Lab 3 activities
advertisement

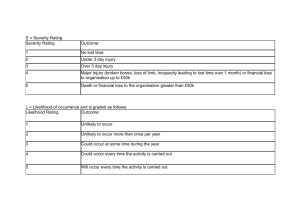
1 Psy 521/621 Lab 3 Activities – October 15, 2008 Categorical Data Analysis Learning Objectives: Learn to conduct and interpret the chi-square test of independence for categorical data in SPSS o Learn to conduct such analyses using a raw data file (i.e., a data file where each row represents a single participant and each column represents a variable) o Learn to conduct such analyses using a data file using the “weighted cases method” which summarizes the number of cases in each cell of the contingency table Learn to conduct and interpret focused follow-up tests for chi-square tests with more than one degree of freedom To accomplish these learning objectives, we will focus on the two end-of-lesson exercises in Lesson 41 “Two-Way Contingency Table Analysis Using Crosstabs” of the Green and Salkind book. Exercise 1 DATAFILE: Lesson 41 Exercise 1.sav Research scenario: Lilly collects data on a sample of 130 high school students to evaluate whether the proportion of female high school students who take advanced math courses in high school varies depending upon whether they have been raised primarily by their father or by both their mother and their father. The SPSS data file contains two variables: math (0 = no advanced math and 1 = some advanced math) and parent (1 = primarily father and 2 = father and mother). Before we start, what will our contingency table look like? It will be a 2 X 2 contingency table because each of our variables has two levels. Let’s conduct a crosstabs analysis to examine whether the proportion of female high school students who take advanced math courses is different for different levels of the parent variable. To run the crosstabs analysis: Click Analyze Descriptive Statistics Crosstabs Click “parent” and move it to the “Rows” box Click “math” and move it to the “Columns” box A box in the bottom left corner called “Display clustered bar charts” should be checked. Keep it this way. Click “Statistics” and check the box next to “Chi-square” and “Phi and Cramer’s V” 2 Click Continue. Click “Cells” and check the box next to “Expected” (the “Observed” box should already be checked). Also, click “Row” and “Column” in the percentages box. Click Continue. Click OK. Parents of female high school student * Math classes Crosstabulation Parents of female high school student Primarily father Father and mother Total Count Expected Count % within Parents of female high school student % within Math class es Count Expected Count % within Parents of female high school student % within Math class es Count Expected Count % within Parents of female high school student % within Math class es Math classes Some No advanced advanced math math 21 9 26.1 3.9 Total 30 30.0 70.0% 30.0% 100.0% 18.6% 92 86.9 52.9% 8 13.1 23.1% 100 100.0 92.0% 8.0% 100.0% 81.4% 113 113.0 47.1% 17 17.0 76.9% 130 130.0 86.9% 13.1% 100.0% 100.0% 100.0% 100.0% Let’s get an idea of what we’re looking at here. On the outermost edges, you see a row called total and a column called total. Each row/column has two cells. In the upper right most cell of data, you get totals for the “primarily father” variable. 30 females in the sample of 130 were raised primarily by their father. Below that cell, you get the totals for females in the sample who were raised by father and mother (count = 100 out of 130 females in the sample). Looking at the lower left most cell of data, you can identify the total number of females in the same who have taken no advanced math (count = 113 out of 130 females in the sample). The cell to the right tells you how many females in the sample have taken some advanced math (count = 17 out of 130 females in the sample). Let’s identify the percentage of female students who took some advanced math classes. Now let’s identify the percent of female students raised by their fathers only. 3 Cells on the interior of the table are conditional percentages. In other words, they ask: given a specified level of one variable, what percentage of these individuals fall into the various levels of another variable? What we’re doing here is focusing on just one level of a variable (e.g., primarily father level of the parent variable), and looking to see what percentage of people within this level appear in the levels of the other variable (i.e., what percentage of students raised primarily by their father took some advanced math classes or no advanced classes). Now let’s identify the percentage of female students who, given that they were raised by their fathers, took no advanced math classes. Parents of female high school student * Math classes Crosstabulation Parents of female high school student Primarily father Father and mother Total Count Expected Count % within Parents of female high school student % within Math class es Count Expected Count % within Parents of female high school student % within Math class es Count Expected Count % within Parents of female high school student % within Math class es Math classes Some advanced No advanced math math 9 21 3.9 26.1 Total 30 30.0 70.0% 30.0% 100.0% 18.6% 92 86.9 52.9% 8 13.1 23.1% 100 100.0 92.0% 8.0% 100.0% 81.4% 113 113.0 47.1% 17 17.0 76.9% 130 130.0 86.9% 13.1% 100.0% 100.0% 100.0% 100.0% What’s the χ2 value for this analysis? How many degrees of freedom are associated with this test? Remember that for χ2 df = (rows – 1)(columns – 1) 4 Chi-Square Tests Pearson Chi-Square Continuity Correction a Likelihood Ratio Fis her's Exact Test Linear-by-Linear As sociation N of Valid Cases Value 9.826b 7.986 8.434 df 1 1 1 9.751 1 As ymp. Sig. (2-sided) .002 .005 .004 Exact Sig. (2-sided) Exact Sig. (1-sided) .004 .004 .002 130 a. Computed only for a 2x2 table b. 1 cells (25.0%) have expected count less than 5. The minimum expected count is 3.92. Formally, we would state this as: χ2(1, N = 130) = 9.83, p < .05. Each of our variables had just two levels, resulting in a 1df test. What does that mean? It means that we do not need to run follow-up tests. What can we say about the strength of the relationship between taking advanced math courses and level of parenting? Let’s look at an effect size for this analysis. Symmetric Measures Nominal by Nominal Phi Cramer's V N of Valid Cases Value -.275 .275 130 Approx. Sig. .002 .002 a. Not ass uming the null hypothesis. b. Us ing the asymptotic standard error as suming the null hypothesis. What does Φ = -.28 mean? Rules of thumb for Φ and Cramer’s V .10=small .30=medium .50=large So, this is a medium effect. Let’s look at a clustered bar chart showing the differences in the number of female students taking some advanced math classes for the different categories of parenting. Remember how we left the box for “Display clustered bar charts” checked? SPSS has already created a barchart for us in the Output file. 5 100 80 60 40 Math classes Count 20 No advanced math 0 Some advanced math Primarily father Father and mother Parents of female high school student Let’s point out a few things about this chart. First, notice that the observed frequencies (called counts) appear on the y-axis, percentages do not. Also, notice that the observed frequencies for “some advanced math” between the two groups (raised by father, raised by mother and father) are not all that different, 9 and 8 respectively. However, remember that chi square tests are testing for differences between observed vs. expected frequencies. Now let’s create a clustered bar chart that displays percentages on the y-axis. Click Graphs Bar Select “Clustered” and “Summaries for groups of cases” and click Define. Select “% of cases” in the Bars Represent box Move “math” to category axis box Move “parent to define clusters by” box Click OK. 6 100 80 60 40 Parents of female hi Percent 20 Primarily father 0 Father and mother No advanced math Some advanced math Math classes We’re most interested in comparing the percentages in these two bars. If we were going to create a chart to accompany our result section, we would probably want it to look similar to this one (as opposed to the one SPSS automatically generates) because it provides a simple visual display of the two categories we are most interested in: females who have taken some advanced math courses who were raised by either their fathers only, or by both their mother and father. So all in all, what can we say about these two variables? Let’s put our conclusions in APA format: A 2 X 2 contingency table analysis was conducted to assess the relationship between childcare responsibility (father only versus father and mother) and enrollment in advanced math courses (none versus one or more). These variables were significantly related, χ2(1, N = 130) = 9.83, p < .05, Φ = -.28. The percentage of females who took advanced math courses is significantly higher for females who were raised by only their fathers (30%) than for females raised by both their mother and father (8%). Exercise 2 Sometimes instead of getting a complete dataset with individual responses to each item, you might get a frequency table. Let’s see how you can set up these data in SPSS in order to be able to conduct a contingency analysis. This exercise requires creating a weighted case SPSS data file. 7 Research scenario: Bobby is interested in knowing whether teaching method has an effect on interest in subject matter. He randomly assigns 90 high school students enrolled in history to one of three teaching conditions. All 90 students are exposed to exactly the same material for the same length of time. However, 30 students are presented a filmed reenactment of historical events; 30 see an MTV-type video presentation of the events; and 30 are presented the information in the form of a traditional lecture. At the end of the presentation, students were asked whether they found the information interesting. Response options were Highly Interesting, Moderately Interesting, and Not at All Interesting. The data are below: Film (1) Video (2) Lecture (3) Highly (1) 12 4 6 Moderately (2) 10 10 6 Not at all (3) 8 16 18 Let’s see how we would create this dataset in SPSS: Click on Variable View We need to create 3 variables: presentation, rating, and number. For the presentation variable, code as follows: Film = 1, Video = 2, Lecture = 3. For the rating variable, code as follows: Highly interesting = 1, Moderately interesting = 2, Not at all interesting = 3. Click on Data View Now we are going to set up all possible combinations of categories from these two variables. Your SPSS file should look like this: present 1.00 1.00 1.00 2.00 2.00 2.00 3.00 3.00 3.00 rating number 1.00 2.00 3.00 1.00 2.00 3.00 1.00 2.00 3.00 For the number variable, we are going to type in the frequency of occurrences for a particular combination of the presentation/rating variables. For example, for the first row, 1 (film), 1 (highly), the observed frequency = 12. For the second row, 1, 2, observed frequency = 10. Now that we’ve entered in all the data we need, we’ll need to tell SPSS to weight our data. Click Data Select “Weight Cases” 8 Click “Weight Cases by” in the Weight Cases Dialog box Move “number” to the Frequency Variable box. Click OK. Now if you look to the bottom right corner of your SPSS screen, you should see a small box that reads “Weight On” Now let’s run the analysis for our 3 X 3 contingency table (it is a 3 X 3 because we have 2 variables, each of which has 3 levels). Select Analyze Descriptive Statistics Crosstabs Click “present” and move it to the “Rows” box Click “rating” and move it to the “Columns” box This time we don’t need to check the “Display clustered barcharts” box Click “Statistics” and check the box next to “Chi-square” and “Phi and Cramer’s V” Click Continue. Click “Cells” and check the box next to “Expected” (the “Observed” box should already be checked). Also, click “Row” and “Column” in the percentages box. Click Continue. Click OK. Let’s take a second to try and get an idea, descriptively, of what’s going on with our data. PRESENT * RATING Crosstabulation PRES ENT Film Video Lecture Total Count Ex pec ted Count % within P RES ENT % within RATING Count Ex pec ted Count % within P RES ENT % within RATING Count Ex pec ted Count % within P RES ENT % within RATING Count Ex pec ted Count % within P RES ENT % within RATING Highly int eres ting 12 7.3 40.0% 54.5% 4 7.3 13.3% 18.2% 6 7.3 20.0% 27.3% 22 22.0 24.4% 100.0% RA TING Moderately int eres ting 10 8.7 33.3% 38.5% 10 8.7 33.3% 38.5% 6 8.7 20.0% 23.1% 26 26.0 28.9% 100.0% Not at all int eres ting 8 14.0 26.7% 19.0% 16 14.0 53.3% 38.1% 18 14.0 60.0% 42.9% 42 42.0 46.7% 100.0% Total 30 30.0 100.0% 33.3% 30 30.0 100.0% 33.3% 30 30.0 100.0% 33.3% 90 90.0 100.0% 100.0% For students who saw the film, what percentage of them rated the material as Highly Interesting? (40%) Let’s compare this percentage, descriptively, to the percentage of students who heard the lecture and rated the material as Highly Interesting. (20%) 9 Now let’s focus on the “Not at all interesting” ratings across the 3 presentation styles. -What percentage of the “Not at all interesting” ratings comes from the lecture format? (42.9%) -Let’s compare that to the percentage that comes from the film format. (19%) OK, now let’s move on to our chi square test of independence. Chi-Square Te sts Pearson Chi-Square Lik elihood Ratio Linear-by-Linear As soc iation N of Valid Cases Value 9.958a 10.240 4 4 As ymp. Sig. (2-sided) .041 .037 1 .012 df 6.376 90 a. 0 c ells (.0% ) have expected count less than 5. The minimum expected count is 7.33. The chi-square is significant χ2(4, N = 90) = 9.96, p < .05. Symmetric Measures Nominal by Nominal Phi Cramer's V N of Valid Cases Value .333 .235 90 Approx. Sig. .041 .041 a. Not ass uming the null hypothesis. b. Us ing the asymptotic standard error as suming the null hypothesis. We also get an effect size for this significance test. We use Cramer’s V here because we are working with a 3 X 3 contingency table. We only use Φ with 2 X 2 contingency tables, anything else requires Cramer’s V. What’s the difference between this chi square and the one we ran earlier? Most notably, this chi square test has 4 df. What does that mean? 4 df makes this an omnibus test. When you run an omnibus test and obtain p-values < .05, you know there are significant differences between groups somewhere in the data, but you don’t know exactly where. What we’ll need to do now is conduct follow-up tests to determine where in our data the differences are. 10 Follow-up tests are typically conducted according to specific hypotheses. In this particular study, Bobby is most interested in knowing if there are significant differences in ratings between the film and video presentation styles. First let’s test for significant differences in the proportion of ratings between the film and video presentation styles. Click Data Click Select Cases Click “If condition is satisfied” Click “If” Type in present = 1 or present = 2 Click Continue Click OK. Click Analyze Descriptive Statistics Crosstabs. Since we just ran the omnibus test, everything should already be set up for us. Click OK. SPSS does give us a new 2 X 3 contingency table, but we’ll skim over that now in the interest of time. Let’s look at the results for the chi square test of independence. Chi-Square Te sts Pearson Chi-Square Lik elihood Ratio Linear-by-Linear As soc iation N of Valid Cases Value 6.667a 6.904 2 2 As ymp. Sig. (2-sided) .036 .032 1 .011 df 6.466 60 a. 0 c ells (.0% ) have expected count less than 5. The minimum expected count is 8.00. The chi square test is significant, but it is still a 2df test, technically an omnibus test. We’ll have to run more follow-up analyses. Symmetric Measures Nominal by Nominal Phi Cramer's V N of Valid Cases Value .333 .333 60 Approx. Sig. .036 .036 a. Not ass uming the null hypothesis. b. Us ing the asymptotic standard error as suming the null hypothesis. Cramer’s V indicates a medium effect size. 11 Since Bobby is most interested in the differences between the film and video groups, let’s run follow-up analyses for these two groups. We’ll compare the proportion of “Highly Interesting” versus “Not at all Interesting” ratings for the film and video presentations. Click Data Select Cases Click If condition is satisfied Click “If” Type in (present = 1 or present = 2) and (rating = 1 or rating = 3) Click Continue Click OK. Click Analyze Descriptive Statistics Crosstabs. Everything should be ready to go. Click OK. Again, SPSS will give you a new 2 X 2 contingency table which I have omitted for the sake of brevity. Chi-Square Tests Pearson Chi-Square Continuity Correction a Likelihood Ratio Fis her's Exact Test Linear-by-Linear As sociation N of Valid Cases Value 6.667b 5.104 6.904 df 1 1 1 6.500 1 As ymp. Sig. (2-sided) .010 .024 .009 Exact Sig. (2-sided) Exact Sig. (1-sided) .022 .011 .011 40 a. Computed only for a 2x2 table b. 0 cells (.0%) have expected count less than 5. The minimum expected count is 8.00. The chi square test is significant. Importantly, we have gotten our follow-up analyses down to a 1df test, so we know exactly where the significant differences lie. Symmetric Measures Nominal by Nominal Phi Cramer's V N of Valid Cases Value .408 .408 40 Approx. Sig. .010 .010 a. Not ass uming the null hypothesis. b. Us ing the asymptotic standard error as suming the null hypothesis. We’ll need to go back to our original 3 X 3 contingency table in order to interpret our results. 12 Based on the percentages we see here, it appears that students are more likely to rate the film, as compared to the video, as highly interesting. But exactly how much more likely? Let’s compute the odds ratio here to see. PRESENT * RATING Crosstabulation PRES ENT Film Video Lecture Total Count Ex pec ted Count % within P RES ENT % within RATING Count Ex pec ted Count % within P RES ENT % within RATING Count Ex pec ted Count % within P RES ENT % within RATING Count Ex pec ted Count % within P RES ENT % within RATING Highly int eres ting 12 7.3 40.0% 54.5% 4 7.3 13.3% 18.2% 6 7.3 20.0% 27.3% 22 22.0 24.4% 100.0% RA TING Moderately int eres ting 10 8.7 33.3% 38.5% 10 8.7 33.3% 38.5% 6 8.7 20.0% 23.1% 26 26.0 28.9% 100.0% Not at all int eres ting 8 14.0 26.7% 19.0% 16 14.0 53.3% 38.1% 18 14.0 60.0% 42.9% 42 42.0 46.7% 100.0% Total 30 30.0 100.0% 33.3% 30 30.0 100.0% 33.3% 30 30.0 100.0% 33.3% 90 90.0 100.0% 100.0% Now let’s calculate the odds ratio: 12/10+8 = 12/18 = 4.34 4/10+16 4/26 We would interpret this as follows: The odds of rating the material as highly interesting when seeing the film are 4.34 times higher than the odds of rating the material as highly interesting when seeing the video. We’ve run all of the analyses we are interested in for the time being. PLEASE NOTE: we have only conducted a small subset of all possible follow-up tests for the sake of time. If we had no specific hypotheses regarding differences between groups, we would likely have conducted ALL possible follow-up tests. Let’s pull our results together in APA format. A 3 X 3 contingency table analysis was conducted to assess the relationship between type of presentation (film, video, lecture) and interest ratings of the material presented (highly interesting, moderately interesting, not at all interesting). The two variables were significantly related, χ2(4, N = 90) = 9.96, p < .05, Cramer’s V = .24. Follow-up tests were conducted to evaluate the differences among the film and video presentation styles. 13 The proportions differed significantly between these two presentation styles, χ2(2, N = 60) = 6.67, p < .05, Cramer’s V = .33. A final pairwise comparison conducted to evaluate the differences between the ratings of “highly interesting” and “not at all interesting” for the film versus video presentation styles was significant, χ2(1, N = 40) = 6.67, p < .05, Cramer’s V = .41. The odds of rating the material as highly interesting when seeing the film are 4.34 times higher than the odds of rating the material as highly interesting when seeing the video. Remember that the analyses we have conducted here today are really an abbreviated version of the analyses we would conduct in real life if we had more time. You might very well run all possible follow-up analyses, which would look like this: 2df tests Film vs video (present = 1 or present = 2) Film vs lecture (present = 1 or present = 3) Video vs lecture (present = 2 or present = 3) * 1df tests Film vs video (present = 1 or present = 2) AND - high vs moderate (rating = 1 or rating = 2) Film vs video (present = 1 or present = 2) AND - high vs not (rating = 1 or rating = 3) Film vs video (present = 1 or present = 2) AND - moderate vs not (rating = 2 or rating = 3) Film vs lecture (present = 1 or present = 3) AND - high vs moderate (rating = 1 or rating = 2) Film vs lecture (present = 1 or present = 3) AND - high vs not (rating = 1 or rating = 3) Film vs lecture (present = 1 or present = 3) AND - moderate vs not (rating = 2 or rating = 3) Video vs lecture (present = 2 or present = 3) AND - high vs moderate (rating = 1 or rating = 2) Video vs lecture (present = 2 or present = 3) AND - high vs not (rating = 1 or rating = 3) Video vs lecture (present = 2 or present = 3) AND - moderate vs not (rating = 2 or rating = 3) *If you actually ran this set of analyses you’d find that the difference between video and lecture presentation styles is not significant. Therefore, you would NOT go on to conduct the focused 1df follow-up tests.