LOG LINEAR ANALYSIS
advertisement

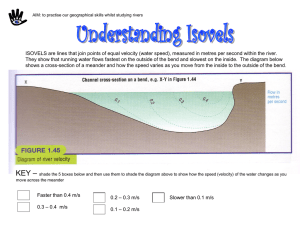
CHAPTER 6 : LOG LINEAR ANALYSIS Purpose: Log linear analysis is an advanced technique that can be used instead of independence tests. There are two main advantages to using the Log linear technique: 1) you can test more than two variables at a time with as many levels as you like, and 2) you can also test for main effects. A main effect occurs when the frequencies for a variable differ among levels of that variable. For example, let’s assume that one of your variables was blue-eye color with two levels, blue and not blue. Let’s also assume that the percentages from your sample were 44% blue and 56% not-blue. Remember that a sample provides estimates but not the true results. The log linear analysis for the main effect “blue-eye color” tests whether the actual proportions of blue to not-blue were really 50-50. Background: Main effects in a 2X2 table Let’s illustrate the main effect in a simple problem. You have noticed that there are two variations of a shrub species, one with smooth leaves and one with hairy leaves. You think that the presence of smooth leaves might be related to the presence of serpentine in the soil. You sample 120 random locations in Santa Clara county where the shrubs are found and you record the leaf type (hairy or smooth) and whether Serpentine is present in the soil. You obtained the following data: Table 6-1: Serpentine soil versus leaf type data for example of log-linear analysis Leaf type Serpentine Soil Yes No Leaf Type Total Hairy 12 36 48 Smooth 22 50 72 Serp. Soil Total 34 86 120 Analyzed as a 2X2 Test of Independence Ho: Leaf type is independent of the presence or absence of Serpentine soil. Alpha ()= 0.025 (Why?) Results: Because the p-value (Prob=5.06) > (0.025) you would accept Ho and conclude that leaf type is independent of the presence or absence of serpentine soil (Table 6-2). Table 6-2: Results fromTwo -Way Crosstabs (Systat™ 10.0) for data in Table 6-1. 6-1 Analyzed as a 2x2 Log linear For this log linear example, there are three Ho’s instead of one: 1. Ho #1: There is no Leaf type*Serpentine soil interaction. This is the same thing as Leaf type is independent of the presence or absence of Serpentine soil. In addition, the following hypotheses can be tested if Ho #1 is accepted: 2. Ho #2: The proportion of sites with serpentine soil is equal to the proportion of sites without serpentine soil. Remember we are dealing with a sample here. 3. Ho #3: The proportion of sites with hairy leaves is equal to the proportion of sites with smooth leaves. The Log linear test results: 1. Accept Ho for Ho #1: There is no interaction (p=0.506) between leaf type and the presence or absence of Serpentine soil (Figure 6-1). This means the leaf type is independent of the presence or absence of Serpentine soil that is the same conclusion as for the 2x2 Test of Independence. Figure 6-1: Test Hypothesis that there is no interaction between leaf type and the presence or absence of Serpentine soil 2. Because we accepted Ho for the interaction, we go on to test the other Hos 3. Reject Ho for Ho #2: The proportion of sites with serpentine soil is significantly different (p<0.001) from the proportion of sites without serpentine soil (Figure 6-2). From the table percentages (not shown here), it can be determined that the proportion of sites with serpentine soil (28.3%) is significantly (p<0.001) less than the proportion of sites without serpentine soil (71.7%). Figure 6-2: Tests for significance of Serpentine Soil type and Leaf type. 4. Accept Ho for Ho #3: The proportion of sites with hairy leaves is not significantly different (p=0.0279 with α=0.025) from the proportion of sites with smooth leaves (Figure 6- 2). This means that you have no evidence that one leaf type is more abundant than the other (i.e., the difference in frequencies could have been a function of chance given your sample size). How does Log Linear analysis work? Log linear analysis involves testing a series of models. Log linear models are equations that contain terms made up of combinations of the variables used in the analysis plus a constant. The 6-2 most complex model (i.e. the one that contains the most terms) is called the Fully Saturated Model. The terms are arranged in a hierarchy starting with all variables singly, then all combinations of 2 variables at a time, then all combinations of three variables at a time etc. until all combinations have been exhausted. In the preceding example there were two variables, Serpentine Soil (Yes or No) and Leaf Type (Hairy or Smooth). In this example, we will use “S” for the Serpentine Soil variable and “L” for the Leaf Type variable. The fully saturated model for the problem above is: CONSTANT+S+L+(S*L). The models consist of terms with each term representing a particular effect. In the model above there are three effects (terms) and a constant (included in all models for statistical reasons). The three effects are the Serpentine main effect (S), the Leaf type main effect (L) and the interaction between Serpentine and Leaf type (S*L). With the exception of CONSTANT, each effect or term in the model refers to a specific Ho. The fully saturated model is used as a standard of comparison for all tests of that system because it explains all of the possible variation in the data. The idea behind Log linear analysis is to find the simplest model that does the same job as the fully saturated model. Simplified models are those with less effects or terms. To find the most simplified model, you do a series of Goodness of Fit type comparisons with the fully saturated model. If you throw out a term and the two models match, the term or effect was not important. If you throw out a term and the two models do not match, that term is important and should be included in the final simplified model. The order in which you throw out terms is important because, if an interaction is important, all main effects that make up the interaction are not important. This is because a significant interaction implies that the main effects affect each other, so you can’t make a simple statement about one main effect without dealing with the others. Therefore, you start the process by first throwing out the interactions. In our simple example, we would first throw out the S*L interaction. This would create the simplified model CONSTANT+S+L. We would then see if the simplified model does the same job as the fully saturated model. If it does, the term we threw out wasn’t important and we would accept Ho for that term. If it doesn’t, we would reject Ho for that term and keep it the model. IMPORTANT: If you do end up rejecting Ho for an interaction, when you put the term back in, you also must get rid of all lower order terms that could be made from the terms in the interaction. In this example, if we reject Ho for S*L, that term would be put back in the model but S and L would we taken out. When lower order terms are taken out in this way, you are NOT testing them; they are simply irrelevant. Why? When there are no more terms to test, the remaining model is called the FINAL MODEL and is the simplest model that will do the same job as the fully saturated model. 6-3 For our specific example, when we threw out S*L and tested the simplified model CONSTANT+S+L, the results of the G-test indicate that we accept Ho. Therefore the interaction was not important (i.e. not significant). The next step would be to throw out one of the single (main) effects; it doesn’t matter which. Let’s start with the S term. If we throw out the S effect and compare the model CONSTANT+L to the fully saturated model, we will find that the two models do not match (we rejected Ho). Therefore, the S effect is important and needs to be included in the final model. Next, we would put the S effect back in and take out the L effect. We find that the model CONSTANT+S does NOT differ significantly from the fully saturated model. Therefore, the L effect is not important and we accept Ho for that term. If you had thrown out the L term first, you would have found a match with the fully saturated model and concluded that Leaf type was not important. Since there are no more terms to throw out, we have the final model: CONSTANT+S. We can then interpret the meaning of the final terms be looking at the totals for the levels. We would then reach the conclusions listed in the Analyzed as a 2x2 log linear section. Computing the test – Basic Steps 1) Determine what you are going to test. 2) Design the experiment. a. What are the variables? b. What are the levels for the variables? c. What analysis should you use? d. What planned comparisons do I want to make among the levels? e. What terms are there in the fully saturated model? f. What are all of the Hos and Has? g. What would it mean if you accept Ho? h. What would it mean if you reject Ho? i. How would you conduct the experiment? j. What statistical error should you avoid? 3) Collect data. 4) In sequence, test most complex (more terms) model to least complex (simplified – with less terms) model for goodness of fit to the fully saturated model. If a simplified model fits the fully saturated model, it is doing the same job as the fully saturated model and all terms not included in the simplified model are not statistically significant. 5) For any significant effects, plot the percentages. 6-4 6) Conduct planned comparisons if you reject Ho for step 5. See pages 5-12 to 5-14 RxC Test of Independence. 7) Conduct any unplanned comparisons if you reject Ho for step 5. See pages 5-14 to 5-15 RxC Test of Independence. 8) Draw conclusion. EXAMPLE 1: 2x2 Log Linear analysis We will use the same experiment and data as for the Banded and Unbanded snake patterns versus the presence or absence of brush (see EXAMPLE 1: 2x2 Test of Independence on Page 6-3) 1) Determine what you are going to test. We want to determine if the snake pattern is related to the presence or absence of brush 2) Design the experiment. a. What are the variables? Snake and Brush b. What are the levels for the variables? Snake: Banded or Unbanded Brush: Present or Absent c. What analysis should you use? You are going to use a stepwise backward hierarchical 2x2 Log linear analysis. d. What planned comparisons do I want to make among the levels? See page 5-10 RxC Test of Independence. Because none of the levels have more than 2 levels, planned comparisons cannot be done. e. What terms are there in the fully saturated model? Constant + Snake + Brush + Snake*Brush f. What are all of the Hos and Has? i. Ho #1: whether a snake is banded or unbanded is independent of the presence or absence of brush (Snake*Brush interaction). Ha #1 is that whether a snake is banded or unbanded depends on the presence or absence of brush. ii. Ho #2: The proportion of sites with banded snakes is equal to the proportion of sites with unbanded snakes. Ha #2 is that the proportion of sites with banded snakes is NOT equal to the proportion of sites with unbanded snakes. iii. Ho #3: The proportion of sites with brush is equal to the proportion of sites without brush. Ha #3 is that the proportion of sites with brush is NOT equal to the proportion of sites without brush. g. What would it mean if you accept Ho? i. Accept Ho #1 would mean that there is no relationship or interaction between the presence or absence of brush and whether snakes are banded or unbanded. Also it is ok to test Hypotheses 2 and 3. ii. Accept Ho #2 would mean that the proportion of banded snakes is not different from the proportion of unbanded snakes. iii. Accept Ho #3 would mean that the proportion of sites with brush is not different from the proportion of sites without brush. h. What would it mean if you reject Ho? 6-5 i. Reject Ho #1 would mean that the presence or absence of brush does have some relationship to the presence of banded or unbanded snakes. Also, do NOT test hypotheses 2 and 3. ii. Reject Ho #2 would mean that the proportion of banded snakes is different from the proportion of unbanded snakes. iii. Reject Ho #3 would mean that the proportion of sites with brush is different from the proportion of sites without brush. i. How would you conduct the experiment? You will randomly sample sites until you find 180 sites with snakes. For each site, you will record whether or not brush was present and whether the snake was banded or unbanded. j. What statistical error should you avoid? Conclude that the worse error is Type I so alpha will equal 0.025. 3) Collect data Table 6-3: Frequency of banded/unbanded snakes and presence/absence of brush for 180 sites with snakes. Data SNAKE Banded Unbanded BRUSH Absent 32 43 Present 46 59 4) In sequence, test most complex (more terms) model to least complex (simplified – with less terms) model for goodness of fit to the fully saturated model. If a simplified model fits the fully saturated model, it is doing the same job as the fully saturated model and all terms not included in the simplified model are not statistically significant. Use SPSS™ 10.0 to compute a stepwise backward elimination hierarchical log linear analysis (see page 7-11 for SPSS instructions). Figure 6-3: Final model for 2x2 log linear analysis Example 1 Figure 6-4: Test Hos for 2x2 log linear analysis - Example 1. Note that the output has been compressed here; normally there are items in between the interaction and the main effects. o Accept Ho #1. There is there is no relationship or interaction (p=0.879) between the presence or absence of brush and whether snakes are banded or unbanded. Also it is ok to test Hypotheses 2 and 3. 6-6 5) 6) 7) 8) o Accept Ho #2. The proportion of banded snakes is not different (p=0.732) from the proportion of unbanded snakes. o Accept Ho #3. The proportion of sites with brush is not different (p=0.025 with α=0.025) from the proportion of sites without brush. For any significant effects, plot the percentages. No graphs needed. Conduct planned comparison if you reject Ho for step 5. None of the variables have more than 2 levels so there can be no unplanned comparisons. Conduct any unplanned comparisons if you reject Ho for step 5. None of the variables have more than 2 levels so there can be no unplanned comparisons. Draw conclusion The banding pattern doesn’t appear to have anything to do with the presence of brush in the environment. EXAMPLE 2: 2x2x2 Log Linear analysis We will now learn how to do a Log linear analysis with 3 variables. You are exploring the relationship between a color morph of lizard (light and dark), the type of ground (sand or dirt) and the presence or absence of shade. 1) Determine what you are going to test. We want to determine if the color morph of the lizard is related to the type of ground and/or the presence or absence of shade. 2) Design the experiment. a. What are the variables? Morph, Ground and Shade b. What are the levels for the variables? Morph: Light or Dark Ground: Sand or Dirt Shade: Present or Absent c. What analysis should you use? You are going to use a 2x2x3 stepwise backward hierarchical log linear analysis. d. What terms are there in the fully saturated model? Constant + Morph + Ground + Shade + Morph*Ground + Morph*Shade + Ground*Shade + Morph*Ground*Shade Main effects Two-way interactions Three-way interaction e. What are all of the Hos and Has (we won’t include these here)? i. Ho #1: there is no interaction between lizard morph, ground and shade. ii. Ho #2: there is no interaction between lizard morph and ground. iii. Ho #3: there is no interaction between lizard morph and shade. iv. Ho #4: there is no interaction between ground and shade. v. Ho #5: the proportion of dark lizard morphs is equal to the proportion of light lizard morphs. vi. Ho #6: the proportion of dirt sites is equal to the proportion of sand sites. vii. Ho #7: the proportion of shaded sites is equal to the proportion of unshaded sites. 6-7 f. What would it mean if you accept Ho? i. Accept Ho #1 would mean that there is no relationship or interaction between the three variables. Also, you can test the two-way interactions. ii. Accept Ho #2 would mean that there is no relationship between lizard morph and ground. Also, you can test the lizard morph and ground main effects. iii. Accept Ho #3 would mean there is no relationship between lizard morph and shade. Also, you can test the lizard morph and shade main effects. iv. Accept Ho #4 would mean there is no relationship between ground and shade. Also, you can test the ground and shade main effects. v. Accept Ho #5 would mean that the proportions of dark and light lizard morphs are equal. vi. Accept Ho #6 would mean that the proportions of dirt and sand sites are equal. vii. Accept Ho #7 would mean that the proportions of shaded and unshaded sites are equal. g. What would it mean if you reject Ho? (not included here). h. How would you conduct the experiment? You will randomly sample sites until you find 885 sites with lizards. For each site, you will record whether the lizard was dark or light, whether the ground was dirt or sand and whether or not shade was present. i. What statistical error should you avoid? Assume that you concluded that the worse error is Type II so alpha will equal 0.050. 3) Collect data Table 6-4: Frequency of lizard morphs, ground types and shade for 885 sites with lizards. Number value of variable in (). SHADE LIZARD COLOR Light (0) Light (0) Dark (1) Dark (1) GROUND Sand (0) Dirt (1) Sand (0) Dirt (1) Absent (0) 231 81 57 177 Present (1) 136 37 47 119 4) In sequence, test most complex (more terms) model to least complex (simplified – with less terms) model for goodness of fit to the fully saturated model. If a simplified model fits the fully saturated model, it is doing the same job as the fully saturated model and all terms not included in the simplified model are not statistically significant. 6-8 Use SPSS 10.0 to compute a stepwise backward elimination hierarchical log linear analysis (see page 7-11 for instructions). Figure 6-5: Final model for 2x2 log linear analysis Example 1 o A c c Figure 6-6: e Test Hos for 2x2 log linear analysis - Example 1. Note that the output has been compressed p here; normally there are items in between the interaction and the main effects. o Accept Ho #1. There is there is no relationship or interaction (p=0.877) between lizard morph (dark or light), ground type (dirt or shade) and shade (present or absent). Also it is ok to test two-way interactions. o Reject Ho #2. There is a significant (p<0.001) interaction between lizard morph (dark or light) ground type (dirt or sand). Need to graph this interaction. Cannot test lizard morph or ground type main effects. o Accept Ho #3. There is there is no relationship or interaction (p=0.076) between lizard morph (dark or light) and shade (present or absent). Also it is ok to test shade main effect. o Accept Ho #4. There is there is no relationship or interaction (p=0.153) between ground type (dirt or sand) and shade (present or absent). Also it is ok to test shade main effect. o Ho #5 can’t be tested. o Ho #6 can’t be tested. o Reject Ho #7. The proportion of shaded sites is significantly different (p<0.001) from the proportion of unshaded sites. 5) For any significant effects, plot the percentages. a. Lizard morph*Ground type interaction. 6-9 Percent 80% 60% Sand Dirt 40% 20% 0% Light Dark Lizard Morph Figure 6- 7: Significant Lizard morph (dark or light)*Ground type (sand or dirt) interaction Percent b. Shade main effect. 70% 60% 50% 40% 30% 20% 10% 0% Shade No shade Figure 6- 8: Significant Shade main effect 6) Conduct planned comparison if you reject Ho for step 5. None of the variables have more than 2 levels so there can be no unplanned comparisons. 7) Conduct any unplanned comparisons if you reject Ho for step 5. None of the variables have more than 2 levels so there can be no unplanned comparisons. 8) Draw Conclusions 6-10 There is there is no relationship (p=0.877) between lizard morph (dark or light), ground type (dirt or shade) and shade (present or absent There is a significant (p<0.001) interaction between lizard morph (dark or light) ground type (dirt or sand). The proportion of light morphs is greater in sandy areas and the proportion of dark morphs is greater in dirt areas (Figure 6- 7). There is there is no relationship (p=0.076) between lizard morph (dark or light) and shade (present or absent). There is there is no relationship (p=0.153) between ground type (dirt or sand) and shade (present or absent). The proportion of shaded sites is significantly less (p<0.001) than the proportion of unshaded sites. Using SPSS 10.0: 2x2x2 Log linear Analysis You are exploring the relationship between a color morph of lizard (light and dark), the type of ground (sand or dirt) and the presence or absence of shade. You have collected the following data: Enter The Data 1) When you start the SPSS program, you will be faced with the window depicted in Figure 6- 9. 2) Select “Type in data” and click on “OK” 3) At the bottom of the next window (Figure 6- 10), click on the “Variable View” tab. Figure 6-10: First Window in SPSS™ 10.00 Figure 6-9: Tabs at bottom of editor window 4) Enter the first variable name, “morph” in the NAME column and enter “Lizard Morph” in the LABEL column (Figure 6- 11). Then click on the VALUES column and then on the gray box in the VALUES column. Figure 6- 11: creating a variable called Morph . 9) The next window (Value Labels) allows you to specify labels for numerical values. We are going to specify that 0 = “Light” and 1= “Dark”. Enter 0 for the VALUE and “Light” for the VALUE LABEL; then click on ADD. Figure 6-12: Value labels window. Enter 1 for VALUE and “Dark” for the VALUE LABEL; then click on ADD. Finally click on OK. 10) Add another variable “ground” with a label of “Ground Type” and values (0=Sandy and 1 =Dirt). 11) Add another variable “shade” with a label of “Shade” and values (0=Absent, 1=Present). 12) Add another variable “freq” with a label of “Frequency”. 13) Click on the DATA VIEW tab (Figure 6- 9). 6-11 14) Table 6-5: Frequency of lizard morphs, ground types and shade for 885 sites with lizards. Number value of variable in (). SHADE LIZARD GROUND Absent (0) Present (1) COLOR Light (0) Sand (0) 231 136 Light (0) Dirt (1) 81 37 Dark (1) Sand (0) 57 47 Dark (1) Dirt (1) 177 119 15) Select VALUE LABELS from the VIEW pull-down menu. 16) Enter 0 for the “morph” variable, 0 for the “ground” variable, 0 for the “shade” variable and 231 for the frequency. 17) Continue entering all of the data. Your data should look like Figure 6- 13. Let SPSS know that you have entered frequency data 1) Select WEIGHT CASES from the DATA pull-down menu. 2) Click on Frequency in the left-hand box (Figure 6Figure 6-13: Data for 2x2x2 14). Click stepwise backward hierarchical on the log linear analysis WEIGHT CASES BY option and then click on the arrow. “Frequency” should appear in the FREQUENCY VARIABLE box. Figure 6-14: Frequency variable window. Create a new draft output window 1) From the FILE pull-down menu, select NEW and then select DRAFT OUTPUT. Run the log linear analysis 1) From the ANALYZE pull-down menu, select LOGLINEAR and then select MODEL SELECTION. 2) You will see the window illustrated in Figure 6- 15. Click on “Lizard Morph” and then on the arrow to select Lizard Morph as a FACTOR. Select “Ground Type” and “Shade” as FACTORS. 6-12 3) Next Click on “morph” in the FACTOR(S) box and then click on the DEFINE RANGE button. Specify 0 as the MINIMUM and 1 as the MAXIMUM. Click on CONTINUE. 4) Do the same for “ground” and “shade”. 5) Finally click on OK to run the analysis. Output Figure 6-15: Loglinear analysis window 1) First examine the total number of observations. It should match your total number. 2) Next, examine the frequencies to make sure you entered your data correctly. 3) K-way tests. These tests tell you the levels of terms that are likely to be significant. In this case, there are some 1 way (main effects) (p=<0.0001) and some 2 way interactions (p<0.0001) but no 3-way interactions (p=0.8776) (Figure 16). Figure 6-16: Test for K-way effects. 5) Next go almost to the end of the output to find the final model (Figure 6- 17). In this case there are two terms in the final model: the Morph*Ground 2-way interaction and the Shade main effect. Figure 6-17: Final model for 2x2x2 stepwise backward hierarchical log linear analysis 6) Fill in the following table by examining the output from the bottom to the top. If Deleted Simple Effect is Df L.R. Chisq Change Prob MORPH*GROUND*SHADE 1 0.024 0.8774 MORPH*GROUND 1 226.544 0.0000 MORPH*SHADE 1 3.149 0.0760 GROUND*SHADE 1 2.044 0.1528 MORPH N/A GROUND N/A SHADE 1 48.868 0.0000 6-13 On Your Own Problem: You are interested in determining if there are relationships between the class of cars people buy (economy, standard, sport, luxury), gender and whether or not they are retired. You especially want to know if people preferences for low cost (economy and standard) versus expensive (sports and luxury) are dependent upon gender and/or whether or not they are retired. If you find differences, you will invest more time and energy in trying to find out why. Data: For this problem you will use the dataset: Car Data.SAV 1) Determine what you are going to test. 2) Design the experiment. a. What are the variables? b. What are the levels for the variables? c. What analysis should you use? d. What planned comparisons do I want to make among the levels? (note: make aa many as possible) e. What terms are there in the fully saturated model? f. What are all of the Hos and Has? g. What would it mean if you accept Ho? 6-14 h. What would it mean if you reject Ho? i. How would you conduct the experiment? j. What statistical error should you avoid? 3) Use the car data.sav file 4) In sequence, test most complex (more terms) model to least complex (simplified – with less terms) model for goodness of fit to the fully saturated model. If a simplified model fits the 6-15 fully saturated model, it is doing the same job as the fully saturated model and all terms not included in the simplified model are not statistically significant. 5) For any significant effects, plot the percentages. 6) Conduct planned comparisons if you reject Ho for step 5. See pages 5-12 to 5-14 RxC Test of Independence. 7) Conduct any unplanned comparisons if you reject Ho for step 5. See pages 5-14 to 5-15 RxC Test of Independence. 8) Draw conclusion. 6-16