Latent Linguistic Codes for Morphemes Using ICA
advertisement

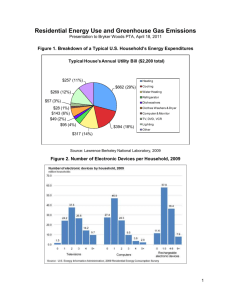
Latent linguistic codes for morphemes using ICA Krista Lagus, Mathias Creutz, Sami Virpioja, and Teemu Varis Neural Networks Research Centre, Helsinki University of Technology (Krista.lagus@hut.fi) In recent years it has been common to analyse word meaning by looking at word contexts. However, in highly inflecting languages such as Finnish many cognitively interesting phenomena may take place within words. For example, semantic roles (Agent, Patient, Recipient, etc) are partly marked using appropriate inflected forms (Juha suuteli Mari-a vs. Juha-a suuteli Mari), not strictly using word ordering as in English (John kissed Mary vs. Mary kissed John). We take morphemes as basic units of meaning, and examine their realizations, morphs (word segments) [1] using contextual analysis. We apply an unsupervised learning method called Independent Component Analysis (ICA) [2] to discover latent dimensional representations for the morphs. ICA differs from PCA in that the latent dimensions found are generally more interesting or meaningful. ICA differs from a clustering algorithm in that each morph is “clustered” to many components, forming a distributed representation. In a related work, ICA was applied to analysis of English words based on their averaged contexts [3]. We analysed the 2254 most frequent morphs from 1,3 million Finnish word forms (types), occurred in a corpus of 30 million words (tokens). The features were 292 common morphs, and as the context the immediately succeeding morph position. ICA was then applied to find the independent components. Finally, for each component we listed the data vectors where that component was most active, and examined these lists. What kind of phenomena do the discovered components then come to represent? Ideally each component might code for a single cognitive, syntactic, semantic or phonological property. A preliminary analysis of the first 20 components suggests that 10 components seem particular to verbs, 6 to nominals, and 4 for some combination. One component marks plural stems, one codes suffixes; three components mark for agent, three others for location. Vowel harmony was evident in several components. The Figure depicts the ICA components for the morph “osallistu” (“participate”). Component 6 appears to code nominal forms of action (“participation”) and component 8 marks agent role (“participant”). Both are particularly active for this morph (seen from the large difference w.r.t. the average values). We conclude that the phenomena encoded in the morphological structure are not in the least exhausted by this study, and that the ICA algorithm seems fruitful for the purpose. Moreover, we argue that the analysis of word internal processes may be a rich source of cognitive and semantic information as well, and amenable to automatic data analysis methods. References [1] M. Creutz and K. Lagus. Unsupervised discovery of morphemes. In Proc. Workshop on Morphol. and Phonol. Learning, ACL-02, pp. 21-30, Philadelphia, PA, 2003. [2] A. Hyvärinen. Fast and Robust Fixed-Point Algorithms for Independent Component Analysis. IEEE Transactions on Neural Networks 10(3):626-634, 1999. [3] Timo Honkela, Aapo Hyvärinen, and Jaakko Väyrynen. Emergence of Linguistic Representations by Independent Component Analysis. Helsinki University of Technology, Publications in Computer and Information Science, Report A72, 2003.