STATA Quick Introduction
advertisement

STATA Quick Introduction
(January 2007)
This handout provides short and quick introduction to STATA. If you want to increase
your skills in using STATA, please check manuals, and use help information whenever
you need help.
OUTLINE:
Starting and stopping Stata
Reading data into Stata:
Typing
Getting external files
Useful commands: List Summation Tabulation
Logical operators
Functions and expressions Generating variables Graphics
Simple linear regression
Subsetting the data Linear restrictions
Time series(lags and differences, DW test and Q-stats, autocrrelation,
Dicky-fuller test, Gold-Feld test)
Starting & Stopping Stata
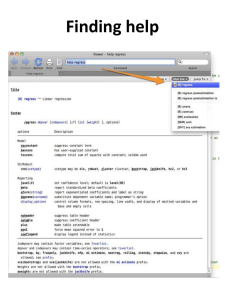
Starting STATA on the PC.
Click Start Programs Stata Intercooled Stata
You will find four windows:
(a) ‘Review’ window on the upper left, past commands will appear there;
(b) ‘Variables’ window on the lower left, variables list will appear there;
(c) ‘Results’ window, results will be displayed there;
(d) ‘Command’ window where you can type commands.
Also you will several ‘buttons’ above the windows. Just hold the mouse
pointer over a button for a moment and a box will appear with a
description of that button. The buttons that most frequently used are:
a. Open: open a Stata dataset;
b. Save: save to disk the Stata dataset currently in memory;
c. Do-file Editor: open the do-file editor or bring do-file editor to the
front of the other stats windows;
d. Data Editor: open the data editor or bring the data editor to the front of
the other Stata windows.
Stopping Stata.
Type exit in the command window, or just click button in upper right
corner of Stata window.
-1-
Reading Data into Stata
Comma/Tab separated file with variable names on line 1
Consider that you have the following data in Excel format.
Name
mary
john
jose
lee
mike
HOUR
10
11
5
6
9
GRADE
90
92
60
71
80
Here GRADE is just the % points. Two common file formats for raw data are
comma separated files and tab separated files. Such files are commonly made
from spreadsheet programs like Excel.
For example, if you have a data set in comma /tab separated file (you can save
excel data into .csv or .txt format), which stored in your C:\temp\data.csv, with
variable names on the first row.
This file has two characteristics. (1) The first line has the names of the
variables separated by comma/tabs. (2) The following lines have the
values for the variables, also separated by commas/tabs.
This kind of file can be read using the insheet command such as:
insheet using C:\temp\study.csv or (comma separated)
insheet using C:\temp\study.txt
(tab separated)
***NOTE:
However, insheet command could not handle a file that uses a mixture of commas
and tabs as delimiters.
****
Comma/Tab separated file without variable names on line 1
The same data as above except that there are no variable names on the first row.
Then where should Stata get the variable names?
If Stata does not have names for variables, it names then v1 v2 v3 etc …as we can
see from the window.
-2-
We can of course tell Stata the names of the variables on the same insheet
command, such as:
insheet name hour grade using C:\temp\study.csv
Space separated file
For this case, file can be read with the infile command as shown below:
infile str4 name hour grade using C:\temp\study.txt
(str4 means that variable NAME is a character variable (a string) and it could take
up to 4 characters wide.)
Fixed format file
If a file uses fixed column data, i.e., the variables are clearly defined by which
column(s) they are located. Then this type of file can be read with the infix
command as shown below:
infix str name 1-4 hour 5-6 grade 8-9 using C:\temp\study.csv
Creating a command file using do-file editor
Let’s introduce do-file editor window. Double-click the do-file editor icon, the
fifth from the right, a blank window will appear, now you can type the commands
such as use filename, list, summ, etc and save that as a do file. Only through this
way, your commands will not disappear after quitting Stata.
Writing Comments
You can put your comments in three different ways
1. ‘*’ type your comments after the ‘star’ (single line comment)
* My project for Econ 509
2. <CODES> // comments in the same line
3. comments in multiple lines
e.g /*My project for Econ 509 999999999999999 00000000000000 8888888888888888
77777777777777777777777 */
With /without Delimiter
You can work in STATA with or without the delimiter, such as ‘;’. Always be consistent.
If you have a habit of forgetting ‘;’ in each line of STATA codes, it is better to avoid its
use from the beginning. Because if you miss the delimiter once you specified it, it will
produce an error. If you are comfortable, then go for it.
Typing your codes
*Open do-file window, and type the following commands. Anything with ‘*’ is just a
comment
*clearing memory every time
clear;
-3-
*expects semi-colon at the end of each command line
#delimit;
*storing output file in: filename.log
log using e:\teaching\409\stexp0.log, replace;
*reading excel .CSV file with the variable labels
insheet using e:\teaching\409\hour.csv;
*Reading stata .DTA file with the variable labels
use a:\study.dta;
*listing the observations
list;
*graphing x-axis vs y-axis
graph hour grade, xlabel ylabel title("graph of study_hour
vs grades");
*Running Regression
regress grade hour;
*predicting fitted value of dependent variable
predict fgrade;
* calculating residuals and printing it
gen res = grade-fgrade;
list res;
*graph observed versus fitted against the indepen variable
graph grade fgrade hour, connect(.l);
*closing the output file
log close;
Do not worry about the commands; let’s take a look at the procedure steps.
a) First, we need to use ‘clear’ to clear the memory;
b) Second, it’d be better to use #delimit to indicate “;” for the end of each command;
c) Third, in order to save the output into a specified file we can create a log file in the
beginning, such as
log using a:\409\study0.log, replace;
which is paired with log close at the end. Then we can either view or copy & paste the
output file easily. Just click the start log icon, which is the fourth icon from the left on the
menu, then open the specified log file you already saved.
If you read in the data correctly, you should see the variable names appear and some lines
goes through results window. (no red letters, red letters indicate error).
-4-
Some useful commands
a. Descriptive statistics (the most simple and powerful commands are):
list ;
//List all or some of the observations.
For example,
list in 1/5 ;
//list the first five observations for all the variables
list hour in f/l ; //list “hour” from the first obs to the last one
*You will have the following in the results window:
1.
2.
3.
4.
5.
hour
10
11
5
6
9
;
list name in –2/l ;
//list the last two variable of “name”
*you will see the following in the results window:
4.
5.
name
lee
joe
.
Attention: -2/l, here “l’ is for “Last”, do not confuse it with one (1) in 1/5.
b.summarize(summ for short)
summ //gives you the mean, standard deviation, minimum and maximum value for all
//numerical variables.
Examples:
summ (gives you means of all numerical variables in your sample), the results should
be:
Variable |
Obs
Mean
Std. Dev.
Min
Max
-------------+----------------------------------------------------hour |
5
8.2
2.588436
5
11
grade |
5
78.6
13.37161
60
92
name |
0
summ hour ;
//only gives you mean study hour for the sample
tabulate
-5-
tab ;
// with one variable gives you a frequency distribution.
*`Tab’ with two or more variables gives you a cross-tab
Examples: tab grade (gives you the number of people (and the percentage) for each
grade level), the results are shown in the following table:
grade |
Freq.
Percent
Cum.
------------+----------------------------------60
|
1
20.00
20.00
71
|
1
20.00
40.00
80
|
1
20.00
60.00
90
|
1
20.00
80.00
92
|
1
20.00
100.00
------------+----------------------------------Total
|
5
100.00
tab hour grade;
level.
//gives you the number of people in study hour level and grade
Be careful not to ask for a tab of a continuous variable: you will get hundreds of values,
such as income.
c. Logical operators
They are used to evaluate an expression and then do something depending on the
outcome. The operators are:
= = equal to (you must use double = signs)
>= greater than or equal to
<= less than or equal to
> greater than
< less than
~= not equal to
& and : both conditions hold
| or : at least one condition holds
Examples:
summ hour if grade >=80 & grade <=100
grade between 80 and 100.
//calculates mean of study hour for students
list if (hour > 5) & (hour !=.) //list all the variables if study hour is greater than 5 and is
not missing
Functions and expressions
Taking log:
Raising to powers:
Taking square root:
Taking absolute value:
gen lhour = log(hour)
gen hournew = hour ^3
gen sqgrade = ln(sqrt(grade))
gen hournew= abs(hour)
-6-
Taking lags:
gen xlag = x[_n – 1]
or
gen xlagged = L.x (lag1 of x)
gen Xlag = X[_n – 2]
(lag2 of x)
Of course, the arithmetic operators, such as +, -, *, /, ^ are working.
Generating variables
New variables may be generated by using the commands generate or egen.
The command generate(gen for short) simply equates a new variable to an
expression which is evaluated for each observation.
generate minutes = hour* 60 if grade>80
Generating dummy variables
Suppose we are interested in construct one dummy variable to a random
variable X, such as grade, we want to create 1s for grade > 79, 0
otherwise. Then the appropriate Stata command is:
gen xdummy = (x > 79)
Stata will offer 1s for X>79, and 0s for X<80 automatically, please
remember we always put the conditions in the parenthesis.
The function egen provides an extension to generate. One advantage of
egen is that some of its functions accept a variable list as an argument,
whereas the functions for gen can only take simple expressions as
arguments.
egen average = rmean(x y z)
Another function works in the same way as generate is replace, which
allows an existing variable to be changed.
replace grade = 0 if grade < 60
Graphics
The command graph may be used to plot a large number of different graphs.
The basic syntax is [graph varlist, options] where varlist is the list of
variables and options are used to specify the type of graph.
For example, graph hour, normal title(“histogram of study hour”)
[the normal option overlaid a normal curve on our histogram, title option has
to be quoted]
-7-
Fraction
.4
0
5
11
hour
histogram of study hour
Now consider about the case that we are interested in the plotting more than
one variable, for example, we are interested in the relationship between the
grades and the study hours.
graph grade hour, xlabel ylabel title("graph of study_hour vs grades")
[the xlabel and ylabel options cause the x- and y-axes to be labeled using
round values, without them, only the minimum and maximum values are
labeled]
90
grade
80
70
60
4
6
8
hour
graph of study_hour vs grades
-8-
10
12
Of course if you want to save the graph, you have to add save(filename).
There are many options for graphics in Stata, if you want to explore more,
please check the manual: Stata Graphics for details.
Simple linear regression
Let’s begin by showing some examples of simple linear regression using
Stata. In this type of regression, we have only one predictor variable. This
variable can be either continuous or discrete. There is only one response or
dependent variable, and it is continuous.
In Stata, the dependent variable is listed immediately after the regress
command followed by one or more predictor variables, like regress [dep.
Var.] [predictors].
Let’s examine the relationship between the study hours and grades. From the
plot above, there is an obvious positive relationship between these two
variables. It looks like the more hours students spent on studying, the better
grade they have. For this example, the model we are interested in is: grade =
+ *hour+e, grade is the dependent variable and hour is the predictor:
regress grade hour
Source |
SS
df
MS
-------------+-----------------------------Model | 684.073134
1 684.073134
Residual | 31.1268657
3 10.3756219
-------------+-----------------------------Total |
715.20
4
178.80
Number of obs
F( 1,
3)
Prob > F
R-squared
Adj R-squared
Root MSE
=
=
=
=
=
=
5
65.93
0.0039
0.9565
0.9420
3.2211
-----------------------------------------------------------------------------grade |
Coef.
Std. Err.
t
P>|t|
[95% Conf. Interval]
-------------+---------------------------------------------------------------hour |
5.052239
.6222138
8.12
0.004
3.072077
7.032401
_cons |
37.17164
5.301613
7.01
0.006
20.29954
54.04374
In addition to getting the regression table, we can also get the predicted
variables and plot them.
For example,
predict fgrade
[fgrade is the name of the new predicted variable]
list grade fgrade [take a look at the predicted ones]
1.
2.
3.
4.
5.
grade
90
92
60
71
80
-9-
fgrade
87.69403
92.74627
62.43283
67.48508
82.64179
graph grade fgrade hour, connect(.l)
[graph the original and fitted values against hour, connecting the fitted line]
grade
Fitted values
92.7463
60
5
11
hour
Subsettting data manipulations
We can subset data by keeping or dropping variables, and we can also subset data
by keeping or dropping observations. Now let’s focus on keeping and dropping
observations.
For example, we have the data as follows, either entering by data editor or reading
from external file. For gender, 0=female, 1=male; income is divided by $100;
year means how long people have experiences for this kind of job; for degree,
0=no degree, 1=B.S.(B.A.), 2=M.S.(M.A.).
gender
1
0
1
1
0
0
1
1
0
0
-999
-999
income
10
30
15
19
27
23
45
27
29
30
22
19
degree
0
1
0
0
2
1
2
1
2
2
1
1
- 10 -
year
5
7
9
10
12
10
5
9
7
8
15
9
Please note that there are two –999 in gender which represent for missing values,
we can generate missing values, using
replace gender=. if gender ==-999 // [double equal ==]
Suppose we only take care of non-missing values, we can drop the missing
values, using drop if (gender==.).
Now we want to split the sample into two sections, one for female, the other for
male, and want to regression on these two parts separately using model:
Income = +1*degree + 2*year. Here is one way to handle this.
To extract only female, keep if gender==0 and save it into a new data file such as
D:\pr_stata\incomef.dta, then we run the regression using the new data set.
*extract only female and save it into new data*
keep if gender==0
save D:\pr_stata\incomef.dta, replace
*run the regression using new data
use D:\pr_stata\incomef.dta
reg income degree year
*back to original data*
use D:\pr_stata\income.dta
*extract only male, and save into another new
data
keep if gender==1
save D:\pr_stata\incomem.dta, replace
*run the regression using male new data
use D:\pr_stata\incomem.dta
reg income degree year
Linear Restrictions
Often we want to test linear hypothesis after model estimation, the most useful
command is test. It performs F or 2 tests of linear restrictions about the estimated
parameters from the most recently estimated model using a Wald test.
There are several version of syntax, we only introduce two versions, for detail
please check Stata Manual [Reference: test].
1) test expressions = expressions
- 11 -
2) test coefficientlist {note: coefficientlist van simply be a list of variable
names}
Examples:
Suppose we have estimated a model of 1980 Census data on the 50 states
recording the birth rate in each state (brate), the median age (medage) and its
square (medagesq), and the region of the country in which each state is located.
The variable reg1 =1 if the state is located in the Northeast, otherwise 0; whereas
reg2 = 1 if the state is located in the North Central, reg3 marks the South, and
reg4 makes the West.
First we estimate the following regression:
reg brate medage medagesq reg2-reg4
*reg2-reg4 is the abbreviation for reg2, reg3 and reg4
If we want to test (F) if the coefficient on medage is zero, just type:
test medage = 0
If we want to test the coefficient on reg2 is the same as that on reg4, we can do
test reg2 = reg4
Of course, we can put more complicated linear restrictions here, like
test 2*reg2-3*reg4 = reg3
However, the real power of test is when we test joint hypothesis. Suppose we
wish to test whether the region variables, taken as a whole, are significant. To
perform tests of this kind, specify each constraint and accumulate it with
previous constraints:
test reg2 = 0
test reg3 = 0, accumulate
test reg4 = 0, accumulate
Typing separate test commands for each constraint, like above, can be tedious, the
second syntax allows us to perform our last test more conveniently:
test reg2 reg3 reg4
- 12 -
Dealing with time series Data
a) Setting the time span
We have to let Stata know the time span variable at the beginning, and the
command is tsset.
There are two cases. One is our data already provide the time span
information, for example, we have an annual exchange rate data consisting
of two observations: year exchrate, “year” here is the variable that infers
the time span, we simply say
tsset year;
then Stata will read the data as annual time series dataset.
The other case is that we have to generate the time span by ourselves since
we do not have it in our data.
For example, if we want to generate annual data starting in 1985,
gen t = y(1985) + _n-1;
//1985 is the start time, y indicates year()
tsset t;
if we want to generate quarterly data starting in 1973:II, then
gen t = q(1973q2) +_n-1;
/*1973q2 means the start time:the 2nd
quarter in 1973, q() infers quarterly()*/
format t %tq;
//assign Stata format for quarterly data to t
tsset t;
if we want to generate monthly data starting in 1995 July, then
gen t = m(1995m7)+_n-1; /*1995m7 means the start time, m() infers
monthly*/
format t %tm;
/*assign Stata format for monthly data to t*/
tsset t;
if we want to generate weekly data starting from the 1st week of 1995, then
gen t = w(1995w1)+_n-1;
/*1995w1 indicates the start time, w() infers
weekly*/
format t %tw;
/*assign Stata format for weekly data to t*/
tsset t;
Generating lags and differences
Suppose x and y are random time series variables.
If we want to create 1 lag of y, then we can generate a new variable ylag1:
gen ylag1 = y[_n-1];
Applying the same idea if we want to create 2 lags of y, then we can
generate another new variable ylag2 as:
gen ylag2 = y[_n-2];
- 13 -
also we can generate lags of x as
gen xlag1 = x[_n-1];
To generate the differences of variables, we use D..
If we want to generate 1st order difference of y, we can create a new
variable dy1 as:
gen dy1 = D.y;
If we want o generate 1st order difference of dy1, we can create another
new variable dy2 as:
gen dy2 = D.D.y;
To generate a seasonal difference, we can create the lags first then take the
difference. For example, we want to create a new variable sdy4 for
seasonal difference of a quarterly data,
gen sdy4 = y-y[_n-4];
Durbin-Walson test and Q-stats
The Stata command are dwstat and wntestq. These commands can be
applied after estimation and storing residuals.
For example:
reg y ylag1 ylag2 xlag1;
predict uhat, residuals;
/*store residuals into uhat*/
dwstat;
wntestq uhat, lag(20);
/*Q-stat on residuals up to 20 lags*/
Autocorrelation
prais estimates a linear regression of depvar on varlist that is corrected for
first-order serially-correlated residuals using the Prais-Winsten
transformed regression estimator, the Cochrane-Orcutt transformed
regression estimator, or a version of the search method suggested by
Hildreth-Lu.
Please pay attention that prais is for use with time-series data. You must
tsset your data before using prais.
For example,
prais y x1 x2, corc;
/*corc specifies that the Cochrane-Orcutt transformation be used to
estimate the equation*/
- 14 -
prais y x1 x2, corc ssesearch;
/*ssesearch specifies that a search is performed for the value of rho that
minimizes the sum of squared errors of the transformed equation*/
Dicky-Fuller and Unit Root
Let’s still use the variables created earlier. There are two ways for D-F
test.
reg dy1 ylag1;
Or,
reg y ylag1;
/*test the coefficient is zero*/
/*test the coefficient is 1*/
To perform augmented Dicky-Fuller test, we can use dfuller command.
This test performs a regression of the differenced variable on its lag and
the user-specified number of lagged differences of the variable.
For example,
dfuller y, lags(5) regress;
Gold_Feld test
To perform the Gold_Feld test, first we need to split the observations into
two parts. Usually we sort the variable first then run two regressions on
separate parts.
For example, we have data about expenditure (exp) and income (inc), and
we are interested in performing Gold-Feld for inc. What we can do is as
follows:
sort inc;
/*sorting the data first*/
list inc exp in 1/5;
/*checking the sorted data*/
reg exp inc in 1/10; /*run OLS on the 1st part of the obs*/
reg exp inc in 21/40; /*run OLS on the 2nd part of the obs*/
then extract the SSR to perform the test.
- 15 -
Some Useful Extras
Merging
When you are dealing with complex data sets, then your data might be in several different
files. Before analyzing such data in different files, you need to create a common file with
the relevant variables from different files that you are interested in. One way of
combining such different tables is using “merge”.
For merging two files, you need common ID in both files. If that is the case, then do the
following
sort ID
// ID is the name of the common ID in both files
*after sorting, save the file under different name
*Read the second file and sort with ID. Now you are ready to merge two data sets.
merge ID using <file name that you just saved>
*Now your two data sets are in one file.
*To make sure you merged the files appropriately, type
* If you have more files, just repeat those steps
Reshaping
Your data might be in one of the following form
(wide form)
i
....... x_ij ........
id sex inc80 inc81 inc82
------------------------------1 0 5000 5500 6000
2 1 2000 2200 3300
3 0 3000 2000 1000
(long form)
i j
x_ij
id year sex inc
----------------------1 80 0 5000
1 81 0 5500
1 82 0 6000
2 80 1 2000
2 81 1 2200
2 82 1 3300
3 80 0 3000
- 16 -
3
3
81
82
0 2000
0 1000
*To reshape the data from wide to long, do the following
reshape long inc, i(id) j(year) // goes from top-form to bottom
*to reshape the data from long to wide, do the following
reshape wide inc, i(id) j(year) //goes from bottom-form to top
Collapsing
*collapse converts the dataset in memory into a dataset of means, sums, medians, etc.
Example: If you have a data set across 50 states and you want to get the summary
statistics of each state. Use the following command
collapse age educ income, by(state) // here age, educ and income are 3
variables
*coll2, an alternative to collapse, converts the data in memory into a data set
of means, sums, medians, etc.
coll2 age educ income, by(state)
*in above cases, you will get mean values of age, edu and income across all the states. If
you want something different such as mode or sum, you have to specify as:
coll2 (model) age educ income, by(state)
Weighting Issue
Most Stata commands can deal with weighted data. It is basically useful in survey data.
Stata allows four kinds
of weights:
1. fweights, or frequency weights, are weights that indicate the number
of duplicated observations.
2. pweights, or sampling weights, are weights that denote the inverse of
the probability that the observation is included due to the sampling
design.
3. aweights, or analytic weights, are weights that are inversely
proportional to the variance of an observation; i.e., the variance of
the j-th observation is assumed to be sigma^2/w_j, where w_j are the
weights. Typically, the observations represent averages and the
weights are the number of elements that gave rise to the average. For
- 17 -
most Stata commands, the recorded scale of aweights is irrelevant;
Stata internally rescales them to sum to N, the number of observations
in your data, when it uses them.
4. iweights, or importance weights, are weights that indicate the
"importance" of the observation in some vague sense. iweights have no
formal statistical definition; any command that supports iweights will
define exactly how they are treated. In most cases, they are intended
for use by programmers who want to produce a certain computation.
Example:
Suppose you are running a regression of y on x1, x2, x3, and you have a variable called
pop that you want to use as a weight, they do the following
regress y x1 x2 x3 [aw=pop]
analytical weight.
// remember the square brackets, and ‘aw’ refers to
- 18 -