Chapter 3. Advanced Data Mining –Neural
advertisement

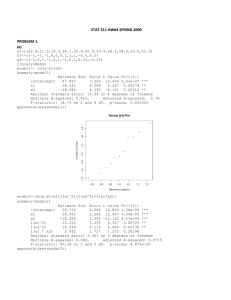
Chapter 3. Advanced Data Mining –Neural Networks 3.1 Supervised Prediction A. Introduction B. Univariate Function Estimation C. Multivariate Function Estimation 3.2 Network Architecture A. Multilayer Perceptrons B. Link Functions C. Normalized Radial Basis Functions 3.3 Training Model A. Estimation B. Optimization C. Issues in Training Model 3.4 Model Complexity A. Model Generalization B. Architecture Selection C. Pruning Inputs D. Regularization 3.5 Predictive Data Mining A. Overview B. Generalized Additive Neural Networks 1 3.1 Supervised Prediction A. Introduction Data set n cases (observations, examples, instances). A vector of input variables x1 , x2 , , xk A target variable y (response, outcome) Supervised prediction: to identify the target variable y, build a model to predict y using inputs x1 , x2 , , xk . Predictive data mining: predictive modeling methods applied to large operational (mainly corporate) database. Types of targets: 1. Interval measurement scale (amount of some quantities) 2. Binary response (indicator of an event) 3. Nominal measurement scale (classifications) 4. Ordinal measurement scale (grade) What do we model? 1. Amount of some quantities (interval measurement) 2. The probability of the event (binary response) 3. The probabilities of each class of grade (nominal or ordinal measurement) 2 B. Univariate Function Estimation Example 3.1 The EXPCAR data set contains simulated data relating a single target, Y1 to a single input X. The variable EY represents the true function relationship given in a form 1 3 3 E ( y ) 1 exp( 4 x) exp( 3 x) 2 3 4 3 4 1 This function form is generally unknown in applications. Nonlinear Regression: Reference Seber and Wild (1989) Nonlinear Regression, New York: John Wiley & Sons. 3 Main idea: assume that the functional form of the relationship between y and x is known, up to a set of unknown parameters. These unknown parameters can be estimated by fitting the model to the data. The SAS NLIN procedure performs nonlinear regression. Model 1: Model is correctly specified, i.e. we know that 3 1 3 E ( y ) 1 exp( 4 x) exp( 3 x) 3 4 2 3 4 1 proc nlin data=Neuralnt.expcar; parms theta1=100 theta2=2 theta3=.5 theta4=-.01; model y1=theta1/((theta3/(theta3-theta4))*exp(theta4*x)+(theta1/theta2(theta3/(theta3-theta4)))*exp(theta3*x)); output out=pred p=y1hat; run; The estimating procedure involves an iterative algorithm, so the initial guesses for the parameter estimates are necessary. The keyword p in the OUTPUT statement signifies the predicted values After fitting the model, we plot the predicted results goptions reset=all; proc gplot data=pred; symbol1 c=b v=none i=join; symbol2 c=bl v=circle i=none; symbol3 c=r v=none i=join; legend1 across=3 position=(top inside right) label=none mode=share; plot ey*x=1 y1*x=2 y1hat*x=3 / frame overlay legend=legend1; run; quit; 4 Clearly, it shows the model fits the data very well. It is to be expected since the model if correctly specified. By default, PROC NLIN finds the least-squares estimated using the Gauss-Newton method. The least-squares estimates: ˆ (ˆ1 ,ˆ2 ,ˆ3 ,ˆ4 ) satisfies ˆ argmin n ˆi ( ) yi y 2 i 1 Note the algorithm is sensitive to the initial guess. It may diverge with a bad initial value. 5 proc nlin data=Neuralnt.expcar; parms theta1=10 theta2=.2 theta3=.05 theta4=-.001; model y1=theta1/((theta3/(theta3-theta4))*exp(theta4*x)+(theta1/theta2(theta3/(theta3theta4)))*exp(theta3*x)); output out=pred p=y1hat; run; goptions reset=all; proc gplot data=pred; symbol1 c=b v=none i=join; symbol2 c=bl v=circle i=none; symbol3 c=r v=none i=join; legend1 across=3 position=(top inside right) label=none mode=share; plot ey*x=1 y1*x=2 y1hat*x=3 / frame overlay legend=legend1; run; quit; 6 Clearly, this is not the right estimate. The NLIN Procedure Iterative Phase Dependent Variable Y1 Method: Gauss-Newton Iter theta1 theta2 theta3 theta4 Sum of Squares 88 89 90 91 92 93 94 95 96 97 98 99 100 -0.00848 -0.00822 -0.00791 -0.00771 -0.00746 -0.00716 -0.00697 -0.00673 -0.00643 -0.00625 -0.00602 -0.00574 -0.00556 1.3514 1.3591 1.3684 1.3741 1.3810 1.3895 1.3946 1.4009 1.4086 1.4133 1.4190 1.4260 1.4303 0.00315 0.00303 0.00289 0.00280 0.00269 0.00255 0.00247 0.00237 0.00225 0.00218 0.00208 0.00197 0.00190 0.5310 0.5295 0.5277 0.5266 0.5252 0.5236 0.5227 0.5215 0.5201 0.5192 0.5182 0.5169 0.5162 160349 159871 159633 159106 158662 158444 157959 157556 157371 156930 156572 156433 156037 WARNING: Maximum number of iterations exceeded. WARNING: PROC NLIN failed to converge. Sometimes alternative algorithms do better. The Marquardt (Levenberg-Marquardt) method is a modification of the Gauss7 Newton method designed for ill-conditioned problems. In this case it is able to find the least squares estimates in 12 iterations. proc nlin data=Neuralnt.expcar method=marquardt; parms theta1=10 theta2=.2 theta3=.05 theta4=-.001; model y1=theta1/((theta3/(theta3-theta4))*exp(theta4*x)+(theta1/theta2(theta3/(theta3-theta4)))*exp(-theta3*x)); output out=pred p=y1hat; run; Parametric Model Fitting: Parametric regression models can be used when the mathematical mechanism of the data generalization is unknown. Empirical model building If we look at the scatter plot carefully, we may find that there is a trend: y is very small when x is close to zero, it increases quickly and then decreases to zero again as x increases. This encourages us to try a parametric model (with two parameters, 1 , 2 ) E ( y ) 1 xe2 x proc nlin data=Nueralnt.expcar; parms theta1=1 theta2=.05; model y1=theta1*x*exp(-theta2*x); output out=pred p=y1hat; run; goptions reset=all; proc gplot data=pred; symbol1 c=b v=none i=join; 8 symbol2 c=bl v=circle i=none; symbol3 c=r v=none i=join; legend1 across=3 position=(top inside right) label=none mode=share; plot ey*x=1 y1*x=2 y1hat*x=3 / frame overlay legend=legend1; run; quit; This empirical model fits the data quite well. Polynomial parametric models: Based in approximation theorem, any smooth function can be approximate by a polynomial with a certain degree. Consider a polynomial model d E ( y ) 0 i xi , i 1 where d is the degree of the polynomial. 9 Polynomials are linear with respect to the regression parameters. The least squares estimates have a close-form solution and do not require iterative algorithms. Polynomials can be fitted in a number of SAS procedures. Alternatively, polynomials (up to degree 3) can be fitted in GPLOT using the i=r<l|q|c> option on the SYMBOL statement. Linear regression: Model: E ( y) 0 1 x goptions reset=all; proc gplot data=pred; symbol1 c=b v=none i=join; symbol2 c=bl v=circle i=none; symbol3 c=r v=none i=rl; legend1 across=3 position=(top inside right) label=none mode=share; plot ey*x=1 y1*x=2 y1*x=3 / frame overlay legend=legend1; run; quit; 10 Cubic Regression: 2 Model: E ( y ) 0 1 x 2 x goptions reset=all; proc gplot data=pred; symbol1 c=b v=none i=join; symbol2 c=bl v=circle i=none; symbol3 c=r v=none i=rc; legend1 across=3 position=(top inside right) label=none mode=share; plot ey*x=1 y1*x=2 y1*x=3 / frame overlay legend=legend1; run; quit; 11 Apparently, lower order polynomials are lack of fit for the data set. Instead of continuing to increase the degree, a better strategy is to use modern smoothing methods. Nonparametric Model Fitting: A nonparametric smoother can fit data without having to specify a parametric functional form. Three popular methods are: Loess-Each predicted value results from a separate (weighted) polynomial regression on a subset of the data centered on that data point (window). Kernel Regression-Each predicted value is a weighted average of the data in a window around that data point. Smoothing Splines-Smoothing splines are made up of piecewise cubic polynomials, joined continuously and smoothly at a set knots Smoothing spline can be fitted using GPLOT with option i=SM<nn> Reference: 12 1. Hastie, T.J. and Tibshirani, R.J. (1990). Generalized Additive Models, New York: Chapman and Hall. 2. Fan, J. and Gijbels, I. (1996). Local Polynomial Modeling and its Applications. New York: Chapman and Hall. Smoothing Splines Goal: to minimize 2 2 y ( x ) ( x ) dx , i i i subject to that ( xi ), (xi ) and (xi ) are continuous at each knots. A smoothing spline is known to be over-parameterization since there are more parameters than data points. But it does not necessarily interpolate (overfit) data. The parameters are estimated using penalized least squares. The penalty term favors curves where the average squared second derivative is low. This discourages a bumpy fit. is the smoothing parameter. When it increases, the fit becomes smoother and less flexible. For smoothing splines the smoothing is specified by the constant after SM in the SYMBOL statement. The smoothing parameter rages from 0 to 99. Incorporating 13 (roughness/complexity) penalties into the estimation criterion is called regularization. A smoothing spline is actually a parametric model, but the interpretation of the parameter is uninformative. Let’s fit this data using some smoothing splines. goptions reset=all; proc gplot data=Neuralnt.expcar; symbol1 c=b v=none i=join; symbol2 c=bl v=circle i=none; symbol3 c=r v=none i=sm0; title1 h=1.5 c=r j=right 'Smoothing Spline, SM=0'; plot ey*x=1 y1*x=2 y1*x=3 / frame overlay; run; quit; 14 15 C. Multivariate Function Estimation Most of the modeling methods devised for supervised prediction problems are multivariate function estimations. The expected value of the target can be thought of as a surface in the space spanned by the input variables. It is uncommon to use parametric nonlinear regression for more than one, or possibly two inputs. Smoothing splines and loess suffer because of the relative sparseness of data in higher dimensions. Multivariate function estimation is a challenging analytical task! Some notable works on multivariate function estimation: Friedman, J. H. and Stuetzle, W. (1981). “Projection Pursuit Regression”, J. am. Statist Assoc. 76, 817-23. 16 Friedman, J.H. (1991). “Multivariate adaptive regression splines”, Ann. Statist. 19. 1-141 Example 3.2. The ECC2D data set has 500 cases, two inputs X1, X 2 , and an interval-scaled target Y1 . The ECC2DTE has an additional 3321 cases. The variable Y1 in ECC2DTE set is the true, usually unknown, value of the target. ECC2DTE serves as a test set; the fitted values and residuals can be plotted and evaluated. The true surface is 17 Method 1: E ( y) 0 1 x1 2 x2 proc reg data=neuralnt.ecc2d outest=betas; model y1=x1 x2; quit; proc score data=neuralnt.ecc2dte type=parms scores=betas out=ste; var x1 x2; run; data ste; set ste; r_y1=model1-y1; run; proc g3d data=ste; plot x1*x2=model1 / rotate=315; plot x1*x2=r_y1 / rotate=315 zmin=-50 zmax=50 zticknum=5; run; quit; 18 Method 2. E ( y ) 0 1 x1 2 x2 11 x12 22 x22 12 x1 x2 111 x13 222 x23 112 x12 x2 221 x1 x22 data a; set neuralnt.ecc2d; x11=x1**2; x22=x2**2; x12=x1*x2; x111=x1**3; x222=x2**3; x112=x1**2*x2; x221=x2**2*x1; run; data te; set neuralnt.ecc2dte; x11=x1**2; x22=x2**2; x12=x1*x2; x111=x1**3; x222=x2**3; 19 x112=x1**2*x2; x221=x2**2*x1; run; proc reg data=a outest=betas; model y1=x1 x2 x11 x22 x12 x111 x222 x112 x221; quit; proc score data=te type=parms scores=betas out=ste; var x1 x2 x11 x22 x12 x111 x222 x112 x221; run; data ste; set ste; r_y1=model1-y1; run; proc g3d data=ste; plot x1*x2=model1 / rotate=315; plot x1*x2=r_y1 / rotate=315 zmin=-50 zmax=50 zticknum=5; run; quit; 20 These multivariate polynomials are apparently lack of fitting! Method 3: Neural Network Modeling 1. Input Data Source node (top): 21 Select the ECC2D data In the variables tab, change the model role of Y1 to target Change the model role of all other variables except X1 and X2 to rejected 2. Input Data Source node (bottom): Select the ECC2DTE data In the Data tab, set the role to score 3. Score node: Select the button to apply training data score code to score data set 4. SAS Code node: Type in the following program proc g3d data=&_score; plot x1*x2=p_y1 /rotate=315; run; 5. Run the flow from the Score node. 22 23