesis is required after a sibilant. Ladefoged p. 109 33 Is there any way of choosing between these statements? Note that it is a basic rule of English phonetics ( = a phonotactic rule) that obstruent clusters must agree for voicing. You can have a cluster of two voiced obstruents, or of two voiceless obstruents, but not a cluster consisting of both voiced and voiceless obstruents. It is another basic rule that you can’t have a sequence of two sibilant obstruents. So, whichever of the three alternants you start with, the phonotactics is going to give you the other two in the appropriate complementary contexts. Is there a reason for preferring one way of stating how the system works to another? What you need is a context where the choice between [s], [z] and [z] is not enforced by the basic phonetics. The illegality of obstruent sequences such *[ds], *[kz], *[sz] has nothing particularly to do with the formation of noun plurals. It applies across the board: there are no words in English, whether nouns, plural nouns, or anything else, that have such obstruent sequences. So, the question is whether there is an environment where as far as the phonetics is concerned you have a choice, and where the noun pluralisation system makes a choice. Yes, there is. After a vowel, English phonotactics allows you to have either [s] or [z] quite freely. So we have pairs of words like his [] ~ hiss [s], prize [] ~ price [], etc. But look what happens when the vowel in question is the final segment of a singular noun, to which you are going to add a sibilant to form the plural. In every case, the plural of a noun whose singular ends in a vowel adds [z]. Phonetically (phonotactically) it could add [s]. But that never happens with a plural noun. Take the sequence [b…] You can follow the vowel [] with either [s] or [z]. If you add [s] you get [bs] brass, which is not, and could not be, a plural noun. If you add [z], you get the plural of bra. That is an argument for taking [z] to be the basic form. The argument can be extended: when you get the epenthetic [] after a sibilant, as in churches etc., once again, phonotactically, you could have either [s] or [z]: there is nothing unpronounceable or unEnglish about the sequence […s…], as in hiss, list , etc. But when the ending of a plural noun is in question you only ever get [z]. Exactly the same distribution of forms, and the same arguments for taking [z] to be basic, apply to [s], [z], [z] as allomorphs of the ‘apostrophe s’ possessive or genitive morpheme, as in Jack’s [s], John’s [z], Alice’s [z], and as allomorphs of the 3sg present verb ending, as in he stamps [s], she stammers [z], he preaches [z]. And (although in this case things are a little more complicated) the same kind of distribution, this time involving the plosives [t], [d], applies to the ‘weak’ past-tense ending in verbs: she danced [t], he smiled [d], they landed [d]. Notice that, as it happens, in these examples the psychological unity of the ending is reflected in the spelling: as with [s], [z], [z] there are three different pronunciations, but in each case the corresponding spelling is –ed. But note that orthographic unity does not apply across the board – consider burned ~ burnt and similar pairs, where there are different spellings but not or not always (for many speakers) different pronunciations. These are called morphophonetic (or morphophonological) alternations, so called because they are phonetic (or phonological) adjustments to how a given morpheme is pronounced, giving rise to a series of allomorphs. Here we have a transcription of one of the passages that abstracts away from certain morphophonological alternations. (It also, incidentally, abstracts away from the rhotic/non-rhotic distinction): 34 +z + + +z +d +d +d +d +d +d +z +z +z +d 10. The fictional nature of phonological processes What we are talking about here is, essentially, phonological relationships. For instance, there are phonological relationships (of different kinds) between the [p] of [p] and the [p] of [sp], between the [t] of [] and the [d] of [], between the [n] of [] and the [m] of [], and so on and so forth. We recognise that the alternations here ([p] ~ [p], [t] ~ [d], [n] ~ [m]) are, to whatever extent, systematic, predictable and therefore part of the subject matter of a phonological acount of a language – or, if generalisable across different languages – of language generally. Such phonological relationships are usually conceived of in dynamic terms. That is to say, we discuss them in terms of phonological processes. We don’t simply set e.g. [p] and [sp] down side by side and compare and contrast them, but talk about a process whereby one alternant ‘becomes’ or ‘changes into’ another. So in this case we talk of a process of aspiration, converting an unaspirated [p] in [sp] into an aspirated [p] in [p]. And then we look for the general conditions under which this process operates: in English a voiceless plosive is aspirated if it is initial in a stressed syllable, but not if it occurs as the second element in a cluster after [s]. But it is important to remember that this talk of ‘processes’ does not model or correspond to what actually happens in speaking or in interpreting speech: when we produce an aspirated [p] in [p] there is no sense in which this is somehow the result of actually ‘doing something’ to an unaspirated [p]: we just say [p]. One reason it is important to remember this is that it explains why there is no answer to a question e.g. about which way round such a process operates. Why don’t we take the aspirated plosive as basic and state the circumstances in which a converse process of ‘de-aspiration’ takes place? Well, we could, in principle. In practice such choices are determined, if possible, by the overall economy, neatness etc. of the resulting description. Sometimes it makes no difference, and the choice is arbitrary. The thing to bear in mind is that there is no right or wrong in the matter: talk of processes is a way of describing relationships, not a way of stating what speakers actually do when speaking their language. We have already looked at a certain range of phonological processes, when we discussed the phonology of connected speech. So, for instance, we looked at the way in 35 which a transcription like [] relates to a transcription like [] in terms of processes such as deletion, vowel reduction, etc. One again, this talk of processes is figurative: there’s no sense in which we arrive at an utterance like [] by ‘starting from’ [] and then proceeding to delete segments, reduce vowels, etc. Nor, as hearers, do we understand the utterance by performing the converse operations and reconstructing the citation form. In fact, what we call ‘connected speech’ is simply speech; the ‘citation forms’ from which we derived the connected speech forms are artificial, to be heard, if at all, only in special contexts such as elocution lessons, etc. Citation forms are the result of an attempt to codify the ‘full’ or ‘correct’ pronunciation of individual words. The reason for starting from citation forms and then proceeding to explain how connected speech pronunciations differ is simply that it’s a convenient way of getting a handle on the phonological phenomena we want to look at: this kind of analysis doesn’t represent the ‘reality’ of speech as it is for either speakers or hearers. This explains several things that might have puzzled you. It explains why there is often doubt as to what the citation form ‘really’ is. How would you transcribe banana? Probably something like [, with schwas in the unstressed syllables. But we know that schwa in English is at least very often the result of what we call the ‘process’ of vowel reduction. Why shouldn’t we treat all occurrences of schwa as the ‘result of’ schwa reduction? In this case that would mean setting up a citation form such as [], and then derive [ from it as a connected- speech form. There is no very good answer to the question. The pragmatic rule of thumb we have been working with is: are there any circumstances at all in which we might pronounce a given citation form? If we are going to treat schwa as always and everywhere derived by reduction from some other vowel, that would require finding some other vowel to reduce to schwa in a case like the suffix(es) –er, as in agent nouns like driver or comparatives like faster. But clearly (at any rate if we’re non-rhotic) we never do have any other vowel here. So we treat the schwa as basic and ‘given’. At the other end of the spectrum, consider the first syllable of the verb (or adjective) compact [. Here we have no hesitation in deriving the schwa via reduction from : we have the noun compact, with stress on the first syllable, which always has . In between there’s a large number of cases where the do-you-ever-pronounce-it-like-that? criterion doesn’t give a clear answer. Do we ever pronounce banana as []? I for one have no very clear intuition : I suppose I just about might say [] if I was, so to speak, spelling out its most ‘correct’ pronunciation as clearly as I could for the benefit of a child or a foreigner, especially if I wanted to suggest the spelling, but I wouldn’t be surprised if other English-speakers disagreed with me. So this criterion for deciding on a citation form is unsatisfactory, if you expect or hope that it will yield a clear, determinate answer in all cases. But that shouldn’t be too surprising and not at all alarming, if you remember that in the end citation forms are artificial constructs set up for various metalinguistic purposes – in this case, to provide a convenient format in which to make statements about phonology. However, not only is the criterion difficult to apply in many cases, its usefulness is in any case limited, and we come up against that limit if we want to look in the most general possible way at phonological processes. Applying it, or trying to apply it gives you a phonological description in which some processes are identified as such, whereas others are left hidden beneath transcriptions. Let me explain what I mean by that. You’re already familiar with the distinction between broad and narrow transcriptions. The very first transcriptions you looked at were quite broad, with a lot of systematic phonetic detail left out. So you transcribed both pat and spat with an ordinary [p], leaf and feel with an ordinary [l], and so on. Then you learned about some systematic alternations, between aspirated and unaspirated [p], between ‘clear’ and ‘dark’ [l], and so on, which would be marked as 36 such in a narrower transcription. So you progressed from transcribing pat as [] to transcribing it as [p]. And leaf and feel similarly. In terms of the broad / narrow distinction, a broad transcription allows aspiration, or velarisation, to emerge as such, i.e. as processes of aspirating or velarising, not represented in the transcription as already ‘there’, but accounted for in a phonological rule for interpreting such a transcription. Whereas a narrow transcription simply represents an aspirated plosive as aspirated and an unaspirated plosive as unaspirated. Unlike the broad transcription, it doesn’t analyse the aspiration process out of the transcription – i.e. it doesn’t abstract away from aspiration). Suppose we forget about the broad/narrow distinction, and instead set about applying the do-you-ever-pronounce-it-like-that? criterion to the question what to include in the transcription and what to abstract away from. In terms of that criterion, aspiration would have to be left in the transcription. Because in almost all accents of English, voiceless plosives are routinely aspirated when stressed-syllable-initial. Leaving aside the speech of second-language English speakers whose first language doesn’t have aspiration, there simply isn’t a pronunciation of a word like pat, no matter how ‘careful’, without the aspiration. In contrast, the criterion does allow you to abstract away from the nasal assimilation in phrases like chain gang, in pieces, because there are alternative pronunciations that don’t have the assimilation. So we can derive chain gang with a velar nasal from chain gang with an alveolar by talking about a process of nasal assimilation. But, as against that, you have to treat some cases of word-internal nasal assimilation, as in [] (cf. []) as ‘basic’, according to the criterion, because there is no other pronunciation of impossible. You can’t set up *[] as the citation form, because it’s never pronounced like that. And this makes it different from incredible, because alongside the pronunciation with the velar, you can also have the alveolar. We have described this situation by saying that in a case like impossible the nasal assimilation has been lexicalised (i.e. made part of the citation form), whereas in incredible it hasn’t. That is true. But if we want to look in the broadest possible way at phonological processes, we aren’t concerned about the question whether in particular words a process has been lexicalised. One reason for that is that lexification is an historical process, and the phonological processes we want to investigate cut across the distinction between synchronic and diachronic ( = historical) linguistics. Phonological processes give rise to synchronic phonological alternations, but also to historical phonological change. For instance, the plural of house [h] is houses [h]. We take it that the same stem morpheme appears in both forms, but there is an alternation between [s] and [z] as the final consonant of the stem. There is a phonological process that takes place to cause the alternation – either voicing (if we take the final consonant as it appears in the singular as basic) or devoicing (if the plural stem is basic), and in a case like this the process is synchronic: it applies as between different forms found in the language at the same time. The word knight was once pronounced, as the spelling suggests, with an initial [k]. There has been an historical change in English whereby initial velar + nasal clusters have been reduced by dropping the velar (cf. kneel, gnat, gnaw), i.e. an historical process of cluster simplification. As it happens, in this case there is no synchronic alternation – there is no coexistent form of a word like knight that retains the [k]. So we want to treat the various instances of a process like nasal assimilation as what they are – instances of the same process, and not confuse the analysis by insisting on irrelevant criteria (e.g. has it been lexicalised in particular words?) for what is included in a transcription and what is abstracted out of it as a general process. In short, we’re 37 going to allow for transcriptions that are much more abstract (i.e. further away from a transcription of any actual pronunciation) than even the broadest transcription you have seen so far. In fact in the end we’re going to replace the broad vs narrow distinction with an abstract vs concrete distinction. But that’s enough for now: this will be pursued further if you study historical linguistics next year. Now it’s time to turn to phonological structure above the level of the segment. 38 Suprasegmental Phonology 1 Syllables 1. 1 Introduction 1.1.1 Everyone finds syllables fairly easy to identify. But people who have not been educated in an alphabetic writing system do not automatically find it easy to think of syllables as made up of segments. Thinking of syllables in this way was what led to the alphabet, which has apparently only been invented once. (The various different extant alphabets are merely variations on the Greek version.) 1.1.2 Although there are usually no practical difficulties in saying how many syllables there are in a word or phrase in one’s own language (but for English see exceptions in §1.1.3 below), the syllable is difficult to define in phonetic terms; i.e. it is hard to say what a syllable is or to find a universally applicable objective procedure for identifying the boundaries between them. Hence the definition that a syllable is what the word syllable has three of. 1.1.3 Three examples of syllable-counting difficulty for English-speakers. They all have to do with the variable extent of glide-formation. (1) How many syllables in words containing a long high front vowel followed by a velarised ( = ‘dark’) [l]? E.g. meal, seal, real. Some would say that these are monosyllabic: [mil], [sil], [il]. The problem is that a velarised [l] tends to causes retraction and lowering of a preceding vowel. So even for those for whom there is just one vowel here, it is liable to diphthongise, moving towards a backer and lower quality: perhaps [l]. And this diphthong may be perceived as a sequence of two vowels ([]), giving a disyllabic analysis. Furthermore, the high front vowel generates an offglide, hence a narrow transcription []. In the extreme, the offglide may be perceived as fully segmental: [], so that we now have a full-blown CVC second syllable (mee-yull). (2) How many syllables (for non-rhotic speakers) in words like hire, fire, hour? The orthodox pronunciation (in SBE) is probably [] [] [], i.e. two syllables. But there is variation as to whether these pronunciations are considered to be mono- or disyllabic. This depends on the extent to which you allow an offglide to appear after the diphthong: i.e. even if you think you’re saying [] you are probably in fact saying [], which may become [], i.e. CVCV – two syllables. If you suppress the offglide you are more likely to perceive only one syllable, especially if the final schwa is unemphatic, which will tend to encourage the idea that the three vowels form a unitary triphthong. Do you think you have different pronunciations of hire and higher, flour and flower? (In this latter case the vowel in question is [] – which in many people’s speech more like [] – i.e. low and either back or moving back, so the glide in question is [].) If you do, it’s probably a matter of having one syllable in the first of each pair, two in the second. Flour and flower is an interesting case: historically there was just one word, whose most usual spelling was flour (meaning both ‘flower’ and ‘the finest part, i.e. the flower, of the wheat’); the definite spelling differentiation of the two senses dates only from the eighteenth century. (3) How many syllables in words like mediate, heavier, neolithic, which contain unstressed high vowels followed by another vowel without an intervening 39 consonant? The vowel is variably likely either to generate an offglide or itself to turn into a glide. So e.g. [] (three syllables) is liable to become either [] > [], or alternatively [] (two syllables). 1.2 The importance of the syllable as a phonological unit 1.2.1 The fact that syllables are important units is illustrated by the history of writing: many writing systems use or used a syllabary: one symbol for each syllable. The development of the alphabet involved splitting syllables into their perceived components. About 4000 years ago the Greeks modified the Semitic syllabary so as to represent consonants and vowels by separate symbols; later alphabets (Roman, Cyrillic, etc.) derive from the Greek. 1.2.2 There are many phonological generalisations that can only be stated clumsily, if at all, without reference to the syllable. For example, it’s commonly said that the difference between rhotic and non-rhotic varieties of English is that the latter don’t have ‘postvocalic’ r. This is an attempt to state the facts without reference to the syllable concept. So it is said that the r in bird or father is not pronounced, in nonrhotic English, because it comes after a vowel. But so does the r in hurry, yet the r here is pronounced. So the statement of where r doesn’t appear has to be modified to something like ‘not after a vowel, unless the r is itself followed by a vowel’. It’s much easier – and truer, in the sense that it captures more accurately what is going on – to say simply that in non-rhotic English r doesn’t appear in syllable codas. (In hu.rry the r is the onset of the second syllable.) 1.2.3 For another example, consider the distribution of [] as a variant of , in those English accents that have this. Cat can be [], nightly can be [], right one [], night rate [] but the (first) t in words such as entail, nitrate, entwine is much less likely to be a glottal stop. So where can you have [] substituting for [t]? Notice how difficult it would be to state the distribution in terms merely of sequences of segments, as such. (The pair night rate and nitrate are significant here: they are near-identical except that the former allows the glottal stop and the latter does not.) Any such statement would be clumsy and unrevealing, and would require the acknowledgement of exceptions: although patrol [] never has a glottal stop, petrol may (for some speakers). A much better way of stating the distribution is with reference to syllable structure. [] can appear for syllable-finally, but not syllable-initially. The explanation for the fact that some speakers may pronounce petrol as [ is that there are two ways of syllabifying the word: pet.rol or pe.trol (see also §1.8.4 below). 1.2.4 Spoonerisms provide further evidence for the importance of the syllable as a phonological unit. A spoonerism is a speech error in which segments or clusters are swapped around. So round moon might come out as *mound rune. I.e. the first Cs of the words have been switched. But dear queen if spoonerised, would not be *kear dween but *queer dean. That is to say, the correct generalisation here is that syllable onsets (see §1.6) may be switched round. 1.2.5 Syllable structure also allows a neat explanation of why certain consonant sequences may appear word-medially or across a word boundary within a phrase, but not word-initially. Given that sleepwalk [pw], lab worker [bw], live wire [vw], leafworm [fw] are perfectly good English, why are *pwell, *bwee *vwoot *fwite impossible English words? Because the relevant phonotactic rule is that the sequences in question mustn’t be tautosyllabic – they can occur as sequences, so long as they aren’t in the same syllable. 40 1.2.6 Here is a French example: grève ‘strike’ ~ gréviste ‘striker’ crème ‘cream’ ~ écrémé ‘creamed’ sèche ‘dry’ ~ sécher ‘to dry’ Liège ‘Liege’ ~ Liégeois ‘of/from Liege’ j’espère ‘I hope’ ~ espérer ‘to hope’ je cède ‘I give in’~ céder ‘to give in’ 1.2.7 Another illustration from French. 1. l’ami ‘the friend’ ### .. . 2. le petit ami ‘the little friend’ #### .... ... 3. le bon ami ‘the good friend’ #### ... ... 4. les amis ‘the friends’ #+#+# .. .. 5. les petits amis ‘the little friends’ #+#+#+# .... ... 6. les bons amis ‘the good friends’ #+#+#+# ... ... 41 7. l’amie ‘the friend’ (f.) ##+# ... . 8. la petite amie ‘the little friend’ (f.) ##+#+# ...... ... 9. la bonne amie ‘the good friend’ (f.) ##+#+# ..... ... ‘the friends’ (f.) #+#++# ...# .. 10. les amies 11. les petites amies ‘the little friends’ (f.) #+#++#++# ...... ... 12. les bonnes amies ‘the good friends’ (f.) #+#++#++# ..... ... 13. le chat ‘the cat’ ### . . 14. le petit chat ‘the little cat’ #### ... .. 15. le bon chat ‘the good cat’ #### .. .. 42 16. les chats ‘the cats’ #+#+# . . 17. les petits chats ‘the little cats’ #+#+#+# ... .. 18. les bons chats ‘the good cats’ #+#+#+# .. .. 19. la chatte ‘the cat’ (f.) ##+# .. . 20. la petite chatte ‘the little cat’ (f.) ##+#+# ..... .. 21. la bonne chatte ‘the good cat’ (f.) ##+#+# .... .. 22. les chattes ‘the cats’ (f.) #+#++# .. . 23. les petites chattes ‘the little cats’ (f.) #+#++#++# ..... .. ‘the good cats’ (f.) #+#++#++# .... ..] 24. les bonnes chattes 43 1.2.8 We can see from §1.2.7 that French is a language where syllable boundaries frequently fail to coincide with word boundaries. This can be further illustrated from La bise et le soleil (‘The North Wind and the Sun’): (i) normal writing: La bise et le soleil se disputaient, chacun assurant qu’il était le plus fort, quand ils ont vu un voyageur qui s’avançait, enveloppé de son manteau. Ils sont tombés d’accord, que celui qui arriverait le premier à faire ôter son manteau au voyageur, serait regardé comme le plus fort. Alors la bise s’est mise à souffler de toute sa force; mais plus elle soufflait, plus le voyageur serrait son manteau autour de lui; et à la fin la bise a renoncé à le lui faire ôter. Alors le soleil a commencé à briller, et au bout d’un moment le voyageur, réchauffé, a ôté son manteau. Ainsi la bise a dû reconnaître que le soleil était le plus fort des deux. (ii) word-by-word transcription: t l a (iii) connected-speech transcription showing syllable boundaries, with highlighting of syllables that cut across word boundaries: ..................... . 44 ..................t. .....l................. .. .................... .................... ..................a..... ..................... . ............... The extent in practice to which codas become onsets depends on where pauses occur, which depends on speech style, etc. In this transcription all conceivable instances have been marked, but the process will not take place across a pause. Note the lowering of to in et (l. 1), soufflé (l. 4) – cf . §1.2.6. Note that the retention and deletion of coda consonants exemplified in §1.2.7 is sensitive to grammatical environment. E.g. the [n] of chacun assurant (l. 1) and the [z] of plus elle (l. 4) disappear notwithstanding the possibility in this context of becoming the onset of the next syllable. The historical final consonant of certain lexical items, e.g. et ‘and’ never appears in any environment. 1.3 The structure of the syllable 1.3.1 A syllable obligatorily contains a nucleus, and in the case of syllables consisting of a single vowel (e.g. monosyllabic words like eye []) is nothing but a nucleus. A syllable may optionally have an onset and/or a coda each consisting of one or more Cs. A syllable with a coda is said to be closed; one without is open. 1.3.2 The nucleus and the coda (if any) together make up the rhyme (sometimes spelled rime), an important constituent in its own right. For instance, it is the nature of the rhyme that determines syllable weight (see §1.10). Rhyme means what it says: what linguists call the rhyme is the part of the syllable relevant for establishing rhymes in the verse of English and other languages. The syllable onset is irrelevant, just as pig doesn’t count as rhyming with pat, even though the onsets are the same. The nucleus by itself, or the onset plus the nucleus, aren’t what matters either: pig and bin or pig and pin give you assonance, but they don’t rhyme. Congruence of codas alone, as in sand, bend, wind yields a verse effect known as ‘chime’, but by the rules of English versification these aren’t proper rhymes. Proper rhyming requires the sameness of the nucleus plus the coda (i.e. the rhyme) of the final syllables of the rhyming lines. 45 1.3.3 You might suppose that the most fundamental kind of syllable is one consisting of a single V, i.e. of the one obligatory element necessary to have a syllable at all. But it is not. The most basic syllable structure is CV – i.e. an open syllable with a single-consonant onset. It’s the most basic in that every language has CV syllables whether or not it also has other types (and many do not), and CV is universally the first syllable type acquired by the child. 46 1.4 The nucleus 1.4.1 The nucleus of a syllable is usually a vowel, but may exceptionally be a resonant (= sonorant C). Consider the word gentleman []. This has three syllables, but only two vowels. Between the two syllables whose nucleus is a vowel is a third syllable, consisting of the lateral approximant [l]. A narrow transcription would be [], with the diacritic indicating that the consonant is syllabic. 1.4.2 The word gentleman is always trisyllabic. Other words with syllabic consonants may have variant pronunciations where the consonant in question is optionally nonsyllabic, reducing the number of syllables by one. Consider the word traveller. This may have two syllables ([]), or three, in which case a narrow transcription would be []. The same applies to a word like rumbling, which may be either [] or []. The two syllabifications are [.] and [..]. As against this an apparently similar word like duckling has only a disyllabic pronunciation: there is no alternative with a syllabic [l]. What accounts for these variations? 1.4.3 Historically the words travel and gentle once had two vowel-nucleic syllables. Travel is a variant of travail, and derives from the French word travail [] ‘work’. (Travelling was once more arduous than it generally is today.) Originally it was [], and perhaps even now that could be set up as the most basic citation-form pronunciation. However, there is a general tendency (i) for unstressed vowels to be reduced to schwa, giving [], and (ii) for the schwa itself then to be deleted if followed by a resonant C capable of being syllabic; hence []. If you now add a syllable beginning with a vowel, as in traveller, one of two things can happen. Either (i) the syllabic consonant retains its syllabicity, and you simply add a third syllable ([..]), or (ii) the syllabic [l] loses its syllabicity and becomes either the onset of the second syllable ([.]), or, in a case like rumbling, the second element in an onset cluster ([.]). The same considerations apply to a word like gentler ‘more gentle’, which has both di- and trisyllabic pronunciations. But the [l] of gentleman can’t lose its syllabicity because there is no vowel immediately to its right such that it could become the onset of a syllable whose nucleus was that vowel. Finally, why isn’t there a trisyllabic variant of duckling? Because the morphological structure is duck+ling: the [l] was never anything but the onset of the second syllable (the first segment of the diminutive suffix –ling). Rumbling is what you do when you rumble, but duckling is not what you do when you duckle. 1.5 The sonority hierarchy and sonority sequencing 1.5.1 The nucleus is the most sonorous element in the syllable. In acoustic terms, the sonority of a sound is its loudness relative to that of other sounds of the same length and pitch (the louder, the more sonorous). Try saying the vowels [,,,,]. You can probably hear that [] has the greatest sonority (due, largely, to its being pronounced with the mouth wider open. 1.5.2 We can establish a sonority hierarchy. Low vowels are more sonorous than high vowels. The approximant [l] has about the same sonority as the high vowel [i]. The nasals [m, n] have slightly less sonority than [i], but greater sonority than a voiced fricative such as [z]. The voiced stops and all the voiceless sounds have very little sonority. 47 1.5.3 NB distinguish sonority and sonorous from the classificatory term sonorant. Sonorants are defined in opposition to obstruents, i.e. they are the resonant consonants plus the vowels. But notice that there is an important relationship between the terms – sonorants are more sonorous than obstruents. In general, to a rough approximation, the standard way of setting out a language’s inventory of speech sounds, starting with the plosives on the left (or at the top) and ending with the vowels on the right (or at the bottom), corresponds to the acoustically defined sonority hierarchy. The most sonorous sounds are vowels, which are voiced, continuant and sonorant. The least sonorous sounds are those that least resemble vowels, i.e. voiceless plosives, which are neither voiced nor continuant nor sonorant. Voiced plosives are (slightly) more sonorous because they are voiced. Voiceless fricatives are more sonorous because they are continuants. Voiced fricatives are more sonorous than voiceless ones because they are both voiced and continuant. Resonant (i.e. non-obstruent) consonants (i.e. nasals, liquids and glides) are more sonorous still because they are sonorants. In English, resonants are the only consonants sufficiently vowel-like to be allowed as syllabic nuclei (but see §1.9.1 below). 1.5.4 Syllables to a greater or lesser degree obey a principle of sonority sequencing. If you start from the nucleus (the most sonorous element), sounds become progressively less sonorous as you move out towards either edge of the syllable. Take e.g. crashed []. [] is a voiceless plosive, and therefore less sonorous than [], which is an approximant (a liquid). [] is the nucleus. [] is a fricative, and therefore less sonorous than [], but more sonorous than [], another voiceless plosive. 1.5.5 Why, when we borrow into English French monosyllables like centre [], entre [], humble [], mètre [], do we make two syllables out of them: cen.tre, en.ter, hum.ble, me.ter? Because the French plosive-liquid coda clusters violate sonority sequencing. This is allowed (in this kind of case) in French, but not in English. The l or the r is more sonorous than the preceding plosive, and therefore can’t follow it in the same syllable. So it has to be in a separate second syllable. (NB although the usual French r-sound [] is a uvular trill, and thus technically a stop in terms of a phonetic description, phonologically it does not behave like an obstruent, and is higher up the sonority hierarchy than any stop. This applies to all r-sounds, whatever they may be phonetically.) Similarly, French regularly allows the resonant m to stand outside the obstruent s in the same syllable. Hence the fact e.g. that in French the suffix -isme (as in communisme, etc., is a single syllable, whereas in English the corresponding form -ism is two syllables, with a syllabic m as required by sonority sequencing. 1.6 Onsets 1.6.1 Simple (i.e. one-C) onsets in English may consist of any consonant except the velar nasal []. Why can’t be a syllable onset in English? Because historically it was a positional variant of [n] before a velar plosive [k] or [], as in sink [], anger []. In some contexts it has gone on to absorb a following [], as in bang [], sing [], which is why it can now appear by itself as a coda. But its impossibility as an onset is a reflection of the impossibility of [] as an onset. 1.6.2 In accordance with sonority sequencing, complex onsets in English basically consist of an obstruent (plosive or fricative) followed by a liquid or glide, as in plot, press, bloom, brick, flag, frock, clock, crack, glad, grill, trap, dress, thrill, slum, 48 shrill, shriek, cute, duke, twin, dwell, queen, thwart, swell… Homorganic or quasihomorganic onsets or not allowed (in most accents). E.g. in SBE there are no syllables beginning [tl, dl] (both elements alveolar), and no syllables beginning [pw, bw] (both elements labial) unless you count certain foreign words as belonging to English: Puerto Rico [pw…], Buenos Aires [bw…]. (Cf. §1.2.5 above.) 1.6.3 The above statement about onsets needs fine-tuning: (1) The glide [j] as the second element in an onset is peculiar, for three reasons. First, it can be preceded not only by an obstruent but also by a nasal or a liquid: mute, newt, lure. Secondly, it is recessive. If the preceding obstruent is alveolar [s], [z], [t], [d] it is liable to be absorbed into a palatoalveolar fricative (in the case of [s], [z]) or affricate (in the case of [t], [d]): sugar [] > , tube > ; or, in any kind of cluster, it may be dropped altogether: suit [] > . (This last possibility has been taken a good deal further in some American accents than in SBE.) Thirdly, it rarely occurs nowadays in any accent unless the vowel of the syllable is [u] or , as in all the examples given here. Before other vowels it has mostly disappeared, or is on its way to disappearing: soldier ] > ]. At one stage in its history the very common abstract noun suffix –tion had [], now invariably []. (2) In two-consonant onsets [s], unlike other obstruents, can appear before a nasal (smug, snow), and violates sonority sequencing by appearing very frequently outside voiceless plosives (spot, stain, scab. . .). See further remarks on [s] in §1.9 below. 1.6.4 Some languages allow what to English ears are highly exotic onsets. For instance, certain African languages which have nasal-plosive combinations syllable-initially, as in names such as Mbeki, Ntini, Nkomo. In pronouncing such words, English speakers tend to adapt these (for them) ‘impossible’ onsets to make them fit in with English phonotactics, by inserting an epenthetic vowel either before or after the nasal, or by making the nasal itself syllabic: [] or [] or [], etc. This has the desired effect by changing the syllable structure in such a way that the nasal and the plosive are no longer tautosyllabic: [..], [..], [..]. 1.7 Codas 1.7.1 Codas in English are more complicated than onsets. What consonants can form a simple coda? Any, except , [] (in non-rhotic accents) and, arguably, the glides j and [w]. The non-occurrence of [h] in codas fits in with analysing it as a voiceless precursor to a stressed vowel. The reason there is room for argument about [j] and [w] is that it depends how you treat diphthongs ending in high vowels, i.e. ending in ] (or ]), [] (or []). How exactly do you pronounce words like high, how? It’s quite likely that you have at least a detectable offglide at the end: [h], ]. Some phonologists would routinely transcribe these as [h], ]; according to such an analysis there are syllables that end in glides. 1.7.2 The velar nasal is again peculiar: in citation forms it cannot close a syllable if the preceding vowel is long. So we have wing, sang, bong alongside wind, sand, bond, but no *woung, *fieng *hing [ alongside wound, fiend, hind. Note the need to specify that *hing is to be read here as [, not [], whereas we have no difficulty in interpreting hind as [nd]. This shows that a V rhyme is quite foreign to English syllable structure. 49 The only exceptions are a few quasi-words such as boing []. (But in connected speech a velar nasal can close a syllable with a long vowel if it occurs through place assimilation: ] clean cup.) This restriction on the velar nasal again illustrates its historical derivation from [] or [n]. Analysed in that way, it can be seen as a particular case of a more general constraint on codas: a long vowel can only precede a coda cluster if all the consonants are coronal (pronounced with the tip or blade of the tongue). So toast is a possible English word, while *toask and *toasp are not. 1.7.3 The consonant sequences at the end of width , depth violate sonority sequencing, as do those in act, apt, albeit in a more minor way (in these latter cases there is no difference in sonority). In fact, coronal (which means, essentially, dental, alveolar and palatoalveolar) obstruents appear to occur unrestrictedly at the right edge of an English word. Sixths and texts apparently have four-consonant codas, in the latter of which a fricative stands outside a plosive twice over (i.e. in second and fourth position). Strict sonority sequencing evidently doesn’t apply to codas across the board. 1.7.4 One reason for this has to do with grammar: English morphology makes extensive use of inflection by suffixation, and the preferred suffixes tend to be coronal obstruents. An added final [z] (or its phonotactically induced variants [s] and [z]) forms plural nouns (dogs), genitive nouns (the dog’s bone) and 3sg present verbs (he dogs my footsteps); [d] or its corresponding variants [t] and [d] gives the past tense of weak ( = regular) verbs; [] forms ordinal numerals from cardinals (eight ~ eighth), etc. These morphological requirements override preferred syllable structure if necessary. So if e.g. you make a noun out of the ordinal or fractional numeral corresponding to six, and then pluralise it, you end up with the morphological structure six+th+s. This gives a virtually unpronounceable syllable coda,23 but the grammar doesn’t seem to care about that. Cf. the way that morphological suffixation overrides the rule that a nasal-obstruent cluster be homorganic. So tamp [mp], tent [nt], tank [k], but never *tanp, *tamk, etc. But this restriction doesn’t apply if the obstruent is a morphological marker (i.e. a separate morpheme): ring+s [], ring+ed [] (both velar nasal followed by alveolar obstruent). 1.8 Syllable boundaries 1.8.1 When a consonant might be either the coda of one syllable or the onset of the next, how do you tell which it is? If you have a sequence of two or more consonants, how do you tell which belong to the coda of one syllable and which belong to the onset of the next? There is not necessarily a definitive formula that holds for each and every case; syllable boundaries can vary from speaker to speaker, can depend on speed and style of speech, and can sometimes be permanently restructured over time. There is a complex interplay between phonetic facts about pronunciation that show what the syllable structure is, and grammatical facts that have an influence on pronunciation, and hence on syllable structure. In so far as the syllable is a unit we are consciously aware of, there is a simple empirical test you can try: take a phrase or polysyllabic word, pronounce it slowly and carefully, syllable by syllable, and see In fact sixth and sixths are very often reduced to [ and [. This makes the coda of sixths merely triconsonantal. 23 50 where you naturally put the boundaries. This may resolve some doubtful cases. At any rate, some general principles can be established. 1.8.2 The most general principle is that, other things being equal, CV is preferred to CVC, VC or V (§1.3.3). So so.li.da.ri.ty, not *sol.id.ar.it.y. In a case like this, the gives an important clue: we have already said (§1.2.2) that we can best state the distribution of in non-rhotic English in terms of its non-occurrence in codas. So that would argue for an analysis that treats as an onset. And the non-occurrence of in codas is in itself evidence that CV is preferred to VC. (The argument may sound circular, but what we are dealing with here is a set of structural principles that fit together holistically.) 1.8.3 When are other things not equal? When there is grammatical structure to be considered. The syllable in English tends to be subordinate to grammatical units. So, on the whole, English does not syllabify across word boundaries. (Contrast what happens in French, as illustrated in §1.2.6 ff.). Take the phrase not a word and pronounce it syllable by syllable. The chances are that your syllabification will be not.a.word, with the [t] of not as a coda rather than an onset. (The French for not a word is pas un mot , but here the syllable structure is clearly .., with the final consonant of pas the onset to un.) However, there are exceptions. The phrase at all is often pronounced , i.e. exactly as if it were a tall: the aspiration of the [t] shows that it is the onset of the stressed syllable. Historically, some words with initial [n] have been reanalysed with the [n] as belonging to the indefinite article. Adder, apron, umpire were once nadder (cf. Latin natrix), napron (cf. French naperon), noumpere (cf. Old French nomper): a nadder was reinterpreted as an adder, which can only have happened on the basis that the [n] could be either onset or coda. However, we would probably now put the first syllable boundary in an adder after the [n] rather than before it, in accordance with the (new) word structure. In English, grammatical structure tends to dominate syllable structure below the word level too: in so far as adder is treated as a single morpheme we are likely to syllabify it as a.dder, in accordance with the general preference for CV over VC; whereas if we interpreted it as add+er ‘someone or something that adds’, we might go for add.er. But we are now in a grey area: in cases like this the question is whether we can reliably distinguish our intuitions about syllables from our grasp of morphology. In cases like adder, where there may be real doubt as to whether a C is the coda of one syllable or the onset of the next, some phonologists would treat it as simultaneously both. But it is doubtful whether this is more than just a formal way of expressing the fact that the syllabification is equivocal or undecidable. 1.8.4 In contexts where in principle obstruent-resonant sequences might be split between the coda of one syllable and the onset of the next, they are usually tautosyllabic – i.e. they form a complex onset to the second syllable that accords with sonority sequencing. So re.cline, ac.tress, poul.try, en.twine, not *rec.line, *act.ress, *poult.ry, *ent.wine). The main evidence for this is that voiceless plosives in these clusters (i) project devoicing or spirantisation on to a following approximant, just as they do when unequivocally syllable-initial, and (ii) don’t undergo glottaling (but see remarks about petrol in §1.2.3 above – if you say [] that is good evidence that, for you, the syllabification is indeed poult.ry. Treating [t] as belonging to the coda in circumstances where it might equally well count as the onset or part of the onset of the next syllable, provided that syllable doesn’t take primary stress, is quite frequent in some accents. Note what happens to the second [t], but not the first, in []). 51 1.8.5 Aspiration of a voiceless plosive (or devoicing/spirantisation of a following approximant) is often a good guide to where the syllable boundary falls when you have the sequence [s] followed by another obstruent. Remember that a voiceless plosive is aspirated primarily when syllable-initial, and that a preceding tautosyllabic [s] suppresses aspiration. Compare mistime and mistake. These are usually pronounced and respectively – i.e. the former with aspiration of the [t], the latter without. This implies the syllabifications mis.time as opposed to mi.stake. Historically both words had the same morphological structure: mis+time and mis+take. But the syllabification mi.stake suggests that, unlike mistime, mistake has become morphologically opaque: i.e. speakers have lost sight of the notion that to mistake something is to mis-take it. 1.9 The international rogue segment in syllable structure 1.9.1 [s] is especially problematic in syllable structure. As far as English is concerned, [s] can in fact appear pretty much anywhere in a syllable, not even excluding the nucleus. You may be dubious about counting psssst! as an English word, but some people may pronounce a word such as spa as two syllables, with two definite peaks of sonority, one on the s, the other on the vowel, and with aspiration of the [p] as heavy as in pa, i.e. as expected when a voiceless plosive is syllable-initial: [.]. [s] can also form what appear to be triconsonantal onsets (stew, straight) and very complex codas (as in sixths, texts, mentioned above). All this without reference to sonority sequencing. Some phonologists treat [s], and not just in English, as a rogue segment that stands outside the structure of the syllable. 1.9.2 A number of Indo-European languages have vacillated between allowing and not allowing [s] to violate syllable structure rules. So e.g. Classical Latin allowed [s] to appear at the beginnings of syllable onsets, in violation of sonority sequencing, in words like sc(h)ola ‘school’. Spoken Latin (‘Vulgar’ Latin) and the early Romance languages couldn’t be doing with this, and required an epenthetic vowel that put the [s] and the following C in different syllables. So in Old Italian ‘school’ is iscuola. But Modern Italian has reverted to allowing [s] in the same syllable as a following obstruent: scuola. In Old French, the [s] also required epenthesis, as in escole, but later the [s] itself dropped out. So there are many etymologically related words in English and Modern French where French has a vowel [e] corresponding (apparently) to an English [s]: école ~ school, état ~ state, étrange ~ strange etc. Welsh has similarly chopped and changed in its treatment of [s]C: early loans like ystafell ‘room’, from Latin stabulum ‘stable’, show epenthesis, but modern loans do not, e.g. sbort ‘sport’, not *ysbort (y here = []). 1.10 Syllable weight 1.10.1 Syllable weight is an important concept in languages which have a length distinction among vowels, especially in relation to stress assignment (see below). A light syllable has a nucleus consisting of a lexically short vowel, and no coda. A heavy syllable has a lexically long vowel, or a coda, or both. Note that onsets have nothing to do with syllable weight; it is entirely a matter of rhyme-structure. 1.10.2 As far as English is concerned, two refinements to the statement in §1.10.1 are required: (1) A syllabic consonant, deriving historically or stylistically from the deletion of a schwa, is equivalent to a short vowel. (2) For purposes of assigning stress, in a polysyllabic word (three or more syllables) a single word-final consonant will not make that syllable heavy, provided the vowel is short. 52 1.10.3 Some illustrations: sy.lla.ble 3 syllables, LLL weight 1 syllable, H im.por.tant 3 syllables, HHH con.cept 2 syllables, HH lang.uag.es 3 syllables, HHL a 1 syllable, (see below) length 1 syllable, H dis.tinc.tion 3 syllables, HHL a.mong 2 syllables, LH vo(.)wels 1 syllable, H -- or 2 syllables, HH re.la.tion 3 syllables, LHL a.ssign.ment 3 syllables, LHH hea.vy 2 syllables, LH no.thing 2 syllables, LH ma.tter 2 syllables, LL The word important in this list shows how the historical loss of coda-r in non-rhotic accents has not (usually) changed the weight of the syllables in which it once occurred: except word-finally the vowel has undergone compensatory lengthening. Note that the final syllables of important and assignment are heavy, because they have CC codas, but the final syllables of the trisyllabic words languages, distinction, relation are light, even though they are closed, because they have short vowels and a single C coda. 1.10.4 An English monosyllable is always heavy. This means that in open monosyllables the vowel will always be lexically long, as in how, me, sea, you. The only apparent exceptions are the articles a and the, where the vowel is schwa. But note that in both cases the schwa derives by reduction from a lexically long vowel. Given the general rule about monosyllabic words, it makes sense to treat the articles as usually pronounced as having undergone proclisis: i.e. in a book, the book they are not phonologically full words, but have become attached (as clitics) to the following word, forming an initial unstressed syllable: [], []. 1.10.5 The reality of syllable weight: heavy syllables of different phonological structure constitute a class and often act as a class (i.e. as if they were equivalent). Study these forms from various Old English noun declensions:24 (a) neuter a-stem, nom. pl. A B + ‘vessels’ v+ ‘dwellings’ 24 ‘funeral pyres’ ‘women’ R. Lass, Phonology: An Introduction to Basic Concepts, Cambridge U.P., 1984, pp. 250 ff. 53 + ‘coals’ + ‘limbs’ ‘words’ ‘lands’ (b) neuter a-stem disyllables, nom. sg. vs gen. sg. A B / + ‘water’ / + ‘game’ / + ‘poison’ / + ‘star’ (c) feminine o-stem, nom. sg. A + + + + B ‘honour’ ‘bier’ ‘linden’ ‘shovel’ ‘disease’ ‘valley’ ‘tale’ ‘journey’ (d) masculine i-stem. nom. sg. A + + + + B ‘gleam’ ‘seagull’ ‘loss’ ‘giant’ ‘friend’ ‘weight’ ‘(rose) hip’ ‘pool’ (e) masculine u-stem, nom. sg. A + + + + B ‘son’ ‘prince’ ‘sea’ ‘custom’ 54 ‘spear’ ‘rank’ ‘field’ ‘ford’ Look first at the alternation of suffixed ‘A’ and unsuffixed ‘B’ forms in (a), (c), (d), (e). There is a phonological generalisation here. There is a suffix if the stem ends in –VC; there is no suffix if the stem ends in –VCC or VC. As for the (b) forms, if the first syllable of a disyllabic sonorant-final noun ends in –VC, then the next vowel does not undergo syncope in the genitive singular; if the first syllable ends in –VCC or -VC, there is syncope. These two processes are clearly related: VCC and VC somehow go together and act as if they were equivalent. They are both rhymes that make their syllable heavy. If the stem ends in VC, the addition of the vocalic suffix allows the C to be the onset of a second syllable, giving two light CV syllables. But the addition of the suffix to VCC or VC would leave a heavy first syllable. 2 Stress 2.1 Introduction 2.1.1 Stress is the phenomenon whereby certain syllables (or the nuclei of certain syllables) are more prominent than others. Stress in itself is an abstract notion, which may be realised in different ways in different languages: prominence may take the form of greater loudness, more length, higher pitch, etc., or some combination of these. Stress has to do with the rhythmic qualities of speech; its study comes under the heading of metrical phonology, where metrical ( < metre) means what it does in poetry. Note: in discussing stress we do not usually need to consider fine phonetic detail, so from here on I shall mostly cite examples in ordinary spelling, with syllableboundaries marked as usual with a full stop (as already in §1.10.3), and the nucleus of the main-stressed syllable in upper-case . 2.2 Stress-timing vs syllable-timing 2.2.1 There are important differences between languages as to the characteristic rhythm with which they are spoken. We can distinguish stress-timed languages from syllable-timed languages. 2.2.2 The Romance languages, e.g. French, Spanish, are syllable-timed. In a syllabletimed language there is a tendency for each syllable to occupy the same amount of time. A concomitant feature of rhythm in a syllable-timed language is that, on the whole, syllables tend to be equally stressed. In fact, in a syllable-timed language the last syllable of the phonological phrase will tend to be stressed and lengthened, but there is nothing that corresponds to the complex shifting of stress from syllable to syllable and concomitant changes in vowel quality that we find in morphologically related words in a stress-timed language like English. E.g. phO.to [], phO.to.graph […], pho.tO.gra.phy […]. It is a feature of syllable-timed languages that they tend to attach little significance to the word as a phonological unit. This can be seen from the French data in §1.2.7, where one of the processes involved amounts to maintaining preferred syllable structure at the expense of changing the phonological form of the individual word: a coda consonant will be lost unless there is a gap for it to become the onset of the 55 following syllable.25 This is what happens in non-rhotic English with respect to one particular segment (r); English would sound very different if it regularly happened across the board. (See §1.8.3 above.) 2.2.3 English is stress-timed. Its rhythm has to be understood with reference to a timing unit called the foot. In ordinarily rhythmic English speech, feet succeed each other at equal intervals of time. Each foot contains one stressed syllable, plus an indefinite number of unstressed syllables. It is easy to see from this that timing in English has nothing to do with the number of syllables. Consider phO.to, phO.to.graph, pho.tO.gra.phy again. These words have two, three and four syllables respectively, but each has two feet. Try chanting these three words to yourself over and over again. You naturally fall into a rhythm whereby each takes up about the same amount of time. The length of individual syllables expands and contracts to fit. Stress in English is primarily a matter of length: stressed vowels tend to be longer than unstressed ones. (But note that this does not mean that only lexically long vowels can be stressed.) Consider, in particular, what happens to the second o of phO.to.graph and the first o of pho.tO.gra.phy. They have no stress, and very little time in which to be pronounced. It takes time to get the tongue into peripheral positions in the vowel space. Hence the tendency for short, unstressed vowels to be reduced. In both these cases, in anything like normal speech the vowel will be schwa. 2.2.4 For English we can draw a distinction between main (or primary) stress, secondary stress, and complete lack of stress. The word phO.to has main stress on the first syllable and secondary stress on the second. phO.to.graph has main stress on the first syllable, no stress on the second, and secondary stress on the third. pho.tO.gra.phy has no stress on the first and third syllables, main stress on the second and secondary stress on the last. The vowels of unstressed syllables are reduced to schwa. Secondarily stressed syllables have less stress than the mainstressed syllable, but unreduced vowels. (Note: the test of whether a syllable is unstressed or secondarily stressed is not whether it actually has a reduced vowel in someone’s pronunciation on a particular occasion, but whether the vowel is capable of reduction, given an appropriate style and speed of utterance. The word photography, spoken slowly and clearly, may have all its vowels unreduced. But the first and third may be reduced, and hence are unstressed. As against that, the fourth can’t be reduced to schwa in any style of speech, and hence counts as secondarily stressed.) 2.2.5 The foot in linguistic metrics is somewhat analogous to the bar in music. Each bar takes the same amount of time to produce, even though different bars may contain different numbers of notes, and each bar is characterised by one main stressed note. 2.3 Word stress in English: an introduction 2.3.1 The rules for assigning stress to English words, considered in isolation, are complicated and full of exceptions. Also, there are many words which different speakers stress differently (watch out for examples in the discussion below). But one general point is that stress tends to be sensitive to grammar. So let us draw out in some detail just one broad pattern concerning words of two grammatical categories: nouns and verbs. The final outcome is complicated by what then happens to schwa, which is lost wherever the result is a possible syllable, whether open or closed. 25 56 Start with these: cOn.flict In.crease Im.plant Up.set prO.test sUr.vey Es.cort dI.gest fEr.ment cOn.tract con.flIct in.crEAse im.plAnt up.sEt pro.tEst sur.vEy es.cOrt di.gEst fer.mEnt con.trAct These are a small sample of a large class of English disyllables where stress shifts according to whether the word is a noun (on the left) or a verb (on the right). Let us take the point from these pairs that stress is nearer the end of the word if it is a verb, and nearer the beginning if it is a noun, and see how far we can generalise from it. 2.3.2 Some trisyllabic nouns: sU.btle.ty sO.li.tude bI.cy.cle O.ra.cle rE.gi.cide pA.ra.dox hIs.to.ry trAm.po.line sU.rro.gate sA.ccha.rine 2.3.3 Compare these with some trisyllabic verbs: de.vE.lop i.mA.gine a.stO.nish de.lI.ver ad.mO.nish de.tEr.mine im.pE.ril These sets fit in. In these trisyllabic words stress is nearer the beginning (on the first syllable) in nouns, nearer the end (on the second syllable) in verbs. 2.3.4 What happens if we have more than three syllables? First, nouns: a.cA.de.my 57 as.pA.ra.gus ki.lOme.tre cen.tEn.a.ry me.ta.mOr.pho.sis hi.ppo.pO.ta.mus pa.ra.llE.lo.gram mag.na.nI.mi.ty a.lu.mI.nium (There are a couple of very common variant pronunciations here: kI.lo.me.tre instead of ki.lOme.tre and me.ta.mor.phO.sis instead of me.ta.mOr.pho.sis. These will be discussed at §2.8.2 and §2.5.8 respectively.) 2.3.5 For verbs, let’s take the trisyllables already listed in §2.3.3 and add the prefix re-: re.de.vE.lop re.i.mA.gine re.a.stO.nish re.de.lI.ver re.ad.mO.nish re.de.tEr.mine re.im.pE.ril The general principle of stress later in the word for verbs still holds. The nouns have either four or five syllables; in each case stress falls on the third from the end. The verbs have four syllables; in each case stress falls on the second from the end. 2.3.6 However… Compare the following trisyllabic nouns with those in §2.3.2: a.gEn.da a.mAl.gam as.bEs.tos in.cI.sor re.trIE.ver sur.vI.val oc.tO.ber an.tArc.tic These have stress on the penult, just as if they were verbs. phonologically in some systematic way from the nouns in §2.3.4? Do they differ Yes, they do. Where nouns are concerned the crucial factor is the weight of the penultimate (last but one) syllable. In a noun of three or more syllables, if the penult is light, the antepenult (last but two) will receive stress. If the penult is heavy, it will attract stress to itself. Check against the definitions given in §1.10.1, §1.10.2 that in all the nouns of §2.3.2 the last but one syllable is light, and that in all the nouns of §2.3.6 the last but one syllable is heavy. 58 2.3.7 Where verbs are concerned the crucial factor is the weight of the ultimate (last) syllable. The verbs in §2.3.3 and §2.3.5 have light final syllables. (Remember that when it comes to assigning stress a single final consonant at the end of a polysyllabic word doesn’t make that syllable heavy, provided the vowel is lexically short.) When the final syllable of a verb is light, stress is on the penult. However, if the final syllable of a verb is heavy, that syllable will attract stress to itself: re.co.mmEnd di.sa.bUse su.per.sEde re.con.vEne re.in.vEnt o.ver.whElm 2.3.8 There is an important class of exceptions to the rule stated in §2.3.7: there are certain productive verb-forming suffixes in English which, although consisting of a heavy syllable, do not take the main stress if the verb that they form has three syllables or more. The chief ones are -ate, -ise and -ify: con.flAte re.lAte cO.llo.cate e.vA.po.rate e.mA.ci.ate cOm.pli.cate dE.mon.strate rE.a.lise I.te.mise sA.ni.tise rEcog.nise prI.va.tise vI.vi.fy sIm.pli.fy mAg.ni.fy tE.rri.fy hO.rri.fy Conflate and relate have final stress because they are disyllabic; the others fall outside the normal stress pattern for verbs. We shall return to these forms later. (§2.5.11). But from here on reference to ‘verbs’ excludes derived forms with these suffixes. 2.3.9 Return to the initial data of §2.3.1, repeated here for convenience. In nouns what matters is whether the penult is heavy. In these words it is, so it receives the stress. In verbs what matters is whether the final syllable is heavy. In these words it is, so it receives the stress. cOn.flict In.crease Im.plant Up.set prO.test sUr.vey Es.cort dI.gest fEr.ment cOn.tract con.flIct in.crEAse im.plAnt up.sEt pro.tEst sur.vEy es.cOrt di.gEst fer.mEnt con.trAct 2.4 The foot 59 2.4.1 So far, we have been talking simply about placing ‘the stress’ in a given word, meaning the main stress, as if stress were simply a binary matter of stressed or not stressed. We have been ignoring the issue of primary vs secondary stress, and the difference between secondarily stressed and unstressed syllables. Consider the words metamorphosis (with the pronunciation as given in the list of examples, i.e. stress on the third syllable) and parallelogram, cited at §2.3.4. In both these pentasyllabic words the second and fourth syllables are unstressed and may have their vowel reduced to schwa. But the vowel of the first syllable can’t be reduced: it takes secondary stress. How do we analyse this situation? 2.4.2 At this point we need to reintroduce the concept of the foot (look back at §2.2.3). The foot is a timing unit containing one stressed syllable. Linguistic feet have heads: the stressed syllable is the head of its foot. 2.4.3 In English poetry the most basic and characteristic foot structure consists of two syllables, unstressed (or secondarily stressed)26 followed by (main-)stressed. In literary metrics this foot is called a iamb(us). Five of them together form the classic line of English verse, the iambic pentameter: put OUt | the lIght, | and thEn | put OUt | the lIght (Shakespeare) the cUr | few tOlls | the knEll | of pArt | ing dAy (Gray) i dEAl | with fAr | mers, thIngs | like dIps | and fEEds (Larkin) But poetry is about combining words, and in fact the iambic foot of verse runs counter to the basic metrical structure of individual words, which is trochaic, i.e. stressed followed by unstressed, giving a left-headed foot. You can hear this trochaic rhythm in the word supercalifragilisticexpialidocious: if it were a line of verse it would be a trochaic heptameter. So there is a conflict between the characteristic rhythm of words and of lines of verse. You can see this conflict at work in the examples: all three words of more than one syllable (curfew, parting, farmers) have stress on the first syllable, which means, given the iambic rhythm of the lines, that the words concerned divide across foot-boundaries. That there should be this conflict is actually important for verse. 2.4.4 As far as the metrical structure of individual words is concerned, let us start with verbs. Here again are the verbs of §2.3.3: de.vE.lop i.mA.gine a.stO.nish Note that on the face of it this conflicts with the definition of the foot as a unit whose head is a stressed syllable, whether primarily or secondarily stressed. We can either say that in poetic metrics the term ‘foot’ is used slightly differently, in that only a main-stressed syllable can be the head of a foot, or, alternatively, that the distinction between secondarily stressed and unstressed is inoperative for purposes of establishing the fundamental rhythm of a line of verse, and hence ignored in the traditional analysis of metre in poetry. 26 60 de.lI.ver ad.mO.nish de.tEr.mine im.pE.ril These are trisyllabic, with stress on the middle syllable. They can be analysed as having a left-headed foot built at the right edge of the word, preceded by an unstressed syllable: de | vE.lop i | mA.gine a | stO.nish de | lI.ver ad | mO.nish de | tEr.mine im | pE.ril (The initial unstressed syllable here might be seen as analogous to starting a piece of music on the last beat of the bar). 2.4.5 But why is this a left-headed foot built at the right edge of the word, preceded by an unstressed syllable, as opposed to a right-headed foot built at the left edge of the word, followed by an unstressed syllable? Why, in fact, this talk of feet at all? Well, consider what happens if we add the prefix re-, as in the examples first given at §2.3.5: re.de.vE.lop re.i.mA.gine re.a.stO.nish re.de.lI.ver re.ad.mO.nish re.de.tEr.mine re.im.pE.ril Compare the pronunciation of re- here with re- in refine, restore, retrieve. In these latter words the vowel is (or may be) schwa (or ]). But not in redevelop, etc. Here the vowel of re- can’t be reduced: the pronunciation is ]. These words contain two left-headed feet, the head in each case being stressed, with primary stress on the head of the foot on the right, and secondary stress (marked here with the standard IPA symbol) on the head of the other: re.de | vE.lop re.i | mA.gine re.a | stO.nish re.de | lI.ver re.ad | mO.nish re.de | tEr.mine re.im | pE.ril 61 An analysis in terms of right-headed feet wouldn’t work. And an analysis that built left-headed feet from left to right wouldn’t work for the unprefixed verbs of §2.4.4. 2.4.6 The basic rule for assigning foot structure to English words (and the only rule that accommodates the verbs of both §2.4.4 and §2.4.5) is: build left-headed feet iteratively from right to left through the word, and assign main stress to the head of the rightmost. That is in effect what we have done to get the correct metrical analysis of the verbs considered so far. 2.4.7 But … this doesn’t seem to work for the verbs in §2.3.7, repeated here: re.co.mmEnd di.sa.bUse su.per.sEde re.con.vEne re.in.vEnt o.ver.whElm According to the rule, these ought to be like the verbs of §2.4.4, with stress on the middle syllable. Why aren’t they? As we saw earlier, the crucial difference between these and the verbs of §2.4.4 is that their final syllable is heavy, and a heavy final syllable attracts main stress in verbs. And this rule has priority over the general rule for foot-building. That is to say, a heavy final syllable in a verb has to be the head of its foot. And because feet in English words are left-headed, the foot of which this syllable is the head will necessarily be incomplete (cf. an incomplete bar at the end of a piece of music). Having established this, you then apply the rule, working back through the word building left-headed feet: re.co | mmEnd di.sa | bUse su.per | sEde re.con | vEne re.in | vEnt o.ver | whElm 2.5 Extrametricality in nouns 2.5.1 So far we have said nothing about the foot structure of nouns. Recall that the crucial point about nouns seemed to be that main stress tends to occur on an earlier syllable in the word than in verbs. Can this difference be accommodated in a unitary account of foot structure that works for both nouns and verbs? Yes, it can. To start with, we can be more precise about the difference between nouns and verbs: in every class of case the crucial factor occurs precisely one syllable earlier in nouns than in verbs. In a disyllabic noun which has a corresponding disyllabic verb (§2.3.1) the stress falls on the first syllable in the noun, on the second in the verb. In a noun of three or more syllables, if the penult is light, the antepenult will be stressed (§2.3.2), whereas in a verb of three or more syllables, if the final syllable is light, the penult will be stressed (§2.3.3, §2.4.4, §2.4.5). In a noun, a heavy penult will attract stress to itself (§2.3.6), whereas in a verb a heavy final syllable will attract stress to itself (§2.3.7, §2.4.7). 62 2.5.2 In nouns, it seems, the final syllable doesn’t count. That is to say, we can arrive at an analysis that deals with nouns and verbs under the same set of rules if we treat the final syllable of a noun as extrametrical, i.e. as lying outside the metrical structure of the word. Let us look again at each of the sets of nouns we have considered, and see if, making use of the idea of extrametricality, we can apply to them the foot-building rules developed for verbs. (The extrametrical syllable is shown in parentheses.) 2.5.3 (cf.§2.3.1, §2.3.9) cOn(flict) In(crease) Im(plant) Up(set) prO(test) sUr(vey) Es(cort) dI(gest) fEr(ment) cOn(tract) As far as stress assignment is concerned, extrametricality in effect reduces disyllables to monosyllables. Which makes it hardly surprising that stress should fall on the one remaining syllable that counts. 2.5.4 (cf. §2.3.2): sU.btle(ty) sO.li(tude) bI.cy(cle) O.ra(cle) rE.gi(cide) pA.ra(dox) hIs.to(ry) trAm.po(line) sU.rro(gate) sA.ccha(rine) Ignoring the last, parenthesised syllable, apply the rules as given in §2.4.6, §2.4.7 for verbs. Is the final syllable (of those remaining to be considered) heavy? No. Then iteratively build left-headed feet starting as far to the right as possible, carrying on till you reach the left edge of the word. The head of the rightmost foot will carry main stress, the head of any foot to the left of the rightmost will carry secondary stress. In the case of these trisyllabic nouns there is only one foot. 2.5.5 (cf. §2.3.4): a.cA.de(my) as.pA.ra(gus) ki.lO.me(tre) cen.tE.na(ry) 63 Ignoring the last, parenthesised syllable, apply the rules. Is the final syllable (of those remaining to be considered) heavy? No. Then iteratively build left-headed feet starting as far to the right as possible, carrying on till you reach the left edge of the word. The head of the rightmost foot will carry main stress, the head of any foot to the left of the rightmost will carry secondary stress. In the case of these tetrasyllabic nouns there is only one complete foot, preceded by an unstressed vowel, reduced or reducible to schwa. 2.5.6 (cf. §2.3.4): me.ta.mOr.pho(sis) hi.ppo.pO.ta(mus) pa.ra.llE.lo(gram) mag.na.nI.mi(ty) a.lu.mI.ni(um) Ignoring the last, parenthesised syllable, apply the rules. Is the final syllable (of those remaining to be considered) heavy? No. Then iteratively build left-headed feet starting as far to the right as possible, carrying on till you reach the left edge of the word. The head of the rightmost foot will carry main stress, the head of any foot to the left of the rightmost will carry secondary stress. In the case of these pentasyllabic words there are two complete feet, the head of the leftmost carrying secondary stress, with a vowel unreducible to schwa. 2.5.7 Note that the word aluminium, although usually pronounced as four syllables, with the third as given in §2.5.6 consonantalised to a glide ([j]), counts as having five for purposes of stress assignment. The glide-formation here is a late and superficial process, the metrical structure being determined by an underlying pentasyllabic citation-form. Contrast the American form aluminum, which only ever has four syllables, and is stressed according to the pattern of academy, etc., with the first vowel reduced. 2.5.8 We are now in a position to say something about the alternation between me.ta.mOr.pho.sis and me.ta.mor.phO.sis, mentioned at §2.3.4. Both pronunciations accord with the rules. In me.ta.mOr.pho.sis the penult is light, so stress falls on the antepenult. In me.ta.mor.phO.sis the penult is heavy, so stress falls on that syllable. The stress shift goes hand in hand with the appropriate adjustment in vowel length (and quality). You might raise a chicken-and-egg question here: is it the vowel length that determines stress assignment, or the stress assignment that determines vowel length? Perhaps there is no good answer to that question. Perhaps we just have to say that the required vowel length goes together with the required stress placement. 2.5.9 (cf. §2.3.6): a.gEn(da) a.mAl(gam) as.bEs(tos) in.cI(sor) re.trIE(ver) sur.vI(val) oc.tO(ber) an.tArc(tic) 64 Ignoring the last, parenthesised syllable, apply the rules. Is the final syllable (of those remaining to be considered) heavy? Yes. Then apply main stress to it as the head of a left-headed foot. This leaves a preceding unstressed syllable. 2.5.10 Stress assignment to nouns is subject to the same rules and principles as to verbs. The difference is that in nouns the final syllable is extrametrical. 2.5.11 We can now reconsider the exceptional suffixed verbs mentioned at §2.3.8. What is exceptional about them is that they have the stress pattern of nouns. I.e. the final syllable (the suffix) is extrametrical. (Check that these verbs do in fact obey the rules as set out for nouns.) This may have something to do with the fact that the suffixes in question are fully productive and extremely common, and it would be pragmatically odd to stress the part of the word that carries least information. 2.6 Extrametricality: one complication 2.6.1 In my accent at least, extrametricality appears not to apply in nouns like the following, which are stressed on the final syllable: an.tIque chim.pan.zEE co.cka.tOO en.gin.EEr smi.the.rEEns bri.ga.dIEr kan.ga.rOO ma.ca.rOOn mar.ga.rIne ma.ga.zIne mi.lli.o.nAIre re.fe.rEE (This seems to be the inverse of the situation with suffixed verbs, which behave stresswise as if they were nouns: these are nouns that think they are verbs.) 2.6.2 Is there a generalisation to be made here? Well, in each case the final syllable, whether open or closed, has a long vowel. So can we insert an additional clause into the rules for stress assignment to the effect that extrametricality is blocked if the final syllable of a noun has a long vowel? It doesn’t look like it. First, the following nouns from the data already considered have long final vowels, but undergo extrametricality just the same: In(crease) Im(plant) sUr(vey) Es(cort) sO.li(tude) rE.gi(cide) a.cA.de(my) 65 trAm.po(line) (Note that in absolute terms the extrametrical ‘long’ vowel here is not necessarily very long. That accords with the fact that unstressed vowels tend to be shorter than stressed vowels, irrespective of the lexical length of the vowel concerned. But these vowels are nonetheless lexically long.) 2.6.3 Secondly, there seems to be a general rule that if the long vowel in the final syllable is [], extrametricality applies as usual, and stress falls on the penult or antepenult, according to the usual principles: bU.ffa.lo mos.quI.to to.mA.to wIn.dow po.tA.to mEA.dow cA.li.co co.mmAn.do (As far as these []-final words are concerned, there is a tendency in at least some of them to reduce the final vowel to schwa (pronunciations like [], etc. – see §1.2.3, §1.6.4), in which case the final vowel would be short anyway. But in my accent at least these schwa-final pronunciations cannot be treated as the citation forms.) 2.6.4 In this context it is interesting to consider the word research. In my speech this has final stress whether it is a noun or a verb. Others make the usual §2.3.1 distinction between disyllabic nouns and verbs: rE.search (noun) and re.sEArch (verb). For such speakers the second syllable of the noun is extrametrical in the normal way. For me the noun does not undergo extrametricality, in accordance with the subpattern whereby final long vowels in nouns are (often) metrical. 2.6.5 The exceptions, and the exceptions to exceptions, to extrametricality discussed above are just the tip of an iceberg of complications (and we haven’t even touched on any words other than nouns and verbs!). The two main reasons stress assignment to English words is complex are (i) that there are many different accents of English, sometimes with very different metrical rules, which are liable to interfere with one another; (ii) English is very prone to borrow words from other languages, which may be wholly, partially or not at all assimilated to native stress patterns, or at different stages along the road to assimilation in the speech of different speakers. 2.7 Stress above word-level: compounds and phrases 2.7.1 The stress pattern of a word considered in isolation may find itself subordinated to the stress pattern of a larger unit of which it forms part. For instance, apple by itself has main stress on the first syllable. But the two-word unit apple pie forms a metrical unit with main stress on the final syllable, reducing the stress on the first syllable of apple to secondary. 66 2.7.2 Two-word units in English have characteristically different stress patterns according to whether they are compounds or phrases: grEEnhouse blAckbird grEAtcoat green hOUse black bIrd great cOAt On the left we have compound nouns, i.e. a single noun formed out of more than one (in these cases two) morphological elements. On the right we have phrases consisting of an adjective followed by a noun. The meanings are very different: a blackbird is a particular species of bird (which may not always be black): a black bird is a bird of any species that happens to be black. 2.7.3 The same stress alternation can be seen in these examples. On the left we again have a compound nouns, on the right a phrase (this time a verb or gerund followed by its object): mIncemeat plAying cards mince mEAt playing cArds In the following example the phrase on the right is ambiguous: the -ing form may be either adjectival (‘apples that are cooking’, as in cooking apples rarely need to be watched closely) or gerundal (as in cooking apples is a pain in the neck). That makes the sequence of words cooking apples, as written, at least three-ways ambiguous. But the stress pattern remains constant: if it’s a compound it’s stressed on the first syllable, if it’s a phrase (whatever its grammatical/semantic interpretation) the main stress falls on a syllable further to the right: cOOking apples cooking Apples Notice that the pattern is at least broadly reminiscent of that for single nouns and verbs: compound nouns are like nouns in having stress on an early syllable; phrases are like verbs in having stress on a later syllable. In fact, metrically, it is as if phrases were treated as ‘compound verbs’, whether or not they actually contain a verb. 2.7.4 How do you pronounce ice-cream? Some people say ice crEAm, others Ice cream. In the former case you are treating it as a phrase – ice is ‘adjectival’, as is pea in pea soup (pea sOUp). In the latter case you are treating it as a compound noun, i.e. both the cream and the ice components are individually nouns, as is bean in bean sprout (bEAn sprout). 2.7.5 Notice that spelling is not a reliable guide to whether a two-word unit is a compound or a phrase. Two-word phrases are indeed written as two words (can you think of any exceptions? See the discussion of Mississippi in §2.9.1 below). But compounds may be written as two words, with or without a hyphen, or as one word. I.e. you can write ice cream, ice-cream or icecream, but you can’t tell from how you write it whether for you it’s a compound or a phrase. What matters is how you stress it. 2.7.6 Compare two of the phrases in §2.7.3 with unitary verbs of similar metrical structure: 67 play.ing | cArds cook.ing | App.les su.per | sEde re.de | vE.lop The same stess-assignment rules apply. Because these are verbs (or ‘verbs’) there is no extrametrical syllable; stress falls on the last syllable if that is heavy, on the penult if the last syllable is light. Note that it makes no difference that cards and apples, in themselves, are nouns: what matters is that in this context they form part of a phrase that is metrically equivalent to a polysyllabic verb. 2.7.7 However, if we now take the phrases green house, black bird, mince meat, it is harder to find exact parallels among simple verbs. The nearest parallels are disyllabic verbs with unstressed first syllable and (main-)stressed second syllable: green hOUse black bIrd mince mEAt pro.tEst com.plAIn su.pplAnt These aren’t exact parallels because in the phrases the first syllable is not unstressed, but secondarily stressed – the vowels can’t be reduced to schwa. 2.7.8 To analyse what is going on here we have to consider how the phrase is built up of words. The phrase green house consists of two monosyllabic words, each of which, by itself, can take main stress: grEEn and hOUse. In coming to form part of the phrase, grEEn subordinates itself to its context by losing its main stress, in accordance with the pattern for phrases, but doesn’t become completely unstressed. 2.7.9 Something similar applies to compound nouns. Blackbird is made up of blAck and bIrd. In coming to form part of the compound, bIrd subordinates itself to its context by losing its main stress. If you like, that the final syllable should do this is a sort of faint echo of extrametricality. But it is not extrametricality. It is not even complete loss of stress. In the second element of these compounds the syllable that would receive main stress if the word was by itself receives secondary stress: grEEn.house) blAck.bird mInce.meat plAy.ing.cards cOOk.ing.a.pples wAsh.ing.pow.der whI.stle.blow.er 2.8 Single words as phonological compounds 2.8.1 We sometimes find that what from a lexical or grammatical point of view seem clearly to be unitary nouns behave phonologically as if they were compounds. Take the word controversy. There is a controversy over how to stress it. Do you say con.trO.ver.sy or cOn.tro.ver.sy? If you have the former pronunciation you are treating it as a regular tetrasyllabic noun with a light penult (§2.5.5). If you have the latter, you are giving it the stress pattern of cOOk.ing.a.pples, i.e. of a compound. 68 2.8.2 This is what is happening if you prefer kI.lo.me.tre to ki.lO.me.tre (cf. §2.3.4 above) – an interesting case because this choice has become something of a shibboleth in those parts of the English-speaking world where the ‘metric’ (which just means ‘measuring’) system of weights and measures is in operation. Many people vociferously insist on the correctness of the former and the abominable sloppiness of the latter. In fact the latter merely shows that for some speakers kilometre has assimilated itself to the normal pattern for nouns with this syllable structure. The reason that for many others kilometre is treated (like most other terms in the metric system) as a compound has to do with the structure of these words and their artificial imposition en bloc as a whole lexical subsystem. They consist of a term (metre, gram, joule etc.) designating the basic unit in question, preceded by a Greek or Latin element expressing a multiple (Greek) or fraction (Latin) of that unit. Many of the words that can be created in this way are quite unfamilar to most speakers (how often do you hear or use words like decajoule or centiwatt?); their interpretability and thus the viability of the system depends on maintaining the structural transparency of the rarer ones, so that their form and meaning can be worked out from how they are built up according to the rules of the system. Kilometre, however, is on everyone’s lips all the time, and has (for progressive speakers at least) escaped the confines of the metric lexical subsystem to become a regular English word. If a significant number of speakers had as regular an everyday use for the word centimetre as we do for kilometre, no doubt it would tend to become cen.tIme.tre. 2.9 Single words as phonological phrases 2.9.1 Consider the stress pattern of certain American topographical names, such as Mississippi, Susquehannah, Chappaquiddick, etc. These are tetrasyllabic nouns with a light penult: you would expect *mi.ssI.ssi.ppi, etc. But what you actually get is mi.ssi.ssI.ppi. This is the stress pattern of phrases, like cook.ing. Apples, gra.cious. lAdy. What’s happening here? Morphologically, these words are quite opaque to English-speakers. No doubt for speakers of the indigenous American languages from which they have been borrowed or adapted they are as structurally transparent as Riviersonderend or Pietermaritzburg are for (some of) us. But for English-speakers they present the problem of having a lot of syllables but no interpretable internal structure: there is nothing to guide the choice between treating them phonologically as simple words or as combinations of words. Dealing with them as if they were phrases (Missy Sippy, etc.) makes as much sense as any alternative. 2.10 Stress clash and stress retraction 2.10.1 The compounds and phrases considered above form units with one main stressed syllable. But the stress pattern of words may be modified in accordance with the metrical environment when combined with other words in units that retain more than one main stress. (a) bri.ga.dIEr kan.ga.rOO brI.ga.dier | gE.ne.ral kAn.ga.roo | cOUrt 69 (b) re.fe.rEE ja.pa.nEse rE.fe.ree’s | whI.stle jA.pa.nese | mAr.kets mi.ssi.ssI.pi rec.ti.lI.near south. a.mE.ri.can mIssi.ssi.ppi | rI.ver.boat rEc.ti.li.near | fI.gures sOUth. a.me.ri.can | mU.sic The words on the left in (a), mostly quoted from §2.6.1, have final stress. The additional words on the right have initial stress. Putting them together gives rise to a stress clash. As also happens in (b). In many syntactic circumstances, English does not tolerate (a) adjacent or (b) near-adjacent main stresses in words that go together to form a phonological unit, and deals with the situation by retracting (moving to an earlier syllable) the first of the two clashing stresses. What are the syntactic circumstances in question? Look at some more examples from §2.6.1: an.tIque chim.pan.zEE co.cka.tOO an.tIque | dEA.ler chim.pan.zEE | trAI.ner co.cka.tOO | brEE.der Why no stress retraction here? There’s a clue in the first example. Remember that antique is also an adjective, and constrast the following pair: an.tIque An.tique | chAIr Here you do get stress retraction as a response to the clash. In these phrases, retraction depends on whether the first element is an adjective, or stands in an ‘adjectival’ relationship to the second. Just as an antique chair is a kind of chair, so a brigadier general is a kind of general, a referee’s whistle a kind of whistle, and so on. But an antique dealer is not a dealer who is antiquated, nor is a cockatoo breeder a breeder who is, or who has the qualities or properties of, a cockatoo. This illustrates once again the point that stress is sensitive to grammar. 2.11 Relexification induced by stress retraction 2.11.1 London’s major international airport is built on the site of a now obliterated rural village known within living memory as Heath Row – two words, stressed as a phrase: heath. rOw, like meat. pIE. Today many people call the airport hEAth.row – a compound, like grEEn.house. Why? As the name of the airport it was from the outset treated orthographically as one word: Heathrow. But that in itself made no difference to its stress pattern: remember that how a two-word unit is written bears no consistent relation to whether it is phonologically a phrase or a compound. What made the difference was stress retraction in the context of one particular larger phrase: heath. rOw hEAth.row | AIr.port The point is that Heathrow Airport is a very frequent combination of words, perhaps as frequent as Heathrow by itself. Hearing it so often in this context, with initial stress, some speakers have relexified it as a compound. 70