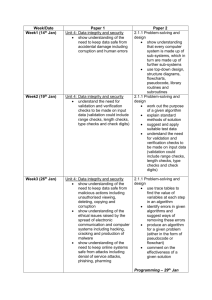
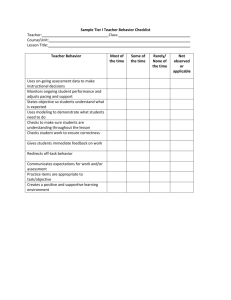
Definition of validation levels and other related concepts
advertisement

European Commission – Eurostat/B1, Eurostat/E1, Eurostat/E6 WORKING DOCUMENT – Pending further analysis and improvements Based on deliverable 2.5 Contract No. 40107.2011.001-2011.567 ‘VIP on data validation general approach’ Definition of validation levels and other related concepts – v 0.1307 July 2013 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 Document Service Data Type of Document Deliverable Reference: 2-5 Definition of “validation levels” and other related concepts Version: 0.1304 Created by: Angel SIMÓN Status: Date: Draft 23.04.2013 European Commission – Eurostat/B1, Eurostat/E1, Eurostat/E6 For Internal Use Only Angel SIMÓN Remark: Pending further analysis and improvements Distribution: Reviewed by: Approved by: Document Change Record Version Date Change 0.1304 23.04.2013 Initial release based on deliverable from contractor AGILIS 0.1307 08.07.2013 Added an executive summary and small improvements Contact Information EUROSTAT Ángel SIMÓN Unit E-6: Transport statistics BECH B4/334 Tel.: +352 4301 36285 Email: Angel.SIMON@ec.europa.eu April 2013 Page 2 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 Table of contents Page 1 Introduction ..................................................................................................................................4 2 2.1 2.2 Some preliminary basic concepts and terminology .................................................................5 Concepts ........................................................................................................................................5 Terminology....................................................................................................................................7 3 Some more formal definitions ....................................................................................................8 4 4.1 4.2 4.3 4.4 4.5 Validation levels ...........................................................................................................................9 Validation level 0 ..........................................................................................................................11 Validation level 1 ..........................................................................................................................12 Validation levels 2 and 3 ..............................................................................................................13 Validation level 4 ..........................................................................................................................15 Validation level 5 ..........................................................................................................................15 5 Some further observations .......................................................................................................15 Annex .....................................................................................................................................................16 April 2013 Page 3 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 1 Executive summary The present document provides definitions to support the classification of validation rules into different levels from 0 to 5 depending on the target dataset and the origin of the checked dataset(s) by validation rules. The document is an evolution of the document “Validation levels” produced by the VIP Validation project in 2011 with added definitions and examples. Following graph represents the validation levels described in the document. Data Between different providers Within a statistical provider Between domains Within a domain From the same source Same dataset Same file Between files Between datasets From different sources Level 5: Consistency checks Level 4: Consistency checks Level 3: Mirror checks Level 2: Between correlated datasets Level 0: Level 1: Level 2: Format & file Cells, Revisions and structure records, file Time series Graph 1: Visual representation of Validation levels and increased complexity April 2013 Page 4 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 2 Introduction The expression "validation levels" is currently given (slightly) different meanings. This document is intended to give some first definitions to this and other related concepts. The document provides examples of rules for each validation level; these examples however are by no means an exhaustive list of the possible rules for each level. Nor is the classification of validation rules into levels the only possible typology of validation rules. The purpose of this document is not to be / become a consistent and exhaustive paper, but just to give some initial elements for an exchange of views with possible stakeholders in both Eurostat and the Member States. The final aim is not to produce a methodological reference but rather a practical tool to improve communication in the concrete statistical production activity. This is in line with the philosophy of the "VIP on validation": "be concrete", "be useful". 3 Some preliminary basic concepts and terminology 3.1 Concepts What is "validation"? The following definitions can be found in a dictionary: Valid o 1(a) legally effective because made or done with the correct formalities o 1(b) legally usable or acceptable o well based or logical; sound Validate o make (sth) legally valid; ratify o make (sth) logical or justifiable Both meanings are applicable to statistical activity. Indeed, Eurostat / NSIs’ "official" statistics are used in precise legal contexts (in both the public and private spheres) and they have to correspond to specific characteristics (harmonised definitions; independence of statistical offices; etc.). Also the second, more general, meaning (logical, sound, well based) can be used with reference to statistical results of good quality. Thus, data validation could be operationally defined as a process which ensures the correspondence of the final (published) data with a number of quality characteristics. More realistically, data validation is an attempt to ensure such a correspondence, since the action of validating or making valid may be successful or not. In the negative event this may lead to a nonpublication of the collected data or to their publication with appropriate explanatory notes in order to guide users to an appropriate use of the data. April 2013 Page 5 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 How to define the concept of data quality in the framework of data validation? In general the concept of data quality encompasses different dimensions. Some relate to the way data (and the accompanying metadata) are published, such as accessibility and clarity; some relate to the time data are published, such as timeliness and punctuality; others relate more generally to the capability of statistics to meet user needs (relevance). However in the framework of data validation, one usually refers to the intrinsic characteristics of the data: accuracy, coherence, comparability. Accuracy Accuracy of statistics refers to the absence of (substantial) errors or in other words to the closeness of results to the "truth", or the "real" value of the phenomenon to be measured. 1 More concretely, data validation tries to ensure the degree of accuracy of the published statistics, required by (known) user needs. More operationally, data validation can be embodied in a "system of quality checks" capable to identify those (substantial) errors which prevent statistics to reach the level of accuracy required by (main) user needs.2 A quality check is meant to identify those values which do not comply with well defined logical or other kinds of (more or less empirically defined) conformity rules. The identified outliers (lying out of the expected or usual range of values) are (potential) errors. The final purpose of data validation is to correct the outliers only where relevant, i.e. by identifying the "real" errors. 3 Usually data validation is aiming at correcting errors before the publication of the statistics. However, sometimes the corrections can be also performed after the publication: revisions. The decision whether to publish or not statistics including identified errors is based on a (usually empirical) trade-off between different and "contradictory" quality components (usually timeliness and accuracy). Sometimes quality checks can help in identifying structural data errors (as opposed to one-off outliers). These can originate from a misinterpretation of the statistical definitions or by the nonconformity of the sources or other characteristics of the data collection vis-à-vis the statistical concepts. The correction of these errors may require an improvement / clarification of the methodological definitions and/or a (structural) modification in the implementation of the data collection. Coherence and comparability Quality checks can also be used to test the internal coherence of a single statistical output (for example arithmetic relations between variables) or the comparability of its results over time or over space. Consistency and comparability can also be tested between two or more different statistical outputs (domains): in this case the possibility to develop quality checks depends on the degree to which the different data collections make use of the same harmonised concepts (definitions, classifications, etc.). 1 This can be defined in terms of "accepted range of deviation". 2 The required level of accuracy has an impact on the way simple equations are implemented. 3 Imputation can be intuitively seen as a kind of correction, specifically for "missing data". April 2013 Page 6 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 3.2 Terminology Term Description Data warehouse Whole set of domains under the (direct or indirect) "control" of the same Institution. Database used for reporting and data analysis. Domain Set of information and data covering a certain topic Source Origin of the data Statistical variable Object of a measurement with reference to a group of statistical units defined by the reference variables. Statistical unit Member of a set of entities being studied. Reference variable Identify the necessary reference to put in a "context" the statistical variables. Quantitative variable Quantitative data is data expressing a certain quantity, amount or range. Usually, there are measurement units associated with the data, e.g. metres, in the case of the height of a person. It makes sense to set boundary limits to such data, and it is also meaningful to apply arithmetic operations to the data. Derived variable A derived statistic is obtained by an arithmetical observation from the primary observations. In this sense, almost every statistic is "derived". The term is mainly used to denote descriptive statistical quantities obtained from data which are primary in the sense of being mere summaries of observations, e.g. population figures are primary and so are geographical areas, but population-per-square-mile is a derived quantity. Outlier An outlier is value standing far out of the range of a set of values which it refers to. In Animal Production Statistics, the set of value for a variable is the known time series for this variable. Suspicious value A value is suspicious when it has broken a validation check but no final decision has yet been taken. Error Outlier or inconsistency compared to the expected result Fatal Error Error stopping the data processing Warning Error not stopping the data processing Dataset Structure for the transmission or organisation of statistical data File A dataset specific transmission occurrence Record A row providing the statistical information in a file Code Allows identifying the statistical references Dictionary List of the allowed codes Revision New occurrence of a data file Correction Modification of statistical information without reception of a new occurrence of a data file April 2013 Page 7 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 4 Some more formal definitions In the previous section some concepts have been given imprecise meaning/definitions, in order not to complicate the presentation. This section is meant to remedy this and provides definitions which are in line with international standards.4 Data editing is the activity aimed at detecting and correcting errors (logical inconsistencies) in data. 5 The editing procedure usually includes three phases: - the definition of a consistent system of requirements (checking rules), - their verification on given data (data validation or data checking) and - elimination or substitution of data which are in contradiction with the defined requirements (data imputation). Checking rule is a logical condition or a restriction to the value of a data item or a data group which must be met if data are to be considered correct. Common synonyms: edit rule, edit. Data validation is an activity aimed at verifying whether the value of the data item comes from the given (finite or infinite) set of acceptable values. 6 Data checking is the activity through which the correctness conditions of the data are verified. It also includes the specification of the type of error or condition not met, and the qualification of the data and its division into the "error free" and "erroneous" data. Data imputation is the substitution of estimated values for missing or inconsistent data items (fields). The substituted values intended to create a data record that does not fail edits. Quality assurance is a planned and systematic pattern of all the actions necessary to provide adequate confidence that a product will conform to established requirements. 7 4 The definitions are taken from the UNECE "Glossary of terms on statistical data editing": http://live.unece.org/fileadmin/DAM/stats/publications/editingglossary.pdf A continuously updated version of the Publication edited in 2000 is available on line: http://www1.unece.org/stat/platform/display/kbase/Glossary 5 The definition of "data validation" in the OECD "Glossary of statistical terms" is identical: http://stats.oecd.org/glossary/detail.asp?ID=2545 6 The definition of "data editing" in the OECD "Glossary of statistical terms" is identical: http://stats.oecd.org/glossary/detail.asp?ID=3408 7 as available in the OECD Glossary of statistical terms: http://stats.oecd.org/glossary/detail.asp?ID=4954 April 2013 Page 8 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 5 Data validation Data editing Quality assurance Taken into account the above international definitions, the following hierarchical relation can be established between three concepts widely utilised in the context of data quality: - Establishment of checking rules; Detection of outliers or potential errors; Communication of the detailed problems to the "actors" in the best position to investigate them; - Corrections of the errors based on appropriate investigations or automatic imputation; - Technical activities, e.g. data analysis, which are not part of the agreed set of checking rules; Activities of other nature, for instance compliance monitoring which is a set of governance processes that are meant to stimulate EU Member States to respect their obligation to apply systematically the EU statistical legislation. - Validation levels Validation levels can be defined with reference to quite different concepts. Sometimes the levels (first level of validation, second level of validation, etc.) reflect simply and empirically the (early vs. late) phases of the production process at which quality checks are performed. On similar grounds the levels can be referred to either the persons / Institutions (for example Member States vs. Eurostat) or the specific IT tools (for example GENEDI, eDAMIS validation engine or eVE vs. Editing Building Block or EBB) performing the quality checks at successive stages in the production chain. Validation levels can also be defined by the degree to which the detected "outliers" are not in conformity with the rules underlying the quality checks: clear (logical / arithmetic) vs. potential nonconformity. In other words the classification of validation levels can based on the above mentioned distinction between errors (or "real errors") and outliers (or "potential errors"). An automatic application of this classification to the kind of operational behaviour to follow for the two types of "outliers" can lead to the distinction between "fatal errors" (the production process is stopped until corrections are made) and "warnings" (the production process can continue). However a less automatic application of this principle, based on a more flexible trade-off between timeliness and accuracy, can lead to consider as "warnings", also situations where real (but not very serious) errors are detected. This case can be implemented in specific validation tools as the possibility to "force" the data transmission (or the publication) even though some real (for example logical or arithmetic) errors are detected. On the contrary, serious outliers (potential errors) can also lead to the decision of stopping the production process until verification is made. A classification of validation levels can also be based on the progressively larger amount of data which are necessary to perform the quality checks. April 2013 Page 9 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 In order to define some basic concepts which are necessary for the above mentioned classification of validation levels, let's assume in a simplified example that data are organised or exchanged by using bi-dimensional tables. The columns of the table identify two different categories of "variables": - the reference "variables" (or classification "variables", or reference metadata) - the statistical variables. The rows identify the "records". The reference variables identify the necessary reference to put in a "context" the statistical variables and give a meaning to the collected numbers. Example of a statistical variable: number of inhabitants (for example: 200,000). Possible corresponding reference "variables": country of residence (for example: Luxembourg), date (for example: 15/02/2011), sex (for example: Females). More precisely a statistical variable is the object of a measurement with reference to a group of statistical units defined by the reference "variables". The above information can be organised in a record (a row of the table): Luxembourg; 15/02/2011; Females; 200,000 More records constitute a file: Luxembourg; 15/02/2011; Females; 200,000: Luxembourg; 15/02/2011; Males; 190,000: Luxembourg; 15/02/2011; Total; 390,000: A dataset is the agreed structure for the transmission or organisation of statistical data. The above dataset could be named "census population by country of residence and by sex". Its agreed structure can be described as: "country; date; sex; number of inhabitants". A dataset is the unit for data transmission.8 A file is a dataset specific transmission occurrence. Certain reference variables are associated to defined (agreed) dictionaries. Dictionaries include the list of the possible occurrences of the specific reference variable. Example of a dictionary is "Sex": - Females - Males - Total 8 If data are not "transmitted" (for example in the case of a "hub" architecture), a dataset is a defined subset of the underlying database. April 2013 Page 10 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 Usually each specific occurrence is associated to an agreed code: this leads to a simplification of the file content. An example of dictionary with codes is "Sex": F; Females M; Males T; Total With the use of agreed dictionaries, the file of the above example could be simplified as follows: LU; 15/02/2011; F; 200,000: LU; 15/02/2011; M; 190,000: LU; 15/02/2011; T; 390,000: In this specific example, colon, semi-colon and comma are special characters used to structure respectively the records, the fields (the variables) and the thousands in the numbers; the date in the second field has a specified format. Let's define now the validation levels on the basis of the progressively larger amount of data which are necessary to perform the quality checks. 5.1 Validation level 0 Some quality checks do not need any data of the file (referring to the specific values of either the statistical or the reference variables) in order to be performed: validation level 0. For these quality checks for example only the structure of the file or the format of the variables are necessary as input. For example, it is possible to define a "dataset naming convention" on the basis of which the file above has to be "named", for example CENSUS_2011_LU_SEX. Before even "reading" the (statistical) content of the data included in the file one can check for example: - if the file has been sent/prepared by the authorised authority (data sender); - if the column separator, the end of record symbol are correctly used; - if the file has 4 columns (agreed format of the file); - if the first column is alphanumeric (format of each variable / column) - if the first column is two-character long (length of the first column) - if the second column fits a particular mask (date); - if all the required information is included in the file (no missing data). Example of a file for which validation level 0 may give error messages: LU; 15/02/2011; F; 200,000: L; 15/02/11; ; 190,000_ LU; 15/02/2011, T; 390,000: April 2013 Page 11 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 Validation level 0 is usually referred to as "(sender,) format and file structure" checks or more simply "format and file structure checks". 5.2 Validation level 1 Validation level 1 can group all these quality checks which only need the (statistical) information included in the file itself. a) Some checks can be based at the level of each record, or even at the level of each cell (identified by "coordinates" of one row and one column). One could check for example: - if the number included in column 4 is not negative; - if the number included in column 4 is an integer. Combining the information of one cell in the file and the file name one could check: - if the year in the second column is 2011, as in the file name; - if the content of the first column is LU, as in the file name. Combining the information of one cell in the file with information included in dictionaries associated to variables one could check: - if the content of the third column is one of the codes of the dictionary "Sex"; - if the content of the first column is one of the codes of the dictionary "Country". Combining the information of one cell in the file and other dictionaries associated to that dataset one could check: - if the content of the first column is consistent with the data sender (let's assume that there is a dictionary including the list of the data senders associated to the specific dataset): data for Luxembourg should not be sent by another country. b) Some checks can be based at the level of a record (using the information included in the cells of one row). For example one could devise the following quality checks: - based on information available before data collection (for example from previous survey or other sources) one could establish a "plausibility range" for inhabitants of Luxembourg in 2011 as follows: IF column 1 = "LU" and Column 3 = "T" then the variable number of inhabitants should be included in the range 100,000 – 1,000,000. This quality check is not a time series check, but rather a plausibility check based on historical or other information. It is an "order of magnitude" check, i.e. it is meant to detect clerical mistakes, like typing one zero more or one zero less, typing a decimal comma instead of a thousand separator comma. - in files where two or more statistical variables are collected, other logical or plausibility checks can be conceived between two or more variables (also using dictionaries): a certain combination of codes is illogical, a variable has to be reported only for a certain combination of codes, etc. c) Some checks can be based at the level of two or more records up to all the records of the entire file. Examples of mathematical expressions to be respected: - Total inhabitants (col 3 = "T") > = Male (Col 3 = "M") inhabitants - Total inhabitants = male inhabitants + female inhabitants (col 3 = "F") April 2013 Page 12 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 Based on information available before data collection one could conceive for example the following plausibility rule: - Female inhabitants = (total inhabitants / 2) +/- 10% - one could check the absence of double records (records for which the combination of the reference variables is identical) Validation level 1 is usually referred to as "intra-dataset checks". Since we have defined a file as a specific occurrence of a dataset, these checks should be more properly called as "intra-file checks"9. 5.3 Validation levels 2 and 3 The next validation levels could group all the quality checks in which the content of the file is compared with the content of "other files" referring to the same statistical system (or domain). Case a) the "other files" can be other versions of exactly the same file. In this case the quality checks are meant to detect "revisions" compared to previously sent data. Detection and analysis of revisions can be useful for example to verify if revisions are consistent with outliers detected in previous quality checks (corrections) or to have an estimate of the impact of the revisions in the "to be published" results, for the benefit of the users. Case b) the "other files" can be already received versions of the same dataset, from the same data provider (for ex. a country), but referring to other time periods. These checks are usually referred to as "time series checks" and are meant to verify the plausibility of the time series. "Revision checks" and "time series checks" could be referred to as "intra-dataset inter-file checks", since they are performed between different occurrences (files) of the same defined data (transmission) structure (a dataset). 9 It is useful to remind that a dataset is defined as the unit of data transmission. The file should correspond to an entire dataset (and not to a sub-set of it) when defining "intra-file checks". However, sometimes a dataset can be physically split in different files, which are sometimes collected by different data providers or Institutions. Sometimes the files are merged before data transmission by one of these Institutions (of another Institutions), who is meant to guarantee the homogeneity of concepts used by the original different data sources. However, sometimes the files are transmitted separately by the different data providers or are assembled in one file by one Institution without an effective action aiming at guaranteeing the homogeneity of the concepts used by the original data providers. In case of inconsistencies between data transmitted by different data providers (for example because of a lack of harmonisation of concepts used by the different providers) the definition of "dataset" should be used in order to identify the correct level of validation to which the detection of these inconsistencies should be classified. Indeed these inconsistencies should be seen as inconsistencies between records of the same dataset: these are "intra-dataset" or (at least conceptually) "intra-file checks" and not "inter-source" or "inter-data providers checks" (to compare with paragraph 4.3 Case d below). April 2013 Page 13 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 Case c) the "other files" can refer to other datasets from the same data provider (country), but referring to the same or other correlated time periods. Sometimes a group of datasets (same country, same reference period) is sent at the same time. Example: three files could be sent at the same time, from the same country and referring to the same time period: one file includes data for "females", one for "male", one for "total". Consistency between the results of the three files can be checked. Another example: results from annual datasets can be compared with the results of the corresponding quarterly datasets. These checks are usually referred to as "inter-dataset checks". More precisely they could be called "intra-data provider (or intra-source) inter-dataset checks".10 Case d) the "other files" can refer to the same dataset, but from another data provider (country). For example mirror checks are included in this class. Mirror checks verify the consistency between declarations from different sources referring to the same phenomenon. Example: export declared by country A to country B should be the same as import declared by country B from country A. Mirror checks are "inter-source intra-dataset checks" (if, in our example, export and import are included in the same dataset) or "inter-source inter-dataset checks". If one defines a database as the combination of all datasets of the same "domain" (this implies that the methodological basis of all these datasets is somehow homogeneous), then all the above quality checks (Cases a, b, c and d) could be referred to as "intra-database checks". Two important aspects have to be clarified. First, the concept of database is technical. For technical reasons it may happen that the same database includes data from different domains; vice-versa the data of the same domain could be stocked in more than one database. As a consequence it would be more correct to refer to the above validation operations (Cases a, b, c and d) as "intra-domain checks". Second, when data for the same domain (= the same homogeneous methodological framework) are collected from different sources (countries), it can happen that the implementation of the methodological concepts may be not completely homogeneous from one source to another. For this and other practical reasons (who is in the best position to perform the specific quality checks?), it could be considered sound to distinguish two different validation levels, as follows: Validation level 2 is defined as "intra-domain, intra-source checks": it includes revision checks, time series checks and (intra-source) inter-dataset checks (Cases a, b and c above). Validation level 3 is defined as "intra-domain inter-source checks": it includes mirror checks (Case d). 10 Or maybe "intra-source intra-group (of correlated datasets) inter-dataset checks" April 2013 Page 14 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 5.4 Validation level 4 Validation level 4 could be defined as plausibility or consistency checks between separate domains available in the same Institution. The availability implies a certain level of "control" over the methodologies by the concerned Institution. These checks could be based on the plausibility of results describing the "same" phenomenon from different statistical domains: example unemployment from registers and from Labour Force Survey. Checks could also be made between results from correlated micro-data and macro-data sources. Other plausibility checks could be based on known correlations between different phenomena: for example external trade and international transport activity in ports. These checks could be defined as intra-Institution checks or inter-domain checks or intra-datawarehouse checks, if one define as a data warehouse the whole set of domains under the (direct or indirect) "control" of the same Institution. 5.5 Validation level 5 Validation level 5 could be defined as plausibility or consistency checks between the data available in the Institution and the data / information available outside the Institution. This implies no "control" over the methodology on the basis of which the external data are collected, and sometimes a limited knowledge of it. Statistical indicators collected by Eurostat might also be compiled for their own needs by national institutions such as National Statistical Institutes or Ministries; by private entities (ports, airports, companies, etc.) and also by international organisations (World Bank, United Nations, International Monetary Fund, etc.). For example, EU road freight statistics are prepared by Member States according to the EU Commission legal acts and in addition countries can carry out specific surveys for national purposes. A benchmarking between indicators common to these different surveys allows assessing the coherence of these data and could help improving the methodologies for data collection. A graphical representation of the allocation of validation rules into validation levels is available in Annex. 6 Some further observations As a general rule, the higher the level of validation the more difficult is to identify "fatal errors", i.e. errors that imply the "rejection" of a data file. The above classification of validation levels seems to be operational in terms of both IT implementation (the level of data needed to carry out the checks) and the attribution of the responsibility (the availability of information generally follows the hierarchical organisation of different Institutions participating to the data collection exercise). April 2013 Page 15 Project: ESS.VIP.BUS Common data validation policy Document: D2.5 - Definition of validation levels and other related concepts Version: 0.1307 Annex Graph 2: Visual guide to the allocation of validation rules into validation levels. Data Within a statistical authority Within a domain From the same source Same file Level 0 Format and File structure checks January 2013 Level 1 Cells, Records, File checks Between files Between domains From different sources Between datasets Same dataset Between statistical authorities Level 5 Consistency checks Level 4 Consistency Checks Level 3 Mirror checks Level 2 Checks between correlated datasets Level 2 Revisions and Time series Page 16