ModILecture4cont
advertisement

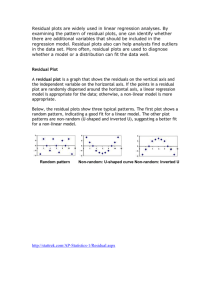
` The last stage of a regression analysis is to assess the adequacy of the model. In order to do this, we need to examine the components of the model which are purely statistical, i.e. the residual terms ei. To see why this is necessary, consider the four data sets in the EXCEL worksheet “Tufte.xls” which you will find in the EXCEL folder MBA Part 1. All four of these data sets lead to exactly the same values of the regression coefficients and se. In addition the y values and x values all have the same means and standard deviations. However when you do the regression and examine the automatic residual graph you get very different results. Consider the residual plot below: Residual Plot 1.5 1 Residuals 0.5 0 3 4 5 6 7 -0.5 -1 -1.5 -2 -2.5 X 8 9 10 11 Now consider the next residual plot: Residual Plot 3.5 3 2.5 Residuals 2 1.5 1 0.5 0 3 4 5 6 7 -0.5 -1 -1.5 X 8 9 10 11 Now consider the third plot: Residual Plot 2.5 2 1.5 Residuals 1 0.5 0 5 6 7 8 9 -0.5 -1 -1.5 -2 X 10 11 12 13 Finally consider the fourth residual plot: Residual Plot 2.5 2 1.5 Residuals 1 0.5 0 -0.5 3 4 5 6 7 -1 -1.5 -2 -2.5 X 8 9 10 11 For our electrical data, the residual plot looks like the following: Residual Plot 1500 Residuals 1000 500 0 -500 0 200 400 600 -1000 -1500 DD 800 1000 EXCEL also provides a plot of the actual values of y and the predicted values for each value of x. This is illustrated below: KWH DD Line Fit Plot 8,000 7,000 6,000 5,000 4,000 3,000 2,000 1,000 - KWH Predicted KWH 0 500 DD 1000 Since our model looks like it fits the data, we can try to use it to predict kilowatt hour usage using degree days as a predictor. The basic equation would be: Predicted KWH usage = 903.515 + 7.089 x (degree days). Thus for a billing period with 100 degree days (possibly a period in the spring or autumn in Dallas), the predicted KWH usage would be 1,612 KWH. This “point” estimate ignores variability. However we can use the results discussed earlier about the “mound” rule and Chebyshev to incorporate variability into our forecasts to get what is called an “interval” forecast. In this case, the formula is given by: Forecast b̂0 b̂1 x 2 se In the case discussed above for a billing period of 100 degree days, the interval forecast would be: 1612 +/- 2*(605.9) or approximately 400 KWH to 2,824 KWH. Although the above method is the most practical way to assess the adequacy of a model for forecasting purposes, it is common to use a single descriptive measure called the “correlation coefficient” to describe the adequacy of the regression fit. The correlation coefficient attempts to quantify how useful x is as a predictor of y. If one were not to use x in the forecasting of y, then one would guess the mean value of y as the forecast of kilowatt hours for each period. If one defines the error made as: i th error yi y and, SST ( y i y ) 2 i SST is a measure of the total errors made not using x as a predictor. If we use x, then we can define the error made as: êi yi b̂0 b̂1 xi and, SSE ê i 2 i SSE is a measure of the total errors made using x as a predictor. One can show that, 0 SSE SST Therefore, 0 SSE 1 SST If we define, R 2 1 SSE SST then, 0 R2 1 By rewriting the definition of R2 as: R 2 ( SST SSE ) / SST One can interpret R2 as the proportion of the variability in y explained (or eliminated) by using x as a predictor As we shall see, all of the above generalizes to the case where one has more than one x as a predictor. In the case however of a single x predictor, one usually encounters the correlation coefficient r defined as: r sign( b̂1 ) R 2 In our case R2=.8538, and r=.9240. Both of these values can be found on the EXCEL as highlighted below: A natural question is how big does R2 have to be in order for the regression analysis to be useful? I would suggest that the important measure is the usefulness of the interval forecast.