MWRreforecast
advertisement

Combined approaches for ensemble post-processing
Thomas Hopson and Joshua Hacker
National Center for Atmospheric Research, Boulder, CO
Abstract
Novel approaches to post-processing (calibrating) 2-m temperature forecasts are explored
with the ensemble reforecast data set published by the NOAA Earth Systems Laboratory
(Climate Analysis Branch). As in several previous studies, verification indicates that
post-processing the ensemble may be necessary to provide meaningful probabilistic
guidance to users. We apply a novel statistical correction approach by combining a
selection of statistical correction approaches used in the literature [e.g. logistic regression,
and quantile regression] under the general framework of quantile regression (QR) to
improve forecasts at specific probability intervals (as compared to fixed climatological
thresholds). One of the benefits of our approach is that no assumptions are required on
the form of the forecast probability distribution function to attain optimality, and we
ensure that resultant forecast skill is no worse than a forecast of either climatology or
persistence. Specifically, we focus on the following research question: a) the impact of
seasonality on (calibrated) ensemble skill; b) the impact of calibration data size on postprocessed forecast skill; c) the utility of ensemble dispersion information to condition
ensemble calibration; d) the benefits of blending logistic regression-derived ensembles
with QR in enhancing forecast skill; e) assessment of most beneficial forecast quantities
for post-processing. Results will be assessed using traditional (probabilistic) verification
measures as well as a new measure we introduce to examine the utility of the ensemble
spread as an estimator of forecast uncertainty.
Introduction
Two motivations for generating ensembles:
Non-Gaussian forecast PDF’s
Ensemble spread as a representation of forecast uncertainty. => our technique addresses
this
Benefits of post-processing:
-- Improvements in statistical accuracy, bias, and, reliability (e.g. reliability diagrams,
rank histograms; Hamill and Colucci 1997, 1998)
-- Improvements in discrimination and sharpness (e.g. rank probability score, ensemble
skill-spread relationship (Wilks, 2006)
=> forecast skill gains equivalent to significant NWP improvements
Statistical post-processing can improve not only statistical (unconditional) accuracy of
forecasts (as measured by reliability diagrams, rank histograms, etc), but also factors
more related to “conditional” forecast behavior (as measured by, say, RPS, skill-spread
relations,etc.)
-- inexpensive statistically-derived skill improvements can equate to significant NWP
developments (expensive) (Hamill reference?)
-- necessity of postprocessing: Application to point location => by definition must
improve ensemble dispersion
Background work: Hamill reforecast project
New approaches:
-- use whatever is available to improve forecasts => persistence
-- blend multiple calibration tools: QR, logistic regression
- Our focus is ensemble forecasts for probability intervals as compared to fixed
climatological thresholds (thus requiring interpolating LR calcs)
Quantile Regression (QR)
Introduced in 1978 (Koenker and Bassett, 1978), quantile regression (QR) is an
absolute error estimator that can conditionally fit specific quantiles of the regressand
distribution (beyond just the mean or median), which does not rely on parametric
assumptions of how either the regressand or residuals are distributed. And by virtue of
being an l1-method, the conditional fit is less sensitive to outliers than square error
estimators (Koenker and Portnoy 1997). See also Bremnes (2004) for an application of
QR to calibrating weather variable output. Specifically, let {yi} represent a set of
observations of the regressand y of interest, and {xi} an associated set of predictor values.
Analogous to standard linear regression, a linear function of x can be used to estimate to
a specific quantile q of y
n
q (xi ;) 0 k xik ri
(1)
k 0
with residuals ri yi q (xi ;) and (0,1) . However, instead of minimizing the
squared residuals as with standard linear regression, in QR a weighted iterative
minimization of {ri} is performed over :
n
n
min (ri ) arg min (yi q (xi ;))
i 1
(2)
i 1
with weighting function
u
u0
.
( 1)u u 0
(u)
(3)
In addition to the benefit of being less sensitive to outliers compared to standard
linear regression, QR optimally determines the relationship of a regressor set on specific
quantiles of the regressor, with no parametric assumptions. This point can be seen in
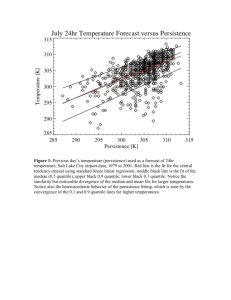
Figure 1 where, by way of example, we have applied Eqs. (1) – (3) for persistence
(previous day’s temperature) as a forecast of 24hr July temperature (Salt Lake City
airport 1979 to 2001; discussed below) for the 0.1, 0.5 (median), and 0.9 quantiles. The
red line is the fit for the central tendency (mean) using standard linear regression; the
middle black line is the fit of the median (q0.5); upper black line is for q0.9; and the lower
black for q0.1. Notice the similarity but noticeable divergence of the median and mean fits
for larger temperatures. Notice also the heteroscedastic behavior of the persistence QR
fitting, which is seen by the convergence of the 0.1 and 0.9 quantile lines for higher
temperatures. Physically, such behavior can be justified from higher temperatures being
typically associated with high pressure anomalies, which have longer persistence than
cold front passages.
Another powerful benefit of QR is that the cost function Eq (3) is precisely
associated with the creation of a flat rank histogram verification, which itself is a
necessary requirement for a calibrated ensemble forecast. Here, we implicitly define a
“calibrated ensemble” as one being equivalent to a random draw from an underlying (but
typically unknown) probability distribution function. This will be discussed further
below. In addition, although QR constrains the resultant quantile estimators to satisfying
this requirement, at the same time it also constrains the estimators to optimal “sharpness”
(Wilks 1995; i.e. creating “narrow” forecast PDFs as compared to a purely climatological
distribution).
Data Sets
1979-2001 15-member 24hr ensemble temperature forecasts (MRF ca. 1998; bred modes;
Hamill ref)
Conditional climatology for winter and summer:
-- include forecasts valid 15 Jan/July +/- 15 days
Surface temperature observations at Salt Lake City airport (KSLC) valid 00 UTC (4 PM
LST)
-- use of persistence as regressor is the observation of temperature valid at
forecast initialization time.
In Figure 2 we show time-series of the daily uncalibrated 15-member ensemble
temperature forecasts (colors) versus the observation (black) at station KSLC over the
period of 1990-2001 for: a) 24hr lead-time January forecasts; b) 24hr July; c) 360hr
January; b) 360hr July, and the associated rank histograms in Figure 3 but for the
complete data set (1979-2001) although sub-sampled to remove temporal
autocorrelations (***Cairyn 2010*** discussed the tendency of rank histograms to
oversample due to the verification time-series’ temporal autocorrelations, which we
remove here to mitigate this effect). Notice the underbias of the forecasts for both months
and lead-times. Also notice the decrease in forecast dispersion from January to July,
noticeable in the time-series plots of 360hr forecasts. If the bias were removed, would
this dispersion be accurate, in that changes in dispersion from season to season and from
day to day would be reflective of forecast skill?
Methods
In this section we describe our ensemble calibration method and experimental design.
Recall the five research questions addressed in this paper: a) the impact of seasonality on
(calibrated) ensemble skill; b) the impact of calibration data size on post-processed
forecast skill; c) the benefits of blending logistic regression-derived ensembles with QR
in enhancing forecast skill; d) the utility of ensemble dispersion information to condition
ensemble calibration; e) assessment of most beneficial forecast quantities for postprocessing; and d) in all this, the impact of forecast lead-time on the preceding issues.
To examine a), we perform separate calibrations on January and July data sets; to
examine b), the calibration methodology (discussed below) uses training sets of 2 months
(Januarys or Julys), 5mo, 10mo, and 22mo. In each case, out-of-sample post-processed
forecasts were generated to reproduce the same 23 month time period (Januarys or Julys
of 1979-2001) as the uncalibrated forecasts to be used for validation.
The initial data was a 15-member ensemble set; so although arbitrary, we produce this
same number of post-processed ensembles for comparison with the original set. Note that
the post-processing described below is done independently for each forecast lead-time
(24-hr, 48-hr, …, 360-hr) to address the impact of d) discussed above.
A description of the steps of the post-processing methodology is described below.
Note that throughout, we employ cross-validation to minimize the likelihood of model
“over-fitting”.
Task I: derive an out-of-sample 15-member ensemble set for each season, day, lead-time,
and training data length (2mo, 5mo, 10mo, 22mo) using logistic regression (hereafter
“LR”; Clark and Hays***; Wilks and Hamill 2007) to be used for comparison with the
original reforecast ensemble set and as trial regressors for QR (Task II below). Figure 4
diagrams this LR procedure.
Step 1: estimate 99 evenly-spaced (in probability) climatological-fixed quantiles
(thresholds) c from the available observational record.
Step 2: estimate CDF of being less than or equal to this set of climatological
thresholds c using LR,
pc (z)
1
1 exp z
(4)
n
where the independent variables of the logit z 0 k xk are: a) persistence; and
k0
chosen from the reforecast ensembles, b) ens median, c) ens mean, d) ens std, e) (ens
mean)*(ens std), f) constant. For each threshold c, significant regressors ( a) – f) ) were
chosen by first ranking the regressors based on their p-values, then apply ANOVA to
assess if sequentially-more-complex models reject the null hypothesis with 95%
confidence (retaining only a constant fit 0 in some instances). Independent models were
generated for each threshold c, season, lead-time, and training data length (2mo, 5mo,
10mo, 22mo). In addition, model training was done on independent sets from those used
to generate final estimates (training on ½, fitting on the remainder, then swapping). These
were then used to generate a daily- and forecast-lead-time-varying CDF of exceeding the
prescribed climatological intervals c.
Step 3: our goal of the post-processing is a 15 member equally-probable ensemble
set to compare with the original reforecast ensemble, so a same-sized out-of-sample LR
ensemble set was generated for each day and each lead-time by linearly-interpolating
from the CDF of Step 2 to produce a “sharper” posterior forecast PDF (15-member
ensemble) than the climatological prior of Step 1. The out-of-sample ensemble set is used
as an independent regressor set in the QR procedure of Task II below, as well as set aside
for verification and comparison. Final model coefficient estimation was also redone using
the complete training data set, and saved.
Task II: derive an out-of-sample 15-member ensemble set for each season, day, leadtime, and training data length using QR, as diagramed in Figure 5.
Step 1: determine 15 evenly-spaced climatological quantiles (thresholds) of the
seasonal temperature (same as used in the LR procedure above, but for only 15); used as
starting baseline to ensure resultant ensemble skill is no worse than “climatology”.
Step 2: use forward step-wise cross-validation to select optimal regressor set
(training on ½, fitting on the remainder, then swapping). The regressors are: a)
persistence; b) corresponding LR-derived out-of-sample quantile as described above in
Task I; and chosen from the reforecast ensembles, c) corresponding ensemble(quantile),
d) ens median, e) ens mean, f) ens std. Note that c) is selected by sorting the ensembles
for each day (and lead-time), and selecting the ensemble that corresponds to the (to-befit-)quantile of interest. Note that we also post-process separately without the LR-derived
ensemble set (regressor b)) to provide an independent comparison of LR and QR postprocessing skill. Model selection proceeds as follows: regressors (a)-(f) are individually
fit using Eqs (1)-(3), and ranked based on the lowest value of their out-of-sample cost
n
function (CF; Equation (2))
(r ) , and are also required to satisfy the binomial
i
i 1
distribution at 95% confidence (if not, the model is excluded). If the best one-regressor
model CF value is lower than the CF value using the climatological (constant) quantile of
Step 1, then the best one-regressor model is retained; otherwise, the climatological fit is
retained, and model selection stops. If the best one-regressor model is retained, then
model selection proceeds to assess a 2-regressor model, which includes the regressor
from the best-fit single-regressor model and iteratively-assessing all remaining
regressors. The best-performing 2-regressor model is retained if its out-of-sample CF
value is lower than the single-regressor model (and also satisfies the binomial distribution
at 95% confidence) and model selection proceeds to the 3-regressor model, etc.; if not,
then the simpler 1-regressor model is retained and model selection stops. Once the bestfit model regressor set is determined, out-of-sample estimates are produced, and a final
model estimation is redone using the complete training data set.
Step 3: for each quantile (and lead-time), refit models for each quantile (Task II,
Steps 1-2) for specific ranges of ensemble dispersion. Out-of-sample best-fit model
estimates (hindcasts) from Step 2 are sorted into three (arbitrary number) different ranges
of quantile dispersion defined by q q0.5 . The dispersion intervals are determined from
the requirement that an equal number of hindcasts (from Step 2) fall within each. Over
each range, model selection and fitting is done using identical steps as just described in
Steps 1-2 above. As with Step 2, out-of-sample estimates are produced from crossvalidation for verification and comparison, and final model coefficient estimation is done
using the complete training data set.
Note that in Task II, Step 3 we deliberately use the previous post-processed
ensembles of Task II, Step 2 to determine dispersion intervals instead of the raw
uncalibrated reforecast dispersion. This ensures that at least the average dispersion of the
ensemble set would be accurate. Further, by segregating the hindcast ensembles into
different ranges of ensemble dispersion, and then re-post-processing (Step 3), we ensure
that (dynamic) changes in ensemble dispersion is also calibrated and contains information
about the (relative and variable) forecast uncertainty. This final step allows the raw
ensemble forecast to self-diagnose periods of relative stability or instability, which itself
informs its own post-processing, and in essence is a form of dynamically-determined
analogue selection (see Hopson and Webster 2010 for an example of analogue postprocessing applied to ensemble forecasts).
Results
The methods described above discuss five separate post-processing approaches:
1) LR (Task I); 2) QR (Task II, Steps 1-2); 3) QR over separate dispersion bands (Task
II, Step 3) (hereafter SS-QR); 4) same as 2) but using LR-derived ensembles as
independent regressors; 5) same as 3) but using LR-derived ensembles as independent
regressors. Unless noted, in what follows we compare out-of-sample ensembles derived
from approaches 1) – 3).
In Figure 6, we show the same time-series of temperature as shown in Figure 2,
but after postprocessing using approach 3) and using the 22mo training set. Note that as
shown, the postprocessed ensemble dispersion has been inflated for all forecast leadtimes and seasons. Also the apparent forecast underbias appears to be removed, in that
the observations are now generally embedded within the ensemble bundle. Also very
apparent is the overall inflation of the ensemble dispersion in the 360-hr forecasts (panels
c and d) compared to the 24-hr forecasts (panels a and b), as one would expect. But also
notice the relative seasonal inflation in forecast dispersion particularly noticeable in the
360hr forecasts of January (panel c) compared to July (panel d).
Have we reached the limits of forecasting skill at 360hrs? Recall that our
postprocessing methodology begins with a (constant) climatological quantile prior; if we
cannot enhance skill further, this prior is taken as the posterior. In panels c) (January) and
d) (July) of Figure 6 we observe daily variations in ensemble structure for (almost) all
quantiles, implying further skill beyond climatology. However notice in panel d) the
constant (climatological) q.875 quantile [14/(15+1) = 0.875], which implies minimal
forecast skill of summer high temperature extremes at 360hr.1 However, we do observe
significant variability in the lower tail of the quantile distribution in panel d), implying
increased skill of the forecast system’s ability to discern cold temperature incursions as
compared to high temperature anomalies during summer months. This stretching of the
PDF (by virtue of the fixed upper quantile) produces a daily-variable skewness in the
resultant postprocessed PDF’s (no gaussianity requirements for QR), as well as daily
skill-spread variations.
1
Also calling into question the observed variability of the upper q.9375 quantile.
Objectively, how successful was the forecast system at providing skillful,
calibrated forecasts? The rank histograms shown in Figure 7 provide one way to assess
the calibration of the ensemble forecasts’ own uncertainty estimates. (Only July 24-hr
lead-times shown; other lead-times show similar results. As discussed in Figure 3, we
sub-sampled the time-series to remove temporal autocorrelations; July was chosen since
its temporal autocorrelation is smaller than January, providing more verification
samples). These figures were generated from out-of-sample 15-member ensemble (with
16 intervals) 24-hr forecasts after postprocessing with LR and 2mo training periods
(panel a); dispersion-selected QR (Task II, Step 3 above) and 2mo training periods (panel
b); LR and 22mo training (panel c); and QR and 22mo training (panel d). The red dashed
lines are 95% confidence intervals (CI) on the expected counts in each bin for a perfect
model. Comparing Figure 3 with Figure 7, we see the large improvements both LR and
QR provide in producing calibrated forecasts. How about comparisons between the two
approaches of LR and QR? For 16 intervals, we would expect one interval count to fall
outside the CI on average, if the forecasts were perfectly calibrated; instead, 7 intervals
for the LR 2mo training lie outside the CI, 4 intervals for the LR 22mo training, 1 for SSQR 2mo training, and none for SS-QR 22mo training. What we see, then, is the utility in
longer training windows producing more accurate ensemble forecasts, especially notable
in the 7 interval-to-4 interval drop for LR. But this also points out the superiority of QR
over LR in producing reliable forecast PDFs (recall QR’s cost function minimizes to
uniform rank histograms), in which the QR rank histograms are statistically uniform.
However, we also expect LR could show fewer out-of-bounds intervals if more
climatological intervals were chosen in the calibration and interpolation (99 were chosen;
see Task I). (In truth, we have not accounted for observation error, which would tend the
rank histograms into a U-shape; flat rank histograms then show the post-processing
approaches have implicitly inflated their dispersion to account for this. A truer calibration
should actually show an underdispersion.)
However, note that flat rank histograms are a necessary but not sufficient
condition … Hamill has argued … SS rank histogram results as f(training window) …
Objectively investigating postprocessing sharpness …
=> SS plots -- assess using: a) RMSE; b) Brier; b) RPSS; d) ROC
For Brier, expect LR to excel (along with CRPS – except LR uses more limited regressor
set).
We return to the earlier point concerning QR’s ability to account for non-gaussian
behavior. In Figure *** kernel-fits to the original uncalibrated and calibrated 24-hr
ensemble forecast for one day (July 3, 1995) contained in the red ovals in Figures 2 and 6
panel b. Comparing the PDFs, notice the significant variation in their non-gaussian
structure and the change in the ensemble spread and mean bias, with the observation now
imbedded within the calibrated PDF. Also shown is the tail of the climatological PDF
(dashed), showing the forecasts for this anomalously cold event are significantly sharper
than climatology.
One of the driving considerations in investigating new postprocessing approaches
was to improve the information content of the ensemble spread (i.e. as a representation of
potential forecast error). In particular, this motivated the additional dispersion
refinements to the postprocessing listed in Task II Step 3 above. However, at this point,
for each quantile of interest we have two different QR-based post-processing models to
choose from: one derived from Task II Step 2, and one from Task II Step 3. These two
models represent trade-offs between robustness (the former uses a larger hindcast data set
for model estimation) and fidelity of forecast dispersion (the latter ensures information in
the variable ensemble dispersion). But this begs the question if there are significantenough gains in the information content in the variable ensemble dispersion of Step 3 to
justify the risk of loss of robustness? Hopson (2011) argues that one measure for
assessing the degree of information in an ensemble’s variable dispersion is given by
m1 s
s2 s
2
2
s
2
var(s)
(5)
which is a ratio of the mean dispersion of a forecast system compared to how much the
forecast spread varies from forecast to forecast, where s is some measure of forecast
ensemble spread,
is the expectation (average) value over the available forecast
hindcasts, and var(s)
s s
2
represents the variance of the dispersion itself.
Alternatively, one could simply take
m2 std(s) s
(6)
where std(s) is the standard deviation of s. In Figure *** we represent both of these
measures in the form of a skill-score (see Wilks 1995),
SS
m forc mref
m perf mref
(7)
where mforc, mref, mperf are some measure of skill for the forecast system, a reference
forecast, and a perfect forecast, respectively. Specifically, we take s to be the ensemble
standard deviation, mref as a non-dispersive model, and mperf as one with very large
variation in dispersion. What we see is ***
=> SS plots of my skill-spread skill score
Investigating merged approach: LR as independent regressor under QR framework -Significant regressors (ranked in importance):
1) - 2) forecast ensemble mean; persistence (21)
3) ens forecast stddev (16)
4) forecast ensemble member (12)
5) logistic regression “ensemble” (8)
-- optimal set varied depending on the quantile and the season
For operational purposes and for a general array of applications, it is not clear the
emphasis that should be placed on which skill measures in particular. One possible option
in making final postprocessing selection between the three postprocessing models of LR,
QR, and SS-QR would be to take the one that gives the highest average skill-score of the
QR CF, Brier (average of results for three climatological thresholds 0.33, 0.5, and 0.67),
ROC (average of results for three climatological thresholds 0.33, 0.5, and 0.67), RMSE,
CRPS, scalar version of the Rank Histogram (ref ***), and a skill-spread verification
measure we have introduced (Hopson ref). The reference forecast chosen for the skillscore is the original reforecast ensemble…
Conclusions
-- Quantile regression provides a powerful framework for improving the whole
(potentially non-gaussian) PDF of an ensemble forecast
-- This framework provides an umbrella to blend together multiple statistical correction
approaches (logistic regression, etc.) as well as multiple regressors (non-NWP)
-- As well, “step-wise cross-validation” calibration provides a method to ensure forecast
skill greater than climatological and persistence for a variety of cost functions
-- As shown here, significant improvements made to the forecast’s ability to represent its
own potential forecast error:
-- more uniform rank histogram
-- significant spread-skill relationship (new skill-spread measure; not shown)
References
Anderson, J. L., 1996: A method for producing and evaluating probabilistic forecasts
from ensemble model integrations. J. Climate, 9, 1518-1530.
Bremnes, J. B., 2004: Probabilistic forecasts of precipitation in terms of quantiles using
NWP model output. Mon. Wea. Rev., 132, 338–347.
Granger, C. W. J. and P. Newbold, 1986: Forecasting Economic Time Series, Academic
Press, Inc., Orlando, Florida.
Hamill, T. M. and S. J. Colucci, 1997: Verification of Eta-RSM short-range ensemble
forecasts, Mon. Wea. Rev., 125, 1312-1327.
Hamill, T.M., J.S. Whitaker, and X. Wei, 2004: Ensemble Reforecasting: Improving
Medium-Range Forecast Skill Using Retrospective Forecasts. Monthly Weather Review,
132, 1434–1447.
Hopson, T. M., 2005: Operational Flood-Forecasting for Bangladesh. Ph.D. Thesis, Univ.
of Colorado, 225 pp.
Koenker, R. W. and G. W. Bassett, 1978: Regression Quantiles. Econometrica, 46, 33-50.
Koenker, R. W. and d’Orey, 1987: Computing regression quantiles. Applied Statistics,
36, 383-393.
Koenker, R. W. and d’Orey, 1994: Computing regression quantiles. Applied Statistics,
36, 383-393.
Koenker, R. and W. Portnoy, 1997: The Gaussian Hare and the Laplacean Tortoise:
Computability of Squared-error vs. Absolute Error Estimators. Statistical Science, 12,
279-300.
Koenker, R., 2006: quantreg: Quantile Regression. R package version 3.85. http://www.rproject.org.
Koenker, R. (2006). quantreg: Quantile Regression. R package version 3.85.
http://www.r-project.org.
Mylne, K. R., 1999: The use of forecast value calculations for optimal decision making
using probability forecasts. Preprints, 17th Conf. on Weather Analysis and Forecasting.
Denver, CO, Amer. Meteor. Soc., 235-239.
Palmer, T. N., 2002: The economic value of ensemble forecasts as a tool for risk
assessment: From days to decades. Q. J. R. Meteorol. Soc., 128,
747-774.
Press, W. H., S. A. Teukolsky, W. T. Vetterling, and B. P. Flannery, 1992: Numerical
Recipes in Fortran: The Art of Scientific Computing. Cambridge University Press, New
York, NY.
R Development Core Team (2005). R: A language and environment for statistical
computing. R Foundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-070, URL http://www.R-project.org.
Richardson, D. S., 2000: Skill and economic value of the ECMWF ensemble prediction
system. Quart. J. Roy. Meteor. Soc., 126, 649-668.
Webster, P. J., T. Hopson, C. Hoyos, A. Subbiah, H-. R. Chang, R. Grossman, 2006: A
three-tier overlapping prediction scheme: Tools for strategic and tactical decisions in the
developing world. In Predictability of Weather and Climate, Ed. T. N. Palmer,
Cambridge University Press.
Webster, P. J., and C. Hoyos, 2004: Predicting monsoon rainfall and river discharge on
15–30 day time scales. Bull. Amer. Meteor. Soc., 17, 1745-1765.
Wilks, D. S., 1995: Statistical Methods in the Atmospheric Sciences. Cambridge Press,
467 pp.
Wilks, D. S., 2001: A skill score based on economic value for probability forecasts.
Meteor. Appl., 8, 209-219.
Yuedong Wang (2004), Model Selection. Book chapter in "Handbook of Computational
Statistics (Volume I)", J. Gentle, W. Hardle, Y. Mori (eds), Springer.
Zhu, Y., Z. Toth, R. Wobus, D. Richardson, K. Mylne, 2002: The economic value of
ensemble-based weather forecasts. Bull. Amer. Meteor. Soc., 83, 73-83.