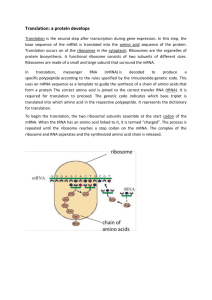
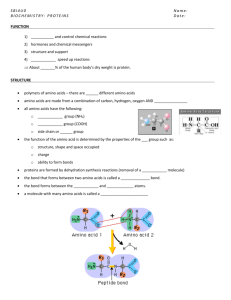
Lecture 3-Translation of mRNA
advertisement

Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 Lecture 3: Translation of mRNA Signals for Recognition of mRNA by Ribosomes in Prokaryotes and Eukaryotes. In prokaryotes, the Shine-Delgarno sequence is recognized and base-paired by the 16S ribosomal RNA in the small ribosomal subunit. This places the start codon (AUG) in the right place within the ribosome for translation to begin. In eukaryotes, the small ribosomal subunit recognizes the 5’ cap on the mRNA. (This is actually mediated by cap binding proteins - not shown). The ribosome then scans down the mRNA and finds the correct start codon for that gene. http://www.ncbi.nlm.nih.gov/books/bv.fcgi?rid=cooper.figgrp.1177 I. Overview of Translation The translation of the mRNA codons into amino acid sequences leads to the synthesis of poypeptides, which then fold and/or aggregate to form functional molecules called proteins. The word “translation” is well-chosen because the chemical language of nucleic acids (in mRNA) is being changed into the chemical language of polypeptides during the process. Page 1 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 Proteins are the active participants in cell structure and function. They are the “work horses” of the cell The main function of the genetic material is, therefore, to encode the production of cellular proteins in the correct cell, at the proper time, and in suitable amounts II. Early Experiments A. Archibald Garrod (early 20th Century) Was the first to propose a relationship between genes and protein production Garrod studied patients who had defects in their ability to metabolize certain compounds He was particularly interested in alkaptonuria o Patients bodies accumulate abnormal levels of homogentisic acid (alkapton) o Disease characterized by black urine and bluish-black discoloration of cartilage and skin He proposed that alkaptonuria was due to a missing enzyme, namely homogentisic acid oxidase Garrod also knew that alkaptonuria follows a recessive pattern of inheritance … He thus proposed that a relationship exists between the inheritance of the trait and the inheritance of a defective enzyme o He described the disease as an “inborn error of metabolism” B. Beedle and Tatum (early 1940s) George Beadle and Edward Tatum were also interested in the relationship among genes, enzymes and traits o They specifically wanted to know whether each gene coded for a single enzyme or whether each gene coded for many enzymes Their genetic model was Neurospora crassa (a common bread mold) o Their studies involved the analysis of simple nutritional requirements Page 2 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 They analyzed more than 2,000 strains that had been irradiated to produce mutations They found three strains that were unable to grow on minimal medium. However, in each case, growth was restored if only a single vitamin is added to the minimal medium 1st strain Pyridoxine 2nd strain Thiamine 3rd strain p-aminobenzoic acid In the normal strains, these vitamins were synthesized by cellular enzymes o In the mutant strains, a genetic defect in one gene prevented the synthesis of one protein required to produce that vitamin o Beadle and Tatum’s concluded that a single gene controlled the synthesis of a single enzyme This was referred to as the “one gene–one enzyme theory” In later decades, this theory had to be modified in two ways: 1. Enzymes are only one category of proteins 2. Some proteins are composed of two or more different polypeptides The term polypeptide denotes structure The term protein denotes function For example: Adult hemoglobin is coded by two genes: alpha-globin and beta-globin. Two alphaglobin polypeptides (AKA subunits) and two beta-globin polypeptides must fold properly and then bind together to make functional hemoglobin. Page 3 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 B. Khorana (early 1960s) The Genetic Code, which links the sequence of nucleotides in an mRNA to the sequence of amino acids in a polypeptide, was deciphered in the early 1960s More than one set of experiments were performed Only the research performed by a team led by Gobind Khorana will be described here Gobind Khorana and his collaborators developed a novel method to synthesize RNA They first created short RNAs (2 to 4 nucleotide long) that had a defined sequence These were then linked together enzymatically to create long copolymers They used these copolymers in a cell-free translation system to see what polypeptides were made o For example, when a copolymer of “UC” was made: UCUCUCUCUCUCUCUCUCUC was translated as either serine or leucine. This meant that UCU and CUC must code for these two amino acids Page 4 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 III. Characteristics of the Genetic Code 1. It is a Triplet Code Since life uses 20 amino acids, biologists reasoned that the genetic code must contain at least 3 letters o A one-letter code could only encode 4 amino acids o A two-letter code could only encode 16 amino acids o A three-letter code could encode 64 amino acids – more than enough Khorana’s team provided experimental support for a 3-letter code Each 3-letter combination is called a codon The code is arbitrary but must have been adopted very early in the evolution of life since all organisms use almost the same code 2. It has START and STOP codons Page 5 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 AUG (which specifies methionine) = start codon o AUG also specifies additional methionines within the coding sequence UAA, UAG and UGA = termination, or stop, codons 2. It is degenerate More than one codon can specify the same amino acid o For example: GGU, GGC, GGA and GGG all code for lysine In most instances, the third base is the degenerate base o It is sometime referred to as the wobble base 3. The code is (nearly) universal All living organisms use the same code o Only a few rare exceptions have been noted, and these are thought to have evolved after the code was first established 4. All nucleotides are read only once Once translation has begun, nucleotides in the mRNA are read in successive triplets (codons) o Nucleotides are never skipped or read more than once The figure below illustrates the process of translation of an mRNA using the Genetic Code. Page 6 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 Note that the mRNA begins with a 5’ untranslated region o In other words, the START codon is not at the 5’ end of the mRNA but somewhat downstream (3’) o Although it is not shown here, the STOP codon is likewise not at the 3’ end of the mRNA. There is a 3’ untranslated region after it. IV. Protein Structure There are four levels of structures in proteins: 1. Primary Is it’s amino acid sequence Within the cell, the protein will not be found in this linear state Rather, it will adapt a compact 3-D structure Indeed, this folding can begin during translation The progression from the primary to the 3-D structure is dictated by the amino acid sequence within the polypeptide The amino acid sequence of the enzyme lysozyme 129 amino acids long Page 7 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 There are 20 amino acids that may be found in polypeptides o Each contains a different side chain, or R group Non-polar amino acids hate water and are usually found buried together deep inside a protein or in regions that span the plasma membrane of various organelles or the cell itself Polar amino acids like water and are often found on the surface of proteins. Page 8 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 2. Secondary The primary structure of a protein folds to form regular, repeating shapes known as secondary structures o There are two types of secondary structures a helix b sheet o These are stabilized by the formation of hydrogen bonds between atoms along the “backbone” of the polypeptide 3. Tertiary The short regions of secondary structure in a protein fold into a threedimensional tertiary structure o This is the final conformation of proteins that are composed of a single polypeptide o The tertiary structure is stabilized via interactions between R groupd of the amino acids Ionic bonds Hydrophic interactions Disulfide bonds Hydrogen bonds Van der Waals forces 4. Quaternary Proteins made up of two or more polypeptides have a quaternary structure o This is formed when the various polypeptides associate together to make a functional protein o Often stabilized by disulfide bonds See Figure 13.6, Brooker V. tRNA Structure and Function A. The Adaptor Hyothesis Page 9 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 In the 1950s, Francis Crick and Mahon Hoagland proposed the adaptor hypothesis, which hypothesized that tRNAs play a direct role in the recognition of codons in the mRNA. In particular, the hypothesis proposed that tRNA has two functions: 1. Recognizing a 3-base codon in mRNA 2. Carrying an amino acid that is specific for that codon to the translation machinery During mRNA-tRNA recognition, the anticodon in tRNA binds to a complementary codon in mRNA: tRNAs are named according to the amino acid they bear Proline anticodon B. tRNA Secondary Structure The secondary structure of tRNAs exhibits a cloverleaf pattern containing: Three stem-loop structures: o Variable region o An acceptor stem (amino acid binding site) o 3’ single strand region (anti-codon) The actual three-dimensional or tertiary structure involves additional folding See Figure 13.10, Brooker Page 10 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 C. Modified Nucleotides and the Wobble Hyothesis In addition to the normal A, U, G and C nucleotides, tRNAs commonly contain modified nucleotides More than 60 of these can occur As mentioned earlier, the genetic code is degenerate With the exception of serine, arginine and leucine, this degeneracy always occurs at the codon’s third position o To explain this pattern of degeneracy, Francis Crick proposed in 1966 the wobble hypothesis o In the codon-anticodon recognition process, the first two positions pair strictly according to the A – U /G – C rule o However, the third position can actually “wobble” or move a bit, thus tolerating certain types of mismatches The modified nucleotides in the tRNA anticodon allow this “wobbling” to occur. VI. The Ribosome Translation occurs on the surface of a large macromolecular complex termed the ribosome A ribosome is composed of structures called the large and small subunits o Each subunit is formed from the assembly of Proteins Ribosomal RNA (rRNA) Ribosomes contain 3 discrete sites: Peptidyl site (P site) Aminoacyl site (A site) Exit site (E site) Page 11 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 Translation can be viewed as occurring in three stages: 1. Initiation In bacteria: The binding of mRNA to the 30S subunit is facilitated by a ribosomalbinding site or Shine-Dalgarno sequence o This is complementary to a sequence in the 16S rRNA within the small bacterial ribosomal subunit 16S rRNA Page 12 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 The only charged tRNA that ever enters through the P site 70S initiation complex This marks the end of the first stage In eukaryotes: Quite different than in bacteria o Recognition of the mRNA by the ribosome is through proteins (cap bainding proteins) attached to the 5’ cap of the mRNA o These are joined by a complex consisting of the 40S subunit, tRNAmet, and other initiation factors o The entire assembly moves along the mRNA scanning for the right start codon o Once it finds this AUG (usually, but not always, the first one it encounters), the 40S subunit binds to it o The 60S subunit then joins, forming the 80S initiation complex Page 13 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 2. Elongation During this stage, the amino acids are added to the polypeptide chain, one at a time See Figure 13.18, Brooker 3. Termination The final stage occurs when a stop codon is reached in the mRNA o In most species there are three stop or nonsense codons UAG UAA UGA o These codons are not recognized by tRNAs, but by proteins called release factors Indeed, the 3-D structure of release factors mimics that of tRNAs See Figure 13.19, Brooker VII. The Newly-translated Polypeptide Polypeptide synthesis has a directionality that parallels the 5’ to 3’ orientation of mRNA During each cycle of elongation, a peptide bond is formed between the last amino acid in the polypeptide chain and the amino acid being added Page 14 Modified from http://www.mhhe.com/brooker BIO 184 Fall 2006 LECTURE 3 VIII. Polypeptide Localization The amino acid sequences of newly-synthesized polypeptides contain “sorting signals” that tell the cell where they belong These are especially important in eukaryotes, where each sorting signal is recognized by a specific cellular component These cellular components facilitate the sorting of the protein to its correct compartment Many polypeptides will not fold properly and become functional proteins until they are properly localized within the cell Sometimes, mutations lead to changes in the amino acid sequence of the polypeptide that prevent its localization Such polypeptides are eventually degraded Localization mutations are usually null mutations (the protein coded by the gene has no residual function in the cell) Page 15