Advanced Data Analysis & Big Data for Business Intelligence

Government of Russian Federation
Federal State Autonomous Educational Institution of Higher Professional
Education
"National Research University
'Higher school of economics'
Faculty of Business Informatics
Discipline program
"Advanced methods of data analysis and big data in business intelligence " for direction 38.04.05 "Business Informatics", Master training
Program’s author:
Nikolay V. Markov, nikolay.markoff@gmail.com
Approved at the meeting of the Department of information and business in the sphere of information technologies «____»____________ 2014 г.
Head of Department, Svetlana V. Maltseva _____________________
Recommended by the EMS section of «Business Informatics» «____»____________ 2014 г.
Chairman, Y. V. Taratukhina ____________________
Moscow, 2014
This program can not be used by other parts of the university and other institutions of higher education without the permission of the department - developer of the program.
1.
Scope and normative references
This program of an academic discipline establishes minimum requirements for knowledge and skills of the student and determines the content and types of studies and reports.
The program is designed for teachers, leading this discipline, teaching assistants and students directions 38.04.05 "Business Informatics" Master training, students in the master's program "Big Data
Systems".
The program is developed in accordance with:
working curriculum of the University towards 080500.68 "Business Informatics" Master training for master's program «Big Data Systems», approved in 2014
2.
Goals for studying
Formation of the theoretical knowledge and practical skills in the collection, storage, processing and analysis of large data.
Develop skills and practical skills to analyze large data to tackle a wide range of applications, including analysis of corporate data, financial data from the data warehousing world markets, modeling data storage and processing, prediction of complex indicators.
3.
Student competences, generated as a result of studying
As a result, during the studying of the discipline a student should::
Understand the theory and fundamentals of storage, processing and analysis of big data, advanced tools for collection, storage, transmission and visualization of big data.
To be able to process and analyze large amounts of data using modern software packages IBM
InfoSphere.
Have the skills to use neural networks and fuzzy models for compression, processing and analysis of large data, as well as their continuing effectiveness.
As a result of the development of the discipline the student acquires the following competences:
Competence
GEF/NR
U code
СК-2
Descriptors - the main features of the development (indicators of achievement results)
Demonstrates
Forms and methods of teaching, contributing to the formation and development of competence
Lectures, workshops, homework
Ability to offer concepts, models, invent and test methods and tools of professional activity
The ability to apply the methods of system analysis and modeling to evaluate and design
Ability to develop and apply mathematical models to justify the design decisions in the field of ICT
Ability to organize self and collective research work at the enterprise and manage it
ПК-13
ПК-14
ПК-16
Owns and uses
Owns and uses
Owns and uses
Lectures, workshops, homework
Lectures, workshops, homework
Lectures, workshops, homework
2
4.
Place in the structure of the discipline of the educational program
As part of the master's program «Big Data Systems» this discipline is a compulsory subject.
For the proper development, students should:
know the content of the following disciplines: numerical methods, optimization methods, data analysis, discrete mathematics, theoretical foundations of computer science, computer systems, networks, telecommunications, information systems management and production company.
Be able to use mathematical and IT-tools for management tasks.
The main provisions of the discipline should be used for the further studying the discipline
"Elaboration and implementation of big data."
5.
Topical plan of an academic discipline
№ Topic name
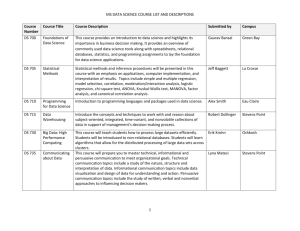
1 Introduction to the analysis and management of large data
2 Data Management
3 Model of distributed file systems and databases computing
4 Search for similarities in the data
5 Analysis of streaming data
6 Link analysis
7 Frequent datasets analysis
8 Clustering algorithms and their applications
9 Neural networks and their applications
10 Advertising on the Web
11 Decision support system
12 Analysis of social network graphs
13 Reducing the dimension of data
14 Large scale machine learning
ИТОГО
Total hours
180
Classroom hours
Lecture s
Semin ars
Workshop s
Homewo rk
2
2
2
2
7
7
38
4
2
2
2
4
4
4
2
2
4
2
2
38
4
2
2
2
4
4
4
2
2
4
2
2
106
8
8
8
8
7
8
8
8
7
8
7
7
6.
Forms of students knowledge control
Type of control
Current
(week)
Form of control
Thesis
1
1 st
year
2
1
Parameters
Volume 25-20 pp., result evaluation – 2 weeks
Total
(week)
Exam 1 Oral exam, 20 min per student
6.1 Criteria for assessing the knowledge, skills
The student should demonstrate the knowledge of sections of the discipline and the ability to present the results of homework and tests in accordance with the required competencies.
Evaluation of all forms of monitoring are set on a 10-point scale.
3
On the final evaluation on a subject matter consists of ratings for:
work in practical classes - O1
control work - O2
response to the competition - O3 according to the formula: O = O1 + 0.2 * 0.4 * O2 + O3 0.4 *
7.
Program content
Topic 1. Introduction to the analysis and management of big data time.
What is big data? Characteristics of Big Data. Big data as one of the global challenges of our
Data analysis, basic principles and methods. Statistical modeling and simulation based on machine learning. Bonferroni principle. Hash functions and indexes. Base of natural algorithms.
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
1.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
Topic 2. Data Management
Data management foundation. Stages of working with data collection, compression, storage, processing, analysis. Principles of storage and data management. Data compression methods.
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
4.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
Topic 3. Model of distributed file systems and databases computing
4
Distributed file systems. Physical organization of computing nodes. Approach MapReduce: Maptask, Reduce-task. Algorithms using MapReduce and their applications. Matrix-vector multiplication, the operation of relational algebra operations on databases, grouping and aggregation.
Extensions to MapReduce. Flow systems. Communication cost models. The theory of complexity for MapReduce: dimension reduction and graph models.
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
4.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
Topic 4. Search for similarities in the data
Application of the Near-Neighbor search. Jaccard similarity in the data. Similarity in information. Collaborative filtering.
Splitting documents. k-splitting: the choice of dimension splitting hashing, splitting construction of words.
LSH - hashing. Measures of distances. Euclidean distance, the distance Jaccard, cosine distance. LS - function. LSH - family and their applications.
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
4.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
Topic 5. Analysis of streaming data.
5
Threading model of data. Management system of streaming data. Discretization of flow data.
Filter streams. Flageolet-Martin algorithm. Alon-Matias-Zhegedi algorithm. Datar-Gionisa-Indica-
Motwani algorithm (DGIM).
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
4.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
Topic 6. Link analysis.
PageRank algorithm. Earlier search engine, network structure. Transition matrix. Iterations of
PageRank using MapReduce.
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
4.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
Topic 7. Frequent datasets analysis
Determination and application of frequent datasets. Model of a market basket. Association rules. A-Priori algorithm. Monotony of data. Storing big data in memory. Park Chan-Yu algorithm.
Multi-level algorithm. Multihash algorithm. Algorithms for restricted access. Savasere-Omichinski-
Nebat algorithm. Toivonen algorithm. Counting the frequent datasets: sampling, hybrid methods.
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
6
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
4.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
Topic 8. Clustering algorithms and their applications
Introduction clustering algorithms: a point space distance. Clustering strategy. Hierarchical clustering in Euclidean and non-Euclidean spaces, its effectiveness. K-means algorithm. Bradley-
Fayyad Reina (BFR) algorithm. CURE algorithm. Cluster tree. GRGPF algorithm. Application of clustering algorithms in in-line and parallel computing.
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
4.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
Topic 9. Neural networks and their applications
Determining the structure and typology of neural networks. Kohonen maps. Neural network inverse distribution. Application of neural networks in economics, logistics, IT-sphere.
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
4.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
5.
Heaton C. Introduction to the Math of Neural Networks. Heaton Research, 2010.
7
Topic 10. Advertising on the Web
Algorithms for online and offline. Greedy algorithm. Competitive ratio. The problem of coincidences. Algorithm balance and the balance of the generalized algorithm.
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
4.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
Topic 11. Decision support system
Model of decision support system. Utility matrix. Making decisions based on the contents of the data. Identification of the properties and parameters of the data. Collaborative filtering. Measurement identity. Reduced dimension. UV - decomposition. Standard deviation.
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
4.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
Topic 12. Analysis of social network graphs
What is a social network? Social networks as graphs. Types of social networks. Clustering of social network graphs, distance in graphs. Girvan-Newman algorithm. Bipartite graphs and subgraphs.
Maximum likelihood algorithm.
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
8
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
4.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
8.
Literature
Basic literature
1.
Minelli M., Chambers M., Dhiraj A. Big Data, Big Analytics: Emerging Business
Intelligence and Analytic Trends for Today's Businesses. John Wiley & Sons, 2012
2.
Ye N. The Handbook of Data Mining. Lawrence Erlbaum Associates, 2003
3.
Leskovec J., Rajaraman A., Jeffrey D. Ullman. Mining of Massive Datasets. Stanford
University, 2010
Additional literature
4.
Eaton C., Deutsch T., Deroos D., Lapis G., Zikopoulos P. Understanding Big Data.
Analytics for Enterprise Class Hadoop and Streaming Data
5.
Heaton C. Introduction to the Math of Neural Networks. Heaton Research, 2010.
9.
Knowledge control questions
1.
Big data. The problem of big data today.
2.
Data Management. Methods of data collection and data preparation. Principles of storage and data management.
3. Modeli distributed file systems. File system Google and Hadoop.
4. MapReduce. Paradigm, the essence of the structure.
5. Search of similarities. Similarity Jaccard. Splitting. LSH - hashing.
6. Stream data model. Flageolet Martin algorithm. The algorithm of Alon-Matias-Zhegedi.
Algorithm Datar-Gionis-Indic-Motwani (DGIM).
7. Link analysis. Page Rank.
8. Determination and application of frequent sets. Model of a market basket. Association rules. A-Priori algorithm.
9. Determination and application of frequent sets. Monotony of data. Storing large data in memory. Algorithm Park Chan-Yu. Multi-level algorithm.
9
10. Determination and application of frequent sets. Multi-level algorithm. Multihash algorithm. Algorithms for restricted access. Savasere-Omichinski-Nebat Algorithm.
Toivonen Algorithm. Counting the frequent data sets: sampling, hybrid methods.
11. Clustering algorithms. Clustering strategy. Hierarchical clustering in Euclidean and non-Euclidean spaces, its effectiveness. K-means algorithm.
12. Bradley-Fayyad-Rein Algorithm (BFR). CURE Algorithm. Cluster tree. GRGPF algorithm. Application of clustering algorithms with in-line and parallel computing.
13 Determination of the structure and typology of neural networks. Kohonen maps. Neural network inverse distribution. Application of neural networks in economics, logistics, ITsphere.
14 Algorithms for online and offline. Greedy. Competitive ratio. The problem of coincidences. Balance algorithm and the balance of the generalized algorithm.
15 The model of decision support system. Matrix utility. Collaborative filtering.
Measurement identity. UV - decomposition. Standard deviation.
16 What is a social network? Social networks as graphs. Types of social networks.
Clustering of social network graphs, distance in graphs. Girvan-Newman algorithm.
Maximum likelihood algorithm.
Developers:
NRU-HSE ________ _______ professor ________ _____ Nikolay V. Markov
(workplace) (position) (инициалы, фамилия)
10