An introduction to Multiple Regression
advertisement

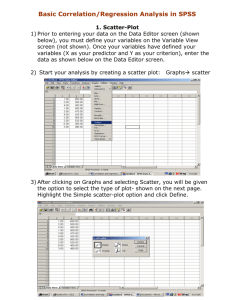
An Introduction to Multiple Regression Life is complex and one variable alone is usually not able to explain a social problem. For example, child abuse may have multiple factors that are associated with it, including: Family level of stress Family income Child’s age Parent’s age Degree of social isolation Parenting skills Quality of support system Parent’s coping skills Family size These variables are called predictor variables, and knowledge of the extent to which they exist can be helpful in predicting the likelihood that child abuse will occur. We choose predictor variables based on theory, prior research, and on our experience. Some predictor variables (independent variables) are more important than others, that is, they have a stronger relationship to what is being predicted (the dependent variable). We might also say that they explain more of the variance in the dependent variable. All of the predictor variables taken together may be more helpful than any one predictor variable by itself. The combination of predictor variables that we believe are important in predicting the dependent variable is sometimes called a model. For example, knowing a family’s level of stress, income, and support system may be more helpful in predicting child abuse than just knowing the income alone. Finally, we rarely have perfect prediction with our list of predictor variables. Other things not considered or measured may also influence the likelihood of child abuse, for example, whether the parent previously experienced abuse as a child, the parent’s involvement with drugs and alcohol, the child’s temperament, and even random events that cause stress or anger. Finally, some things are simply not useful in predicting child abuse. They explain little or none of the variance in child abuse, for example, the child’s hair color, the parent’s political affiliation, and the number of movie theaters in the neighborhood. Knowing which variables are good predictor variables is very useful in making decisions about how to handle child abuse cases. It helps to better prioritize who receives immediate and intensive services and which services are most useful in developing an intervention plan. Research for Effective Social Work Practice by Judy L. Krysik and Jerry Finn © 2010 Routledge / Taylor & Francis Multiple regression is a statistical procedure that finds the relationship between several independent or predictor variables and a dependent or criterion variable. Multiple regression is based on a number of assumptions that include: Data are at the interval or ratio level. The relationship between the independent and dependent variables is linear. Scores should be normally distributed and vary about equally (homoscedasticity). Independent variables should not correlate highly with each other, no more than about .60 (otherwise, they may simply be two measures of the same thing). There is sufficient sample size. It is recommended that there be at least 10 to 20 cases (observations) for each variable in the analysis (Cohen & Cohen, 1983). Multiple regression is based on multiple correlation. As noted above, several variables may be used as predictor variables. The correlation of these combined variables may be higher than the correlation of any one predictor variable. For example, a child’s self-esteem may be predicted by the number of friends the child has, as well as the score on a Family Relationships scale. The Family Relationship Scale correlates .70 with selfesteem; Number of Friends correlates .51. In this case, Family Relationship is a stronger predictor than Number of Friends. The correlation of the combination of the predictors and the dependent variable is known as multiple R; R is called the coefficient of multiple correlation. The combination of Family Relationship and Number of Friends may correlate more highly than either variable alone, R = .84. Notice that multiple R is not just the addition of two predictor variables. The simple addition of the variables is 1.21 (.70 +.51), an impossible score for correlation, which has values only between -1 and 1. The reason that R is .84 is because some of the variance explained by each predictor variable is accounted for by the correlation of Family Relationships and Number of Friends; in other words, children with good family relationships also have a higher number of friends. Each variable, however, independently accounts for some of the variance in self-esteem. To summarize, if we know both the Family Relationship score and the Number of Friends, we can predict self-esteem better than if we know only one of the predictor variables. Finally, R² is a measure of how much of the variance is Research for Effective Social Work Practice by Judy L. Krysik and Jerry Finn © 2010 Routledge / Taylor & Francis accounted for by the multiple correlation. In this case, R² = .71; 71% of the variance in self-esteem can be explained by the combination of the two predictor variables. Reading Multiple Regression Tables Statistical programs return a number of statistics when computing multiple regression. SPSS, for example, first calculates multiple R. The significance of multiple R is tested with the F statistic. If the p-value of the F test is <.05, then the correlation is greater than zero and the result in not likely due to sample error. In addition, multiple regression returns beta coefficients (b). Beta coefficients allow prediction of the dependent variable given the independent variable score. Multiple regression also produces standardized beta (β) scores. These indicate the strength and direction of the association (correlation). For example, Age and Income are used to predict Health Status (a scale in which higher scores indicate better health). A beta score of 1.45 for Age (b_Age) tells us the impact of every additional year. For each additional year, the Health Status score will be 1.45 points higher. If b_Income is .23, that indicates that for each additional dollar of income, the Health Status score will be .23 higher. The standardized betas are ß_Income = .66 and ß_Age = .24. This indicates that Income is almost three times as strong a predictor as Age. Case-in-Point – Predicting Life Satisfaction What factors are associated with a happy life? What is more important to life satisfaction - health or self-esteem? Is life satisfaction related to age or gender? In this example, a random sample of 100 parents was selected from a Pennsylvania school district. Parents were given several self-report scales. The dependent variable was Life Satisfaction. The predictor variables were the Health Scale, Self-Esteem Scale, Gender, and Age. The null hypothesis is: There is no relationship between the predictor variables and Life Satisfaction. Note that the scales are interval level data, but Gender is a nominal level variable. A nominal level variable can be used in multiple regression when a dummy variable is created. A dummy variable is one in which the attributes are measured as either the presence or absence of the variable, coded 1 and 0. Gender is coded so that “Female” is 1 and “Male” is 0. Male is considered the absence of Female. Research for Effective Social Work Practice by Judy L. Krysik and Jerry Finn © 2010 Routledge / Taylor & Francis When a dummy variable is created, it has the properties of a ratio scale since there is a true zero and the attributes are equally spaced. A multiple regression in SPSS produces the following tables: Model Summary Model 1 R R Square Adjusted R Square Std. Error of the Estimate .846(a) .716 .704 7.58729 a Predictors: (Constant), Gender, AGE, Health Scale, Self Esteem Scale The first table indicates the strength of the model, that is, how well all of the variables together predict Life Satisfaction. In this case, the multiple correlation R = .85 and the amount of variance explained by the model is R²=.72 (.85 X .85). There is also a result “Adjusted R Square”. Mathematicians have found that the R² slightly overestimates the amounted of explained variance and have computed an adjustment that more accurately show the amount of explained variance. When reporting R², it is more conservative to report the adjusted R Square. The SPSS output also produces an ANVOA table to indicate if the result is likely due to sample error and whether the explained variance is greater than zero. ANOVA(b) Model 1 Regression Residual Sum of Squares 13807.15 5468.85 4 Mean Square 3451.786 95 57.567 df F 59.961 Sig. .000(a) Total 19276.00 99 a Predictors: (Constant), Gender, AGE, Health Scale, Self Esteem Scale b Dependent Variable: Life Satisfaction Scale In this case F is 59.56 and the p-value is .00, indicating that there is very little likelihood that the relationship is greater than zero and the result is probably not due to sample error. Since our model explains 72% of the variance in Life Satisfaction, the combination of predictor variables is quite useful in predicting or explaining Life Satisfaction. But which variables are the strongest predictors? Which are significant predictors? The next table reports the beta values and standardized beta values. Looking first at the two right columns, the t-test and significance level indicate that only SelfEsteem and Health are statistically significant predictors of Life Satisfaction since the pResearch for Effective Social Work Practice by Judy L. Krysik and Jerry Finn © 2010 Routledge / Taylor & Francis value is <.05. Age and Gender are not associated with Life Satisfaction more than would be expected by sample error or chance. The Standardized Coefficients (ß) indicate that Self Esteem (.669) is about twice as strong predictor of Life Satisfaction than is Health (.281). Finally, the unstandardized coefficients (b) indicate the relationship between scores. For Self Esteem, b .75 means that for each point increase in Self Esteem, there is a .75 increase on the Life Satisfaction score. Similarly, for each point increase on the Health scale, there is a .74 increase on the Life Satisfaction scale. We can conclude the following in considering life satisfaction: High self-esteem and good health are import factors in determining who will have a satisfying life. These factors together explain about 70% of the difference between people regarding life satisfaction. A person’s age and gender make no difference in life satisfaction. 30% of the variance (differences between people) is not accounted for by our model. Other factors such as income, family relationships, education, support system, and many others should be investigated. We must also consider the following when considering life satisfaction: The small sample of parents in Pennsylvania is not representative of the people in the United States. Perhaps this model only applies in certain areas of Pennsylvania. Self esteem and good health do not cause someone to have high life satisfaction. Something else may account for both high self-esteem and good health, for example, income. High self-esteem and good health are not necessary for life satisfaction. While this research indicates that they are associated with life satisfaction, we do not have perfect prediction. Some people may have low self esteem and poor health and still report a satisfying life. Research for Effective Social Work Practice by Judy L. Krysik and Jerry Finn © 2010 Routledge / Taylor & Francis No doubt, further research is needed. Research for Effective Social Work Practice by Judy L. Krysik and Jerry Finn © 2010 Routledge / Taylor & Francis