Chapter 8 Appendix: Forecasting
advertisement

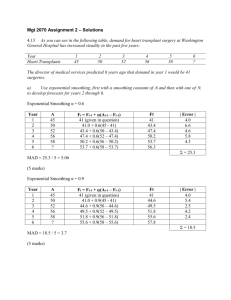
Chapter 8 Appendix: Forecasting Think of what you could accomplish if you could see the future. Of course, no one can truly predict future events. However, in many situations a forecast can provide a good idea of the possibilities. Of course, forecasting patterns for the near future is much easier than predicting what might happen several years out. Forecasting is used in many areas of business. Marketing forecasts future sales, the effect of various sales strategies, and changes in buyer preferences. Finance forecasts future cash flows, interest rate changes, and market conditions. The HRM department builds forecasts of various job markets, the amount of absenteeism, and labor turnover. Strategic managers forecast technological changes, actions by rivals, and various market conditions. Sometimes these forecasts are built on intuition and rules of thumb. But, it is better to use statistical techniques whenever possible. The science of forecasting is dominated by P S two major approaches: time-series forecasting that identifies trends over time, and structural modeling that identifies relationships among the underlying D’ D variables. Many forecasts require the use of both Q Figure Error! No text of specified style in document..1A Structural model forecast. The underlying model helps explain the causal relationships, making it easier to forecast the effect of changes. Here, an increase in income shifts the demand curve, which causes increased sales (Q) even at higher prices. techniques. As shown in Figure 8.1A, by focusing on the underlying model, structural modeling seeks to identify the cause of changes. For example, if consumer income increases, the demand for our product shifts out, which results in more sales. If we know the shapes of the supply and demand curves, it is straightforward to predict how sales will increase. Figure 8.2A shows a time-series-approach to sales trend the same issue of sales forecasting. In some ways it is simpler. We know nothing about the underlying model and have simply collected sales data for the past few months. The data is plotted over time. By time Figure Error! No text of specified style in document..2A Time series forecast. Sales change over time. The trend line provides a forecast of future values. But it assumes that underlying factors behave as they did in earlier times. fitting a trend line to the data, it is clear that sales are increasing. Assuming that this trend continues, it is easy to forecast sales for the next period. It is often tempting to say that structural models are “better” than time series forecasts. After all, the model provides an understanding of the causal relationships. So we know that the increase in sales is occurring because of increasing consumer income. While this knowledge is valuable, the structural model does not tell us how fast income will increase in the next period. Hence, we end up using time-series techniques to estimate the trends in consumer income. Consequently, we need both techniques. As much as possible, find a structural model to explain the problem. Then use time-series methods to estimate the underlying trends. Plug these forecasts into the structural model to determine the outcome of the desired variables. Structural Modeling Modeling an underlying structure provides the most information and knowledge about a problem. Consider a simple physics problem: If you throw a ball at a certain angle, with a certain force, how far will it travel? You could try several experiments, timing each event and measuring the outcome. You could then use this data to make a forecast of future attempts. However, if you know the underlying model of gravity (e.g., Newton’s equations), then it is easy to determine the outcome of any attempt. Many economic models have been developed to determine relationships that apply to business decisions. For instance, cost models are used to determine supply relationships, and consumer preferences generate demand curves. Demand for a product can be expressed as a function of several variables: price, income, and prices of related products. These relationships can be estimated with common statistical techniques (e.g., multiple regression). Figure 8.3A presents the Model QD = b0 + b1 Price + b2 Income + b3 Substitute basic steps in using a structural Quantity Price Income Substitute 1 24926 134 20000 155 Data 2 26112 150 21000 155 model to forecast sales demand. 3 27313 142 22000 135 4 26143 141 21000 150 5 26741 144 21500 150 First you need a model—in this Estimate QD = 11146 - 0.126149 Price + 1.2 Income -21000 1.0 Substitute 137 155 7 27893 140 22500 143 case, a basic economic model. Forecast 33318 = 1114 - 26397 0.1 (155) + 1.2 - 1.0 (160) 8 142 (20000) 21200 153 9 24895 147 20000 155 Figure Error! No text specified148 style 23000 in 10 of 28501 160 Then you need to collect data for 11 29747 150 24000 165 document..3A 12 29175 134 23500 153 Forecasting process using 13 a structural Collect23700 data and use158 each of the variables in the 29413model.142 regression to estimate the 14 underlying plug in 162 30348parameters. 147 Then 24500 estimates of the future values the independent 15 of 32148 150 variables 26000 to forecast 163 model. It is best if the underlying 33327 152 27000 164 the value of the dependent16variable (quantity). 17 34532 158 28000 165 34775 28200 observations 160 variables change over18time, and you162 will need from several points in time. It is 19 33372 157 27000 155 20 32681 155 26500 160 Time best to have at least 40 observations, but you get better results with more data. Next you use regression analysis to estimate the values of the model parameters. Finally, you plug in estimates of the independent variables to obtain a forecast of the future sales. Time-Series Forecasts When you do not have a structural model, or when you need to forecast the value of an underlying variable, you can use time-series techniques to examine how variables change over time. The basic process is to collect data over time, identify any patterns that exist, and then extrapolate this pattern for the future. The approach assumes that the underlying pattern will remain the same. For example, if income has been gradually increasing over time, it assumes that this increase will continue. Figure 8.4A shows a time sales series consists of a number of observations made over a period of Seasonal Trend time. Four types of patterns often arise in time-series data: (1) trends, time Dec Dec Dec (2) cycles, (3) seasonal variations, Dec Figure Error! No text of specified style in document..4A Time series components. A trend is a gradual change over time. Seasonal patterns show up as peaks and troughs at annual intervals. Other cycles are similar but cover longer time periods and are usually less regular. Random change is shown because the cycle and trend are not perfect. and (4) random changes. A trend is a gradual increase or decrease over time. A cycle consists of up and down movements relative to the trend. Seasonal variations arise in many disciplines. For instance, agricultural production increases in the summer and fall seasons, and many industries experience an increase in sales in November and December due to holiday sales. Random components are variations that we cannot explain through other means. In some cases, the random component dominates the others, and forecasting is virtually impossible. For example, many people believe this situation exists for stock market prices. Exponential Smoothing Random variations make it difficult to see the underlying trend, seasonal, and cyclical components. One solution is to remove these variations with exponential smoothing. Exponential smoothing computes a new data point based on the previously computed value and the newly observed data value. The weight given to each component is called the smoothing factor. The higher the smoothing factor, the more weight that is given to the new data point. Typical values range from 0.2 to 0.30, although it is possible to use factors up to 1.0 (which would consider only the new value and ignore the old ones). Lower values (down to 0.01) put more weight on previous computations and result in a smoother estimate. Current spreadsheets (e.g., Exponential Smoothing Microsoft Excel) have procedures 1600 1500 that will quickly estimate the 1400 1300 Raw Data 1200 1100 1000 Smooth:0.20 moving average for a range of data. You simply mark the range of data, 900 800 1 3 5 7 9 11 13 15 17 19 21 highlight the output range, and supply the smoothing factor. As Figure Error! No text of specified style in document..5A Exponential smoothing. The smoothed data is computed by Excel by applying a smoothing factor to each new data point. shown in Figure 8.5A, it is then easy to graph the original and the smoothed data. How do you choose the smoothing factor? The best method is to apply several smoothing factors (start with 0.10, 0.20, and 0.30), and then examine the accuracy of the result. The accuracy is typically measured as the sum-of-squared errors. For each smoothed column of data, compute (actual – smoothed)*(actual – smoothed) to get the squared-error on each row. Add these values to get the Double Exponential Smoothing total. Now compare these totals for each 34000 of the smoothing factors. The smoothing 32000 30000 28000 Raw Data 26000 Smooth:0.20 factor with the smallest error is the one 24000 22000 to use. 20000 1 3 5 7 9 11 13 15 17 19 In practice, most data will have a Figure Error! No text of specified style in document..6A Double exponential smoothing. When there is a trend, you need to smooth the data a second time. trend component. In these cases, you need to use double exponential smoothing. Perform the first smoothing as usual and find the best smoothing factor. Then perform a second smoothing on the new (smoothed) column of data using the same smoothing factor. Figure 8.6A shows that the result follows the basic trend line but still incorporates the cyclical variations in the data. The smoothed data can be used Forecast for time T+ [ 2] yT 2 S T 1 ST 1 1 T = 20 =1 = 0.2 S20 = 32,064 last of the raw data forecast one period ahead smoothing factor (value at time 20, after one smoothing) S[2] = 33,141 (value at time 20, after second smoothing) Y21 = (2.25)32,064 - (1.25)33,141 = 30,718 to forecast the dependent variable for future periods. It is wise to stick with forecasts only one or two periods ahead. Longer range forecasts are less likely to be accurate. The basic formula is given Figure Error! No text of specified style in document..7A in Figure 8.7A. You need the smoothing Forecasting with double exponential smoothing. Plug your values into this formula to estimate future values of the data. factor () and the number of time periods ahead to forecast (). Then you take the smoothed values at the last data point (single and double) and plug them into the formula. The result is a forecast that incorporates a linear trend Time Quantity Trend Difference 1 24917 24484 432 2 26152 24983 1169 3 27297 25482 1816 4 26157 25980 177 5 26710 26479 231 6 26103 26977 -874 7 27981 27476 505 8 26327 27975 -1647 9 24913 28473 -3560 10 28524 28972 -448 11 29774 29470 303 12 29136 29969 -833 13 29332 30468 -1136 14 30306 30966 -660 15 32133 31465 669 16 33329 31963 1366 17 34522 32462 2060 18 34769 32961 1808 19 33355 33459 -104 20 32684 33958 -1274 21 34456 22 34955 23 35454 24 35952 along with the basic cyclical Yt = b0 + b1(t) Use regression to estimate b0 and b1. Intercept Time Coefficients Std Error t Stat P-value 23985.81 652.48 36.76 2.2E-18 498.60 54.47 9.15 3.4E-08 Plug t into equation to estimate new value (on trend): variations in the data. If you want a forecast that utilizes only the trend (and none of the Y21 = 23,986 + 498.6 * (21) = 34,456 cyclical variations), you can Result is the prediction on the trend, with no random factors and no cycles. use a simple regression Figure Error! No text of specified style in document..8A Forecasting with linear trends. Use regression to estimate the two parameters. Then plug in the desired time value to obtain the predicted trend value for any new time period. technique. Use standard regression techniques with the observed data as the dependent (Y) variable and time (t) as the independent variable. Then use the computed parameters to estimate the predicted value at any future point in time. Again remember that linear trends may not continue for extended time periods, so keep your predictions down to a few periods. Figure 8.8A illustrates the process, using Excel to obtain the regression coefficients. The result is the prediction along the trend line, which ignores cyclical variations. Once you compute the trend factor, you can subtract it from the original series to identify the cyclical, seasonal, and random components. Use the spreadsheet to plug in values for each time period and compute the trend line. Then subtract these values from the original series. If you plot the new series, you will see the data without the trend. It should be easier to see seasonal and cyclical patterns on this new chart. Seasonal and Cyclical Components Two powerful methods exist to decompose time series data into its trend, seasonal, and cyclical components. They are Box-Jenkins and Fourier analysis. You can purchase tools that will perform the complex calculations for these methods. Unfortunately, it would take many pages to describe either one of these techniques, so they are beyond the scope of this appendix. Just remember that it is possible to perform much more detailed analyses (and forecasts) of time series data. If you need them, hire an expert, or take a separate class in time series forecasting. Exercises 1. Obtain a three-year set of monthly data from the Bureau of Labor Statistics Web site (http://stats.bls.gov) that is not seasonally adjusted (e.g., Producer Price Index). Transfer the data to a spreadsheet. Plot the data and include a trend line. Sales data for the remaining exercises Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 1998 414 382 396 530 551 396 365 415 424 485 684 802 1999 457 432 465 598 632 424 392 476 489 555 768 883 2000 505 477 534 636 696 466 442 506 531 610 825 973 2. Plot the sales data from the table. Draw one graph with a trend line and a second chart with three-period exponential smoothing. 3. Using the regression functions in the spreadsheet, estimate the trend line and produce a forecast for four periods ahead. 4. Use double exponential smoothing (damping of 0.3) and plot the new data. 5. Use the formula in Figure 8.7A to forecast sales for the next four periods using double exponential smoothing.