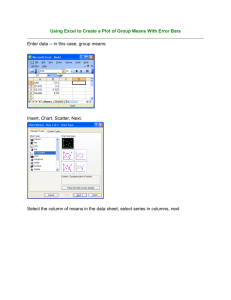
6.6 Discriminant analysis
advertisement

6. Discriminant Analysis: (i) Two populations: 1. Separation: Suppose we have two populations. Let X 1 , X 2 ,, X n 1 be the n1 observations from population 1 and let X n 1 , X n 2 ,, X n n 1 observations from 1 population2. X 1 , X 2 , , X n1 , X n1 1 , X n1 2 , , X n1 n2 are p 1 1 2 Note be n 2 that vectors. The Fisher’s discriminant method is to project these p 1 vectors to the real values via a linear function l ( X ) a t X and try to separate the two populations as much as possible, where a is some p 1 vector. Fisher’s discriminant method is as follows: Find the vector â maximizing the separation function S (a) , S (a) n1 n2 n1 where Y1 Yi i 1 n1 , Y2 Y i n1 1 n1 i n2 Y1 Y2 , SY , S Y2 (Y i 1 i Y1 ) 2 n1 n2 (Y i n1 1 n1 n2 2 i Y2 ) 2 , and Yi a t X i , i 1,2,, n1 n2 Intuition of Fisher’s discriminant method: Rp X 1 , X 2 , , X n1 X n1 1 , X n1 2 , , X n1 n2 l ( X ) aˆ t X R Yn1 1 , Yn1 2 , , Yn1 n2 Y1 , Y2 , , Yn1 1 Intuitively, As far as possible by finding â Y Y2 measures the difference S (a) 1 SY between the transformed means Y1 Y2 relative to the sample standard deviation SY . If the transformed observations Y1 , Y2 , , Yn1 and Yn1 1 , Yn1 2 , , Yn1 n2 are completely separated, Y1 Y2 should be large as the random variation of the transformed data reflected by SY is also considered. Important result: The vector â maximizing the separation S (a) Y1 Y2 SY is the form of 1 X 1 X 2 S pooled , where X X 1 X i X 1 n1 S pooled n1 1S1 n2 1S 2 n1 n2 2 n1 n2 S2 X i n1 1 , S1 i 1 t i , n1 1 X 2 X i X 2 t i n2 1 , and where n1 n2 n1 X1 X i 1 n1 i and X 2 2 X i n1 1 n2 i . Justification: n1 Xi Yi a X i t i 1 i 1 i 1 Y1 a n n1 n1 1 n1 n1 t at X 1. Similarly, Y2 a t X 2 . Also, (Y Y ) a X n1 i 1 n1 2 i 1 t i 1 i n1 a X1 at X i at X1 at X i at X1 t 2 t i 1 n1 t a X i X 1 X i X 1 a a X i X 1 X i X 1 a . i 1 i 1 n1 t t t Similarly, n1 n2 Y Y 2 i i n1 1 2 n1 n2 t a X i X 2 X i X 2 a i n1 1 t Thus, Y n1 S Y2 i 1 i Y1 2 n1 n2 Y i n1 1 i Y2 2 n1 n2 2 n1 n2 n1 t t t a X i X 1 X i X 1 a a X i X 2 X i X 2 a i 1 i n1 1 n1 n2 2 t n1 n2 n1 t t X i X 1 X i X 1 X i X 2 X i X 2 i 1 i n1 1 at n1 n2 2 n 1S1 n2 1S 2 t at 1 a a S pooled a n1 n2 2 3 a Thus, Y1 Y2 a t X 1 X 2 S (a) SY a t S pooled a â can be found by solving the equation based on the first derivative of S (a ) , 2S pooled a S (a) X 1 X 2 1 t a X 1 X 2 0 3/ 2 a a t S pooled a a t S pooled a 2 Further simplification gives a t X 1 X 2 X1 X 2 t S pooled a . a S a pooled Multiplied by the inverse of the matrix S pooled on the two sides gives S Since 1 pooled a t X 1 X 2 X 1 X 2 t a , a S a pooled at ( X1 X 2 ) is a real number, a t S pooled a 1 X1 X 2 , aˆ cS pooled where c is some constant. 2. Classification: Suppose we have an observation X 0 . Then, based on the discriminant function l ( X ) aˆ t X we obtain, we can allocate this observation to some class. 4 Important result: Allocate X 0 to population 1 if 1 1 t 1 Yˆ0 aˆ t X 0 X 1 X 2 S pooled X 0 aˆ t ( X 1 X 2 ) (Y1 Y2 ) 2 2 = 1 1 X 1 X 2 t S pooled X 1 X 2 . 2 Otherwise, if 1 t 1 1 X 1 X 2 , then allocate X 0 to Yˆ0 ( X 1 X 2 ) t S pooled X 0 X 1 X 2 S pooled 2 population 2. Intuition of this result: Intuition of this result: X n1 1 , X n1 2 ,, X n1 n2 Rp X0 . . . . . X. .2 . . . . . . . . . . l( X ) at X l( X ) at X X 1 , X 2 ,, X n1 . . . . . .X.1.. .. .. . . . . . . l( X ) at X R Y2 Y1 Y2 2 Ŷ0 (population 2) If Ŷ0 is on the right hand side of Ŷ0 Y1 (population 1) Y1 Y2 (closer to Y1 ), then allocate 2 X 0 to population 1 and vice versa. Note: significant separation does not necessarily imply good classification. On the other hand, if the separation is not significant, the search for a useful classification rule will probably fruitless!! 5 (ii) Several populations (more than two populations): 1. Separation: Suppose there are k populations, X 1 , X 2 ,, X n1 : population 1 X n1 1 , X n1 2 ,, X n1 n2 : population 2 X n1 nk 1 1 ,, X nT : population k, n1 n2 nk nT . where Let X j be the sample mean for the population j, j 1, , k , and nT X X i 1 nT i . The sample between matrix k B n j ( X j X )( X j X )t j 1 Thus, a t Ba n j a t X j X X j X a n j a t X j a t X X tj a X t a k k t j 1 j 1 n j Y j Y , k 2 j 1 Yi a t X i , i 1, , nT , Y j is the mean for the j’th population, j 1, , k , n1 for example, Y1 Yi i 1 n1 nT and Y Y i i 1 nT . The sample within group matrix W is X n1 i 1 X 1 X i X 1 t i n1 n2 X i n1 1 X 2 X i X 2 t i 6 X nT i i n1 nk 1 1 X k X i X k . t Thus, a tWa a t X i X 1 X i X 1 a n1 a X nT t i 1 n1 n2 Yi Y1 n1 Y 2 i 1 Y2 i Y nT 2 i i n1 1 i n1 nk 1 1 X k X i X k a t t Yk . 2 i i n1 nk 1 1 Note: Y Y1 n1 t a Wa nT k i 1 2 i Y i n1 1 i Y2 Y nT 2 Yk 2 i i n1 nk 1 1 nT k the pooled estimate based on Y1 , Y2 , , Yn . T X n1 S pooled n1 n2 W nT k i 1 X 1 X i X 1 i X nT t i i n1 nk 1 1 X k X i X k t nT k the pooled estimate based on X 1 , X 2 ,, X nT . We now introduce Fisher’s linear discriminant method for several p Fisher’s discriminant method for several populations is as follows: Find the vector â1 maximizing the separation function n Y k S (a) t a Ba a tWa j 1 Y n1 i 1 i Y1 2 n1 n2 Y i n1 1 i j Y 2 j Y2 2 Y nT Yk , 2 i i n1 nk 1 1 subject to aˆ1t S pooled aˆ1 1. The linear combination aˆ1t X is called the sample first discriminant. Find the vector â 2 maximizing the separation function S (a ) subject to aˆ 2t S pooled aˆ 2 1 and aˆ 2t S pooled aˆ1 0 . 7 Find the vector â s maximizing the separation function S (a ) subject to aˆ st S pooled aˆ s 1 and aˆ st S pooled aˆl 0, l s. aˆ tj S pooled aˆ j is the estimate of Var(aˆ tj X ), j 1,, s. Note: aˆ tj S pooled aˆ l , j l. is the estimate of Cov(aˆ tj X , aˆ lt X ), j l. The condition aˆ tj S pooled aˆl 0 is similar to the condition given in the principal component analysis. Intuitively, S (a ) measures the difference among the transformed means reflected by n Y k j 1 j Y 2 j relative to the random variation of the transformed Y n1 data reflected by i i 1 Y1 2 n1 n2 Y i n1 1 i Y2 2 Y nT Yk . As the 2 i i n1 nk 1 1 transformed observations Y1 , Y2 ,, Yn1 ( population 1), Yn1 1 , Yn1 2 ,, Yn1 n2 ( population 2), , Yn1 nk 1 1 ,, YnT ( population k ) n Y k are separated, j 1 j Y 2 j should be large even as the random variation of the transformed data is taken into account. Important result: Let e1 , e2 ,, es corresponding be the orthonormal eigenvector of W to the eigenvalues 1 2 s 0. 1 / 2 1 / 2 1 / 2 1 aˆ j S pooled e j , j 1,, s, where S pooled S pooled S pooled . 8 1 2 BW 1 2 Then, 2. Classification: Fisher’s classification method for several populations is as follows: For an observation X 0 , Fisher’s classification procedure based on the first r s sample discriminants is to allocate X 0 to the population l if 2 2 j 2 t t j 2 ˆ ˆ ˆ ˆ Y Y a X X a X X Y Y j l j 0 l j 0 i j i , i l, r j 1 r j 1 r j 1 r j 1 where Yˆj aˆ tj X 0 , Yi j aˆ tj X i , j 1,, r; i 1,k Intuition of Fisher’s method: R p : population 1 X 1 population 2 X 2 l j ( X ) aˆ tj X , Y11 ,, Y1 r R : Yˆ r j 1 j Y1 j 2 X0 population k X k j 1,, r Yˆ1 ,, Yˆr Y21 ,, Y2r Yk1 ,, Ykr : the “total” square distance between the transformed X 0 ( Yˆ1 ,, Yˆr ) and the transformed mean of the population 1 ( Y11 ,, Y1 r ). Yˆ r j 1 j Y2 j 2 : the “total” square distance between the transformed X 0 ( Yˆ1 ,, Yˆr ) and the transformed mean of the population 2 ( Y21 ,, Y2r ). 9 Yˆ r j 1 Yk j j 2 : the “total” square distance between the transformed ( Yˆ1 ,, Yˆr ) X 0 and the transformed mean of the population k ( Yk1 ,, Ykr ). Yˆ r j 1 j Yl j Yˆ 2 r j 1 2 j Yi , i l , imply the total distance between the transformed X 0 and the transformed mean of the population l is smaller than the one between the one between the transformed X 0 and the transformed mean of the other populations. In some sense, X 0 is “closer” to the population l than to the other populations. Therefore, X 0 is allocated to the population l. 10