Testing safety-critical software systems
advertisement

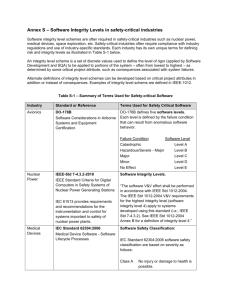
Testing safety-critical software systems Quality Assurance and Testing G53QAT Coursework report Written by: Marcos Mainar Lalmolda Date: 26/11/2009 CONTENTS Page Introduction 1 1. Safety critical standards 2 2. Programming features and languages 3 3. Approaches on designing safety-critical software systems 4 4. Testing safety-critical software systems 6 Conclusion 8 Further information – useful links and resources 9 List of references 10 1. Introduction A safety-critical software system could be defined as any system whose failure or malfunction can severely harm people's lives, environment or equipment. These kinds of risks are managed using techniques of safety engineering. [1] Safety-critical systems are widely used in various different fields such as medicine, nuclear engineering, transport, aviation, aerospace, civil engineering, industrial simulation, process control, military devices, telecommunications, infrastructures, etc. Safety-critical systems consist of hardware equipment and software and both of them have to be secure in order to ensure that the whole system is fully secure. However, in this paper, we will limit our scope to the software component of the systems. It is necessary to mention that safety-critical software is a highly complex topic which cannot be covered in high detail in this paper. For this reason, the aim of this paper is to provide a brief overview of safety-critical software systems and describe the main techniques or approaches used to design and test these kinds of systems. In this paper, we consider the broader notion of testing which comprises all the development cycle of a software product without limiting the scope of testing only to the testing of code. This paper first introduces standards used and applied in different fields when developing safety-critical systems. The next section focuses on the programming features and languages recommended and not for developing safety-critical software systems. The paper then will go on to describe different approaches on designing safety-critical software systems. Two main approaches will be considered. Finally, it will then outline the main techniques used to test these kinds of particular systems. Throughout the paper, examples of tools used to test real systems as well as companies or institutions using the techniques mentioned will be provided. “There are three basic approaches to achieving reliability [of safety-critical systems] – 1) Testing – lots of it; 2) Software fault tolerance; and 3) Fault avoidance – by formal specification and verification, automatic program synthesis and reusable modules” [Lawren 92]. 2. Safety-critical standards Industries have developed a number of different standards to deal with the development of safety-critical systems. For instance, we can find standards in medicine, to develop medical device software, in nuclear engineering, to develop nuclear power control stations software, in transport, to develop software for railway control, in aviation, etc. In general, every field which uses safety-critical systems has its own standards to handle the development of the systems they need ([2] and [3]). Standards for safety critical software have been classified on a scale of 5 levels of safety integrity: 4 is very high, while 0 is a system which not safety related. Formal mathematical methods are recommended by most standards at integrity level of 4 whereas not required at levels 0 or 1. Standards are legal and regulatory requirements help in the design of safetycritical software systems as they make the designers follow the requirements. Standards are a fundamental issue as they allow non experts to learn from experiences and knowledge from experts in a formal way and they are what really makes software engineering establish, advance and progress as an engineering. 3. Programming features and languages When designing a safety-critical software system, the general principle applied is to try to keep the system as simple as possible. This principle, of course, extends to the decision of which programming language is going to be used to code the system. In most modern programming languages there are some particular features which could cause problems and therefore should be avoided for safety-critical software systems. IPL, a leading supplier of software testing products, recommends avoiding the following aspects [4]: Pointers and dynamic memory allocation/deallocation. Unstructured programming: use of gotos. Variant data. Multiple entry and exit points to loops, blocks, procedures and functions. Implicit declaration and implicit initialisation. Procedural parameters. Recursion. Concurrency and interrupts. On the other hand, other programming features which provide reliability and are less likely to lead to errors are: Strong typing. Runtime constraint checking. Parameter checking. And, in general, programming languages well structured in blocks and which force modular programming. Taking into account the previous recommendations, we can easily think of some programming languages totally not recommendable to use to develop safety-critical software systems. For instance, C should be avoided for this particular task. Among the programming languages with the good features required mentioned above, Ada stands out as one of the most reliable and secure, however, as none programming language is perfect, the common approach is to use a small subset of it in order to avoid the risky features and make the most of the reliable ones. The Ada subset most commonly used for safety-critical software systems is called SPARK. 4. Approaches on designing safety-critical software systems Although there are many different approaches on designing safety-critical software systems, in this paper two main approaches will be considered and described. The basic idea when designing safety-critical software systems is to identify hazards as early as possible in the development life-cycle and try to reduce them as much as possible to an acceptable level. The first approach considered is to formally prove that the system does not contain errors by construction by means of formal methods. Formal methods are mathematical techniques and tools used to specify, design and verify software systems. Specifications are written as wellformed statements using logic mathematical language and formal proves are logic deductions using rules of inference. [5] and [6] However, using formal methods for large scale systems is fairly complicated and timeconsuming and has big problems such as human introducing errors in the specification and proves. As F.P. Brooks wisely remembered us in his No Silver Bullet article in 1987 [7], “program verification does not mean error-proof programs […]. Mathematical proofs can also be faulty. So whereas verification might reduce the program-testing load, it cannot eliminate it.” It is also almost impossible to formally prove everything used to develop the system such as the compiler, the operating system in which the system will ultimately operate and in general every underlying program used to build the target critical system. That makes necessary the use of specialised tools to help with formal specifications and proves. There are already some tools for that but they are not completely satisfactory up to date and it remains as a developing task. For small systems, where formal specifications and proves are easier to deal with, the approach can be very successful. The technique used to overcome problems with large scale systems is to try to separate the critical functionality of the system from the other non-critical parts. This way of using components with different safety integrity levels works well providing it is proved that the non-critical components cannot affect the high integrity ones or the whole system. In “Specifying software: a hands-on introduction”, R.D. Tennent [8] gives us an example of formal methods applied to a real case with successful results. “The program used to control the NASA space shuttle is a significant example of software whose development has been based on specifications and formal methods. […] As of March 1997 the program was some 420,000 lines long. The specifications for all parts of the program filled some 40,000 pages. To implement a change in the navigation software involving less than 2% of the code, some 2,500 pages of specifications were produced before a single line of code was changed. Their approach has been outstandingly successful. The developers found 85% of all coding errors before formal testing began, and 99.9% before delivery of the program to NASA. Only one defect has been discovered in each of the last three versions. In the last 11 versions of the program, the total defect count is only 17, an average of fewer than 0.004 defects per 1,000 lines of code.” The second approach is based on assuming that errors exist and the main aim will be to design prevention and recovery mechanisms in order to avoid hazards or risks caused by the system. These mechanisms will go from small parts of the code such as control errors inside procedures and functions, through all the software and ending on the whole system. This prevention and recovery mechanisms are based sometimes on redundancy approaches which mean replicating the critical parts of the system. For instance, it is common to use redundancy techniques systems in aircrafts where some parts of the control system may be triplicated [9]. An example of redundancy focusing only in the software part of a critical-system is the N-version programming technique also known as multi-version programming. In this approach, separate groups develop independent versions of the same system specifications. Then, the outputs are tested to check that they match in the different versions. However, this is not infallible as the errors could have been introduced in the development of the specifications and also because different versions may coincide in errors. 5. Testing safety-critical software systems In the process of verifying safety-critical software systems, the same techniques applied to typical software systems are still used, as well as special techniques conceived to minimise risks and hazards. The techniques are obviously applied in a more formal and rigorous way than in typical systems. Independent verification is usually required in those systems by means of a separate team within the overall project structure or a verification team supplied by an external company who may not ever meet the development team, depending on the criticality of the system. In this section, we have to remember and empathise that when testing software at different stages of its development, tests are always performed to verify correct behaviour against specifications, not against observed behaviour. For this reason, design of test cases for coding, should be done before coding the software system. Otherwise, software developers are tempted to design test cases for the behaviour of the system which they already known, rather than for the specified behaviour. [10] Some well-known techniques used to generate test cases to test these kinds of systems are white box and black box testing and reviews. However, they are taken to a further level of detail than with typical systems. For instance, according to IPL, reviews become more formal including techniques such as detailed walkthroughs of even the lowest level of design and also the scope of reviews is extended to include safety criteria. If formal mathematical methods have been used during the specification and design, then formal mathematical proof is a verification activity indeed. To give a real example, Hewlett-Packard generates test cases using white box and black box techniques to test their patient monitors of the HP Omni Care Family. [11] Complex static analysis techniques with control and data flow analysis as well as checking that the source code is consistent with a formal mathematical specification are also used. Tools such as SPARK Examiner are available for that [12]. Dynamic analysis testing and dynamic coverage analysis are also performed using known techniques such as equivalence partitioning, boundary value analysis and structural testing. IPL has developed tools such as AdaTEST [13] and Cantata [14] to give support for dynamic testing and dynamic coverage to the levels of functionality required by standards for safety-critical software. Any tools used to verify and test safety-critical software systems have to be developed in the same formal way as the systems they will test. For instance, again with the example of the HP patient monitors, in [6] they explain how in their validation phase, the test tool is validated against its specifications and also the most up-to-date revision of the patient monitor under development is used as a test bed for the tool's validation. They point at us the inversion of roles: the product is used to test the test tool! Their experience shows that this is the most fruitful period for finding bugs in both the tool and the product. Then they create a regression package for future changes. Considering now some of the specific techniques from safety engineering to test and verify safety-critical software systems, we can name a range of them such as probabilistic risk assessment, a method which combines failure modes and effect analysis (FMEA) with fault trees analysis (FTA), also failure modes, effects and criticality analysis (FMECA), an extension of the former FMEA, hazard and operability analysis (HAZOP), hazard and risk analysis and finally tools such as cause and effect diagrams (also known as fishbone diagrams). The main idea behind all these techniques is the same. We are going to describe the idea considering the point of view of probabilistic risk assessment. Then, we will briefly explain FMEA and FTA which are used in PRA. The first step in PRA is to perform a preliminary hazard analysis to determine which hazards can affect system safety. Then, the severity of each possible adverse consequence is calculated. It can be classified as catastrophic, hazardous, major, minor or not safety related. The probability of each possible consequence to occur is also calculated next. We can classify them in probable, remote, extremely remote and extremely improbable. Assessment of risks is made by combining both the severity of consequences with the probability of occurrence (in a matrix). For this evaluation we use different risk criteria like riskcost trade-offs, risk benefit of technological options, etc. Risks that fall into the unacceptable category (e.g.: high severity and high probability), that is to say, are unacceptable, must be mitigated by some means such as safeguards, redundancy, prevention and recovery mechanisms, etc., to reduce the level of safety risk. Probabilistic risk assessment also uses tools such as cause and effect diagrams [15]. For instance, HP applies these techniques to their patient monitors naming it as risk and hazard analysis and they consider it to be a grey box method. Failure modes and effect analysis (FMEA) is a procedure for analysis of potential failures within a system for classification by severity or determination of the effect of these failures on the system. Failure modes can be defined as any errors or defects in a process, design or item, especially those that affect the customer and can be potential or actual. Effects analysis refers to studying the consequences of these failures. Failure modes, effects and criticality analysis (FMECA) is an extension to this procedure, which includes criticality analysis used to chart the probability of failures against the severity of their consequences. Fault trees analysis is a graphical technique that provides a systematic description of the combinations of possible occurrences in a system which can result in an undesirable outcome (failure). An undesired effect is taken as the root of a tree of logic. Each situation that could cause that effect is added to the tree as a series of logic expressions. Events are labelled with actual numbers about failure probabilities. The probability of the top level event can be determined using mathematical techniques [16]. Here, we can see an example of a FTA: *From http://syque.com/quality_tools/toolbook/FTA/how.htm 6. Conclusion In this paper, a basic overview of safety-critical software systems has been given. They were first defined and some standards to cope with their development were named. Programming features and languages related to these kinds of systems have also been mentioned. Then, the two main approaches used when designing safety-critical software were explained. Finally, some techniques used to test safety-critical software have been described, both general techniques also used to test typical software systems and special techniques from safety engineering aimed at safety-critical software. The main idea behind the testing techniques mentioned is to reduce risks of implementation errors. Throughout this paper, it has been showed that safety-critical software systems is a very complex topic. It is this complexity and their relevance in our nowadays society what makes safety-critical systems development to require huge efforts both in time and budget. The key to the success of any software development, critical or not, are the people in charge of it. They need to have enough training and experience. Both of them become absolutely essential in safety-critical software development. IPL Company states that [4] “Above all, the best way to minimise risk, both to safety, reliability and to the timescale of a software development project, is to keep it simple.” We have to keep in mind the philosophy behind Occam's razor and apply it to software development. 7. Further information – useful links and resources In this section we provide a set of links and resources which may interest readers. The World Wide Web Virtual Library: Safety-Critical Systems http://en.wikipedia.org/wiki/SPARK_%28programming_language%29 http://www.praxis-his.com/sparkada/ Interesting article about the NASA space shuttle software group: http://www.fastcompany.com/magazine/06/writestuff.html?page=0%2C1 Testing safety-critical software with AdaTEST, Linux Journal http://www.linuxjournal.com/article/5965 Safety critical systems – Formal methods wiki. http://formalmethods.wikia.com/wiki/Safety-critical_systems An Investigation on the Therac-25 Accidents: http://courses.cs.vt.edu/~cs3604/lib/Therac_25/Therac_1.html 8. References [1] Wikipedia, Life-critical system or safety-critical system definition. Available at: http://en.wikipedia.org/wiki/Life-critical_system [2] Software Engineering Process Technology (SEPT), Software Safety Standards. Available at: http://www.12207.com/safety.htm [3] Bill St. Clair, Software securing critical systems, VME and Critical Systems, 2006, OpenSystems Publishing. [4] IPL Information Processing Ltd, An Introduction to Safety Critical Systems, Testing Papers. Available at (e-mail required): http://www.ipl.com/include/download/CookieRequestPage.php?FileID=p0820 [5] NASA LaRC Formal Methods Program: What is Formal Methods? Available at: http://shemesh.larc.nasa.gov/fm/fm-what.html [6] Wikipedia, Formal methods Available at: http://en.wikipedia.org/wiki/Formal_methods [7] Frederick P. Brooks, Jr. , No Silver Bullet: Essence and Accidents of Software Engineering, 1986. [8] R.D. Tennet, Specifying Software: A Hands-On Introduction, 2002. [9] Wikipedia, Redundancy (Engineering). Available at: http://en.wikipedia.org/wiki/Redundancy_%28engineering%29 [10] IPL Information Processing Ltd, An Introduction to Software Testing, Testing Papers, Available at (e-mail required): http://www.ipl.com/include/download/CookieRequestPage.php?FileID=p0826 [11] Evangelos Nikolaropoulos, Testing safety-critical software, Hewlett-Packard Journal, June 1997. Available at: http://findarticles.com/p/articles/mi_m0HPJ/is_n3_v48/ai_19540814/ [12] Praxis His Integrity Systems, The SPARK Examiner, description of the analysis performed. Available at: http://www.praxis-his.com/sparkada/examiner.asp [13] AdaTEST 95, IPL. Major features and Technical Brief. Available at: http://www.ipl.com/products/tools/pt600.uk.php [14] IPL Information Processing Ltd, Cantata, Major features Available at: http://www.ipl.com/products/tools/pt400.uk.php [15] Wikipedia, Probabilistic Risk Assessment. Available at: http://en.wikipedia.org/wiki/Probabilistic_Risk_Assessment [16] Fault trees analysis how to understand it. Available at: http://syque.com/quality_tools/toolbook/FTA/how.htm