Logistic Regression
advertisement

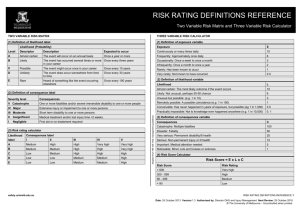
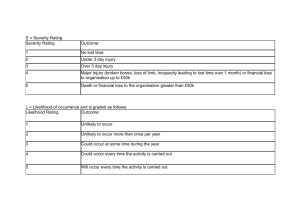
Logistic Regression: Example Questions and Outline Model Answers Question 1 Researchers investigated the characteristics that may affect the performance of trainee air-traffic controllers on their final mock exam, taken at the end of their training. Trainees’ mock exam performance (1=passed; 2=failed) was coded under the variable name passfail. Trainees were also categorised in terms of gender (0=male; 1=female) and level of prior education (1=graduate; 2=non-graduate). Trainees were also rated by the tutor who had supervised their training, prior to sitting the final mock exam, using a four-point scale (1=poor to 4=excellent; variable name=rating). A series of logistic regression analyses was conducted with passfail as the dependent variable, gender and level of education as factors, and the tutor’s rating as a covariate. The SPSS output shown is from the second stage of the analysis (using the Multinomial Logistic Regression command), in which a main effects model was fitted. The printout also shows some relevant contingency tables generated by the SPSS Crosstabs command. (a) (b) What was the appropriate first stage of the analysis, and what outcome would have led to the fitting of a main effects model in the second stage? (25% of marks for question) Describe in detail what each part of the printout from the second stage tells us about the variables that are related to the trainees’ mock exam performance? (75% of marks for question) Printout For Question 1 Ca se P rocessi ng S um mary N PA SSFAIL res ult on passed exam final mock exam failed exam EDLEV EL level of graduate educat ion non graduate GE NDER male female Valid Missing Total 42 55 51 46 53 44 97 0 97 Model Fitting Information Model Intercept Only Final -2 Log Likelihood 70.164 40.306 Chi-Squa re df 29.858 Sig. 3 .000 Likelihood Ratio Tests Effect Intercept RATING EDLEVEL GENDER -2 Log Likelihood of Reduced Model 40.306 49.255 43.622 59.905 Chi-Squa re .000 8.949 3.316 19.599 df Sig. 0 1 1 1 . .003 .069 .000 The chi-square statistic is the difference in -2 log-likelihoods between the final model and a reduced model. The reduced model is formed by omitting an effect from the final model. The null hypothesis is that all parameters of that effect are 0. Parameter Estimates PASSFAIL result on final mock exam passed exam Intercept RATING [EDLEVEL=1] [EDLEVEL=2] [GENDER=0] [GENDER=1] B -3.777 .686 .885 0a 2.197 0a Std. Error .924 .245 .491 0 .549 0 Wald 16.730 7.817 3.248 . 16.001 . df 1 1 1 0 1 0 Sig. .000 .005 .072 . .000 . a. This parameter is set to zero because it is redundant. GENDER * PASSFAIL result on fi nal mock ex am Crosstabulation Count GENDER male female Total PASSFAIL res ult on final mock exam passed failed ex am ex am 33 20 9 35 42 55 Total 53 44 97 EDLEV EL level of education * PASS FAIL re sult on fina l mock e xam Crosstabulation Count EDLEV EL level of educ ation graduate non graduate Total PA SSFAIL res ult on final mock exam passed failed ex am ex am 28 23 14 32 42 55 Total 51 46 97 Question 1: MODEL ANSWER (a) The second stage involves the fitting of a main effects model. The first stage (or stages) should have involved the fitting of a more complete model (e.g., a full factorial model). This should have included a likelihood ratio test for removing the factor interaction effect (i.e. gender*educational level). This must have been found to be nonsignificant in order to proceed to the next stage, in which the model contains only main effect terms. Note 1: Because all effects in logistic regression are really interactions with the DV, this interaction can also be described as a gender*ed_level*passfail interaction. Note 2: It is rare to include interaction terms for covariates unless you have very large samples; however, students who talk about a test of any interaction involving the Exp(B) 1.986 2.424 . 8.994 . covariate RATING need to discuss several first stages in which the combined effect of all the higher-order interactions were tested i.e. gender*ed_level*rating plus gender*ed_level plus gender*rating plus ed_level*rating [and, of course, each of these could be described as *passfail also]). (b) Case processing summary -- gives frequencies for each main effect variable Model fitting information -- The intercept only model (i.e. without any of the main effects) has a (-2 times log of) likelihood of 70.164 whereas the corresponding likelihood term for the final model (i.e., the model including the 3 main effects) is 40.306. The difference between these two terms provides a likelihood ratio test statistic with 3 df (3= number of parameters in final model) which is distributed as chi-square. The p value reflects the probability of getting a likelihood ratio this large by chance, if the reduced (intercept only) model were true. This value is highly significant, and so one cannot safely reject the model which has these 3 main effects in it. Likelihood Ratio tests -- (students who simply parrot back the text under the table in the printout get 0 marks) each of the 3 main effects is listed in the Effect column; the -2 log likelihood column gives the likelihood term for a model which is the main effect model minus the individual effect specified. Thus this provides a test of the importance of each main effect separately. The chi-square column is a likelihood ratio test statistic once again and is the difference in likelihood terms between the model minus a main effect and the main effects model (the intercept line is meaningless). Hence, 49.255-40.306=8.949 etc. Each main effect has 1 df because each main effect has only two levels and the DV has only two levels (for working out df it is important to remember that main effects are really interactions with the DV; df= [2-1]*[2-1]). The likelihood ratios for the removal of each main effect is tested against chi-square as described before. The main effects for RATING and Gender contribute significantly to the overall model although the main effect of Educational level narrowly fails to attain significance. Parameter estimates -- This table provides more detail on the main effects and considers the significance of each effect/parameter in a model with all the other parameters (it will usually produce very similar results to the likelihood ratio tests). The table says “passed exam” because it computes odds for a subject passing the exam relative to a subject failing an exam. Each single df effect is tested via an odds ratio: the B parameter is the regression weight (it is also the “log odds ratio”) and its significance is tested by the Wald statistic (Wald value=[B/std error]2) which is distributed as chi-squared with 1 df; EXP(B) gives the odds ratio and the confidence limits of the odds ratio are calculated as EXP(B±1.96*stderr). Significance levels agree with the likelihood ratio test statistics in the previous table. The 95% confidence intervals for the odds ratio should not include 1 (=chance) for a significant effect (hence the ed_level effect does include 1 -- just -- and so is narrowly nonsignificant). The odds ratio for RATING reflects the change in odds (of passing:failing) for each unit increase in the RATING score. The positive B value means that the higher the rating score the higher the odds of passing (so the raters are able to predict exam success). For gender the odd ratio is computed for males (gender =0) relative to females. The odds ratio (EXP[B]) is thus the odds of passing:failing for males divided by the odds of passing:failing for females and it is >1 (i.e. positive B) because males have a greater odds of passing than females (check against crosstabs output). The row for females (Gender=1) is empty because we can’t compute an odds ratio for females vs. females (odds=1; log odds=B=0). Need note only that similar considerations apply to the Ed_Level effect. Crosstabs tables -- can be used to cross-check interpretation of parameter estimates table as already noted. An impressive student may calculates the odds ratio from the cross tab table by hand (showing working) and shows it has roughly the same value as the corresponding EXP(B) in the parameter estimates table. (It won’t be exactly the same because of the other terms in the model will affect the parameters to some extent, but do not affect the crosstabs table).