This is an experimental study in which eligible people are randomly
advertisement

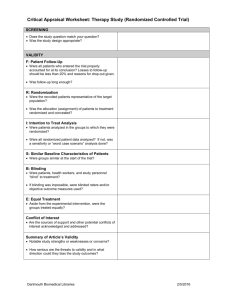
Critical Appraisal of Quantitative Research What is Critical Appraisal & Why is it Important Health professionals are faced with an overwhelming quantity of information and from this they must be able to sift the important and relevant findings in order to apply these to their practice. Critical appraisal is the process of systematically weighing up the quality and relevance of research to see how useful it is in decision making. Critical appraisal is the balanced assessment of benefits and strengths of research against its flaws and weaknesses. Critical appraisal skills can help you in making informed decisions, in evidencing proposals and researching for reports. Critical Appraisal is a skill and it needs to be practised by all health professionals as part of their work Levels of Evidence There are different types of evidence available to answer clinical queries. These can be arranged as a hierarchy in a pyramid as shown in below: Systematic Review Randomised Control Trial Cohort Study Case Control Study Case Series & Case Reports Expert Opinion Anecdotal The pyramid is a list of studies which provide evidence with anecdotal evidence at the bottom providing the least reliable evidence and a systematic review at the top providing the strongest evidence. As you move up the pyramid the amount of available literature decreases, but its relevance to the clinical setting increases. You may not always find the best level of evidence (eg: a systematic review) to answer your question. In the absence of the best evidence, you then need to consider moving down the pyramid to other types of studies. More detailed levels of evidence tables can be found at: www.cebm.net (under More EBM tools) Systematic reviews and meta-analyses These review, appraise and summarise all the available evidence on a particular topic or question. A review is described as systematic if the authors have followed a systematic approach in producing it. Most systematic reviews are based on randomised controlled trials. Meta analysis uses statistical techniques to combine the results of several studies into one, so providing results with a greater statistical significance. Randomised, controlled clinical trial This is an experimental study in which eligible people are randomly allocated into two groups: an intervention group and a control group. The intervention group receives the intervention under consideration and control group receives an alternative. The results are assessed by comparing outcomes in each group. Adapted from: Cochrane Collaboration glossary (online) www.cochrane.org/glossary/ (accessed 12/4/12) What is randomisation and why is it important? Method analogous to tossing a coin to assign patients to treatment groups (the experimental treatment is assigned if the coin lands heads and a conventional, control or placebo treatment is given if the coin lands tails). This is usually done by using a computer that generates a list of random numbers, which can then be used to generate a treatment allocation list. The reason for using randomisation is that it avoids any possibility of selection bias in a trial. The test that randomisation has been successful is that different treatment groups have the same characteristics at baseline. For instance, there should be the same number of men and women, or older or younger people, or different degrees of disease severity. Bandolier glossary (online). http://www.medicine.ox.ac.uk/bandolier/booth/glossary/RCT.html (accessed 12/04/12) Blinding A process of masking, or hiding, which participant has been allocated to which arm of the trial. Single blinding - the participant doesn’t know which arm of the trial s/he has been allocated to. Double blinding - neither the trial administrator nor the participant knows which arm of the trial the participant has been allocated to. Triple blinding - neither the participant, trial administrator nor researcher knows which arm of the trial the participant has been allocated to. Cohort studies (prospective studies) These studies follow groups of people who are selected on the basis of their exposure to a particular agent (eg: vaccine, drug) over a period of time, which can be years. They are compared with another group who are not affected by the condition or treatment. These studies are not as reliable as randomised controlled clinical trials as the two groups may differ in a way other than the variable being studied. One of the most famous cohort studies concerned the smoking habits of 40,000 British doctors in which 4 cohorts (non-smokers, light, moderate and heavy smokers) were followed up for 40 years. The results constitute one of the first and strongest pieces of evidence on the dangers of smoking. Clinical questions that should be examined by a cohort include: o Does smoking cause lung cancer? o What happens to infants who have been born very prematurely in terms of subsequent physical development? Case control studies (retrospective studies) These are studies in which patients who already have a specific condition are compared with people who do not. These types of studies are often less reliable than randomized controlled trials and cohort studies because showing a statistical relationship does not mean than one factor necessarily caused the other. Clinical questions that should be examined by a case-control study include: o Does whooping cough vaccine cause brain damage? o Do overhead power cables cause leukaemia? Case series and case reports These consist of collections of reports on the treatment of individual patients or a report on a single patient. Because they are reports of cases and use no control groups with which to compare outcomes, they have no statistical validity. Expert opinion This is a consensus of experience and opinions between professionals. Anecdotal evidence This is something overheard somewhere. Statistics Power Calculation A sample size calculation designed to highlight the likelihood of detecting a true difference between outcomes in the control and intervention groups. They allow researchers to work out how large a sample they will need in order to have a moderate, high or very high chance of detecting a true difference between the groups. It is common for studies to stipulate a power of between 80% and 90%. Greenhalgh, T. (2010). How to read a paper: the basics of evidence based medicine. 4th edn. London: BMJ Books. Probability (p value) The p value gives a measure of how likely it is that any differences between the control and experimental groups are due to chance alone. P values can range from 0 (impossible for the event to happen by chance) to 1 (the event will certainly happen). If p=0.001 the likelihood of a result happening by chance is extremely low: 1 in 1000 If p=0.05 it is fairly unlikely that the result happened by chance: 1 in 20 If p=0.5 it is fairly likely that the result happened by chance: 1 in 2 If p=0.75 it is very likely that the result happened by chance: 3 in 4 Results where p is less than 0.05 are often said to be “significant.” This is just an arbitrary figure as in 1 in 20 cases, the results could be due to chance. Confidence Intervals These are used in the same way as p values in assessing the effects of chance but can give you more information. Any result obtained in a sample of patients can only give an estimate of the result which would be obtained in the whole population. The real value will not be known, but the confidence interval can show the size of the likely variation from the true figure. A 95% confidence interval means that there is a 95% chance that the true result lies within the range specified. (This is equivalent t o a p value of 0.05). The larger the trial the narrower the confidence interval, and therefore the more likely the result is to be definitive. In an odds ratio diagram if the confidence interval crosses the line of zero difference (no effect) it can mean either that there is no significant difference between the treatments and/or that the sample size was too small to allow us to be confident where the true result lies. Intention-to-treat analysis An intention-to-treat analysis is one in which all the participants in a trial are analysed according to the intervention to which they were allocated, whether they received it or not (for whatever reason). Intention-to-treat analyses are favoured in assessments of effectiveness as they reflect the non-compliance and treatment changes that are likely to occur when the intervention is used in practice and because of the risk of bias when participants are excluded from the analysis. Adapted from: Cochrane Collaboration glossary (online) www.cochrane.org/glossary/ (accessed 12/4/12) Bias Anything which erroneously influences the conclusions about groups and distorts comparisons. In RCTs sources of bias to look for are: Selection bias: systematic differences in the groups being compared caused by incomplete randomisation (allocation stage). Performance bias: systematic differences in the care provided apart from the intervention being evaluated (intervention stage). Exclusion bias: systematic differences in withdrawals / exclusions of people from the trial (follow up stage). Detection bias: systematic differences in the ways outcomes are assessed (outcomes stage). Greenhalgh, T. (2010). How to read a paper: the basics of evidence based medicine. 4th edn. London: BMJ Books. Risks and odds When talking about the chance of something happening, e.g. death, hip fracture, we can talk about: • risk and relative risk • odds and odds ratio. or Risks. A proportion. Numerator / Denominator. Odds. A ratio. Numerator / (Denominator - Numerator). Outcome event Total Yes No Experimental group a b a+b Control group c d c+d a+c b+d a+b+c+d Total Risk is: a proportion. Risk of event in expt. group = a = EER (Experimental Event Rate). a+b Risk of event in control group = c = CER (Control Event Rate). c+d Relative risk (RR) is: a ratio of proportions. RR = EER CER. A measure of the chance of the event occurring in the experimental group relative to it occurring in the control group. RR <1 if group represented in the numerator is at lower “risk” of the event. Want this if the event is a bad outcome e.g. death. RR >1 if group represented in numerator is at greater “risk” of the event. Want this if the event is a good outcome e.g. smoking cessation. Relative risk reduction The difference in the risk of the event between the control and experimental groups, relative to the control group. RRR = (CER - EER)/CER. Use this term if the event is bad e.g. death. An alternative way of calculating the relative risk reduction is to use the relative risk: RRR = (1 - RR). Use this term if the event is bad e.g. death. Absolute Risk Reduction The absolute difference between the risk of the event in the control and experimental groups. ARR = CER - EER. ARR can be used to calculate the number needed to treat (NNT). Use this term if the event is bad e.g. death. Relative benefit increase The difference in the risk of the event between the control and experimental groups, relative to the control group. RBI = (CER - EER)/CER. Use this term if the event is good e.g. smoking cessation. An alternative way of calculating the relative benefit increase is to use the relative risk: RBI = (1 - RR). Use this term if the event is good e.g. smoking cessation. Absolute benefit increase The absolute difference between the risk of the event in the control and experimental groups. ABI = CER - EER. ABI can be used to calculate the number needed to treat (NNT). Use this term if the event is good e.g. smoking cessation. experimental groups. Number needed to treat The number of patients who needed to be treated to prevent the occurrence of one adverse event (e.g. complication, death) or promote the occurrence of one beneficial event (e.g. cessation of smoking). NNT = 1/ARR. Odds is: a ratio. Odds of event in expt. group = a b. Odds of event in control group = c d. Odds ratio (OR) is: a ratio of ratios. OR = ad bc. Dr Kate O'Donnell, General Practice & Primary Care, University of Glasgow.