EMM Beta
advertisement

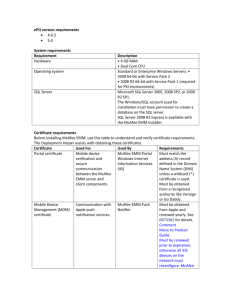
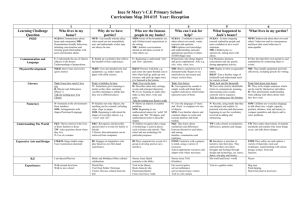
EMM Beta Release Date March 29, 2008 General Information: This is a Java implementation of the Extensible Markov Model (EMM) spatiotemporal modeling technique [3]. It consists of code to create an EMM (using a training dataset), and then uses the created EMM model for some application. The Beta version only supports anomaly (rare event) detection. General EMM information is available online at http://www.engr.smu.edu/cse/dbgroup/emm.html [1] and in published articles [3]. All code has been developed by Jie Huang and Charlie Isaksson. The project implementation is JAVA and the environment programmed in is NetBeans IDE 6.0.1. However other IDE can be used. The following discussions all assume that NetBeans is used. You can download NetBeans from: http://www.netbeans.org/. If you don't have JDK installed on your system, then you can download (JDK 6 Update 5 with NetBeans 6.0.1.) from the Sun home page : http://java.sun.com/javase/downloads/index.jsp . From this link you may choose to download only JDK or a bundle of JDK and NetBeans. Installation: The project is delivered compressed with tar.gz. To uncompress in a Unix environment use:tar xfz JEMM.tar.gz In a Windows environment, you can use WinZip or other software. Extract all files. At this point a directory entitled JEMM is created. There are five subdirectories: build: Executables (including classes) dist: Created by NetBeans (jar files) nbproject: Created by NetBeans src: Java source files test: Created by NetBeans . Execution: 1. When NetBeans is started, begin execution of EMM by opening an existing project in the File link. Select the location of the JEMM folder created when the download file was uncompressed. At this point you will see JEMM listed as an existing project. Future executions can then simply use this project. 2. At this point all of the EMM libraries and code are inserted into the IDE environment. 3. Begin EMM execution by either clicking on the green arrow or on Run Main project tab on the NetBeans toolbar. Each EMM run creates a new EMM from a supplied input dataset and executes the chosen application against that EMM. The EMMBeta version executes only the anomaly detection application. EMM execution is performed through a GUI interface as seen in Figure 1. Two tabs can be found in the GUI: The EMM tab is used to setup and run EMM. The Visualization tab is used to see the results of running an EMM application (anomaly detection). 2/16/2016 EMM Beta 1 Figure 1. EMM GUI Parameters: Prior to running EMM, the following input parameters must be supplied: Similarity Measure: You have the option to choose the similarity measurements: Cosine, Dice, Jaccard, and Overlap [2]. This is used to determine the similarity between an input vector found in the input dataset to all existing clusters. The current implementation assumes that clusters are represented by centroids of the vectors placed in that cluster. Threshold: Once you have chosen the similarity metric the threshold must be selected. A default threshold is set to 0.8, however any value from 0 to 1 can be set. The threshold value is used to determine whether the input vector should be placed in a cluster or not. Using a simple nearest neighbor (in this implementation) approach, the centroid of the closest existing cluster is found. If the similarity is less than the threshold then the input vector is added to the cluster. If it isn’t, then a new cluster is created with the input vector as the starting centroid. Input File Options: There are three options for invoking the input files (training and testing): Use Training Set: If this option is clicked, an EMM is constructed using the indicated dataset, but no application on that EMM is performed. Supplied Test Set: With this option two separated input files are supplied. The first is for training and the second is for testing. Once the EMM is constructed using the training dataset, the testing automatically begins using the indicated application. During this testing phase, learning of the EMM continues. Percentage Split: Only one dataset is supplied and is divided into a training and test set based on the split percentage indicated. The entered value is the amount used for training. The remaining part is then used for testing. The input dataset must be indicated by clicking on the Set Train 2/16/2016 EMM Beta 2 button. The name of the file(s) to be used are entered by clicking on the Set Train (and Set Test) buttons. Based on the chosen input file option, the needed input file buttons are highlighted. Only files from the JEMM directory (or subdirectories can be used at this time). Input File Format: The input file is assumed to be a simple text file. Each input vector is represented by one line of input. The individual vector values are numeric and separated by TABS. Each vector is separated by a LINEFEED. An attempt to execute with an invalid file or one not found inside the JEMM directory will result in an error message “FileNotFoundException”. Execution Output: With a successful EMM run, the output is shown in the EMM Output panel. A sample output is shown in Figure 2. The “== New states, training mode ==“ is followed by a list of all states created. States are labeled with integers assigned in ascending numeric order. (State 1 is always assumed to exist by default.) The “== EMM Transitions ==“ heading is followed by a list of state transitions with the corresponding count for each. == New states, training mode == new state: 2 new state: 3 new state: 4 new state: 5 new state: 6 new state: 7 == EMM Transitions == 5:2 1:2 6:4 2:6 2:3 2:1 3:4 4:5 5:7 1 2 1 1 1 1 1 2 1 Figure 2. EMM Output When EMM is executed, a trace of the run is produced on the bottom panel of the NetBeans execution screen. This output labeled (Output – JEMM(run)) contains a trace of execution. A sample run output is shown in Figure 3. The first five lines here trace the execution sequence including a timestamp. The last two lines indicate that a file not found error has occurred. 2/16/2016 EMM Beta 3 init: deps-jar: compile: run: Mar 28, 2008 1:12:49 PM jemm.JEMMView buStartMouseClicked SEVERE: null java.io.FileNotFoundException: MaggiDataset.txt (The system cannot find the file specified) Figure 3. Sample EMM Trace The screen created with the Visualization tab is shown in Figure 4. This screen is divided into two panels. The top panel shows the anomaly input states. An overview of the anomaly detection algorithm can be found in [3]. The bottom panel shows a synopsis of the EMM structure which exists at the end of the EMM run. Shown is the centroid of each EMM node (in cluster number order) followed by the count of input states placed in this node. Figure 4. Visualization Screen 2/16/2016 EMM Beta 4 Output Files: EMM output files are placed in the JEMM folder. Each run creates three output files: xxx_link – Text file showing the transitions and their counts. (Same as that seen in Figure 2.) xxx_numOfState – Text file showing states and their counts. xxx_state – Text file showing centroids for all clusters (states) and their counts. (Same as that in Figure 4.) Here xxx is replaced with either Dice, Jaccard, or Cosine based on the similarity measure used for that run. Example: A simple example of EMM creation can be found in [3]. This sample dataset is found in the JEMM directory under the name of Maggidataset.txt and is shown in Figure 5. Here each input vector consists of 7 numeric values. There are 12 input states. The EMM which is created using this input (Jaccard, 0.8) is shown in Figure 4. This steps in creation of this EMM are shown as Figure 2 in [3]. 20 20 40 15 40 5 0 20 45 15 5 10 50 80 30 60 15 5 35 60 40 20 45 30 100 50 75 30 25 40 55 30 15 40 55 10 30 20 20 30 10 35 2 11 18 40 10 4 25 10 30 10 35 10 1 20 20 10 10 15 4 10 20 10 40 5 3 15 20 10 15 15 10 10 25 15 9 4 5 10 15 14 0 10 Figure 5: Sample Input File (Maggidataset.txt) Sample Input Files: There are several other sample output files in addition to the Maggidataset.txt. These include those based on DARPA Intrusion Detection datasets as reported in [4]: normalDataDARPA1999.txt: Contains training data-set for one weeks without any network attacks. normalDataDARPA1999_AND_2000DDoS.txt: Contains training data-set for two weeks without any network attacks 2000Attack.txt: Contains testing data-set with network attacks. Error Messages: Contact: The application is still under development. Please contact Charlie Isaksson at charliei@engr.smu.edu if you have any questions. The overall EMM project is under the direction of Professor Margaret H. Dunham who can be contacted at mhd@engr.smu.edu . 2/16/2016 EMM Beta 5 EMM References: [1] Dunham, Margaret H., EMM Web Page, http://www.engr.smu.edu/cse/dbgroup/emm.html . [2] Dunham, Margaret H., Data Mining Introductory and Advanced Topics, Prentice Hall, 2003. [3] Jie Huang, Yu Meng, and Margaret H. Dunham, “Extensible Markov Model,” Proceedings IEEE ICDM Conference, November 2004, pp 371-374. [4] Charlie Isaksson, Yu Meng, and Margaret H. Dunham, “Risk Leveling of Network Traffic Anomalies,” International Journal of Computer Science and Network Security, Vol 6, No 6, June 2006, pp 258-265. 2/16/2016 EMM Beta 6