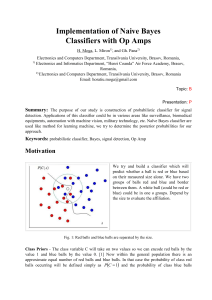
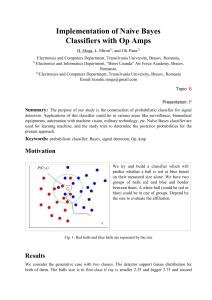
II. General Implementation
advertisement

Implementation of Naive Bayes Classifiers with Op Amps Horatiu Moga, Gheorghe Pana Liliana Miron Electronics and Computers Department Transilvania University, UTBv Brasov, Romania horatiu.moga@gmail.com gheorghe.pana@unitbv.ro Department of Electronics and IT, “Henri Coanda” Air Force Academy, AFAHC Brasov, Romania miron_liliana@yahoo.com Abstract— The purpose of the study is the construction of probabilistic classifiers for signal detection. Applications of this classifier can be found in various areas like surveillance, biomedical equipments, automation with machine vision, military technology, etc. Naïve Bayes classifiers are used for learning machines, and the study tries to determine the posterior probabilities for the present approach. number of red balls and blue balls. In that case the probability of class red balls occurring will be defined simply as PC 1 and the probability of class blue balls occurring will be PC 0 . These probabilities are set prior to making any measurements and hence are called the prior probabilities of class membership. Keywords-component; probabilistic classifier, Bayes, signal detection, Op Amp B. Class Conditional Likelihood There is a ball (plotted white), randomly selected from the population, and we measure its size. There will be a natural distribution of the size of red balls and blue balls, in other words there will be a class conditional distribution of the measured features, in this case size. We can name these class conditional distributions ps | C 1 and ps | C 0 fom red balls and blue balls classes respectively. I. INTRODUCTION We try to build a classifier which will predict whether a ball is red or blue based on their measured size alone. We have two groups of balls red and blue and a border between them. A white ball (could be red or blue) can be in one of groups (Fig. 1). Depends on the size to evaluate the affiliation. C. Class Posterior The Bayes rule helps us obtain the posterior probability of class membership by noting that Ps, C 1 ps | C 1 PC 1 PC 1 | s p(s) and PC 1 | s ps | C 1 PC 1 p(s) and the marginal likelihood of our measurement, ps , is the probability of measuring a size s irrespective of the class and therefore Figure 1. Red balls and blue balls are separated by size A. Class Priors The class variable C will take on two values so we can encode red balls by the value 1 and blue balls by the value 0. [1] Within the general population there is an approximate equal ps ps | C 1 PC 1 ps | C 0 PC 0 which means that the class posteriors will also sum to one, PC 0 | s PC 1 | s 1 D. Discriminant Functions [2] From Fig.1 we can see the empirical distributions of size for both reds and blues. The first thing to notice is that there is a distinct difference in the location of the distributions and that they can be separated by a large extent (supposing that reds are typically bigger than blues). However there is a region where the two distributions overlap and it is here that classification errors can be made. The region of intersection where PC 1 | s PC 0 | s is important as it defines our decision boundary. If we make a measurement of f s log PC 1 | s PC 0 | s ps | C 0 and then use these estimates to define our posterior probabilities and hence our discriminant function. As the class-conditioning densities define the statistical process which generates the features, we then measure this approach which is often referred to as the generative approach. s0 size then we can see that PC 1 | s PC 0 | s and whilst there is some probability that we have measured a rather bigger blue, to minimize the unavoidable errors that will be made then our decision should be based on the largest posterior probability. We can then define a discriminant function based on our posterior probabilities. One such function could be the ratio of posterior probabilities for both classes. If we consider the logarithm of this ratio then the general discriminant function often referred to as the discriminative approach to defining a classifier as all effort is placed on defining the overall discriminant function with no consideration to the classconditional densities which form the discriminant. The second way is to focus on estimating the class-condition densities (distributions if the features are discrete) ps | C 1 and would define the rules that s would be assigned to C 1 (male) if f s 0 and if f s 0 the assignment would be to C 0 (female). II. GENERAL IMPLEMENTATION The general schematic of Bayes classifier is presented in Fig. 2. The coming signal is captured by parallel independent blocks and it is calculated by class conditional likelihood. Multiplicator blocks calculate partial probabilities and the “Maximum Selector” block selects the maximum probability and the involved class. For digital approach, we can use a DSP or FPGA area, and general schematic could be quickly executed. The main idea remains in the analog area. For conditional likelihood calculation, we need a general reconfigurable analog block, that could have a non-liniar variable transfer function. The decision over a specific transfer function is getting in learning process. We have to catch up a couple of patterns for the distribution functions, and to decide which of them use it in a specific time. E. Discriminative and Generative Classifiers There are two ways in which we can define our discriminant function. [3] In the first case we can explicitly model our discriminant function using for example a linear or nonlinear model. This is P(s|C=1) P(C=1) s-signal Maximum Selector P(s|C=2) P(C=2) P(s|C=k) P(C=k) General schematic of Bayes classifier P(C) For analog implementation, we could use FPAA circuits, which are large analog area circuits, fully reconfigurable, with wide area of implementation in a small frequency spectrum, from telecommunication, automation, audio signal processing, etc. III. We consider the generative case with two classes. The detector support Gauss distribution is used for both of them. The balls’ size is in the first class if the ray is smaller than 2.25 and bigger than 2.75 and in the second class it is the opposite. For the first class we calculated the mean µ1=2.5 and the standard deviation ϭ1=0.88. The second class mean is µ2=0.91 and the standard deviation is ϭ2=3.6. The schematic is presented in Fig. 3. Generally we have to focus on analog non-linear electronic circuits using synthesis and analysis. For this we may use a few types of research: Smooth approximations Polynomials and power series Piecewise-linear function fitting [4] We suppose that the uniform distribution for both classes is 0.7 for first and 0.5 for second one. The results (Fig. 4) show us that it verifies the initial hypotheses. The transition band between (2.25, 2.5) and (2.5, 2.75) decides if the white ball is red or blue, and if it belongs to one class or the other. For multiplication blocks we may use regular multiplication circuits and the “Maximum Selector” block will use comparative integrated circuits. 8 - 4 R9 V-2Meg TL082 V- Q1 V- V- 10k 7 - 4 V+ U9B TL082 V- R5 5 U5B VR6 OUT 6 10k Vmiu2 3.6 + 10k - 4 TL082 6 7 R10 V-2Meg V- X1 X2 U0 U1 U2 Y1 Y2 VP DD W Z1 Z2 ER VN 14 13 12 11 10 9 8 V+ + Q2 8 V+ TL082/301/TI 7 OUT - 4 V- V- R14 0 3.9k 0 Vsigma2 -1.82 - V+ VP2 5V 0 6 VVLM311/301/TI 0 V+ AD633/AD V1 15V V- 0 V2 15V V- 0 Figure 2. The schematic of the circuit 15V 10V 5V 0V 0V 0.5V 1.0V 1.5V 2.0V 2.5V 3.0V 3.5V 4.0V V(out) V_Vz Figure 3. The result of the Spice simulation 4.5V 0 7 R12 1T 0 out 0 AD734/AD 0 + U7 1 2 X1 3 X2 4 Y1 W 6 Y2 Z Q2N2222 V- V- 0 V+ 0 U4 1 2 3 4 5 6 7 R15 4.7k V+ U8 OUT 5 0 8 OUT 6 VP1 7V 0 R11 1T 0 0 3.9k AD734/AD 0 R13 Q2N2222 0 V+ V- V+ Vsigma1 -1.76 V+ Vz 2 VP DD W Z1 Z2 ER VN V+ 0 R8 10k V+ U2B 5 + 8 R7 X1 X2 U0 U1 U2 Y1 Y2 V- V+ 2 0 1 4 5 OUT - 8 + V+ 2 14 13 12 11 10 9 8 V+ V+ 1 2 3 4 5 6 7 V- R4 10k 3 U3 5 8 V+ U9A U6 AD633/AD 1 2 X1 3 X2 7 4 Y1 W 6 Y2 Z TL082/301/TI 1 OUT 0 1 V+ 10k + 8 U1A + 8 OUT R3 V+ V+ 4 3 0 3 V+ U10A 10k V- TL082 2 - V- 10k Vmiu1 2.5 R2 V+ R1 RESULTS 5.0V 5.5V 6.0V [3] REFERENCES [1] [2] Christopher M. Bishop,“Pattern Recognition and Machine Learning”, Springer Science+Business Media, LLC, 2006, pg. 181. Andrew Webb, “Statistical Pattern Recognition”, Second Edition, John Wiley & Sons Ltd., 2000, pp. 123-180. [4] Sebe N., Ira Cohen, Ashutosh Garg, Thomas S. Huang, “Machine Learning in Computer Vision”, Springer Science+Business Media, LLC, 2005, pp. 71. Daniel Sheingold, „Nonlinear Circuit Handbook“, Analog Device Inc., 1976.